DC学院爬虫学习笔记(六):浏览器抓包及headers设置
爬虫的一般思路:
- 抓取网页、分析请求
- 解析网页、寻找数据
- 储存数据、多页处理 -
分析具体网页请求:
1. 观察以下网址翻页后的URL:
http://www.zkh360.com/zkh_catalog/3.html
可以看到,有些网址翻页后URL是不变的,那该怎么爬取,请看下文。
2. 使用谷歌浏览器分析网页的真实请求
- 谷歌浏览器——检查——Network
- 首先清空请求列表,点击下一页(第2页)
- 在请求列表里查找真实的请求,可发现包含商品信息的真实请求为: http://www.zkh360.com/Product/SearchProduct?catalogueId=3&pageIndex=2&pageSize=20
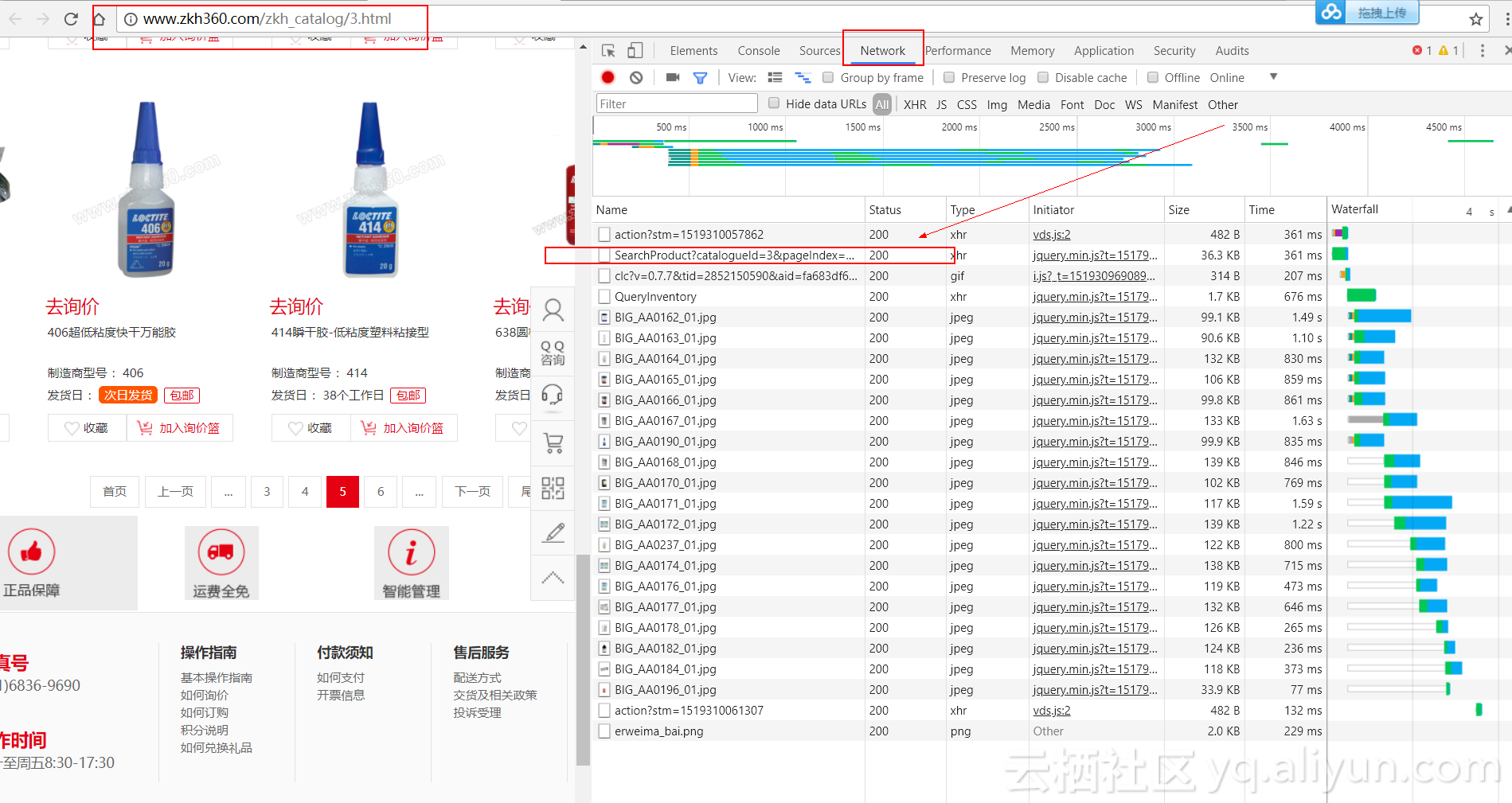
箭头所指的地方就是真实请求
以下是第2、3、4页的请求,通过对比可以发现网站是通过pageIndex参数控制翻页的,并且pageSize参数删去之后并不会对请求产生影响
- 第2页:http://www.zkh360.com/Product/SearchProduct?catalogueId=3&pageIndex=2&pageSize=20
- 第3页:http://www.zkh360.com/Product/SearchProduct?catalogueId=3&pageIndex=3&pageSize=20
- 第4页:http://www.zkh360.com/Product/SearchProduct?catalogueId=3&pageIndex=4&pageSize=20
- 有关参数的信息可以在Hearders的Query String Parameters里查找到
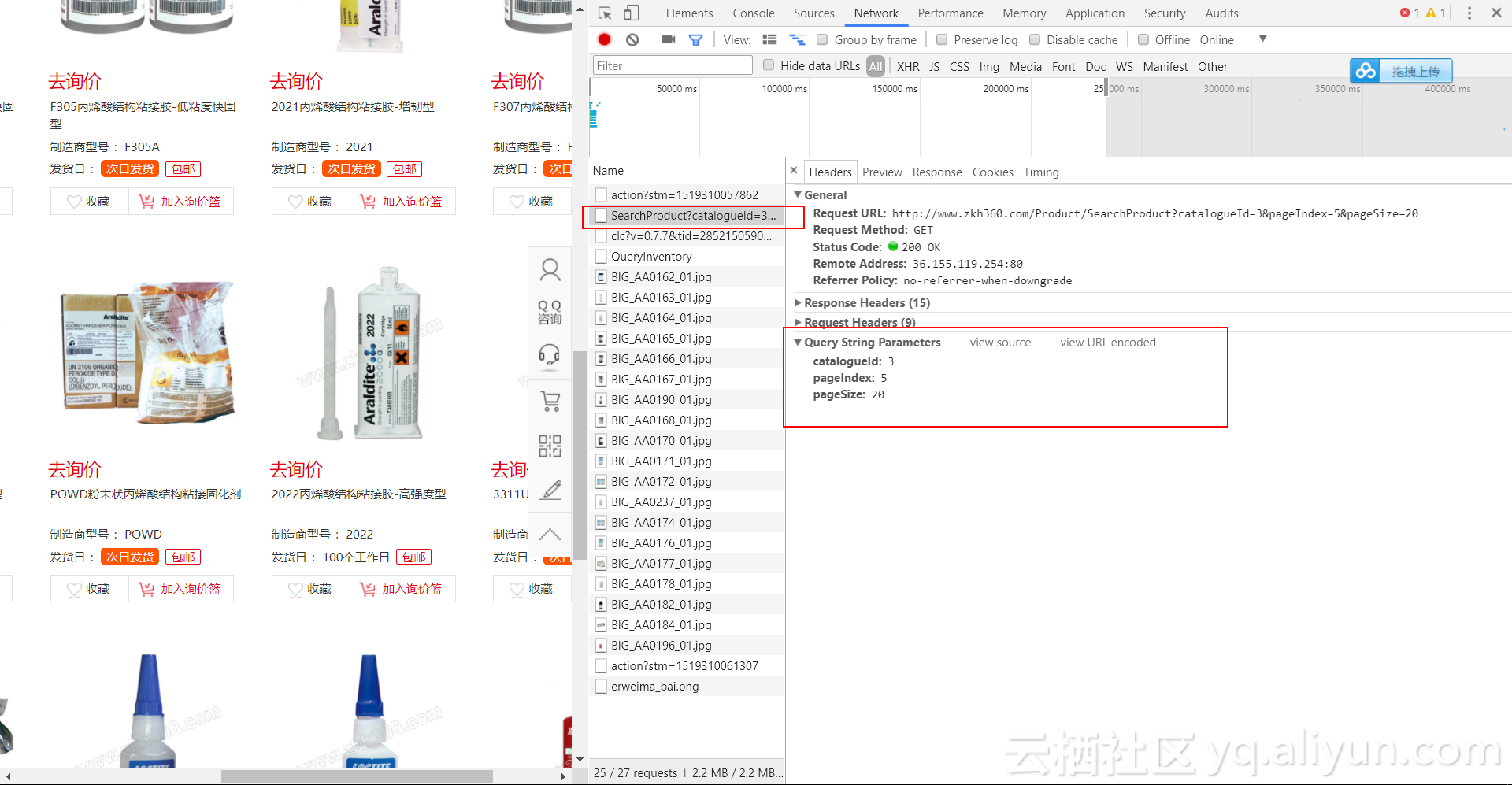
- 翻页后URL不发生变化的网站的数据一般都是通过Ajax或者JavaScript加载的,可以在过滤器的XHR或者JS中找到真实请求
3. 寻找真实请求的三个步骤

- 分析:使用谷歌浏览器开发者工具分析网页的请求
- 测试:测试URL请求中每个参数的作用,找出控制翻页等功能的参数
- 重复:多次重复寻找符合爬虫需要的真实请求
实战:爬取知乎
通过爬取知乎“轮子哥”——vczh关注的人分析Ajax或者JavaScript加载的数据的真实请求并展示这种爬取方法的具体过程。
1. 寻找真实请求的测试
- 首先,进入“轮子哥——vczh”关注的人的页面(注意:需要先登录个人知乎账号)
- 通过禁止JavaScript加载的方法发现页面不能正常加载,确认该页面的翻页是通过JavaScript加载数据实现的
- 使用谷歌浏览器开发者工具寻找包含关注人信息的真实请求,可以发现真实请求是以“followees”开头的请求,其返回一个JSON格式的数据,该数据对应下一页的“他关注的人”:
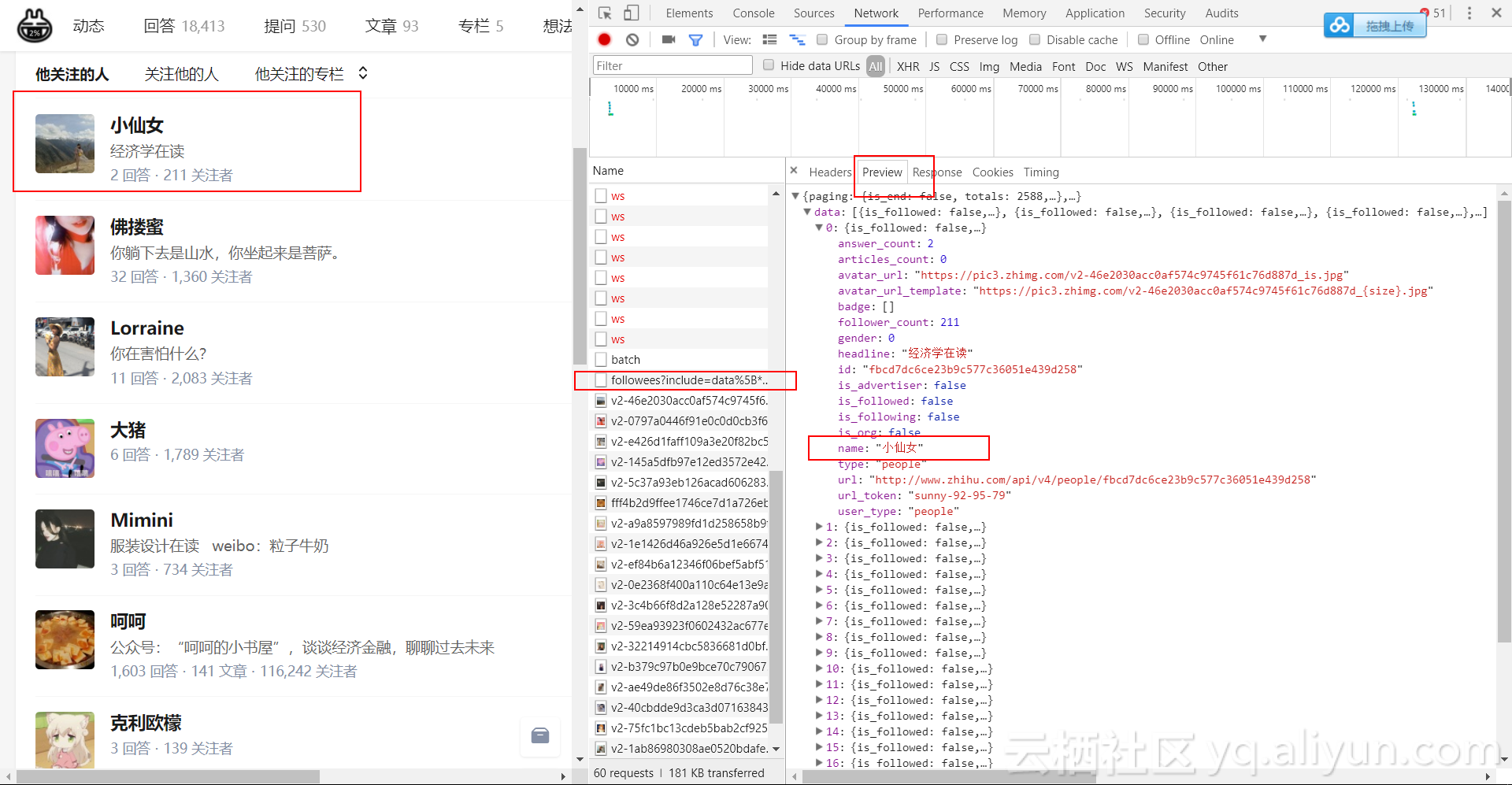
- 双击这个请求,返回一个JSON格式的数据,可以通过安装JSONView插件在浏览器中更好地显示该数据
- 接下来便可以尝试爬取该请求的数据
2. 尝试爬取真实请求的数据
- 首先使用requests.get()尝试爬取数据
# -*- coding:utf-8 -*-import requestsurl = 'https://www.zhihu.com/api/v4/members/excited-vczh/followees?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset=20&limit=20'
response = requests.get(url).textprint(response)<html><body><h1>500 Server Error</h1>
An internal server error occured.
</body></html>- 可以发现返回了“500 Server Error”,即由于网站反爬虫的原因,服务器返回了“500服务错误”
- 该问题可以通过添加hearders请求头信息解决
3. 添加hearders请求头信息模拟浏览器访问
- 请求头信息承载了关于客户端浏览器、请求页面、服务器等相关的信息,用来告知服务器发起请求的客户端的具体信息
- 知乎的反爬虫机制是通过核对请求头信息实现的,所以需要在使用requests请求数据的时候加上所需的请求头
- 对比知乎的请求头信息和常见的请求头信息,发现知乎请求头多了authorization和X-UDID的信息

- 在爬虫程序中添加请求头信息,即添加headers
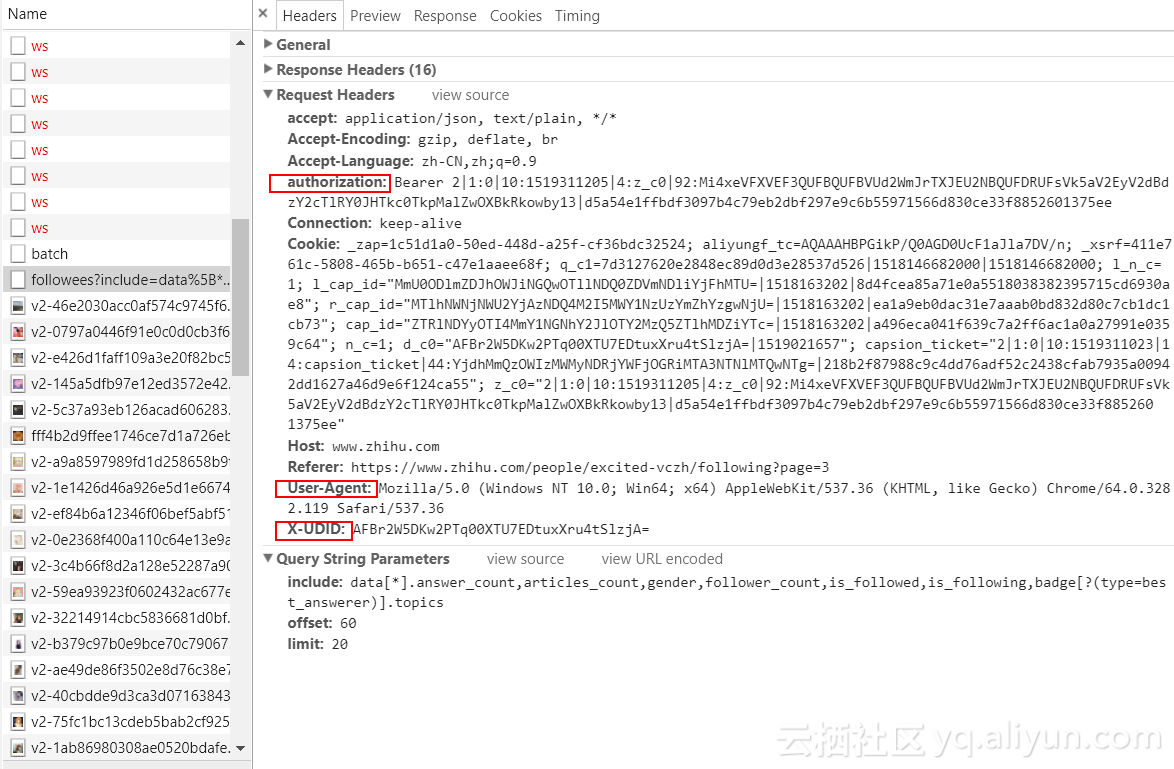
# -*- coding:utf-8 -*-import requestsheaders = {'authorization':'Bearer 2|1:0|10:1519311205|4:z_c0|92:Mi4xeVFXVEF3QUFBQUFBVUd2WmJrTXJEU2NBQUFDRUFsVk5aV2EyV2dBdzY2cTlRY0JHTkc0TkpMalZwOXBkRkowby13|d5a54e1ffbdf3097b4c79eb2dbf297e9c6b55971566d830ce33f8852601375ee ', #括号中填上你的authorization'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36',#括号中填上你的User-Agent
}
url = 'https://www.zhihu.com/api/v4/members/excited-vczh/followees?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset=20&limit=20'
response= requests.get(url, headers = headers).json()##print(response) 注:刚才写的时候出问题了,说是User-Agent问题,查了半天,发现是在最前面多了个空格。。
- 运行程序,成功返回数据
4. 使用pandas把数据保存入库
- pandas DataFrame的from_dict()方法可以很方便地把爬取到的数据保存为DataFrame格式的结构化数据
import pandas as pd
response= requests.get(url, headers = headers).json()['data'] #添加上['data']是因为关注人的信息是保存在data下面的,只需要这一部分的数据df = pd.DataFrame.from_dict(response)
df.to_csv('user.csv')5. 定义函数实现翻页爬取
- 定义一个get_user_data()函数,实现翻页爬取功能,并添加上爬取时间间隔以免由于爬取太频繁给服务器造成负担
import time
user_data = []
def get_user_data(page):for i in range(page):url = 'https://www.zhihu.com/api/v4/members/excited-vczh/followees?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset={}&limit=20'.format(i*20)response = requests.get(url, headers=headers).json()['data']user_data.extend(response) #把response数据添加进user_dataprint('正在爬取第%s页' % str(i+1))time.sleep(1) #设置爬取网页的时间间隔为1秒if __name__ == '__main__':get_user_data(10)df = pd.DataFrame.from_dict(user_data)df.to_csv('users2.csv')正在爬取第1页
正在爬取第2页
正在爬取第3页
正在爬取第4页
正在爬取第5页
正在爬取第6页
正在爬取第7页
正在爬取第8页
正在爬取第9页
正在爬取第10页ok,成功解决
DC学院爬虫学习笔记(六):浏览器抓包及headers设置相关推荐
- 学习笔记:测试抓包工具fiddler
正文 fiddler是一款常用的代理式HTTP抓包工具. 实现原理:客户端服务器进行消息交互时,HTTP客户端需要设置fiddler作为代理,把http请求发送给fiddler,fiddler再转发给 ...
- 学习笔记(01):Fiddler抓包实战【小强测试品牌】-移动app端抓包
立即学习:https://edu.csdn.net/course/play/4867/87815?utm_source=blogtoedu 移动app端抓包
- React Native 学习笔记六(关于宽高的设置)
继续在之前的例子上进行添加 尺寸 1.使用固定的尺寸 设置View容器 和设置自定义的组组件 如果父组件的空间不足 自控件的会出现重叠的情况 示例: import {AppRegistry,S ...
- python网络爬虫学习笔记(6)动态网页抓取(一)知识
文章目录 网络爬虫学习笔记(2) 1 资料 2 笔记 2-1 动态抓取概述 2-2 通过浏览器审查元素解析真实网页地址 2-3 网页URL地址的规律 2-4 json库 2-5 通过Selenium模 ...
- Python3 爬虫学习笔记 C05 【Selenium + 无界面浏览器】
Python3 爬虫学习笔记第五章 -- [Selenium + 无界面浏览器] 文章目录 [5.1]关于无界面浏览器 [5.2]PhantomJS [5.3]Headless Chrome [5.4 ...
- 2022 最新 Android 基础教程,从开发入门到项目实战【b站动脑学院】学习笔记——第六章:数据存储
第 6 章 数据存储 本章介绍Android 4种存储方式的用法,包括共享参数SharedPreferences.数据库SQLite.存储卡文 件.App的全局内存,另外介绍Android重要组件-应 ...
- 爬虫学习笔记(十)—— Scrapy框架(五):下载中间件、用户/IP代理池、settings文件
一.下载中间件 下载中间件是一个用来hooks进Scrapy的request/response处理过程的框架. 它是一个轻量级的底层系统,用来全局修改scrapy的request和response. ...
- 爬虫学习笔记(七)——Scrapy框架(二):Scrapy shell、选择器
一.Scrapy shell scrapy shell的作用是用于调试,在项目目录下输入scrapy shell start_urls (start_urls:目标url)得到下列信息: scrapy ...
- Python3 爬虫学习笔记 C17【爬虫框架 pyspider — 基本使用】
Python3 爬虫学习笔记第十七章 -- [爬虫框架 pyspider - 基本使用] 文章目录 [17.1]初识 pyspider [17.2]使用 pyspider [17.2.1]主界面 [1 ...
最新文章
- 《数据科学家养成手册》傅里叶变换与反傅里叶变换笔记
- C++ 调试技术:addr2line
- win10安装JDK cmd中可以运行java,但不能用javac,解决方案
- windowsphone开发_APP软件开发用哪些软件比较好
- python log函数_python要点-装饰器
- Socket连接心跳包的机制总结
- server2008R2平台部署exchange2010
- signature=54cb1c123491dc1a268a21f3502cccfc,Modelling information routing with noninterference
- 学习swing鼠标点击事件心得体会_西门子COMOS软件开发定制学习8-查询列表间的数据交互...
- 挑战练习14.8 删除crime 记录
- Neo4j 的一些使用心得
- 解决办法:ImportError: No module named google.protobuf.internal
- 《机器学习》课后习题3.5 编辑实现线性判别分析,并给出西瓜数据集 3.0α 上的结果.
- AC_PosControl.cpp的AC_PosControl::set_alt_target_with_slew函数代码分析
- vscode error: You have not concluded your merge
- Git安装及密钥的生成
- 先验分布与后验分布,认真看看这篇
- cancel java_Future.cancel()疑难杂症
- 动态生成的dom为什么绑定事件会失效,以及如何解决
- 用NERO刻录ISO等镜像光盘的方法