python网易云_Python数据可视化:网易云音乐歌单
网易云音乐2018年度听歌报告—遇见你,真好。
相信有不少人在上周,应该已经看过自己网易云音乐的年度报告了。
小F也是去凑凑热闹,瞅了一波自己的年度听歌报告。
那么你在云村又听了多少首歌,听到最多的歌词又是什么呢?
2018年你的年度歌手又是谁,哪些又是你***的歌呢?
不过相比去年,我的票圈并没有很多发自己年度报告的朋友。
不得不说,版权之争开始,网易云音乐似乎就在走下坡路。
很多喜欢的歌听不了,这应该是大家共同的痛点。
***的印象就是周董的歌,在愚人节时下架了,原以为只是个玩笑,不想却是真的。
本次通过对网易云音乐华语歌单数据的获取,对华语歌单数据进行可视化分析。
可视化库不采用pyecharts,来点新东西。
使用matplotlib可视化库,利用这个底层库来进行可视化展示。
一、网页分析
01 歌单索引页
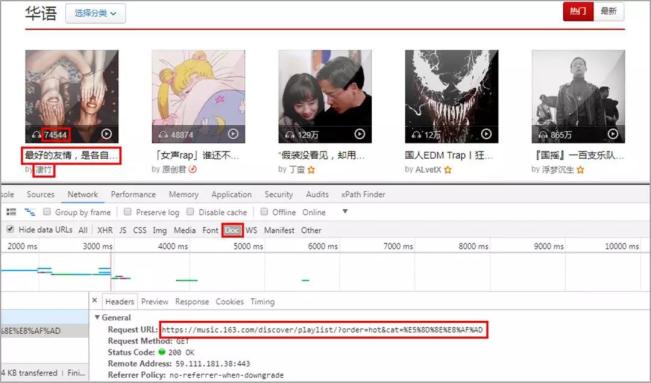
选取华语热门歌单页面。
获取歌单播放量,名称,及作者,还有歌单详情页链接。
本次一共获取了1302张华语歌单。
02 歌单详情页
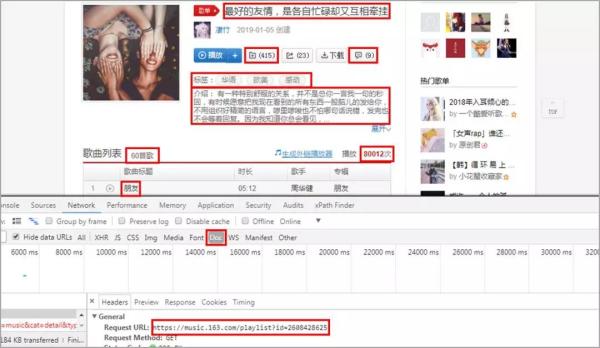
获取歌单详情页信息,信息比较多。
有歌单名,收藏量,评论数,标签,介绍,歌曲总数,播放量,收录的歌名。
这里歌曲的时长、歌手、专辑信息在网页的iframe中。
需要用selenium去获取信息,鉴于耗时过长,小F选择放弃...
有兴趣的小伙伴,可以试一下哈...
二、数据获取
01 歌单索引页
frombs4 import BeautifulSoup
import requests
import time
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
foriinrange(0, 1330, 35):
print(i)
time.sleep(2)
url = 'https://music.163.com/discover/playlist/?cat=欧美&order=hot&limit=35&offset='+ str(i)
response = requests.get(url=url, headers=headers)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
# 获取包含歌单详情页网址的标签
ids = soup.select('.dec a')
# 获取包含歌单索引页信息的标签
lis = soup.select('#m-pl-container li')
print(len(lis))
forjinrange(len(lis)):
# 获取歌单详情页地址
url = ids[j]['href']
# 获取歌单标题
title = ids[j]['title']
# 获取歌单播放量
play = lis[j].select('.nb')[0].get_text()
# 获取歌单贡献者名字
user= lis[j].select('p')[1].select('a')[0].get_text()
# 输出歌单索引页信息
print(url, title, play, user)
# 将信息写入CSV文件中
withopen('playlist.csv','a+', encoding='utf-8-sig')asf:
f.write(url + ','+ title +','+ play +','+user+'\n')
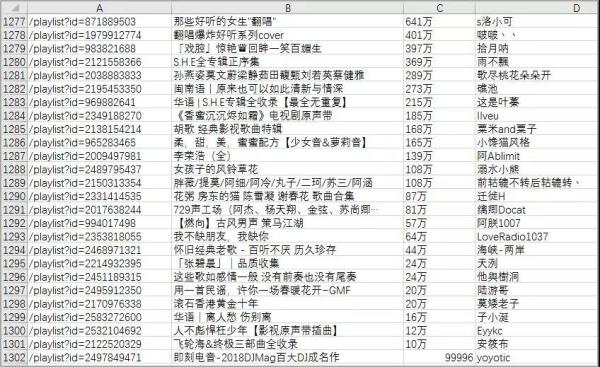
获取歌单索引页信息如下,共1302张华语歌单。
02、歌单详情页
frombs4 import BeautifulSoup
import pandas aspd
import requests
import time
df = pd.read_csv('playlist.csv', header=None, error_bad_lines=False, names=['url','title','play','user'])
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
foriindf['url']:
time.sleep(2)
url = 'https://music.163.com'+ i
response = requests.get(url=url, headers=headers)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
# 获取歌单标题
title = soup.select('h2')[0].get_text().replace(',',',')
# 获取标签
tags = []
tags_message = soup.select('.u-tag i')
forpintags_message:
tags.append(p.get_text())
# 对标签进行格式化
if len(tags) > 1:
tag = '-'.join(tags)
else:
tag = tags[0]
# 获取歌单介绍
if soup.select('#album-desc-more'):
text = soup.select('#album-desc-more')[0].get_text().replace('\n','').replace(',',',')
else:
text = '无'
# 获取歌单收藏量
collection = soup.select('#content-operation i')[1].get_text().replace('(','').replace(')','')
# 歌单播放量
play = soup.select('.s-fc6')[0].get_text()
# 歌单内歌曲数
songs = soup.select('#playlist-track-count')[0].get_text()
# 歌单评论数
comments = soup.select('#cnt_comment_count')[0].get_text()
# 输出歌单详情页信息
print(title, tag, text, collection, play, songs, comments)
# 将详情页信息写入CSV文件中
withopen('music_message.csv','a+', encoding='utf-8-sig')asf:
f.write(title + ','+ tag +','+ text +','+ collection +','+ play +','+ songs +','+ comments +'\n')
# 获取歌单内歌曲名称
li = soup.select('.f-hide li a')
forjinli:
withopen('music_name.csv','a+', encoding='utf-8-sig')asf:
f.write(j.get_text() + '\n')
获取的1302张华语歌单的详情。
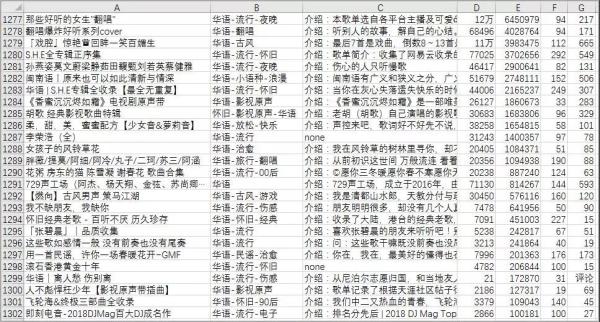
1302张歌单里的121118首歌。

三、数据可视化
可视化代码已上传GitHub,点击左下角阅读原文即可访问!!!
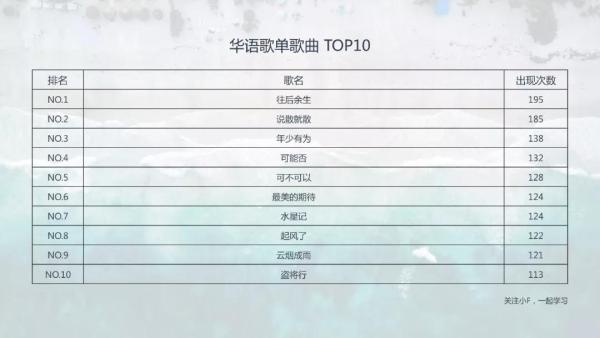
01 歌曲出现次数 ***0
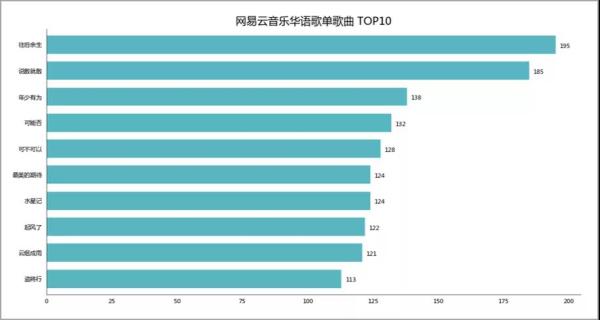
榜上的十首歌,除了「水星记」,小F听得次数都不少。
那么你又是如何的呢?
在小F的印象里,这些歌都曾在网易云音乐热歌榜的榜首出现过。
02 歌单贡献UP主 ***0
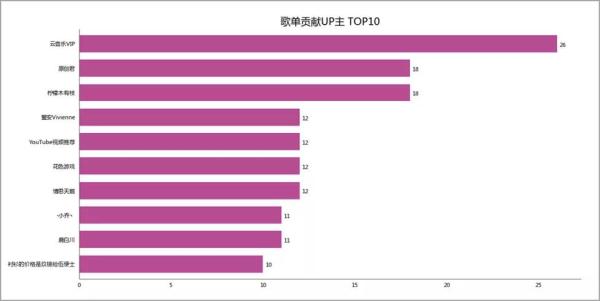
10大歌单贡献UP主,感谢这些辛勤的“搬运工”,给大家带来优质的歌单。
给广大懒人癌患者,亦或选择困难症患者,带来福利。
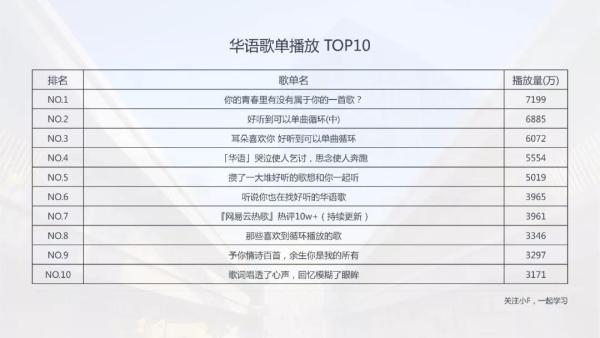
03 歌单播放量 ***0
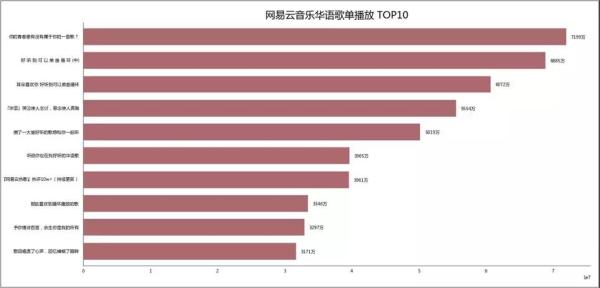
歌单播放量前十名单,***名7000多万播放量。
其实matplotlib生成的图是挺清楚的,只不过一上传就变模糊了。
所以这里你可能会觉得图片质量不行...
其实并不是,为此小F做了相应的图表,具体见文末~
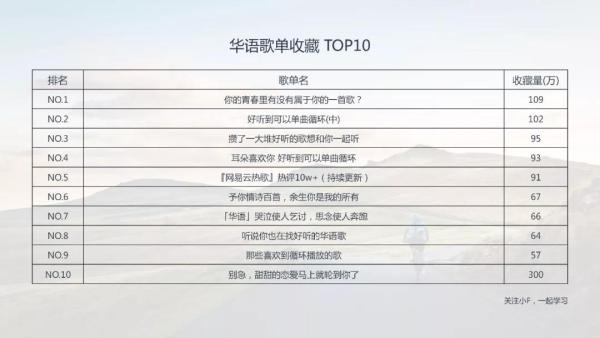
04 歌单收藏量 ***0
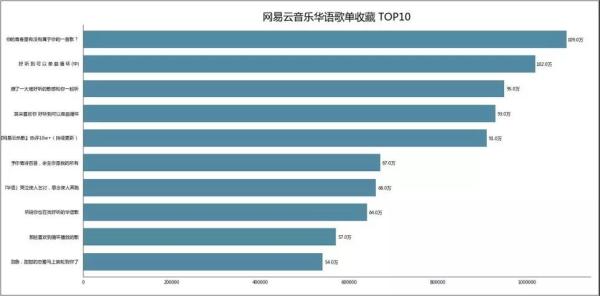
同样是好东西,收藏收藏!!!
有一些歌单和播放量***0里歌单有重复。
05 歌单评论数 ***0
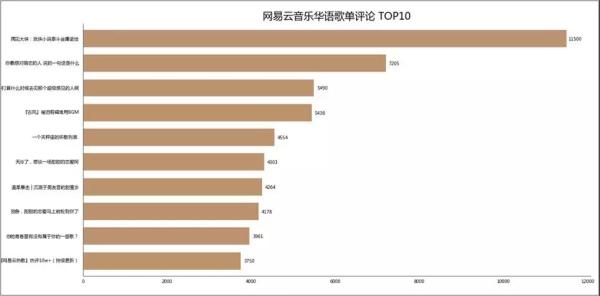
歌单「再见大侠:武侠小说泰斗金庸逝世」评论数最多。
相信不少人的阅读时光,就是与金庸前辈的武侠小说一起度过。
飞雪连天射白鹿,笑书神侠倚碧鸳。
还有由小说改编成的电视剧,都是经典!!!
小F武侠小说看的少,武侠电视剧看的多...
06 歌单收藏数量分布情况
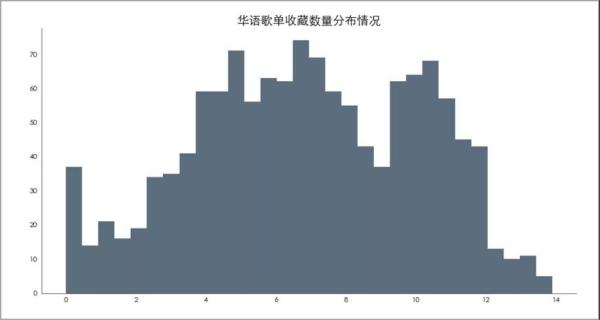
将收藏数做对数处理,使得能直观看出歌单收藏数的分布。
主要分布在0-15万之间(ln(150000)=12)。
07 歌单播放数量分布情况
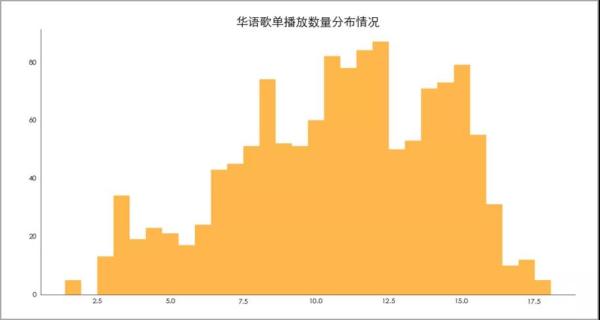
歌单播放数主要分布在0-1000万。
其中ln(10000000)=16。
08 歌单标签图
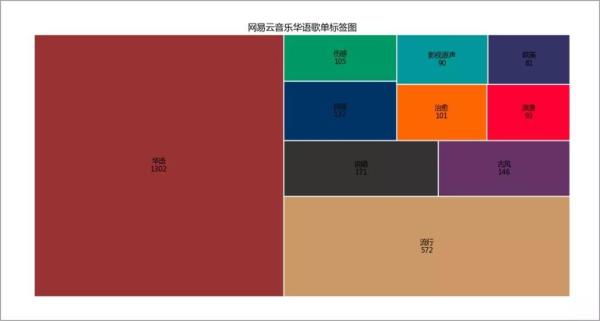
既然选取的是华语歌单,那么华语这二字必不可少,而且还占大头。
那么就看看除了华语,还有什么其他标签。
「流行」没啥好说的。
「古风」「说唱」「民谣」近些年来热度是越来越高,不过也有玩坏的时候。
比如「离人愁」、「一人我饮酒醉」,小F作为吃瓜群众,只能说且行且珍惜...
09 歌单介绍词云图

歌单介绍词云图,希望你能找到你喜欢某首歌的原因!!!
到底是希望,还是青春,亦或是回忆呢?
四、总结
***,把本次搜刮的干货,分享给大家。
可视化及相关代码都放「GitHub」上头了。
GitHub:https://github.com/Tobby-star/music_163
作者:法纳斯特,Python爱好者,喜欢爬虫,数据分析以及可视化。
【编辑推荐】
【责任编辑:未丽燕 TEL:(010)68476606】
点赞 0
python网易云_Python数据可视化:网易云音乐歌单相关推荐
- python音乐可视化效果_Python数据可视化 | 网易云音乐年度歌曲
网易云音乐2018年度听歌报告-遇见你,真好. 相信有不少人在上周,应该已经看过自己网易云音乐的年度报告了. 小F也是去凑凑热闹,瞅了一波自己的年度听歌报告. 那么你在云村又听了多少首歌,听到最多的歌 ...
- python matplotlib 地图_Python数据可视化,看这篇就够了
说到python的常见应用,很多人会想到python的数据分析,作为数据分析中的表现层面,数据可视化都是其中必不可少的部分.但本文并非只推荐无任何数据分析需求仅需要做漂亮可视化图表的人学习python ...
- python界面散点图_Python数据可视化——散点图
PS: 翻了翻草稿箱, 发现居然存了一篇去年2月的文章...虽然naive,还是发出来吧... 本文记录了python中的数据可视化--散点图scatter, 令x作为数据(50个点,每个30维),我 ...
- python柱形图代码_Python数据可视化:基于matplotlib绘制「条形图」
简介 条形图 (bar chart)是用宽度相同条形的高度或长短来表示数据多少的图形,可以横置或纵置.纵置时的条形图也称为 柱形图 (column chart). 绘制条形图 1 import mat ...
- 用python画熊_Python数据可视化:Pandas库,只要一行代码就能实现
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 以下文章一级AI入门学习 ,作者小伍哥 刚接触Python的新手.小白,可以复制下面的链接去免费观 ...
- python plt包_Python 数据可视化-Matplotlib包学习笔记(一)
Python 数据可视化 本文主要参照Matplotlib的官方教程进行整理,作为个人的学习笔记进行分享,欢迎相互讨论. Matplotlib包学习笔记(一) 本文主要简单介绍一下Matplotlib ...
- python hist函数_Python数据可视化:一文读懂直方图和密度图
一图胜千言,使用Python的matplotlib库,可以快速创建高质量的图形. 用matplotlib生成基本图形非常简单,只需要几行代码,但要创建复杂的图表,需要调用更多的命令和反复试验,这要求用 ...
- python画板颜色_Python数据可视化:Seaborn(二):色板
在进行数据可视化处理的时候,常常会涉及到多个类的数据,有些时候默认的颜色并不是我们想要的,这时候,如果我们想要一些我们喜欢的颜色,就需要调整色板,下面我们就来介绍一下Seaborn的色板调整. 首先依 ...
- python 画虚线_Python数据可视化 - matplotlib
数字可视化是将数据用统计图表方式呈现. python的作图库有两种,matplotlib 和 seaborn,本文主要介绍Matplotlib. Matplotlib 是一个 Python 的 2D绘 ...
最新文章
- 虚拟桌面最佳组合---Windows 7
- 判断均匀平面波的极化形式_化学选修3丨分子极性如何判断?四步就能搞定!...
- RANSAC算法做直线拟合
- 开源项目SlidingMenu的使用(Android)
- 【C++编程题1】数组指针之字符串排序
- 缓存,你真的用对了么?
- Android版本历史变迁
- overfeat 测试
- 一次搞懂清晰度、对比度以及锐化的区别
- 【导数术】10.导数数列不等式
- [latex]参考文献格式
- python笔记27:数据分析之交叉分析
- 闲逸游戏态度决定胜负,安全决定未来!
- 【VMW】虚拟机安装小攻略
- Origin ##外推法作图求斜率##两组数据绘图到同一个坐标系
- 解决Failed to load resource: net::ERR_INCOMPLETE_CHUNKED_ENCODING
- 【完美解决】org.apache.catalina.core.StandardContext.filterStart 启动过滤器异常
- Cppcheck 1.54 C/C++静态代码分析工具
- oracle 监控内存和硬盘的排序比率_最好使它小于 .10,监控数据库性能的SQL
- 康奈尔大学的电影对白语料库介绍 --Cornell Movie-Dialogs Corpus