深度 | Google Brain研究工程师:为什么随机性对于深度学习如此重要?
在一个怡人的午后,我开始尝试着用通俗易懂的语言向我妈妈解释随机性对于深度学习的重要性。尽管我妈妈还是对于深度学习一知半解,但是我认为我的努力部分成功了,我迷上了这种方式并将它应用在了我的实际工作中。
我想将这篇稍具技术性的小文章送给在深度学习领域的实践者,希望大家能够对神经网络内部的运行过程有更好的理解。
* * *
如果你是一个刚刚入门的新手,那么你有可能会觉得一大堆技术被随意的一股脑的用在了训练神经网络上,例如dropout正则化、扩增梯度噪声、异步随机下降。那这些技术有什么相同的呢?答案是他们都利用了随机性!
随机性是深度神经网络正常运行的关键:
· 随机噪声使得神经网络在单输入的情况下产生多输出的结果;
· 随机噪音限制了信息在网络中的流向,促使网络学习数据中有意义的主要信息;
· 随机噪声在梯度下降的时候提供了“探索能量”,使得网络可以寻找到更好的优化结果。
单输入多输出
* * *
(单进多出)
让我们假设你正在训练一个深度神经网络去实现分类。
对于图中的每一个区域,网络会学习将图像映射到一系列的词语标签上,例如“狗”或者“人”。
这样的分类表现很不错,并且这样的深度神经网络不需要在推理模型中加入随机性。毕竟任何一张狗的图片应该被映射到“狗”这个词语标签上,这没有任何的随机性。
现在让我们来假设你在训练一个深度神经网络下围棋,在下图这样的情况下,深度神经网络需要落下第一个棋子。如果我们还是使用确定不变的策略,那么将无法得出一个好的结果。你可能会问,为什么啊?因为在这样的情况下最优的“第一步”选择不是唯一的,对于棋盘上的每一个位置来说,他们都和对面位置具有旋转对称性,所以具有相同的机会成为较优的选择。这是一个多元最优问题。如果神经网络的策略是确定并且是单输入单输出的话,优化过程会迫使网络选择移向所有最佳答案的平均位置,而这个结果不偏不倚的落在了棋盘的中心,这恰恰在围棋里被认为是一个糟糕的先手。
所以,随机性对于一个想输出多元最优估计的网络十分重要,而不是一遍遍重复输出相同的结果。当行动空间暗含对称性的情况下,随机性一个十分关键的因素,在随机性的帮助下,我们可以打破夹杂中间不能自拔的对称悖论。
同样的,如果我们想训练一个神经网络去作曲或者画画,我们当然不希望它总是演奏相同的音乐,描绘单调重复的场景。我们期待得到变化的韵律,惊喜的声音和创造性的表现。在结合随机性的深度神经网络中,一方面保持了网络的确定性,但是另一方面将其输出变成为概率分布的参数,使得我们可以利用卷积采样方法画出具有随机输出特性的样例图片。
DeepMind的阿法狗采用了这样的原则:基于一个给定的围棋盘图片,输出每一种走棋方式的获胜的概率。这种网络输出的分布建模被广泛应用与其他深度强化学习领域。
随机性与信息论
* * *
在刚刚接触概率论与数理统计时,我十分纠结于理解随机性的物理含义。抛一枚硬币时,结果的随机性来自哪里?随机性是否仅仅是确定性混沌?是否可以做到绝对的随机?
老实地说,我还是没有完全弄明白这些问题。
信息论中将随机性定义为信息的缺失。具体来说一个物体的信息便是在计算机程序里能确定描述它的最小字节数。例如π的前一百万个字节可以被表示为字节长度为1,000,002个字符,但是同样也可以被完整的用70个字符表示出来,如下用莱布尼茨公式所示:
上面的公式是π的一百万个数据的压缩表示。而更为精确的公式可以将π的前一百万个数据表示为更少的比特。从这个角度去解释的话,随机性是不可以被压缩的量。π的前一百万个量可以被压缩说明它们不是随机的。经验证据表明π是一个正规数(normal number),π中编码的信息是无穷的。
我们现在考虑用数字a表示π的前万亿个位数,如a=3.14159265...。如果我们在其中加上一个随机数r属于(-0.01,0.01),我们将会得到一个处于3.14059...和3.14259...之间的数。那么a+r里的有效信息只有三位数,因为加性随机噪声破坏了百位小数以后数位携带的信息。
迫使深度神经网络学到简洁表示
* * *
这个随机性的定义(指“随机性是不可以被压缩的量”,译者注)与随机性有什么联系呢?
随机性嵌入到深度神经网络的另一种途径是直接将噪声嵌入到网络本身,这与用深度神经网络去模拟一个分布不同。这种途径使得学习任务变得更加困难,因为网络需要克服这些内在的“扰动”。
我们到底为什么想要在网络中引入噪声?一个基本的直觉是噪声能够限制数据通过网络传输的信息容量。
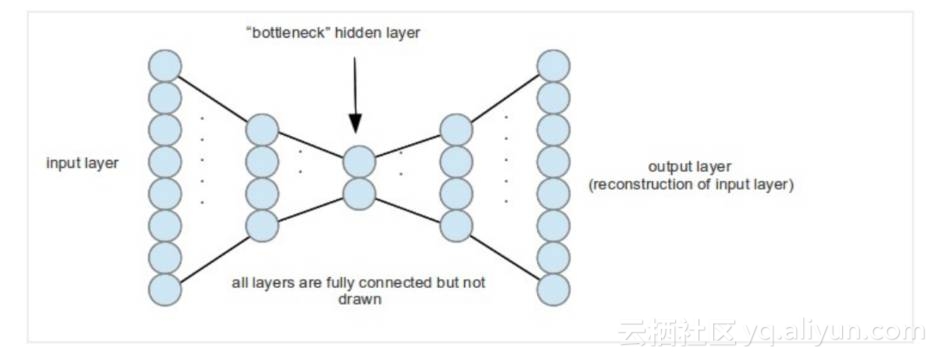
我们可以参考自动编码(auto-encoder)模型,这种神经网络结构尝试通过“压缩”输入数据、在隐含层得到更低维度的表示来得到有效的编码,并且在输出层重构原始数据。下面是一个示意图:
在训练过程中,输入数据从左边通过网络的节点,在右边出来,非常像一个管道。
假设我们有一个理论上存在的神经网络,其可以在实数(而不是浮点数)上训练。如果该网络中没有噪声,那么深度神经网络的每一层实际上都在处理无穷多的信息量。尽管自动编码网络可以把一个1000维的数据压缩到1维,但是这个1维的数可以用实数去编码任意一个无穷大维度的数,如3.14159265……
因此网络不需要压缩任何数据,也学不到任何有意义的特征。尽管计算机不会真的把数字以无穷维精度表示,但它倾向于给神经网络提供远远超过我们原本希望的数据量。
通过限制网络中的信息容量,我们可以迫使网络从输入特征里学到简洁的表示。现在已经有几种方法是这么做的:
• 变分自动编码(VAE) – 其在隐含层里加入高斯噪声,这种噪声会破坏“过剩信息”,迫使网络学习到训练数据的简洁表示。
• Dropout正则化与变分自动编码的噪声紧密相关(可能等价?) - 其随机将网络中的部分单元置为0,使其不参与训练。与变分自动编码相似,dropout噪声迫使网络在有限的数据里学习到有用的信息。
• 随机深度的深度网络 – 思想与dropout类似,但不是在单元层面上随机置0,而是随机将训练中的某些层删除,使其不参与训练。
• 有一篇非常有趣的文章是《二值化神经网络》(Binarized Neural Networks)。作者在前向传播中使用二进制的权重和激活,但在后向传播中使用实值的梯度。这里网络中的噪声来自于梯度—— 一种带噪声的二值化梯度。二进制网络(BinaryNets)不需要比常规的深度神经网络更加强大,每个单元只能编码一个比特的信息,这样正则是为了防止两个特征通过浮点编码被压缩在一个单元里。
更加有效的压缩方案意味着测试阶段的更好的泛化能力,这也解释了为什么dropout对防止过拟合如此有效。如果你决定用常规的自动编码而不是变分自动编码,你必须用随机正则化技巧,比如dropout,去控制压缩后的特征的比特数,不然你的网络将非常可能过拟合。
客观地说,我觉得变分自动编码网络(VAEs)更有优势,因为它们容易实现,并且允许你精确指定每层网络有多少比特的信息通过。
在训练中避免局部最小值
* * *
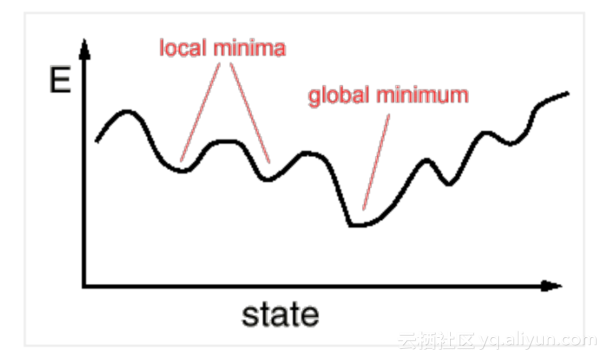
训练深度神经网络通常是通过梯度下降的变体来完成,基本意味着网络是通过降低在整个训练数据集上的平均损失误差来迭代参数。这就像从山上向山下走,当你走到山谷最底部的时候,你会找到神经网络的最优参数。
这种方法的问题是,神经网络的损失函数表面有很多个局部最小值和高原(因为网络拟合的函数通常非凸,译者注)。网络的损失函数很容易陷入一个小坑里,或者陷入一个斜率几乎为0的平坦区域(局部最小值),但你觉得此时还没有得到满意的结果。
随机性到底如何帮助深度学习模型?我的第三点解释是基于探索的想法。
因为用于训练深度神经网络的数据集通常都非常大,如果我们在每次梯度下降中对上千兆的数据通通计算梯度,这个计算量实在是太大了!事实上,我们可以使用随机梯度下降算法(SGD)。在这个算法里,我们只需要从数据集中随机挑选小部分数据,并且计算其平均梯度就可以了。
在进化中,如果物种的成功延续用随机变量X模拟,那么随机的突变或噪声会增加X的方差,其子孙可能会远远变得更好(适应性,防毒能力)或者远远变得更差(致命弱点,无法生育)。
在数值优化中,这种“基因突变”被称为“热力学能量”或“温度”,其允许参数的迭代轨迹并非总走“下山路”,而是偶尔地从局部最小值跳出来或者通过“穿山隧道”。
这些都与增强学习里的“探险-开采”平衡紧密相关。训练一个纯确定性的、没有梯度噪声的深度神经网络,其“开采”能力为0、直接收敛到最近的局部最小点,而且网络是浅层的。
使用随机梯度(通过小批量样本或在梯度本身加入噪声)是一个允许优化方法去做一些“搜索”和从局部最小值“跳出”的有效途径。异步随机梯度下降算法是另一个可能的噪声源,其允许多个机器并行地计算梯度下降。
这种“热力学能量”保证可以破坏训练的早期阶段中的对称性,从而保证每层网络中的所有梯度不同步到相同的值。噪声不仅破坏神经网络在行为空间中的对称性,而且破坏神经网络在参数空间里的对称性。
最后的思考
* * *
我发现有个现象非常有趣,即随机噪声事实上在帮助人工智能算法避免过拟合,帮助这些算法在优化或增强学习中找到解空间。这就提出了一个有趣的哲学问题:是否我们的神经编码中的固有噪声是一种特征,而不是瑕疵(bug)。
有一个理论机器学习问题让我很有兴趣:是否所有的神经网络训练技巧事实上是某些通用正则化定理的变形。也许压缩领域的理论工作将会对理解这些问题真正有所帮助。
如果我们验证不同神经网络的信息容量与手工设计的特征表示相比较,并观察这些比较如何关系到过拟合的趋势和梯度的质量,这会是一件非常有趣的事情。度量一个带有dropout或通过随机梯度下降算法训练的网络的信息容量当然不是没有价值的,而且我认为这是可以做到的。比如,构建一个合成矢量的数据集,这些矢量的信息容量(以比特,千字节等为单位)是完全已知的,我们可以通过结合类似于dropout的技巧,观察不同结构的网络如何在这个数据集上学到一个生成式模型。
-END-
本文来源于"中国人工智能学会",原文发表时间" 2016-08-12"




深度 | Google Brain研究工程师:为什么随机性对于深度学习如此重要?相关推荐
- TensorFlow可以做什么?让Google Brain首席工程师告诉你
编辑 | 明明 1月19日,在极客公园创新者大会IF2018的现场,Google Brain首席工程师陈智峰发表题为:<找答案从定义问题开始 --TensorFlow 可以用来做什么?>的 ...
- 【资源下载】旷视研究院张祥雨valse2019报告PPT——高效轻量级深度模型的研究与实践
报告题目 高效轻量级深度模型的研究与实践 报告摘要 深度基础模型在现代深度视觉系统中居于核心地位.在实际应用中,受应用场景.目标任务.硬件平台等的不同,经常会对模型的执行速度.存储大小.运算功耗等进行 ...
- 论文简读《视听觉深度伪造检测技术研究综述》
<视听觉深度伪造检测技术研究综述> 概述: 深度学习被广泛的应用于各个领域,自然语言处理.计算机视觉.无人驾驶等,推动了人工智能的发展.但在带来好处的同时,也对信息安全方面也有一定 ...
- 热门 | Google Brain前员工深度盘点2017人工智能和深度学习各大动态
翻译 | AI科技大本营 参与 | shawn 编辑 | Donna 2017年是人工智能井喷的一年.Google Brain团队前成员Denny Britz在自己的博客WILDML上对过去一年人工智 ...
- 跟风Google Brain,Facebook AI研究机构启动见习项目
2015年,Google Brain公布了其帮助机器学习研究者进阶的见习项目,研究内容灵活.薪资福利又高.发展机会应有尽有,瞬间吸引了大量的申请者,其中甚至还有Node.js之父Ryan Dahl,A ...
- 前端也能玩转机器学习?Google Brain 工程师来支招
演讲嘉宾 | 俞玶 编辑 | 伍杏玲 来源 | CSDN(ID:CSDNnews) 导语:9 月 7 日,在CSDN主办的「AI ProCon 2019」上,Google Brain 工程师,Tens ...
- 前端也能玩转机器学习?Google Brain 工程师来支招!
演讲者 | 俞玶 整理 | 伍杏玲 出品 | CSDN(ID:CSDNnews) [CSDN 编者按]9 月 7 日,在CSDN主办的「AI ProCon 2019」上,Google Brain 工程 ...
- 标签平滑深度学习:Google Brain解释了为什么标签平滑有用以及什么时候使用它(SOTA tips)...
点击上方"AI公园",关注公众号,选择加"星标"或"置顶" 作者:Less Wright 编译:ronghuaiyang 导读 标签平滑算是 ...
- Google Brain 团队的研究方法
来源:全球人工智能 概要:大约一年之前,Google Brain 团队首次分享了我们的使命:让机器拥有智慧,造福人类生活. 大约一年之前,Google Brain 团队首次分享了我们的使命:让机器拥有 ...
最新文章
- mysql查询数字比字符串快,与字符串相比,MySQL在where子句中使用数字更快吗?
- mysql如何配置hbm.xml_配置数据库映射文件hbm.xml
- ble之Transmit window offset and Transmit window size
- ACL 2019 | 基于知识增强的语言表示模型,多项NLP任务表现超越BERT
- python车辆轨迹分析_Ngsim数据集分析与python处理,NGSIM,解析,及
- C#2.0 从sql server 中读取二进制图片
- java实现map和object互转
- as3.0 mysql_RedhatAS3.0上安装Apache2+PHP5+MySQL+Resin+SSL+GD+weba_PHP教程
- Linux怎么添加交换空间,如何在Ubuntu上增加swap交换空间
- github仓库建立及配置教程新手教程
- C语言编辑飘扬的红旗代码,C语言 飘动的红旗(要有旗杆)
- Flex Application初始化顺序
- Mac中java实现自动打开软件问题
- html图片白色背景怎么去掉,怎么把PPT图片的白色背景去掉 PPT去除图片背景颜色技巧...
- 干货,看微信小程序后台用户数据如何演变和递增
- PDF转换器的使用步骤
- IP转换为long类型
- Weakly Guiding Fibers(弱导光纤)
- matlab/simulink学习的笔记都总结在这里
- Linux 如何查看内存使用情况
热门文章
- rbac权限管理5张表_thinkphp框架下基于rbac的后台程序
- android 实现论坛界面,android界面开发之主流UI布局范例
- 分组聚合查询两门以上MySQL_MySQL中的分组聚合查询
- 四种依恋类型_【工具】成人依恋量类型介绍
- doc转docx文件会乱吗_利用python将doc文件转换为docx
- matlab smooth 函数,matlab中smooth函数平滑处理数据实例
- java面向对象测试题二_JAVA面向对象-测试题
- exists hive中如何使用_07045.16.2如何使用Hive合并小文件
- 20200827:2020力扣第33周双周赛题解
- mysql怎么用sb文件_初识mysql数据库