新浪微博搜索结果数据抓取
这篇文章抓取使用的是jsoup,要求简单的情况下比起httpclient确实方便的多。有启示性但对我的需求来说不太适用,比如没有登陆。
项目需要在抓取新浪微博搜索结果数据,顺手做了个工具,以实现在新浪微博搜索中自动抓取配置的关键字的搜索结果。在此分享一下。
先看一下新浪微博搜索结果页面的源码:
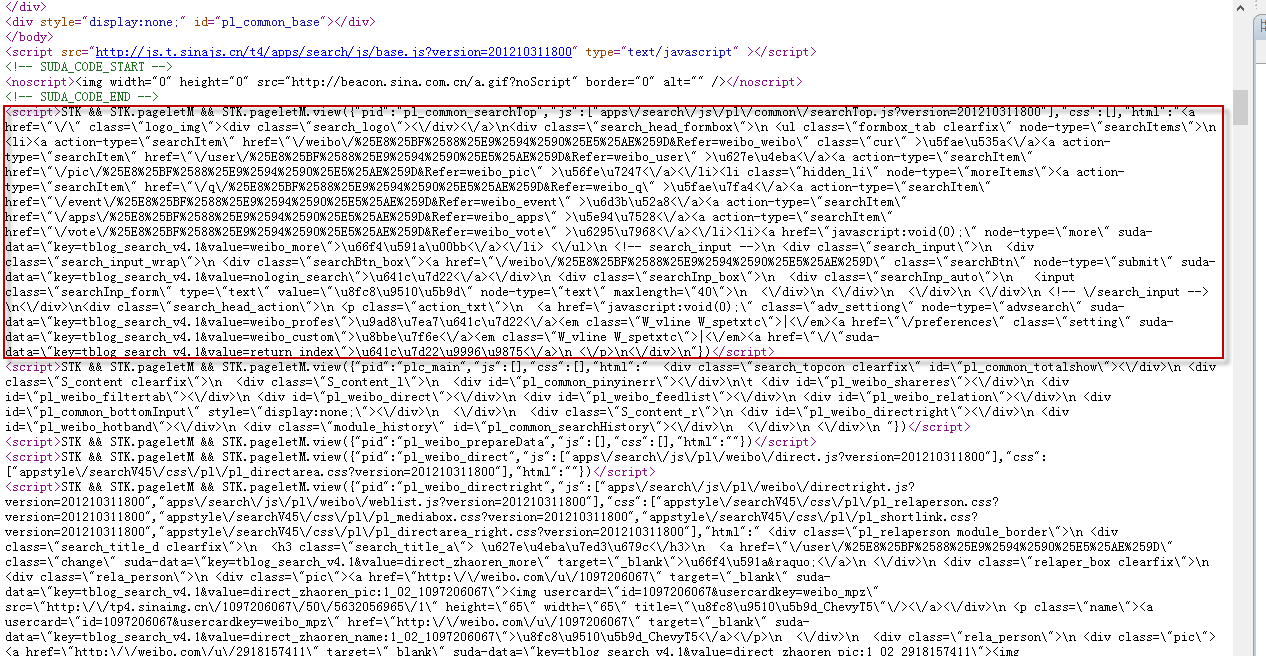
可以看到,得到的并不是普通html,都是通过js调用的。其中汉字全部是经过编码的。文本元素全部都是上图红框中的格式,要得到搜索结果就需要对红框中的文本进行解析。其中用到了jsoup 和 fastjson jar包,需要自行下载。
jsoup: http://jsoup.org/download
fastjson:http://sourceforge.net/projects/fastjson
搜索结果抓取核心类:
- import java.io.IOException;
- import java.text.ParseException;
- import java.util.ArrayList;
- import java.util.Date;
- import java.util.List;
- import java.util.regex.Matcher;
- import java.util.regex.Pattern;
- import org.apache.solr.common.SolrInputDocument;
- import org.jsoup.Jsoup;
- import org.jsoup.nodes.Document;
- import org.jsoup.nodes.Element;
- import org.jsoup.safety.Whitelist;
- import org.jsoup.select.Elements;
- import com.alibaba.fastjson.JSON;
- public class WeiboFetcher extends AbstractFetcher {
- // 文本块正文匹配正则
- private final String blockRegex = "<script>STK\\s&&\\sSTK\\.pageletM\\s&&\\sSTK\\.pageletM\\.view\\(.*\\)";
- private Pattern pattern = Pattern.compile(blockRegex);
- private static Whitelist whitelist = new Whitelist();
- static{
- // 只保留em标签的文本
- whitelist.addTags("em");
- }
- @Override()
- public List<SolrInputDocument> fetch() {
- List<SolrInputDocument> newsResults = new ArrayList<SolrInputDocument>();
- newsResults = WeiboResult();
- System.out.println("WeiboFetcher Over: " + newsResults.size());
- return newsResults;
- }
- /**
- * 获取关键字搜索结果
- * @return
- */
- private List<SolrInputDocument> WeiboResult() {
- String keyWord = null;
- List<SolrInputDocument> newsResultList = new ArrayList<SolrInputDocument>();
- // 获取配置的关键字
- List<String> keyWordList = KeywordReader.getInstance().getKeywords();
- for (String keyWordLine : keyWordList) {
- // 转换为新浪微博搜索接受的格式
- keyWord = policy.getKeyWord(keyWordLine,null);
- newsResultList.addAll(getWeiboContent(keyWord));
- }
- return newsResultList;
- }
- /**
- * 获取搜索结果
- * @param keyWord
- * @return
- */
- private List<SolrInputDocument> getWeiboContent(String keyWord){
- System.out.println("fetch keyword: " + keyWord);
- List<SolrInputDocument> resultList = new ArrayList<SolrInputDocument>();
- for(int i = 0; i < depth; i++){
- String page = "";
- if(i > 0){
- page = "&page=" + (i+1);
- }
- //抓取返回50个内容
- try {
- System.out.println("fetch url page depth " + (i + 1));
- // 注意&nodup=1
- Document doc = Jsoup.connect(
- "http://s.weibo.com/weibo/" + keyWord+"&nodup=1" + page).get();
- String source = doc.html();
- // 匹配文本块
- Matcher m = pattern.matcher(source);
- while(m.find()){
- String jsonStr = m.group();
- jsonStr = jsonStr.substring(jsonStr.indexOf("{"), jsonStr.lastIndexOf(")"));
- // 解析json,转换为实体类
- WeiboBlock block = JSON.parseObject(jsonStr, WeiboBlock.class);
- if(block.getHtml().trim().startsWith("<div class=\"search_feed\">")){
- doc = Jsoup.parse(block.getHtml());
- }
- }
- List<Element> elements = getAllElement(doc);
- if(elements == null || elements.size() == 0){
- System.out.println("No more urls to fetch with current keyword." );
- return resultList;
- }
- for (Element elem : elements) {
- String url = elem.select(".date").last().attr("href");
- String dateS = elem.select(".date").last().attr("date");
- String content = null;
- Date date = null;
- String content_text = null;
- String title = null;
- if (!isCrawledUrl(url)){
- if (url != null) {
- if (dateS != null && !"".equals(dateS)) {
- try {
- date = sdf.parse(changeString2Date(dateS));
- } catch (ParseException e) {
- e.printStackTrace();
- }
- }
- if (date != null) {
- elem.getElementsByClass("info W_linkb W_textb").remove();
- content = Jsoup.clean(Jsoup.clean(elem.select(".content").html(), whitelist), Whitelist.none());
- title = this.parseTitle(content);
- url = elem.select(".date").last().attr("href");
- SolrInputDocument sid = buildSolrInputDocumentList(url, content, title, date);
- if (sid != null && sid.size() > 0) {
- resultList.add(sid);
- }
- }
- }else {
- System.out.println("current Url: ---------null------------" );
- }
- }
- }
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- return resultList;
- }
- /**
- * 获取所有的结果正文节点
- * @param doc
- * @return
- */
- private List<Element> getAllElement(Document doc) {
- List<Element> resultList = new ArrayList<Element>();
- Elements elems = doc.select(".search_feed .feed_list");
- for (Element element : elems) {
- resultList.add(element);
- }
- return resultList;
- }
- @Override
- protected boolean isCrawledUrl(String url) {
- return isAvaliableUrl(url);
- }
- /**
- * 生成标题
- * @param htmlContent
- * @return
- */
- private String parseTitle(String htmlContent) {
- if (htmlContent == null || htmlContent.trim().equals(""))
- return null;
- String title = htmlContent;
- title = title.trim();
- for (int i = 0; i < title.length(); i++) {
- if (String.valueOf((title.charAt(i))).matches("[,.\\?\\!\\.,]")) {
- title = title.substring(0, i);
- break;
- }
- }
- return title;
- }
- }
结果实体类:
- public class WeiboBlock{
- private String pid;
- private String js;
- private String css;
- private String html;
- public WeiboBlock(){}
- public String getPid() {
- return pid;
- }
- public void setPid(String pid) {
- this.pid = pid;
- }
- public String getJs() {
- return js;
- }
- public void setJs(String js) {
- this.js = js;
- }
- public String getCss() {
- return css;
- }
- public void setCss(String css) {
- this.css = css;
- }
- public String getHtml() {
- return html;
- }
- public void setHtml(String html) {
- this.html = html;
- }
- }
关键字生成策略类:
- public class SinaKeyWordsPolicy implements KeyWordsPolicy {
- @Override
- public String getKeyWord(String keyWordLine, String siteLine) {
- String keyWord = null;
- keyWordLine = keyWordLine.replaceAll("\"", "");
- keyWordLine = keyWordLine.replaceAll("AND", " ");
- keyWordLine = keyWordLine.replaceAll("OR", "|");
- if (keyWordLine.contains("|")) {
- String[] tempStrings = keyWordLine.split("|");
- if (tempStrings.length > 3) {
- for (int i=0; i<3 ;i++) {
- keyWord += tempStrings[i];
- keyWord += "|";
- }
- }else {
- keyWord = keyWordLine;
- }
- }else {
- keyWord = keyWordLine;
- }
- return java.net.URLEncoder.encode(java.net.URLEncoder.encode(keyWord));
- }
- }
关键字配置文件使用文本文件即可,每行一组关键字,格式类似如下:
"key1"
"key1"AND"key2"
"key1"AND("key2"OR"key3")
附:项目源码已经整理并上传GitHub, 访问地址:https://github.com/Siriuser/WeiboCrawler
需要源码的话请自行下载。
本文出自 “果壳中的宇宙” 博客,请务必保留此出处http://williamx.blog.51cto.com/3629295/1047832
新浪微博搜索结果数据抓取相关推荐
- php天猫列表数据抓取,如何翻页抓取网页数据——以采集天猫搜索列表为例
我们在抓取数据时,通常不会只抓取网页当前页面的数据,往往都会继续抓取翻页后的数据.本文就为大家介绍,集搜客GooSeeker网络爬虫如何在进行数据抓取时,自动抓取翻页后的数据. 在MS谋数台的爬虫路线 ...
- 关于Python爬虫原理和数据抓取1.1
为什么要做爬虫? 首先请问:都说现在是"大数据时代",那数据从何而来? 企业产生的用户数据:百度指数.阿里指数.TBI腾讯浏览指数.新浪微博指数 数据平台购买数据:数据堂.国云数据 ...
- Python学习笔记——爬虫原理与Requests数据抓取
目录 为什么要做网络爬虫? 通用爬虫和聚焦爬虫 HTTP和HTTPS 客户端HTTP请求 请求方法 HTTP请求主要分为Get和Post两种方法 常用的请求报头 1. Host (主机和端口号) 2. ...
- python爬虫百度百科-python爬虫(一)_爬虫原理和数据抓取
本篇将开始介绍Python原理,更多内容请参考:Python学习指南 为什么要做爬虫 著名的革命家.思想家.政治家.战略家.社会改革的主要领导人物马云曾经在2015年提到由IT转到DT,何谓DT,DT ...
- python教程怎么抓起数据_介绍python 数据抓取三种方法
三种数据抓取的方法正则表达式(re库) BeautifulSoup(bs4) lxml *利用之前构建的下载网页函数,获取目标网页的html,我们以https://guojiadiqu.bmcx.co ...
- Uipath 学习栏目基础教学:10、数据抓取
提示:专栏解锁后,可以查看该专栏所有文章. 文章目录 一.数据抓取 1.1表格数据抓取 1.2 搜索结果爬取 提示:以下是本篇文章正文内容,下面案例可供参考 一.数据抓取 UiPath Studio ...
- b站视频详情数据抓取,自动打包并发送到指定邮箱(单个或者群发)
BiLiBiLi Time: 2020年11月6日19:44:58 Author: Yblackd BiLiBiLi BiLiBiLi 介绍 软件架构 安装教程 使用说明 源码下载 BiLiBiLi ...
- Ajax异步数据抓取
1.简介 1 有时候我们在用requests抓取页面的时候,得到的结果可能和在浏览器中看到的不一样,在浏览 2 器中可以看到正常显示的页面数据,但是使用requests得到的结果并没有.这是因为req ...
- 李沐【实用机器学习】1.3网页数据抓取
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言 一.数据抓取工具 二.实例解析 总结 前言 网页数据抓取目标:在一个网站里面感兴趣的数据抓取出来 数据特点:噪点较多, ...
最新文章
- Android 设置透明的方法
- C语言实现简易通讯录
- 【渝粤教育】国家开放大学2018年秋季 1021t劳动与社会保障法 参考试题
- (转)nmake学习笔记
- 无心剑随感《最完美的图形——圆》
- php发送http put/patch/delete请求
- GDAL插值使用示例
- 没有的功能,直接回答并不好
- unity数组或链表需要空间很大赋值与调用
- vm虚拟机获取ip地址
- 东大oj1155 等凹函数
- Qt Design Studio安装教程
- 联通4G业务或沿用沃品牌 不推无限量套餐
- 操作系统第五章 设备管理(上)笔记
- python 表格查询,Python实现数据表查找
- Oracle中Blob和Clob类型的区别
- 122.买卖股票的最佳时机 II
- js根据日期时间区间获取季度Q1-Q4列表
- pycharm切换文件夹_Pycharm中一些不为人知的技巧
- 全国计算机应用基础统考成绩查询,网络教育统考成绩查询的方法有哪些