基于RNN循环神经网络lstm的藏头诗制作
基于RNN循环神经网络lstm的藏头诗制作
简单介绍
在一次偶然中接触到藏头诗,觉得十分有意思。但是好像都是利用古代本就有的诗句重新组合而成。比如输入清风袭来,结果如下图所示。

之后想到不如利用深度学习制作一个藏头诗,发现github上有学者已经制作了唐诗生成的相关代码。
完整代码地址https://github.com/jinfagang/tensorflow_poems
在此基础上,我对代码进行稍微修改,并进行了注释,希望能帮到对此方面有需求的同学。
模型model.py
import tensorflow as tf
import numpy as npdef rnn_model(model, input_data, output_data, vocab_size, rnn_size=128, num_layers=2, batch_size=64,learning_rate=0.01):"""construct rnn seq2seq model.:param model: model class:param input_data: input data placeholder:param output_data: output data placeholder:param vocab_size::param rnn_size::param num_layers::param batch_size::param learning_rate::return:"""end_points = {}#可以选择rnn的模型if model == 'rnn':cell_fun = tf.contrib.rnn.BasicRNNCellelif model == 'gru':cell_fun = tf.contrib.rnn.GRUCellelif model == 'lstm':cell_fun = tf.contrib.rnn.BasicLSTMCellcell = cell_fun(rnn_size, state_is_tuple=True)cell = tf.contrib.rnn.MultiRNNCell([cell] * num_layers, state_is_tuple=True)if output_data is not None:initial_state = cell.zero_state(batch_size, tf.float32)else:initial_state = cell.zero_state(1, tf.float32)with tf.device("/cpu:0"):#此处选择用cpuembedding = tf.get_variable('embedding', initializer=tf.random_uniform([vocab_size + 1, rnn_size], -1.0, 1.0))inputs = tf.nn.embedding_lookup(embedding, input_data)# [batch_size, ?, rnn_size] = [64, ?, 128]outputs, last_state = tf.nn.dynamic_rnn(cell, inputs, initial_state=initial_state)output = tf.reshape(outputs, [-1, rnn_size])weights = tf.Variable(tf.truncated_normal([rnn_size, vocab_size + 1]))bias = tf.Variable(tf.zeros(shape=[vocab_size + 1]))logits = tf.nn.bias_add(tf.matmul(output, weights), bias=bias)# [?, vocab_size+1]if output_data is not None:# output_data must be one-hot encodelabels = tf.one_hot(tf.reshape(output_data, [-1]), depth=vocab_size + 1)# should be [?, vocab_size+1]loss = tf.nn.softmax_cross_entropy_with_logits(labels=labels, logits=logits)# loss shape should be [?, vocab_size+1]total_loss = tf.reduce_mean(loss)train_op = tf.train.AdamOptimizer(learning_rate).minimize(total_loss)end_points['initial_state'] = initial_stateend_points['output'] = outputend_points['train_op'] = train_opend_points['total_loss'] = total_lossend_points['loss'] = lossend_points['last_state'] = last_stateelse:prediction = tf.nn.softmax(logits)end_points['initial_state'] = initial_stateend_points['last_state'] = last_stateend_points['prediction'] = predictionreturn end_points
文本处理 poems.py
import collections
import numpy as npstart_token = 'B'
end_token = 'E'def process_poems(file_name):# poems -> list of numberspoems = []with open(file_name, "r", encoding='utf-8', ) as f:for line in f.readlines():try:title, content = line.strip().split(':')#每一行以:分割,分别赋予title,contentcontent = content.replace(' ', '') #对content处理,以,分割if '_' in content or '(' in content or '(' in content or '《' in content or '[' in content or \start_token in content or end_token in content:#去除乱码错误的诗句,以及字数过长或过短的诗句continueif len(content) < 5 or len(content) > 79:continuecontent = start_token + content + end_token#形成B content E的形式poems.append(content)except ValueError as e:pass# poems = sorted(poems, key=len)all_words = [word for poem in poems for word in poem]counter = collections.Counter(all_words)words = sorted(counter.keys(), key=lambda x: counter[x], reverse=True) #按每一个词出现的频率排序(正序)words.append(' ')#末尾加上空格L = len(words)word_int_map = dict(zip(words, range(L)))#制作字典,每一个字都对应一个数字,频率越高的汉字ID数字越小poems_vector = [list(map(lambda word: word_int_map.get(word, L), poem)) for poem in poems]#遍历所有诗句将其转换成数字数组return poems_vector, word_int_map, wordsdef generate_batch(batch_size, poems_vec, word_to_int):n_chunk = len(poems_vec) // batch_sizex_batches = []y_batches = []for i in range(n_chunk):start_index = i * batch_sizeend_index = start_index + batch_sizebatches = poems_vec[start_index:end_index]length = max(map(len, batches))#取第一个batch中最大诗句的长度x_data = np.full((batch_size, length), word_to_int[' '], np.int32)#把第一个batch的所有诗句都转换成数字存储到x_data中for row, batch in enumerate(batches):x_data[row, :len(batch)] = batch#print(x_data.ndim)y_data = np.copy(x_data)y_data[:, :-1] = x_data[:, 1:]#将y_data向左移一位"""x_data y_data[6,2,4,6,9] [2,4,6,9,9][1,4,2,8,5] [4,2,8,5,5]"""x_batches.append(x_data)#将每个batch存入x_batch,y_batch中y_batches.append(y_data)return x_batches, y_batches
训练 train.py
import os
import tensorflow as tf
from poems.model import rnn_model
from poems.poems import process_poems, generate_batchtf.app.flags.DEFINE_integer('batch_size', 64, 'batch size.')
tf.app.flags.DEFINE_float('learning_rate', 0.01, 'learning rate.')
tf.app.flags.DEFINE_string('model_dir', os.path.abspath('./model'), 'model save path.')
tf.app.flags.DEFINE_string('file_path', os.path.abspath('./data/qijue-all.txt'), 'file name of poems.')
tf.app.flags.DEFINE_string('model_prefix', 'poems', 'model save prefix.')
tf.app.flags.DEFINE_integer('epochs', 50, 'train how many epochs.')FLAGS = tf.app.flags.FLAGSdef run_training():if not os.path.exists(FLAGS.model_dir):os.makedirs(FLAGS.model_dir)poems_vector, word_to_int, vocabularies = process_poems(FLAGS.file_path)batches_inputs, batches_outputs = generate_batch(FLAGS.batch_size, poems_vector, word_to_int)input_data = tf.placeholder(tf.int32, [FLAGS.batch_size, None])output_targets = tf.placeholder(tf.int32, [FLAGS.batch_size, None])end_points = rnn_model(model='lstm', input_data=input_data, output_data=output_targets, vocab_size=len(vocabularies), rnn_size=128, num_layers=2, batch_size=64, learning_rate=FLAGS.learning_rate)saver = tf.train.Saver(tf.global_variables())init_op = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer())with tf.Session() as sess:# sess = tf_debug.LocalCLIDebugWrapperSession(sess=sess)# sess.add_tensor_filter("has_inf_or_nan", tf_debug.has_inf_or_nan)sess.run(init_op)start_epoch = 0checkpoint = tf.train.latest_checkpoint(FLAGS.model_dir)if checkpoint:saver.restore(sess, checkpoint)print("## restore from the checkpoint {0}".format(checkpoint))start_epoch += int(checkpoint.split('-')[-1])print('## start training...')try:n_chunk = len(poems_vector) // FLAGS.batch_sizefor epoch in range(start_epoch, FLAGS.epochs):n = 0for batch in range(n_chunk):loss, _, _ = sess.run([end_points['total_loss'],end_points['last_state'],end_points['train_op']], feed_dict={input_data: batches_inputs[n], output_targets: batches_outputs[n]})n += 1print('Epoch: %d, batch: %d, training loss: %.6f' % (epoch, batch, loss))#每100步储存loss和batchif batch % 100 == 0:f = open('/users/damon/desktop/tensorflow_poems-master/txt/data100.txt', 'a')f.write(str(epoch) + ',' + str(batch) + ',' + str(loss) + '\n')f.close()#每6割epoch保存一次if epoch % 6 == 0:saver.save(sess, os.path.join(FLAGS.model_dir, FLAGS.model_prefix), global_step=epoch)except KeyboardInterrupt:#人员退出自动保存checkpoint,下次打开可从上次继续训练print('## Interrupt manually, try saving checkpoint for now...')saver.save(sess, os.path.join(FLAGS.model_dir, FLAGS.model_prefix), global_step=epoch)print('## Last epoch were saved, next time will start from epoch {}.'.format(epoch))def main(_):run_training()if __name__ == '__main__':tf.app.run()
藏头诗生成 compose_poems.py
import tensorflow as tf
from poems.model import rnn_model
from poems.poems import process_poems
import numpy as npstart_token = 'B'
end_token = 'E'
model_dir = './model/'
corpus_file = './data/qijue-all.txt'lr = 0.0002def to_word(predict, vocabs): #预测产生一个汉字predict = predict[0]predict /= np.sum(predict)sample = np.random.choice(np.arange(len(predict)), p=predict)#每一个字被选中的概率是predict,选一次if sample > len(vocabs):return vocabs[-1]else:#print(vocabs[sample])return vocabs[sample]def gen_poem(begin_word):batch_size = 1print('## loading corpus from %s' % model_dir)poems_vector, word_int_map, vocabularies = process_poems(corpus_file)input_data = tf.placeholder(tf.int32, [batch_size, None])end_points = rnn_model(model='lstm', input_data=input_data, output_data=None, vocab_size=len(vocabularies), rnn_size=128, num_layers=2, batch_size=64, learning_rate=lr)saver = tf.train.Saver(tf.global_variables())init_op = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer())with tf.Session() as sess:sess.run(init_op)checkpoint = tf.train.latest_checkpoint(model_dir)saver.restore(sess, checkpoint)#x = np.array([list(map(word_int_map.get, start_token))])#[predict, last_state] = sess.run([end_points['prediction'], end_points['last_state']],#feed_dict={input_data: x})#word = begin_word or to_word(predict, vocabularies)poem_ = ''for j in range(len(begin_word)):word=begin_word[j]while word != end_token:poem1 = ''x = np.array([list(map(word_int_map.get, start_token))])[predict, last_state] = sess.run([end_points['prediction'], end_points['last_state']],feed_dict={input_data: x})while len(poem1) < 18:poem1 += word# poem_ += word#i += 1if word == ',':#保证一行诗句中不会出现多个逗号if len(poem1)>9:poem1 = begin_word[j]word = begin_word[j]if word == '。':#保证诗句不会过短if len(poem1) >10:breakelse:poem1 = begin_word[j]word = begin_word[j]x = np.zeros((1, 1))x[0, 0] = word_int_map[word]x = np.array([[word_int_map[word]]])[predict, last_state] = sess.run([end_points['prediction'], end_points['last_state']],feed_dict={input_data: x, end_points['initial_state']: last_state})word = to_word(predict, vocabularies)#预测下一个字poem_ += poem1breakreturn poem_#输出生成的藏头诗
def pretty_print_poem(poem_):poem_sentences = poem_.split('。')k = 0for s in poem_sentences:if s != '' and len(s) > 10:#去除诗句过短if k > len(begin_char)-1:breakif s[0] ==begin_char[k]:#保证诗句第一个字必须是用户输入的汉字print(s + '。')k +=1if __name__ == '__main__':begin_char = input('## please input the characters you want to compose:')poem = gen_poem(begin_char)pretty_print_poem(poem_=poem)
结果
测试结果如下,输入九月十二

输入正在下架
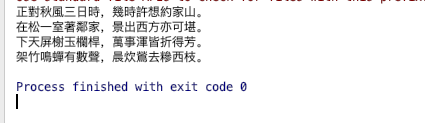
这藏头诗写的是不是有一定水平的哈?虽然我不怎么看懂。不过总而言之我们的藏头诗制作完成啦!
问题分析
有一个问题,训练集不够大,导致在生成藏头诗时容易出现以下问题,输入清风袭来
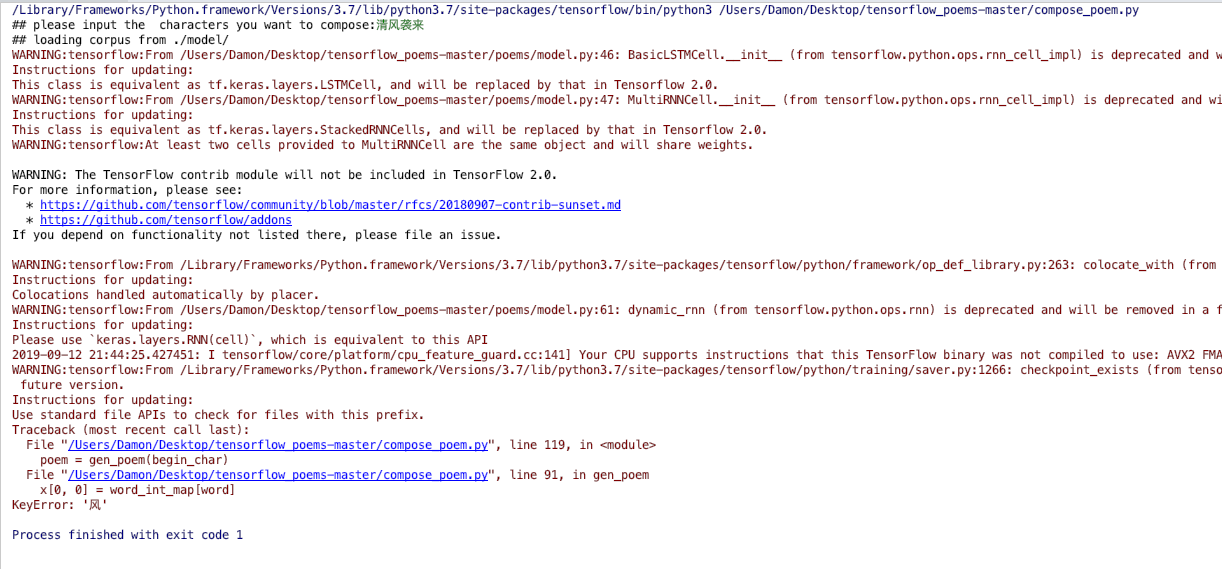
会出现keyerror,对此我觉的是训练集中这个‘风’字一次都没有出现过,希望有需求的同学可以自行寻找或制作更多的数据集对模型进行训练。
对于训练中生成的txt文件,我们进行画图。
import matplotlib.pyplot as plt
import numpy as npfile_name1='data100.txt'x=[]
y=[]
with open (file_name1) as file_object:lines=file_object.readlines()for line in lines:line=line.split(',')a=int(line[0])*1200b=int(line[1])x.append(a+b)y.append(float(line[2]))
print(np.min(y))
print(y.index(min(y)))
print(x[y.index(min(y))])
#plt.scatter(x,y,color='blue',s=1)
plt.plot(x,y)
plt.show()
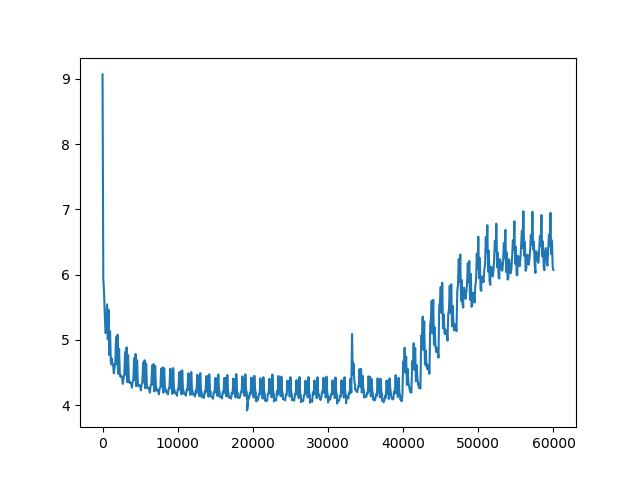
大概在epoch=26时loss最低。
发现出现了过拟合现象,对此感兴趣的同学可以通过修改网络层数,神经元个数以及学习率等来解决。
基于RNN循环神经网络lstm的藏头诗制作相关推荐
- 自然语言处理实战-基于LSTM的藏头诗和古诗自动生成
自然语言处理实战-基于LSTM的藏头诗和古诗自动生成 第一次写也是自己的第一篇博客,分享一下自己做的实验以及遇到的一些问题和上交的结课作业.资源都是开源的,参考文章写的很好,菜鸟的我也能理解.原文链接 ...
- Tensorflow:基于LSTM生成藏头诗
Tensorflow:基于LSTM生成藏头诗 最近在学习TensorFlow,学习到了RNN这一块,相关的资料不是很多,了解到使用RNN可以生成藏头诗之后,我就决定拿这个下手啦! 本文不介绍RNN以及 ...
- 基于RNN(循环神经网络)的北京雾霾天气指数的预测(keras实现RNN,LSTM神经网络算法)
随着科学技术的发展,人们渴望对天气有一定的掌握空间,从古代的夜观天象到如今的气象卫星,人类在对天气的预测上不断的进步与发展,本文将运用循环神经网络实现对天气情况的初步预测,循环神经网络是人工智能领域深 ...
- 微信小程序藏头诗制作
扫描二维码获取源码
- 趣味娱乐小程序源码多流量主 趣味制作/藏头诗/隐藏图
简介: 内由趣味制作,藏头诗制作,隐藏图制作三个部分组成,主要是以趣味为主,趣味制作又包含N个模板: 比如有: 1.人生目标,朋友圈点赞,签名照: 2.代写寒假作业,喝酒认怂书: 3.逢考必升符,打印 ...
- 【小程序源码】趣味娱乐趣味制作,藏头诗,隐藏图
这是一款趣味娱乐小程序 内由趣味制作,藏头诗制作,隐藏图制作三个部分组成 主要是以趣味为主,趣味制作又包含N个模板 比如有: 人生目标,朋友圈点赞,签名照 代写寒假作业,喝酒认怂书 逢考必升符,打印机 ...
- 小程序源码:趣味娱乐多流量主下载趣味制作,藏头诗,隐藏图-多玩法安装简单
这是一款趣味娱乐小程序 内由趣味制作,藏头诗制作,隐藏图制作三个部分组成 主要是以趣味为主,趣味制作又包含N个模板 比如有: 人生目标,朋友圈点赞,签名照 代写寒假作业,喝酒认怂书 逢考必升符,打印机 ...
- 趣味娱乐多微信小程序源码下载趣味制作,藏头诗,隐藏图
这是一款趣味娱乐小程序 内由趣味制作,藏头诗制作,隐藏图制作三个部分组成 主要是以趣味为主,趣味制作又包含N个模板 比如有: 人生目标,朋友圈点赞,签名照 代写寒假作业,喝酒认怂书 逢考必升符,打印机 ...
- 趣味娱乐多流量主微信小程序源码下载趣味制作,藏头诗,隐藏图
这是一款趣味娱乐小程序 内由趣味制作,藏头诗制作,隐藏图制作三个部分组成 主要是以趣味为主,趣味制作又包含N个模板 比如有: 人生目标,朋友圈点赞,签名照 代写寒假作业,喝酒认怂书 逢考必升符,打印机 ...
最新文章
- 2021年大数据Hive(十一):Hive调优
- Apache Traffic Server 4.2.1/5.3.2上的坑!
- 2020新款笔记本送一台!4核+8G+512固态
- echarts 动态改变数据_Echarts的使用
- python免费入门手册-python基础入门手册。。。。。。
- 不可思议的#define
- 1.12 改善你的模型表现-深度学习第三课《结构化机器学习项目》-Stanford吴恩达教授
- SDL介绍和简单实用
- 天猫不搞双十一“开玩笑”
- jmeter(2)录制脚本
- Taro+react开发(88):taro条件渲染
- C# 文件流相关操作
- JavaSE——数组基础(创建格式、下标、获取长度、常见问题、多维数组)
- 32张感恩海报!武汉市文化和旅游局这波操作太可以了
- sql语句执行步骤详解
- C++远征离港篇-学习笔记
- 程序员代码面试指南:IT 名企算法与数据结构题目最优解
- oracle 认证视频,Oracle 认证专家视频教程-OCP全套教程【98集】_IT教程网
- MATLAB 基础教程:编程习惯
- XSS原理dvwaxssvalidator使用
热门文章
- 【自用】学习代码中不懂东西...
- 蓝桥杯单片机第十届国赛练习
- 新疆大学计算机对口支援高校,国内10所高校签订对口支援新疆大学协议
- 潇洒学校老师小课堂:数控车床上螺纹加工的三大问题和解决方法
- PKCS1 PKCS8 公私钥 加密解密过程
- Spring源码深度解析(郝佳)-学习-源码解析-创建AOP静态代理(七)
- 创业圣经---讲透创业成功的秘籍
- MySQL配置文件无法生效、错误日志无法打印、my.cnf权限644无法启动、主从复制配置失效各式配置文件疑难杂症最终解决办法
- android studio程序打不开,Android Studio project 文件打不开问题解决
- WindowLess RichEdit 实现QQ聊天窗口的气泡效果,设计思路和方法。