RHadoop搭建(HDFS+MapReduce)
*********************************************************************************
hadoop集群(virtualBox虚拟机,CentOS6.4)
hadoop1 192.168.100.171(hadoop master、secondaryname、zookeeper、hbase HMaster)
hadoop2 192.168.100.172(zookeeper、hbase HRegion、Hive Shell)
hadoop3 192.168.100.173(hadoop slave、zookeeper、hbase HRegion)
hadoop4 192.168.100.174(hadoop slave、zookeeper、hbase HRegion)
hadoop5 192.168.100.175(hadoop slave、zookeeper、hbase HRegion)
dataserver 192.168.100.141(Hive metastore、MySQL Server、Oracle)
安装文档: hadoop2.2.0测试环境搭建
*********************************************************************************
本次测试在dataserver进行
1:下载RHadoop相关软件包,放置在/mnt/mydisk/R/目录下
http://www.r-project.org/
R语言包
https://github.com/RevolutionAnalytics/RHadoop/wiki/Downloads
rhdfs R使用HDFS相关软件包
rmr R使用MapReduce相关软件包
rhbase R使用Hbase相关软件包

2:安装R语言
[root@dataserver app]# tar zxf /mnt/mydisk/soft/R/R-3.0.2.tar.gz
[root@dataserver app]# cd R-3.0.2
[root@dataserver R-3.0.2]# yum install readline-devel
[root@dataserver R-3.0.2]# yum install libXt-devel
[root@dataserver R-3.0.2]# ./configure --enable-R-shlib
[root@dataserver R-3.0.2]# make
[root@dataserver R-3.0.2]# make install
其中readline-devel、libXt-devel在编译R的时候需要,而--enable-R-shlib是安装R的共享库,在安装Rstudio需要。
3:确认Java环境变量
RHadoop依赖于rJava包,安装rJava前确认已经配置了Java环境变量,然后进行R对jvm建立连接。
[root@dataserver R-3.0.2]# cat /etc/profile
export JAVA_HOME=/usr/lib/jdk1.7.0_21
export JRE_HOME=/usr/lib/jdk1.7.0_21/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib/tools.jar
export PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin:$PATH
[root@dataserver R-3.0.2]# R CMD javareconf
4:安装相关的依赖包,确保RHadoop软件包能正常使用
[root@dataserver R-3.0.2]# R
> install.packages("rJava")
> install.packages("reshape2")
> install.packages("Rcpp")
> install.packages("iterators")
> install.packages("itertools")
> install.packages("digest")
> install.packages("RJSONIO")
> install.packages("functional")
> install.packages("bitops")
> quit()
5:安装RHadoop软件包
[root@dataserver R-3.0.2]# export HADOOP_CMD=/app/hadoop/hadoop220/bin/hadoop
[root@dataserver R-3.0.2]# export HADOOP_STREAMING=/app/hadoop/hadoop220/share/hadoop/tools/lib/hadoop-streaming-2.2.0.jar
[root@dataserver R-3.0.2]# R CMD INSTALL /mnt/mydisk/soft/R/rhdfs_1.0.8.tar.gz
[root@dataserver R-3.0.2]# R CMD INSTALL /mnt/mydisk/soft/R/rmr2_2.3.0.tar.gz
**************************************************************************************************
export HADOOP_CMD=/app/hadoop/hadoop220/bin/hadoop
export HADOOP_STREAMING=/app/hadoop/hadoop220/share/hadoop/tools/lib/hadoop-streaming-2.2.0.jar
加入/etc/profile或用户的.bashrc中
**************************************************************************************************
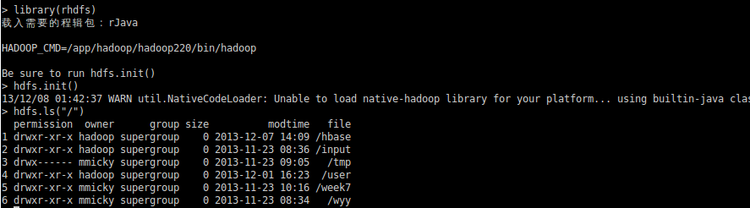
6:使用RHadoop软件包
[root@dataserver R-3.0.2]# R
> library(rhdfs)
> hdfs.init()
> hdfs.ls("/")
7:安装Rstudio
[root@dataserver R-3.0.2]# cd ..
[root@dataserver app]# rm -rf R-3.0.2
[root@dataserver app]# tar -zxf /mnt/mydisk/soft/R/rstudio-0.98.484-x86_64-fedora.tar.gz
8:TIPS
A:R相关的软件包安装在/usr/local/lib64/R/library下,可以在该目录下查看是否已经安装了相应的软件包。
B:如果安装的时候不是用root身份安装,则R安装的软件包会在用户目录上,其他用户将使用不了软件包。
C:如果使用的hadoop集群是hadoop1.2.0,则配置参数为:
export HADOOP_CMD=/app/hadoop/hadoop120/bin/hadoop
export HADOOP_STREAMING=/app/hadoop/hadoop120/contrib/streaming/hadoop-streaming-1.2.0.jar
D:在安装rhbase软件需要安装thrift,在后面章节介绍。
转载于:https://my.oschina.net/victorlovecode/blog/344215
RHadoop搭建(HDFS+MapReduce)相关推荐
- Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
编者按:HDFS和MapReduce是Hadoop的两大核心,除此之外Hbase.Hive这两个核心工具也随着Hadoop发展变得越来越重要.本文作者张震的博文<Thinking in BigD ...
- linux搭建hdfs
搭建hdfs分布式集群 1.设置静态IP 设置静态IP https://blog.csdn.net/weixin_42119153/article/details/100124300#commentB ...
- 基于hadoop的电商销售预测分析系统HDFS+MapReduce+springboot或springcloud+Echarts
基于hadoop的电商销售预测分析系统 使用分布式文件存储系统HDFS+mapreduce+springboot和springcloud+Echarts实现的简单的电商销售数据预测分析系统. 主要通过 ...
- Thinking in BigData(八)大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
纯干货:Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解. 通过这一阶段的调研总结,从内部机理的角度详细分析,HDFS.MapReduce.Hbase.H ...
- Hadoop(HDFS+MapReduce+Hive+数仓基础概念)学习笔记(自用)
文章目录 修改虚拟机IP 复制网卡的配置 Vi编辑器的常用命令 实操部分 复制网卡的配置 Hadoop集群初体验 20.secondarynameNode如何辅助管理FSImage与Edits文件 ⭐ ...
- 分布式大数据系统概览(HDFS/MapReduce/Spark/Yarn/Zookeeper/Storm/SparkStreaming/Lambda/DataFlow/Flink/Giraph)
分布式大数据处理系统概览(三) 本博文主要对现如今分布式大数据处理系统进行概括整理,相关课程为华东师范大学数据科学与工程学院<大数据处理系统>,参考大夏学堂,下面主要整理HDFS/Ma ...
- Hadoop集群搭建及MapReduce应用
一.Hadoop集群的搭建与配置 1.节点准备 集群规划: 主机名 IP 安装的软件 运行的进程 weekend 01 192.168.1.60 jdk.hadoop NameNode.DFSZKFa ...
- 大数据之hadoop伪集群搭建与MapReduce编程入门
一.理论知识预热 一句话介绍hadoop: Hadoop的核心由分布式文件系统HDFS与Map/Reduce计算模型组成. (1)HDFS分布式文件系统 HDFS由三个角色构成: 1)NameNode ...
- 学习笔记Hadoop(十三)—— MapReduce开发入门(1)—— MapReduce开发环境搭建、MapReduce单词计数源码分析
一.MapReduce MapReduce是Google提出的一个软件架构,用于大规模数据集(大于1TB)的并行运算.概念"Map(映射)"和"Reduce(归纳)&qu ...
- 【Hadoop】在Linux中的Hadoop部署与yarn HDFS MapReduce 的配置中常见的问题?你解决了吗?
(1) 浏览器问题 当你配置都完成了,你输入主机名+端口号去访问时,不能访问,但是你得确定前面的配置的哪些步骤都没有错,这可能是你浏览器的问题,我推荐用Chrome或者火狐,这两个基本上是可以的 ...
最新文章
- C/C++头文件一览
- plsql 无法解析指定的连接标识符_Java方法加载、解析、存储、调用
- GitHub项目协作基本步骤
- 理论基础 —— 队列 —— 链队列
- node.js request get 请求怎么拿到返回的数据_从零开始用nodejs写一个简单的静态服务器
- JMM和synchronized
- UI使用素材模板|login登录界面
- Jquery跨域调用(JSONP)遇到error问题的解决
- PR 审批界面增加显示项方法
- 进程/线程间通信和同步
- SM3算法的编程实现
- Layout inflation的正确使用
- Ipython安装错误集锦
- IIS配置ipa下载设置
- 银行钱数(带小数位)转大写
- Power BI应用案例:销售帕累托分析(28法则)
- 适合笔记本计算机玩的游戏,十款,笔记本电脑可以畅玩的单机游戏
- 机场航班保障系统总体设计
- 九耶丨阁瑞钛伦特-金融软件开发介绍
- 基于机器视觉的疲劳驾驶检测
热门文章
- 西南科技大学OJ题 图的按录入顺序深度优先搜索1068
- POI 实现Word替换书签
- 天正自定义填充图案怎么添加_cad里怎么增加自定义填充图案
- 乌龟git安装和使用
- 解决方法-SQLserver建表后更改列,显示不允许保存更改。您所做的更改要求删除并重新创建以下表
- JS 实现海康威视摄像头笔记
- 区块链宠物移动端交互原型模板、免费领取、宠物交易、宠物领养、宠物购买、宠物集市、用户中心、注册登录、订单管理、常用元件、通用元件、设计框架、规则说明、功能流程、界面流程、规则模板、Axure原型、rp
- 【Matlab】建立最优控制LQR控制器模型
- 关于COM类工厂80070005和8000401a错误分析及解决办法
- dmx512 java_什么书通过软件层讲解DMX512协议