Python | Xpath实战训练
一、前言
今天给大家分享的是,如何在cmd和pycharm中启动自己的spider以及Xpath的基本介绍,并利用Xpath抓取伯乐在线单篇文章基本信息。
二、Xpath介绍
1. 维基百科看 Xpath
XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。
XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。起初XPath的提出的初衷是将其作
为一个通用的、介于XPointer与XSL间的语法模型。但是XPath很快的被开发者采用来当作小型查询
语言。
2. 我来扯扯Xpath
1. Xpath使用路径表达式在xml和html中进行导航(据说访问速度、效率比bs4快)
2. Xpath包含标准函数库
3. Xpah是一个W3c的标准
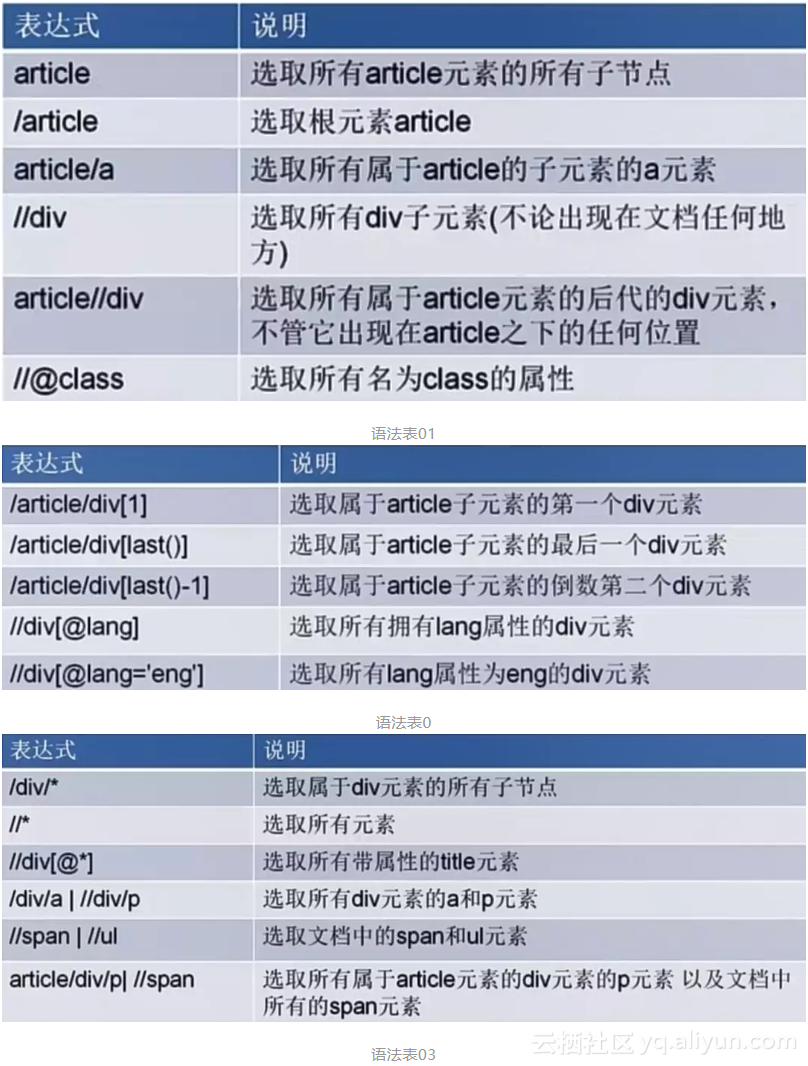
3. Xpath基本使用语法
三、看代码,边学边敲边记
1.在cmd下启动我们的Scrapy项目子项---jobbole
(1)快速进入虚拟环境(设置方法见上一篇)
C:\Users\82055\Desktop>workon spiderenv(2)进入到项目目录
(spiderenv) C:\Users\82055\Desktop>H:
(spiderenv) H:\env\spiderenv>cd H:\spider_project\spider_bole_blog\spider_bole_blog
(3)输入spider命令(格式:scrapy crawl 子项的name)
(spiderenv) H:\spider_project\spider_bole_blog\spider_bole_blog>scrapy crawl jobbole(4)如果是win系统,可能会出现下面错误
<module>
from twisted.internet import _win32stdio
File "h:\env\spiderenv\lib\site-packages\twisted\internet\_win32stdio.py", line 9, in <module>
import win32api
ModuleNotFoundError: No module named 'win32api'
(5)解决方法:安装 pypiwin32模块(采用豆瓣源安装)
# 虚拟环境中
pip install -i https://pypi.douban.com/simple pypiwin32
(6)再次执行spider命令
(spiderenv) H:\spider_project\spider_bole_blog\spider_bole_blog>scrapy crawl jobbole
2018-08-23 23:42:01 [scrapy.utils.log] INFO: Scrapy 1.5.1 started (bot: spider_bole_blog)
···
2018-08-23 23:42:04 [scrapy.core.engine] INFO: Closing spider (finished)
2018-08-23 23:42:04 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 440,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 21919,
'downloader/response_count': 2,
'downloader/response_status_count/200': 2,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2018, 8, 23, 15, 42, 4, 695188),
'log_count/DEBUG': 3,
'log_count/INFO': 7,
'response_received_count': 2,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2018, 8, 23, 15, 42, 2, 770906)}
2018-08-23 23:42:04 [scrapy.core.engine] INFO: Spider closed (finished)
2. 在`Pycharm`下启动我们的Scrapy项目子项---jobbole
(1)打开项目,在项目根目录下新建一个main.py,用于调试代码。
(2)在main.py中输入下面内容
'''
author : 极简XksA
data : 2018.8.22
goal : 调试模块
'''
import sys
import os
# 导入执行spider命令行函数
from scrapy.cmdline import execute
# 获取当前项目目录,添加到系统中
# 方法一:直接输入,不便于代码移植
#(比如小明和小红的项目路径可能不一样,那么小明的代码想在小红的电脑上运行,
# 路径就要手动改了,python怎么能这么麻烦呢,请看方法二)
# sys.path.append("H:\spider_project\spider_bole_blog\spider_bole_blog")
# 方法二:代码获取,灵活,代码移植也不影响
# print(os.path.dirname(os.path.abspath(__file__)))
# result : H:\spider_project\spider_bole_blog\spider_bole_blog
# 获取当前项目路径,添加到系统中
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
# 执行spider命令
execute(['scrapy','crawl','jobbole'])
(3)修改setting.py文件设置,将ROBOTSTXT_OBEY值改为False,默认为True或者被注释掉了,文件中注释解释内容:Obey robots.txt rules,表示我们的spider的网址必须要遵循robots协议,不然会直接被过滤掉,所以这个变量的属性值必须设置为Fal0se哦!
# 大概是第21-22行,ROBOTSTXT_OBEY默认值为True
# 修改为False,如下:
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
(4)直接运行测试文件main.py,运行结果和上面在cmd是一样的。
(5)在jobbole.py中的的parse函数中加一个断点,然后Debug模式运行测试文件main.py
断点设置:
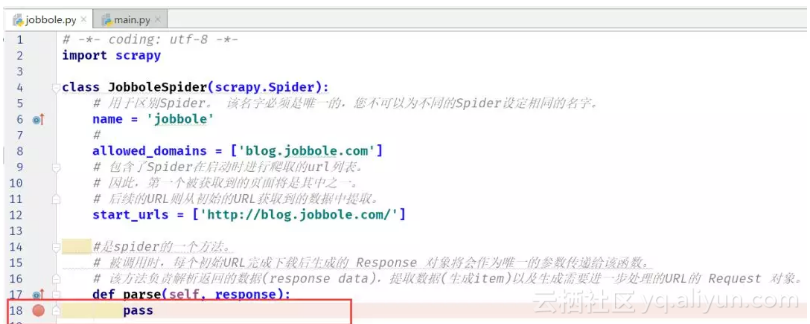
断点设置
debug结果分析:
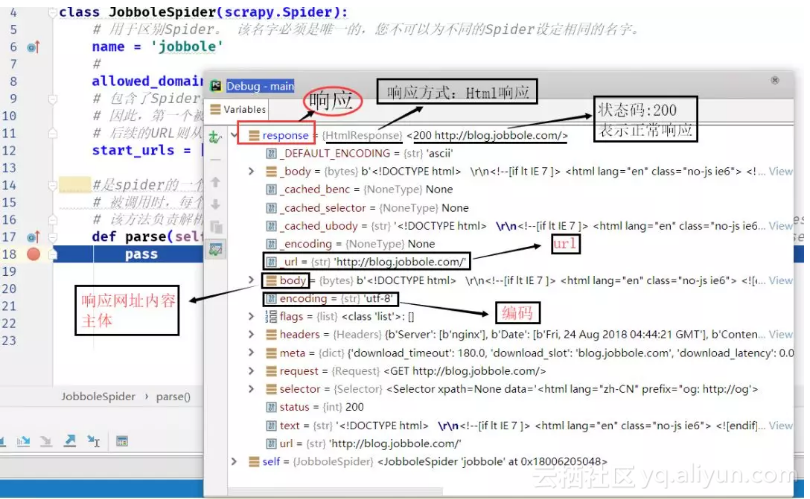
debug结果分析
3. 编写`jobbole.py`中的的`parse`函数,利用Xpath获取网页内容
(1)为了简单起见,我随便选取了一篇文章《Linux 内核 Git 历史记录中,最大最奇怪的提交信息是这样的》。
(2)把start_urls的属性值改为http://blog.jobbole.com/114256/,使spider从当前文章开始爬起来。
start_urls = ['http://blog.jobbole.com/114256/'](3)网页中分析并获取文章标题Xpath路径
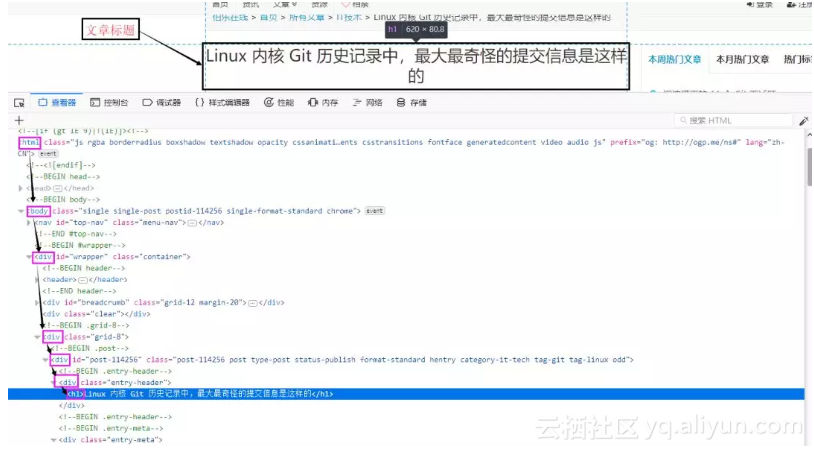
页面分析
在FireFox浏览器下按F12进入开发者模式,选择查看器左边的选取图标功能,然后将鼠标移动到标题处,在查看器中会自动为我们找到源码中标题的位置
如上图分析,标题应该在html下的body中的第一个div中的第三个div中的第一个div中的第一个div中的h1标签中,那么Xpath路径即为:
/html/body/div[1]/div[3]/div[1]/div[1]/h1是不是感觉到很复杂,哈哈哈,不用灰心,其实分析起来挺简单的,另外我们还有更简单的方法获取Xpath,当我们在查看器重找到我们要的内容后,直接右键,即可复制我们想要的内容的Xpath路径了。
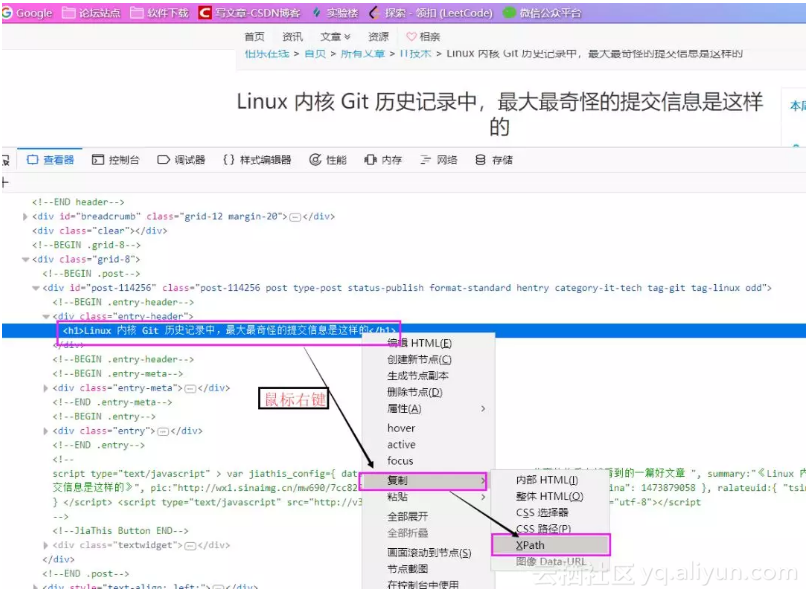
页面复制Xpath
(4)修改jobbole.py中的的parse函数,运行打印出文章标题
# scrapy 的 response里面包含了xpath方法,可以直接用调用,返回值为Selector类型
# Selector库中有个方法extract(),可以获取到data数据
def parse(self, response):
# firefox 浏览器返回的Xpath
re01_selector = response.xpath('/html/body/div[1]/div[3]/div[1]/div[1]/h1/text()')
# chrome 浏览器返回的Xpath
re02_selector = response.xpath('//*[@id="post-114256"]/div[1]/h1/text()')
re01_title = re01_selector.extract()
re02_title = re02_selector.extract()
print('xpath返回内容:'+str(re01_selector))
print('firefox返回文章标题为:' + re01_title)
print('chrome返回文章标题为:' + re02_title)
运行结果:
# 观察结果发现Xpath返回的Selector对象值包括 xpath路径和data数据
xpath返回内容:[<Selector xpath='/html/body/div[1]/div[3]/div[1]/div[1]/h1/text()'
data='Linux 内核 Git 历史记录中,最大最奇怪的提交信息是这样的'>]
firefox返回文章标题为:Linux 内核 Git 历史记录中,最大最奇怪的提交信息是这样的
chrome返回文章标题为:Linux 内核 Git 历史记录中,最大最奇怪的提交信息是这样的
从上面可以看出,FireFox和Chorme获取到的Xpath是不一样的,but实际返回的东西是一样的,只是用了不同的语法,我这里说明的意思是想告诉大家:Xpath的表达方式不止一种,可能某个内容的Xpath有两种或者更多,大家觉得怎么好理解就使用哪一个。
(5)我们继续获取其他数据(复习巩固一下Xpath的用法)
为了快速、有效率的调式数据,给大家推荐一种方法:
# cmd 虚拟环境中输入: scrapy shell 你要调试的网址
scrapy shell http://blog.jobbole.com/114256/
这样在cmd中就能保存我们的访问内容,可以直接在cmd下进行调试,不用在pycharm中每调试一个数据,就运行一次,访问一次页面,这样效率是非常低的。
获取文章发布时间
>>> data_r = response.xpath('//p[@class="entry-meta-hide-on-mobile"]/text()')
>>> data_r.extract()
['\r\n\r\n 2018/08/08 · ', '\r\n \r\n \r\n\r\n \r\n · ', ', ', '\r\n \r\n']
>>> data_r.extract()[0].strip()
'2018/08/08 ·'
>>> data_str = data_r.extract()[0].strip()
>>> data_str.strip()
'2018/08/08 ·'
>>> data_str.replace('·','').strip()
'2018/08/08'
# data_selector = response.xpath('//p[@class="entry-meta-hide-on-mobile"]/text()')
# data_str = data_selector.extract()[0].strip()
# data_time = data_str.replace('·','').strip()
获取文章点赞数、收藏数和评论数
# 点赞数
>>> praise_number = response.xpath('//h10[@id="114256votetotal"]/text()')
>>> praise_number
[<Selector xpath='//h10[@id="114256votetotal"]/text()' data='1'>]
>>> praise_number = int(praise_number.extract()[0])
>>> praise_number
1
# praise_number = int(response.xpath('//h10[@id="114256votetotal"]/text()').extract()[0])
# 收藏数
>>> collection_number = response.xpath('//span[@data-book-type="1"]/text()')
>>> collection_number
[<Selector xpath='//span[@data-book-type="1"]/text()' data=' 1 收藏'>]
>>> collection_number.extract()
[' 1 收藏']
>>> collection_word = collection_number.extract()[0]
>>> import re
>>> reg_str = '.*(\d+).*'
>>> re.findall(reg_str,collection_word)
['1']
>>> collection_number = int(re.findall(reg_str,collection_word)[0])
>>> collection_number
1
# collection_str = response.xpath('//span[@data-book-type="1"]/text()').extract()[0]
# reg_str = '.*(\d+).*'
# collection_number = int(re.findall(reg_str,collection_word)[0])
# 评论数
>>> comment_number = response.xpath('//span[@class="btn-bluet-bigger href-style hide-on-480"]/text()')
>>> comment_number
[<Selector xpath='//span[@class="btn-bluet-bigger href-style hide-on-480"]/text()' data=' 评论'>]
>>> comment_number.extract()[0]
' 评论'
# 由于我选的这篇文章比较新,还没有评论,哈哈哈。。。
# 如果有的话,后面和上面获取收藏数是一样的方法(正则匹配)。
上是在cmd中的测试过程,可以看出来,我基本上都是用的都是//span[@data-book-type="1"]这种格式的Xpath,而非像FireFox浏览器上复制的Xpath,原因有两点:
1.从外形来看,显然我使用的这种Xpath要更好,至少长度上少很多(特别对于比较深的数据,如果像
`FireFox`这种,可能长度大于100也不奇怪)
2.从性能上来看,我是用的这种形式匹配更加准确,如果莫个页面包含js加载的数据(也包含div,p,a
等标签),如果我们直接分析`FireFox`这种Xpath,可能会出错。
建议:
(1)决心想学好的,把本文二中的Xpath语法好好记一下,练习一下;
(2)爬取网页抓取数据尽量用谷歌浏览器。
3.现在`jobbole.py`中的代码及运行结果
代码:
# -*- coding: utf-8 -*-
import scrapy
import re
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/114256/']
def parse(self, response):
# 标题
# chrome 浏览器返回的Xpath
re01_seletor = response.xpath('//*[@id="post-114256"]/div[1]/h1/text()')
re01_title = re01_seletor.extract()
# 发布日期
data_selector = response.xpath('//p[@class="entry-meta-hide-on-mobile"]/text()')
data_str = data_selector.extract()[0].strip()
data_time = data_str.replace('·','').strip()
# 点赞数
praise_number = int(response.xpath('//h10[@id="114256votetotal"]/text()').extract()[0])
# 收藏数
collection_str = response.xpath('//span[@data-book-type="1"]/text()').extract()[0]
reg_str = '.*(\d+).*'
collection_number = int(re.findall(reg_str,collection_str)[0])
print("文章标题:"+re01_title[0])
print("发布日期:"+data_time)
print("点赞数:"+str(praise_number))
print("收藏数:"+str(collection_number))
运行结果:
文章标题:Linux 内核 Git 历史记录中,最大最奇怪的提交信息是这样的
发布日期:2018/08/08
点赞数:1
收藏数:2
四、后言
学完这一期,大家应该能感受到爬虫的诱惑了哈,虽然现在我们还只是爬取的一个页面的文章标题等基本数据,最重要的是学会如何在cmd和pycharm中启动我们的爬虫项目和Xpath的学习,下一期,我将带大家使用CSS选择器,看看那个更好用,哈哈哈!
原文发布时间为:2018-09-7
本文作者:XksA
本文来自云栖社区合作伙伴“Python专栏”,了解相关信息可以关注“Python专栏”。
Python | Xpath实战训练相关推荐
- python语言训练教程_PYTHON零基础快乐学习之旅(K12实战训练)
本书在讲解Python编程语言语法概念的同时融入了相关的科学知识.随着人工智能技术的飞 速发展,编程教育越来越重要.编程的核心是算法和逻辑,是通往未来的语言.近期,国务院发 布<新一代看人工智能 ...
- python原创第十四篇~判断,循环实战训练+答案
2017-12-07 09:23:55 December Thursday the 49 week, the 341 day #原创第十四篇~判断,循环实战训练 题目:一个整数,它加上100后是一个完 ...
- 〖Python网络爬虫实战⑬〗- XPATH实战案例
订阅:新手可以订阅我的其他专栏.免费阶段订阅量1000+ python项目实战 Python编程基础教程系列(零基础小白搬砖逆袭) 说明:本专栏持续更新中,目前专栏免费订阅,在转为付费专栏前订阅本专栏 ...
- python爬虫图片实例-【图文详解】python爬虫实战——5分钟做个图片自动下载器...
我想要(下)的,我现在就要 python爬虫实战--图片自动下载器 之前介绍了那么多基本知识[Python爬虫]入门知识(没看的赶紧去看)大家也估计手痒了.想要实际做个小东西来看看,毕竟: talk ...
- selenium2 python自动化测试实战(回归测试)
selenium2 python自动化测试实战 最近接手商城的项目,针对后台测试,功能比较简单,但是流程比较繁多,涉及到前后台的交叉测试.在对整个项目进行第一轮测试完成之后,考虑以后回归测试任务比较重 ...
- python图像处理实战 戴伊_这一套封面的程序员专业书籍你读过哪一本?
以往我们总盯着畅销书,经典书,新书,今天给大家介绍Packt Publishing的程序员专业书籍.这一套封面的程序员书你读过哪一本? 1.Python图像处理实战 [印度] 桑迪潘·戴伊(Sandi ...
- qq纵横四海源码_【0基础】纵横中文网python爬虫实战
原文在此~ [0基础]纵横中文网python爬虫实战mp.weixin.qq.com 大家好,我是你们的机房老哥! 在粉丝群的日常交流中,爬虫是比较常见的话题.python最强大的功能之一也是爬虫. ...
- 我妈给我介绍对象了,我大学还没毕业呢,先在婚介市场也这么卷了的吗?【Python爬虫实战:甜蜜蜜婚介数据采集】
大家好,我是辣条. 说出来你们可能不信,我一个在校还没毕业的学生家里竟然给我介绍对象了-这么着急的吗?现在结婚市场都这么卷了吗?男孩们女孩们不努力的话是会被家里捉回去结婚的哦. 这是和我妈的聊天对话, ...
- python自动化测试实战-无涯(学习与研究)[一]
python自动化测试实战-无涯(学习与研究)[一] 一. 使用Selenium,下载的浏览器驱动文件,到底应该放在那里? 单个元素定位实战 一. 使用Selenium,下载的浏览器驱动文件,到底应该 ...
最新文章
- Android单元测试 mock Context,mock静态类的静态方法,测试方法的顺序
- [洛谷P1156][codevs1684]垃圾陷阱
- IOS客户端Coding项目记录导航
- java读取excel图表模板,修改选值范围
- Datawhale数据分析思考与问题解决
- halcon中的分水岭算法讲解以及作用和实例
- 车管所免检测审车流程
- try{}里有一个return语句,那么紧跟在这个try后的finally{}里的代码会不会被执行,是在return前还是后
- qt中socket编程
- Robot Framework + Pywinauto 框架实现Windows GUI Automation
- mysql的自身防御不包括_2020高校邦《MySQL数据库基础》作业题库2020智慧树《大学物理 Ⅰ》判断题答案...
- 最新版 FatFS f_mkfs 详解
- DAY DAY UP 1
- 隐式龙格库塔法举例说明
- 最新彩虹秒赞 V7.27免授权源码
- opencv实现视频和图像的转换
- 高仿墨迹天气-天鹰气象
- Istio金丝雀发布
- 智能链杀机器人 芬shib,慈善回流是怎样的合约部署原理?
- 基于OpenCASCADE自制三维建模软件(十一)使用ASSIMP导入导出