RabbitMQ 简介
为什么80%的码农都做不了架构师?>>> 
RabbitMQ 简介
MQ
消息队列,上承生产者,下接消费者。从生产者侧获取消息,然后将消息转发给消费者。
由此可见,MQ必须具有两个属性:消息的缓存和路由。
此外,由于MQ的存在,使得原来消息的一次投递(生产者 --- > 消费者)变成了两次投递(生产者 ---> MQ ---> 消费者)。由此,MQ就需要考虑消息投递的可靠性问题,并由此引申出消息的防重发、防丢失问题。
RabbitMQ
MQ有好多种,比如ActiveMQ、RabbitMQ、RocketMQ、ZeroMQ、Kafaka。不过这里只讨论RabbitMQ。对于RabbitMQ,只需要知道,它是采用Erlang语言实现AMQP协议形成的消息中间件。
几个概念
先看一张总览图
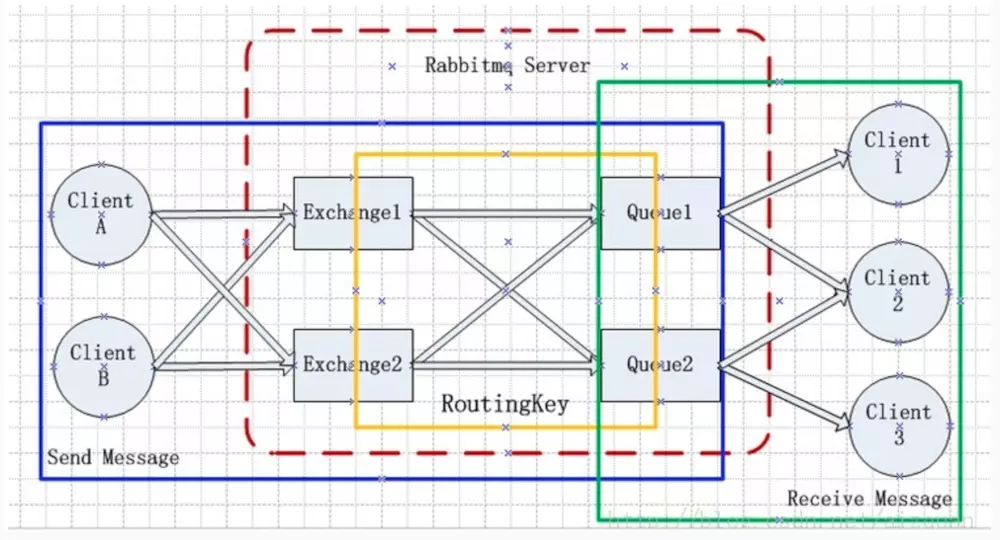
RabbitMQ Server
也叫broker server。RabbitMQ isn't a food trunk, it's a delivery service.它的角色是维护一条从Producer到Consumer的路线,保证数据能够按照指定的方式进行传输。但是这个保证也不是100%的保证,不过对于普通的应用来说,已经足够了。当然对于商业系统而言,再做一层数据一致性的guard,就可以彻底保证系统的一致性了。
Producer
生产者。数据的发送方。位于MQ的上游。
Consumer
消费者,数据的消费方。位于MQ的下游。
exchange
where producers publish their messages。
生产者直接将消息发送到exchange里面。
Queues
where messages end up and are received by consumers。
exchange接收到消息之后,会把消息投递给对应的Queue,交由消费者进行处理。这里的投递规则就是RabbitMQ的消息路由规则,下文再说。
Bindings
how the messages get routed from the exchange to particular queues.
也就是我们上面所说的路由规则。下文再进行详述。
vhost
虚拟主机。一个RabbitMQ物理服务器上可以支持有多个vhost。不同的vhost可以认为都是一个RabbitMQ Server,可以简单的理解为,每一个vhost都是运行在物理机上的一个虚拟机。它会拥有自己的queue、exchange、bindings等,并且不同的vhost单独配置自己的权限。注意,不同的vhost,其queue和exchange不允许绑定。
Connection
就是一个TCP连接。Producer和Consumer都是通过TCP连接到RabbitMQ Server的。
Channel
虚拟连接。建立在上述的Connection之上,一个Connection支持建立多个Channel,而我们的指令,就是通过channel来告知到RabbitMQServer的。一般情况下,程序起始,第一步就是建立Connection,第二步就是建立Channel(当然关闭的时候,需要先关闭channel,再关闭Connection)。
注意
- 我们几乎所有的指令都是通过channel执行的,包括建立exchange和建立Queue的指令都是通过Channel发送到server的。但是channel和exchange或者queue没啥关系,可以认为channel完全就是一个命令管道,主要为了复用TCP连接,除此之外,没啥其他特殊的地方。
- channel算是一种虚拟连接,只要TCP连接扛得住,创建多少都没关系。
- channel其实是可以支持多线程的,但是我们往往让一个channel只负责一个线程。当channel用于多线程时,其接收到的指令会进行排序,依次执行。所以,可以认为只能保证一定程度的线程安全(类似SynchronizedMap与SynchronizedList)。
channel存在的必要性
因为对于服务器来说,TCP链接也算是一种比较昂贵的资源(TCP连接数是有限制的,一定程度上限制了系统的并发能力),同时,对TCP连接的频繁建立和删除,也是相当耗费资源的。所以,引入了channel的概念,用以对Connection进行高度复用。
ConnectionFactory
建立Connection的工厂
消费模式
对于MQ来说,有两种经典的消费模式:推、拉。
部分MQ只支持推模式或者拉模式。而RabbitMQ同时支持两种模式。
推和拉两种模式都是针对消费者而言的。
拉
拉模式的话,就是消费者根据自己的意愿,主动从MQ中获取消息。MQ将不会主动将消息告知到消费者。
核心的方法就是:
GetResponse basicGet(String queue, Boolean autoACK);
代码示例如下:
public class ReceiverByGet {public final static String QUEUE_NAME = "hello";public static void main(String[] args) {ConnectionFactory factory = new ConnectionFactory();factory.setHost("localhost");Connection connection = factory.newConnection();Channel channel = connection.createChannel();channel.queueDeclare(QUEUE_NAME, false, false, false, null);while(true) {// 这里才是重点GetResponse response = channel.basicGet(QUEUE_NAME, true);if (response = null) {System.out.println("Get Nothing");TimeUnit.MILLISECONDS.sleep(1000);} else {String message = new String(response.getBody(), "UTF-8");System.out.println(message);TimeUnit.MILLISECONDS.sleep(500);}}}
}
推
顾名思义,推模式情况下, MQ主导什么情况下向消费者发送消息,以及每次发送多少消息。
而由于是MQ进行主导,在没有任何控制的情况下,很有可能会对消费者产生压力。基于此,MQ往往会提供一个字段,用来标识所允许的最大未消费(也就是未ack)的消息数。一旦未消费的消息数超过这个数值,将不会再往消费者推送消息。RabbitMQ里面同样有这么一个字段(叫做prefatchCount,是设置在channel上面的, 默认是1)。
推拉模式对比
显而易见,使用推模式的话,必须谨慎的设置prefatchCount字段,不然要么有可能会导致消费者消费能力不足导致被压垮,要么因为prefatchCount字段过小导致系统处理消息的能力受限。
但是,使用拉模式的话,消费者可以根据自己的能力来决定消费速率,但是在消费迟缓的时候,很容易造成消息的堆积。并且,有可能会导致消息从生产到消费的时间过长,在处理存在有效期的消息时,会造成一定的影响。
路由方式
如上文所述,MQ必须拥有两个功能:消息的缓存和路由。这里就讨论一下RabbitMQ所支持的消息路由方式。
(这里所说的消息路由是指从exchange向queue中消息的转发)
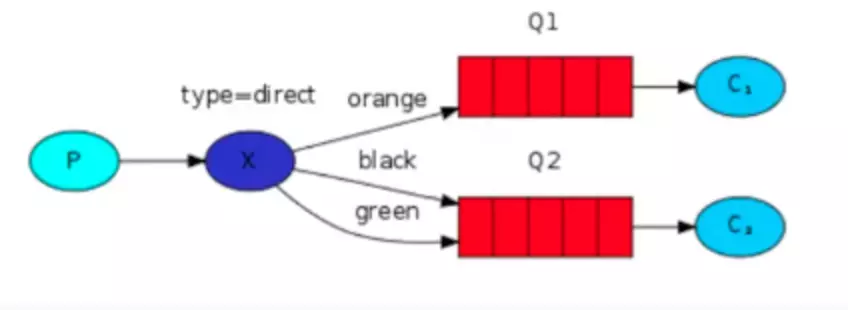
direct
direct模式下,exchange根据消息的routing key来将消息分发给不同的queue。其工作流程如下:
- 声明一个queue,并且用K作为routing key绑定到direct模式的exchange上
- exchange接收到以R作为routing key的消息时,如果K==R,直接转发到对应的queue上
注意
- 即使direct经常用在单播的场景下,但是如果有两个queue使用同一个routing key绑定到同一个exchange上(如上图所示),那么这一条消息会在每一个queue发送一份。
实际使用中,往往会有如下的使用情况,一个queue用两个routing key挂载到exchange上面:
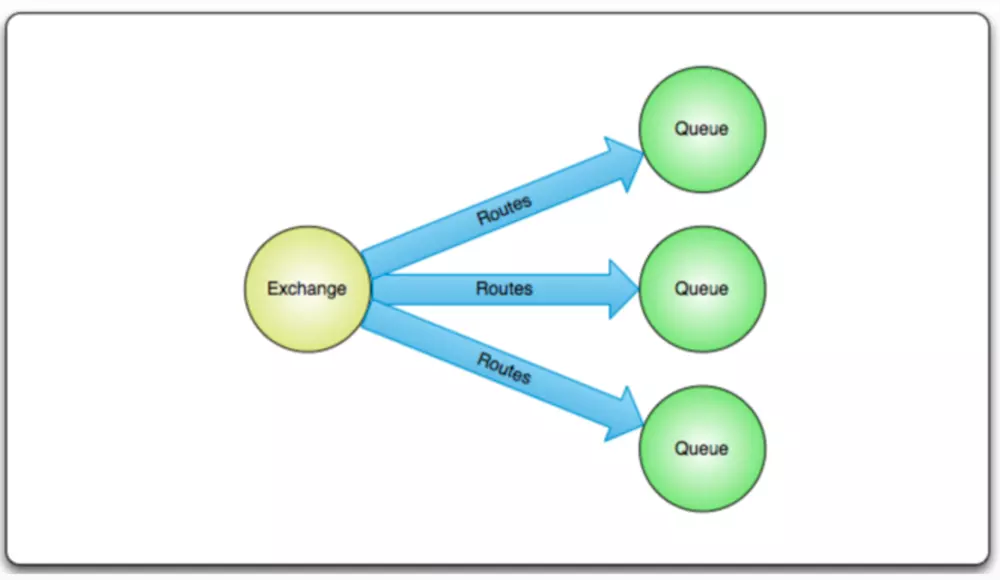
fanout
fanout模式又往往被认为是广播模式。如下图所示。
fanout模式的exchange会把消息发送到所有绑定到这个exchange上面的queue里面去。
也就是说,假设有N个queue绑定到同一个fanout的exchange上,这个exchange每接收到一条消息,就会向这N个queue分别发送一条消息。
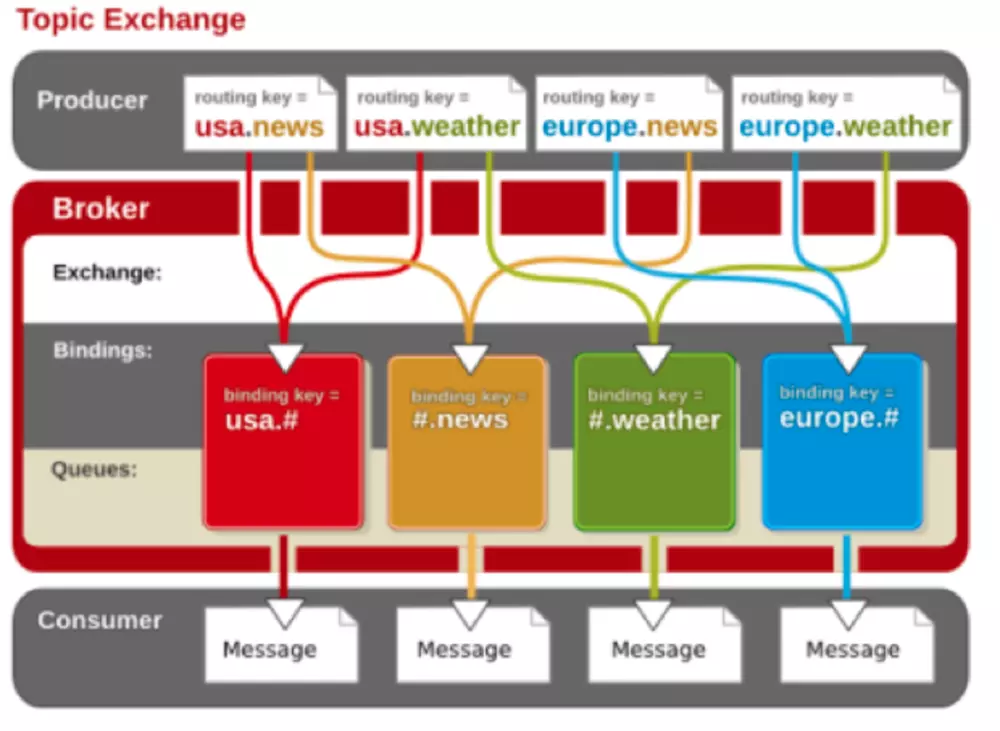
topic
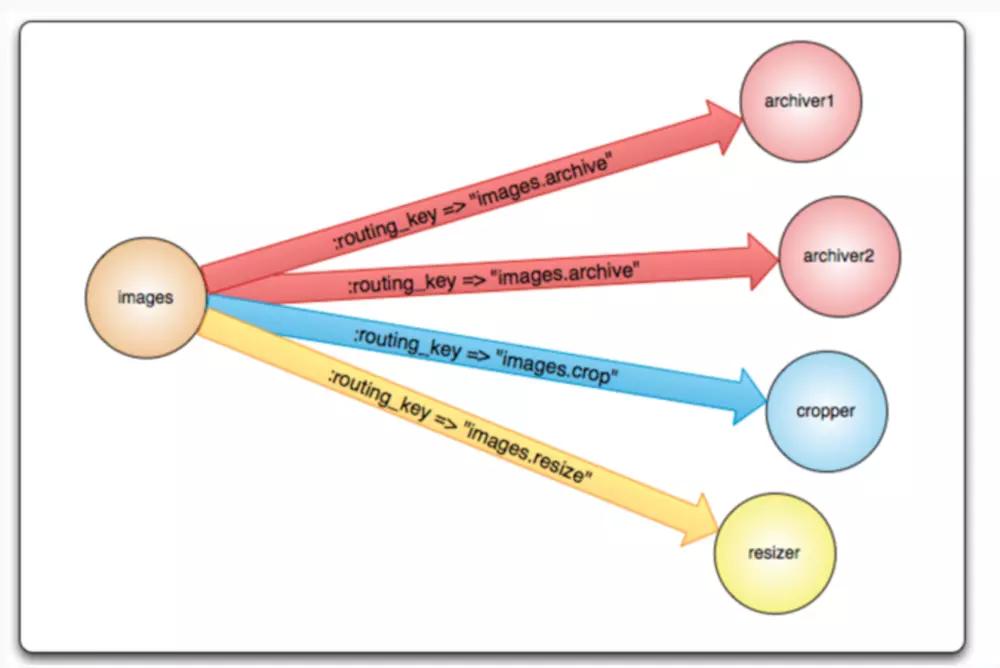
topic与direct模式有些相似,都是exchange拿到消息,之后会根据routing key,将消息发送到routing key相匹配并且绑定到了这个exchange上的queue里面去(如果有多个queue的routing key都匹配,那么这些queue都会收到消息)。不过topic与direct的一个区别在于:topic模式下,queue向exchange绑定所用的routing key是支持模糊匹配的,其中*可以匹配一个标志符,#可以匹配零个或多个字符。比如消息的 routing key为callcenter.agent.C1.call,那么queue做绑定时使用如下的routing key都能够获取到消息:callcenter.agent.#、callcenter.agent.C1.*、callcenter.agent.*.call。
根据topic的性质,此模式经常用做消息的多播模型。
header
上面所说的三种是最经常使用的模式,此外,还有一种header模式。
header模式的exchange在路由消息时,是不会使用routing key作为路由依据的,它的路由依据为消息的headers属性(并且只有在完全匹配的时候才会进行路由,否则是不会向这些queue投递消息的,消息会进入Alternate Exchanges,后面会详述)。
消息的可靠性投递
消息的确认机制
生产侧的消息确认
消息从生产者产生,交给RabbitMQ,但是由于网络的不确定性,消息是有可能交付失败的,所以RabbitMQ提供了两种模式来保证生产者侧的消息可靠性投递。
事务模式
这里的事务有三个核心方法:
channel.txSelect(); // 开启事务
channel.txCommint(); // 事务提交
channel.txRollback(); //事务回滚
只有成功地将消息交付给RabbitMQ,事务才算完成。显而易见,使用事务会对性能造成影响。
使用示例:
try {channel.txSelect();channel.basicPublish(exchange, routingKey, MessageProperties.PERSISTENT_TEXT_PLAIN, msg.getBytes());channel.txCommint();
} catch(Exception ex) {ex.printStackTrace();channel.txRollback();
}
confirm模式
原理
生产者将信道设置成confirm模式,一旦信道设置成confirm模式,所有在该信道上面发布的消息都会被指派一个唯一的ID(从1开始),一旦消息被投递到所有匹配的队列后,broker就会发送一个确认给生产者(包含消息的唯一ID),这就使得生产者知道消息已经正确到达目的队列了。如果消息和队列是持久化的(持久化的内容下文再说),那么确认消息会在消息写入磁盘后再发出。broker回传给生产者的确认消息中deliver-tag域包含了确认消息的序列号。此外,broker也可以设置basic.ack的multiple域,表示到这个序列号之前的所有消息都已经得到了处理。
confirm模式最大的好处在于它可以是异步的,一旦发布一条消息,生产者的应用程序就可以在等信道确认的同时继续发送下一条消息,当消息最终得到确认之后,生产者应用便可以通过回调方法来处理该确认消息,如果RabbitMQ因为自身内部错误导致消息丢失,就会发送一条nack消息,生产者应用程序同样可以在回调方法中处理该nack消息。
在channel被设置成confirm模式之后,所有被publish的后续消息都将被confirm(即ack)或者被nack一次。但是没有对消息被confirm的快慢做任何保证,并且同一条消息不回既被ack又被nack。
同时,confirm模式和事务模式不允许同时存在。
confirm方式又分为三种:单条confirm、批量confirm、异步confirm
单条confirm
又称普通confirm模式。每发送一条消息,调用waitForConfirms()方法,等待MQ服务器端confirm。这实际上算是一种串行confirm了。
如果服务器端返回false或者超时未返回,生产者会对这条消息进行重传。
代码示例:
channel.basicPublish(ConfirmConfig.exchangeName, confirmConfig.routingKey, MessageProperties.PERSISTENT_TEXT_PLAIN, ConfirmConfig.msg_10B.getBytes());
if (!channel.waitForConfirms()) {System.out.println("send message failed");
}
批量confirm
每发送一批消息后,调用waitForConfirms()方法,等待服务器端confirm。
批量confirm比单条confirm稍微复杂一些。生产者程序需要定期(每隔多少秒)或者定量(达到多少条)或者两者结合起来publish消息,然后等待服务器端进行confirm。相比于单条confirm模式,批量confirm极大地提升了confirm效率。但是问题在于,一旦出现confirm返回false或者超时的情况,生产者需要将这一批次的消息全部重发,这会明显会带来消息重复。并且,在confirm消息经常丢失的情况下,批量confirm的性能应该是不升反降的。
代码示例:
channel.confrimSelect();
for (int i=0; i<batchCount; i++) {channel.basicPublish(ConfirmConfig.exchangeName, ConfirmConfig.routingKey, MessageProperties.PERSISTENT_TEXT_PLAIN, ConfirmConfig.msg_10B.getBytes());if (!channel.waitForConfirms()) {System.out.println("send message failed");}
}
异步confirm
提供一个回调方法,服务器端confirm了一条或者多条消息后client端会回调这个方法。
异步confirm模式的编程实现最为复杂。Channel对象提供的ConfirmListener()回调方法只包含deliveryTag(当前Channel发出的消息序号),我们需要自己为每一个Channel维护一个unconfirm的消息序号集合,每publish一条消息,集合中元素加1;每回调一次handleAck方法,unconfirm集合删掉相应的一条(multiple = false)或多条(multiple = true)记录。从程序运行效率上看,这个unconfirm集合最好采用有序集合SortedSet存储结构。实际上,SDK中的waitForConfirms()方法也是通过SortedSet维护消息序号的。
关键代码:
SortedSet<Long> confirmSet = Collections.SynchronizedSortedSet(new TreeSet<Long>());
channel.confirmSelect();
channel.addConfirmListener(new ConfirmListener(){public void handleAck(long deliveryTag, boolean multiple) throws IOException {if (multiple) {confirm.headSet(deliveryTag + 1).clear();} else {confirmSet.remove(deliveryTag);}}public void handleNack(long deliveryTag, boolean multiple) throws IOException {System.out.println("Nack, SeqNo: " + deliveryTag + ", multiple: " + multiple);if (multiple) {confirmSet.headSet(deliveryTag + 1).clear();} else {confirmSet.remove(deliveryTag);}}
});
while(true) {long nextSeqNo = channel.getNextPublishSeqNo();channel.basicPublish(ConfirmConfig.exchangeName, ConfirmConfig.routingKey, MessageProperties.PERSISTENT_TEXT_PLAIN, ConfirmConfig.msg_10B.getBytes());confirmSet.add(nextSeqNo);
}
性能比较
事务模式 < 单条confirm << 批量confirm < 异步confirm
使用事务模式,性能是最差的。单条confirm模式性能会比事务稍微好一些。但是和批量confirm模式还有异步confirm模式相比,就差的远了。批量confirm模式的问题在于confirm频繁返回false进行大量消息重发时会使性能降低,异步confirm模式(async)编程模型较为复杂,至于要采用哪种方式,视情况而定,自己选择。
消费侧的消息确认
为了保证消息成功到达消费者进行消费,RabbitMQ同样对消费侧存在消息的确认机制。
消费者在声明队列时,可以指定noAck参数,当noAck = false时,RabbitMQ会等待消费者显式发回ack信号才会从内存(和磁盘,如果是持久化消息的话)中移除消息。否则,RabbitMQ会在队列中消息被消费后立即进行删除。
三种模式:
- AcknowledgeMode.NONE:无需确认。在消息发送到消费者时,就进行ack,也就认为消费成功了。这种情况下,只有负责队列的进程出现了异常,才会进行nack,其他情况都是ack。
- AcknowledgeMode.AUTO:根据情况ack。如果消费过程中没有抛出异常,就认为消费成功了,也就进行ack。这里有几个异常会存在特殊处理:AmqpRejectAndDontRequeueException,会认为消息失败,拒绝消息,并且requeue = false(也就是不再重新投递);ImmediateAcknowledgeAmqpException,会进行ack;其他的异常均进行nack,同时requeue = true(也就是进行重新投递)。
- AcknowledgeMode.MANUAL:手动ack。上面两种都是不需要关心ack方法调用的,但是使用手动ack时,必须要手动调用ack方法。不过,手动ack是支持批量处理的(可以设置是否进行批量ack),这样可以减小IO消耗。不过它有着与批量confirm相同的问题。
注意
- 只有收到了ack消息,MQ才会从存储中把这一条消息给移除。
- 对于消费者这一侧的消息确认,RabbitMQ是没有设置超时时间的,理由是并不能确认消息的消费时长。但是一旦消费者的链接断开,这些没有ack的消息是会被重新投递的。换句话说,如果一个消费者挂掉(与MQ的连接断开),没有ack的消息会进行重新投递,但是假如这个消费者没有挂掉,那么会一直等待ack,没有超时时间的限制。
- queue中一个消息每一次发送给消费者后只能被ack或者nack一次。如果超过一次,会报出通道(channel)异常。这是因为channel对于其中的每一个消息都会进行编号(回忆一下上面异步confirm所讲的内容,很类似)。同理,如果ack或者nack了一个从未出现过的编号,同样会抛出异常。
- ack与nack的一些内容:
- ack代表消息进行了正常消费
- nack和reject其实是一样的,都是代表消息并没有被正常消费,其区别在于reject每次只能处理一条消息
- nack和reject之后,消息的处理策略是依据requeue而定的。如果requeue为true,则消息会被重新投递,再次尝试进行消费(如果存在多个消费者,那么有可能不是之前的消费者拿到这个消息);如果requeue = false,则会判断当前队列是否设置了Dead Letter Exchange,如果有设置,消息会进入这个exchange,如果没有设置,消息会被直接移除。
持久化机制
持久化主要为了解决RabbitMQ在异常情况下的可靠性问题(比如直接crash了)。
持久化的作用就是,把指定的内容保存到磁盘上,这样即使在MQ服务器崩溃的时候,重启之后也能重新从磁盘中读取出来,恢复之前的内容。
持久化可以分为三部分:Exchange的持久化、Queue的持久化、消息的持久化。
加深理解:
- exchange、queue、消息这三部分的持久化没什么关联,谁声明为持久化,服务器重启之后,就会对谁进行重新构建。不过,如果想恢复整个的流程,最好对这三者都进行持久化(当然,持久化是会效率有损耗的)。
- Queue和exchange都可以在创建的时候直接声明为持久化的(declare方法中的一个参数)。而消息是在发送的时候设置为持久化的(basicPublish的一个参数)。
- 不需要为Binding持久化,只要对exchange和queue设置为持久化的,在恢复的时候,binding会自动恢复(其实可以理解为binding本身只是一个虚拟概念,实际是依仗于exchange的模式以及queue的routing key设置才建立的)。
- RabbitMQ不会允许一个非持久化的exchange和一个持久化的queue进行绑定,反之亦然。想要成功绑定,exchange和queue必须都是持久化的,或者都是非持久化的。
- 一旦创建了exchange或者queue之后,是不允许进行修改的,要想修改只能删除重建。所以,要将一个非持久化的队列变成持久化的,唯一的办法只能删除这个队列之后重新建立。
- 在不设置持久化的情况下,消息是会放在内存中的,不会落到磁盘上(所以重启时会丢消息)。
- 如果生产者这一侧开启了事务模式,消息是一定会被持久化的。只有在消息刷到磁盘上,才会告知成功。
其他:
- 将Queue、exchange、消息都设置成持久化的,就能保证消息100%不丢了吗?
当然不是。
一个关键的问题就在于,在生产者这一侧,如果没有采用事务模式,消息在进入RabbitMQ之后,并不是立刻落到磁盘上的,这里有一个刷盘时机的限制。如果这时服务器宕机了,那么这部分没有刷盘的消息自然会被丢了。当然,前面也说了,这是生产者这一侧没有采用事务模式的情况下的问题,如果设置了事务,只有在消息刷到磁盘上,才算是正常结束。 - 消息什么时间会刷到磁盘上?
前提:生产侧非事务场景。
RabbitMQ会有一个buffer,大小为1M,生产者产生的数据进入MQ的时候,会先进入这个buffer。只有当buffer写满之后,才会将buffer里面的内容写入文件中(这里仍不一定立即写入磁盘中)。
此外,还有一个固定的刷盘周期:25ms,也就是不管buffer有没有满,每隔25ms,都会进行一次刷盘操作,将buffer里面的内容与未刷入磁盘的文件内容落到磁盘上。
负载均衡
在MQ集群中,往往不会只有一台机器,这样的话,每一个客户端要具体连接到那一台服务器就需要进行控制。举个例子,假设集群中三台机器,但是所有的连接都打到了其中的一台机器上,这样的话,整个系统的性能和可靠性显然是有问题的。
实际上,对于RabbitMQ而言,可以在客户端连接时简单地使用一些算法来实现负载均衡,这一类的算法有很多种,这里说下常见的一些:
轮询法
将请求按顺序轮流地分配到后端服务器上,它均衡地对待后端的每一台服务器,而不关心服务器实际的连接数和当前的系统负载。
代码示例:
public class RoundRobin {private static List<String> list = new ArrayList<String>() {{add("192.168.0.2");add("192.168.0.3");add("192.168.0.4");}};private static int pos = 0;private static final Object lock = new Object();public static String getConnectionAddress() {String ip = null;synchronized(lock) {ip = list.get(pos);if (++pos >= list.size()) {pos = 0;}}return ip;}
}
随机法
通过随机算法,根据后端服务器的列表大小值来随机选取其中的一台服务器进行访问。由概率统计理论可以得知,随着客户端调用服务端的次数增多,其实际效果越来越接近于平均分配(也就是轮询分配)。
代码示例:
public class RandomAccess {private static List<String> list = new ArrayList<String>(){{add("192.168.0.2");add("192.168.0.3");add("192.168.0.4");}};public static String getConnectionAccess() {Random random = new Random();int pos = random.nextInt(list.size());return list.get(pos);}
}
源地址哈希法
源地址哈希的思想是根据获取的客户端ip地址,通过哈希函数计算到一个数值,用该数值对服务器列表的大小进行取模运算,得到的结果便是客户端要访问服务器的序号。采用源地址哈希法进行负载均衡,同一ip地址的客户端,当后端服务器列表不变时,它每次都会映射到同一台后端服务器进行访问。
代码示例:
public class IpHash {private static List<String> list = new ArrayList<String>(){{add("192.168.0.2");add("192.168.0.3");add("192.168.0.4");}};public static String getConnectionAccess() throws UnknownHostException {int ipHashCode = InetAddress.getLocalHost().getHostAddress().hashCode();int pos = ipHashCode % list.size();return list.get(pos);}
}
加权轮询法
不同的服务器可能机器的配置和当前系统的负载并不相同,因此它们的抗压能力也不相同。给配置高、负载低的机器配置更高的权重,让其处理更多的请求;而配置低、负载高的机器,给其分配较低的权重,降低其系统负载。加权轮询能够很好地处理这一问题,并将请求顺序且按照权重分配到后端。
加权随机法
与加权轮询法一样,加权随机法也根据后端机器的配置、系统的负载分配不同的权重。不同的是,它是按照权重随机请求后端服务器,而非顺序。
最小连接数法
最小连接数算法比较灵活和智能,由于服务器的配置不尽相同,对于请求的处理有快有慢,它是根据服务器当前的连接情况,动态地选择其中当前积压连接数最少的一台服务器来处理当前的请求,尽可能地提高服务器的利用效率,将负载合理地分流到每一台服务器。
集群
这里只讨论cluster模式的集群。
首先,需要了解一个点:RabbitMQ是基于Erlang实现的,而Erlang天生是具有分布式特性的(基于Erlang的magic cookie),所以对于RabbitMQ而言,实现集群非常简单,并不像其他的MQ那样实现集群需要zk等。
这里只讨论两种模式的集群:默认模式、镜像队列模式。
元数据
在集群中,不同的节点会彼此同步四种类型的元数据:
- 队列元数据:队列名称和它的属性
- 交换器元数据:交换器名称、类型和属性
- 绑定元数据:一张简单的表格展示了如何将消息路由到queue
- vhost元数据:为vhost内的队列、交换器和绑定提供命名空间和安全属性。
所以,可以认为在每一个节点通过rabbitmqctl指令查询到的queue/user/exchange/vhost信息都是相同的。
此外,在RabbitMQ集群中,会有多个节点,这些节点有内存节点和磁盘节点之分。顾名思义,内存节点,就是上面所说的同步的内容都放到了内存中,而磁盘节点就是这些信息都会放到磁盘中。当然,如果将exchange和queue设置为持久化的,即使是在内存节点上,这些信息也是会持久化到磁盘上的。
这里有两个注意点:
- 如果只有一个节点,则只能设置为磁盘节点。
- RabbitMQ集群中至少要有一个磁盘节点,所有其他的节点都可以是内存节点。在这种情况下,所有元数据有改动时,必须通知到磁盘节点,由其进行落盘处理。一旦磁盘节点挂掉,MQ可以正常运转,但是不会允许进行元数据的增删改查
- 解决这种问题的一个思路是,使用双磁盘节点,那么只会在两个节点都挂掉的时候,才会出现这个问题,而出现这种情况的几率就比较低了。
- RabbitMQ节点启动时,不指定的话,默认是磁盘节点。
- 其实RabbitMQ文档表示磁盘节点比内存节点性能差不了多少,建议都是用磁盘节点。
默认模式
下图展示了默认模式下的各节点示意图。各个节点之间只会复制队列元数据,不会同步队列的消息内容。
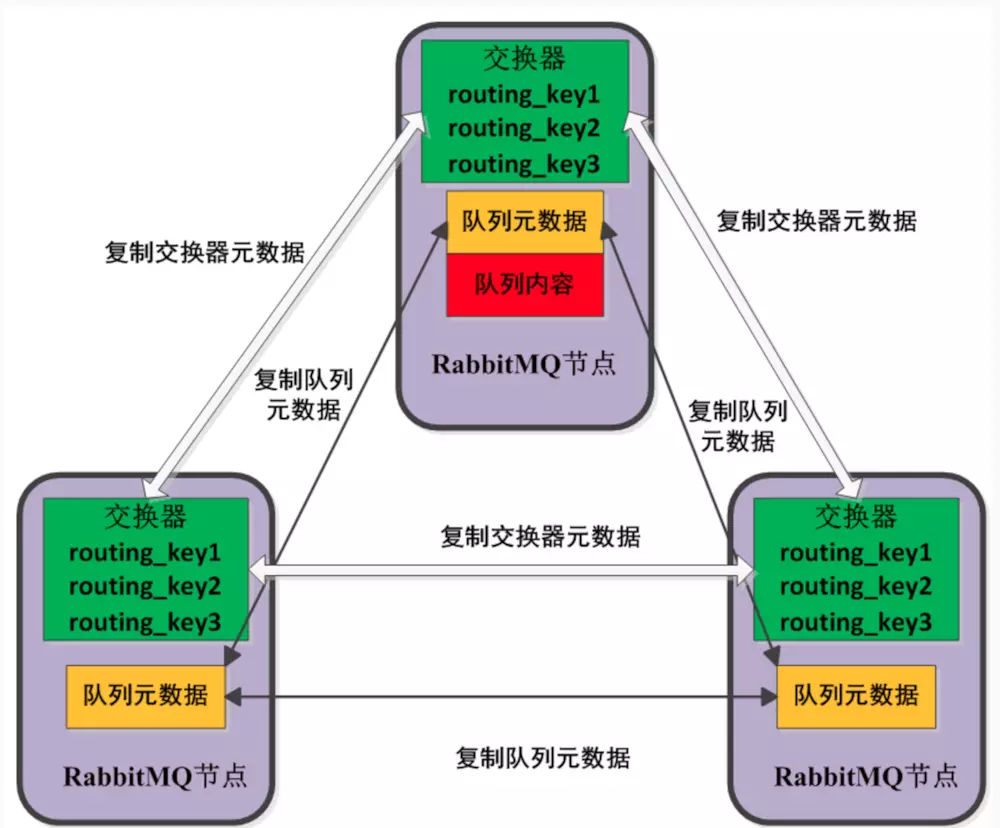
默认的集群模式下,对于exchenge的拷贝,是镜像拷贝,每个节点的内容完全一致,所有节点共享相同的exchange信息。此外,queue的元数据也会在各个节点之间进行同步,但是队列内的数据不会参与同步。
可以这么理解:MQ在从生产者那里拿到消息之后,消息是会先进入exchange的,而exchange会立即将消息路由到queue里面去,如果消费者消费能力不足,消息就会堆积在queue里面。换句话说,MQ的消息缓存能力主要由queue来实现。而这里的默认模式,每个节点之间会同步所有的exchange信息,并且会复制队列元数据,所以每一个节点都知道exchange和queue的所有属性,因此,消息无论从哪个节点进入exchange,这个节点都会知道这个消息应该路由到哪一个queue里面去。但是,一个consumer往往不会与所有的节点建立连接,这样的话,未建立连接的节点需要将queue里面的消息转发到那些建立了连接的节点以供消费。但是,一个队列里面的每一条消息最终都只会放到一个节点里面。
举个例子,假设我们有两个节点(rabbit01,rabbit02),首先,我们在02节点创建一个exchange,那么01节点会自动同步过去这个exchange的全部信息。之后我们在02节点创建了一个queue,那么对于集群中的01节点,它将只知道集群中有这么一个队列,并且知道它的结构等元数据。同时它将保存一个指向02节点这个queue的指针。这样就会出现一个场景:生产者生产了一条消息,并且发送到了01节点,这时候01这个节点的exchange接收到了消息,对消息进行路由,但是由于当前的consumer连接是位于02节点上面的,所以这时会利用上面所说的“指向02节点这个queue的指针”,将消息路由到02节点上去。然后进入queue,再交给consumer进行消费(这个过程中,逻辑上消息只有一份,01节点和02节点的同一个queue不会同时拥有这一条消息)。如下图所示:
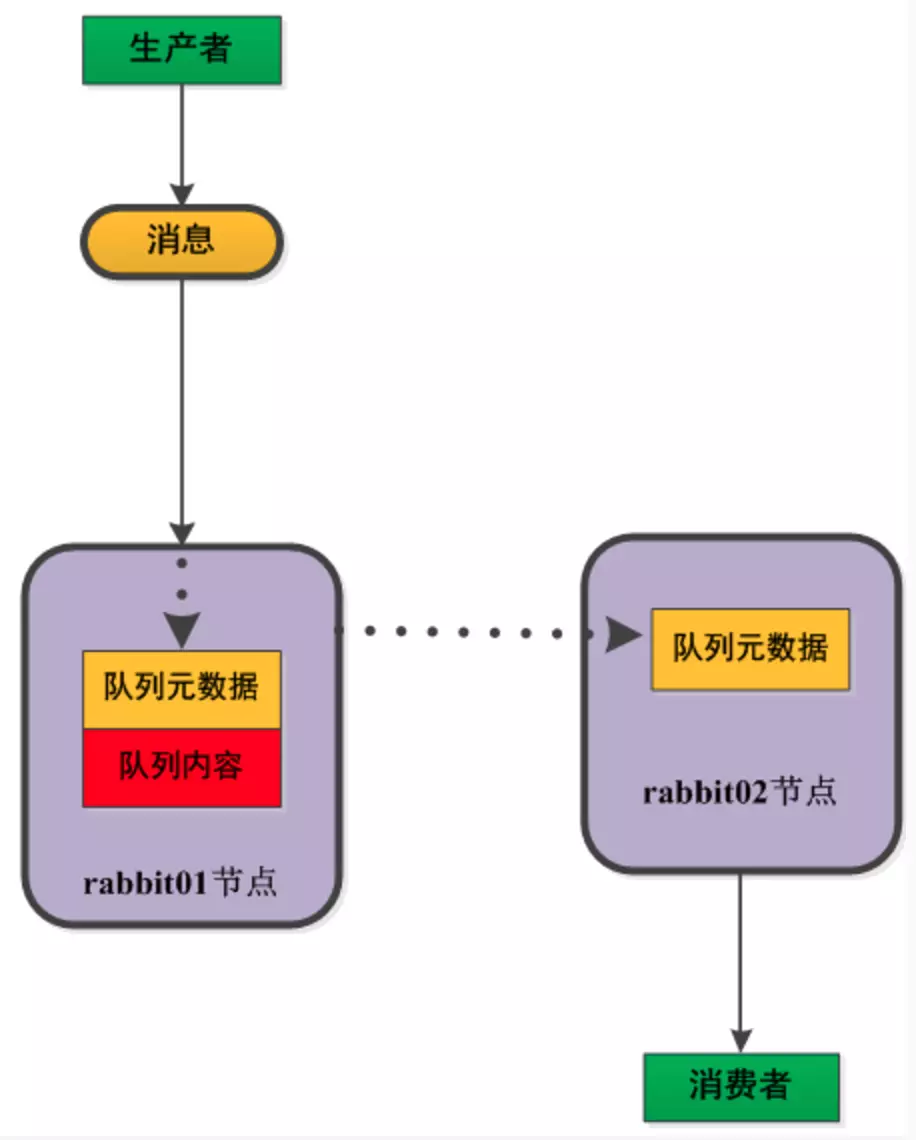
很容易可以想到,这种模式的优点在于,每个节点不用关心所有的消息内容,因此可以有更大的空间来缓存消息(因为消息只会存一份)。当然缺点就是,如果一个节点挂掉,这个节点上所有未消费的消息都无法从其他节点获取,一旦消息没有做持久化,这些消息都会丢失。如果做了持久化,也只能等这个节点重启之后,才能再进行消费。
此外,就如上面的例子,如果consumer只与其中一个节点(假设是02节点)建立了物理连接,那么对于集群来说,这个queue消息的出口将总是在02节点上,这就很容易产生性能瓶颈。并且,这种情况下02节点宕机,所有未确认消息都会暂时无法获取(因为都是缓存在这个节点上的)。一个处理的方案是,consumer尽可能地连接每一个节点(即对一个逻辑queue,在多个节点分别建立物理queue),从这些节点获取消息,这样一方面可以避免消息的大量路由,另一方面可以降低某一节点宕机带来的影响。
镜像模式
镜像模式与默认模式的一个区别就是队列内消息的处理方式。
在镜像模式下,每一个消息会在每一个节点主动进行拷贝,每个节点存储一份(默认模式下,只有当consumer需要消费数据时,才会对消息进行拷贝)。如下图所示:
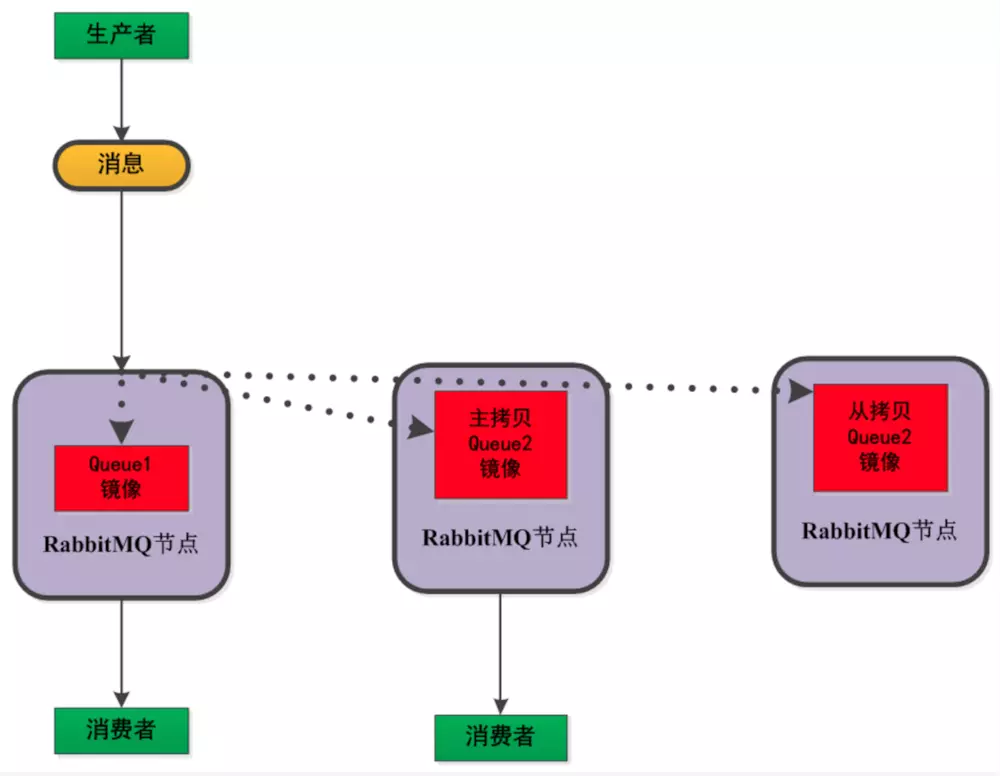
同样,我们可以看出,对于镜像模式而言,当某一个节点挂掉的时候,只要将链接切到另外一个节点下,就可以继续进行消息的正常消费,可靠性大为提升。但是,因为MQ内部会存在大量的消息路由,所以MQ的整体性能会受到影响(内部拷贝会占用大量的内部网络带宽),同时因为每一个节点都会保存所有的消息,所以对消息的缓存能力会有一定的影响(主要是跟默认模式进行比较)。
一种使用思路
默认模式和镜像模式都互有优劣,其实可以考虑一种使用思路:大部分节点使用默认模式,少部分(比如两个)节点使用镜像模式。不过这部分还没有深究。
其他
流量控制
MQ的流控主要是指发生在消费者消费能力不足的情况下,对生产者进行阻塞。
两种触发条件:
- 基于内存:如果MQ内存使用量超过40%,会抛出异常警告并阻塞所有生产链接(这个值可以调整)
- 基于磁盘:如果磁盘剩余容量少于1G,同样会阻塞所有的生产者(这个值同样可以调整)
特殊队列/exchange
排他队列
如果一个队列声明为了排他队列,那么该队列仅对首次声明它的连接可见,并且在断开连接时自动进行删除。
- 排他队列是基于连接可见的,同一个连接的不同channel是可以访问其他channel创建的排他队列的
- 如果一个连接建立了排他队列,那么是不允许其他连接建立同名的排他队列的
- 即使这个队列设置了持久化,一旦关闭连接(比如客户端退出),这个队列也会自动删除。所以,一旦机器宕机,这个队列是无法恢复的。同样,排他队列适用于一个客户端进行消息的发送和读取的应用场景。
临时队列
队列可以设置一个自动删除属性,如果队列没有任何订阅消费者时,会自动删除的。
优先级队列
RabbitMQ本身并没有实现优先级队列,不过有插件可以进行支持(好像3.5之后RabbitMQ自身已经支持了,没有考证)。
Dead Letter Exchange
可以对一个queue设置一个Dead Letter Exchange属性,当消息超时或者消息被nack/reject并且设置requeue=false时,会进入这个队列。
因为RabbitMQ没有延时队列和死信队列的设置,所以需要借助于Dead Letter Exchange来实现。RabbitMQ可以为queue或者消息添加一个超时属性,当超时未消费的话,会进行判断,如果有设置Dead Letter Exchange,会进入这个exchange里面,如果没有设置,会直接被丢弃掉。
Alternate Exchanges
生产者生产出来的消息,进入exchange之后,找不到合适的queue时,会落到这个队列中。
项目中使用的RabbitMQ
我们用的是SpringBoot,核心代码如下:
package com.rrc.async;import org.springframework.amqp.core.*;
import org.springframework.amqp.rabbit.connection.CachingConnectionFactory;
import org.springframework.amqp.rabbit.connection.ConnectionFactory;
import org.springframework.amqp.rabbit.core.RabbitAdmin;
import org.springframework.amqp.rabbit.listener.SimpleMessageListenerContainer;
import org.springframework.amqp.support.converter.Jackson2JsonMessageConverter;
import org.springframework.amqp.support.converter.MessageConverter;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;Configuration
public class MqConfig {@Beanpublic ConnectionFactory connectionFactory() {CachingConnectionFactory connectionFactory = new CachingConnectionFactory("localhost", 12345);connectionFactory.setVirtualHost("vhostName");connectionFactory.setUsername("userName");connectionFactory.setPassword("password");return connectionFactory;}@Beanpublic AmqpAdmin amqpAdmin() {return new RabbitAdmin(connectionFactory());}@Beanpublic MessageConverter jsonMessageConverter() {return new Jackson2JsonMessageConverter();}@Beanpublic TopicExchange exchange() {return new TopicExchange("exchangeName");}@Beanpublic Queue testQueue() {return new Queue("queueName");}@Beanpublic Binding testBind() {return BindingBuilder.bind(testQueue()).to(exchange()).with("routingKey");}@Beanpublic SimpleMessageListenerContainer testContainer() {SimpleMessageListenerContainer simpleMessageListenerContainer = new SimpleMessageListenerContainer();simpleMessageListenerContainer.setConnectionFactory(connectionFactory());simpleMessageListenerContainer.addQueues(testQueue());simpleMessageListenerContainer.setConcurrentConsumers(1);simpleMessageListenerContainer.setMaxConcurrentConsumers(2);// 这里没有写出来,testListener就是接收消息的bean(或者直接做成一个component)simpleMessageListenerContainer.setMessageListener(testListener);return simpleMessageListenerContainer;}
}
问题
- 如何将一台机器加入到MQ集群中?
需要首先设置Erlang cookie,集群中的所有节点必须拥有相同的cookie。
cookie是一个字符串,最多可以有255个字符,通常存储在本地文件中,并且该文件必须设置成所有者访问(400权限)。每个集群里面的所有节点必须拥有相同的cookie,文件位置:/var/lib/rabbitmq/.erlang.cookie
再之后执行rabbitmqctl的指令即可:rabbitmqctl join_cluster rabbit@rabbit1
(上面的rabbit1是第一个节点的机器名,其实rabbit@rabbit1就类似于work@10.171.12.3)
转载于:https://my.oschina.net/fymoon/blog/3013888
RabbitMQ 简介相关推荐
- RabbitMQ 简介以及使用场景
点击上方"方志朋",选择"设为星标" 回复"666"获取新整理的面试文章 作者:海向 cnblogs.com/haixiang/p/1019 ...
- RabbitMQ简介和六种工作模式详解
一.RabbitMQ简介 是一个开源的消息代理和队列服务器,用来通过普通协议在完全不同的应用之间共享数据,RabbitMQ是使用Erlang(高并发语言)语言来编写的,并且RabbitMQ是基于AMQ ...
- rabbitmq多个消费者_为什么要选择RabbitMQ,RabbitMQ简介,各种MQ选型对比
MQ 是什么?队列是什么,MQ 我们可以理解为消息队列,队列我们可以理解为管道.以管道的方式做消息传递. 场景: 1.其实我们在双11的时候,当我们凌晨大量的秒杀和抢购商品,然后去结算的时候,就会发现 ...
- 《RabbitMQ 实战指南》第一章 RabbitMQ 简介
<RabbitMQ 实战指南>第一章 RabbitMQ 简介 文章目录 <RabbitMQ 实战指南>第一章 RabbitMQ 简介 一.什么是消息中间件 二.消息中间件的作用 ...
- RabbitMQ简介及其安装
一.简介 RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件). RabbitMQ服务器是用Erlang语言编写的. 二.工作过程 发布者(Publisher ...
- RabbitMQ简介以及AMQP协议
RabbitMQ能为你做些什么? 消息系统允许软件.应用相互连接和扩展.这些应用可以相互链接起来组成一个更大的应用,或者将用户设备和数据进行连接.消息系统通过将消息的发送和接收分离来实现应用程序的异步 ...
- rabbitmq简介及安装
概述 RabbitMQ是对高级消息队列协议(Advanced Message Queueing Protocol, AMQP)的实现,RabbitMQ是消息传输的中间者,可以把它当做是一个消息代理,你 ...
- RabbitMQ简介以及应用
一.简要介绍 开源AMQP实现,Erlang语言编写,支持多种客户端 分布式.高可用.持久化.可靠.安全 支持多种协议:AMQP.STOMP.MQTT.HTTP 适用于多系统之间的业务解耦的消息中间件 ...
- rabbitMq简介及docker安装
一.JMS协议和AMQP协议 关于JMS和AMQP的区别:主要是AMQP是协议,JMS是API而RabbitMQ 基于AMQP协议,erlang语言开发,是部署最广泛的开源消息中间件,是最受欢迎的开源 ...
最新文章
- 服务器最小化安装后的优化脚本
- 仿九天音乐图片切换技术[二],兼容ie,ff
- 《网络管理员考试案例导学》复习重点
- php多图片上传并压缩,PHP 上传图片并压缩方法详解
- mysql deadlock6_mysql deadlock、Lock wait timeout解决和分析
- [导入]2007年美国电影上映时间表
- python的smtplib
- 【渝粤题库】广东开放大学 质量管理 形成性考核
- Python函数总结大全(函数定义,参数种类、返回值等)
- 小猫咪,Naughty baby
- HTML5 页面布局【结合案例】
- mysql-mmm vip 切换问题_mysql-mmm复制延迟的想法
- 基于matlab的MIMO信道容量仿真
- 【分享】VMOS Pro1.4.2最新会员版
- php中如何获得当前周数,PHP中根据输入的周数获取到该周的日期范围
- 牛津词典 2018 年度词汇 ——「有毒」! 1
- linux关闭防火墙(临时/永久)
- C语言 输入n,输出n各位数字之和
- 物联网充电桩(电动自行车)管理方案
- 738. Monotone Increasing Digits