汤国安mooc实验数据_用漂亮的汤建立自己的数据集
汤国安mooc实验数据
In this world of the Internet, the amount of data that is surrounded by you is like a vast ocean for any field of research or personal interest. To effectively harvest this data, you’ll need to develop the skillset for web scraping. With Web scraping, we can build our own dataset as per our requirements for further analysis. Using this technique only, Amazon’s rating, Netflix review, IMDB ratings, and many other datasets are prepared and analyzed.
在这个互联网世界中,您所包围的数据量就像是一块广阔的海洋,适合任何研究领域或个人兴趣。 为了有效地收集这些数据,您需要开发Web抓取的技能。 使用Web抓取,我们可以根据我们的需求构建自己的数据集,以进行进一步的分析。 仅使用此技术,就可以准备和分析Amazon的评分,Netflix的评论,IMDB评分以及许多其他数据集。
I learned recently Web Scrapping and then suddenly I got an exciting idea if I can apply to scrape the Medium data to find the list of publications and do further analysis of it.
我最近了解了Web Scrapping,然后突然间我有了一个令人振奋的主意,如果我可以申请对Medium数据进行抓取以查找出版物列表并对其进行进一步分析。
Also, there’s a key point to remember here:
另外,这里要记住一个关键点:
The things that we learned from examples or toy implementation is always different for real-time examples.
我们从示例或玩具实现中学到的东西对于实时示例总是不同的。
Let’s start without any delay.
让我们开始吧!
This blog speaks about the code for web scraping multiple pages using Beautiful Soup. The website I have scrapped to build the dataset for this analysis is “https://toppub.xyz/publications”. To implement this code I have used Python libraries requests and Beautiful Soup, which is considered the most powerful tool for this job.
该博客介绍了使用Beautiful Soup在Web上抓取多个页面的代码。 我为构建此分析数据集而废弃的网站是“ https://toppub.xyz/publications ”。 为了实现此代码,我使用了Python库requests和Beautiful Soup,这被认为是这项工作中功能最强大的工具。
Pre-requisites: It is very much needed to understand the HTML tags and different divisions of web-pages. You can easily grasp it with a link https://www.dataquest.io/blog/web-scraping-beautifulsoup/. This is the only most challenging part of web scrapping, as we need to understand someone’s written code and then adapt to our code, as per our expected result.
先决条件:非常需要了解HTML标签和网页的不同划分。 您可以通过链接https://www.dataquest.io/blog/web-scraping-beautifulsoup/轻松地掌握它。 这是Web爬网中最具挑战性的部分,因为我们需要了解某人的书面代码,然后根据我们的预期结果适应我们的代码。
网页抓取: (Web scraping:)
Web scraping is collecting information from the Internet. Even copy-pasting the lyrics of your favorite song is a form of web scraping! However, when we do this process with automation it is called ‘Web Scraping’. Before proceeding, on this, always check that you are not violating any Terms of Service. As some websites don’t like it when automatic scrapers gather their data, while others don’t mind.
Web抓取是从Internet收集信息。 甚至复制粘贴您喜欢的歌曲的歌词也是Web抓取的一种形式! 但是,当我们以自动化方式执行此过程时,则称为“ Web Scraping”。 在进行此操作之前,请务必检查您是否未违反任何服务条款。 由于有些网站不喜欢自动抓取工具收集数据,而其他网站则不介意。
If you’re scraping a page respectfully for educational and research purposes, then you are in a safe zone. Automated web scraping helps to speed up the data collection process. We write our code once and it will get the information as we want many times and from many pages.
如果您出于教育和研究目的而认真刮取页面,那么您处于安全区域。 自动化的网页抓取有助于加快数据收集过程。 我们只编写一次代码,它将根据需要多次从许多页面中获取信息。
要考虑的要点: (Points to consider:)
Every website is different and this is the most important point o consider the variety of each site. While there are some general structures that tend to repeat themselves, but still each website is unique and will need its own personal treatment if you want to extract the information that’s relevant to you.
每个网站都是不同的,这是最重要的一点,请考虑每个网站的多样性。 虽然有一些一般的结构会重复出现,但是每个网站仍然是唯一的,如果您想提取与您相关的信息,则需要对其进行个人处理。
There is always constant development in building websites and so here comes the matter of durability. So it may happen that, initially your code and script worked flawlessly. But when you run the same script only a short while later, you run into a discouraging and lengthy stack of tracebacks. Keep integrating with your code, as per your need and project requirements.
网站建设始终在不断发展,因此,持久性问题就来了。 因此,有可能发生的情况是,最初您的代码和脚本可以完美地工作。 但是当您不久之后运行同一脚本时,就会遇到令人沮丧且冗长的回溯堆栈。 根据您的需求和项目要求,与代码保持集成。
报废: (Scrapping:)
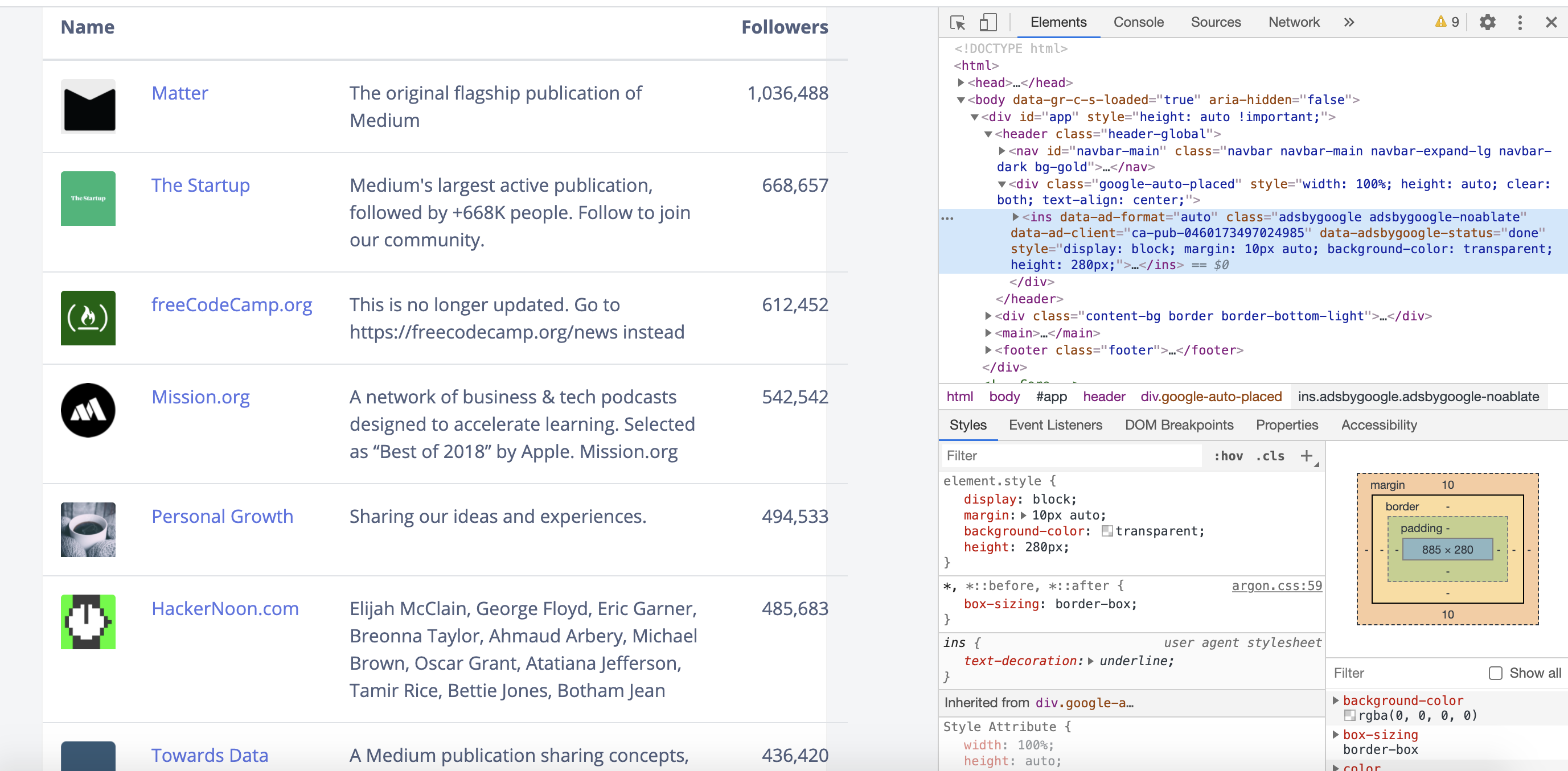
My intention is to build the dataset with Name of Publication, Description, and No.of followers for it. It has a total of 792 pages to scrape. The website looks like this which provided the necessary information as per my expectation:
我的意图是使用发布名称,描述和关注者编号来构建数据集。 它总共有792页要刮。 该网站看起来像这样,它按照我的期望提供了必要的信息:

Next, Step is to Inspect the site and identify the class and tags which we want to scrape.
接下来,步骤是检查站点并确定我们要抓取的类和标签。
My required information is in the form of a table and so the below code gives the required information and store it in the form of CSV file format. GitHub Link.
我所需的信息以表格的形式出现,因此以下代码提供了所需的信息并以CSV文件格式存储。 GitHub链接 。
报废后,分析如下: (After Scrapping, the analysis is as follows:)
1. Medium has a total of 11,865 publishers.
1.中级总共有11,865家出版商。
2. The topmost Publications is Matter, which is own of Medium with 10,36,488 followers then it is followed by Startup with 6,68,651 its followers.
2.最重要的出版物是Matter ,该公司属于Medium,拥有10,36,488位关注者,其次是Startup,拥有6,68,651位关注者。
3. There are 646 publications which are having ≤0 followers.
3.有646个出版物的关注者≤0。
4. There are 45 publications that have more than 100 thousand (1 lakh followers).
4.有45种出版物的发行量超过10万(关注者达10万)。
Enjoy Scraping!!!
享受刮!
翻译自: https://medium.com/swlh/build-your-own-dataset-with-beautiful-soup-583717e3dad7
汤国安mooc实验数据
http://www.taodudu.cc/news/show-1873995.html
相关文章:
- python开发助理s_如何使用Python构建自己的AI个人助理
- 学习遗忘曲线_级联相关,被遗忘的学习架构
- 她玩游戏好都不准我玩游戏了_我们可以玩游戏吗?
- ai人工智能有哪些_进入AI有多么简单
- 深度学习分类pytorch_立即学习AI:02 —使用PyTorch进行分类问题简介
- 机器学习和ai哪个好_AI可以使您成为更好的运动员吗? 使用机器学习分析网球发球和罚球...
- ocr tesseract_OCR引擎之战— Tesseract与Google Vision
- 游戏行业数据类丛书_理论丛书:高维数据101
- tesseract box_使用Qt Box Editor在自定义数据集上训练Tesseract
- 人脸检测用什么模型_人脸检测模型:使用哪个以及为什么使用?
- 不洗袜子的高文博_那个孩子在夏天中旬用高袜子大笑?
- word2vec字向量_Anything2Vec:将Reddit映射到向量空间
- ai人工智能伪原创_AI伪科学与科学种族主义
- ai人工智能操控什么意思_为什么要建立AI分散式自治组织(AI DAO)
- 机器学习cnn如何改变权值_五个机器学习悖论将改变您对数据的思考方式
- DeepStyle(第2部分):时尚GAN
- 肉体之爱的解释圣经_可解释的AI的解释
- 机器学习 神经网络 神经元_神经网络如何学习?
- 人工智能ai应用高管指南_理解人工智能指南
- 机器学习 决策树 监督_监督机器学习-决策树分类器简介
- ai人工智能数据处理分析_建立数据平台以实现分析和AI驱动的创新
- 极限学习机和支持向量机_极限学习机的发展
- 人工智能时代的危机_AI信任危机:如何前进
- 不平衡数据集_我们的不平衡数据集
- 建筑业建筑业大数据行业现状_建筑—第4部分
- 线性分类模型和向量矩阵求导_自然语言处理中向量空间模型的矩阵设计
- 离散数学期末复习概念_复习第1部分中的基本概念
- 熵 机器学习_理解熵:机器学习的金标准
- heroku_如何通过5个步骤在Heroku上部署机器学习UI
- detr 历史解析代码_视觉/ DETR变压器
汤国安mooc实验数据_用漂亮的汤建立自己的数据集相关推荐
- ArcGIS空间分析实验数据(汤国安版)
通过百度网盘分享的文件:汤国安教材数据(- 链接:https://pan.baidu.com/s/1xHsL1k4clF6CZ-38OObzYA?pwd=2022 提取码:2022 复制这段内容打开 ...
- daad转换器实验数据_实验十DAAD转换器教程解析.ppt
一 实验目的 二.实验原理 二.实验原理 二.实验原理 二.实验原理 1.数字电路实验装置KHD-2型 . 六.注意事项 2.为了提高运算精度,首先应对输出直流电位进行调零,即保证在零输入时运放输出为 ...
- 科大奥锐密立根油滴实验数据_密立根油滴实验数据处理分析
第 01 卷第 3期 1 9 9 4 年 9 月 黄 淮 H U A N G H U A I 学 刊 J O U R N A L V o l . 1 0 N o . 3 Se P t . 1 9 9 ...
- 科大奥锐密立根油滴实验数据_(最新)大学物理实验报告系列之密立根油滴实验...
[实验名称] 密立根油滴实验 [ 实验目的 ] 1 .了解密立根油滴实验仪的结构以及利用油滴测定电子电荷的设计思想和方法. 2 .通过对带电油滴在重力场和静电场中运动的测量,验证电荷的不连续性,并测定 ...
- daad转换器实验数据_箔芯片电阻在高温应用A/D转换器中的应用
工业/应用领域 高温:地震数据采集系统.石油勘探监测.高精度检测仪 产品采用:V5X5 Bulk Metal (R) Foil芯片电阻 案例介绍 TX424是一个完整的4通道24位模数转换器,采用40 ...
- daad转换器实验数据_实验十一DAAD转换器.doc
实验十一DAAD转换器 实验十一 D / A.A / D转换器 一.实验目的 1.了解D / A和A / D转换器的基本工作原理和基本结构 2.掌握大规模集成D / A和A / D转换器的功能及其典型 ...
- 科大奥锐密立根油滴实验数据_密立根油滴实验数据表格
静态法(平衡法) ------------------------------------------------------------------------------------------- ...
- 科大奥锐密立根油滴实验数据_大学物理实验--密立根油滴实验报告
实验报告模板 实验题目: 密里根油滴实验 学 号 姓名 实验日期 实 验 目 的 1. 学习密立根油滴实验的设计思想: 2. 通过对带电油滴在重力场和静电场中运动的测量,验证电荷的不连续性,并测定基本 ...
- python获取币安k线数据_如何利用Python 爬取币乎的数据
1LSGO软件技术团队 贡献人:李金原 如果喜欢这里的内容,你能够给我最大的帮助就是转发,告诉你的朋友,鼓励他们一起来学习. If you like the content here, the gre ...
- 科大奥锐密立根油滴实验数据_请问科大奥锐的实验满分都是100吗?
单摆法测量重力加速度 100 钢丝杨氏模量的测定 60 光电效应和普朗克常量的测定 60 迈克耳孙干涉仪 180 密立根油滴实验 100 偏振光的观察与研究 100 声速的测量 100 示波器实验 1 ...
最新文章
- Spring Boot 服务监控,健康检查,线程信息,JVM堆信息,指标收集,运行情况监控...
- Linux(CentOS 7_x64位)系统下安装GaussView5
- php 多图上传编辑器,laravel中使用WangEditor及多图上传
- SimNIBS一款无创脑刺激仿真软件安装
- 文本编辑器中菜单栏删除功能的实现
- 【DP】【BFS】迷之阶梯
- matlab飞行数据仿真,基于MATLAB的飞行仿真
- vs2013和vs2010的配置
- Java游戏有易筋经_易筋经- JavaWeb-1
- TensorFlow多层感知机实现MINIST分类
- 米思齐 Mixly 解决函数模块无法上下连接。
- 对象存储(OSD)及架构原理
- QT5.11编译出现undefined reference to `_imp___ZN12QApplicationC1ERiPPci’
- mysql 历史数据迁移,MySQL 历史数据表迁移方法
- LeetCode 491 递增子序列
- 【论文笔记之 FDAF and MAF】Frequency-Domain and Multirate Adaptive filtering
- httpclient的两个重要的参数maxPerRoute及MaxTotal
- 一篇文章解读提速、降费黑科技:PCDN定义、功能、架构、场景和优势
- thinkphp图片拖动验证码
- 食品领域排名靠前的品牌咨询公司塔望/华与华等服务优势对比
热门文章
- 互联网带来的颠覆,改变了传统的营销套路
- C#.NET的Linq查询、lambda、委托:Func和Action
- 西门子STEP7 MICROWIN V4 SP5 下载
- Rad Software Regular Expression Designer 正则表达式工具软件
- 第六章 梯度下降法 学习笔记 上
- 《图解算法》学习之算法复杂度、运行时间
- Atitit 微服务的一些理论 目录 1. 微服务的4个设计原则和19个解决方案 1 2. 微服务应用4个设计原则 1 2.1. AKF拆分原则 2 2.2. 前后端分离 2 2.3. 无状态服务
- Atitit Persistence API持久性标准化法总结 目录 1. 持久性对于大多数企业应用程序都非常要害 1 2. 持久化api内容 2 2.1. 一种声明式地执行O-R映射的方式。 2
- Atitit 防止迟到与防止打卡打不上解决方案 attilax总结
- Atitit 提升用户体验 生物识别 与登录 身份验证