UTF-8是如何编码的?
2019独角兽企业重金招聘Python工程师标准>>> 
众所周知计算机上存储的是二进制0和1,string字符串是如何转变为二进制0和1的呢?
每一个字符都会转换为对应的16进制,16进制也是一堆01代码,就相当于存储在计算机上的01代码。
不同的字符集通过不同的编码方式存储不同数目的字节数。下面以UTF-8是如何编码存储字符为二进制的为例子进行说明:
String a = “A”a.getBytes().length is 1byte array is [65]String a = "ë"a.getBytes().length is 2byte array is [-61, -85]
如上所示: A字符占用一个字节 ë字符占用两个字节。
etBytes()假设默认编码方式为UTF-8。
一些字符是一个字节,一些字符是两个字节,或者更多的字节,那么如何进行解码呢?
UTF-8如何进行编码? 在Wikipedia中给出了相关的规则:
if the first byte starts with 0 then it is a single byte char
if the first byte starts with 110 then it is 2 bytes
if the first byte starts with 1110 then it is 3 bytes
if the first byte starts with 11110 then it is 4 bytes
if the first byte starts with 111110 then it is 5 byte
if the first byte starts with 1111110 then it is 6 byte
翻译: 如果第一个字节以0开始,代表是一个单字节字符。 如果第一个字节以110开始,代表是双字节字符。 如果第一个字节以1110开始,代表是三字节字符。 如果第一个字节以11110开始,代表是四字节字符。 如果第一个字节以111110开始,代表是五字节字符。 如果第一个字节以1111110开始,代表是六字节字符。
所以我们解码就是反推即可: if the first byte starts with 0 then it is a single byte char so it decodes only that byte
if the first byte starts with 110 then it is 2 byte so it decodes 2 consecutive bytes
if the first byte starts with 1110 then it is 3 byte so it decodes 3 consecutive bytes
if the first byte starts with 11110 then it is 4 byte so it decodes 4 consecutive bytes
if the first byte starts with 111110 then it is 5 byte so it decodes 5 consecutive bytes
if the first byte starts with 1111110 then it is 6 byte so it decodes 6 consecutive bytes
下面用表格的方式列出Unicode和16进制以及占用字节之间的关系:
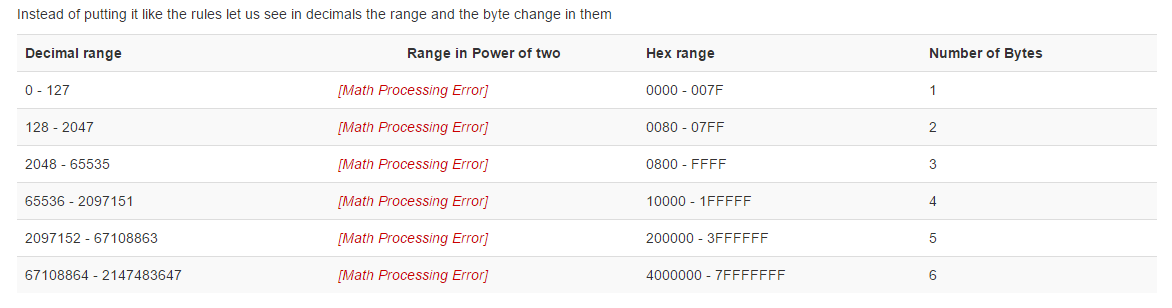
实例实战
ë
110 xxxxx 10 xxxxxx
110 00011 10 101011
00011 101011 → binary equivalent of hex pointing to ë
ɟ 110 xxxxx 10 xxxxxx
110 01001 10 011111
01001 011111 → binary equivalent of hex pointing to ɟ
11100000 10101101 10011111如何解码? 1110代表是三个字节为一个字符: 1110xxxx 10xxxxxx 10xxxxxx
11100000 10101101 10011111
so 0000 101101 011111 is the binary to be decoded.
所以为 0000 101101 011111 每四位为: 0000 1011 0101 1111 为:B5F
The binary is B5F in hexadecimal (If you don't know to convert use this binary to hex converter website ) Now from map B5F means ୟ .
练习:对01000010 01000001 11000011 10110000 11100010 10001011 10110011进行解码
1、第一个字符 01000010 为一个字符: 0100 0010为:42 参考这里 对应字符B
2、第二个字符
01000001 为一个字符: 0100 0001为:41 参考表格 对应字符A
3、第三个字符 11000011 10110000 为一个字符: 0000 11 110000 就是F0, 参考表格 映射为字符:ð
4、第四个字符: 11100010 10001011 10110011 为一个字符: 00010 001011 110011 就是 22F3 参考表格映射为字符:⋳
结论就是:01000010 01000001 11000011 10110000 11100010 10001011 10110011 采用UTF-8编码为BAð⋳
String 的 getBytes("UTF-8")做了什么操作呢?
String s = "ABCDEF⋳";
ABCDEF⋳通过getBytes("UTF-8")被编码为UTF-8格式,它是如何存储的呢? A - 01000001
B - 01000010
C - 01000011
D - 01000100
E - 01000101
F - 01000110
⋳ - 11100010 10001011 10110011
注意:以上是以字节的形式存储在内存中
所以getBytes("UTF-8")是获取每一个字节返回。
在内存中是如何存储的呢?
01000001 代表正数 65 但是11100010 代表负数 -31
所以存储在内存中为: 01000001 - 65
01000010 - 66
01000011 - 67
01000100 - 68
01000101 - 69
01000110 - 70
11100010 - -31
10001011 - -117
10110011 - -77
代码为证:
String s = "ABCDEF⋳";byte[] bs = s.getBytes("UTF-8");for(byte b : bs)System.out.print(b+",");
输出:
65,66,67,68,69,70,-30,-117,-77
Reference1 Reference2
转载于:https://my.oschina.net/u/2525142/blog/618929
UTF-8是如何编码的?相关推荐
- Unicode、UTF 和 ISO-8859-1等编码方式详解与浏览器URL编码
将字符转换为二进制码的过程,我们称为编码,将二进制码转换为字符的过程,我们称为解码. 编码和解码时所采用的规则,我们称为字符集 常见的字符集: ASCII - 美国人编码,使用7位来对美国常用的字符进 ...
- python解码utf报错_Python编码-无法解码为utf8
Python试图通过将文本片段(作为字节存储在数据库中)转换为Pythonstr对象来提供帮助.为了进行这种转换,python必须猜测查询返回的每个字节(或字节组)代表的字母.默认猜测是一种称为utf ...
- python字符编码讲解_python 字符编码讲解
ASCII控制字符 Unicode编码 ASCII(American Standard Code for Information Interchange,美国信息互换标准代码,ASCⅡ)是基于拉丁字 ...
- java linux urlencode_java字符编码转换研究(转)
1. 概述 本文主要包括以下几个方面:编码基本知识,java,系统软件,url,工具软件等. 在下面的描述中,将以"中文"两个字为例,经查表可以知道其GB2312编码是" ...
- 关于编码ansi、GB2312、unicode与utf-8的区别
关于编码ansi.GB2312.unicode与utf-8的区别 2014-01-25 08:51 529人阅读 评论(0) 收藏 举报 本文章已收录于: 关于编码ansi.GB2312.uni ...
- Unicode、UTF-8 和 ISO8859-1到底有什么区别(转载)
本文主要包括以下几个方面:编码基本知识,java,系统软件,url,工具软件等. 在下面的描述中,将以"中文"两个字为例,经查表可以知道其GB2312编码是"d6d0 c ...
- python字符编码
字符编码: ASCII:占一个字节,只支持英文 GBK2312:占两个字节,支持6700+汉字 GBK GB2312的升级版:支持21000+汉字 Unicode:2-4个字节 Unicode作用: ...
- 【JAVA编码专题】 JAVA字符编码系列三:Java应用中的编码问题
这两天抽时间又总结/整理了一下各种编码的实际编码方式,和在Java应用中的使用情况,在这里记录下来以便日后参考. 为了构成一个完整的对文字编码的认识和深入把握,以便处理在Java开发过程中遇到的各种问 ...
- 【JAVA编码专题】JAVA字符编码系列一:Unicode,GBK,GB2312,UTF-8概念基础
这两天抽时间又总结/整理了一下各种编码的实际编码方式,和在Java应用中的使用情况,在这里记录下来以便日后参考. 为了构成一个完整的对文字编码的认识和深入把握,以便处理在Java开发过程中遇到的各种问 ...
- java encode in ansi_Java应用中的编码问题
1. 概述 本文主要包括以下几个方面:编码基本知识,java,系统软件,url,工具软件等. 在下面的描述中,将以"中文"两个字为例,经查表可以知道其GB2312编码是" ...
最新文章
- UVA 10700 Camel trading
- 给程序员的几条建议,精彩配图!
- POJ2533解题报告
- linux 配置快速查看
- 【C语言入门学习笔记】如何把C语言程序变成可执行文件!
- 配置.net连接数据库的配置文件
- android 微信小程序 gps 飘,微信小程序实现自动定位功能
- 深度学习是什么,深度学习概念的基本理解?
- 12000 颗卫星为地球织网!马斯克昨夜踏上改变世界的第6个征程
- 10 个最佳 WordPress 幻灯片插件
- struct和typedef struct的用法和区别
- hpgs2wnd.exe
- FasterReport
- 查壳去壳和加壳的使用指南
- GPS-Uber:一个用于预测一般和e3特异性赖氨酸泛素化位点的混合学习框架
- 2009成渝微型计算机处于空白,学海园大联考 2020届高三信息卷(二)文综答案
- Python求均值,方差,标准差
- 《算法笔记》第三章3.2节、3.3节、3.4节学习笔记
- platform设备驱动简介
- python基金筛选_如何利用python挑选基金?
热门文章
- org.apache.jasper.JasperException: /index.jsp(14,2) The s:form tag declares that it accepts dyna
- bzoj2038 [2009国家集训队]小Z的袜子(hose)
- Python的字符串格式化 %r %s
- [Python]小甲鱼Python视频第020课(函数:内嵌函数和闭包)课后题及参考解答
- 16.1 Class类与Java反射
- [BZOJ1594] [Usaco2008 Jan]猜数游戏(二分 + 并查集)
- 黑马程序员 oc中的类与对象
- Linux串口编程详解(转)
- iptables小结
- Xml序列化和反序列化对象-使用MemoryStream-实践