KafkaStream之时间窗口WindowBy
Kafka Stream的大部分API还是比较容易理解和使用的,但是,其中的时间窗口聚合即windowBy方法还是需要仔细研究下,否则很容易使用错误。
本文先引入Kafka Stream,然后主要针对时间窗口聚合API即windowBy()做详细分析。
引言
Kafka Streams是一个用于构建应用程序和微服务的客户端库,其中的输入和输出数据存储在Kafka集群中。它结合了在客户端编写和部署Java/Scala应用程序的简单性,以及Kafka服务器集群的优点。
Kafka Stream为我们屏蔽了直接使用Kafka Consumer的复杂性,不用手动进行轮询poll(),不必关心commit()。而且,使用Kafka Stream,可以方便的进行实时计算、实时分析。
比如官方Demo,统计topic中不同单词的出现次数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
public class WordCountApplication {public static void main(final String[] args) throws InterruptedException {Properties props = new Properties();props.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-application");props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");props.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG, "500");// 默认30s commit一次props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());StreamsBuilder builder = new StreamsBuilder();// 从名为“TextLinesTopic”的topic创建流。KStream<String, String> textLines = builder.stream("TextLinesTopic");KTable<String, Long> wordCounts =textLines.flatMapValues(textLine -> Arrays.asList(textLine.toLowerCase().split("\\W+"))).groupBy((key, word) -> word).count();// 官方文档实例中是 wordCounts.toStream().to("WordsWithCountsTopic", Produced.with(Serdes.String(), Serdes.Long())); 直接写回kafka// 我们这里为了方便观察,直接打印到控制台wordCounts.toStream().print(Printed.toSysOut());KafkaStreams streams = new KafkaStreams(builder.build(), props);streams.start();Thread.currentThread().join();}}
|
启动程序、kafka服务端。
启动kafka-console-producer, 创建主题TextLinesTopic0,并发送消息。
1 2 3 |
.\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic TextLinesTopic.\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic TextLinesTopic0 |
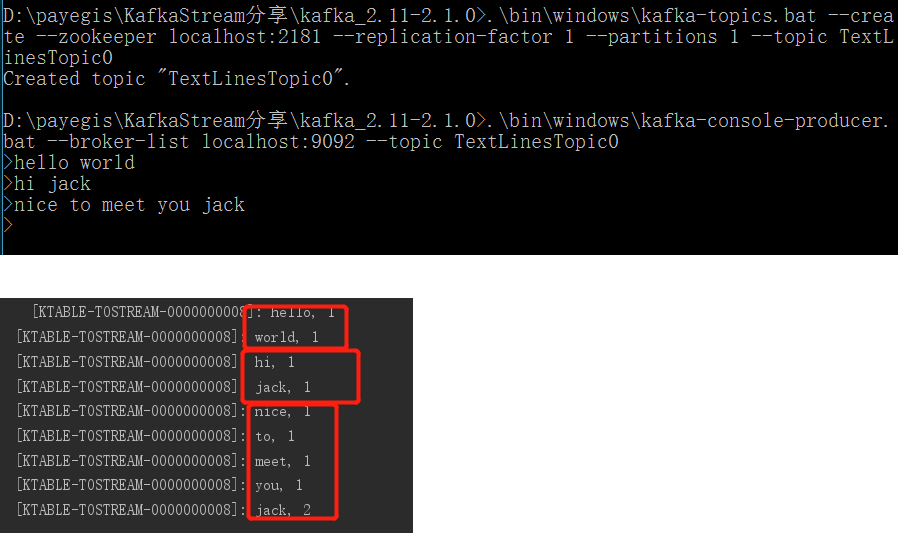
可以看到,每次向kafka写入一条消息后,我们的demo程序在控制台会立即输出产生变化的数据统计。
这其中的简单原理可以参考http://kafka.apache.org/23/documentation/streams/quickstart#quickstart_streams_process。我们的流计算应用保存一个KTable<String, Long> 用来记录统计条目,随着流中元素的到来,KTable中的统计条目发生变化,这些变化回发送到下游流中(本文中的下游流就是控制台)。
借助KafkaStream的API,我们可以方便的编写实时计算应用。比如上面的groupBy、count方法,再比如接下来的windowBy方法,如果不使用KafakStream,直接使用Kafka Consumer自行实现,则比较麻烦。
Kafka Stream的大部分API还是比较容易理解和使用的,但是,其中的时间窗口聚合即windowBy方法还是需要仔细研究下,否则很容易使用错误。
WindowBy
根据时间窗口做聚合,是在实时计算中非常重要的功能。比如我们经常需要统计最近一段时间内的count、sum、avg等统计数据。
Kafka中有这样四种时间窗口。
| Window name | Behavior | Short description |
|---|---|---|
| Tumbling time window | Time-based | Fixed-size, non-overlapping, gap-less windows |
| Hopping time window | Time-based | Fixed-size, overlapping windows |
| Sliding time window | Time-based | Fixed-size, overlapping windows that work on differences between record timestamps |
| Session window | Session-based | Dynamically-sized, non-overlapping, data-driven windows |
Tumbling time windows
翻滚时间窗口Tumbling time windows是跳跃时间窗口hopping time windows的一种特殊情况,与后者一样,翻滚时间窗也是基于时间间隔的。但它是固定大小、不重叠、无间隙的窗口。翻滚窗口只由一个属性定义:size。翻滚窗口实际上是一种跳跃窗口,其窗口大小与其前进间隔相等。由于翻滚窗口从不重叠,数据记录将只属于一个窗口。
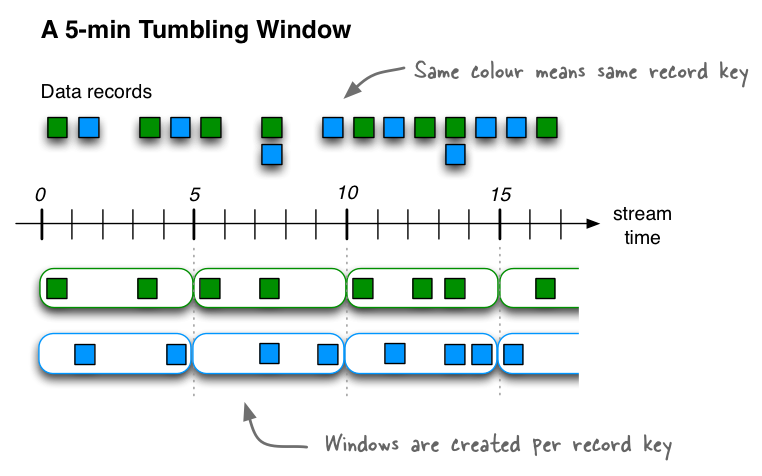
Tumbling time windows are aligned to the epoch, with the lower interval bound being inclusive and the upper bound being exclusive. “Aligned to the epoch” means that the first window starts at timestamp zero. For example, tumbling windows with a size of 5000ms have predictable window boundaries
[0;5000),[5000;10000),...— and not[1000;6000),[6000;11000),...or even something “random” like[1452;6452),[6452;11452),....
看个翻滚窗口的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
private static final String BOOT_STRAP_SERVERS = "localhost:9092";
private static final String TEST_TOPIC = "test_topic";
private static final long TIME_WINDOW_SECONDS = 5L; //时间窗口大小@Test
public void testTumblingTimeWindows() throws InterruptedException {Properties props = configStreamProperties();StreamsBuilder builder = new StreamsBuilder();KStream<String, String> data = builder.stream(TEST_TOPIC);Instant initTime = Instant.now();data.groupByKey().windowedBy(TimeWindows.of(Duration.ofSeconds(TIME_WINDOW_SECONDS))).count(Materialized.with(Serdes.String(), Serdes.Long())).toStream().filterNot(((windowedKey, value) -> this.isOldWindow(windowedKey, value, initTime))) //剔除太旧的时间窗口,程序二次启动时,会重新读取历史数据进行整套流处理,为了不影响观察,这里过滤掉历史数据.foreach(this::dealWithTimeWindowAggrValue);Topology topology = builder.build();KafkaStreams streams = new KafkaStreams(topology, props);streams.start();Thread.currentThread().join();
}
|
Test启动前启动一个KafkaProducer,每1秒产生一条数据,数据的key为“service_1”,value为“key@当前时间”。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
@BeforeClass
public static void generateValue() {Properties props = new Properties();props.put("bootstrap.servers", BOOT_STRAP_SERVERS);props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("request.required.acks", "0");new Thread(() -> {Producer<String, String> producer = new KafkaProducer<>(props);try {while (true) {TimeUnit.SECONDS.sleep(1L);Instant now = Instant.now();String key = "service_1";String value = key + "@" + toLocalTimeStr(now);producer.send(new ProducerRecord<>(TEST_TOPIC, key, value));}} catch (Exception e) {e.printStackTrace();producer.close();}}).start();
}
private static String toLocalTimeStr(Instant i) {return i.atZone(ZoneId.systemDefault()).toLocalDateTime().toString();
}
|
下面是些公共代码,之后的例子也有会用到 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
private Properties configStreamProperties() {Properties props = new Properties();props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-ljf-test");props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, BOOT_STRAP_SERVERS);props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());props.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG, "500");//todo 默认值为30s,会导致30s才提交一次数据。return props;
}private boolean isOldWindow(Windowed<String> windowKey, Long value, Instant initTime) {Instant windowEnd = windowKey.window().endTime();return windowEnd.isBefore(initTime);
}private void dealWithTimeWindowAggrValue(Windowed<String> key, Long value) {Windowed<String> windowed = getReadableWindowed(key);System.out.println("处理聚合结果:key=" + windowed + ",value=" + value);
}private Windowed<String> getReadableWindowed(Windowed<String> key) {return new Windowed<String>(key.key(), key.window()) {@Overridepublic String toString() {String startTimeStr = toLocalTimeStr(Instant.ofEpochMilli(window().start()));String endTimeStr = toLocalTimeStr(Instant.ofEpochMilli(window().end()));return "[" + key() + "@" + startTimeStr + "/" + endTimeStr + "]";}};
}
|
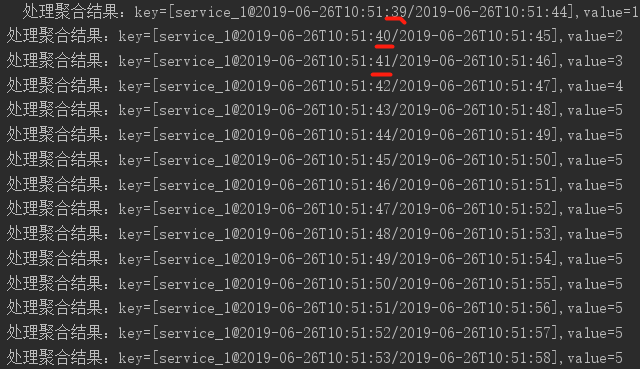
上面的testTumblingTimeWindows()中,创建了一个流任务,先groupByKey(),再调用count()计算每个时间窗口的消息个数。我们创建了一个size为5秒的翻滚时间窗口。而且generateValue()方法中启动了一个Producer,每隔一秒发送一条消息。使用JUnit运行testTumblingTimeWindows(),控制台输出如下(在创建流计算逻辑时,我们最后使用foreach(this::dealWithTimeWindowAggrValue)将上游流(这里是filterNot方法的结果)传来的元素打印到控制台):
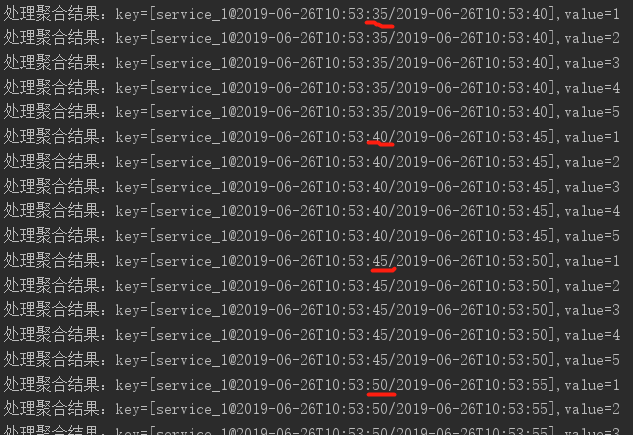
可以看到,每个时间窗口统计到5的时候,重新从1开始count。这也印证了翻滚窗口的特性。
这里我们再看下groupByKey的特性。
如果将generateValue()方法改为,模拟另一个服务也在发送消息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
@BeforeClass
public static void generateValue() {Properties props = new Properties();// ...配置不变,此处省略new Thread(() -> {Producer<String, String> producer = new KafkaProducer<>(props);try {while (true) {TimeUnit.SECONDS.sleep(1L);Instant now = Instant.now();String key = "service_1";String value = key + "@" + toLocalTimeStr(now);producer.send(new ProducerRecord<>(TEST_TOPIC, key, value));String key2 = "service_2"; // 模拟另一个服务也在发送消息producer.send(new ProducerRecord<>(TEST_TOPIC, key2, value));}} catch (Exception e) {e.printStackTrace();producer.close();}}).start();
}
|
重新运行testTumblingTimeWindows():
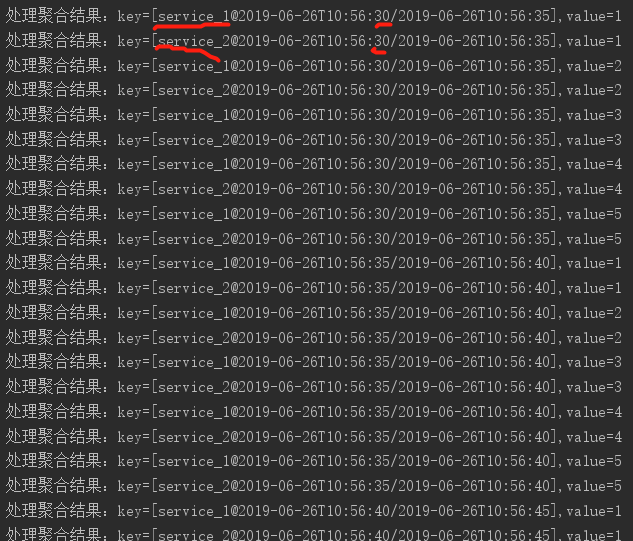
可以看到,我们的流任务根据key的不同先做group,在进行时间窗口的聚合。
PS:类似groupByKey,还有groupBy,前者可以看做后者的特化,后者可以根据消Message的key、value自定义分组逻辑。关于此,可以参考API官方文档Stateless transformations
Sliding time windows
Sliding windows are actually quite different from hopping and tumbling windows. In Kafka Streams, sliding windows are used only for join operations, and can be specified through the JoinWindows class.
A sliding window models a fixed-size window that slides continuously over the time axis; here, two data records are said to be included in the same window if (in the case of symmetric windows) the difference of their timestamps is within the window size. Thus, sliding windows are not aligned to the epoch, but to the data record timestamps. In contrast to hopping and tumbling windows, the lower and upper window time interval bounds of sliding windows are both inclusive.
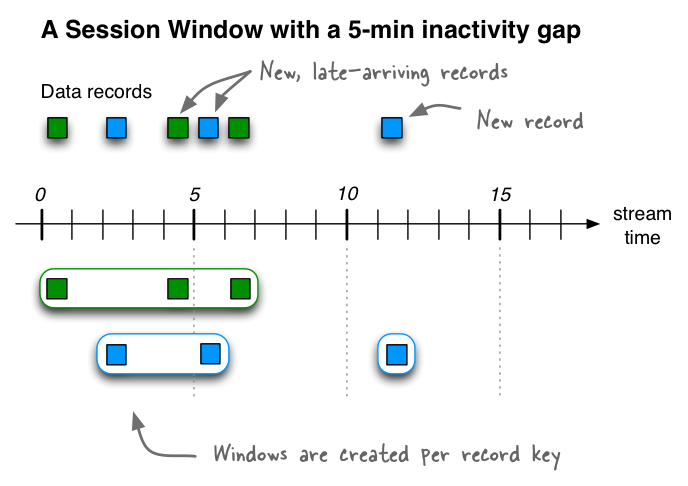
Session Windows
Session windows are used to aggregate key-based events into so-called sessions, the process of which is referred to as sessionization. Sessions represent a period of activity separated by a defined gap of inactivity (or “idleness”). Any events processed that fall within the inactivity gap of any existing sessions are merged into the existing sessions. If an event falls outside of the session gap, then a new session will be created.
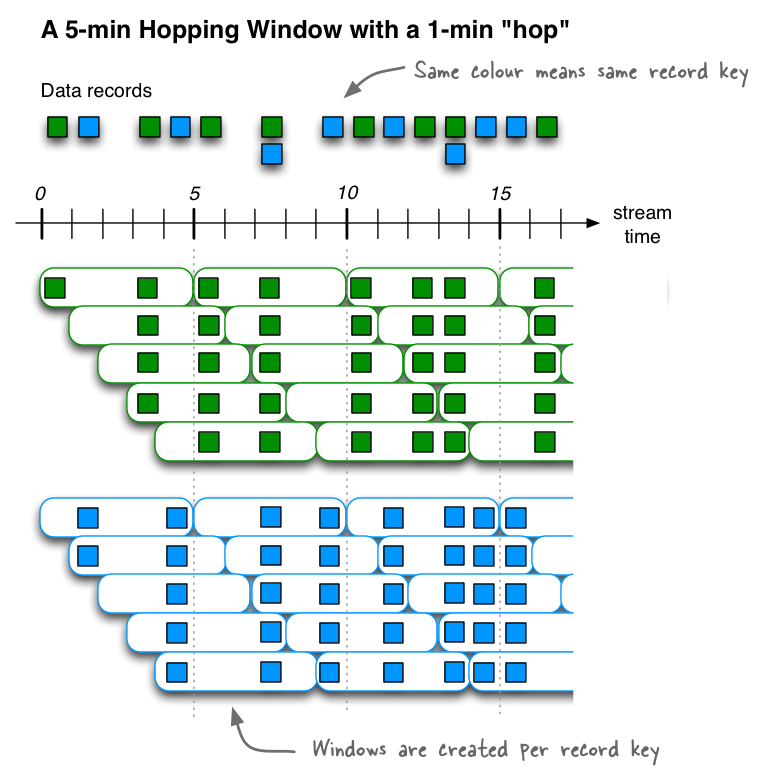
Hopping time windows
我们口中的“滑动窗口”,在Kafka这里叫做跳跃窗口。
Note Hopping windows vs. sliding windows: Hopping windows are sometimes called “sliding windows” in other stream processing tools. Kafka Streams follows the terminology in academic literature, where the semantics of sliding windows are different to those of hopping windows.
Hopping time windows are aligned to the epoch, with the lower interval bound being inclusive and the upper bound being exclusive. “Aligned to the epoch” means that the first window starts at timestamp zero. For example, hopping windows with a size of 5000ms and an advance interval (“hop”) of 3000ms have predictable window boundaries
[0;5000),[3000;8000),...— and not[1000;6000),[4000;9000),...or even something “random” like[1452;6452),[4452;9452),....
跳跃时间窗口Hopping time windows是基于时间间隔的窗口。它们为固定大小(可能)重叠的窗口建模。跳跃窗口由两个属性定义:窗口的size及其前进间隔advance interval (也称为hop)。前进间隔指定一个窗口相对于前一个窗口向前移动多少。例如,您可以配置一个size为5分钟、advance为1分钟的跳转窗口。由于跳跃窗口可以重叠(通常情况下确实如此),数据记录可能属于多个这样的窗口。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
private static final long TIME_WINDOW_SECONDS = 5L; //窗口大小设为5秒
private static final long ADVANCED_BY_SECONDS = 1L; //前进间隔1秒
@Test
public void testHoppingTimeWindowWithSuppress() throws InterruptedException {Properties props = configStreamProperties();StreamsBuilder builder = new StreamsBuilder();KStream<String, String> data = builder.stream(TEST_TOPIC);Instant initTime = Instant.now();data.groupByKey().windowedBy(TimeWindows.of(Duration.ofSeconds(TIME_WINDOW_SECONDS)).advanceBy(Duration.ofSeconds(ADVANCED_BY_SECONDS)).grace(Duration.ZERO)).count(Materialized.with(Serdes.String(), Serdes.Long())).suppress(Suppressed.untilWindowCloses(Suppressed.BufferConfig.unbounded())).toStream().filterNot(((key, value) -> this.isOldWindow(key, value, initTime))) //剔除太旧的时间窗口.foreach(this::dealWithTimeWindowAggrValue);Topology topology = builder.build();KafkaStreams streams = new KafkaStreams(topology, props);streams.start();Thread.currentThread().join();
}
|
注意到上面的代码中,我们还用到了grace(Duration.ZERO)和suppress(Suppressed.untilWindowCloses(Suppressed.BufferConfig.unbounded()))
后者的意思是:抑制住上游流的输出,直到当前时间窗口关闭后,才向下游发送数据。前面我们说过,每当统计值产生变化时,统计的结果会立即发送给下游。但是有些情况下,比如我们从kafka中的消息记录了应用程序的每次gc时间,我们的流任务需要统计每个时间窗口内的平均gc时间,然后发送给下游(下游可能是直接输出到控制台,也可能是另一个kafka topic或者一段报警逻辑)。那么,只要当这个时间窗口关闭时,向下游发送一个最终结果就够了。而且有的情况下,如果窗口还没关闭就发送到下游,可能导致错误的逻辑(比如数据抖动产生误报警)。
grace的意思是,设立一个数据晚到的期限,这个期限过了之后时间窗口才关闭。比如窗口大小为5,当15:20的时候,15:15-15:20的窗口应当关闭了,但是为了防止网络延时导致数据晚到,比如15点22分的时候,有可能才接收时间戳是15点20分的数据。所以我们可以把这个晚到时间设为2分钟,那么知道15点22的时候,15:15-15:20的窗口才关闭。
注意一个坑:**如果使用Suppressed.untilWindowCloses,那么窗口必须要指定grace。因为默认的grace时间是24小时。所以24小时之内窗口是一直不关闭的,而且由于被suppress住了,所以下游会一直收不到结果。**另外也可以使用Suppressed.untilTimeLimit来指定上游聚合计算的值在多久后发往下游,它与窗口是否关闭无关,所以可以不使用grace
上面的代码中,为了方便,我们令grace为0,也就是当窗口的截止时间到了后立即关闭窗口。
另外我们还使用suppress,抑制住中间的计算结果。所以可以看到,每个窗口关闭后,向下游(这里就是控制台)发送了一个最终结果“5”。
为了验证,我们去掉suppress方法试一下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
@Test
public void testHoppingTimeWindow() throws InterruptedException {Properties props = configStreamProperties();StreamsBuilder builder = new StreamsBuilder();KStream<String, String> data = builder.stream(TEST_TOPIC);Instant initTime = Instant.now();data.groupByKey().windowedBy(TimeWindows.of(Duration.ofSeconds(TIME_WINDOW_SECONDS)).advanceBy(Duration.ofSeconds(ADVANCED_BY_SECONDS)).grace(Duration.ZERO)).count(Materialized.with(Serdes.String(), Serdes.Long())).toStream().filterNot(((key, value) -> this.isOldWindow(key, value, initTime))).foreach(this::dealWithTimeWindowAggrValue);Topology topology = builder.build();KafkaStreams streams = new KafkaStreams(topology, props);streams.start();Thread.currentThread().join();
}
|
运行结果如下:

如果不仔细观察,可能会觉得结果很乱。所以我用方框做了区分:
51秒时第一个消息到达,使得所在的5个窗口都进行聚合计算count后,结果立即发往下游,所以是1,1,1,1,1。
52秒时第二个消息到达,所在的5个窗口都进行count累加计算后,结果立即发往下游,所以是2,2,2,2,1。注意到,最后的“1”是新的窗口(51秒-56秒窗口)的累加计算,所以值为1。而“46秒-51秒”这个窗口由于已经关闭,就不会再进行累加计算,从而不会有新的结果发送给下游输出。
53秒第三个消息到达,之前的2,2,2,2,1的第一个“2”所在窗口关闭了,然后剩下的三个分别加1,变成了3,3,3,2。另外还有一个新的时间窗口打开。所以最后得到3,3,3,2,1。
时间窗口上聚合计算的坑
上面我特意强调了两点,一是所在的窗口都进行聚合计算,二是聚合计算的结果立即发往下游。第二点我们已经验证了。我们将最开始Tumbling time window的程序加上suppres进一步验证一下。
聚合计算结果何时到达下游
之前的代码会输出123451234512345…,而且每个12345都是同一个窗口输出的。可见聚合结果计算后,默认会立即发给下游。
改变代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
@Test
public void testTumblingTimeWindowWithSuppress() throws InterruptedException {Properties props = configStreamProperties();StreamsBuilder builder = new StreamsBuilder();KStream<String, String> data = builder.stream(TEST_TOPIC);Instant initTime = Instant.now();data.groupByKey().windowedBy(TimeWindows.of(Duration.ofSeconds(TIME_WINDOW_SECONDS)).grace(Duration.ZERO)).count(Materialized.with(Serdes.String(), Serdes.Long())).suppress(Suppressed.untilWindowCloses(Suppressed.BufferConfig.unbounded())).toStream().filterNot(((key, value) -> this.isOldWindow(key, value, initTime))) .foreach(this::dealWithTimeWindowAggrValue);Topology topology = builder.build();KafkaStreams streams = new KafkaStreams(topology, props);streams.start();Thread.currentThread().join();
}
|
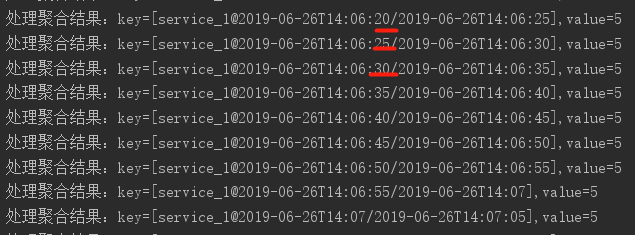
可以看到,只有当窗口关闭后,窗口的聚合结果才会发送到下游。所以最终下游只得到了555555…
何时进行聚合计算
我们再来看下第一点:当新的数据到来时,所在的时间窗口都会进行聚合计算。
有的人可能会误解,如果使用了Suppressed.untilWindowCloses,是不是只用在窗口关闭时进行一次求和计算就好了。其实不是这样的,只要一个数据落到了某个窗口内(同一数据可以落到多个窗口),窗口便会立即进行聚合计算。
我们继续使用testTumblingTimeWindowWithSuppress()的例子,改动如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
@Test
public void testTumblingTimeWindowWithSuppress() throws InterruptedException {Properties props = configStreamProperties();StreamsBuilder builder = new StreamsBuilder();KStream<String, String> data = builder.stream(TEST_TOPIC);Instant initTime = Instant.now();data.groupByKey().windowedBy(TimeWindows.of(Duration.ofSeconds(TIME_WINDOW_SECONDS)).grace(Duration.ZERO)).aggregate(() -> 0L, this::aggrDataInTimeWindow, Materialized.with(Serdes.String(), Serdes.Long())) // 使用自定义aggregator.suppress(Suppressed.untilWindowCloses(Suppressed.BufferConfig.unbounded())).toStream().filterNot(((key, value) -> this.isOldWindow(key, value, initTime))) .foreach(this::dealWithTimeWindowAggrValue);Topology topology = builder.build();KafkaStreams streams = new KafkaStreams(topology, props);streams.start();Thread.currentThread().join();
}private Long aggrDataInTimeWindow(String key, String value, Long curValue) {curValue++;System.out.println("聚合计算:key=" + key + ",value=" + value + "\nafter aggr, curValue=" + curValue);return curValue;
}
|
之前我们使用count()方法,现在我们使用aggregate()方法来达到count的同样功能,另外打印一行日志,这样我们就可以知道何时进行的聚合计算。
PS:aggregate方法接收三个参数,第一个指明聚合计算的初始值,第二个指明如何将流中当前元素累加到历史的聚合值上,第三个指明聚合计算后key和value的数据类型:
1 2 3 |
<VR> KTable<Windowed<K>, VR> aggregate(final Initializer<VR> initializer,final Aggregator<? super K, ? super V, VR> aggregator,final Materialized<K, VR, WindowStore<Bytes, byte[]>> materialized); |
运行后:
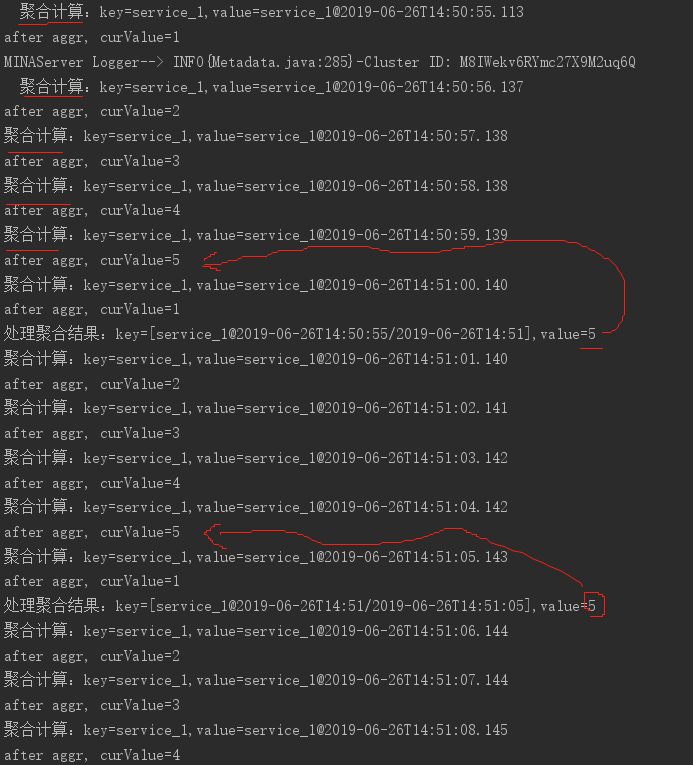
可以看到,虽然被suppress了,但是聚合函数会在每次数据到来时被调用。
进一步地,我们在使用hopping time windows 进行验证:到达的数据落到的每个窗口上,都会立即、分别调用该窗口的聚合函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
@Test
public void testHoppingTimeWindowWithSuppress() throws InterruptedException {Properties props = configStreamProperties();StreamsBuilder builder = new StreamsBuilder();KStream<String, String> data = builder.stream(TEST_TOPIC);Instant initTime = Instant.now();data.groupByKey().windowedBy(TimeWindows.of(Duration.ofSeconds(TIME_WINDOW_SECONDS)).advanceBy(Duration.ofSeconds(ADVANCED_BY_SECONDS)).grace(Duration.ZERO)).aggregate(() -> 0L, this::aggrDataInTimeWindow, Materialized.with(Serdes.String(), Serdes.Long())) // 使用自定义aggregator.suppress(Suppressed.untilWindowCloses(Suppressed.BufferConfig.unbounded())).toStream().filterNot(((key, value) -> this.isOldWindow(key, value, initTime))) .foreach(this::dealWithTimeWindowAggrValue);Topology topology = builder.build();KafkaStreams streams = new KafkaStreams(topology, props);streams.start();Thread.currentThread().join();
}
|
结果如下:
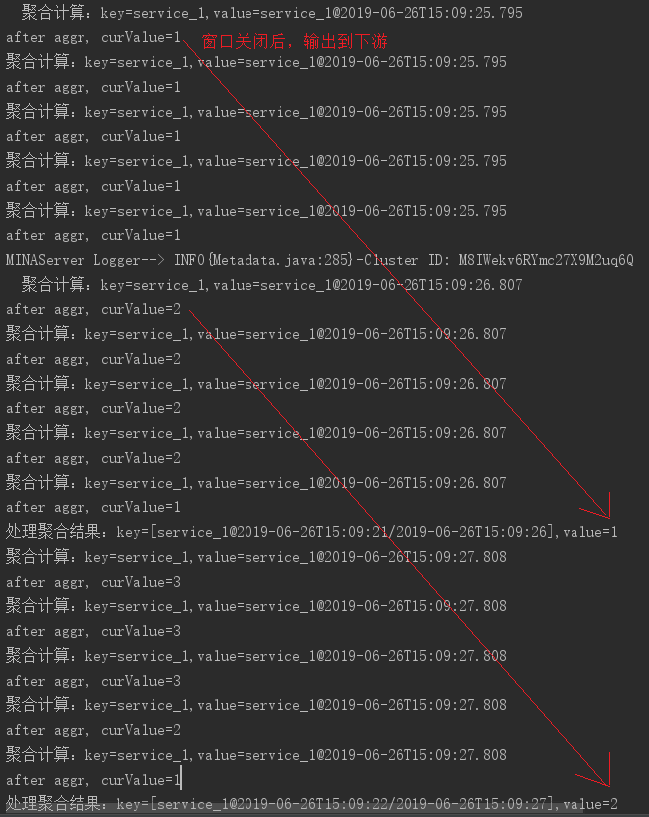
可以看到,由于我们设置的时间窗口size=5s,前进间隔hop=1s,所以每个数据可以同时落到5个窗口内(见图)。
小结
明白了事件窗口的聚合计算逻辑,我们在编程是就可以避免一些错误。比如自定义聚合函数时,Aggregator内应当只负责聚合计算,不应把其他的逻辑(比如将计算结果保存到db)写到Aggreagator里面。如果这样做了,一旦修改了时间窗口的配置,修改了时间窗口类型、grace、suppress等,会导致混乱的结果。Aggreagator应当只封装聚合算法,而其他的逻辑如filter、map等应当单独封装。
Time
最后我们研究下Kafka Stream中的时间概念。
上面我们利用时间窗口进行了实时计算,用起来很方便。但是你有没有想过,当我们的流任务收到一条消息时,是如何定义这条消息的时间戳呢?
这个问题其实不光是Kafka Stream的问题,也牵扯到Kafka基本生产者消费者模型。但是由于实时计算的特点,在Kafka Stream中需要格外关注。
Kafka有这样几个时间概念: http://kafka.apache.org/23/documentation/streams/core-concepts#streams_time
- Event time - 事件时间:事件真正发生的时间点,比如一个GPS设备在某刻捕获到了位置变化,产生了一个记录,这就是事件时间。(也就是说,事件时间与Kafka无关)
- Processing time - 处理时间:KafkaStream应用处理数据的时间点,即消息被应用消费时的时间点。此时间点比EventTime晚,有可能是毫秒、小时甚至几天。
- Ingestion time - 摄入时间:消息被存入到Kafka的时间点。(准确地说是存入到Topic分区的时间点)。
摄入时间与事件时间的区别:前者是消息存入到topic的时间,后者是事件发生的事件。 摄入时间与处理时间的去表:后者是被KafkaStream应用消费到的时间点。如果一个记录从未被消费,则它拥有摄入时间而没有处理时间。
The choice between event-time and ingestion-time is actually done through the configuration of Kafka (not Kafka Streams): From Kafka 0.10.x onwards, timestamps are automatically embedded into Kafka messages. Depending on Kafka’s configuration these timestamps represent event-time or ingestion-time. The respective Kafka configuration setting can be specified on the broker level or per topic. The default timestamp extractor in Kafka Streams will retrieve these embedded timestamps as-is. Hence, the effective time semantics of your application depend on the effective Kafka configuration for these embedded timestamps.
指定事件时间
应用可以自行将事件时间信息保存到消息内容里,然后将消息发送到kafka。在KafkaStream应用中,继承TimeStampExtractor,在重载的extract方法中定义如何从消息中抽取时间时间。并在构造KafkaStream的props里配置上该自定义的时间提取器。
比如我们自定义一个TimeStampExtractor,它可以从消息体中抽取我们在发送时写入的时间信息。
1 2 3 4 5 6 7 8 9 10 11 12 |
public class MyTimestampExtractor implements TimestampExtractor {@Overridepublic long extract(ConsumerRecord<Object, Object> record, long timeMill) {String value = record.value().toString();String eventTimeStr = value.split("@")[1]; //发送消息时 value = key + "@" + timeStrLocalDateTime eventTime = LocalDateTime.parse(eventTimeStr);Instant instant = eventTime.toInstant(ZoneOffset.ofHours(8));return instant.toEpochMilli();}}
|
我们在发送消息的时候,将时间信息放到消息内容里,但是我们做个小把戏,将时间对齐到每分钟的0秒。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
@BeforeClass
public static void generateValue() {Properties props = new Properties();props.put("bootstrap.servers", BOOT_STRAP_SERVERS);props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("request.required.acks", "0");new Thread(() -> {Producer<String, String> producer = new KafkaProducer<>(props);try {while (true) {TimeUnit.SECONDS.sleep(1L);Instant now = Instant.now();String key = "service_1";// 将时间信息放到消息内容里,但是我们做个小把戏,将时间对齐到每分钟的0秒String value = key + "@" + alignToMinute(now);producer.send(new ProducerRecord<>(TEST_TOPIC, key, value));}} catch (Exception e) {e.printStackTrace();producer.close();}}).start();
}
|
然后需要指定使用我们自定义的时间提取器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
private static final long TIME_WINDOW_SECONDS = 5L;
@Test
public void testEventTime() throws InterruptedException {Properties props = configStreamProperties();// 指定使用自定义的时间提取器props.put(StreamsConfig.DEFAULT_TIMESTAMP_EXTRACTOR_CLASS_CONFIG, MyTimestampExtractor.class);StreamsBuilder builder = new StreamsBuilder();KStream<String, String> data = builder.stream(TEST_TOPIC);Instant initTime = Instant.now();data.groupByKey().windowedBy(TimeWindows.of(Duration.ofSeconds(TIME_WINDOW_SECONDS))) // 使用翻滚窗口.count(Materialized.with(Serdes.String(), Serdes.Long())).toStream().filterNot(((key, value) -> this.isOldWindow(key, value, initTime))).foreach(this::dealWithTimeWindowAggrValue);Topology topology = builder.build();KafkaStreams streams = new KafkaStreams(topology, props);streams.start();Thread.currentThread().join();
}
|
我们的窗口大小仍然是5秒,使用翻滚窗口,聚合计算的值立即输出到下游(控制台)。
还记的在Tumbling time windows小节里的例子吗,当时的输出是123451234512345…。但是我们现在使用自定义时间提取器,从消息内容里提取时间信息,而在发送时做了点小把戏,所以在同一分钟内接收到的消息,提出来的时间都是0秒的,也就是都会落到第一个时间窗口内(0秒-5秒窗口)。
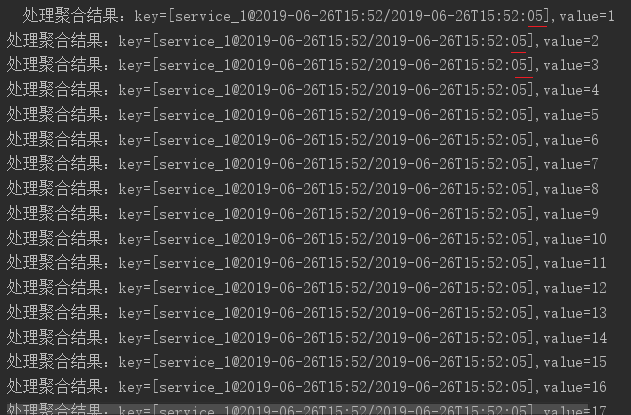
使用内嵌的时间戳
如果不制定自定义的时间提取器,时间又是哪里来的呢? kafka每条消息中其实自带了时间戳,作为CreateTime 我们在发送消息时,一般时这样写的
1 |
producer.send(new ProducerRecord<>(TOPIC, key, value) |
看线ProducerRecord的这个构造方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
public ProducerRecord(String topic, K key, V value) {this(topic, null, null, key, value, null);
}/*** Creates a record with a specified timestamp to be sent to a specified topic and partition* * @param topic The topic the record will be appended to* @param partition The partition to which the record should be sent* @param timestamp The timestamp of the record, in milliseconds since epoch. If null, the producer will assign* the timestamp using System.currentTimeMillis().* @param key The key that will be included in the record* @param value The record contents* @param headers the headers that will be included in the record*/
public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value, Iterable<Header> headers) {//...
}
|
我们注意到第三个参数,如果传入的是null,则会使用System.currentTimeMillis()
KafkaStream在不配置自定义TimeStampExtractor时,会使用这个消息中内嵌的时间戳,而这个时间戳可能是Producer程序中ProducerRecord生成的时候的时刻,也可能是消息写入到topic的log文件中的时刻。
相关配置:message.timestamp.type。
| name | desc | type | default | VALID VALUES |
|---|---|---|---|---|
| message.timestamp.type | Define whether the timestamp in the message is message create time or log append time | string | CreateTime | [CreateTime, LogAppendTime] |
该配置在broker和topic维度上可分别配置。
我们再进行实验,这次不配置自定义的TimestampExtractor了。这时默认的TimeStampExtractor会使用消息中内嵌的时间戳。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
@Test
public void testEventTime() throws InterruptedException {Properties props = configStreamProperties();// 指定使用自定义的时间提取器// props.put(StreamsConfig.DEFAULT_TIMESTAMP_EXTRACTOR_CLASS_CONFIG, MyTimestampExtractor.class);StreamsBuilder builder = new StreamsBuilder();KStream<String, String> data = builder.stream(TEST_TOPIC);Instant initTime = Instant.now();data.groupByKey().windowedBy(TimeWindows.of(Duration.ofSeconds(TIME_WINDOW_SECONDS))).count(Materialized.with(Serdes.String(), Serdes.Long())).toStream().filterNot(((key, value) -> this.isOldWindow(key, value, initTime))).foreach(this::dealWithTimeWindowAggrValue);Topology topology = builder.build();KafkaStreams streams = new KafkaStreams(topology, props);streams.start();Thread.currentThread().join();
}
|
在发送的时候,传入内嵌的时间戳的值,但是我们做个小把戏,将时间对齐到每分钟的30秒。这时默认的TimeStampExtractor从内嵌的时间戳提取出来后,会发现他们都落在“30秒-35秒”这个窗口内。
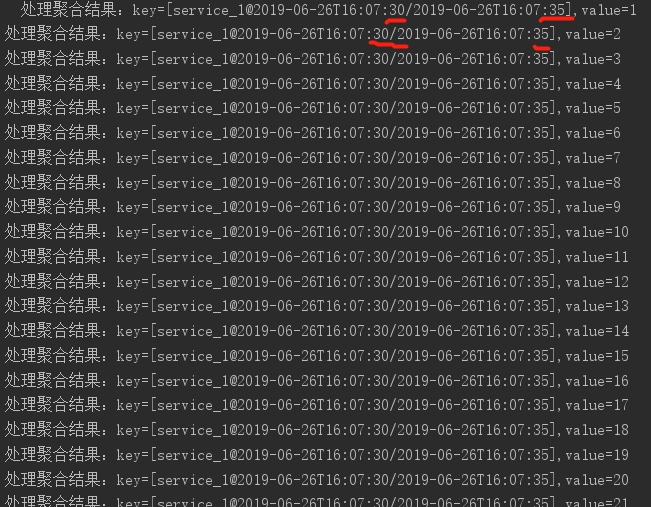
上面讲的是流任务面对收到的消息时,如何获取时间信息。
而当流任务如果要将处理过的内容打回Kafka时,是如何添加时间信息的呢?
Whenever a Kafka Streams application writes records to Kafka, then it will also assign timestamps to these new records. The way the timestamps are assigned depends on the context:
- When new output records are generated via processing some input record, for example,
context.forward()triggered in theprocess()function call, output record timestamps are inherited from input record timestamps directly.- When new output records are generated via periodic functions such as
Punctuator#punctuate(), the output record timestamp is defined as the current internal time (obtained throughcontext.timestamp()) of the stream task.- For aggregations, the timestamp of a resulting aggregate update record will be that of the latest arrived input record that triggered the update.
Note, that the describe default behavior can be changed in the Processor API by assigning timestamps to output records explicitly when calling
#forward().
总结
- Kafka Stream中有4种时间窗口:
Tumbling time window、Hopping time window、sliding time window、session time window - 可以使用supress方法不让每次新的数据落到窗口内时,都立即向下游发送新的统计值。
- 如果使用
Suppressed.untilWindowCloses,那么窗口必须要指定grace。因为默认的grace时间是24小时。所以24小时之内窗口是一直不关闭的,而且由于被suppress住了,所以下游会一直收不到结果。 - 可以使用
Suppressed.untilTimeLimit来指定上游聚合计算的值在多久后发往下游,它与时间窗口是否关闭无关,所以可以不使用grace。 - 到达的数据落到的每个窗口上,都会立即、分别调用该窗口的聚合函数,计算结果默认情况下立即发送到下游,除非使用了suppress()。
- Aggregator内应当只负责聚合计算,不应把其他的逻辑(比如将计算结果保存到db)写到Aggreagator里面。如果这样做了,一旦修改了时间窗口的配置,修改了时间窗口类型、grace、suppress等,会导致混乱的结果。
- KafkaStream的默认TimeStampExtractor,会提取消息中内嵌的时间戳,供依赖于时间的操作(如windowBy)使用。这个时间戳可能是Producer程序中
ProducerRecord生成的时刻,也可能是消息写入到topic的log文件中的时刻,取决于message.timestamp.type配置。 - 如果要使用事件时间,发送消息时可将事件时间信息保存到消息内容里,然后将消息发送到kafka。在KafkaStream应用中,继承TimeStampExtractor,在重载的extract方法中定义如何从消息中抽取时间时间。并在构造KafkaStream的props里配置上该自定义的时间提取器。
参考文档
Kafka Stream 官方文档
KafkaStream之时间窗口WindowBy相关推荐
- 2021年大数据Spark(五十二):Structured Streaming 事件时间窗口分析
目录 事件时间窗口分析 时间概念 event-time 延迟数据处理 延迟数据 Watermarking 水位 官方案例演示 事件 ...
- sentinel 时间窗口_Sentinel使用令牌桶实现预热【原理源码】
前言 Sentinel的QPS流控效果有快速失败.预热模式.排队等待.预热+排队等待模式,本文主要分析预热模式中是如何使用令牌桶算法限流的. 一.流控效果源码结构 在FlowRule更新缓存时,根据配 ...
- Java 实现滑动时间窗口限流算法,你见过吗?
点击上方蓝色"程序猿DD",选择"设为星标" 回复"资源"获取独家整理的学习资料! 作者 | dijia478 来源 | https://w ...
- mongodb 服务器时区设置_关于MongoDB-Balancer设置时间窗口的问题
##7月1日19点过5分,设置时间窗口为12:00-12:10 [mongodb@cst ~]$ date Wed Jul 1 19:05:41 CST 2015 [mongodb@cst ~]$ / ...
- sentinel 时间窗口_Sentinel潜龙勿用篇
前言 我为什么写这篇文章,是因为Sentinel实在是太强大太好用了,再加上阿里开源,Sentinel的发展迅猛.已有多家公司生产使用,但但凡神功,一个不慎,就有可能走火入魔,轻则离职走人,重则走火入 ...
- 基于 Scheduled SQL 对 VPC FlowLog 实现细粒度时间窗口分析
简介: 针对VPC FlowLog的五元组和捕获窗口信息,在分析时使用不同时间窗口精度,可能得到不一样的流量特征,本文介绍一种方法将原始采集日志的时间窗口做拆分,之后重新聚合为新的日志做分析,达到更细 ...
- 使用Spark Streaming SQL基于时间窗口进行数据统计
1.背景介绍 流式计算一个很常见的场景是基于事件时间进行处理,常用于检测.监控.根据时间进行统计等系统中.比如埋点日志中每条日志记录了埋点处操作的时间,或者业务系统中记录了用户操作时间,用于统计各种操 ...
- 专家:未来三年为转云时间窗口
本文讲的是专家:未来三年为转云时间窗口,物理主机托管业态在云计算的冲击下逐步云化是大势所趋.或者说IDC转云不是转不转的问题,而是什么时候转和怎么转的问题. 传统的物理主机托管业务主要涵盖了主机托管. ...
- sentinel 时间窗口的实现
本文的github地址点击这里 获取时间窗口的主要流程 在 Sentinel 中,主要是通过 LeapArray 类来实现滑动时间窗口的实现和选择.在 sentinel 的这个获取时间窗口并为时间窗口 ...
- Flink从入门到真香(12、Flink一大利器-时间窗口)
flink中支持多种窗口,包括:时间窗口,session窗口,统计窗口等等,能想到的基本都可以实现 时间窗口(Time Windows) 最简单常用的窗口形式是基于时间的窗口,flink支持三种种时间 ...
最新文章
- 【Netty】NIO 简介 ( NIO 模型 | NIO 三大组件 | 选择器 Selector | 通道 Channel | 缓冲区 Buffer | NIO 组件分配 | 缓冲区示例 )
- java中单列集合的根接口是_java 单列集合总结
- jquery 遍历java对象的属性_用jquery each标签遍历java list对象
- Linux-Android启动之Machine-Init函数
- 合成/聚合原则: 桥接模式
- java静态初始化模块,在静态初始化程序块中加载java属性
- 钉钉机器人自动推送股票信息
- 如果微软开发了 Android,会有何不同?
- 干货丨3分钟了解今日头条推荐算法原理(附视频+PPT)
- gst-launch命令转换为C代码(gstreamer框架)
- html中图片左右切换,超简单的图片左右切换滑动
- 使用python修复文件乱码
- K8S DiskPressure造成pod被驱逐——筑梦之路
- 解决Ubuntu Linux终端输入命令没有颜色提示的设置方法
- 加密芯片ATSHA204读序列号(Serial Number)
- MPLAB常见问题及解决方法
- 去除em斜体的方法_鱼缸水体pH值对观赏鱼的影响,以及偏高或偏低的调节方法...
- 输入法编程相关资源汇集-欢迎补充
- 201571030121《小学四则运算练习软件软件需求说明》结对项目报告
- Hibernate QBC与QBE