如何快速爬取网页数据(干货)
摘要:对于程序员或开发人员来说,拥有编程能力使得他们构建一个网页数据爬取程序,非常的容易并且有趣。但是对于大多数没有任何编程知识的人来说,最好使用一些网络爬虫软件从指定网页获取特定内容。
网页数据爬取是指从网站上提取特定内容,而不需要请求网站的API接口获取内容。“网页数据” 作为网站用户体验的一部分,比如网页上的文字,图像,声音,视频和动画等,都算是网页数据。
对于程序员或开发人员来说,拥有编程能力使得他们构建一个网页数据爬取程序,非常的容易并且有趣。但是对于大多数没有任何编程知识的人来说,最好使用一些网络爬虫软件从指定网页获取特定内容。以下是一些使用八爪鱼采集器抓取网页数据的几种解决方案:
1、从动态网页中提取内容
网页可以是静态的也可以是动态的。通常情况下,您想要提取的网页内容会随着访问网站的时间而改变。通常,这个网站是一个动态网站,它使用AJAX技术或其他技术来使网页内容能够及时更新。AJAX即延时加载、异步更新的一种脚本技术,通过在后台与服务器进行少量数据交换,可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
表现特征为点击网页中某个选项时,大部分网站的网址不会改变;网页不是完全加载,只是局部进行了数据加载,有所变化。这个时候你可以在八爪鱼的元素“高级选项”的“Ajax加载”中可以设置,就能抓取Ajax加载的网页数据了。
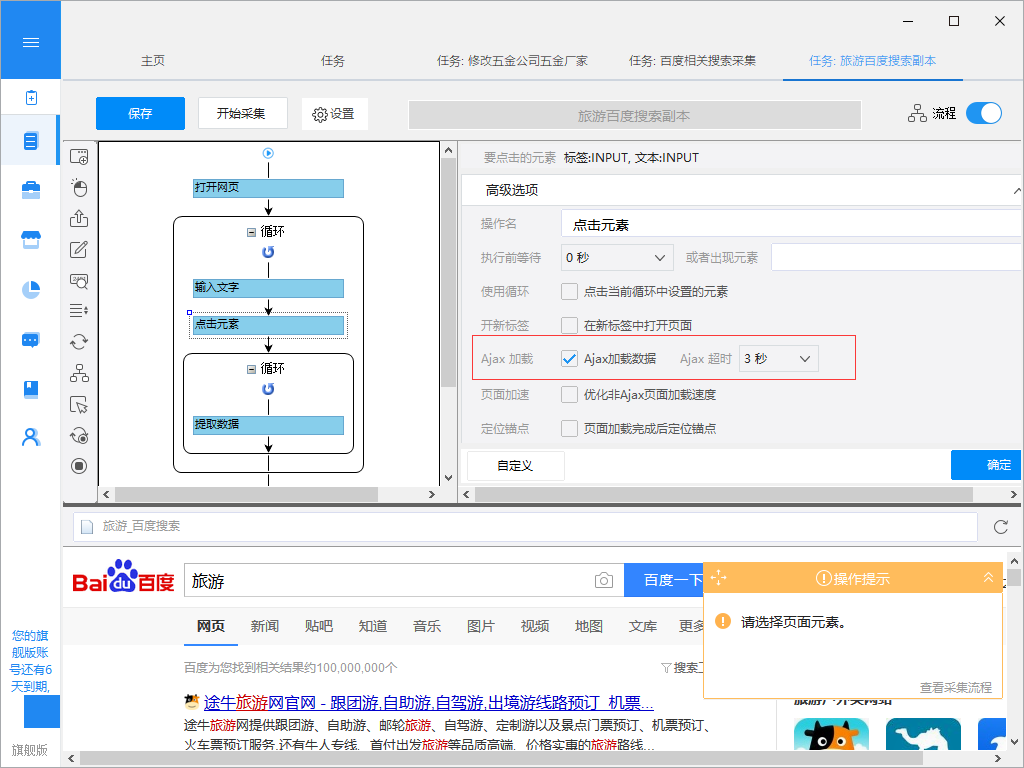
2、从网页中抓取隐藏的内容
你有没有想过从网站上获取特定的数据,但是当你触发链接或鼠标悬停在某处时,内容会出现?例如,下图中的网站需要鼠标移动到选择彩票上才能显示出分类,这对这种可以设置“鼠标移动到该链接上”的功能,就能抓取网页中隐藏的内容了。
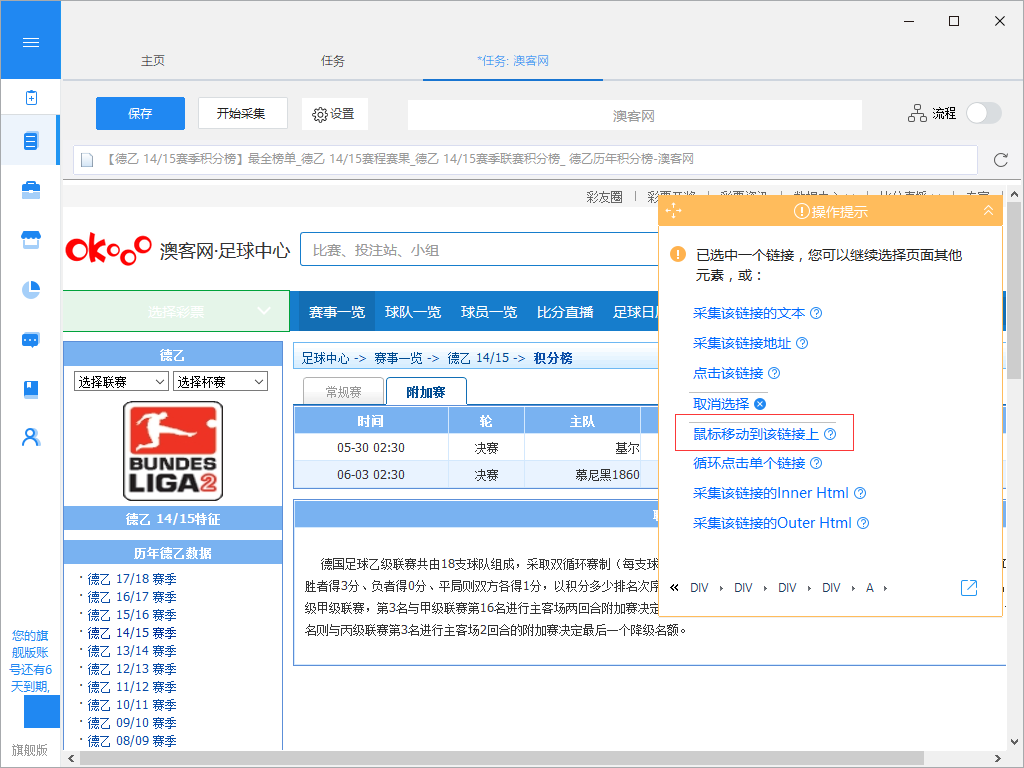
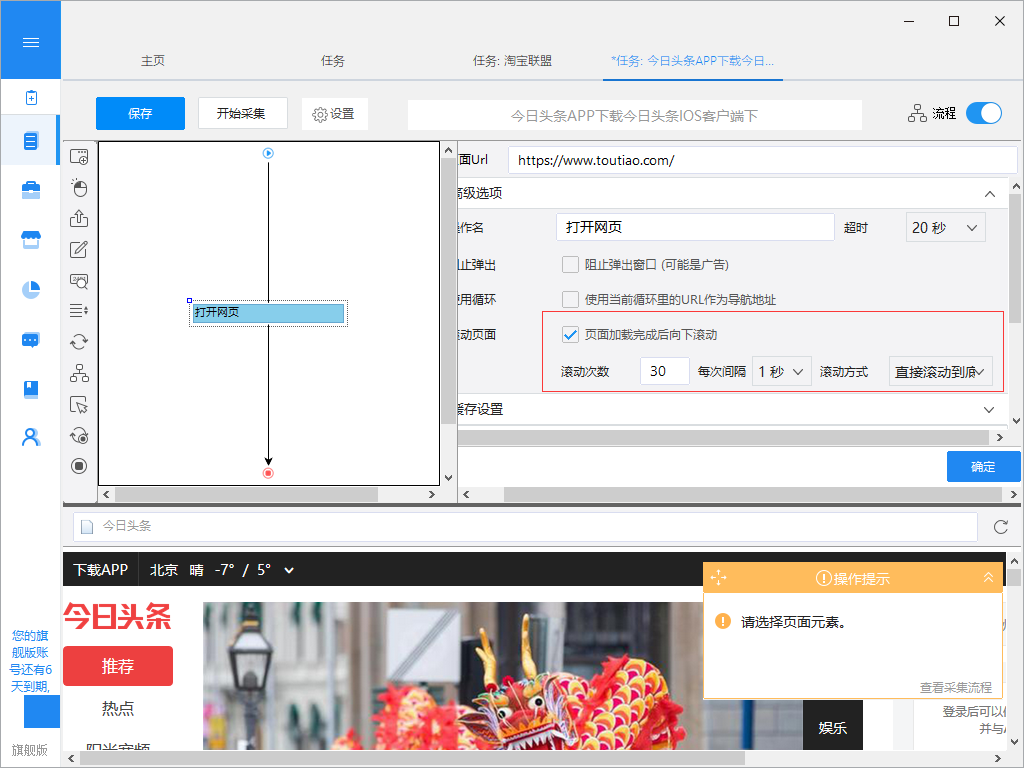
3、从无限滚动的网页中提取内容
在滚动到网页底部之后,有些网站只会出现一部分你要提取的数据。例如今日头条首页,您需要不停地滚动到网页的底部以此加载更多文章内容,无限滚动的网站通常会使用AJAX或JavaScript来从网站请求额外的内容。在这种情况下,您可以设置AJAX超时设置并选择滚动方法和滚动时间以从网页中提取内容。
4、从网页中爬取所有链接
一个普通的网站至少会包含一个超级链接,如果你想从一个网页中提取所有的链接,你可以用八爪鱼来获取网页上发布的所有超链接。
5、从网页中爬取所有文本
有时您需要提取HTML文档中的所有文本,即放置在HTML标记(如<DIV>标记或<SPAN>标记)之间的内容。八爪鱼使您能够提取网页源代码中的所有或特定文本。
6、从网页中爬取所有图像
有些朋友有采集网页图片的需求。八爪鱼可以将网页中图片的URL采集,再通过下载使用八爪鱼专用的图片批量下载工具,就能将我们采集到的图片URL中的图片下载并保存到本地电脑中。
如何快速爬取网页数据(干货)相关推荐
- 如何利用python的newspaper包快速爬取网页数据
文章目录 前言 一个爬取新闻网页数据的神器 小试牛刀 如何快速安装 windows安装 Debian / Ubuntu安装 OSX安装 体验更多的功能 前言 随着越来的进行自然语言处理相关方面的研究, ...
- Python小姿势 - Python爬取网页数据
Python爬取网页数据 爬取网页数据是一个比较常见的Python应用场景,有很多第三方库可以帮助我们完成这个任务.这里我们介绍一下urllib库中的一个常用方法:urllib.request.url ...
- python初学-爬取网页数据
python初学-爬取网页数据 1,获取网页源代码 import urllib url = 'http://www.163.com'wp = urllib.urlopen(url) file_cont ...
- 爬虫批量保存网页html,2分钟带你学会网络爬虫:Excel批量爬取网页数据(详细图文版)...
面对网页大量的数据,有时候还要翻页,你还在一页一页地复制粘贴吗?别人需要几小时完成的任务,学会这个小技巧你只需要几分钟就能解决.快来学习使用Excel快速批量地爬取网页数据吧! 1.分析网页数据结构 ...
- Jsoup:用Java也可以爬虫,怎么使用Java进行爬虫,用Java爬取网页数据,使用Jsoup爬取数据,爬虫举例:京东搜索
Jsoup:用Java也可以爬虫,怎么使用Java进行爬虫,用Java爬取网页数据,使用Jsoup爬取数据,爬虫举例:京东搜索 一.资源 为什么接下来的代码中要使用el.getElementsByTa ...
- python爬取网页公开数据_如何用Python爬取网页数据
使用Python爬取网页数据的方法: 一.利用webbrowser.open()打开一个网站:>>> import webbrowser >>> webbrowse ...
- 编程python爬取网页数据教程_实例讲解Python爬取网页数据
一.利用webbrowser.open()打开一个网站: >>> import webbrowser >>> webbrowser.open('http://i.f ...
- python爬取网页数据(例如淘宝)
爬取网页数据(例如淘宝) 现在淘宝商品页面不能直接爬取,需要登录,所以我们得实现模拟登录,如下即可实现模拟登录: import requests cookie_str = r'cna=QsJDGKPt ...
- python爬虫教程:实例讲解Python爬取网页数据
这篇文章给大家通过实例讲解了Python爬取网页数据的步骤以及操作过程,有兴趣的朋友跟着学习下吧. 一.利用webbrowser.open()打开一个网站: >>> import w ...
- 如何使用python实现简单爬取网页数据并导入MySQL中的数据库
前言:要使用 Python 爬取网页数据并将数据导入 MySQL 数据库,您需要使用 Requests 库进行网页抓取,使用 BeautifulSoup 库对抓取到的 HTML 进行解析,并使用 Py ...
最新文章
- Office 365系列(7)------ Exchange 2013与Office 365 Hybrid混合部署Step by Step参考
- Linux学习笔记 Day 4~5
- gson生成jsonobject_GSON形式生成和解析json数据
- C++描述杭电OJ 2015.偶数求和 ||
- 小程序和android联调,小程序打开APP指定页面
- 计算机控制考试试卷及答案,计算机控制系统A考试试卷带答案.doc
- click Arguments
- python_day9 异常处理
- 关于为什么说OLTP必须要求变量绑定而OLAP不应该绑定变量的原因
- 爬取微博的数据时别人用的是FM.view方法传递html标签那么jsoup怎么解析呢
- 国内外优秀音视频博客索引(持续更新)
- 分享超级表格用户在知乎上与我们的对话
- 高德地图语音助手实测:驾车导航基本实现动口不动手
- 天刀服务器维护时间表,3月2日服务器例行维护公告
- mock.js文档详解5及下载(Random中的Name,Web,Address种类函数)
- 【情感分析:挖掘观点、情感和情绪】读书笔记-01
- glibc 知:手册06:字符集处理
- 基于SSH的实验室预约管理系统
- 定制化chromium的修改方法
- Ubuntu16.04 + Geforce GT630 OEM安装cuda 8.0