ANSI环境下支持多语言输入的单行文本编辑器 V0.01
File: SMLInput
Name: ANSI环境下支持多语言输入的单行文本编辑器
Author: zyl910
Blog: http://blog.csdn.net/zyl910/
Version: V0.1
Updata: 2006-6-23
下载(注意修改下载后的后缀名)
平时我们使用文本框控件的确很舒服,但有没有想过——一个这样简单的、常用的控件中有了多少技术。当你看到使用PhotoShop的文字工具时能直接在图片上输入文字、看到Word与微软拼音完美融合,你会不会妒忌。特别是IE浏览器中的文本框根本没使用系统的文本框控件,而是IE自己提供的,所以能使用CSS定制风格、能接收多国语言输入,极其羡慕啊。
这个程序是我的一个尝试,试图编写一个简单的支持多语言输入的单行文本编辑器。使用的开发工具是VC++6.0,MFC框架能减少许多枯燥的API调用。但即使是这样简单的要求,但我在写这个程序的时候仍然是困难重重。
不单单是技术上的难度,很大一部分原因是找不到资料。只有每天狂啃MSDN,自己慢慢摸索。我在这段时间,平均每两天新建一个工程,将代码重写一编。
到了6月23号,发现很难实现双向文本情况下插入符的定位,所以把该版本定义为0.1版,暂时歇一歇。
现在该程序支持WindowsXP带的绝大多数输入法(英、德、法、俄、希腊文、希伯来文、阿拉伯文、简体中文、繁体中文、日文、韩文、越南文、泰文……),唯一不支持梵文。后来仔细观察,ANSI环境下是无法支持梵文的,连RichEdit都不支持呢。
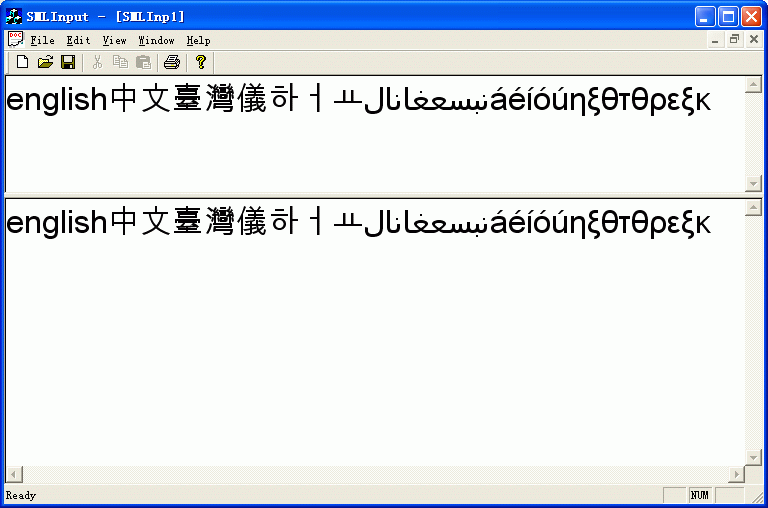
技术要点
~~~~~~~~
零、Windows9X下能使用的Unicode函数
Windows9X下能使用的Unicode版函数有:
字符串处理:
lstrlen
lstrcat
lstrcpy
字体/文字:
GetCharWidth
GetTextExtentExPoint
GetTextExtentPoint32
GetTextExtentPoint
TextOut
ExtTextOut
资源:
EnumResourceLanguages
EnumResourceNames
EnumResourceTypes
FindResource
FindResourceEx
进程:
GetCommandLine
用户界面:
MessageBox
MessageBoxEx
还有这两个,专门作编码转换的(所以只有一种,不分ANSI、Unicode,所有Win32平台都支持):
MultiByteToWideChar
WideCharToMultiByte
在Windows 98中,可以使用(除ImmIsUIMessage以外的)Unicode版的IMM函数。我们可以先调用ImmGetProperty取得输入法属性,根据它是否带有IME_PROP_UNICODE标志以调用不同的函数。
一、文本数据管理
作为一个文本编辑器,最基础的就是对输入的文本数据进行管理。
由于现在是做支持多语言的文本编辑器,所以应该使用Unicode字符串。在Windows平台,使用UTF-16字符串是最方便的,它就是wchat_t数据类型。
由于这是一个单行文本编辑器,所以只用一个字符数组就行了。
由于现在是做文本数据管理,所以应该由文档类负责。
最好不要让外部直接访问类中的变量,而应该定义一些操作函数来实现数据操作。我尝试是很久,最后发现只需提供一个最基础setSubstr函数就能实现任意文本修改需求。
在SMLInputDoc.h中添加以下声明:
class CSMLInputDoc : public CDocument
{
……
// Attributes
enum{
MAXTEXTLINE = 0x1000, // 4KB
};
wchar_t m_Text[MAXTEXTLINE];
int m_TextLen;
……
};
然后在SMLInputDoc.cpp中编写实现代码:
// 替换部分文本。基于字符数组。注意该函数不会修改文本选区,需手动计算
//Return: 复制的字符单元数。
//iChgBegin:选区开始
//iChgEnd: 选区结束
//lpstr: 字符串数据。
//cchstr: 字符串数据的字符单元数,不包括'/0'。<=0时该函数返回0。
int CSMLInputDoc::setSubstr(int iChgBegin, int iChgEnd, LPWSTR lpstr, int cchstr)
{
int iChgMin;
int iChgMax;
int cchChg;
int iStart;
int iLen;
// check string
if (cchstr < 0) return 0;
if (lpstr == NULL) {
if (cchstr > 0) return 0;
}
// check min/max
ASSERT(iChgBegin >= 0);
ASSERT(iChgBegin <= m_TextLen);
ASSERT(iChgEnd >= 0);
ASSERT(iChgEnd <= m_TextLen);
// conv to [min, max)
if (iChgBegin <= iChgEnd){
iChgMin = iChgBegin;
iChgMax = iChgEnd;
}else{
iChgMin = iChgEnd;
iChgMax = iChgBegin;
}
cchChg = iChgMax - iChgMin;
// 输入文本的最大长度为剩余空间大小
iLen = MAXTEXTLINE - (m_TextLen - cchChg);
if (cchstr > iLen) cchstr = iLen;
// 需要复制数据
if (cchstr != cchChg){
// 将选取范围的文本移动到后面去
iStart = iChgMin + cchstr;
iLen = m_TextLen - iChgMax;
if (iLen > 0) {
MoveMemory(m_Text+iStart, m_Text+iChgMax, iLen * sizeof(m_Text[0]));
}
m_TextLen = iStart + iLen;
}
if (cchstr > 0) {
// 插入lpstr
CopyMemory(m_Text+iChgMin, lpstr, cchstr * sizeof(m_Text[0]));
}
// Notify
if ((cchstr > 0) || (cchstr != cchChg)) {
CNotifyChgSubstr in;
in.m_iChgMin = iChgMin;
in.m_iChgMax = iChgMax;
in.m_cchStr = cchstr;
UpdateAllViews(NULL, 0, &in);
}
return cchstr;
}
注意在文本被修改后调用了UpdateAllViews函数去通知视图窗口刷新,并将详细的被修改信息通过CNotifyChgSubstr类传递给视图窗口。这不单单是为了处理刷新问题,而是为了以后实现“每个视图拥有自己文本选区”做准备。
二、文本选区的处理
既然MFC支持窗口拆分,那么得支持“一个文档有多个视图”这种情况。
很多支持拆分窗口文本编辑器都是“每个视图拥有自己文本选区”,所以文本选区处理代码应该放在视图类中。
平时在文本框控件时,它放回选区信息是“最小值-最大值”。而实际的文本选取不是那个样子的:
1.先按下Shift键,开始文本选取。假设现在的位置是i。
2.按方向键“右”,插入符会跟着文本选区右移。假设插入符位置是j,那么文本选区是 [i,j) 这个区间。
3.按方向键“右”,插入符会跟着文本选区右移。可以一直移动到i的左边去,此时文本选区是 [j,i) 这个区间。
也就是说,i是选区开始位置,j是当前插入符位置。
在SMLInputView.h添加以下申明:
class CSMLInputView : public CScrollView
{
……
// Attributes
public:
// 选取范围是半闭半开区间——“[iSelBegin,iSelEnd)”。其实刚才的描述并不准确,这是因为iSelEnd允许在iSelBegin前面。
int m_iSelBegin; // 开始选取时的位置
int m_iSelEnd; // 当前光标位置
// Operations
public:
int setSelText(LPWSTR lpstr);
int setSelTextN(LPWSTR lpstr, int cchstr);
……
};
然后在SMLInputView.cpp中编写实现代码:
/
// Text function
// 设置被选择的文本。基于'/0'终止字符串
//Return: 复制的字符单元数。
//lpstr: 字符串数据。
int CSMLInputView::setSelText(LPWSTR lpstr)
{
int cchstr;
if (lpstr != NULL) {
cchstr = wcslen(lpstr);
}
else {
cchstr = 0;
}
setSelTextN(lpstr, cchstr);
return 0;
}
// 设置被选择的文本。基于字符数组
//Return: 复制的字符单元数。
//lpstr: 字符串数据。
//cchstr: 字符串数据的字符单元数,不包括/0。<=0时该函数返回0。
int CSMLInputView::setSelTextN(LPWSTR lpstr, int cchstr)
{
CSMLInputDoc* pDoc = GetDocument();
ASSERT_VALID(pDoc);
// check string
if (cchstr < 0) return 0;
if (lpstr == NULL) {
if (cchstr > 0) return 0;
}
// check min/max
ASSERT(m_iSelBegin >= 0);
ASSERT(m_iSelBegin <= pDoc->m_TextLen);
ASSERT(m_iSelEnd >= 0);
ASSERT(m_iSelEnd <= pDoc->m_TextLen);
// set sub string
cchstr = pDoc->setSubstr(m_iSelBegin, m_iSelEnd, lpstr, cchstr);
return cchstr;
}
三、WM_CHAR消息处理
WM_CHAR消息的参数很简单,wParam是字符编码数据,lParam是按键信息。但实际处理起来非常麻烦。
Unicode窗口是最简单的,因为此时WM_CHAR消息的wParam参数是该字符的Unicode编码,不需要特殊处理。而且我们还可以考虑代理对(Surrogates)问题,将U+10000到U+10FFFF范围内的字符转为两个UTF-16编码单元。就算Windows系统对于代理对是分成两个WM_CHAR消息的,但是由于我们用的就是UTF-16编码方式,并不会出问题。
对于ANSI窗口就复杂了,因为此时WM_CHAR消息的wParam参数是一个字节的数据,而且具体使用那种文本编码也耐人寻味(具体情形会在下一节详细解说)。我们现在可认为那个字节使用的是该键盘布局对应的代码页,具体情形可以看Charles Petzold《Windows程序设计》中“6. 键盘”的“键盘消息和字符集”。
那我们如何得知该键盘布局所对应的代码页呢?
当切换键盘布局时,窗口会接收到WM_INPUTLANGCHANGE,wParam参数是所使用的字符集,lParam参数是该键盘布局的HKL。为什么会给出字符集呢,这是为了方便编写ANSI文本编辑器:由于此时我们是自己编写文本编辑器,不使用 USER API,而是直接用 GDI API 来绘制文本,此时只需根据字符集创建字体就可使用(ANSI版)TextOut等函数来绘制该国文字。打住打住。我们现在内部使用的Unicode字符串,不能再调用ANSI版函数,所以必须得将输入内容转为Unicode。
既然知道了字符集,我们可以调用TranslateCharsetInfo得到该字符集的信息,函数传回的CHARSETINFO结构体的ciACP成员就是该字符集对应的代码页。除了这种方法以外,还有其他办法,比如根据HKL的低16位是语言标识符:用TranslateCharsetInfo转换嘛,可惜只能用于Windows 2000+;用GetLocaleInfo取得地区信息嘛,不太明白LOCALE_IDEFAULTCODEPAGE、LOCALE_IDEFAULTANSICODEPAGE、LOCALE_IDEFAULTMACCODEPAGE有什么区别。
然后现在又要面对对一个难题——半个汉字问题。注意wParam参数只传来一个字节的数据,而像简体中文gbk这样的编码是用两个字节来表示一个字符的。当进行编码转换时,1个字节肯定会转换失败。所以必须用一个缓冲区存放输入的内容,然后在每次向缓冲区添加字节时尝试编码转换。
这个缓冲区应该多大呢?自从GB18030-2000横空出世,采用四字节编码,所以我们不能再简单假设只有两个字节那种情况了。还有UTF-8是使用1到6字节变长编码,有可能某些编码会吸收该思想而定义变态的编码规则。所以,我最终决定使用一个32字节的缓冲区,应该不可能出现超过16字节的字符编码吧(2^8^16 = 2^128 ≈ 10^38,能为这个宇宙中每个原子编号了,够用了吧!)。
还要考虑容错性问题:万一正在处理WM_CHAR消息序列时,有人SendMessage发来WM_CHAR消息怎么办?由于存在非法字节,所以永远无法成功转换,然后缓冲区会溢出,造成不可预知的结果。我们可以使用CharNextExA来检查缓冲区中有多少个字符,如果有多个字符,我们就将前面那几个字符强制转换编码,再对最后那个字符尝试编码转换。
在SMLInputView.h添加以下申明:
class CSMLInputView : public CScrollView
{
……
// ANSI string buffer
protected:
HKL m_hkl;
DWORD m_ImeProp;
CHARSETINFO m_csInfo;
UINT m_CurCP;
#ifdef UNICODE
#else
enum{
MAXANSIBUF = 0x20 // 32
};
char m_asbText[MAXANSIBUF];
int m_asbTextLen;
BOOL asbAddByte(BYTE by);
BOOL asbSubmit(void);
BOOL asbClear(void);
#endif
// Overrides
virtual LRESULT WindowProc( UINT message, WPARAM wParam, LPARAM lParam );
// Generated message map functions
protected:
//{{AFX_MSG(CSMLInputView)
afx_msg void OnChar(UINT nChar, UINT nRepCnt, UINT nFlags);
//}}AFX_MSG
DECLARE_MESSAGE_MAP()
……
};
然后在SMLInputView.cpp中编写实现代码:
/
// ANSI string buffer function
#ifdef UNICODE
#else
// 添加一个字节
//Return: 是否提交了字符。
BOOL CSMLInputView::asbAddByte(BYTE by)
{
// 添加该字节
m_asbText[m_asbTextLen++] = by;
if (m_asbTextLen == MAXANSIBUF){ // 如果缓冲区满只有提交
return asbSubmit();
}else{
// '/0'字符串终结符
m_asbText[m_asbTextLen] = '/0';
}
wchar_t wsBuf[MAXANSIBUF];
int cchBuf;
char* p0;
char* p1;
char* pMax;
// 分析缓冲区中有多少字符
p0 = p1 = m_asbText;
pMax = m_asbText + m_asbTextLen;
while(1){
p1 = CharNextExA(m_CurCP, p0, 0);
if((*p1 == '/0')||(p1 >= pMax)||(p1 == p0)||(p1==NULL)) break;
}
// 提交前面的字符
if(p0 != m_asbText){
// 转为Unicode
cchBuf = MultiByteToWideChar(m_CurCP, 0, m_asbText, p0 - m_asbText, wsBuf, MAXANSIBUF);
// 提交字符串
setSelTextN(wsBuf, cchBuf);
}
// 尝试转换最后一个字符
cchBuf = MultiByteToWideChar(m_CurCP, MB_ERR_INVALID_CHARS, p0, p1 - p0, wsBuf, MAXANSIBUF);
if(cchBuf > 0){ // 转换成功
// 提交该字符
setSelTextN(wsBuf, cchBuf);
// 清空缓冲区
asbClear();
}else{ // 转换失败
// 由于前面的数据已提交,所以将最后那些字节移动到前面来
m_asbTextLen = p1 - p0;
MoveMemory(m_asbText, p0, m_asbTextLen);
m_asbText[m_asbTextLen] = '/0';
}
return (cchBuf > 0)||(p0 != m_asbText);
}
// 提交数据
//Return: 有数据就提交,返回非0;否则返回0
BOOL CSMLInputView::asbSubmit(void)
{
wchar_t wsBuf[MAXANSIBUF];
int cchBuf;
if (0==m_asbTextLen) return FALSE;
// 转为Unicode
cchBuf = MultiByteToWideChar(m_CurCP, 0, m_asbText, m_asbTextLen, wsBuf, MAXANSIBUF);
// 提交字符串
setSelTextN(wsBuf, cchBuf);
// 清空缓冲区
asbClear();
return TRUE;
}
// 清空数据
//Return: 有数据就清空,返回非0;否则返回0
BOOL CSMLInputView::asbClear(void)
{
if (0==m_asbTextLen) return FALSE;
m_asbTextLen = 0;
ZeroMemory(m_asbText, sizeof(m_asbText));
return TRUE;
}
#endif
/
// CSMLInputView message handlers
void CSMLInputView::OnChar(UINT nChar, UINT nRepCnt, UINT nFlags)
{
// TODO: Add your message handler code here and/or call default
if (nChar == VK_BACK) {
// Backspace(退格键)
doBackspace();
}
else {
// 文本字符数据
#ifdef UNICODE
wchar_t chBuf[2];
if ((nChar >= SurrogateMin)&&(nChar <= SurrogateMax)) {
// Surrogates(代理对)
UINT uCode = nChar - SurrogateMin;
chBuf[0] = SurrogateBaseHigh | ((uCode >> SurrogateBitCount) & SurrogateBitMask);
chBuf[1] = SurrogateBaseLow | (uCode & SurrogateBitMask);
setSelTextN(chBuf, 2);
}
else {
chBuf[0] = (WORD)nChar;
setSelTextN(chBuf, 1);
}
#else
asbAddByte((BYTE)nChar);
#endif
}
CScrollView::OnChar(nChar, nRepCnt, nFlags);
}
LRESULT CSMLInputView::WindowProc( UINT message, WPARAM wParam, LPARAM lParam )
{
switch(message)
{
case WM_INPUTLANGCHANGE:
//TRACE("WM_INPUTLANGCHANGE/n");
{
// IME info
m_hkl = (HKL)lParam;
m_ImeProp = ImmGetProperty(m_hkl, IGP_PROPERTY);
#ifdef UNICODE
m_ImeProp = m_ImeProp | IME_PROP_UNICODE;
#endif
// Charset info
TranslateCharsetInfo((DWORD*)wParam, &m_csInfo, TCI_SRCCHARSET);
m_CurCP = m_csInfo.ciACP;
//TRACE("CP: %d/n", m_CurCP);
// 已经切换了输入法。与原来的数据再无关系
asbSubmit();
}
break;
……
}
return CView::WindowProc(message, wParam, lParam);
}
四、处理输入法输入
运行程序,你会发现能正常输入简体中文与其他许多语言,我测试过:英、德、法、俄、希腊文、希伯来文、阿拉伯文、越南文、泰文。可是其他带输入法的语言得到的是乱码,如繁体中文、日文、韩文。不会吧,连繁体中文都无法输入?!于是我用Spy++仔细观察使用输入法输入时的消息。
当确认输入时,IMM会向窗口发送WM_IME_COMPOSITION消息并使用GCS_RESULTSTR参数来通知该窗口。
一般程序没有处理WM_IME_COMPOSITION消息,所以最终该消息会交给DefWindowProc来处理。当DefWindowProc收到WM_IME_COMPOSITION消息时,它会使用ImmGetCompositionString函数来取得字符串(ANSI窗口用ImmGetCompositionStringA、Unicode窗口用ImmGetCompositionStringW)。得到字符串数据后,DefWindowProc会将字符串的各个字符拆开,逐个字符逐个字符地向自身窗口发送WM_IME_CHAR消息(ANSI窗口发送的是该字符的DBCS编码数据,Unicode窗口发送的是Unicode编码数据)。
一般程序没有处理WM_IME_CHAR消息,所以最终该消息会交给DefWindowProc来处理。当DefWindowProc收到WM_IME_CHAR消息时,它会将字符数据分解为多个byte(ANSI)或多个word(Unicode),然后将这些数据用WM_CHAR消息的方式投递到自身窗口。
问题就出在这里!ImmGetCompositionString是user函数,所使用的代码页是ACP(当前系统代码页)。而我们程序以为WM_CHAR中的字符编码数据是使用HKL对应代码页的,这就造成了转换失败。
我们得自己处理ImmGetCompositionString消息来获得输入法输入的内容。
然后在SMLInputView.cpp的WindowProc改成这个样子:
LRESULT CSMLInputView::WindowProc( UINT message, WPARAM wParam, LPARAM lParam )
{
switch(message)
{
case WM_INPUTLANGCHANGE:
//TRACE("WM_INPUTLANGCHANGE/n");
{
// IME info
m_hkl = (HKL)lParam;
m_ImeProp = ImmGetProperty(m_hkl, IGP_PROPERTY);
#ifdef UNICODE
m_ImeProp = m_ImeProp | IME_PROP_UNICODE;
#endif
// Charset info
TranslateCharsetInfo((DWORD*)wParam, &m_csInfo, TCI_SRCCHARSET);
m_CurCP = m_csInfo.ciACP;
//TRACE("CP: %d/n", m_CurCP);
// 已经切换了输入法。与原来的数据再无关系
asbSubmit();
}
break;
case WM_IME_COMPOSITION:
if (lParam & GCS_RESULTSTR) {
HIMC hIMC;
LPBYTE lpBuf = NULL;
LONG cchBuf = 0;
hIMC = ImmGetContext(this->GetSafeHwnd());
if (hIMC != NULL) {
if (m_ImeProp & IME_PROP_UNICODE) {
// 取得文本数据
cchBuf = ImmGetCompositionStringW(hIMC, GCS_RESULTSTR, NULL, 0);
if (cchBuf > 0) {
lpBuf = (LPBYTE)malloc(cchBuf);
if (lpBuf != NULL) {
cchBuf = ImmGetCompositionStringW(hIMC, GCS_RESULTSTR, lpBuf, cchBuf);
cchBuf = cchBuf / sizeof(wchar_t);
}
else {
cchBuf = 0;
}
}
}
else {
LPBYTE lpStr = NULL;
LONG cchStr = 0;
// 取得文本数据
cchStr = ImmGetCompositionStringA(hIMC, GCS_RESULTSTR, NULL, 0);
if (cchStr > 0) {
lpStr = (LPBYTE)malloc(cchStr);
if (lpStr != NULL) {
cchStr = ImmGetCompositionStringA(hIMC, GCS_RESULTSTR, lpStr, cchStr);
}
else {
cchStr = 0;
}
}
// 转成Unicode
if (cchStr > 0) {
cchBuf = MultiByteToWideChar(CP_ACP, 0, (LPSTR)lpStr, cchStr, NULL, 0);
if (cchBuf>0) {
lpBuf = (LPBYTE)malloc(cchBuf * sizeof(wchar_t));
if (lpStr != NULL) {
cchBuf = MultiByteToWideChar(CP_ACP, 0, (LPSTR)lpStr, cchStr, (LPWSTR)lpBuf, cchBuf);
}
else {
cchBuf = 0;
}
}
}
// 释放
if (lpStr != NULL) free(lpStr);
}
ImmReleaseContext(this->GetSafeHwnd(), hIMC);
}
if (cchBuf > 0) {
setSelTextN((LPWSTR)lpBuf, cchBuf);
}
if (lpBuf != NULL) free(lpBuf);
if (cchBuf > 0) {
return 0;
}
}
break;
}
return CView::WindowProc(message, wParam, lParam);
}
有没有注意调用了ImmGetProperty函数,可通过检查IME_PROP_UNICODE标志来判断该输入是否支持Unicode。如果该输入法支持Unicode,我们可直接调用Unicode版IMM函数,还记得Windows98支持Unicode版IMM函数吗。
五、处理插入符
作为文本编辑器,最典型特征是输入时有个光标在闪来闪去,那就是插入符(Carets)。SDK中有插入符函数,MFC将它封转到CWnd类中,就是CreateCaret、SetCaretPos等函数。具体用法在很多书上讲过,如Charles Petzold的《Windows程序设计》。按道理,实现插入符并不困难,但我为什么没继续动了呢?
这是因为我们这是支持多语言的文本编辑器,输入内容中有常规的从左到右书写的文本,还有像阿拉伯文那样的从右往左书写的文本,这给插入符定位带来了极大的复杂性。
你可以试试:安装阿拉伯人输入,并在记事本中乱按,并使用Unicode字体,你会发现插入符一直停留在最左边。此时按方向健“右”,没反应。按方向健“左”,居然插入符向右移动一个字符了。原来方向反了。不不不!这个结论下得太早了,右击鼠标弹出快捷菜单,选上“从右到左的阅读顺序(R)”,此时方向键貌似正常了。这还不算什么,当你混合使用不同的输入法时,经常会发现插入符不可思议的行进。当軭选文本时,会发现文本选区存在断开。这还要人活吗(现在知道文本框控件有多么伟大了吧)!
其实这不是无法解决的,有三种方案可供选择,但都不太现实:
1.传统做法是使用GetCharacterPlacement得到各个字符的位置。可Windows9X不支持GetCharacterPlacementW。
2.理论上应该使用专业的Uniscribe来处理文本排版。但是只有Windows 2000+、IE 5.0+提供Uniscribe。
3.自己写嘛——不懂双向文本排版算法,文本与字体排版属性那些底层API不知道怎么用。
六、与输入法窗口融合
在使用输入法输入时,你会发现输入法的组字窗口、候选窗口并不在插入符附近。特别是微软拼音,居然停在屏幕左上角。怎么实现与输入法窗口融合呢?
其实IMM造就提供了ImmSetCandidateWindow、ImmSetCompositionFont、ImmSetCompositionWindow、ImmSetStatusWindowPos这些函数让用户自定义输入法外观,详细代码可以看MSDN示例HalfIME。
甚至你可以自定义输入法窗口,自己绘制输入法窗口能实现许多界面效果。这被称为完整的IME支持,Word就是这样做出来的。详细代码可以看MSDN示例FullIME。
转载于:https://www.cnblogs.com/zyl910/archive/2006/06/26/2186641.html
ANSI环境下支持多语言输入的单行文本编辑器 V0.01相关推荐
- vivado环境下用Verilog语言实现编码器
** vivado环境下用Verilog语言实现编码器 ** 编码器的分类 编码器通常分为两大类: 普通编码器和优先编码器. 其中,普通编码器对某一个给定时刻只能对一个输入信号进行编码的编码器, 它的 ...
- iar环境下c语言编程,STM8在IAR环境下的C语言开发.doc
STM8在IAR环境下的C语言开发 STM8单片机在IAR环境下的C语言开发 头文件搜索路径设置 在工程管理窗口按右键,选择option,打开选项设置窗口如下 选择C/C++ compiler选项,然 ...
- Windows环境下安装Go语言
Windows环境下安装Go语言 下载 打开Go语言中文网下载页面:https://studygolang.com/dl 按照对应平台选择下载:https://studygolang.com/dl/g ...
- 解决Windows环境下Git Bash 不能输入中文的问题
解决Windows环境下Git Bash 不能输入中文的问题 打开Git Bash后,对窗口右键->Options->Text->Locale改为zh_CN,Character se ...
- 基于Windows环境下cmd/编译器无法输入中文,显示中文乱码解决方案
基于Windows环境下cmd/编译器无法输入中文,显示中文乱码解决方案 参考文章: (1)基于Windows环境下cmd/编译器无法输入中文,显示中文乱码解决方案 (2)https://www.cn ...
- r语言在linux怎么实现,如何在linux环境下使用r语言
如何在linux环境下使用r语言 真朱丶379 | 浏览 1974 次 发布于2015-12-23 13:05 最佳答案 1.下载 wget http://mirror.bjtu.edu.cn/cra ...
- fedora16英文环境下支持中文输入法
fedora16英文环境下支持FCITX的中文输入法: $ im-chooser 就会出现选择界面,选择第二个就行了.
- 在Linux环境下用C语言编写一个乘法程序mult,从命令行接收两个数字,然后输出其乘积;再用C语言编写一个exec1程序,在程序中使用execvp调用mult程序计算5与10的乘积。
在Linux环境下用C语言编写一个乘法程序mult,从命令行接收两个数字,然后输出其乘积:再用C语言编写一个exec1程序,在程序中使用execvp调用mult程序计算5与10的乘积. 1.mult. ...
- Jupyter环境下运行R语言、Java
文章目录 Jupyter环境下运行R语言 Jupyter环境下运行Java 在mac系统验证运行有效. Jupyter环境下运行R语言 下载好R语言.安装好Anaconda 在R(不要用Rstudio ...
最新文章
- html5 data url,HTML5 / Javascript – DataURL到Blob和Blob到DataURL
- RID枚举工具RidEnum
- [云炬创业学笔记]第一章创业是什么测试1
- AAAI 2022 | 基于强化学习的视频弹幕攻击
- 禁止微信内置浏览器调整字体大小
- Linux 下查看系统是32位 还是64 位的方法
- java web登录action_JavaWeb中登陆功能
- 调用API发送短信python
- 148. Sort List 1
- 4种方法帮你解决IntelliJ IDEA控制台中文乱码问题
- mysql主从io为no_mysql主从同步错误解决和Slave_IO_Running: NO
- Java中 intValue,parseInt,Valueof 这三个关键字的区别
- 快速集成华为AGC-AppLinking服务-Cocos平台
- 爬取某视频网站电影,仅参考学习
- 联想服务器怎么使用uefi启动不了系统,联想小新如何用uefi启动在win10下装win7系统...
- github push 出错:fatal: Authentication failed for 'https://github.com/ ..的解决
- 银行打来的电话可以不接吗?有一类人必须接听
- vue中$emit跟$on,$off跟用法
- 通过commons-email-1.5简单实现邮件发送
- windows强制关闭Tomcat