Java 从零开始学爬虫(gecco)
废话:
第一次学习并尝试分析、爬取一个网站的数据,全部是从零开始的经验,希望对各位看官有帮助,当然,本次爬取的是一个比较简单的网页,没有任何反爬虫措施的网页。
网上查了一下Java爬数据,最原始的方式是用请求网页的字符串然后用正则解析标签,再查了一下有什么爬虫、解析网页的工具,然后就查到了这个gecco,当是也没多想,就是干吧。
主要参考了两个博客:
1、入门到精通:https://segmentfault.com/a/1190000010086659
2、精通到放弃:https://blog.csdn.net/gf771115/article/details/53218022
最后附上官方地址:http://www.geccocrawler.com/
导入gecco包
maven代码:
<!--gecco抓包工具--><dependency><groupId>com.geccocrawler</groupId><artifactId>gecco</artifactId><version>1.0.8</version></dependency>目标网站
因为我是搞定了才会过来写博客的,所以就直奔主题,说明我主要要做什么了。
网站是:https://doutushe.com/portal/index/index
(站主要是看到了,请联系我删除,没看到的话,嘿嘿,我就不厚道的继续放着了)
经过观察,分页之后的格式是:https://doutushe.com/portal/index/index/p/1(没错,这个1就是对应页数)
页面大概是这样的:

然后每一个帖子的详情:https://doutushe.com/portal/article/index/id/XR5(最后的XR5是帖子id)
页面是这样的:
我的任务
我的任务很简单,就是把列表的所有的帖子的标题、所有的图片,这两个数据爬下来
逻辑
1、访问第1页
2、读取第一页的帖子列表,然后进入每一个帖子的帖子详情,将标题、图片列表的数据拿出来
3、访问下一页,然后遍历帖子列表拿数据,一直循环,直到没有下一页
第一步:解析第一页
废话:按照我做的时候,我解析第一页的时候,是先解析列表信息,最后才开始研究怎么解析出来哪个是下一页,现在是回过来写的,所以就一步到位了,直接解析第一页的列表信息和下一页的连接地址
1、创建一个类(我这里命名是:DoutuSheIndex)

大概意思是主要gecco爬了这个https://doutushe.com/portal/index/index/p/格式的网址,就会交给DuotusheIndex这个类来解析,后面这个popelines则是解析出来的结果传送到另外一个类做下一步处理,这个popelines算是一个标识,之后就会发现玄机。
我们通过页面的审查元素,可以看到列表的标签信息(如下图),我们所要的信息,基本上全部包含在这个class为link-2的a标签里面:

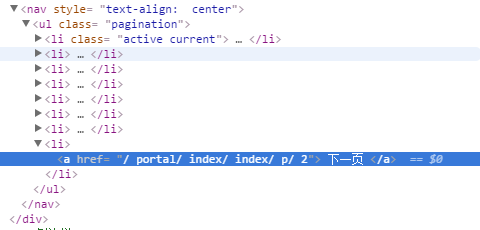
所以我分为两个List<String>用来分别保存列表的名称和详情页面的链接,即a标签的内容和a标签的href值,所以得到的解析为下图:

这里需要再次提醒的是,@Href注解不能单独使用,必须用@HtmlField定位到对应的地方,然后再在上方加上@Href标签才能拿到href的值,否则拿到的就是a标签的值,其他的注解用法,可以直接查看gecco官网的“使用手册”,吐槽一些,写得好简单,只有说明没有示例,有时候不太明白他的意思,又没有例子可以参考,蛋蛋的忧伤。
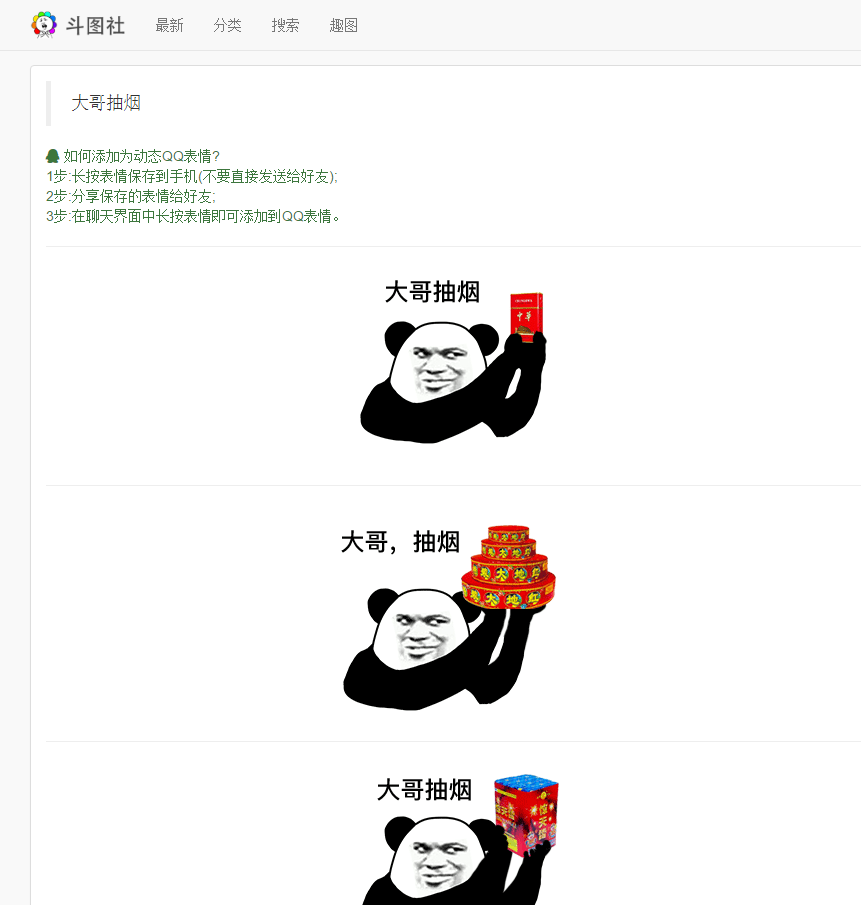
然后接着也需要将下一页的地址给解析出来,给分页审查元素的时候,得到下图:
我没有找到只解析后面一个或者是根据标签内容过滤的方法,所以我只能是用最原始的办法,就是将所有的分页链接都解析出来。所以就涉及到了另外一个东西,前面是解析单个内容,这次解析的话,除了解析分页的连接,我还需要页数,以判定是否是下一页,所以需要解析的是一个对象。
这东西跟json是一个道理,我要将一个东西直接解析为一个对象的时候,首先要将整个对象的数据拿下来,然后再把这串数据解析为对象。看上面的图,ul标签的li标签就是一个对象的数据,所以我们就将一个个li定位出来,也就有了下图的解析(IndexPageEntity是页数的对象)(建议第一次的时候,将IndexPageEntity改成String,看看输出了什么):

接着是IndexPageEntity:
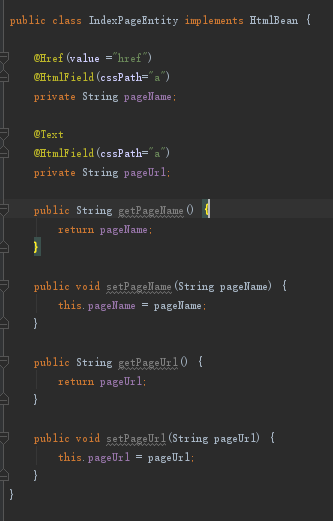
因为a里面已经包含了我们所要的信息,所以我们将a标签解析为我们需要的数据格式就可以了。
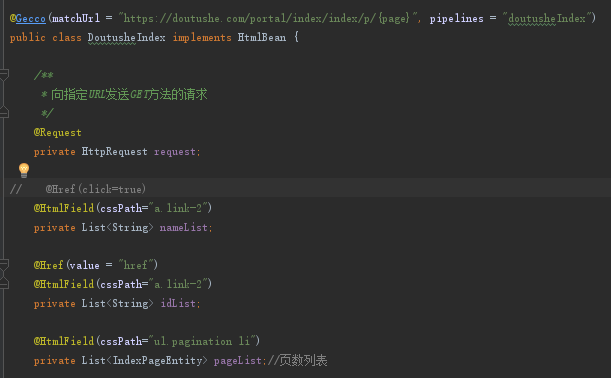
最后附上DoutusheIndex类的详细内容(省略get set方法,注:代码中必须要有)
2、创建一个类,我这里命名(FinishDoutusheIndex)
这个类就是前面提到的需要用到popelines的,这个类主要的作用就是等待DoutusheIndex类解析好了网页的内容之后,跳到这一个类来处理下一步的信息,比如我这里如下图这样写:

然后得到的输出结果是(我没有打印名称列表):

我们需要的信息已经打印出来了,所以我们需要完善我们的逻辑。
3、第一页的逻辑
第一页的数据我们其实不需要保存的,详情页的数据才是我们需要的,所以第一页的数据解析出来之后,就要执行我们的两个逻辑了:1、遍历列表(打开列表的每一个详情页)2、跳到下一页
所以我们改一下FinishDoutusheIndex就可以了,修改之后如下:
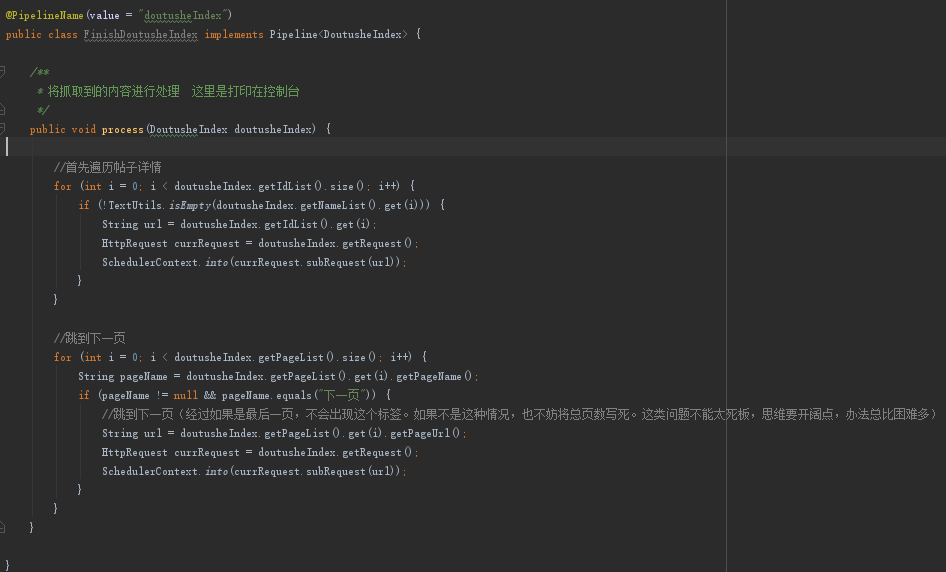
注:我们做好相关网页解析就好,如果访问了这个网页,url匹配的上的话,会调起解析程序,所以这里遍历的放心大胆的访问连接就可以了,不需要其他操作。
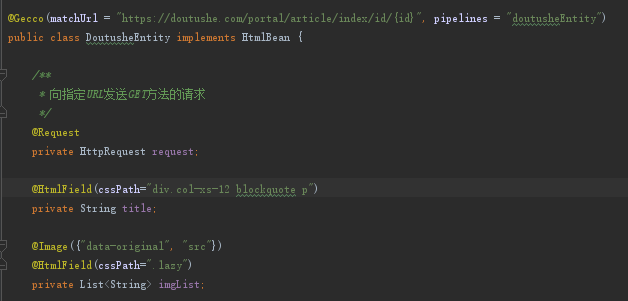
4、创建类DoutusheEntity、FinishDoutusheEntity
解析帖子详情,并对我们索需要的数据进行处理,该说的上面都说了,这里直接贴代码就好了。

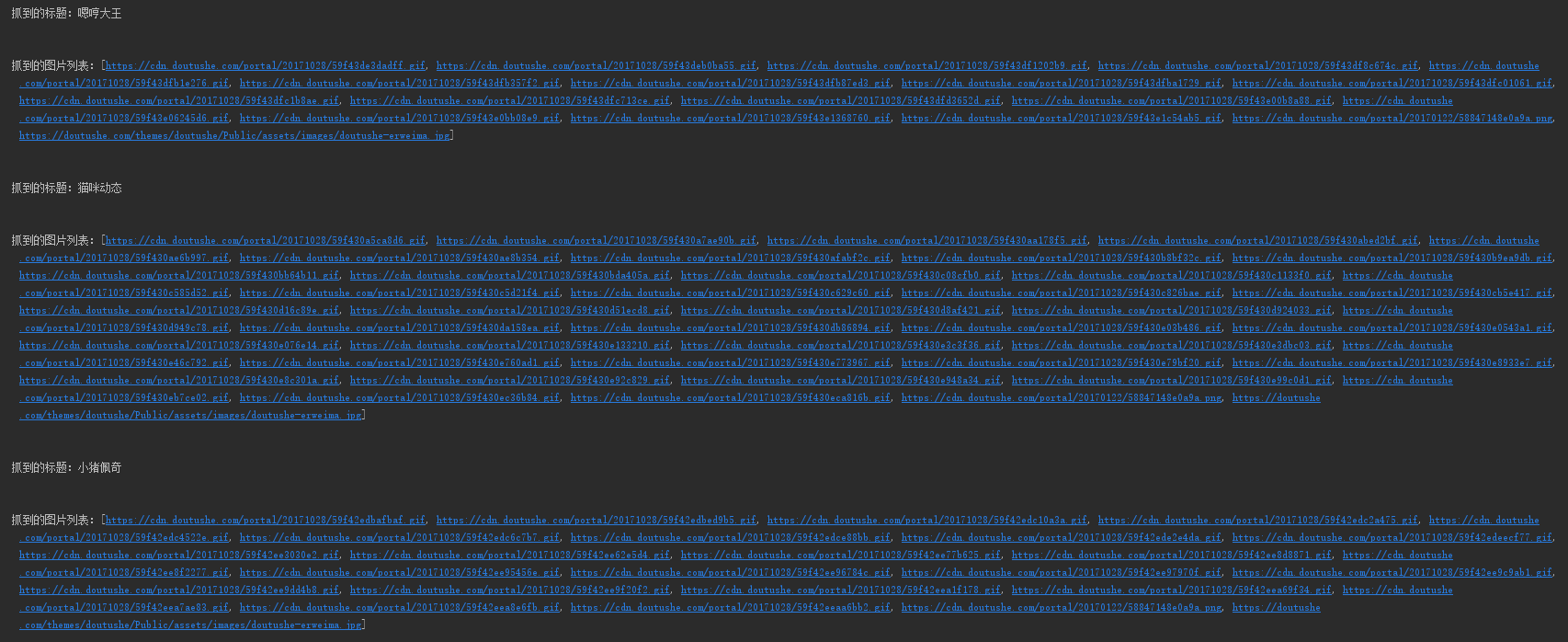
最后输出的结果,随便贴一点:
5、调用
![]()
OK,搞定
Java 从零开始学爬虫(gecco)相关推荐
- 从零开始学爬虫系列3:漫画下载,动态加载、反爬虫这都不叫事!
1 前言 前文回顾: 从零开始学爬虫系列1:初识网络爬虫之夜探老王家 从零开始学爬虫系列2:下载小说的正确姿势 经过上两篇文章的学习,爬虫三步走:发起请求.解析数据.保存数据,已经掌握,算入门爬虫了吗 ...
- Java从零开始学四十五(Socket编程基础)
一.网络编程中两个主要的问题 一个是如何准确的定位网络上一台或多台主机,另一个就是找到主机后如何可靠高效的进行数据传输. 在TCP/IP协议中IP层主要负责网络主机的定位,数据传输的路由,由IP地址可 ...
- Java从零开始学二十三(集合Map接口)
一.Map接口 Collection.Set.List接口都属于单值的操作,即:每次只能操作一个对象,而Map与它们不同的是,每次操作的是一对对象,即二元偶对象,Map中的每个元素都使用key à v ...
- Java从零开始学十四(包和访问控制)
一.java中的包 Java文件的组织形式Windows中的文件功能类似 在开发比较大的项目时,不可能只涉及到一个java文件,可能要创建几十,甚至几百个java文件,这个时候,我们就可以使用包,把相 ...
- python从零开始学爬虫_从零开始学爬虫(爬取豆瓣),一看就会
一. 准备工作 语言:python 编辑器:pycharm 需要导的包:bs4.re.urllib.xlwt(可以通过左上角file->settings->project->inte ...
- Java从零开始学三十六(JAVA IO- 字符流)
一.字符流 BufferedReader:BufferedReader是从缓冲区之中读取内容,所有的输入的字节数据都将放在缓冲区之中 BufferedWriter:把一批数据写入到缓冲区,当缓冲区区的 ...
- 从零开始学爬虫系列4:快速下载视频
1 前言 你知道的视频下载"姿势",有哪些吗? 本文绝对有你意想不到的玩法! 2 陈年往事 视频下载,跟图片下载其实并无差别,甚至更简单. 玩过视频下载的,应该对「you-get」 ...
- 【从零开始学爬虫】采集易贝(ebay)商品信息
l 采集网站 [场景描述]采集易贝(ebay)中某一类别的所有商品信息. [源网站介绍]易贝(eBay)是一个可让全球民众上网买卖物品的线上拍卖及购物网站.ebay于1995年9月4日由Pierre ...
- 【从零开始学爬虫】采集亚马逊商品信息
l 采集网站 [场景描述]采集亚马逊搜索关键词出来的商品信息. [入口网址]https://www.amazon.com/-/zh/ref=nav_logo [采集内容]采集亚马逊搜索关键词搜索出来的 ...
最新文章
- java笔试题(3)
- SharePoint 2007 如果在计算列中使用Today变量
- Django的静态资源
- 【POJ - 2186】Popular Cows (Tarjan缩点)
- 同步异步 阻塞非阻塞
- 光眼图和电眼图_一种电眼调试方法及装置制造方法及图纸
- Python中几个操作列表的内置函数filter(),map(),reduce(),lambda
- Week2 Teamework from Z.XML 软件分析与用户需求调查(三)必应助手体验评测
- 关于Tokenizer与TokenFilter的区别
- Qt Creator子目录项目-类似VS解决方案
- 多线程之使用读写锁ReentrantReadWriteLock实现缓存系统
- 宏基因组 微生物组 微生态杂志简介及2019最新影响因子
- 蓝桥杯_等差素数列_java
- python计算机二级刷题软件(未来教育) 第十五套
- 【程序员金典】字符串互异
- 个人音乐流媒体服务器mStream
- 基于SSM实现的儿童疫苗信息管理系统设计与实现 毕业设计-附源码311930
- 激光SLAM:Livox激光雷达硬件时间同步
- 对于自我的反省 - 对底层人民认知产生的商业思考
- Codeforces Raif Round 1 (Div. 1 + Div. 2) E. Carrots for Rabbits(优先队列+贪心)
热门文章
- 502含义php,微信小程序502是什么意思
- C语言输出ABBBCCCCCDDDDDDDCCCCCBBBA
- mysql lnk2019_“error LNK2019: 无法解析的外部符号”之分析
- VS报错LNK2019 无法解析的外部符号 _main,函数 “int __cdecl invoke_main(void)“ (?invoke_main@@YAHXZ) 中引用了该符号的解决方法
- myeclipse修改tomcat内存大小
- Oracle EBS R12经验谈(二)
- Shell中less命令使用
- Codeforces891C. Envy
- java springboot maven使用geotools
- 轻量级网络EdgeViTs论文翻译