几种常见的模式识别算法
2019独角兽企业重金招聘Python工程师标准>>> 
1. K-Nearest Neighbor
K-NN可以说是一种最直接的用来分类未知数据的方法。基本通过下面这张图跟文字说明就可以明白K-NN是干什么的
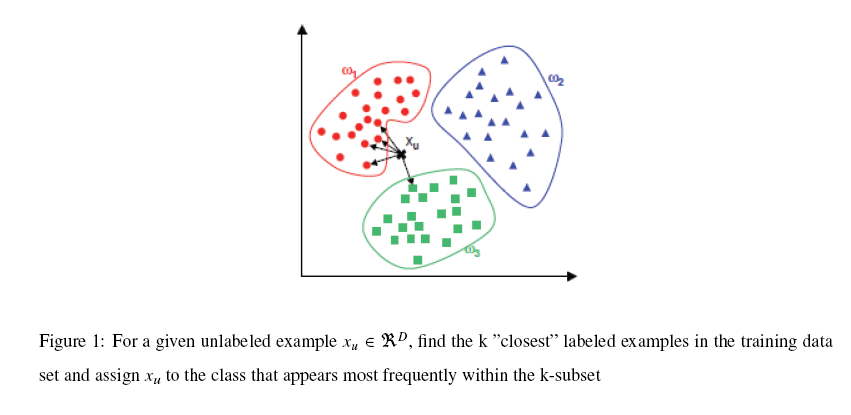
简单来说,K-NN可以看成:有那么一堆你已经知道分类的数据,然后当一个新数据进入的时候,就开始跟训练数据里的每个点求距离,然后挑离这个训练数据最近的K个点看看这几个点属于什么类型,然后用少数服从多数的原则,给新数据归类。一个比较好的介绍k-NN的课件可以见下面链接,图文并茂,我当时一看就懂了
http://courses.cs.tamu.edu/rgutier/cs790_w02/l8.pdf
实际上K-NN本身的运算量是相当大的,因为数据的维数往往不止2维,而且训练数据库越大,所求的样本间距离就越多。就拿我们course project的人脸检测来说,输入向量的维数是1024维(32x32的图,当然我觉得这种方法比较silly),训练数据有上千个,所以每次求距离(这里用的是欧式距离,就是我们最常用的平方和开根号求距法) 这样每个点的归类都要花上上百万次的计算。所以现在比较常用的一种方法就是kd-tree。也就是把整个输入空间划分成很多很多小子区域,然后根据临近的原则把它们组织为树形结构。然后搜索最近K个点的时候就不用全盘比较而只要比较临近几个子区域的训练数据就行了。kd-tree的一个比较好的课件可以见下面链接:
http://www.inf.ed.ac.uk/teaching/courses/inf2b/learnnotes/inf2b-learn06-lec.pdf
当然,kd-tree有一个问题就是当输入维数跟训练数据数量很接近时就很难优化了。所以用PCA(稍后会介绍)降维大多数情况下是很有必要的
2. Bayes Classifier
贝叶斯方法一篇比较科普的中文介绍可以见pongba的平凡而神奇的贝叶斯方法: http://mindhacks.cn/2008/09/21/the-magical-bayesian-method/,实际实现一个贝叶斯分类器之后再回头看这篇文章,感觉就很不一样。
在模式识别的实际应用中,贝叶斯方法绝非就是post正比于prior*likelihood这个公式这么简单,一般而言我们都会用正态分布拟合likelihood来实现。
用正态分布拟合是什么意思呢?贝叶斯方法式子的右边有两个量,一个是prior先验概率,这个求起来很简单,就是一大堆数据中求某一类数据占的百分比就可以了,比如300个一堆的数据中A类数据占100个,那么A的先验概率就是1/3。第二个就是likelihood,likelihood可以这么理解:对于每一类的训练数据,我们都用一个multivariate正态分布来拟合它们(即通过求得某一分类训练数据的平均值和协方差矩阵来拟合出一个正态分布),然后当进入一个新的测试数据之后,就分别求取这个数据点在每个类别的正态分布中的大小,然后用这个值乘以原先的prior便是所要求得的后验概率post了。
贝叶斯公式中还有一个evidence,对于初学者来说,可能会一下没法理解为什么在实际运算中它不见了。实则上,evidence只是一个让最后post归一化的东西,而在模式分类中,我们只需要比较不同类别间post的大小,归一化反而增加了它的运算量。当然,在有的地方,这个evidence绝对不能省,比如后文提到的GMM中,需要用到EM迭代,这时候如果不用evidence将post归一化,后果就会很可怕。
Bayes方法一个不错的参考网页可见下面链接:
http://www.cs.mcgill.ca/~mcleish/644/main.html
3. Principle Component Analysis
PCA,译为主元分析或者主成份分析,是一种很好的简化数据的方法,也是PR中常见到不能再常见的算法之一。CSDN上有一篇很不错的中文博客介绍PCA,《主元分析(PCA)理论分析及应用》,可以见下面链接:
http://blog.csdn.net/ayw_hehe/archive/2010/07/16/5736659.aspx
对于我而言,主元分析最大的意义就是让我明白了线性代数中特征值跟特征向量究竟代表什么,从而让我进一步感受到了线性代数的博大精深魅力无穷。- -|||
PCA简而言之就是根据输入数据的分布给输入数据重新找到更能描述这组数据的正交的坐标轴,比如下面一幅图,对于那个椭圆状的分布,最方便表示这个分布的坐标轴肯定是椭圆的长轴短轴而不是原来的x y。
那么如何求出这个长轴和短轴呢?于是线性代数就来了:我们求出这堆数据的协方差矩阵(关于什么是协方差矩阵,详见本节最后附的链接),然后再求出这个协方差矩阵的特征值和特征向量,对应最大特征值的那个特征向量的方向就是长轴(也就是主元)的方向,次大特征值的就是第二主元的方向,以此类推。
关于PCA,推荐两个不错的tutorial:
(1) A tutorial on Principle Component Analysis从最基本的数学原理到应用都有,让我在被老师的讲课弄晕之后瞬间开悟的tutorial:
http://www.cs.otago.ac.nz/cosc453/student_tutorials/principal_components.pdf
(2) 里面有一个很生动的实现PCA的例子,还有告诉你PCA跟SVD是什么关系的,对编程实现的帮助很大(当然大多数情况下都不用自己编了):
http://www.math.ucsd.edu/~gptesler/283/pca_07-handout.pdf
4. Linear Discriminant Analysis
LDA,基本和PCA是一对双生子,它们之间的区别就是PCA是一种unsupervised的映射方法而LDA是一种supervised映射方法,这一点可以从下图中一个2D的例子简单看出

图的左边是PCA,它所作的只是将整组数据整体映射到最方便表示这组数据的坐标轴上,映射时没有利用任何数据内部的分类信息。因此,虽然做了PCA后,整组数据在表示上更加方便(降低了维数并将信息损失降到最低),但在分类上也许会变得更加困难;图的右边是LDA,可以明显看出,在增加了分类信息之后,两组输入映射到了另外一个坐标轴上,有了这样一个映射,两组数据之间的就变得更易区分了(在低维上就可以区分,减少了很大的运算量)。
在实际应用中,最常用的一种LDA方法叫作Fisher Linear Discriminant,其简要原理就是求取一个线性变换,是的样本数据中“between classes scatter matrix”(不同类数据间的协方差矩阵)和“within classes scatter matrix”(同一类数据内部的各个数据间协方差矩阵)之比的达到最大。关于Fisher LDA更具体的内容可以见下面课件,写的很不错~
http://www.csd.uwo.ca/~olga/Courses//CS434a_541a//Lecture8.pdf
5. Non-negative Matrix Factorization
NMF,中文译为非负矩阵分解。一篇比较不错的NMF中文介绍文可以见下面一篇博文的链接,《非负矩阵分解:数学的奇妙力量》
http://chnfyn.blog.163.com/blog/static/26954632200751625243295/
这篇博文很大概地介绍了一下NMF的来龙去脉(当然里面那幅图是错的。。。),当然如果你想更深入地了解NMF的话,可以参考Lee和Seung当年发表在Nature上面的NMF原文,"Learning the parts of objects by non-negative matrix factorization"
http://www.seas.upenn.edu/~ddlee/Papers/nmf.pdf
读了这篇论文,基本其他任何介绍NMF基本方法的材料都是浮云了。
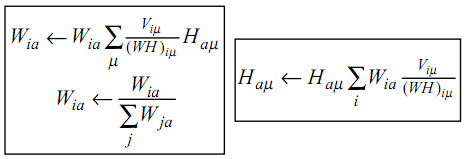
NMF,简而言之,就是给定一个非负矩阵V,我们寻找另外两个非负矩阵W和H来分解它,使得后W和H的乘积是V。论文中所提到的最简单的方法,就是根据最小化||V-WH||的要求,通过Gradient Discent推导出一个update rule,然后再对其中的每个元素进行迭代,最后得到最小值,具体的update rule见下图,注意其中Wia等带下标的符号表示的是矩阵里的元素,而非代表整个矩阵,当年在这个上面绕了好久。。
当然上面所提的方法只是其中一种而已,在http://spinner.cofc.edu/~langvillea/NISS-NMF.pdf中有更多详细方法的介绍。
相比于PCA、LDA,NMF有个明显的好处就是它的非负,因为为在很多情况下带有负号的运算算起来都不这么方便,但是它也有一个问题就是NMF分解出来的结果不像PCA和LDA一样是恒定的。
6. Gaussian Mixture Model
GMM高斯混合模型粗看上去跟上文所提的贝叶斯分类器有点类似,但两者的方法有很大的不同。在贝叶斯分类器中,我们已经事先知道了训练数据(training set)的分类信息,因此只要根据对应的均值和协方差矩阵拟合一个高斯分布即可。而在GMM中,我们除了数据的信息,对数据的分类一无所知,因此,在运算时我们不仅需要估算每个数据的分类,还要估算这些估算后数据分类的均值和协方差矩阵。。。也就是说如果有1000个训练数据10租分类的话,需要求的未知数是1000+10+10(用未知数表示未必确切,确切的说是1000个1x10标志向量,10个与训练数据同维的平均向量,10个与训练数据同维的方阵)。。。反正想想都是很头大的事情。。。那么这个问题是怎么解决的呢?
这里用的是一种叫EM迭代的方法。
转载于:https://my.oschina.net/u/2409257/blog/614158
几种常见的模式识别算法相关推荐
- 完整性校验用到常见的算法_几种常见的校验算法
素材来源:网络 编辑整理:strongerHuang UART有一个奇偶校验,CAN通信有CRC校验.Modbus.MAVlink.USB等通信协议也有校验信息. 在自定义数据存储时,有经验的工程师都 ...
- 五种常见的聚类算法总结
目录 一.关于聚类的基础描述 1.1 聚类与分类的区别 1.2 聚类的概念 1.3 聚类的步骤 二.几种常见的聚类算法 2.1 K-means聚类算法 1) K-means算法的流程: 2)K- ...
- 七种常见的排序算法总结
目录 引言 1.什么是排序? 2.排序算法的目的是什么? 3.常见的排序算法有哪些? 一,插入排序 1.基本思想 2.代码实现 3.性能分析 4.测试 二,希尔排序(缩小增量排序) 1.基本思想 2. ...
- access两字段同时升序排序_7 天时间,我整理并实现了这 9 种常见的排序算法
排序算法 回顾 我们前面已经介绍了 3 种最常见的排序算法: java 实现冒泡排序讲解 QuickSort 快速排序到底快在哪里? SelectionSort 选择排序算法详解(java 实现) 然 ...
- 10种常见的回归算法总结和介绍
线性回归是机器学习中最简单的算法,它可以通过不同的方式进行训练. 在本文中,我们将介绍以下回归算法:线性回归.Robust 回归.Ridge 回归.LASSO 回归.Elastic Net.多项式回归 ...
- 搭建直播网站时使用 Python 实现几种常见的排序算法
排序是非常常见的算法,今天就来分享几种常见排序算法的 Python 实现 冒泡排序 冒泡排序是最为基础的排序算法,其核心思想就是相邻元素两两比较,把较大的元素放到后面,在一轮比较完成之后,最大的元素就 ...
- 数据结构几种常见的排序算法
学习过经典的冒泡排序算法后,我们将继续深入学习,了解更多算法排序 插入排序 直接插入排序 直接插入排序其基本思想是:把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,指导所有记录插 ...
- 几种常见的hash算法
原文链接:https://www.cnblogs.com/qijunhui/p/8445484.html 常用字符串哈希函数 BKDRHash,APHash,DJBHash,JSHash,RSHash ...
- c语言大小排序算法,七种常见的数组排序算法整理(C语言版本)
---C语言版本--- 冒泡排序 选择排序 直接插入排序 二分插入排序 希尔排序 快速排序 堆排序 #define EXCHANGE(num1, num2) { num1 = num1 ^ num2; ...
最新文章
- 赫夫曼树(哈夫曼树)
- 用质因子去分解质因数
- 【iOS开展-94】xcode6如何使用GIT以及如何添加太老项目GIT特征?
- Raspberry Pi, UPNP(二), Scala
- 任给十进制整数,请从低位到高位……
- Android动态添加Device Admin权限
- 《Python CookBook2》 第四章 Python技巧 对象拷贝 通过列表推导构建列表
- linux6.5防火墙开端口,Linux(CentOS6.5) 开放端口,配置防火墙
- 机器学习—LightGBM的原理、优化以及优缺点
- Djangon 基础总结 汇总 从请求到返回页面的过程,
- 通达+oa+php+文件+乱,通达OA文件上传+文件包含get shell复现
- 超像素经典 SLIC 算法 python 实现
- CVE-2017-0143(远程溢出)漏洞复现
- 字根校对-中文校对软件
- UCloud宗泽:区块链安全现状堪忧,泡沫与价值并存
- python中mysqldb模块_Python学习之MySQLdb模块
- 《科研诚信与学术规范》
- 2.Hadoop 生态圈及核心组件简介
- Grid布局练习案例
- 模拟退火算法及常见应用