Slot Filling详细讲解
1. 从一个栗子开始 - Slot Filling
比如在一个订票系统上,我们的输入 “Arrive Taipei on November 2nd” 这样一个序列,
我们设置几个槽位(Slot),希望算法能够将关键词'Taipei'放入目的地(Destination)槽位,
将November和2nd放入到达时间(Time of Arrival)槽位,将Arrive和on放入其他(Other)
槽位,实现对输入序列的一个归类,以便后续提取相应信息。
用前馈神经网络(Feedforward Neural Network)来解决这个问题的话,我们首先要对输入序列向量化,
将每一个输入的单词用向量表示,可以使用 One-of-N Encoding 或者是 Word hashing 等编码方法,输出预测槽位的概率分布。
但是这样做的话,有个问题就出现了。如果现在又有一个输入是 “Leave Taipei on November 2nd”,这里Taipei是作为一个出发地(Place of Departure),所以我们应当是把Taipei放入Departure槽位而不是Destination 槽位,可是对于前馈网络来说,
对于同一个输入,输出的概率分布应该也是一样的,不可能出现既是Destination的概率最高又是Departure的概率最高。
所以我们就希望能够让神经网络拥有“记忆”的能力,能够根据之前的信息(在这个例子中是Arrive或Leave)
从而得到不同的输出。将两段序列中的Taipei分别归入Destionation槽位和Departure槽位。
2. RNN
基本概念
在RNN中,隐层神经元的输出值都被保存到记忆单元中,下一次再计算输出时,隐层神经元会将记忆单元中的值认为是输入的一部分来考虑
RNN中考虑了输入序列顺序,序列顺序的改变会影响输出的结果。
常见变体
- Elman Network
将隐层的输出(即记忆单元中的值)作为下一次的输入
ht=σh(Whxt+Uhht−1+bh)ht=σh(Whxt+Uhht−1+bh)
yt=σh(Wyht+by)yt=σh(Wyht+by)
- Jordan Network
将上一时间点的输出值作为输入
ht=σh(Whxt+Uhyt−1+bh)ht=σh(Whxt+Uhyt−1+bh)
yt=σh(Wyht+by)yt=σh(Wyht+by)
- Bidirectional RNN
- Elman Network
3. Long Short-term Memory (LSTM)
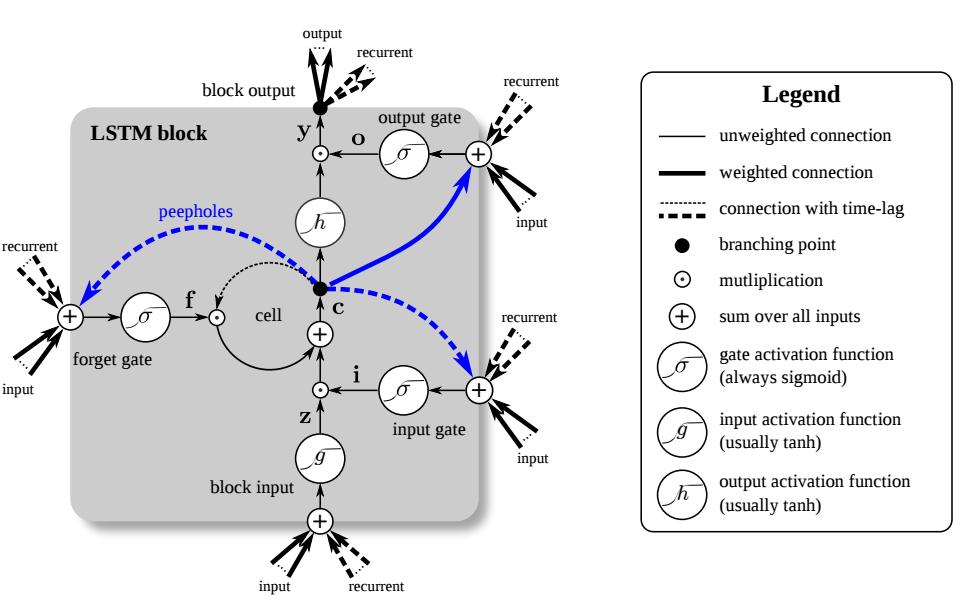
- 基本结构
- 由Memory Cell, Input Gate, Output Gate, Forget Gate 组成
- 特殊的神经元结构,包含4个input(三个Gate的控制信号以及输入的数据),1个output
- 激活函数通常选用sigmoid function, sigmoid的输出介于0到1之间,表征了Gate的打开程度。
Traditional LSTM
ftitotctht=σg(Wfxt+Ufht−1+bf)=σg(Wixt+Uiht−1+bi)=σg(Woxt+Uoht−1+bo)=ft∘ct−1+it∘σc(Wcxt+Ucht−1+bc)=ot∘σh(ct)(1)(2)(3)(4)(5)(1)ft=σg(Wfxt+Ufht−1+bf)(2)it=σg(Wixt+Uiht−1+bi)(3)ot=σg(Woxt+Uoht−1+bo)(4)ct=ft∘ct−1+it∘σc(Wcxt+Ucht−1+bc)(5)ht=ot∘σh(ct)
Peephole LSTM, 在大部分的情况下,用ct−1ct−1取代ht−1ht−1
ftitotctht=σg(Wfxt+Ufct−1+bf)=σg(Wixt+Uict−1+bi)=σg(Woxt+Uoct−1+bo)=ft∘ct−1+it∘σc(Wcxt+bc)=ot∘σh(ct)(6)(7)(8)(9)(10)(6)ft=σg(Wfxt+Ufct−1+bf)(7)it=σg(Wixt+Uict−1+bi)(8)ot=σg(Woxt+Uoct−1+bo)(9)ct=ft∘ct−1+it∘σc(Wcxt+bc)(10)ht=ot∘σh(ct)
- xtxt表示输入向量,htht表示输出向量,ctct表示记忆单元的状态向量,∘∘代表Hadamard product(A.k.a. Schur product)
- WW表示输入权重,UU表示循环权重,bb表示偏置
- δgδg代表sigmoid function,δcδc代表hyperbolic tangent, δhδh表示 hyperbolic tangent(peephole LSTM论文中建议选用δh(x)=xδh(x)=x)
- ftft,itit和otot表示门控向量值
- ftft表示遗忘门向量,表征记忆旧信息的能力
- itit表示输入门向量,表征获取新信息的能力
- otot表示输出门向量,表征输出信息的能力
- 补充知识点
- Short-term,表示保留对前一时间点输出的短期记忆,相比于最原始的RNN结构中的记忆单元(每次有新的输入时记忆体的状态就会被更新,因此是短期的记忆),而LSTM的记忆体则拥有相对较长的记忆时间(由Forget Gate决定),所以是Long Short-term
- LSTM一般采用多层结构组合,Multiple-layer LSTM
- Keras中实现了LSTM,GRU([Cho,Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation,EMNLP'14] 只有两个Gate,容易训练),SimpleRNN层,可以方便的调用。
4. RNN如何学习?
- 损失函数的定义:
- 每一个时间点的RNN的输出和标签值的交叉熵(cross-entropy)之和
- 训练过程:
- 使用被称作Backpropagation through time(BPTT)的梯度下降法
- 训练其实是比较困难的,因为Total Loss可能会出现剧烈的抖动
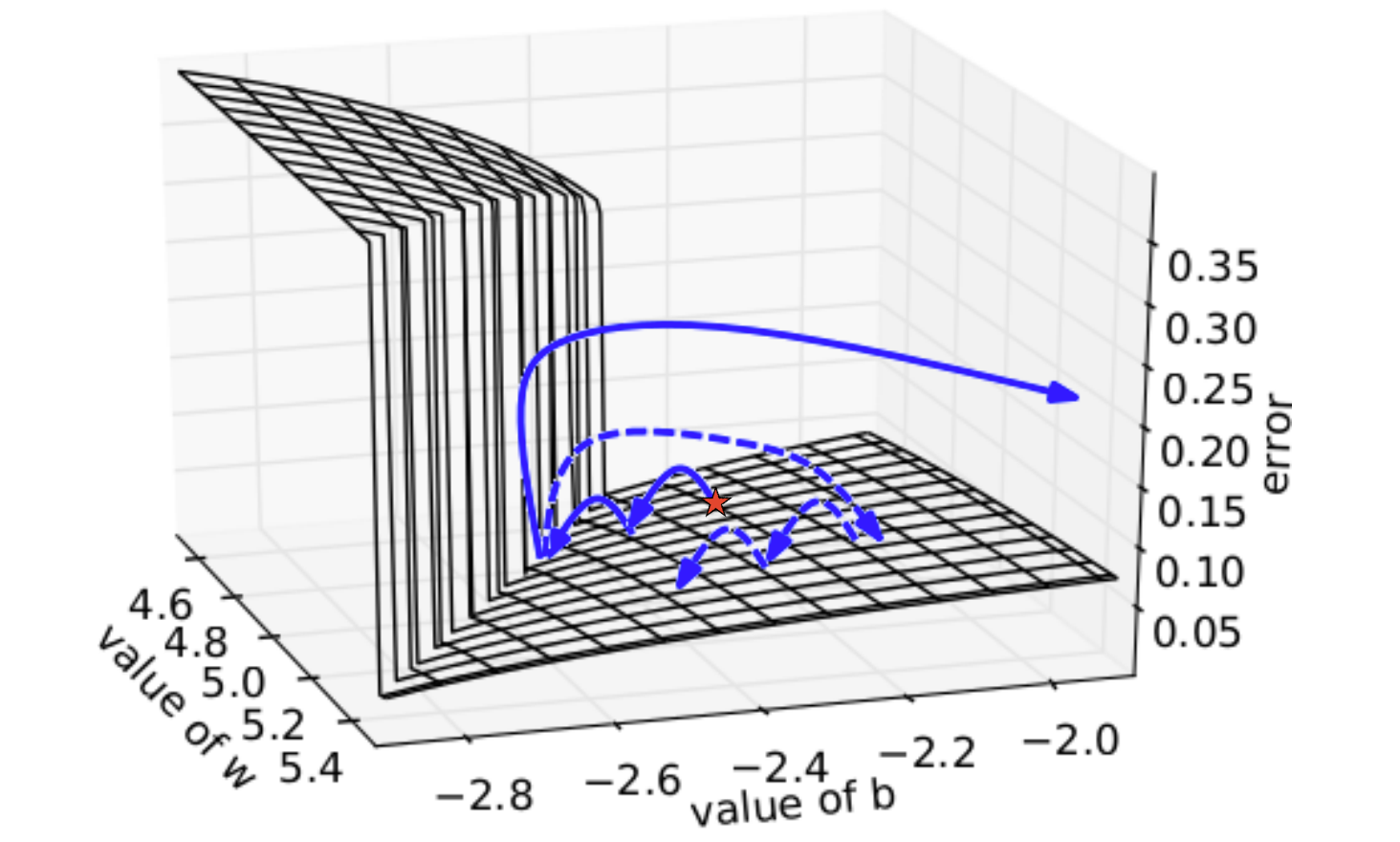
- 根据论文[Razvan Pascanu,On the difficulty of training Recurrent Neural Networks,ICML'13]上对RNN的分析,损失函数
- 的表面要么非常平坦,要么非常陡峭(The error surface is either very flat or very steep),当你的参数值在较为平坦的区域做更新时,因此该区域梯度值比较小,此时的学习率一般会变得的较大,如果突然到达了陡峭的区域,梯度值陡增,再与此时较大的学习率相乘,参数就有很大幅度更新(实线表示的轨迹),因此学习过程非常不稳定。Razvan Pascanu使用了叫做“Clipping”的训练技巧:为梯度设置阈值,超过该阈值的梯度值都会被cut,这样参数更新的幅度就不会过大(虚
- 线表示的轨迹),因此容易收敛。
- 为什么在RNN中会有这种问题?
- 是因为激活函数选用了sigmoid而不是ReLU么?然而并不是。事实上,在RNN中使用ReLU反而效果会不如Sigmoid,
- 不过也是看你的参数初始化值的选取,所以也不一定,比如后面提到的Quoc V.Le的那篇文章,使用特别初始化技巧硬训ReLU的RNN得到了可比拟LSTM的效果。因此激活函数并不是这里的关键点。
- 那究竟是什么原因呢?我们来分析梯度更新公式中的w−η∂L∂ww−η∂L∂w来探寻一番。但是这样一个偏微分的关系我们应该如何来分析呢?这里我们用一个技巧:给w值一个微小的变化,观察对应的Loss的变化情况。假设当前模型是1000个只含有一个线性隐层的RNN级联结构。并假设我们当前的输入是100000……(只有第一个值是1,剩下全是0),
- 因此最后的输出值是w999w999。现在假设我们ww的值是1,那么RNN在最后时间点的输出是1,给ww一个微小的变化+0.01,此时的输出变成了大约20000!这段区域呈现出一个陡峭的趋势。如果给ww一个微小的变化-0.01变为0.99,
- 测试的输出基本变成0,哪怕是ww变到0.01时,输出依旧是0,这段区域呈现出一个平坦的趋势。因此我们可以看出由于RNN采用时间序列的结构,权重值在不同时间点被反复使用,这种累积性的变化可能对结果造成极大的影响,也可能会很长一段时间保持平稳。
- 常用的技巧
- 使用LSTM单元。LSTM单元可以处理梯度消失问题,但无法处理梯度爆炸问题。为什么呢?这是因为RNN和LSTM对待记忆单元的做法是不同的,RNN中每一个时间点的记忆单元中的内容(状态)都会更新,而LSTM则是将记忆单元中的值与输入值相加(按某种权值)再更新状态,记忆单元中的值会始终对输出产生影响(除非Forget Gate完全的关闭),
- 因此不用担心梯度值会弥散,相反的,这倒极易引起梯度爆炸。
- 采用一些更新颖的结构或训练方法,比如:
- Clockwise RNN [Jan Koutnik,A Clockwork RNN,JMLR'14]
- Structurally Constrained Recurrent Network(SCRN)[Tomas Mikolov,Learning Longer Memory in Recurrent Neural Networks,ICLR'15]
- Vanilla RNN Initialized with Identity matrix + ReLU activation function [Quoc V.Le,A Simple Way to Initialize Recurrent Networks of Rectified Linear Units,arXiv'15]该位仁兄用了特别的初始化技巧,硬训RNN,
- 效果可比拟甚至超越LSTM
5. RNN的更多应用场景
- Sentiment Analysis 情感分析
- Key Term Extraction 关键字提取
- Speech Recognition 语音辨识
- Connectionist Temporal Classification(CTC):语音辨识中的一个关键技术,通过增加一个额外的Symbol代表NULL来解决叠字问题(参考论文[Graves, Alex, and Navdeep Jaitly. "Towards end-to-end speech recognition with recurrent neural networks." Proceedings of the 31st International Conference on Machine Learning (ICML-14). 2014.])。
- Sequence to sequence learning(输入和输出都是不同长度的序列)
- Machine Translation 机器翻译
- Syntactic parsing 句法分析
- Seq-to-seq Auto-encoder
- 将文档转换为向量表示(BoW模型会忽略掉语序,在某些情况下相反意思的语句会产生相同的词袋模型,
- 而RNN的方法考虑语序,因此更为鲁棒)
- 将语音转换为向量表示
- Attention-based Model 注意力模型
- Neural Turing Machine 神经图灵机
- Reading Comprehension
- [End-To-End Memory Networks. S. Sukhbaatar, A. Szlam, J. Weston, R. Fergus. NIPS, 2015.]
- 基于Keras实现的一个example
- 问答系统
6. 其他的学习资料
- The Unreasonable Effectiveness of Recurrent Neural Networks
- http://karpathy.github.io/2015/05/21/rnn-effectiveness/
- Understanding LSTM Networks
- http://colah.github.io/posts/2015-08-Understanding-LSTMs/
7. 本文参考资料
- Machine Learning (2016,Fall), Hung-yi Lee, NTU
- http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2016/Lecture/RNN%20(v2).pdf
- Deep Learning, Ian Goodfellow and Yoshua Bengio and Aaron Courville
- http://www.deeplearningbook.org/
- Deep Learning in a Nutshell: Sequence Learning
- https://devblogs.nvidia.com/parallelforall/deep-learning-nutshell-sequence-learning/
- Long short-term memory
- https://en.wikipedia.org/wiki/Long_short-term_memory
Deep & Structured 未完待
Slot Filling详细讲解相关推荐
- react的超详细讲解
create-react-app 项目目录 在HTML中使用react 1 2 3基础 React的注意事项 模拟的React 和 render React组件 函数组件 类组件 React 的数据源 ...
- Java字节码的详细讲解-刘宇
Java字节码的详细讲解-刘宇 一.字节码的整体结构 二.字节码范围解析 2.1.魔数 2.2.版本信息 2.3.常量池(constant pool) 2.4.描述符规则 2.5.访问标志(Acces ...
- 适合新手练手,用Python爬取OPGG里英雄联盟英雄胜率及选取率,详细讲解加注释(建议收藏练手)
今天来个简单的小项目,适合新手拿来练手,在OPGG上爬取英雄联盟里的法师,ADC,打野,辅助所有英雄的胜率及选取率,是不是感觉很高大上,但是却很简单,只要用三十多行代码就能实现,详细讲解每一行代码加注 ...
- Python的零基础超详细讲解(第十三天)-Python的类与对象
基础篇往期文章如下: Python的零基础超详细讲解(第一天)-Python简介以及下载 Python的零基础超详细讲解(第二天)-Python的基础语法1 Python的零基础超详细讲解(第三天)- ...
- Python的零基础超详细讲解(第十二天)-Python函数及使用
基础篇往期文章: Python的零基础超详细讲解(第一天)-Python简介以及下载_编程简单学的博客-CSDN博客 Python的零基础超详细讲解(第二天)-Python的基础语法1_编程简单学的博 ...
- Python的零基础超详细讲解(第七天)-Python的数据的应用
往期文章 Python的零基础超详细讲解(第一天)-Python简介以及下载_编程简单学的博客-CSDN博客 Python的零基础超详细讲解(第二天)-Python的基础语法1_编程简单学的博客-CS ...
- Python的零基础超详细讲解(第五天)-Python的运算符
往期文章 Python的零基础超详细讲解(第一天)-Python简介以及下载_编程简单学的博客-CSDN博客 Python的零基础超详细讲解(第二天)-Python的基础语法1_编程简单学的博客-CS ...
- java异常详细讲解_Java异常处理机制的详细讲解和使用技巧
一起学习 1. 异常机制 1.1 异常机制是指当程序出现错误后,程序如何处理.具体来说,异常机制提供了程序退出的安全通道.当出现错误后,程序执行的流程发生改变,程序的控制权转移到异常处理器. 1.2 ...
- 未来网络发展的趋势——IPv6详细讲解与基本配置
实验目的: 1. 掌握IPv6的基本工作原理: 2. 区别IPv6和IPv4有什么区别: 3. 掌握IPv6的一些新的特征: 4. 掌握IPv6的发展进程和部署情况: 实验拓扑: 实验步骤: 一. ...
最新文章
- Python多分类问题下,micro-PR计算以及macro-PR计算
- 011_Cascader级联选择器
- SpringBoot面向切面编程-用AOP方式管理日志
- eWebEditor不支持IE8的解决方法
- 升级鸿蒙系统效果,鸿蒙系统初体验 全方位体验升级[多图]
- matlab radn,如何用matlab编写randn函数?
- 再砸67亿!本硕博都给钱!该市带头抢人!
- 力荐联邦学习系统,据说英伟达Clara“上架”新进展!
- CSS:CSS定位和浮动
- Building beautiful User Interface in Android
- 阿里云发布ET环境大脑 对抗雾霾、排污和自然灾害
- dubbo源码之SPI机制源码
- 台达内部速度指令_【2017年整理】台达B2伺服电机参数设定.doc
- CryptoJS与C#AES加解密互转
- mcgs rtu方式通讯两台施耐德ATV312变频器示例 ,通讯实现触摸屏控制监控变频器,中间不需要plc
- sqlmap注入之tamper绕过WAF防火墙过滤
- 乘法计算机公式,Excel表格乘法函数公式
- 由火车上的查票事件所引起的思考
- 拦截广告的链接(注意软件的广告不拦截,只拦截桌面图标链接)
- Win10怎么关闭smartscreen筛选器检测功能?