多看一眼多进步,python入门到放弃
python相关工具都安装完成后,就可以开始学习了,以下在pycharm中,以下学习内容来自b站边学习边整理的笔记,好记性不如赖笔头,多总结多记录,总是不错的
print()函数的使用
- print函数可以输出哪些内容
(1)数字
(2)字符串
(3)含有运算符的表达式 - print()函数可以将内容输出的目的地
(1)显示器
(2)文件 - print()函数的输出形式
(1)换行
(2)不换行
具体代码如下:
#学习输出函数print
#数字
print(100)
print(98.5)
#字符串
print("hello world")
print('hello world')
#含有运算符的表达式
print(3+1)
#将数据输出到文件中,注意点:1.盘符必须存在2.使用file=fp(定义fp就写fp,定义a写a,随你咯)
#a+如果文件不存在就创建,存在就在文件内容的后面继续追加
fp = open("D:/test.txt",'a+')
print("hello word",file=fp)
fp.close()
#不进行换行输出,输出内容在一行中
print('hello','world','python')
转义字符
反斜杠+想要实现的转移功能的首字母
使用转义字符目的:
1.当字符串中包含反斜杠、单引号和双引号等有特殊用途的字符时,必须使用反斜杠对这些字符进行转义(转换一个含义)
- 反斜杠:\
- 单引号:’
- 双引号:"
2.当字符串中包含换行、回车、水平制表符或退格等无法直接表示的特殊字符时,也可以使用转义字符
- 换行:\n
newline光标 移动到下一行的开头 - 回车:\r
return光标 移动到本行的开头 - 水平制表符:\t
tab键,光标移动到下一组四个空格的开始处 - 退格:\b
键盘上的backspace键,回退一个字符
具体代码如下,为了方便进行了标号
#转义字符
print('1.hello\nworld')#\+转义功能的首字母 \n换行
print('2.hello\tworld') #\t tab键
print('3.helloooo\tworld')
print('4.hello\rworld')#\r world将hello进行了覆盖
print('5.hello\bworld')#\b是退一个格,将o退没了print('6.http:\\\\www.baidu.com')
print('7.他说:\"大家好啊!\"')#原字符 不希望字符串中的转义字符起作用,就使用原字符,就是在字符串之前加上r或R
print(r'8.hello\nworld')
#注意事项最后一个字符不能说反斜杠
#print(r'hello\nworld\')这一句会报错
print(r'9.hello\nworld\\')![]()
Python中的表示符和保留字
- 保留字
部分单词被赋予特定的意义,在给任何对象起名字时都不能用
如下图所示:
import keywordprint(keyword.kwlist)
部分截图
![]()
规则:
- 变量、函数、类、模块和其他对象起的名字就叫标识符
- 字母、数字、下划线
- 不可以以数字开头
- 不能时保留字
- 严格区分大小写
变量的定义和使用
- 变量就是内存中一个带标签的盒子,把需要的数据放进去
变量由三部分组成- 标识:表示对象所存储的内存地址,使用内置函数id(obj)来获取
- 类型:表示对象的数据类型,使用内置函数type(obj)来获取
- 值:表示对象所存储的具体数据,使用print(obj)可以将值进行打印输出
name = '张三'print(name)print('标识',id(name))print('类型',type(name))print('值',name)
![]()
当多次赋值之后,变量名会指向新的空间,之前的就是内存垃圾了
name = '张三'print(name)name = '李四'print(name)
![]()
数据类型
常用的数据类型
- 整数类型->int->98
- 浮点数类型->float->3.14259
- 布尔类型->bool->True,False
- 字符串类型->str->‘好好学习,我爱Python’
整数类型
英文为integer,简写为int,可以表示正数、负数和零
整数的不同进制表示方式
- 十进制:默认的进制,0~9,逢10进一。例:118
- 二进制:以0b开头,0~1,逢2进一。例:0b10101111
- 八进制:以0o开头,0~7,逢8进一。例:0o176
- 十六进制:以0x开头,0~9,A ~ F,逢16进一。例:0x1EAF
n1=99
n2=-99
n3=0
print(n1,type(n1))
print(n2,type(n2))
print(n3,type(n3))
print('十进制',116)
print('二进制',0b10101111)
print('八进制',0o176)
print('十六进制',0x1EAF
![]()
浮点类型
- 由整数部分和小数部分组成
- 浮点数存储具有不精确性
使用浮点数进行计算时,可能会出现小数位数不确定的情况,如下:
print(1.1+2.2)#3.3000000000000003
print(1.1+2.1)#3.2
![]()
解决方案:导入模块decimal
from decimal import Decimal
print(Decimal('1.1')+Decimal('2.2'))
![]()
布尔类型
用来表示真或假的值,True表示真,False表示假
布尔值可以转化为整数,True:1,False:0
print(True+1)#2
print(False+1)#1
字符串类型
又称不可变的字符序列
可以使用单引号’,双引号",三引号’''或"""来定义
单引号和双引号定义的字符串必须在一行
三引号定义的字符串可以分布在连续的多行
数据类型转换
目的:将不同数据类型的数据拼接在一起
函数str():
作用:将其他数据类型转成字符串
注意事项:也可用引号转换
举例:str(123),‘123’函数int():
作用:将其他数据类型转成整数
注意事项:- 文字类和小数类字符串,无法转换成整数
- 浮点数转化成整数:抹零取整
举例:int(‘123’),int(9.8)
函数float()
作用:将其他数据类型转换成浮点数
注意事项:- 文字类无法转成整数
- 整数转成浮点数,末尾为“.0”
举例:float(‘9.9’),float(9)

以下是代码演示:
#进行字符串拼接时name='张三'age=20print(type(name),type(age))#可以发现name和age的数据类型不同#print('我叫'+name+'今年'+age+'岁')#当将str类型与int类型进行连接时,报错,解决方案,类型转换print('我叫'+name+',今年'+str(age)+'岁')#将int类型的age通过str()函数转成了str类型print('---------str()将其他类型转换成str类型---------')a=10b=198.8c=Falseprint(type(a),type(b),type(c))print(str(a),str(b),str(c),type(str(a)),type(str(b)),type(str(c)))print('---------int()将其他类型转换成int类型---------')s1='128'f1=98.7s2='76.77'ff=Trues3='hello'print(type(s1),type(f1),type(s2),type(ff),type(s3))print(int(s1),type(int(s1)),'将str转换成int类型,前提是:字符串为数字串')#将str转换成int类型 字符串为数字串print(int(f1),type(int(f1)),'将float转换成int类型 截取整数部分,舍掉小数部分')#将float转换成int类型 截取整数部分,舍掉小数部分#print(int(s2),type(int(s2)))#将str转换成int类型,报错,因为字符串为小数串print(int(ff),type(int(ff)))#print(int(s3),type(int(s3)))#将str类型转成int类型,字符串必须是数字串(整数),非数字串不允许转换print('---------float()函数,将其他函数类型转换成float类型---------')s1='128.98's2='76'ff=Trues3='hello'i=98print(type(s1),type(s2),type(ff),type(s3),type(i))print(float(s1),type(float(s1)))print(float(s2),type(float(s2)))print(float(ff),type(float(ff)))#字符串中的数据如果是非字符串,则不允许转换print(float(i),type(float(i)))
![]()
注释
提高代码的可读性,注释的内容会被Python解释器忽略
通常包含三种类型的注释
- 单行注释:以“#”开头,指导换行结束
- 多行注释:并没有单独的多行注释标记,将一对三引号之间的代码称为多行注释
- 中文编码声明注释:在文件开头加上中文声明注释,用以制动源码文件的编码格式
#coding:gbk
第三章
1.输入函数input()
input()函数介绍:
![]()
基本使用:
present=input(“你是谁?”)
present: 变量
=: 赋值运算符,将输入函数的结果赋值给变量present
input()函数:是一个输入函数,需要输入回答
#输入函数input()
present=input('你是谁?')
print(present,type(present))
![]()
input()函数的高级应用
输入两个整数进行相加求和
a=int(input('请输入第一个整数'))
b=int(input('请输入第二个整数'))
print(a+b)
![]()
2.Python中的运算符
2.1算术运算符
2.1.1标准算术运算符
加(+),减(-),乘(*),除(/),整除(//)
2.1.2取余运算符
%
2.1.3幂运算符
**
整除(//):一正一负向下取整
取余(%):一正一负要公式
余数=被除数-除数*商
#我们常见的
print(9//4)#2
print(9//4)#2
#一正一负向下取整
print(9//-4)#-3
print(-9//4)#-3
#一正一负,余数=被除数-除数*商
print(9%-4)#-3 9-(-4)*(-3)=-3
print(-9%4)#3 -9-4*(-3)=3
2.2赋值运算符
=
执行顺序:右->左
支持链式赋值:a=b=c=20
支持参数赋值:+=,-=,*=,/=,//=,%=
支持系列解包赋值:a,b,c=20,30,40
i=3+4
print(i)
print('------链式赋值------')
a=b=c=20
print(a,id(a))
print(b,id(b))
print(c,id(c))
print('------支持参数赋值------')
a=20
a+=30 #相当于a=a+30
print(a)
a-=10 #相当于a=a-10
print(a)
a*=2 #相当于a=a*2
print(a)
a/=3
print(a,type(a))
a//=2
print(a,type(a))
print('------解包赋值------')
a,b,c=20,30,40
print(a,b,c)
print('------交换两个变量的值------')
a,b=10,20
print('交换之前:',a,b)
#交换
a,b=b,a
print('交换之后:',a,b)2.3比较运算符
对变量或表达式的结果进行大小、真假等比较
比较运算符:>,<,>=,<=,!=
==:对象的value比较
is,is not:对象的id比较
#比较远算符,比较运算符的结果是bool类型
a,b=10,20
print('a>b吗?',a>b)#False
print('a<b吗?',a<b)#True
print('a<=b吗?',a<=b)#True
print('a>=b吗?',a>=b)#False
print('a==b吗?',a==b)#False
print('a!=b吗?',a!=b)#True
'''
一个 = 称为赋值运算符,==称为比较运算符
一个变量由三部分组成:标识、类型、值
==比较的是值
is比较的是对象的标识
'''
a=10
b=10
print(a==b)#True 说明a与b的value相等
print(a is b)#True 说明a与b的id标识相等
print('以此为分界')
lst1=[11,22,33,44]
lst2=[11,22,33,44]
print(lst1==lst2)#value True
print(lst1 is lst2)#id False
print(id(lst1))
print(id(lst2))
print(a is not b)# “a is not b“的意思是:a的id与b的id是不相等的吗 False
print(lst1 is not lst2)#True
2.4布尔运算符
对于布尔值之间的运算
and,or,not,in,not in
and 当两个运算数都为True时,运算结果才为True
or只要有一个运算数为True,运算结果就为True
not如果运算数为True,运算结果为False,如果运算数为False,运算结果为True
#布尔运算符
a,b=1,2
print('------and------')
print(a==1 and b==2) #True and True ->True
print(a==1 and b<2) #True and False ->False
print(a!=1 and b==2)#False and True ->False
print(a!=1 and b!=2)#False And False ->False
print('------or------')
print(a==1 or b==2) #True or True ->True
print(a==1 or b<2) #True or False ->True
print(a!=1 or b==2)#False or True ->True
print(a!=1 or b!=2)#False or False ->False
print('------not 对bool类型操作数取反------')
f1=True
f2=False
print(not f1)
print(not f2)
print('------in 与 not in------')
s = 'helloworld'
print('w'in s)#True
print('k'in s)#False
print('w' not in s)#False
print('k'not in s)#True2.5位运算符
将数据转成二进制进行计算
位与:& 对应数位都是1,结果数位才是1,否则为0
位或:|对应数位都是0,结果数位才是0,否则为1
左移位运算符:<< 高位溢出舍弃,低位补0
右移位运算符:>>低位溢出舍弃,高位补0
print(4&8)# 0 按位与&,同为1时结果为1
print(4|8)# 12 按位或|,同为0时结果为0
print(4<<1)# 8 向左移动1位(移动一个位置)相当于*2
print(4<<2)# 16 向左移动2位(移动2个位置)相当于*4print(4<<1)#向左移动1位(移动一个位置)相当于*2
print(4>>1)# 2 向右移动1位(移动一个位置)相当于➗2
print(4>>2)# 1 向右移动2位(移动2个位置)相当于➗4
3.运算符的优先级
![]()
第四章 程序的组织结构
任何简单或复杂的算法都可以由顺序结构、选择结构和循环结构三种基本结构组合而成
4.1顺序结构
程序从上到下顺序的执行代码,中间没有任何的判断和跳转,直到程序结束
#顺序结构
'''把大象装进冰箱一共分几步'''
print('------程序开始------')
print('1.把冰箱门打开')
print('2.把大象放进冰箱里')
print('3.把冰箱门关上')
print('------程序结束------')
对象的布尔值
所有对象都有一个布尔值
获取对象的布尔值:
使用内置函数bool()
以下对象的布尔值为FalseFalse
数值0
None
空字符串
空列表
空元组
空字典
空集合
#测试对象的布尔值
print('以下对象的布尔值都是False')
print(bool(False))
print(bool(0))
print(bool(0.0))
print(bool(None))
print(bool(''))
print(bool(""))
print(bool([]))#空列表
print(bool(list()))#空列表
print(bool(()))#空元组
print(bool(tuple()))#空元组
print(bool({}))#空字典
print(bool(dict()))#空字典
print(bool(set()))#空集合
print('------其他对象的布尔值均为True------')
print(bool(18))
print(bool(True))
print(bool('hello'))
4.2选择结构
程序根据判断条件的布尔值选择性的执行部分代码
明确地让计算机知道在什么条件下。该去做什么。
单分支结构
money=1000#余额
s=int(input('请输入取款金额'))#取款金额
#判断余额是否充足
if money>=s:money=money-sprint('取款成功,余额为:',money)
运行结果
请输入取款金额1000
取款成功,余额为: 0
双分支结构
如果…不满足…就…
语法结构:
if 条件表达式:条件执行体1
else条件执行体2
#输入一个数判断奇偶
num=int(input('请输入一个整数'))
if num%2==0:print(num,'是一个偶数')
else:print(num,'是一个奇数')
多分支结构
if 条件表达式1:条件执行体1
elif 条件表达式2:条件执行体2......
elif 条件表达式N:条件执行体N
[else:]条件执行体N+1
判断成绩等级代码
'''
输入一个成绩,判断成绩等级
A级 90~100
B级 80~89
C级 70~79
D级 60~69
E级 0~59
其他,不合法数据,不在成绩有效范围内
'''
score=int(input('请输入成绩:'))
if score>=90 and score<=100:print('A级')
elif score>=80 and score<=89:print('B级')
elif score>=70 and score<=79:print('C级')
elif score>=60 and score<=69:print('D级')
elif score>=0 and score<=59:print('E级')
else:print('对不起,成绩有误,不在成绩的有效范围')
嵌套if
#语法结构
if 条件表达式1:if 内层条件表达式:内层条件执行体1else:内存条件执行体2
else:条件执行体
'''
会员 >= 200 8折>=100 9折其它 不打折
非会员 >= 200 9.5折其它 不打折
'''
answer=input('请输入您是会员吗?y/n')
money=float(input('请输入您的购物金额:'))
if answer=='y':if money>=200:print('打八折,您的购物金额为:',money*0.8)elif money>=100:print('打九折,您的购物金额为:',money*0.9)else:print('不打折,您的购物金额为:',money)
else:if money>=200:print('打九五折,您的购物金额为:',money*0.95)else:print('不打折,您的购物金额为:',money)
条件表达式
条件表达式是if…else的简写
#语法结构
x if 判断条件 else y
运算规则
如果判断条件的布尔值为True,条件表达式的返回值为x,否则条件表达式的返回值为y
从键盘录入两个整数,比较两个整数的大小代码如下:
'''
从键盘录入两个整数,比较两个整数的大小
'''
num_a = int(input('请输入第一个整数'))
num_b = int(input('请输入第二个整数'))
'''
print('------常规if else比较大小')
if num_a>=num_b:print(num_a,'>=',num_b)
else:print(num_a,'<',num_b)
'''
print('条件表达式比较大小')
print(str(num_a) + '>=' + str(num_b) if num_a >= num_b else str(num_a) + '<' + str(num_b))pass语句
语句什么也不做,只是一个占位符,用在语法上需要语句的地方
- 什么时候使用:
先搭建语法结构,还没想好代码怎么写的时候 - 哪些语句一起使用
if语句的条件执行体
for-in语句的循环体
定义函数时的函数体
第五章
5.1内置函数range()
range()函数:
1.用于生成一个整数序列
2.创建range对象的三种方式
- range(stop):创建一个(0,stop)之间的整数序列,步长为1
- range(start,stop):创建一个(start,stop)之间的整数序列,步长为1
- range(start,stop,step):创建一个(start,stop)之间的整数序列,步长为step
3.返回值是一个迭代器对象
4.range类型的优点:不管range对象表示的整数序列有多长,所有range对象占用的内存空间都是相同的,因为仅仅需要存储start,stop和step,只有当用到range对象时,才会计算序列中的相关元素
5.in与not in判断整数序列中是否存在(不存在)指定的整数
具体的相关代码示例如下:
#range的三种创建方式
'''第一种创建方式,只有一个参数(小括号中只给了一个数)'''
print('第一种创建方式,只有一个参数(小括号中只给了一个数)')
r=range(10) #[0,1,2,3,4,5,6,7,8,9],默认从0开始,默认相差1为步长
print(r)#range(0,10)
print(list(r))#用于查看range对象中的整数序列,list是列表的意思
'''第二种创建方式,给了两个参数(小括号中给了两个数)'''
print('第二种创建方式,给了两个参数(小括号中给了两个数)')
r=range(1,10)#指定了起始值,从1开始,到10结束(不包含10),默认步长为1
print(list(r))#[1, 2, 3, 4, 5, 6, 7, 8, 9]
'''第三种创建方式,给定了三个参数(小括号中给了三个数)'''
print('第三种创建方式,给定了三个参数(小括号中给了三个数)')
r=range(1,10,2)#指定了起始值,从1开始,到10结束(不包含10),默认步长为2
print(list(r))#[1, 3, 5, 7, 9]
5.2循环结构
1.反复做同一件事的情况,称为循环
2.循环的分类:
- while
- for-in
while
3.语法结构
while 条件表达式条件执行体(循环体)
4.选择结构的if和循环结构while的区别
- if是判断一次,条件为True执行一次
- while是判断N+1次,条件为True执行N次
while循环的执行流程
四步循环法
1.初始化变量
2.条件判断
3.条件执行体(循环体)
4.改变变量
'''计算1+2+3+4'''
#初始化变量
sum=0
i=0
#条件判断
while i<5:#条件执行体(循环体)sum=sum+i#改变变量i=i+1
print(sum)
计算1~100之间的偶数和
'''计算1到100之间的偶数和'''
sum=0#用于存储偶数和
'''初始化变量'''
a=1
'''条件判断'''
while a<=100:'''条件执行体(求和)'''#条件判断是否是偶数#if a%2==0:#写法1if not bool(a%2):#写法2,其中不带not是求奇数和sum=sum+a'''改变变量'''a=a+1
print('1~100之间的偶数和',sum)
for-in循环
- in表达从(字符串、序列等)中依次取值,又称为遍历
- for-in遍历的对象必须是可迭代对象
- 语法结构:
for 自定义的变量 in 可迭代对象:循环体
- 循环体内不需要访问自定义变量,可以将自定义变量替代为下划线
for item in 'Python':#第一次取出的是P,将P赋值item,将item的值输出print(item)''' Python'''#range产生一个整数序列,也就是一个可迭代对象
for i in range(10):print(i)''' 0123456789
'''
#如果在循环中不需要使用到自定义变量,就将自定义变量写为“-”
for _ in range(5):print('人生苦短,我要好好学习!')
''' 人生苦短,我要好好学习!人生苦短,我要好好学习!人生苦短,我要好好学习!人生苦短,我要好好学习!人生苦短,我要好好学习!'''
print('使用for循环计算1到100之间的偶数和')
sum=0#用于存储偶数和
for item in range(0,101):if item%2==0:sum=sum+item
print('1到100之间的偶数和',sum)#1到100之间的偶数和 2550
使用for循环输出100~999的水仙花数
'''输出100-999之间的水仙花数'''
for i in range(100,1000):bai=i//100shi=i//10%10ge=i%10#print(bai,shi,ge)if bai**3+shi**3+ge**3 == i:print(i)''' 153370371407'''流程控制语句
break
break语句,用于结束循环结构,通常和分支结构if一起使用
for ... in ......if ...:break
三次机会输入密码。密码正确运行结束
for i in range(3):pwd=input('请输入密码:')if pwd == '8888':print('密码正确')breakelse:print('密码错误')
while (条件):...if ...:break
a=0
while a<3:pwd=input('请输入密码')if pwd=='8888':print('密码正确')breakelse:print('密码错误')a+=1
continue
用于结束当前循环,进入下一次循环,通常与分支结构中的if一起使用
![]()
for ... in ......if ...:continue
while (条件):...if ...:continue
'''要求输出1-50之间所有5的倍数5,10,15,20......'''
#法一
for item in range(1,51):if item%5==0:print(item)
#法2
print('使用continue')
for i in range(1,51):if i%5!=0:continueelse:print(i)else语句
与else语句配合使用的三种情况
if...:...else:#if表达式不成立时执行else...
while ...:...
else:#没有碰到break语句执行else...
for...:...
else:#没有碰到break语句执行else...
for 版
for item in range(3):pwd=input('请输入密码:')if pwd=='8888':print('密码正确')breakelse:print('密码错误')
else:print('对不起,已经连续三次密码输入错误')
while版
a=0
while a<3:pwd=input('请输入密码:')if pwd=='8888':print('密码正确')breakelse:print('密码错误,重新输入')a=a+1
else:print('对不起,已经连续三次密码输入错误')
嵌套循环
循环结构中又嵌套了另外的完整的循环结构,其中内层循环作为外岑故乡你换的循环体执行
#输出一个三行四列的矩形
for i in range(1,4):#行表,执行三次,一次是一行for j in range(1,5):print('*',end='\t')#不换行输出print()#打行
运行结果
* * * *
* * * *
* * * *
for i in range(1,10):#行数for j in range(1,i+1):print('*',end=' ')print()
执行结果
*
* *
* * *
* * * *
* * * * *
* * * * * *
* * * * * * *
* * * * * * * *
* * * * * * * * *
输出99乘法表
#99乘法表
for i in range(1,10):#行数for j in range(1,i+1):print(i,'*',j,'=',i*j,end='\t')print()
1 * 1 = 1
1 * 2 = 2 2 * 2 = 4
1 * 3 = 3 2 * 3 = 6 3 * 3 = 9
1 * 4 = 4 2 * 4 = 8 3 * 4 = 12 4 * 4 = 16
1 * 5 = 5 2 * 5 = 10 3 * 5 = 15 4 * 5 = 20 5 * 5 = 25
1 * 6 = 6 2 * 6 = 12 3 * 6 = 18 4 * 6 = 24 5 * 6 = 30 6 * 6 = 36
1 * 7 = 7 2 * 7 = 14 3 * 7 = 21 4 * 7 = 28 5 * 7 = 35 6 * 7 = 42 7 * 7 = 49
1 * 8 = 8 2 * 8 = 16 3 * 8 = 24 4 * 8 = 32 5 * 8 = 40 6 * 8 = 48 7 * 8 = 56 8 * 8 = 64
1 * 9 = 9 2 * 9 = 18 3 * 9 = 27 4 * 9 = 36 5 * 9 = 45 6 * 9 = 54 7 * 9 = 63 8 * 9 = 72 9 * 9 = 81
二重循环中的break和continue
用于控制本层循环
'''流程控制语句break和continue在二重循环中的使用'''
for i in range(5):for j in range(1,11):if j%2==0:break#continueprint(j,end='\t')
print()
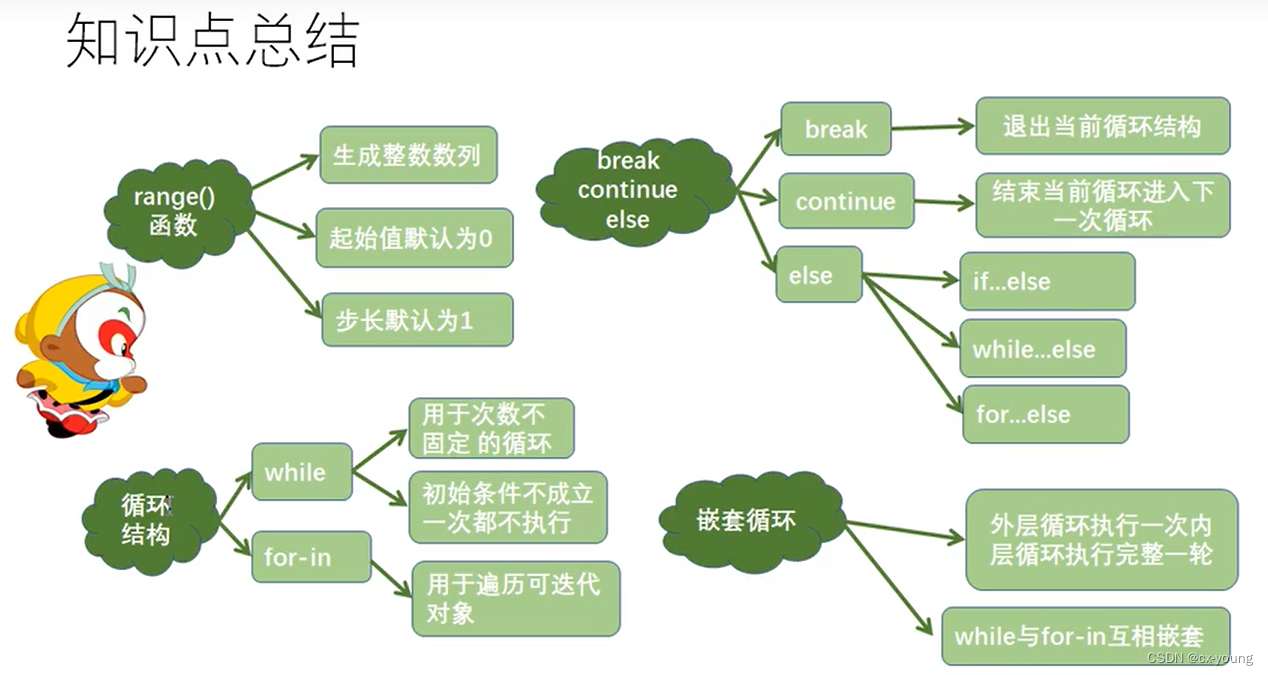
本章总结
第六章
为什么需要列表?
- 变量可以存储一个元素,而列表是一个“大容器”可以存储N多个元素,程序可以方便地对这些数据进行整体操作
- 列表详单与其它语言中的数组
- 列表示意图
代码演示
a=10#变量存储的是一个对象的引用
lst=['hello','world',98]
print(id(lst))
print(type(lst))
print(lst)
运行结果
3005041993416
<class 'list'>
['hello', 'world', 98]
列表的创建
列表需要使用中括号[],元素之间使用英文的逗号进行分割
内存示意图
![]()
列表的创建方式
- 使用中括号
- 调用内置函数list()
'''创建列表的第一种方式,使用[]'''
lst=['hello','world',98]
print(lst)
print(lst[0])
print(lst[-3])
'''创建列表的第二种方式,使用内置函数list()'''
lst2=list(['hello','world',98])
print(lst2)
运行结果
['hello', 'world', 98]
hello
hello
['hello', 'world', 98]
列表的特点
- 列表元素按顺序有序排序
- 索引映射唯一一个数据
- 列表可以存储重复数据
- 任意数据类型混存
- 根据需要动态分配或回收内存
列表的查询操作
获取列表中指定元素的索引
index():
- 如所查询列表中存在N个相同元素,只返回相同元素中的第一个元素的索引
- 如果查询的元素在列表中不存在,则会抛出ValueError
- 还可以在指定的start和stop之间进行查找
lst=['hello','world',98,'hello']
#如果列表中有相同元素只返回列表中相同元素的第一个元素的索引
print(lst.index('hello'))#0
#ValueError: 'Python' is not in list
# print(lst.index('Python'))
#ValueError: 'hello' is not in list
#print(lst.index('hello',1,3))#1,2相当于'world',98
print(lst.index('hello',1,4))#3
获取列表中的单个元素
- 正向索引从0到N-1,举例:lst[0]
- 逆向索引从-N到-1,举例:lst[-N]
- 指定索引不存在,抛出indexError
lst=['hello','world',98,'hello','world',234]
#获取索引为2的元素
print(lst[2])
#获取索引为-3的元素
print(lst[-3])
#获取索引为10的元素
#此处报错 IndexError: list index out of range 超出索引范围
#print(lst[10])
获取列表中的多个元素
#语法格式
列表名[start:stop:step]
| 切片操作 | |||
|---|---|---|---|
| 切片的结果 | 原列表片段的拷贝 | ||
| 切片的范围 | [start:stop) | ||
| step默认为1 | 简写为[start:stop] | ||
| step为正数 | [:stop:step] | 切片的第一个元素默认是列表的第一个元素 | 从start开始往后计算切片 |
| [start::step] | 切片的最后一个元素默认是列表的最后一个元素 | 从start开始往后计算切片 | |
| step为负数 | [:stop:step] | 切片的第一个元素默认是列表的最后一个元素 | 从start开始往前计算切片 |
| [start::step] | 切片的最后一个元素默认是列表的第一个元素 | 从start开始往前计算切片 |
lst=[10,20,30,40,50,60,70,80]
#start=1,stop=6,step=1
print(lst[1:6:1])
print('原列表:',id(lst))
print('切的片段:',id(lst[1:6:1]))
print(lst[1:6])#默认步长为1
print(lst[1:6:])#默认步长为1
#start=1,stop=6,step=2
print(lst[1:6:2])
#stop=6,step=2,start采用默认
print(lst[:6:2])
#start=1,step=2,stop采用默认
print(lst[1::2])
print('以下是step步长为负数的情况')
print('原列表:',lst)
print(lst[::-1])
#start=7,stop省略,step=-1
print(lst[7::-1])
#start=6,step=0,step=-2
print(lst[6:0:-2])
运行结果
[20, 30, 40, 50, 60]
原列表: 2435934054088
切的片段: 2435933182344
[20, 30, 40, 50, 60]
[20, 30, 40, 50, 60]
[20, 40, 60]
[10, 30, 50]
[20, 40, 60, 80]
以下是step步长为负数的情况
原列表: [10, 20, 30, 40, 50, 60, 70, 80]
[80, 70, 60, 50, 40, 30, 20, 10]
[80, 70, 60, 50, 40, 30, 20, 10]
[70, 50, 30]
判断指定元素在列表中是否存在
元素 in 列表名
元素 not in 列表名
print('P' in 'Python')#True
print('k' not in 'Python')#True
lst=[10,20,'python','hello']
print(10 in lst)#True
print(100 in lst)#False
print(10 not in lst)#False
print(100 not in lst)#True
列表元素的遍历
for 迭代变量 in 列表名:操作
lst=[10,20,'python','hello']
for i in lst:print(i)
列表元素的增加操作
| 方法 | 操作描述 |
|---|---|
| append() | 在列表的末尾添加一个元素 |
| extend() | 在列表的末尾至少添加一个元素 |
| insert() | 在列表的任意位置添加一个元素 |
| 切片 | 在列表的任意位置至少添加一个元素 |
#向列表的末尾添加一个元素
lst=[10,20,30]
print('添加元素之前',lst,id(lst))
lst.append(100)
print('添加元素之后',lst,id(lst))
lst2=['hello','world']
#将lst2作为一个元素添加到列表的末尾
lst.append(lst2)
print(lst)#向列表的末尾一次性添加多个元素
lst.extend(lst2)
print(lst)#在任意位置添加一个元素
lst.insert(1,90)
print(lst)lst3=[True,False,'hello']
#在任意位置添加N多个元素
lst[1:]=lst3
print(lst)运行结果
添加元素之前 [10, 20, 30] 1342114490056
添加元素之后 [10, 20, 30, 100] 1342114490056
[10, 20, 30, 100, ['hello', 'world']]
[10, 20, 30, 100, ['hello', 'world'], 'hello', 'world']
[10, 90, 20, 30, 100, ['hello', 'world'], 'hello', 'world']
[10, True, False, 'hello']
元素的删除操作
| 方法 | 操作描述 |
|---|---|
| remove() | 一次删除一个元素 |
| 重复元素只删除第一个 | |
| 元素不存在抛出ValueError | |
| pop() | 删除一个指定索引位置上的元素 |
| 指定索引不存在抛出IndexError | |
| 不指定索引,删除列表中最后一个元素 | |
| 切片 | 一次至少删除一个元素 |
| clear() | 清空列表 |
| del | 删除列表 |
lst=[10,20,30,40,50,60,30]
#从列表中移除一个元素,如果有重复元素只移第一个元素
lst.remove(30)
print(lst)#[10, 20, 40, 50, 60, 30]
#lst.remove(100)#ValueError: list.remove(x): x not in list#pop()根据索引移除元素
lst.pop(1)
print(lst)#[10, 40, 50, 60, 30]
#若指定索引位置不存在,将抛出异常IndexError: pop index out of range
#lst.pop(5)#如果不指定参数(索引),将删除列表中的最后一个元素
lst.pop()
print(lst)#[10, 40, 50, 60]print('切片操作-删除至少一个元素,将产生一个新的列表对象')
new_lst=lst[1:3]
print('原列表',lst)#原列表 [10, 40, 50, 60]
print('切片后',new_lst)#切片后 [40, 50]
print('不产生新的列表对象,而是删除原列表中的内容')
lst[1:3]=[]
print(lst)#[10, 60]#清空列表中的所有元素
lst.clear()
print(lst)#[]
#del语句将列表对象删除
del lst
#print(lst)#NameError: name 'lst' is not defined
运行结果
[10, 20, 40, 50, 60, 30]
[10, 40, 50, 60, 30]
[10, 40, 50, 60]
切片操作-删除至少一个元素,将产生一个新的列表对象
原列表 [10, 40, 50, 60]
切片后 [40, 50]
不产生新的列表对象,而是删除原列表中的内容
[10, 60]
[]
列表元素的修改操作
- 为指定索引位置的元素赋予一个新值
- 为指定的切片赋予一个新值
lst=[10,20,30,40]
#一次修改一个值
lst[2]=100
print(lst)
lst[1:3]=[300,400,500,600]
print(lst)
运行结果
[10, 20, 100, 40]
[10, 300, 400, 500, 600, 40]
列表元素的排序操作
常用的两种方式
- 调用sort()方法,列表中所有元素默认按照从小到大的顺序进行排序,可以指定reverse=True,进行降序排序
- 调用内置函数sorted(),可以指定reverse=True,进行降序排序,原列表不发生改变
#调用sort()方法
lst=[20,40,10,98,54]
print('排序前的列表',lst,id(lst))
#开始排序,调用列表对象的sort方法,升序排序
lst.sort()
print('排序后的列表',lst,id(lst))
#通过指定关键字参数,将列表中的元素进行降序排序
lst.sort(reverse=True)
print(lst)
lst.sort(reverse=False)#默认就是False,即默认升序
print(lst)
运行结果
排序前的列表 [20, 40, 10, 98, 54] 2512752666312
排序后的列表 [10, 20, 40, 54, 98] 2512752666312
[98, 54, 40, 20, 10]
[10, 20, 40, 54, 98]
#使用内置函数sorted()对列表进行排序,将产生一个新的列表对象
lst=[20,40,10,98,54]
print('原列表',lst)
#开始排序
new_list=sorted(lst)
print('lst',lst,id(lst))
print('new_lst',new_list,id(new_list))
#指定关键字参数,实现列表元素的降序排序
desc_list=sorted(lst,reverse=True)
print('desc_lst',desc_list)
运行结果
原列表 [20, 40, 10, 98, 54]
lst [20, 40, 10, 98, 54] 2868109043400
new_lst [10, 20, 40, 54, 98] 2868108171656
desc_lst [98, 54, 40, 20, 10]
列表生成式
列表生成式简称“生成列表的公式”
#语法格式
#i*i 表示列表元素的表达式
#i 自定义变量
#range(1,10) 可迭代对象
[i*i for i in range(1,10)
注意:“表示列表元素的表达式”中通常包含自定义变量
lst=[i*i for i in range(1,10)]
print(lst)
'''列表中元素的值为2,4,6,8,10'''
lst2=[i*2 for i in range(1,6)]
print(lst2)
运行结果
[1, 4, 9, 16, 25, 36, 49, 64, 81]
[2, 4, 6, 8, 10]
本章小结
![]()
第七章
字典
定义
Python内置的数据结构之一,与列表一样是一个可变序列
以键值对的方式存储数据,字典是一个无序的序列
#例子
scores={'张三':100,'李四':98,'王五':45}
字典示意图
字典的实现原理
与查字典类似,查字典是先根据部首或者拼音查找相应的页码,Python中的字典是根据key查找value所在的位置
字典的创建
- 最常用的方式:使用花括号
- 使用内置函数dict()
'''字典的创建方式''''''1.使用{}创建字典'''
scores={'张三':100,'李四':98,'王五':45}
print(scores,type(scores))'''2.使用dict()内置函数'''
student=dict(name='jack',age=20)
print(student,type(student))'''空字典'''
d={}
print(d)
{'张三': 100, '李四': 98, '王五': 45} <class 'dict'>
{'name': 'jack', 'age': 20} <class 'dict'>
{}字典中元素的获取
| 获取字典中的元素 | 例子 | 区别 |
|---|---|---|
| [] | 举例:scores[‘张三’] | []如果字典中不存在指定的key,抛出keyError异常 |
| get()方法 | 举例:scores.get("张三’) | get()方法取值,如果字典中不存在指定的key,并不会抛出keyError,而是返回None,可以通过设置参数设置默认的value,以便指定的key不存在时返回 |
scores={'张三':100,'李四':98,'王五':45}'''第一种方式,使用[]'''
print(scores['张三'])
#print(scores['陈六'])#KeyError: '陈六''''第二种方式'''
print(scores.get('张三'))
print(scores.get('陈六'))#None
print(scores.get('玛奇',999))#999是在查找'玛奇'所对应的value不存在时,提供的一个默认值
输出结果
100
100
None
999
字典元素的增删改操作
| key的判断 | ||
|---|---|---|
| in | 指定的key在字典中存在返回True | ‘张三’ in scores |
| not in | 指定的key在字典中不存在返回False | ‘玛奇’ not in scores |
字典元素的删除
del scores['张三']
字典元素的新增
scores['jack']=90
代码案例
'''key的判断'''
scores={'张三':100,'李四':98,'王五':45}
print('张三' in scores)#True
print('张三' not in scores)#False#删除指定的key-value对
del scores['张三']
print(scores)#{'李四': 98, '王五': 45}
# scores.clear()#清空字典的元素
print(scores)
scores['陈六']=98#新增元素
print(scores)#{'李四': 98, '王五': 45, '陈六': 98}
scores['陈六']=100#修改元素
print(scores)#{'李四': 98, '王五': 45, '陈六': 100}
获取字典视图的三个方法
| 获取字典视图的三个方法 | 含义 |
|---|---|
| keys() | 获取字典中所有的key |
| values() | 获取字典中所有value |
| items() | 获取字典中所有key-value对 |
| 代码案例 |
scores={'张三':100,'李四':98,'王五':45}
#获取所有的key
keys=scores.keys()
print(keys)
print(type(keys))
print(list(keys))#将所有的key组成的视图转成列表#获取所有的value
print('------获取所有的value------')
values=scores.values()
print(values)
print(type(values))
print(list(values))#获取所有的key-value对
print('获取所有的key-value对')
items=scores.items()
print(items)
print(list(items))#转换之后的列表元素是由元组组成
运行结果
dict_keys(['张三', '李四', '王五'])
<class 'dict_keys'>
['张三', '李四', '王五']
------获取所有的value------
dict_values([100, 98, 45])
<class 'dict_values'>
[100, 98, 45]
获取所有的key-value对
dict_items([('张三', 100), ('李四', 98), ('王五', 45)])
[('张三', 100), ('李四', 98), ('王五', 45)]
字典元素的遍历
for item in scores:print(item)
代码案例
scores={'张三':100,'李四':98,'王五':45}
#字典元素的遍历
for item in scores:print(item,scores[item],scores.get(item))
运行结果
张三 100 100
李四 98 98
王五 45 45字典的特点
- 字典中的所有元素都是一个key-value对,key不允许重复,value可以重复
- 字典中的元素是无序的
- 字典中的key必须是不可变对象
- 字典也可以根据需要动态地伸缩
- 字典会浪费较大的内存,是一种使用空间换时间的数据结构
d={'name':'张三','name':'李四'}#key值不允许重复
print(d)d={'name':'张三','nikename':'张三'}#value可以重复
print(d)lst=[10,20,30]
lst.insert(1,100)
print(lst)
#d={lst:100}#TypeError: unhashable type: 'list'
print(lst)
运行结果
{'name': '李四'}
{'name': '张三', 'nikename': '张三'}
[10, 100, 20, 30]
字典生成式
内置函数zip()
- 用于将可迭代的对象作为参数,将对象中对应的元素打包成一个元组,然后返回由这些元组组成的列表
items=['Fruits','Books','Others']
prices=[96,78,85]
d={item.upper():price for item,price in zip(items,prices)}
print(d)
运行结果
{'FRUITS': 96, 'BOOKS': 78, 'OTHERS': 85}
本章总结
![]()
第八章
元组
元组定义
Python内置的数据结构之一,是一个不可变序列
不可变序列与可变序列
| 不可变序列与可变序列 | 举例 | 特点 |
|---|---|---|
| 不可变序列 | 字符串、数组 | 没有增删改操作 |
| 可变序列 | 列表、字典、集合 | 可以对序列执行增删改操作,对象地址不会改变 |
| 代码案例 |
'''不可变序列、可变序列'''
'''可变序列 列表、字典 对象地址不会改变'''
lst=[10,20,30]
print(id(lst))
lst.append(100)
print(id(lst))
'''不可变那序列,字符串、数组'''
s='hello'
print(id(s))
s=s+' world'
print(id(s))
print(s)
运行结果
2027317356232
2027317356232
2027316425648
2027316450992
hello world元组的创建方式
| 直接小括号 |
t=('Python','hello',90)
|
|---|---|
| 使用内置函数tuple() |
t=tuple(('Python','hello',90))
|
| 只包含一个元组的元素需要使用逗号和小括号 |
t=(10,)
|
'''元组的创建方式'''
'''第一种方式,使用()'''
print('------第一种方式,使用()------')
t=('Python','world',98)
print(t)
print(type(t))#省略了小括号
t2='Python','world',98
print(t2)
print(type(t2))
print('------如果元组只有一个元素,逗号不能省------')
t3=('Python',)
print(t3)
print(type(t3))
'''第二种创建方式,使用内置函数tuple()'''
t1=tuple(('Python','world',98))
print(t1)
print(type(t1))
运行结果
------第一种方式,使用()------
('Python', 'world', 98)
<class 'tuple'>
('Python', 'world', 98)
<class 'tuple'>
------如果元组只有一个元素,逗号不能省------
('Python',)
<class 'tuple'>
('Python', 'world', 98)
<class 'tuple'>
空列表,空字典,空元组
#空列表
lst=[]
lst1=list()
#空字典
d={}
d2=dict()
#空元组
t4=()
t5=tuple()
print('空列表',lst,lst1,type(lst),type(lst1))
print('空字典',d,d2,type(d),type(d2))
print('空元组',t4,t5,type(t4),type(t5))
为什么将元组设计成不可变序列
- 在多任务环境下,同时操作对象时不需要加锁
- 因此,在程序中尽量使用不可变序列
- 注意事项:元组存储的是对象的引用
- 如果元组中对象本身是不可变对象,则不能再引用其他对象
- 如果元组中的对象是可变对象,则可变对象的引用不允许改变,但数据可以改变
t=(20,[20,30],9)
print(t,type(t))
print(t[0],type(t[0]),id(t[0]))
print(t[1],type(t[1]),id(t[1]))
print(t[2],type(t[2]),id(t[2]))
#尝试将t[1]改为100
#t[1]=100 #TypeError: 'tuple' object does not support item assignment
# print(id(100))
'''由于[20,30]是列表,而列表是可变序列,所以可以向列表中添加元素,而列表的内存地址不变'''
t[1].append(100)#向列表中添加元素
print(t,id(t[1]))
运行结果
(20, [20, 30], 9) <class 'tuple'>
20 <class 'int'> 1714651856
[20, 30] <class 'list'> 2342609938120
9 <class 'int'> 1714651504
(20, [20, 30, 100], 9) 2342609938120
元组的遍历
元组是可迭代对象,所以可以使用for…in进行遍历
'''元组的遍历'''
t=('Python','world',98)
'''第一种获取元组元素的方式,使用索引'''
print(t[0])
print(t[1])
print(t[2])
#IndexError: tuple index out of range
# print(t[3])
'''第二种方式,遍历元组'''
print('------------')
for item in t:print(item)
运行结果
Python
world
98
------------
Python
world
98
集合
定义
- Python语言提供的内置数据结构
- 与列表、字典一样都属于可变类型的序列
- 集合是没有value的字典
集合的创建方式
- 直接{}
s={'Python','hello',90}
- 使用内置函数set()
s=set(range(6))print('range(6):',s)print('列表[]:',set([3,3,3,4,54,56]))print('元组():',set((3,3,4,4,54,56)))print('字符串序列:',set('Python'))print('集合{}:',set({1,2,3,44,55,5,44}))print(set())
代码演示
'''第一种创建方式使用{}'''
s={2,3,4,4,5,6,7}#集合中的元素不允许重复
print(s)
'''第二种方式,使用set()'''
s1=set(range(6))
print(s1,type(s1))#列表
s2=set([1,2,4,5,5,5,6,6,6])
print(s2,type(s2))
#元组
s3=set((1,2,4,4,5,65))#集合中的元素是无序的
print(s3,type(s3))
#字符串序列
s4=set('python')
print(s4,type(s4))
#集合
s5=set({12,4,34,55,66,44,44})
print(s5)
#定义一个空集合
s6={}#dict字典类型
print(type(s6))
#应该使用set()
s7=set()
print(type(s7))
运行结果
{2, 3, 4, 5, 6, 7}
{0, 1, 2, 3, 4, 5} <class 'set'>
{1, 2, 4, 5, 6} <class 'set'>
{65, 1, 2, 4, 5} <class 'set'>
{'h', 'o', 'n', 'p', 'y', 't'} <class 'set'>
{34, 66, 4, 55, 12, 44}
<class 'dict'>
<class 'set'>
集合的相关操作
集合元素的判断操作
in或not in
集合元素的新增操作
- 调用add()方法,一次添加一个元素
- 调用update()方法,至少添加一个元素
集合元素的删除操作
- 调用remove()方法,一次删除一个指定元素,如果指定的元素不存在抛出KeyError
- 调用discard()方法,一次删除一个指定元素,如果指定元素不存在不抛出异常
- 调用pop()方法,一次只删除一个任意元素
- 调用clear()方法,清空集合
代码如下
#集合的相关操作
s={10,20,30,40,50,60}
'''集合的判断操作'''
print(20 in s)#True
print(200 in s)#False
print(10 not in s)#False
print(100 not in s)#True
'''集合元素的新增操作'''
s.add(80)#add一次添加一个元素
print(s)
s.update({200,300,400})#一次至少添加一个元素 集合
print(s)
s.update([100,99,8])#列表
s.update((78,64,56))#元组
print(s)
#集合元素的删除操作
s.remove(100)
print(s)
# s.remove(500) 报异常
s.discard(500)
s.pop()
print(s)
s.clear()
print(s)
集合间的关系
两个集合是否相等
可以使用运算符==或!=进行判断
一个集合是否是另一个集合的子集
![]()
可以调用方法issubset进行判断
B是A的子集
一个集合是否是另一个集合的超集
可以调用方法issuperdet进行判断
A是B的超集
两个集合是否没有交集
可以调用方法isdisjoint进行判断
'''两个集合是否相等(元素相同就相等)'''
s={10,20,30,40}
s2={30,40,20,10}
print(s==s2)#True
print(s!=s2)
'''一个集合是否是另一个集合的子集'''
s1={10,20,30,40,50,60}
s2={10,20,30,40}
s3={10,20,90}
print(s2.issubset(s1))#True
print(s3.issubset(s1))#False
'''一个集合是否是另一个集合的超集'''
print(s1.issuperset(s2))#True
print(s1.issuperset(s3))#False
'''两个集合是否有交集'''
print(s2.isdisjoint(s3))#False 有交集为False
s4={1000,200,300}
print(s2.isdisjoint(s4))#True 没有交集为True
![]()
集合生成式
用于生成集合的公式
将{}改成[]就是列表生成式
没有元组生成式
#列表生成式
lst=[i*i for i in range(10)]
print(lst)
#集合生成式
s={i*i for i in range(10)}
print(s)
列表、字典、元组、集合总结
| 数据结构 | 是否可变 | 是否重复 | 是否有序 | 定义符号 |
|---|---|---|---|---|
| 列表(list) | 可变 | 可重复 | 有序 | [] |
| 元组(tuple) | 不可变 | 可重复 | 有序 | () |
| 字典(dict) | 可变 | key不可重复,value可重复 | 无序 | {key:value} |
| 集合(set) | 可变 | 不可重复 | 无序 | {} |
第九章
字符串
在python中字符串是基本数据类型,是一个不可变的字符序列
字符串驻留机制
仅保存一份相同且不可变字符串的方法,不同的值被存放在字符串的驻留池中,python的驻留机制对相同的字符串只保留一份拷贝,后续创建相同字符串时,不会开辟新空间,而是把该字符串的地址赋给新创建的变量
驻留机制的几种情况(交互模式win+R–>cmd)
- 字符串的长度为0或1时
- 符合标识符的字符串
- 字符串只在编译时进行驻留,而非运行时
- [-5,256]之间的整数数字
sys的intern方法强制2个字符串指向同一个对象
PyCharm对字符串进行了优化处理
字符串驻留机制的优缺点
- 当需要值相同的字符串时,可以直接从字符串池里拿来使用,避免频繁的创建和销毁,提升效率和节约内存,因为拼接字符串和修改字符串是比较影响性能的
- 在需要进行字符串拼接时建议使用str类型的join方法,而非+,因为join()方法是先计算出所有字符中的长度,然后再拷贝,只new一次对象,效率比“+”高。
字符串的常用操作
字符串的查询操作的方法
| 方法名称 | 作用 |
|---|---|
| index() | 查找子串substr第一次出现的位置,如果查找的子串不存在时,则抛出ValueError |
| rindex() | 查找子串substr最后一次出现的位置,如果查找的子串不存在时,则抛出ValueError |
| find | 查找子串substr第一次出现的位置,如果查找的子串不存在时,则返回-1 |
| rfind | 查找子串substr最后一次出现的位置,如果查找的子串不存在时,则返回-1 |
#字符串的查询操作
s='hello,hello'
print(s.index('lo'))#3
print(s.find('lo'))#3
print(s.rindex('lo'))#9
print(s.rfind('lo'))#9
#要查找的子串不存在时,建议使用find或rfind 返回-1
print(s.rfind('kk'))#-1
字符串的大小写转换操作的方法
| 方法名称 | 作用 |
|---|---|
| upper() | 把字符串中所有字符都转成大写字母 |
| lower() | 把字符串中所有字符都转成小写字母 |
| swapcase() | 把字符串所有大写字母都转成小写字母,把所有小写字母都转成大写字母 |
| capitalize() | 把第一个字符转成大写,把其余字符转换成小写 |
| title() | 把每个单词的第一个字符转换成大写,把每个单词的剩余字符转换成小写 |
#字符串中的大小写转换方法
s='hello,world'
a=s.upper()#转换大写之后,会产生一个新的字符串对象
print(a,id(a))
print(s,id(s))
b=s.lower()#转换之后,会产生一个新的字符串对象
print(b,id(b))
print(s,id(s))
print(b==s)
print(b is s)#Falses2='hello,World'
print(s2.swapcase())
print(s2.title())
print(s.capitalize())
字符串内容对齐操作的方法
| 方法名称 | 作用 |
|---|---|
| center() | 居中对齐,第1个参数指定宽度,第2个参数指定填充符,第2个参数是可选的,默认是空格,如果设置宽度小于实际宽度则则返回原字符串 |
| ljust() | 左对齐,第1个参数指定宽度,第2个参数指定填充符,第2个参数是可选的,默认是空格如果设置宽度小于实际宽度则则返回原字符串 |
| rjust() | 右对齐,第1个参数指定宽度,第2个参数指定填充符,第2个参数是可选的,默认是空格如果设置宽度小于实际宽度则则返回原字符串 |
| zfill() | 右对齐,左边用0填充,该方法只接收一个参数,用于指定字符串的宽度,如果指定的宽度小于等于字符串的长度,返回字符串本身 |
s='hello,Python'
print(s.center(20,'*'))
print(s.ljust(20,'*'))
字符串劈分操作的方法
| 方法名称 | 作用 |
|---|---|
| split() | 从字符串的左边开始劈分,默认的劈分字符是空格字符串,返回的值都是一个列表 |
| 可以通过参数sep指定劈分字符串是劈分符 | |
| 通过参数maxsplit指定劈分字符串的最大劈分次数,在经过最大次劈分之后,剩余的子串会单独作为一部分 | |
| rsplit() | 从字符串的右边开始劈分,默认的劈分字符是空格字符串,返回的值都是一个列表 |
| 可以通过参数sep指定劈分字符串是劈分符 | |
| 通过参数maxsplit指定劈分字符串的最大劈分次数,在经过最大次劈分之后,剩余的子串会单独作为一部分 |
s='hello world python'
lst=s.split()
print(lst)
s1='hello|world|python'
print(s1.split(sep='|'))
print(s1.split(sep='|',maxsplit=1))
print('------------------------')
'''rsplit()从右侧开始劈分'''
print(s.rsplit())
print(s1.rsplit('|'))
print(s1.rsplit(sep='|',maxsplit=1))#指定最大分割次数,则左右侧劈分结果不一样
判断字符串操作的方法
| 方法名称 | 作用 |
|---|---|
| isidentifier() | 判断指定的字符串是否是合法的标识符 |
| isspace() | 判断指定的字符串是否全部由空白字符组成(回车、换行、水平制表符) |
| isalpha() | 判断指定的字符串是否全部由字母组成 |
| isdecimal() | 判断指定的字符串是否全部由十进制的数字组成 |
| isnumberic() | 判断指定的字符串是否全部由数字组成 |
| isalnum() | 判断指定的字符串是否全部由字母和数字组成 |
print('123'.isdecimal())#True
字符串操作的其它方法
| 功能 | 方法名称 | 作用 |
|---|---|---|
| 字符串替换 | replace() | 第一个参数指定被替换的子串,第二个参数指定替换子串的字符串,该方法返回替换后得到的字符串,替换前的字符串不发生变化,调用该方法时可以通过第三个参数指定最大替换次数 |
| 字符串合并 | join() | 将列表或元素中的字符串合并成一个字符串 |
s='hello Python'
print(s.replace('Python','Java'))
s1='hello,Python,Python,Python'
print(s1.replace('Python','Java',2))
#列表
lst=['hello','java','Python']
print('|'.join(lst))
print(''.join(lst))
#元组
t=('hello','Java','Python')
print(''.join(t))
print('*'.join('Python'))
字符串的比较操作
- 运算符:>,>=,<,<=,==,!=
- 比较规则:首先比较两个字符串中的第一个字符,如果相等则继续比较下一个字符,依次比较下去,直到两个字符串中的字符不相等时,其比较结果就是两个字符串的比较结果,两个字符串中的所有后续字符将不再被比较
- 比较原理:两个字符进行比较时,比较的是其ordinal value(原始值),调用内置函数ord可以得到指定字符的ordinal value。与内置函数ord对应的是内置函数chr,调用内置函数chr时指定ordinal value可以得到对应的字符。
print('apple'>'app')#True
print('apple'>'banana')#False 相当于97》98
print(ord('a'),ord('b'))
print(ord('杨'))
print(chr(97),chr(98))
print(chr(26472))print('''
==和is的区别
==比较的是value
is 比较的是id是否相等
''')
a=b='Python'
c='Python'
print(a==b)#True
print(b==c)#True
print(a is b)#True
print(b is c)
print(id(a),id(b),id(c))
字符串的切片操作
字符串是不可变类型
不具备增删改等操作
切片将产生新的对象
s='hello,Python'
s1=s[:5]
s2=s[6:]
s3='!'
newStr=s1+s3+s2
print(s1)
print(s2)
print(newStr)
print('----------------------------')
print(id(s),id(s1),id(s2),id(s3),id(newStr))
print('-----------切片[start:end:step] -----------------')
print(s[1:5:1])#从1开始裁到5(不包含5),步长为1
print(s[::2])#默认从0开始,未写结束,默认到字符串的最后一个元素,步长为2,两个元素之间的索引间隔为2
print(s[::-1])#默认从字符串的最后一个元素开始,到字符串的第一个元素结束,因步长是负数
print(s[-6::1])#从索引为-6开始,到字符串的最后一个元素结束,步长为1
格式化字符串
两种方式
- %作占位符
%s:字符串
%i或%d:整数
%f:浮点数 - {}作占位符
#格式化字符串
#1.%占位符
name='张三'
age=20
print('我叫%s,今年%d岁' % (name,age))
#2.{}
print('我叫{0},今年{1}岁'.format(name,age))
#3.f-string
print(f'我叫{name},今年{age}岁')
print('%10d' % 99)#10表示的是宽度
print('%.3f' % 3.1415926)#.3表示小数点后三位
#同时表示宽度和精度
print('%10.3f' % 3.1415926)#一共总宽度为10,小数点后三位
print('hellohello')print('{0:.3}'.format(3.1415926))#.3表示一共是3位数
print('{:.3f}'.format(3.1415926))#.3f表示是3位小数
print('{:10.3f}'.format(3.1415926))
字符串的编码转换
为什么需要字符串的编码转换?
A计算机str在内存中以Unicode表示–编码–>byte字节传输–解码–>B计算机显示
编码和解码的方式
- 编码:将字符串转换为二进制数据(bytes)
- 解码:将bytes类型的数据转换成字符串类型
s='天涯共此时'
#编码
print(s.encode(encoding='GBK'))#在GBK这种编码格式中,一个中文占两个字节
print(s.encode(encoding='UTF-8'))#在UTF-8这种编码格式中,一个中文占三个字节
#解码
#byte代表就是一个二进制数据(字节类型的数据)
byte=s.encode(encoding='GBK')#编码
print(byte.decode(encoding='GBK'))#解码
byte=s.encode(encoding='UTF-8')#编码
print(byte.decode(encoding='UTF-8'))#解码
第十章 函数
什么是函数
函数就是执行特定任务和完成特定功能的一段代码
为什么需要函数
- 代码复用
- 隐藏实现细节
- 提高可维护性
- 提高可读性便于调试
函数的创建
def 函数名([输入参数]):函数体[return xxx]
函数的创建和调用代码
def calc(a,b):c=a+breturn cresult=calc(10,20)
print(result)
函数的参数传递
- 位置实参
根据形参对应的位置进行实参传递 - 关键字实参
根据形参名称进行实参传递
def calc(a,b):#a,b称为形式参数,简称形参,形参的位置是在函数的定义处c=a+breturn cresult=calc(10,20)#10,20称为实际参数的值,简称实参,实参的位置是函数的调用处
print(result)res=calc(b=10,a=20)#左侧的变量的名称为 关键字参数
print(res)
def fun(arg1,arg2):print('arg1=',arg1)print('arg2=',arg2)arg1=100arg2.append(10)print('arg1=',arg1)print('arg2=',arg2)print('调用结束')n1=11
n2=[22,33,44]
print('调用前',n1)
print('调用前',n2)
print('------------------')
#位置传参,arg1,arg2是函数定义处的形参,n1,n2是函数调用处的实参
#总结:实参名称和形参名称可以不同
fun(n1,n2)
print('调用后',n1)
print('调用后',n2)
#在函数调用过程中,进行参数的传递
#如果是不可变对象,在函数体的修改不会影响实参的值
#如果是可变对象,在函数体的修改会影响实参的值函数的返回值
1.如果函数没有返回值,函数执行完毕之后,不需要给调用处提供数据,return可以省略不写
2.一个返回值,直接返回类型
3.函数返回多个值时,结果为元组
'''
函数的返回值
1.如果函数没有返回值,函数执行完毕之后,不需要给调用处提供数据,return可以省略不写
2.一个返回值,直接返回类型
3.多个返回值,返回的结果为元组
'''
#1
def fun1():print('hello')
fun1()
#2
def fun2():return 'hello'
res=fun2()
print(res)
#3
def fun3():return 'hello','world'
print(fun3())
运行结果
hello
hello
('hello', 'world')
def fun(num):odd=[]#存奇数even=[]#存偶数for i in num:if i%2:odd.append(i)else:even.append(i)return odd,even#函数的调用
lst=[10,21,34,23,44,53,55]
print(fun(lst))
运行结果
([21, 23, 53, 55], [10, 34, 44])
函数参数定义
默认值参数
函数定义时,给形参设置默认值,只有默认值不符的时候才需要传递实参
def fun(a,b=10):#b称为默认值参数print(a,b)#函数的调用
fun(100)
fun(20,30)print('hello',end='\t')
print('world')
个数可变的位置参数
- 定义函数时,可能无法事先确定传递的位置实参的个数时,使用可变的位置参数
- 使用*定义个数可变的位置形参
- 结果为一个元组
个数可变的关键字形参
- 定义函数时,无法事先确定传递的关键字实参的个数时,使用可变的关键字形参
- 使用**定义个数可变的关键字形参
- 结果为一个字典
#个数可变的位置参数
def fun(*args):print(args)
fun(10)
fun(10,20,30)
#个数可变的关键字形参
def fun(**args):print(args)
fun(a=10)
fun(a=10,b=20,c=30)
'''
在一个函数的定义过程中,既有个数可变的关键字形参,也有个数可变的位置形参
要求:个数可变的位置形参在前
'''
def fun(*args1,**args2):pass
def fun(a,b,c):#a,b,c在函数的定义处,所以是形参print('a=',a)print('b=',b)print('c=',c)
#函数的调用
fun(10,20,30)
lst=[11,22,33]
fun(*lst)#在函数调用时,将列表中的每个元素都转换为位置实参传入
print('-------------------')
fun(a=100,c=300,b=200)#函数的调用,所以是关键字实参
dic={'a':100,'b':200,'c':300}
fun(**dic)#在函数调用时,将字典中的键值对都转换为关键字实参传入
变量的作用域
程序代码能访问该变量的区域
根据变量的有效范围可分为
- 局部变量
在函数内定义并使用的变量,只在函数内部有效,局部变量使用global声明,这个变量就会成为全局变量 - 全局变量
函数体外定义的变量可作用于函数内外
递归函数
- 什么是递归函数?
如果一个函数的函数体内调用了该函数本身,这个函数就称为递归函数 - 递归的组成部分
递归调用和递归终止条件 - 递归的调用过程
每递归调用一次函数,都会在栈内分配一个栈帧
每执行完一次函数,都会释放相应的空间 - 递归的优缺点
缺点:占用内存多,效率低下
优点:思路和代码简单
递归求n!代码
def fun(n):if n==1:return 1else:return n*fun(n-1)
print(fun(6))
斐波那契额数列
def fib(n):if n==1:return 1elif n==2:return 1else:return fib(n-1)+fib(n-2)
#输出斐波那契额数列第六位上的数字
print(fib(6))
#输出这个数列的前六位上的数字
for i in range(1,7):print(fib(i))
知识点总结
![]()
![]()
第十一章 类
类的创建
语法
class Student:pass
类的组成
- 类属性
- 实例方法
- 静态方法
- 类方法
class Student:#Student为类的名称,类名由一个或多个单词组成,每个单词的首字母大写,其余小写native_place='河南'#直接写在类里的变量,称为类属性def __init__(self,name,age):#name,age为实例属性self.name=nameself.age=age#实例方法def eat(self):#一个selfprint('学生在吃饭')#静态方法@staticmethoddef method():print('我使用了staticmethod进行修饰,所以我是静态方法')#类方法@classmethoddef cm(cls):print('我是类方法,因为我使用了classmethod进行修饰')#在类之外定义的称为函数,在类之内定义的称为方法
def drink():print('喝水')
对象的创建
又称类的实例化。有了实例,就可以调用类中的内容
语法:
实例名=类名()
#创建Student类的对象
stu1=Student('张三',20)
stu1.eat()#对象名.方法名
print(stu1.name)
print(stu1.age)
print('------------------------------')
Student.eat(stu1)#类名.方法名(类的对象,实际上就是方法定义处的self)
类属性、类方法、静态方法
- 类属性:类中方法外的变量称为类属性,被该类的所有对象所共享
- 类方法:使用@classmethod修饰的方法,使用类名直接访问的方法
- 静态方法:使用@staticmethod修饰的方法,使用类名直接调用的方法
动态绑定属性和方法
Python是动态语言,在创建对象后,可以动态地绑定属性和方法
class Student:def __init__(self,name,age):self.name=nameself.age=agedef eat(self):print(self.name+'在吃饭')stu1=Student('张三',20)
stu2=Student('李四',30)
print(id(stu1))
print(id(stu2))
print('---------为stu1动态绑定性别属性------------')
stu1.gender='女'#动态绑定性别属性
print(stu1.name,stu1.age,stu1.gender)
print(stu2.name,stu2.age)
print('---------动态绑定方法--------------')
stu1.eat()
stu2.eat()def show():print('定义在类之外的称函数')
stu1.show=show#动态绑定方法
stu1.show()
# stu2.show() 报错。因为stu2并没有绑定show方法
面向对象的三大特征
封装
- 提高程序的安全性
- 将数据(属性)和行为(方法)包装到类对象中。在方法内部对属性进行操作,在类对象的外部调用方法。这样,无需关心方法内部的具体实现细节,从而隔离了复杂度。
- 在Python中没有专门的修饰符用于属性的私有,如果该属性不希望在类对象外部被访问,前面使用2个“_”
class Student:def __init__(self,name,age):self.name=nameself.__age=age#年龄不希望在类的外部被使用,所以加了两个_def show(self):print(self.name,self.__age)#1.封装
stu=Student('张三',23)
stu.show()
#在类的外部使用name与age
print(stu.name)
# print(stu.__age)报错
print(stu._Student__age)
继承
- 提高代码的复用性
- 语法格式:
class 子类类名(父类1,父类2...):pass
- 如果一个类没有继承任何类,则默认继承object
- Python支持多继承
- 定义子类时,必须在构造方法中调用父类的构造函数
- 方法重写,如果子类对继承自父类的某个属性或方法不满意,可以在子类中对其(方法体)进行重新编写。
子类重写后的方法中可以通过super().xxx()调用父类中被重写的方法
class Person(object):def __init__(self,name,age):self.name=nameself.age=agedef info(self):print('姓名:{0},年龄{1}'.format(self.name,self.age))
#定义子类
class Student(Person):def __init__(self,name,age,score):super().__init__(name,age)self.score=score#方法重写def info(self):super().info()print('分数:{0}'.format(self.score))#print('姓名:{0},年龄{1},分数{2}'.format(self.name,self.age,self.score))#测试
per=Person('人类',100)
per.info()
stu=Student('张三',23,99)
stu.info()
多态
提高程序的可扩展性和可维护性
简单地说,多态就是“具有多种形态”,它指的是:即便不知道一个变量所引用的对象到底是什么类型,仍然可以通过这个变量调用方法,在运行过程中根据变量所引用对象的类型,动态决定调用哪个对象中的方法。
静态语言和动态语言关于多态的区别
- 静态语言实现多态的三个必要条件
继承,方法重写,父类引用指向子类对象 - 动态语言的多态
崇尚“鸭子类型”,当看到一只鸟走起来像鸭子,游泳起来像鸭子,那么这只鸟就可以被称为鸭子。在鸭子类型中,不需要关心对象是什么类型,到底是不是鸭子,只关心对象的行为。
class Animal(object):def eat(self):print('动物会吃')class Dog(Animal):def eat(self):print('狗啃骨头')
class Cat(Animal):def eat(self):print('猫吃鱼')class Person(object):def eat(self):print('人吃五谷杂粮')def fun(obj):obj.eat()#开始调用函数
fun(Cat())
fun(Dog())
fun(Animal())
fun(Person())
object类
- object类是所有类的父类,因此所有类都有object类的属性和方法
- 内置函数dir()可以查看指定对象所有属性
- object有一个__str__()方法,用于返回一个对于“对象的描述”,对应于内置函数str()经常用print()方法,帮助查看对象的信息,所以经常会对__str__()方法进行重写
class Person(object):def __init__(self,name,age):self.name=nameself.age=agedef info(self):print('姓名:{0},年龄{1}'.format(self.name,self.age))def __str__(self):return '姓名:{0},年龄{1}'.format(self.name,self.age)o=object()
print(dir(o))
p=Person('张三',20)
print(dir(p))
print(p)
特殊属性和特殊方法
![]()
第十二章 模块化编程
什么叫模块
- 函数与模块的关系
一个模块中可以包含N多个函数 - 在Python中一个扩展名为.py的文件就是一个模块
- 使用模块的好处
方便其它程序和脚本的导入并使用
避免函数名和变量名冲突
提高代码的可维护性和可重用性
自定义模块
- 创建模块
新建一个.py文件,名称尽量不要与Python自带的标准模块名称相同 - 导入模块
import 模块名称 [as 别名]
from 模块名称 import 函数/变量/类
多看一眼多进步,python入门到放弃相关推荐
- python入门到放弃篇46绘制几何图形
昨天,因为有时间.所以,久违地python编程一波.突然有一个新奇的想法,然后去实践了一下,又烧死了不少脑细胞,不过已经习惯了. 废话不多说,今天的代码有点小多,希望各位客官能够满意. 代码1: #随 ...
- python入门到放弃恶搞图-《Python3从入门到放弃》视频教程
<Python3从入门到放弃>视频教程2016年 001.01.python编程环境配置 001.02.IDE的又一选择PyCharm 002.01.name 002.02.namespa ...
- python入门到放弃恶搞图-学Python方法用错,直接从入门到放弃!
原标题:学Python方法用错,直接从入门到放弃! 从你开始学习编程的那一刻起,就注定了以后所要走的路-从编程学习者开始,依次经历实习生.程序员.软件工程师.架构师.CTO等职位的磨砺:当你站在职位顶 ...
- Python入门到放弃系列一
目录 初衷 基本概念 前言 第一部分:基础知识 第一章 起步 安装&配置部分 第二章 变量和简单数据类型 注释学习 代码自动补全 初衷 考虑到很多的地方都说要会python,shell,之类的 ...
- 从python入门到放弃_《Python3从入门到放弃》视频教程
" A! l% N+ q8 t% F& B9 u 001.01.python编程环境配置 001.02.IDE的又一选择PyCharm 002.01.name 002.02.name ...
- 从python入门到放弃_Python从入门到放弃?方法不对一切白费
从你开始学习编程的那一刻起,就注定了以后所要走的路 -从编程学习者开始,依次经历实习生.程序员.软件工程师.架构师. CT O 等职位的磨砺:当你站在职位顶 峰的位置蓦然回首时,会发现自己的成功并不是 ...
- Python入门到放弃(一)
介绍python和库文件管理 python是解释型语言 Python的特点:简单.易学.速度快.免费开源.高层语言.可移植性.解释性.面向对象(也支持面向过程).可扩展性.可嵌入性.丰富的库.规范的代 ...
- python ** 运算符_Python从入门到放弃运算符(2)
摘要:上一篇Python从入门到放弃-运算符(1),讲了Python的运算符中的算术运算符.赋值运算符.比较(关系)运算符,这篇继续讲Python的运算符. 逻辑运算符 逻辑运算符是对真和假两种布尔值 ...
- python从入门到放弃系列恶搞短片-太惨!学Python方法用错,直接从入门到放弃!...
原标题:太惨!学Python方法用错,直接从入门到放弃! 从你开始学习编程的那一刻起,就注定了以后所要走的路-从编程学习者开始,依次经历实习生.程序员.软件工程师.架构师.CTO等职位的磨砺:当你站在 ...
最新文章
- 使用spark计算文档相似度
- npoi word在试图打开文件时遇到错误_【技巧】word在试图打开文件时遇到错误
- Python类的私有属性、私有方法、类方法
- linspace函数matlab_Matlab入门2-莫比乌斯环
- 步长条件梯度下降算法步长和收敛条件的设置的一些看法
- Jenkins 官网文档翻译汇总
- .Net转Java自学之路—基础巩固篇二十二(XML)
- JSONObject.fromObject 找不到这个方法或是报错
- pp助手可以刷机吗android,pp助手刷机 pp助手怎么刷机
- 7z解压crc错误_7-Zip - 常见问题解答(FAQ)
- PHP开发之读取照片EXIF中的经纬度位置信息
- 安装西门子博图一直重启_博途V15.1安装及无限重启和.net3.5SP1错误处理解决方法...
- 谷歌怎么设置下载位置
- 怎样修复小米服务器,小米手机删除的视频想要恢复?那你一定不能错过这些实用技巧...
- 健身类小程序前后端源码
- mysql配置和优化
- 知乎问题:北京,2017,多少k的java web程序员应该懂多线程和jvm优化?
- centos7的网卡重启方法
- 论文查重自己文章会查吗?
- 人工智能调研报告汇总