Linux TCP队列相关参数的总结
作者:阿里技术保障锋寒
原文:https://yq.aliyun.com/articles/4252
在Linux上做网络应用的性能优化时,一般都会对TCP相关的内核参数进行调节,特别是和缓冲、队列有关的参数。网上搜到的文章会告诉你需要修改哪些参数,但我们经常是知其然而不知其所以然,每次照抄过来后,可能很快就忘记或混淆了它们的含义。本文尝试总结TCP队列缓冲相关的内核参数,从协议栈的角度梳理它们,希望可以更容易的理解和记忆。注意,本文内容均来源于参考文档,没有去读相关的内核源码做验证,不能保证内容严谨正确。作为Java程序员没读过内核源码是硬伤。
下面我以server端为视角,从 连接建立、 数据包接收 和 数据包发送 这3条路径对参数进行归类梳理。
一、连接建立
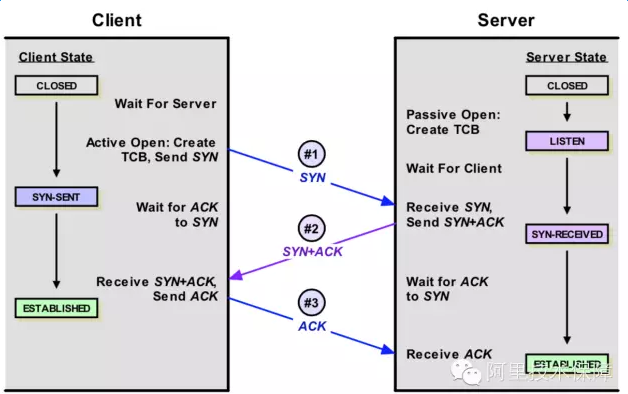
简单看下连接的建立过程,客户端向server发送SYN包,server回复SYN+ACK,同时将这个处于SYN_RECV状态的连接保存到半连接队列。客户端返回ACK包完成三次握手,server将ESTABLISHED状态的连接移入accept队列,等待应用调用accept()。
可以看到建立连接涉及两个队列:
半连接队列,保存SYN_RECV状态的连接。队列长度由net.ipv4.tcp_max_syn_backlog设置
accept队列,保存ESTABLISHED状态的连接。队列长度为min(net.core.somaxconn,backlog)。其中backlog是我们创建ServerSocket(intport,int backlog)时指定的参数,最终会传递给listen方法:
#include int listen(int sockfd, int backlog);
如果我们设置的backlog大于net.core.somaxconn,accept队列的长度将被设置为net.core.somaxconn
另外,为了应对SYNflooding(即客户端只发送SYN包发起握手而不回应ACK完成连接建立,填满server端的半连接队列,让它无法处理正常的握手请求),Linux实现了一种称为SYNcookie的机制,通过net.ipv4.tcp_syncookies控制,设置为1表示开启。简单说SYNcookie就是将连接信息编码在ISN(initialsequencenumber)中返回给客户端,这时server不需要将半连接保存在队列中,而是利用客户端随后发来的ACK带回的ISN还原连接信息,以完成连接的建立,避免了半连接队列被攻击SYN包填满。对于一去不复返的客户端握手,不理它就是了。
二、数据包的接收
先看看接收数据包经过的路径:
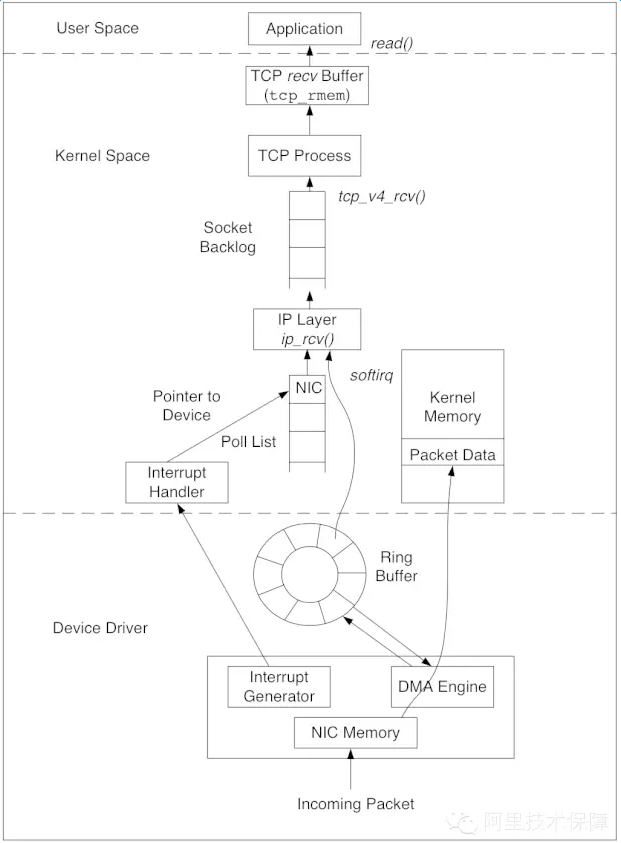
数据包的接收,从下往上经过了三层:网卡驱动、系统内核空间,最后到用户态空间的应用。Linux内核使用sk_buff(socketkernel buffers)数据结构描述一个数据包。当一个新的数据包到达,NIC(networkinterface controller)调用DMAengine,通过RingBuffer将数据包放置到内核内存区。RingBuffer的大小固定,它不包含实际的数据包,而是包含了指向sk_buff的描述符。当RingBuffer满的时候,新来的数据包将给丢弃。一旦数据包被成功接收,NIC发起中断,由内核的中断处理程序将数据包传递给IP层。经过IP层的处理,数据包被放入队列等待TCP层处理。每个数据包经过TCP层一系列复杂的步骤,更新TCP状态机,最终到达recvBuffer,等待被应用接收处理。有一点需要注意,数据包到达recvBuffer,TCP就会回ACK确认,既TCP的ACK表示数据包已经被操作系统内核收到,但并不确保应用层一定收到数据(例如这个时候系统crash),因此一般建议应用协议层也要设计自己的确认机制。
上面就是一个相当简化的数据包接收流程,让我们逐层看看队列缓冲有关的参数。
网卡Bonding模式
当主机有1个以上的网卡时,Linux会将多个网卡绑定为一个虚拟的bonded网络接口,对TCP/IP而言只存在一个bonded网卡。多网卡绑定一方面能够提高网络吞吐量,另一方面也可以增强网络高可用。Linux支持7种Bonding模式:详细的说明参考内核文档LinuxEthernet Bonding Driver HOWTO。我们可以通过cat/proc/net/bonding/bond0查看本机的Bonding模式:
一般很少需要开发去设置网卡Bonding模式,自己实验的话可以参考这篇文档
Mode 0(balance-rr) Round-robin策略,这个模式具备负载均衡和容错能力
Mode 1(active-backup) 主备策略,在绑定中只有一个网卡被激活,其他处于备份状态
Mode 2(balance-xor) XOR策略,通过源MAC地址与目的MAC地址做异或操作选择slave网卡
Mode 3 (broadcast) 广播,在所有的网卡上传送所有的报文
Mode 4 (802.3ad) IEEE 802.3ad动态链路聚合。创建共享相同的速率和双工模式的聚合组
Mode 5 (balance-tlb) Adaptive transmit loadbalancing
Mode 6 (balance-alb) Adaptive loadbalancing
网卡多队列及中断绑定
随着网络的带宽的不断提升,单核CPU已经不能满足网卡的需求,这时通过多队列网卡驱动的支持,可以将每个队列通过中断绑定到不同的CPU核上,充分利用多核提升数据包的处理能力。
首先查看网卡是否支持多队列,使用lspci-vvv命令,找到Ethernetcontroller项:
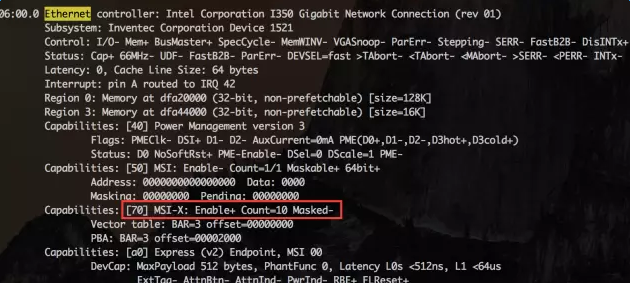
如果有MSI-X, Enable+ 并且Count > 1,则该网卡是多队列网卡。
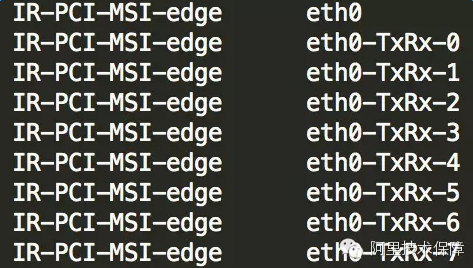
然后查看是否打开了网卡多队列。使用命令cat/proc/interrupts,如果看到eth0-TxRx-0表明多队列支持已经打开:
最后确认每个队列是否绑定到不同的CPU。cat/proc/interrupts查询到每个队列的中断号,对应的文件/proc/irq/${IRQ_NUM}/smp_affinity为中断号IRQ_NUM绑定的CPU核的情况。以十六进制表示,每一位代表一个CPU核:
(00000001)代表CPU0(00000010)代表CPU1(00000011)代表CPU0和CPU1
如果绑定的不均衡,可以手工设置,例如:
echo "1" > /proc/irq/99/smp_affinity echo "2" > /proc/irq/100/smp_affinity echo "4" > /proc/irq/101/smp_affinity echo "8" > /proc/irq/102/smp_affinity echo "10" > /proc/irq/103/smp_affinity echo "20" > /proc/irq/104/smp_affinity echo "40" > /proc/irq/105/smp_affinity echo "80" > /proc/irq/106/smp_affinity
RingBuffer
Ring Buffer位于NIC和IP层之间,是一个典型的FIFO(先进先出)环形队列。RingBuffer没有包含数据本身,而是包含了指向sk_buff(socketkernel buffers)的描述符。
可以使用ethtool-g eth0查看当前RingBuffer的设置:
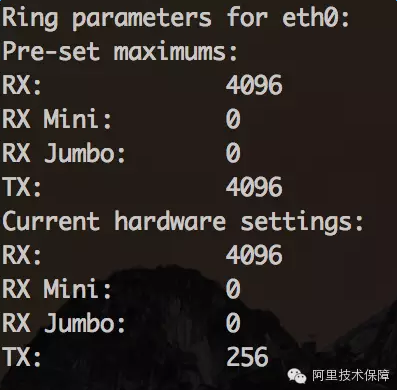
上面的例子接收队列为4096,传输队列为256。可以通过ifconfig观察接收和传输队列的运行状况:
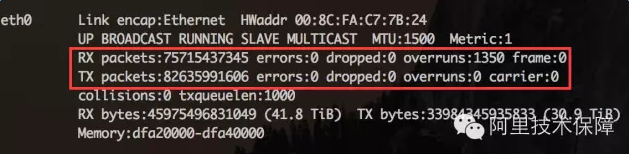
RXerrors:收包总的错误数
RX dropped:表示数据包已经进入了RingBuffer,但是由于内存不够等系统原因,导致在拷贝到内存的过程中被丢弃。
RX overruns:overruns意味着数据包没到RingBuffer就被网卡物理层给丢弃了,而CPU无法及时的处理中断是造成RingBuffer满的原因之一,例如中断分配的不均匀。
当dropped数量持续增加,建议增大RingBuffer,使用ethtool-G进行设置。
InputPacket Queue(数据包接收队列)
当接收数据包的速率大于内核TCP处理包的速率,数据包将会缓冲在TCP层之前的队列中。接收队列的长度由参数net.core.netdev_max_backlog设置。
recvBuffer
recv buffer是调节TCP性能的关键参数。BDP(Bandwidth-delayproduct,带宽延迟积) 是网络的带宽和与RTT(roundtrip time)的乘积,BDP的含义是任意时刻处于在途未确认的最大数据量。RTT使用ping命令可以很容易的得到。为了达到最大的吞吐量,recvBuffer的设置应该大于BDP,即recvBuffer >= bandwidth * RTT。假设带宽是100Mbps,RTT是100ms,那么BDP的计算如下:
BDP = 100Mbps * 100ms = (100 / 8) * (100 / 1000) = 1.25MB
Linux在2.6.17以后增加了recvBuffer自动调节机制,recvbuffer的实际大小会自动在最小值和最大值之间浮动,以期找到性能和资源的平衡点,因此大多数情况下不建议将recvbuffer手工设置成固定值。
当net.ipv4.tcp_moderate_rcvbuf设置为1时,自动调节机制生效,每个TCP连接的recvBuffer由下面的3元数组指定:
net.ipv4.tcp_rmem =
最初recvbuffer被设置为,同时这个缺省值会覆盖net.core.rmem_default的设置。随后recvbuffer根据实际情况在最大值和最小值之间动态调节。在缓冲的动态调优机制开启的情况下,我们将net.ipv4.tcp_rmem的最大值设置为BDP。
当net.ipv4.tcp_moderate_rcvbuf被设置为0,或者设置了socket选项SO_RCVBUF,缓冲的动态调节机制被关闭。recvbuffer的缺省值由net.core.rmem_default设置,但如果设置了net.ipv4.tcp_rmem,缺省值则被覆盖。可以通过系统调用setsockopt()设置recvbuffer的最大值为net.core.rmem_max。在缓冲动态调节机制关闭的情况下,建议把缓冲的缺省值设置为BDP。
注意这里还有一个细节,缓冲除了保存接收的数据本身,还需要一部分空间保存socket数据结构等额外信息。因此上面讨论的recvbuffer最佳值仅仅等于BDP是不够的,还需要考虑保存socket等额外信息的开销。Linux根据参数net.ipv4.tcp_adv_win_scale计算额外开销的大小:
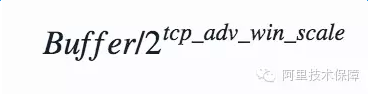
如果net.ipv4.tcp_adv_win_scale的值为1,则二分之一的缓冲空间用来做额外开销,如果为2的话,则四分之一缓冲空间用来做额外开销。因此recvbuffer的最佳值应该设置为:
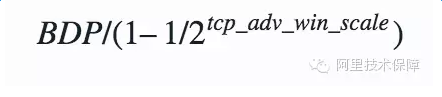
三、数据包的发送
发送数据包经过的路径:
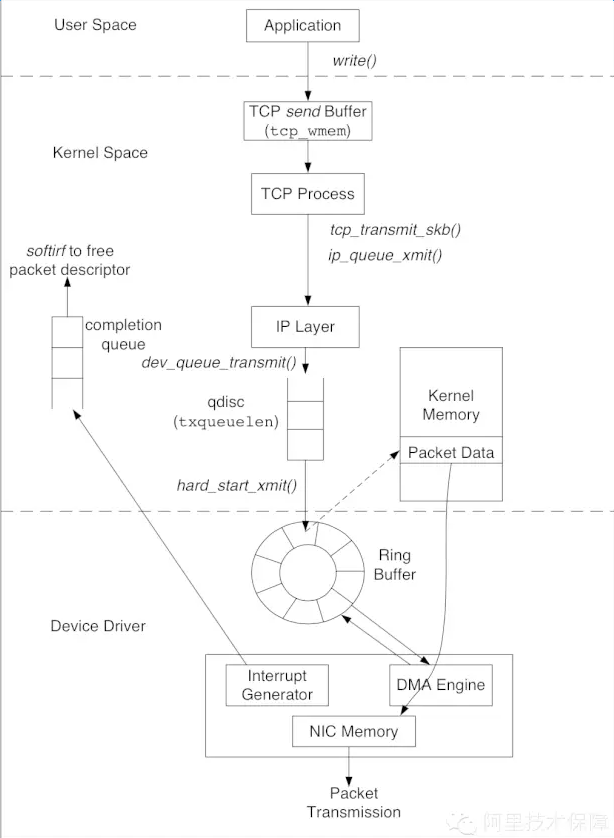
和接收数据的路径相反,数据包的发送从上往下也经过了三层:用户态空间的应用、系统内核空间、最后到网卡驱动。应用先将数据写入TCP sendbuffer,TCP层将sendbuffer中的数据构建成数据包转交给IP层。IP层会将待发送的数据包放入队列QDisc(queueingdiscipline)。数据包成功放入QDisc后,指向数据包的描述符sk_buff被放入RingBuffer输出队列,随后网卡驱动调用DMAengine将数据发送到网络链路上。
同样我们逐层来梳理队列缓冲有关的参数。
sendBuffer
同recvBuffer类似,和sendBuffer有关的参数如下:net.ipv4.tcp_wmem = net.core.wmem_defaultnet.core.wmem_max
发送端缓冲的自动调节机制很早就已经实现,并且是无条件开启,没有参数去设置。如果指定了tcp_wmem,则net.core.wmem_default被tcp_wmem的覆盖。sendBuffer在tcp_wmem的最小值和最大值之间自动调节。如果调用setsockopt()设置了socket选项SO_SNDBUF,将关闭发送端缓冲的自动调节机制,tcp_wmem将被忽略,SO_SNDBUF的最大值由net.core.wmem_max限制。
QDisc
QDisc(queueing discipline )位于IP层和网卡的ringbuffer之间。我们已经知道,ringbuffer是一个简单的FIFO队列,这种设计使网卡的驱动层保持简单和快速。而QDisc实现了流量管理的高级功能,包括流量分类,优先级和流量整形(rate-shaping)。可以使用tc命令配置QDisc。
QDisc的队列长度由txqueuelen设置,和接收数据包的队列长度由内核参数net.core.netdev_max_backlog控制所不同,txqueuelen是和网卡关联,可以用ifconfig命令查看当前的大小:
使用ifconfig调整txqueuelen的大小:
ifconfig eth0 txqueuelen 2000
RingBuffer
和数据包的接收一样,发送数据包也要经过RingBuffer,使用ethtool-g eth0查看: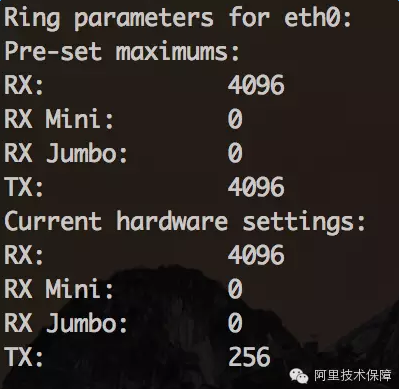
其中TX项是RingBuffer的传输队列,也就是发送队列的长度。设置也是使用命令ethtool-G。
TCPSegmentation和Checksum Offloading
操作系统可以把一些TCP/IP的功能转交给网卡去完成,特别是Segmentation(分片)和checksum的计算,这样可以节省CPU资源,并且由硬件代替OS执行这些操作会带来性能的提升。
一般以太网的MTU(MaximumTransmission Unit)为1500 bytes,假设应用要发送数据包的大小为7300bytes,MTU1500字节- IP头部20字节 -TCP头部20字节=有效负载为1460字节,因此7300字节需要拆分成5个segment: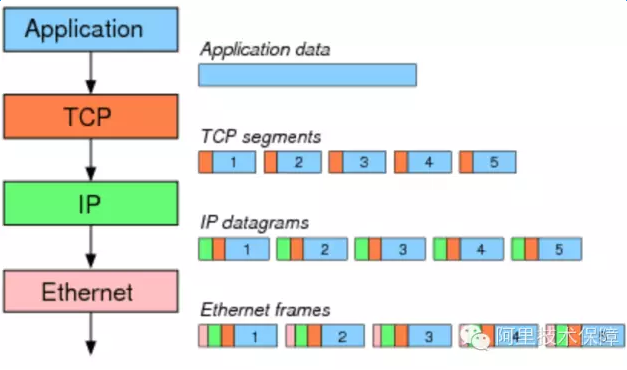
Segmentation(分片)操作可以由操作系统移交给网卡完成,虽然最终线路上仍然是传输5个包,但这样节省了CPU资源并带来性能的提升:
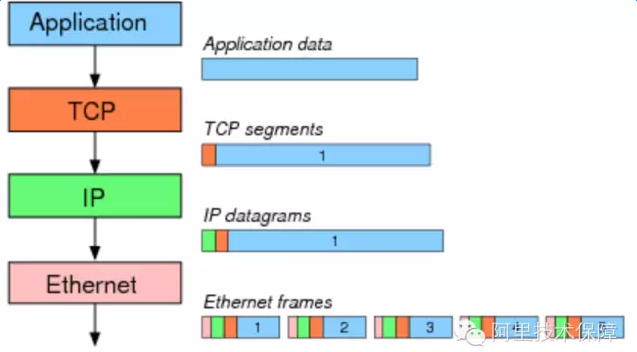
可以使用ethtool-k eth0查看网卡当前的offloading情况:
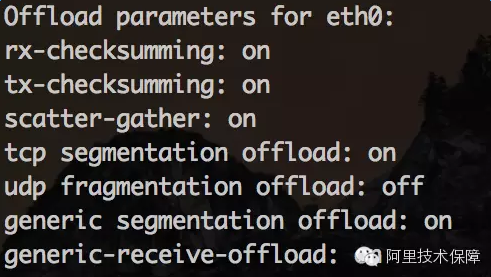
上面这个例子checksum和tcpsegmentation的offloading都是打开的。如果想设置网卡的offloading开关,可以使用ethtool-K(注意K是大写)命令,例如下面的命令关闭了tcp segmentation offload:
sudo ethtool -K eth0 tso off
网卡多队列和网卡Bonding模式
在数据包的接收过程中已经介绍过了。
至此,终于梳理完毕。整理TCP队列相关参数的起因是最近在排查一个网络超时问题,原因还没有找到,产生的“副作用”就是这篇文档。再想深入解决这个问题可能需要做TCP协议代码的profile,需要继续学习,希望不久的将来就可以再写文档和大家分享了。
参考文档
Queueing in the Linux Network Stack
TCP Implementation in Linux: A Brief Tutorial
Impact of Bandwidth Delay Product on TCP Throughput
Java程序员也应该知道的系统知识系列之网卡
说说网卡中断处理
Linux TCP队列相关参数的总结相关推荐
- linux 内核调整相关参数
linux 内核调整相关参数 net.ipv4.tcp_syncookies = 1 表示开启SYN Cookies.当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN***,默认 ...
- vm跑linux性能,linux的vm相关参数介绍
linux的vm相关参数介绍 1. 保证linux有足够的物理内存,可以调整vm的如下参数 vm.min_free_kbytes=409600;//默认值是3797,保证物理内存有足够空闲空间,防止突 ...
- linux的vm相关参数介绍
http://blog.csdn.net/wyzxg/article/details/5661489 linux的vm相关参数介绍 1. 保证linux有足够的物理内存,可以调整vm的如下参数 vm ...
- linux消息队列的内核限制
[from:http://blog.csdn.net/cwj649956781/article/details/8804908] 消息队列: 1.每次msgrcv一个消息,1.那个消息会在内核中移除 ...
- linux tcp文件分包_Linux内核参数优化
前言: 1:介绍下linux内核的整个知识体系,(学会它,你肯定对linux内核有不一样的理解.) 2:谈谈Linux内核参数优化 一:linux内核技术点 Linux内核知识体系分为五个部分 1:l ...
- Linux kernel内存管理之OOM相关参数
一.OOM概念 OOM是Out Of Memory(内存溢出)的缩写,虽然linux kernel的内存管理有很多机制(从cache中回收.swap out等)可以满足用户空间的各种虚拟内存需求,但是 ...
- 关于linux内存管理相关的内核参数
最近闲来无事,就打算整理一下linux内存管理相关的内核参数,以便以后查阅使用.在整理的过程中除了参考内核文档Document/sysctl/vm.txt之外,更多的是参考网上的各位大神写的资料,大部 ...
- Linux内核参数(如kernel.shmmax)及Oracle相关参数调整(如SGA_MAX_SIZE)
Linux内核参数(如kernel.shmmax)及Oracle相关参数调整(如SGA_MAX_SIZE) 我们一般在Linux 上安装 设置Oracle 数据库 或者在更换或升级硬件的时候都需要配置 ...
- Linux 内核参数及Oracle相关参数调整
我们一般在Linux 上安装设置Oracle 数据库或者在更换或升级硬件的时候都需要 配置Linux 系统的核心参数, 然后才是调整Oracle 系统参数 .具体这些参数的实质意 义是什么,为什么要做 ...
最新文章
- LeetCode简单题之增量元素之间的最大差值
- 来自星星的你,我要代表月亮消灭你一
- matlab学习记录之基本操作整理
- n9009 Android5.0内核,三星N9009(Galaxy Note 3 电信版 Android 5.0)刷Recovery教程
- 陶哲轩实分析命题 11.10.7
- 并发执行变成串行_网易Java研发面试官眼中的Java并发——安全性、活跃性、性能...
- 将编号为0和1的两个栈存放于一个数组空间V[m]中。
- 最新天猫Java面试题(含总结):线程池+并发编程+分布式设计+中间件
- GitHub 有望在中国开设子公司?
- jdbc至sql server的两种常见方法
- C++操作符operator的另一种用法
- 485通信c语言讲解,51单片机485通讯讲解 通俗易懂
- 专业卸载工具Your Uninstaller! Pro
- Nodejs KOA服务搭建打包
- The C++ Frontend
- oracle导出导入同义词,使用datapump 导出导入同义词
- error while loading shared libraries: libaio.so.1: cannot open shared object file: No such file
- 抽奖摇号系统随机性算法介绍
- 用SETFOS模拟Tadf OLED和超荧光OLED
- yum配置文件 重启后还原_电脑里重启后,重启前所有设置都还原到以前了,怎么办啊...