深度强化学习基础(一):RL中的基本概念
目录
强化学习是什么?
强化学习能做什么?
关键概念和术语
概率论
术语
AI如何控制agent
策略学习--学习policy函数
价值学习--学习最优动作价值函数
总结
强化学习是什么?
强化学习(Reinforcement Learning, RL),又称再励学习、评价学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。
强化学习能做什么?
计算机利用强化学习在模拟器中控制机器人。
用于复杂的战略游戏(围棋和Dota)。
关键概念和术语
![]()
强化学习的最主要特征是智能体和环境。环境是智能体生活并与之交互的世界。在交互的每一步,智能体会看到(可能是部分的)对世界状态的观察,然后决定要采取的行动。当智能体对其进行操作时,环境会发生变化,但也可能会自行发生变化。
智能体还感知来自环境的奖励信号,一个告诉它当前世界状态好坏的数字。的目标是最大化其累积奖励,称为回报。
概率论
随机变量:未知的量,值取决于未知的量,值取决于一个随机事件的结果。![]() 概率密度函数:随机变量在某个确定的取值点附近的可能性。
概率密度函数:随机变量在某个确定的取值点附近的可能性。![]() 期望
期望
随机抽样
术语
状态:对世界状态的完整描述。
观察:状态的部分描述,可能会省略信息。
在深度强化学习中,我们几乎总是用实值向量、矩阵或高阶张量来表示状态和观察结果。例如,视觉观察可以由其像素值的 RGB 矩阵表示;机器人的状态可以用它的关节角度和速度来表示。
动作:给定环境中所有有效动作的集合。
![]() 策略
策略 :智能体用来决定采取什么行动的规则。可是确定性的,表示为
:
或者可能是随机的,表示为:
给定状态做出的动作
![]()
上图中,agent的动作是随机的(随机抽样得到的),根据policy函数输出的概率来做动作。
奖励:取决于世界的当前状态,刚刚采取的行动,以及世界的下一个状态。
状态转移:可以是随机的,随机性来自环境(世界)。
![]()
![]()
agent(智慧体)与环境(世界)交互:
![]()
![]()
![]()
强化学习的随机性:
1、动作的随机性。
![]()
![]()
动作是根据policy函数随机抽样得到的,利用policy函数控制agent,给定当前状态s,agent动作a是按照policy函数
输出的概率来随机抽样。
2、状态转移的随机性
![]()
![]()
假定agent做出某一动作,环境就要生成下一个状态,
具有随机性,环境用状态转移函数
算出概率,然后用概率来随机抽样得到下一个状态
。
轨迹:一系列状态和动作,
回报:未来的累计奖励。把t时刻的return记为,
问题:奖励和
一样重要吗?
>
,t时刻的奖励要比t+1时刻的奖励重要,因为未来具有不确定性。即
的权重比
的权重小。
折扣回报:
折扣率:0到1之间,折扣率为超参数,需要自己调,折扣率对强化学习的效果有一定的影响。
回报的随机性:
假如游戏结束,所有的奖励都观测到了,均为数值,用r表示,若t时刻还没结束,奖励为随机变量没有观测到,用R表示,由于依赖于R,所以
为随机变量。
随机性的两个来源:
1、动作随机。
![]()
policy函数用s作为输入,输出一个概率分布,动作a从概率分布中随机抽样得到。
2、下一个状态的随机。
![]()
给定当前动作a和状态s,下一个状态是随机的,状态转移函数
输出个概率分布,环境从概率分布中随机抽样得到新的状态
。
对于任意,奖励
取决于
和
。
给定,return
的依赖于未来所有的动作
和状态
。
动作价值函数:
![]()
由于为随机变量,为了评估当前形势,可以对
求期望,将里面的随机性利用积分积掉得到的为实数。
例如:抛硬币之前不知道结果,假设正面计1,反面计0,已知两种结果概率为0.5,则期望为1*0.5+0*0.5=0.5。
期望如何求,把当做未来所有的动作
和状态
的函数,未来的动作A和状态S都有随机性,动作A的概率密度函数是policy函数
,状态S的概率密度函数是状态转移函数
,除了
,
,其余动作和状态都被积掉了。
动作价值函数直观意义:用policy函数
在状态
下做动作
是好还是坏。给动作打分。
不同的policy函数就会有不同的
,即不同策略,价值不同。
最优动作价值函数:
![]()
取使最大化的
,此时最优动作价值函数
与policy函数
无关。
直观意义:对动作a做评价。例如:下围棋时,将棋子放在某个位置的胜算有多大。
状态价值函数:
![]()
状态价值函数是动作价值函数
的期望,把动作A作为随机变量,
,A的概率密度函数为
,关于A求期望把A消掉,此时
只跟
和
有关。
直观意义:可以告诉我们当前局势好不好。
AI如何控制agent
策略学习--学习policy函数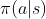
![]()
利用policy函数控制agent做动作,每观测一个状态
,就把
作为
函数的输入,
函数会输出每一个动作的概率,用这些概率做随机抽样得到
,agent执行动作
。
价值学习--学习最优动作价值函数 
![]()
agent可以根据函数来做动作,
函数告诉我们,当状态处在
,那么做动作是好还是坏,每观测到一个
,将
作为
函数的输入,让
函数对每一个动作都做一个评价,这样就知道每一个动作的Q值,选Q值最大(因为Q值是对未来奖励和的期望)的动作作为
。
总结
强化学习的目的就是学习policy函数和最优动作价值函数
深度强化学习基础(一):RL中的基本概念相关推荐
- 深度强化学习基础知识 思维导图
学习了王树森老师的深度强化学习入门课件,将各个算法整理在如下思维导图中. 深度强化学习基础知识 思维导图
- 电子网络发票应用系统网络不通_深度强化学习在典型网络系统中的应用综述
作 者:郑莹,段庆洋,林利祥,游新宇,徐跃东,王新 摘 要:近几年来,以深度强化学习(Deep Reinforcement Learning,DRL)为代表的人工智能技术被引入计算机网络系统设计中 ...
- 深度强化学习在时序数据压缩中的应用--ICDE 2020收录论文
彼节者有间,而刀刃者无厚:以无厚入有间,恢恢乎其于游刃必有余地矣 ----- 庖丁解牛 前言:随着移动互联网.IoT.5G等的应用和普及,一步一步地我们走进了数字经济时代.随之而来的海量数据将是一种客 ...
- 【从RL到DRL】深度强化学习基础(四)——策略梯度中的Baseline,Reinforce与A2C的对比
目录 带有Baseline的策略梯度 数学推导 蒙特卡洛近似(With Baseline) Reinforce With Baseline 使用Reinforce算法训练: Advantage Act ...
- 【从RL到DRL】深度强化学习基础(五)离散控制与连续控制——确定策略梯度方法(DPG)、使用随机策略进行连续控制
目录 确定策略梯度(Deterministic Policy Gradient,DPG) 改进:使用Target Network 随机策略与确定策略网络对比 使用随机策略进行连续控制 策略网络搭建 策 ...
- 【ICML2021】 9篇RL论文作者汪昭然:构建“元宇宙”和理论基础,让深度强化学习从虚拟走进现实...
深度强化学习实验室 官网:http://www.neurondance.com/ 论坛:http://deeprl.neurondance.com/ 来源:转载自AI科技评论 作者 | 陈彩娴 深度强 ...
- 深度强化学习中带有阴影的曲线是怎么画的?
记录学习一下: 1.强化学习论文里的训练曲线是用什么画的?如何计算相关变量 - 深度强化学习实验室 2. 论文中画带标准差阴影的曲线图:seaborn.lineplot()_条件反射104的博客-CS ...
- 《强化学习周刊》第33期:UdeM | 基于不确定性估计的样本高效深度强化学习
No.33 智源社区 强化学习组 强 化 学 习 研究 观点 资源 活动 关于周刊 强化学习作为人工智能领域研究热点之一,其研究进展与成果也引发了众多关注.为帮助研究与工程人员了解该领域的相关进展和 ...
- 深度强化学习的现在,将来与未来
1 前言 从2013年Deepmind提出DQN开始,深度强化学习(Deep Reinforcement Learning)作为一种面向决策控制的革命性技术,已经发展了8年之久,在这8年中,涌现了Al ...
最新文章
- GT Transceiver中的重要时钟及其关系(5)QPLL的工作原理介绍
- github密码格式_如何使用GitHub构建一个简单的网页 (不用框架版本)
- addcslashes php 有什么用处,PHP addcslashes函数有什么用
- Mysql Packet for query is too large解决方法
- java c# 线程,DART隔离和线程(Java,C#)之间的区别
- 微软已停止对Vista RTM(SP0)的服务支持
- jq和thinkphp经常使用的几种ajax
- 25个常用Matplotlib图的Python代码,爱了爱了
- 华为鸿蒙系统英语报纸_“鸿蒙”系统的英文名叫这个!华为注册的这些名字都该怎么翻译?...
- Altium Designer PCB常用规则中英文对照
- 新手自己搭建、开发网络直播平台历程——了解实现一个简单直播平台的结构
- 新一代三维GIS技术资料集锦
- 【SpringBoot】Bean 注入失败问题汇总
- sap 流程图 退货销售订单_销售订单_退货型
- 案例分享:Qt + 树莓派3B+ 智能笔筒系统
- vscode翻译插件最佳搭配、翻译变量、划词翻译、中译英(提高生产效率)
- mysql 计算近30天总金额_计算月嫂每天工资,应该用总工资除以30天还是26天?-免费法律咨询...
- Matlab解方程, 等到数字解和解析式解
- Kernel: printk: pr_debug:动态日志打印功能
- thread dump分析