第六章、epub文件处理 -- 解析container文件与.opf文件
2019独角兽企业重金招聘Python工程师标准>>> 
第六章、epub文件处理 -- 解析container文件与.opf文件
这一章我们会接着第三章结尾介绍的FBReaderApp类的openBookInternal继续,开始介绍解析container文件与.opf文件。
这一章中会涉及到第二章、第四章、第五章中介绍的内容,大家可以互相参照,加深理解
首先,我们来回顾下第四章“epub文件处理 -- epub文件内部组成”的内容。我们在第四章中曾经介绍过,epub文内部包含的文件包括“container.xml文件、.opf文件、.ncx文件、.xhtml文件”。这些文件都是被压缩过的xml文件,而在这些不同的xml文件中包含着不同的标签,每种标签又都代表着不同的信息。为了对每种xml文件的标签作统一处理,FBReader程序对每种文件都设置了对应的类。每种类就专门处理来对应的xml文件里面的标签。
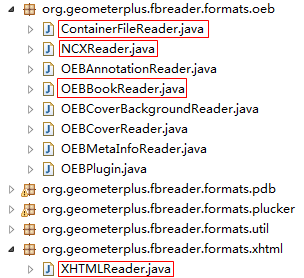
ContainerFileReader类对应container.xml文件;OEBBookReader类对应.opf文件; NCXReader类对应.ncx文件文件;XHTMLReader类对应.xhtml文件。
PS:这些类都是ZLXMLReaderAdapter抽象类的子类,本章会涉及到ContainerFileReader类与OEBBookReader类
我们在第四章中还曾经分别介绍过container文件与.opf文件分别的作用。
container文件的“作用就是标明了.opf文件的位置”;.opf文件则描述了epub书籍的元信息、epub文件内部对应不同章节对应的文件的位置以及每个章节出现的先后次序。
我们这一章解析这两种文件,就是为了获取这些信息。
在介绍解析流程之前,我们还需要再回顾下解析xml文件的三个核心类。这个部分内容,我们曾经在第二章“解析资源文件”中介绍过。当时,我们是这么介绍的:“
继续回到解析xml文件的核心类ZMLZMLProcessor、ZLXMLParser、ZLXMLReader。
这三个核心类的调用顺序一般是这样的:
1、ZLXMLReaderAdapter抽象类的子类(ResourceTreeReader类)里面的read方法调用ZLXMLProcessor类的read方法
2、ZLXMLProcessor类的read方法通过AndroidAssetsFile类(ZLResourceFile类的子类)的getInputStream方法获取一个针对资源文件的字节流类(AssetInputStream类),并以这个字节流类为参数初始化了一个针对资源文件的字符流类。接着,就调用了ZLXMLParser类的doIt方法。
3、 ZLXMLParser类的doIt方法利用字符流类将文件转换成一个char数组。再利用for循环迭代byte数组的过程中,doIt方法又反过来调用ZLXMLReader接口实现类(ResourceTreeReader类)的startElementHandler与endElementHandler方法对byte数组中元素所代表的不同节点进行操作。
请注意,上面这段话标红的部分,这些部分在解析epub内部文件的流程中已经不适用了。
1、ZLXMLReaderAdapter抽象类的子类(ContainerFileReader类、OEBBookReader类、NCXReader类、XHTMLReader类中的一种)里面的read方法调用ZLXMLProcessor类的read方法
2、ZLXMLProcessor类的read方法通过ZLZipEntryFile类的getInputStream方法和ZLZipEntryFile类对应的LocalFileHeader类获取一个针对epub内部xml文件的字节流类(ZipInputStream类),并以这个字节流类为参数初始化了一个针对资源文件的字符流类。接着,就调用了ZLXMLParser类的doIt方法。
3、 ZLXMLParser类的doIt方法利用字符流类将文件转换成一个char数组(第五章用一整个章节介绍了这个转换的流程)。再利用for循环迭代byte数组的过程中,doIt方法又反过来调用ZLXMLReader接口实现类(ResourceTreeReader类)的startElementHandler与endElementHandler方法对byte数组中元素所代表的不同节点进行操作。
首先,“ZLXMLReaderAdapter抽象类的子类”已经不再是那个ResourceTreeReader类了,而是专门对应epub内部各种xml文件的一个类(ContainerFileReader类、OEBBookReader类、NCXReader类、XHTMLReader类中的一种)。
PS:ResourceTreeReader类是程序专门为处理资源文件内部的标签而创建的类
其次,程序在解析epub内部xml文件的时候,不会去获取“针对资源文件的字节流类”,而是会通过调用ZLZipEntryFile类的getInputStream方法获取针对epub内部xml文件的字节流类(ZipInputStream类)。相对得,之后也会以这个字节流类来获得对应的字符流类。
PS:ZLZipEntryFile类的getInputStream方法的具体处理流程我们曾经用了第五章“XML文件处理 -- 解压”一整章来作介绍
好了,下面我们就正式开始解析流程。
FBReaderApp类的openBookInternal方法中会调用BookModel类的createModel方法。

crateModel方法,会调用PluginCollection类的getPlugin方法

getPlugin方法调用了所有FormatPlugin抽象类子类的acceptsFile方法,这个方法其实就是比较了Book类中File属性指向的File类的myExtension属性(这个属性的赋值我们在第三章“获取书籍信息”中介绍过),如果myExtension属性代码内置的变量相同,getPlugin方法就会返回当前的FormatPlugin抽象类子类。而在处理epub文件时,代码会返回OEBPlugin类。
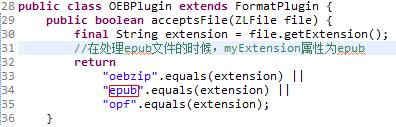
OEBPlugin类readModel方法
获得了OEBPlugin类之后,代码就会调用该类中的readModel方法。
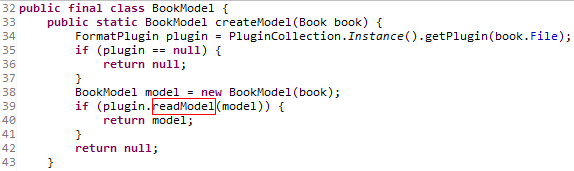
readModel方法调用了两个方法:OEBPlugin类的getOpfFile方法与OEBBookReader类readBook方法
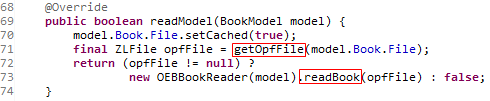
OEBPlugin类的getOpfFile方法:
getOpfFile方法一共有三步: 
第一步
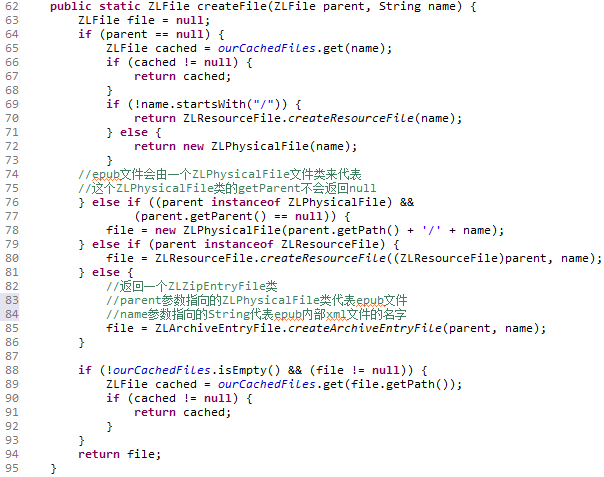
调用ZLFile类的createFile方法
这个方法的参数oebFile参数是Book类的File属性(这个属性的赋值过程在第三章“获取书籍信息”介绍过),最终这个方法会返回一个代表container.xml文件的ZLZipEntryFile类。
我们曾经在第二章“解析资源文件”中介绍过:“ZLZipEntryFile类用来处理epub文件内部的xml文件”。也曾经在第四章“epub文件处理 -- epub文件内部组成”介绍过container.xml文件,这个文件的作用就是“标明了.opf文件的位置”。
我们从代码中可以看到,代表container.xml文件的ZLZipEntryFile会包含两个属性(85行):一个代表epub文件的ZLPhysicalFile类,一个代表epub内部xml文件名种子的String变量(在这里就是)。
第二步
ContainerFileReader类的read方法。
看到这个方法,你应该会记起这一章开头介绍的“解析epub内部文件的流程”吧。
1、ZLXMLReaderAdapter抽象类的子类(ContainerFileReader类、OEBBookReader类、NCXReader类、XHTMLReader类中的一种)里面的read方法调用ZLXMLProcessor类的read方法
2、ZLXMLProcessor类的read方法通过ZLZipEntryFile类的getInputStream方法和ZLZipEntryFile类对应的LocalFileHeader类获取一个针对epub内部xml文件的字节流类(ZipInputStream类),并以这个字节流类为参数初始化了一个针对资源文件的字符流类。接着,就调用了ZLXMLParser类的doIt方法。
3、 ZLXMLParser类的doIt方法利用字符流类将文件转换成一个char数组(第五章用一整个章节介绍了这个转换的流程)。再利用for循环迭代byte数组的过程中,doIt方法又反过来调用ZLXMLReader接口实现类(ResourceTreeReader类)的startElementHandler与endElementHandler方法对byte数组中元素所代表的不同节点进行操作。
在这个解析流程中, .opf 文件的位置信息会被存储到 ContainerFileReader 类的 myRootPath 属性( 35 行)


第三步
代码以包含.opf的位置信息的String为参数又调用了ZLFile类的createFile方法,这个方法会返回代表.opf文件的ZLZipEntryFile类,获取这个类之后,代码会进入OEBBookReader类readBook方法
OEBBookReader类readBook方法:
这个方法分为两步:第一步、更新myHtmlFileNames属性;第二步、for循环迭代myHtmlFileNames属性指向的ArrayList,解析xhtml文件。
第一步
更新myHtmlFileNames属性
OEBBookReader类的read方法更新了myHtmlFileNames属性。

OEBBookReader类的read方法用让代码进入了解析xml文件的流程:
1、ZLXMLReaderAdapter抽象类的子类(ContainerFileReader类、OEBBookReader类、NCXReader类、XHTMLReader类中的一种)里面的read方法调用ZLXMLProcessor类的read方法
2、ZLXMLProcessor类的read方法通过ZLZipEntryFile类的getInputStream方法和ZLZipEntryFile类对应的LocalFileHeader类获取一个针对epub内部xml文件的字节流类(ZipInputStream类),并以这个字节流类为参数初始化了一个针对资源文件的字符流类。接着,就调用了ZLXMLParser类的doIt方法。
3、 ZLXMLParser类的doIt方法利用字符流类将文件转换成一个char数组(第五章用一整个章节介绍了这个转换的流程)。再利用for循环迭代char数组的过程中,doIt方法又反过来调用ZLXMLReader接口实现类(ResourceTreeReader类)的startElementHandler与endElementHandler方法对byte数组中元素所代表的不同节点进行操作。
我们曾经在第四章“epub文件处理 -- epub文件内部组成”中介绍过.opf文件中的“manifest节点的作用是描述epub文件内部对应不同章节对应的文件的位置”。

我们现在就是要把这些位置信息存储到myHtmlFileNames属性指向的ArrayList中。而这个工作是OEBBookReader类的startElementHandler方法中完成的。

第二步
for循环迭代myHtmlFileNames属性指向的ArrayList,解析xhtml文件
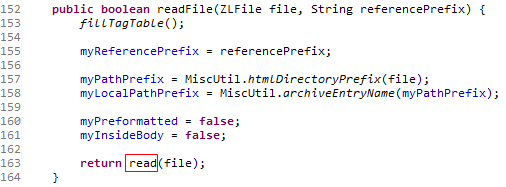
ZLFile类的createFileByPath方法会生成代表xhtml文件的ZLZipEntryFile类。之后XHTMLReader类的readFile方法会开始对xhtml文件的解析。

XHTMLReader类的readFile方法会调用本类的read方法。这个方法又会让代码进入解析xml文件的流程。这个流程我们在本章中已经多次遇到了。走完这个流程,我们就会得到一个有xml文件转换成的char数组。代码循环迭代这个char数组,调用XHTMLReader类的startElementHandler与endElementHandler方法对byte数组中元素所代表的不同节点进行操作。
对xhtml文件中各节点的操作比container.xml与.opf文件的操作要复杂很多,我们将用两个章节来介绍。
转载于:https://my.oschina.net/u/938986/blog/335878
第六章、epub文件处理 -- 解析container文件与.opf文件相关推荐
- C/C++ 语言中.h文件和.c文件详细解析 引用 .c和.h文件的区别
参考:http://blog.csdn.net/wuan584974722/article/details/30362405 简单的说其实要理解C文件与头文件(即.h)有什么不同之处,首先需要弄明白编 ...
- epub格式电子书剖析之二:OPF文件构成
OPF文档是epub电子书的核心文件,且是一个标准的XML文件,依据OPF规范,主要由五个部分组成: 1.<metadata>,元数据信息,由两个子元素组成: <dc-metadat ...
- FSN文件的解析(点钞机读取钱币文件)
1.FsnParser.h文件 #pragma once #include <Windows.h> #include <iostream> #include <vecto ...
- java读取.fsn文件内容_FSN文件的解析(点钞机读取钱币文件)
1.FsnParser.h文件 #pragma once #include #include #include #include #define READ_SIZE 100 /** * @brief ...
- php修改音频文件_解析用PHP读写音频文件信息的详解(支持WMA和MP3)
// AudioExif.class.php // 用PHP进行音频文件头部信息的读取与写入 // 目前只支持 WMA 和 MP3 两种格式, 只支持常用的几个头部信息 // // 写入信息支持: T ...
- Android视频开发进阶(part2-MP4文件的解析)
上一期文章我分享了一些视频播放里面的术语和基本概念.这一篇文章我会主要介绍容器(container format file)格式文件的细节,以最常见的MP4文件入手.然后会简短的介绍一个标准的播放器的 ...
- 大学物理第六章 静电场详解(全)
电场 电场强度 一.电荷 电荷的概念是从物体带电的现象中产生的,电荷是物体状态的一种属性,宏观物体或微观粒子处于带电状态就说它们带有电荷 物体或微观粒子所带的电荷有两种,称为正电荷和负电荷,带同种电荷 ...
- ECC有关DER文件的解析(Java)
ECC有关DER文件的解析(Java) 本篇博客提供有关ECC的DER文件的Java解析方式,如ECC公钥和ECC签名值对应DER文件的解析,PEM文件也能够使用本博客中提供的解析方式进行解析,PEM ...
- Zip文件的解析与生成
一.Zip文件的解析 在解压zip文件时,有一类专门的输入流ZipInputStream,继承自FilterInputStream,用来实现Zip文件的读取,这类输入流是完成特定功能的输入流,采用ja ...
最新文章
- 【渝粤题库】陕西师范大学200701 数字逻辑
- 浮点数转换为整数四舍五入_定义宏以将浮点值四舍五入为C中最接近的整数
- 【知识】人工智能数学基础知识
- 类型转换和操作符重载 (c#)
- python中的或运算_python入门:if语句中的逻辑运算符
- 某LINUX下,从快捷方式的目录运行程序,参数就是快捷方式的名
- 如何将Java源代码转换为HTML页面
- Swift -《从0到1 - 5》:封装网络请求工具类(Alamofire + Moya + SwiftyJSON)和链式封装
- 新个人所得税计算公式
- TWR_MPC8309调试日志
- AutoJs学习-读取手机短信
- 《编译原理》(一)绪论
- 电商产品精修训练营第3天_ps修复画笔工具_ps修补工具_ps仿制图章工具
- 1.已知长方形的长和宽,求长方形的周长和面积。
- 搭建 rasa 框架中遇到的 domain.yml 无效问题
- 【转载】按键精灵对安卓APP进行自动化界面点击测试
- html动画变圆,HTML5 canvas制作圆形的万花筒动画效果
- 如何开发一个浏览器插件
- java研发工程师、数据库开发
- java 算法移植_Java:Chacha20算法(从openssl移植)