bigquery_如何在BigQuery中进行文本相似性搜索和文档聚类
bigquery
BigQuery offers the ability to load a TensorFlow SavedModel and carry out predictions. This capability is a great way to add text-based similarity and clustering on top of your data warehouse.
BigQuery可以加载TensorFlow SavedModel并执行预测。 此功能是在数据仓库之上添加基于文本的相似性和群集的一种好方法。
Follow along by copy-pasting queries from my notebook in GitHub. You can try out the queries in the BigQuery console or in an AI Platform Jupyter notebook.
然后在GitHub中从我的笔记本复制粘贴查询。 您可以在BigQuery控制台或AI Platform Jupyter笔记本中尝试查询。
风暴报告数据 (Storm reports data)
As an example, I’ll use a dataset consisting of wind reports phoned into National Weather Service offices by “storm spotters”. This is a public dataset in BigQuery and it can be queried as follows:
举例来说,我将使用由“风暴发现者”致电国家气象局办公室的风报告组成的数据集。 这是BigQuery中的公共数据集,可以按以下方式查询:
SELECT EXTRACT(DAYOFYEAR from timestamp) AS julian_day, ST_GeogPoint(longitude, latitude) AS location, commentsFROM `bigquery-public-data.noaa_preliminary_severe_storms.wind_reports`WHERE EXTRACT(YEAR from timestamp) = 2019LIMIT 10The result looks like this:
结果看起来像这样:
Let’s say that we want to build a SQL query to search for comments that look like “power line down on a home”.
假设我们要构建一个SQL查询来搜索看起来像“家中的电源线”的注释。
Steps:
脚步:
- Load a machine learning model that creates an embedding (essentially a compact numerical representation) of some text.
加载一个机器学习模型,该模型创建一些文本的嵌入(本质上是紧凑的数字表示形式)。 - Use the model to generate the embedding of our search term.
使用该模型生成搜索词的嵌入。 - Use the model to generate the embedding of every comment in the wind reports table.
使用该模型可将每个评论嵌入风报告表中。 - Look for rows where the two embeddings are close to each other.
查找两个嵌入彼此靠近的行。
将文本嵌入模型加载到BigQuery中 (Loading a text embedding model into BigQuery)
TensorFlow Hub has a number of text embedding models. For best results, you should use a model that has been trained on data that is similar to your dataset and which has a sufficient number of dimensions so as to capture the nuances of your text.
TensorFlow Hub具有许多文本嵌入模型。 为了获得最佳结果,您应该使用经过训练的模型,该数据类似于您的数据集,并且具有足够的维数,以捕获文本的细微差别。
For this demonstration, I’ll use the Swivel embedding which was trained on Google News and has 20 dimensions (i.e., it is pretty coarse). This is sufficient for what we need to do.
在此演示中,我将使用在Google新闻上接受训练的Swivel嵌入,它具有20个维度(即,非常粗略)。 这足以满足我们的需求。
The Swivel embedding layer is already available in TensorFlow SavedModel format, so we simply need to download it, extract it from the tarred, gzipped file, and upload it to Google Cloud Storage:
Swivel嵌入层已经可以使用TensorFlow SavedModel格式,因此我们只需要下载它,从压缩后的压缩文件中提取出来,然后将其上传到Google Cloud Storage:
FILE=swivel.tar.gzwget --quiet -O tmp/swivel.tar.gz https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1?tf-hub-format=compressedcd tmptar xvfz swivel.tar.gzcd ..mv tmp swivelgsutil -m cp -R swivel gs://${BUCKET}/swivelOnce the model files on GCS, we can load it into BigQuery as an ML model:
将模型文件保存到GCS后,我们可以将其作为ML模型加载到BigQuery中:
CREATE OR REPLACE MODEL advdata.swivel_text_embedOPTIONS(model_type='tensorflow', model_path='gs://BUCKET/swivel/*')尝试在BigQuery中嵌入模型 (Try out embedding model in BigQuery)
To try out the model in BigQuery, we need to know its input and output schema. These would be the names of the Keras layers when it was exported. We can get them by going to the BigQuery console and viewing the “Schema” tab of the model:
要在BigQuery中试用模型,我们需要了解其输入和输出架构。 这些将是导出时Keras图层的名称。 我们可以通过转到BigQuery控制台并查看模型的“架构”标签来获得它们:
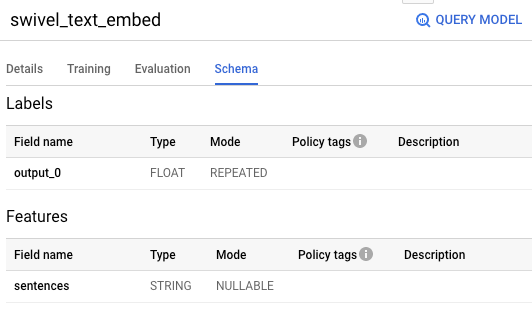
Let’s try this model out by getting the embedding for a famous August speech, calling the input text as sentences and knowing that we will get an output column named output_0:
让我们通过获得著名的August演讲的嵌入,将输入文本称为句子并知道我们将得到一个名为output_0的输出列来试用该模型:
SELECT output_0 FROMML.PREDICT(MODEL advdata.swivel_text_embed,(SELECT "Long years ago, we made a tryst with destiny; and now the time comes when we shall redeem our pledge, not wholly or in full measure, but very substantially." AS sentences))The result has 20 numbers as expected, the first few of which are shown below:
结果有20个预期的数字,其中前几个显示如下:
文件相似度搜寻 (Document similarity search)
Define a function to compute the Euclidean squared distance between a pair of embeddings:
定义一个函数来计算一对嵌入之间的欧几里德平方距离:
CREATE TEMPORARY FUNCTION td(a ARRAY<FLOAT64>, b ARRAY<FLOAT64>, idx INT64) AS ( (a[OFFSET(idx)] - b[OFFSET(idx)]) * (a[OFFSET(idx)] - b[OFFSET(idx)]));CREATE TEMPORARY FUNCTION term_distance(a ARRAY<FLOAT64>, b ARRAY<FLOAT64>) AS (( SELECT SQRT(SUM( td(a, b, idx))) FROM UNNEST(GENERATE_ARRAY(0, 19)) idx));Then, compute the embedding for our search term:
然后,为我们的搜索词计算嵌入:
WITH search_term AS ( SELECT output_0 AS term_embedding FROM ML.PREDICT(MODEL advdata.swivel_text_embed,(SELECT "power line down on a home" AS sentences)))and compute the distance between each comment’s embedding and the term_embedding of the search term (above):
并计算每个评论的嵌入与搜索词的term_embedding之间的距离(如上):
SELECT term_distance(term_embedding, output_0) AS termdist, commentsFROM ML.PREDICT(MODEL advdata.swivel_text_embed,( SELECT comments, LOWER(comments) AS sentences FROM `bigquery-public-data.noaa_preliminary_severe_storms.wind_reports` WHERE EXTRACT(YEAR from timestamp) = 2019)), search_termORDER By termdist ASCLIMIT 10The result is:
结果是:
Remember that we searched for “power line down on home”. Note that the top two results are “power line down on house” — the text embedding has been helpful in recognizing that home and house are similar in this context. The next set of top matches are all about power lines, the most unique pair of words in our search term.
请记住,我们搜索的是“家中的电源线”。 请注意,最上面的两个结果是“房屋上的电源线断开”-文本嵌入有助于识别房屋和房屋在这种情况下是相似的。 下一组热门匹配项都是关于电源线的,这是我们搜索词中最独特的词对。
文件丛集 (Document Clustering)
Document clustering involves using the embeddings as an input to a clustering algorithm such as K-Means. We can do this in BigQuery itself, and to make things a bit more interesting, we’ll use the location and day-of-year as additional inputs to the clustering algorithm.
文档聚类涉及将嵌入用作聚类算法(例如K-Means)的输入。 我们可以在BigQuery本身中做到这一点,并使事情变得更加有趣,我们将位置和年份作为聚类算法的其他输入。
CREATE OR REPLACE MODEL advdata.storm_reports_clusteringOPTIONS(model_type='kmeans', NUM_CLUSTERS=10) ASSELECT arr_to_input_20(output_0) AS comments_embed, EXTRACT(DAYOFYEAR from timestamp) AS julian_day, longitude, latitudeFROM ML.PREDICT(MODEL advdata.swivel_text_embed,( SELECT timestamp, longitude, latitude, LOWER(comments) AS sentences FROM `bigquery-public-data.noaa_preliminary_severe_storms.wind_reports` WHERE EXTRACT(YEAR from timestamp) = 2019))The embedding (output_0) is an array, but BigQuery ML currently wants named inputs. The work around is to convert the array to a struct:
嵌入(output_0)是一个数组,但是BigQuery ML当前需要命名输入。 解决方法是将数组转换为结构:
CREATE TEMPORARY FUNCTION arr_to_input_20(arr ARRAY<FLOAT64>)RETURNS STRUCT<p1 FLOAT64, p2 FLOAT64, p3 FLOAT64, p4 FLOAT64, p5 FLOAT64, p6 FLOAT64, p7 FLOAT64, p8 FLOAT64, p9 FLOAT64, p10 FLOAT64, p11 FLOAT64, p12 FLOAT64, p13 FLOAT64, p14 FLOAT64, p15 FLOAT64, p16 FLOAT64, p17 FLOAT64, p18 FLOAT64, p19 FLOAT64, p20 FLOAT64>AS (STRUCT( arr[OFFSET(0)] , arr[OFFSET(1)] , arr[OFFSET(2)] , arr[OFFSET(3)] , arr[OFFSET(4)] , arr[OFFSET(5)] , arr[OFFSET(6)] , arr[OFFSET(7)] , arr[OFFSET(8)] , arr[OFFSET(9)] , arr[OFFSET(10)] , arr[OFFSET(11)] , arr[OFFSET(12)] , arr[OFFSET(13)] , arr[OFFSET(14)] , arr[OFFSET(15)] , arr[OFFSET(16)] , arr[OFFSET(17)] , arr[OFFSET(18)] , arr[OFFSET(19)] ));The resulting ten clusters can visualized in the BigQuery console:
可以在BigQuery控制台中看到生成的十个集群:
What do the comments in cluster #1 look like? The query is:
第1组中的注释是什么样的? 查询是:
SELECT sentences FROM ML.PREDICT(MODEL `ai-analytics-solutions.advdata.storm_reports_clustering`, (SELECT sentences, arr_to_input_20(output_0) AS comments_embed, EXTRACT(DAYOFYEAR from timestamp) AS julian_day, longitude, latitudeFROM ML.PREDICT(MODEL advdata.swivel_text_embed,( SELECT timestamp, longitude, latitude, LOWER(comments) AS sentences FROM `bigquery-public-data.noaa_preliminary_severe_storms.wind_reports` WHERE EXTRACT(YEAR from timestamp) = 2019))))WHERE centroid_id = 1The result shows that these are mostly short, uninformative comments:
结果表明,这些大多是简短的,无用的评论:
How about cluster #3? Most of these reports seem to have something to do with verification by radar!!!
第3组如何? 这些报告大多数似乎与雷达验证有关!!!
Enjoy!
请享用!
链接 (Links)
TensorFlow Hub has several text embedding models. You don’t have to use Swivel, although Swivel is a good general-purpose choice.
TensorFlow Hub具有多个文本嵌入模型。 尽管Swivel是一个不错的通用选择,但您不必使用Swivel 。
Full queries are in my notebook on GitHub. You can try out the queries in the BigQuery console or in an AI Platform Jupyter notebook.
完整查询在我的GitHub笔记本上 。 您可以在BigQuery控制台或AI Platform Jupyter笔记本中尝试查询。
翻译自: https://towardsdatascience.com/how-to-do-text-similarity-search-and-document-clustering-in-bigquery-75eb8f45ab65
bigquery
相关文章:
- vlookup match_INDEX-MATCH — VLOOKUP功能的升级
- flask redis_在Flask应用程序中将Redis队列用于异步任务
- 前馈神经网络中的前馈_前馈神经网络在基于趋势的交易中的有效性(1)
- hadoop将消亡_数据科学家:适应还是消亡!
- 数据科学领域有哪些技术_领域知识在数据科学中到底有多重要?
- 初创公司怎么做销售数据分析_为什么您的初创企业需要数据科学来解决这一危机...
- r软件时间序列分析论文_高度比较的时间序列分析-一篇论文评论
- selenium抓取_使用Selenium的网络抓取电子商务网站
- 裁判打分_内在的裁判偏见
- 从Jupyter Notebook切换到脚本的5个理由
- ip登录打印机怎么打印_不要打印,登录。
- 机器学习模型 非线性模型_调试机器学习模型的终极指南
- 您的第一个简单的机器学习项目
- 鸽子为什么喜欢盘旋_如何为鸽子回避系统设置数据收集
- 追求卓越追求完美规范学习_追求新的黄金比例
- 周末想找个地方敲代码_观看我们的代码游戏,全周末直播
- javascript 开发_25个新JavaScript开发人员的免费资源
- 感谢您的提问_感谢您的反馈,我们正在改进的5种方法
- 堆叠自编码器中的微调解释_25种深刻漫画中的编码解释
- Free Code Camp现在有本地组
- 递归javascript_JavaScript中的递归
- 判断一个指针有没有free_Free Code Camp的每个人现在都有一个档案袋
- 使您的Java代码闻起来很新鲜
- Stack Overflow 2016年对50,000名开发人员进行的调查得出的见解
- 编程程序的名称要记住吗_学习编程时要记住的5件事
- 如何在开源社区贡献代码_如何在15分钟内从浏览器获得您的第一个开源贡献
- utf-8转换gbk代码_将代码转换为现金-如何以Web开发人员的身份赚钱并讲述故事。...
- 有没有编码的知识图谱_没有人告诉您关于学习编码的知识-以及为什么如此困难...
- 你鼓舞了我是世界杯主题曲吗_选择方法和鼓舞人心的网站列表
- reddit_我在3天内疯狂地审查了Reddit上的50个投资组合,从中学到了什么。
bigquery_如何在BigQuery中进行文本相似性搜索和文档聚类相关推荐
- css可以设置文本框颜色吗,如何在css中设置文本框颜色
如何在css中设置文本框颜色 发布时间:2021-04-29 15:33:54 来源:亿速云 阅读:72 作者:Leah 如何在css中设置文本框颜色?针对这个问题,这篇文章详细介绍了相对应的分析和解 ...
- html 获取文本框值,html - 如何在JavaScript中获取文本框值
html - 如何在JavaScript中获取文本框值 我正在尝试使用JavaScript从HTML文本框中获取值,但值不是在空格之后 例如: 我只得到:上面的"软件". 我正在使 ...
- element 搜索匹配_如何在Element-ui中实现一个远程搜索功能
如何在Element-ui中实现一个远程搜索功能 发布时间:2021-01-29 14:50:00 来源:亿速云 阅读:87 作者:Leah 这篇文章给大家介绍如何在Element-ui中实现一个远程 ...
- 浅析如何在Nancy中使用Swagger生成API文档
原文:浅析如何在Nancy中使用Swagger生成API文档 前言 上一篇博客介绍了使用Nancy框架内部的方法来创建了一个简单到不能再简单的Document.但是还有许许多多的不足. 为了能稍微完善 ...
- python怎么字体加阴影_如何在pythonptx中给文本添加阴影?
我正在做一个项目,我必须用pythonptx创建一个PowerPoint.我需要添加有阴影的文本,使其显示如下: 如何在pythonptx中使用阴影格式化文本?在 下面是我使用的代码:from ppt ...
- 【NLP】竞赛中的文本相似性!
文本相似度是指衡量两个文本的相似程度,相似程度的评价有很多角度:单纯的字面相似度(例如:我和他 v.s. 我和她),语义的相似度(例如:爸爸 v.s. 父亲)和风格的相似度(例如:我喜欢你 v.s. ...
- txt文本变为粗体_如何在PHP中使文本变为粗体?
txt文本变为粗体 Sometimes we might want to display text with style. That it's font, color, make it bold, i ...
- php 字体如何加粗和调大小,如何在PHP中使文本变为粗体?
有时我们可能想要显示带有样式的文本.它是字体,颜色,使其变为粗体,斜体,下划线等.添加任何样式都是基于我们想要传达的信息或引起某人关注的信息. 在本文中,我们将学习如何在PHP中加粗文本?当我们加粗文 ...
- 文本挖掘和文本分析与nlp_如何在NLP中保护文本表示的隐私
文本挖掘和文本分析与nlp 问题概述 (Problem overview) Recently, we have been experiencing numerous breakthroughs in ...
最新文章
- 矩阵的卷积核运算(一个简单小例子的讲解)深度学习
- 网络工程师职业发展解读
- 阿里某员工面试华为后吐槽:面试官太水,反问几句都答不上来
- Navigator 对象
- 润乾V4导出TXT时自定义分隔符
- python3.6安装tensorflow gpu_tensorflow-gpu安装的常见问题及解决方案
- GCC同时使用静态库和动态库链接
- mysql 状态机_动画状态机(2)
- java map isempty_Java HashMap isEmpty() 使用方法及示例
- 17. QTreeView 简单用法
- 排序提示若执行此操作所有合并单元格需大小相同
- java零碎要点---Tesseract 3.0,Java OCR 图像智能字符识别技术,可识别中文
- 变电所自动化系统的电源配置
- 【细节处理】LeetCode 66. Plus One
- Oracle Clusterware工具3
- 使用 Python 构建电影推荐系统
- 如何用echarts创建市区地图
- 手机定位--GPS定位,基站定位,辅助定位
- 超级狗C++的Demo程序运行流程
- Cisco交换机产品线和主要产品--- 型号说明
热门文章
- string 转化 xml,并找到指定节点及节点值
- org.dom4j.DocumentException: null Nested exception: null解决方法
- 约束布局constraint-layout导入失败的解决方案 - 转
- Android保存图片到本地相册
- hdu 2048 神、上帝以及老天爷
- 解决Warning: Cannot modify header information - headers already sent b...
- OWASP TOP 10 1
- 快餐文化短视频源码行业竞争激烈,短视频发展任重道远
- 锦欣生殖获战略投资,华平、信银领投,红杉、药明康德跟投
- elasticsearch,elasticsearch-service安装