NodeJs妹子图爬虫
Nodejs爬妹子图,本人费尽周折试了好多种方式,最后找到了一个好用的nodejs爬妹子图的方法,此代码仅供学习使用。
废话不多说,思路,我们要爬妹子图,首先要找到一个有妹子图的网页,然后从网页中获取这些图片的地址,然后批量下载自己的电脑里,带着这样的思路
需要以下工具
var fs = require('fs');
var path = require('path');
var request = require('request');
var cheerio = require('cheerio');
首先,fs和path模块均为nodejs自带,主要是下面两个,一个是request模块和cheerio模块。
request模块的介绍以及API:https://github.com/request/request
cheerio模块的介绍以及API:https://github.com/cheeriojs/cheerio
简单来说,request模块是用来请求网页的,cheerio是对请求来的网页进行解析的,也就是从html中解析出来图片的src地址
说一下为什么没用jquery解析呢,因为在试验过程中我用npm下载jquery模块之后,引入到文件的时候竟然报错了,详细原因不得而知,然后在网上看到了这个叫cheerio的利器,它跟jquery有很多相似的地方。
安装上面的两个模块
npm install request
npm install cheerio
先找到一个测试页面,比如 http://jandan.net/ooxx/page-1319
我们先要用request来获取这个页面的html
|
1
2
3
4
5
6
7
8
9
|
var request = require('request');
var requrl = 'http://jandan.net/ooxx/page-1319';
request(requrl, function (error, response, body) {
if (!error && response.statusCode == 200) {
console.log(body); //返回请求页面的HTML
}
})
|
运行后会得到大概下面这样的代码
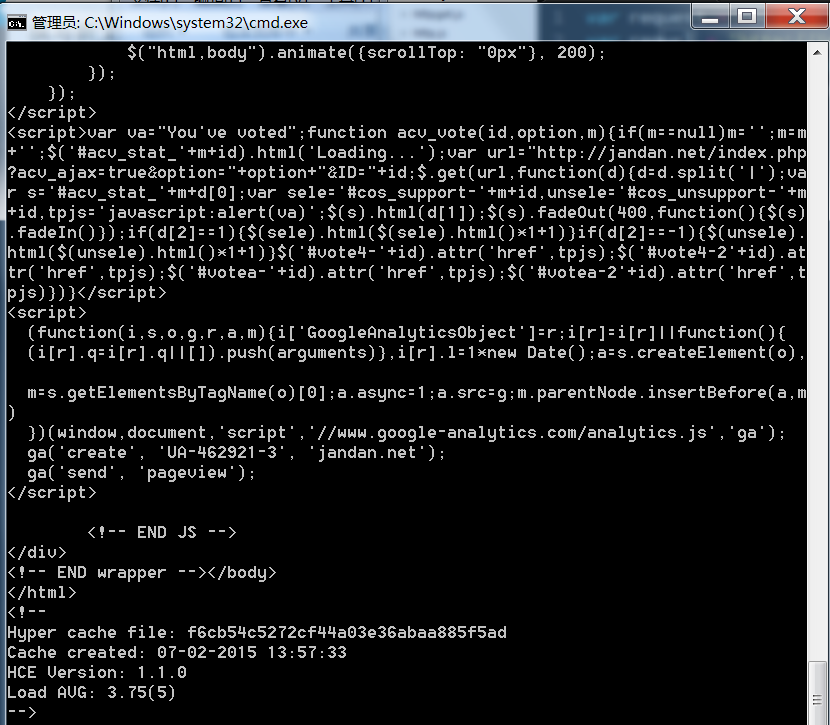
这个就是我们用request请求到的此页面的HTML,然后我们该使用cheerio模块来解析这个页面了
通过审查页面元素我们可以看出,这些妹子图都是放在 class="text" 下的 img 标签中

其实使用cheerio跟jquery是一样的,我们写了一个acquire方法来解析页面中的img标签中的src地址,代码如下
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
var request = require('request'); //引入request
var cheerio = require('cheerio'); //引入cheerio
var requrl = 'http://jandan.net/ooxx/page-1319';
request(requrl, function (error, response, body) {
if (!error && response.statusCode == 200) {
console.log(body); //返回请求页面的HTML
acquireData(body);
}
})
function acquireData(data) {
var $ = cheerio.load(data); //cheerio解析data
var meizi = $('.text img').toArray(); //将所有的img放到一个数组中
console.log(meizi.length);
var len = meizi.length;
for (var i=0; i<len; i++) {
var imgsrc = meizi[i].attribs.src; //用循环读出数组中每个src地址
console.log(imgsrc); //输出地址
}
}
|
当然,如果你拿不准选择器的话,可以多用console.log来输出,看看取到的地址是否正确,代码运行效果如下
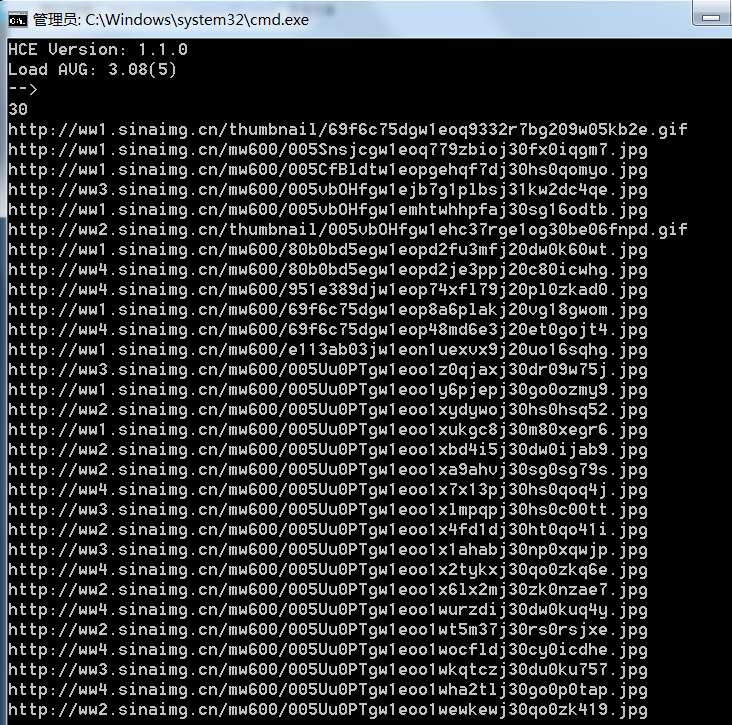
可以看到我们拿到了此页面中所有妹子图的地址,最后一步就是下载这些妹子图了,你不能是一个一个复制这些地址,然后粘贴到浏览器中右键另存为吧,首先,我们要先解析这些图片的文件名,解析文件名很简单,调用path模块中的basename方法就可以得到URL中的文件名
|
1
2
3
4
5
6
7
8
|
//NodeJs API http://nodejs.org/api/path.html#path_path_basename_p_ext
path.basename('http://hehe.com/foo/bar/baz/asdf/quux.jpg')
// 返回
'quux.jpg'
|
现在我们有了图片的地址和图片的名字,就可以下载了,在这里我们调用的是request模块的head方法来下载,请求到图片再调用fs文件系统模块中的createWriteStream来下载到本地目录
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
var request = require('request');
var cheerio = require('cheerio');
var path = require('path');
var fs = require('fs');
var requrl = 'http://jandan.net/ooxx/page-1319';
request(requrl, function (error, response, body) {
if (!error && response.statusCode == 200) {
console.log(body); //返回请求页面的HTML
acquireData(body);
}
})
function acquireData(data) {
var $ = cheerio.load(data);
var meizi = $('.text img').toArray();
console.log(meizi.length);
var len = meizi.length;
for (var i=0; i<len; i++) {
var imgsrc = meizi[i].attribs.src;
console.log(imgsrc);
var filename = parseUrlForFileName(imgsrc); //生成文件名
downloadImg(imgsrc,filename,function() {
console.log(filename + ' done');
});
}
}
function parseUrlForFileName(address) {
var filename = path.basename(address);
return filename;
}
var downloadImg = function(uri, filename, callback){
request.head(uri, function(err, res, body){
// console.log('content-type:', res.headers['content-type']); //这里返回图片的类型
// console.log('content-length:', res.headers['content-length']); //图片大小
if (err) {
console.log('err: '+ err);
return false;
}
console.log('res: '+ res);
request(uri).pipe(fs.createWriteStream('images/'+filename)).on('close', callback); //调用request的管道来下载到 images文件夹下
});
};
|
执行之后就可以看到images文件夹下有一大波妹子图了,想要爬多页的话,写个循环就好
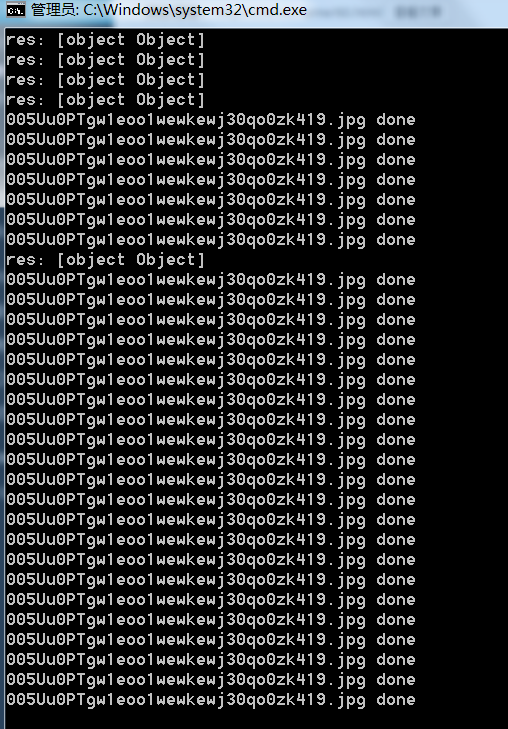
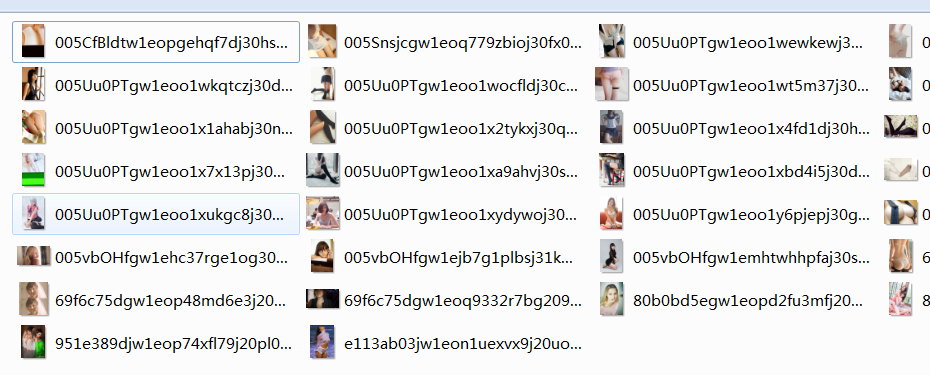
注意:有的网站是有反爬机制的,并不是每个网站都可以爬的
NodeJs妹子图爬虫相关推荐
- 煎蛋网妹子图爬虫(requests库实现)
煎蛋网妹子图爬虫(requests库实现) 文章目录 煎蛋网妹子图爬虫(requests库实现) 一.前言 环境配置 二.完整代码 一.前言 说到煎蛋网爬虫,相比很多人都写过,我这里试着用reques ...
- python爬虫随笔3 妹子图爬虫
前言 其实最早知道python爬虫就是知乎接触的妹子图爬虫,这次等于是自己写的:很多类库都是自己喜欢那个就用那个了: 思路 首先我们需要一个导航页,然后找到我们需要的类似于列表之类的,然后得到链接集合 ...
- Python爬虫(6):煎蛋网全站妹子图爬虫
Python爬虫(6):煎蛋网全站妹子图爬虫 上一篇文章中我们抓取了豆瓣图书的数据,如果大家运行成功,并且看到文件夹下的 txt 文件了.是不是有一种刚接触编程,第一次输出Hello world!时的 ...
- python打开交互界面设计_老司机必备——用PyQt做一个有交互界面的妹子图爬虫...
内容简介:老司机必备--用PyQt做一个有交互界面的妹子图爬虫 代码飙车,指日可待.今天的课程教大家结合PyQt和 Python 爬虫技术,做一个带有交互界面的妹子图网站爬虫程序. 一.实验简介 1. ...
- python妹子图爬虫5千张高清大图突破防盗链福利5千张福利高清大图
meizitu-spider python通用爬虫-绕过防盗链爬取妹子图 这是一只小巧方便,强大的爬虫,由python编写 所需的库有 requests BeautifulSoup os lxml 伪 ...
- Python爬虫 煎蛋网全站妹子图爬虫
爬取流程 从煎蛋网妹子图第一页开始抓取: 爬取分页标签获得最后一页数字: 根据最后一页页数,获得所有页URL: 迭代所有页,对页面所有妹子图片url进行抓取:访问图片URL并且保存图片到文件夹. 开始 ...
- [Python爬虫]煎蛋网OOXX妹子图爬虫(1)——解密图片地址
之前在鱼C论坛的时候,看到很多人都在用Python写爬虫爬煎蛋网的妹子图,当时我也写过,爬了很多的妹子图片.后来煎蛋网把妹子图的网页改进了,对图片的地址进行了加密,所以论坛里面的人经常有人问怎么请求的 ...
- [Python 爬虫]煎蛋网 OOXX 妹子图爬虫(1)——解密图片地址
之前在鱼C论坛的时候,看到很多人都在用 Python 写爬虫爬煎蛋网的妹子图,当时我也写过,爬了很多的妹子图片.后来煎蛋网把妹子图的网页改进了,对图片的地址进行了加密,所以论坛里面的人经常有人问怎么请 ...
- Python爬虫之煎蛋网妹子图爬虫,解密图片链接加密方式
之前在鱼C论坛的时候,看到很多人都在用Python写爬虫爬煎蛋网的妹子图,当时我也写过,爬了很多的妹子图片.后来煎蛋网把妹子图的网页改进了,对图片的地址进行了加密,所以论坛里面的人经常有人问怎么请求的 ...
- python妹子图爬虫5千张高清大图突破防盗链
代码思路/程序流程: 我通过观察发现meizitu网站的分布结构虽然找不到切入口但是其结构每一个页面都会展示一个main-image主图,并且页面下面都会有 推荐 这个板块,所以就i昂到了利用从 一个 ...
最新文章
- linux内核添加c代码,如何从C代码加载Linux内核模块?
- php统计键出现的次数,php统计数组元素出现的次数
- GitLab CI/CD 基础教程(三)
- 杭电2669拓展欧几里得
- mysql传参数 和 区别_mybatis中#{}和${}传参方式的区别
- clone是深拷贝还是浅拷贝_go-clone:深拷贝 Go 数据结构
- Oracle配置OneMap中的sql数据库问题及解决方案
- matplotlib画散点图
- 在VMWare上安装Win3.2
- C语言实现二叉树-04版
- IE下的一个安全BUG —— 可实时跟踪系统鼠标位置
- Oracle_spatial的常见错误与注意事项
- 服务器上使用 git 更新 wordpress 内核方案
- 【Java从0到架构师】SpringBoot - 页面模版_Thymeleaf
- ASP.NET中的回调技术(CallBack)
- puppet详解(八)——puppet自动化
- php系统变量有哪些,php预定义系统变量
- VC++学习(5):文本编程
- WPF调用 ECharts 显示图表
- rtmp代理php源码_RTMP直播系统(示例代码)