关于KL距离(KL Divergence)
作者:覃含章
链接:https://www.zhihu.com/question/29980971/answer/103807952
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
最早KL divergence就是从信息论里引入的,不过既然题主问的是ML中的应用,就不多做具体介绍。只是简单概述给定真实概率分布P和近似分布Q,KL divergence所表达的就是如果我们用一套最优的压缩机制(compression scheme)来储存Q的分布,对每个从P来的sample我需要多用的bits(相比我直接用一套最优的压缩机制来储存P的分布)。这也叫做 Kraft–McMillan theorem。
所以很自然的它可以被用作统计距离,因为它本身内在的概率意义。然而,也正因为这种意义,题主所说的不对称性是不可避免的。因为D(P||Q)和D(Q||P)回答的是基于不同压缩机制下的“距离”问题。
至于general的统计距离,当然,它们其实没有本质差别。更广泛的来看,KL divergence可以看成是phi-divergence的一种特殊情况(phi取log)。注意下面的定义是针对discrete probability distribution,但是把sum换成integral很自然可以定义连续版本的。
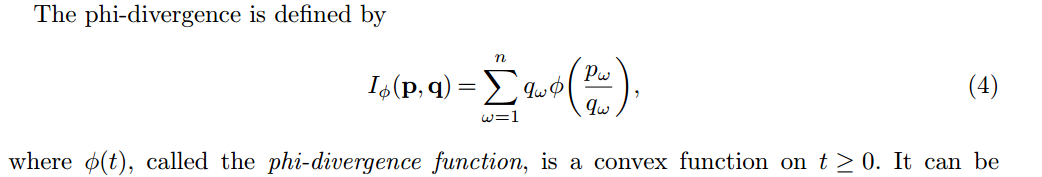
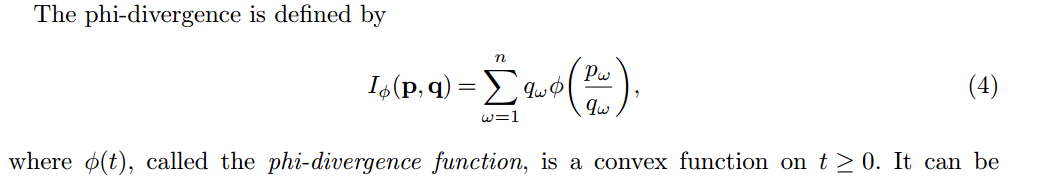 用其它的divergence理论来做上是没有本质区别的,只要phi是convex, closed的。
用其它的divergence理论来做上是没有本质区别的,只要phi是convex, closed的。

 因为它们都有相似的概率意义,比如说pinsker's theorem保证了KL-divergence是total variation metric的一个tight bound. 其它divergence metric应该也有类似的bound,最多就是order和常数会差一些。而且,用这些divergence定义的minimization问题也都会是convex的,但是具体的computation performance可能会有差别,所以KL还是用的多。
因为它们都有相似的概率意义,比如说pinsker's theorem保证了KL-divergence是total variation metric的一个tight bound. 其它divergence metric应该也有类似的bound,最多就是order和常数会差一些。而且,用这些divergence定义的minimization问题也都会是convex的,但是具体的computation performance可能会有差别,所以KL还是用的多。


Reference: Bayraksan G, Love DK. Data-Driven Stochastic Programming Using Phi-Divergences.
链接:https://www.zhihu.com/question/29980971/answer/93489660
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
KL divergence KL(p||q), in the context of information theory, measures the amount of extra bits (nats) that is necessary to describe samples from the distribution p with coding based on q instead of p itself. From the Kraft-Macmillan theorem, we know that the coding scheme for one value out of a set X can be represented q(x) = 2^(-l_i) as over X, where l_i is the length of the code for x_i in bits.
We know that KL divergence is also the relative entropy between two distributions, and that gives some intuition as to why in it's used in variational methods. Variational methods use functionals as measures in its objective function (i.e. entropy of a distribution takes in a distribution and return a scalar quantity). It's interpreted as the "loss of information" when using one distribution to approximate another, and is desirable in machine learning due to the fact that in models where dimensionality reduction is used, we would like to preserve as much information of the original input as possible. This is more obvious when looking at VAEs which use the KL divergence between the posterior q and prior p distribution over the latent variable z. Likewise, you can refer to EM, where we decompose
ln p(X) = L(q) + KL(q||p)
Here we maximize the lower bound on L(q) by minimizing the KL divergence, which becomes 0 when p(Z|X) = q(Z). However, in many cases, we wish to restrict the family of distributions and parameterize q(Z) with a set of parameters w, so we can optimize w.r.t. w.
Note that KL(p||q) = - \sum p(Z) ln (q(Z) / p(Z)), and so KL(p||q) is different from KL(q||p). This asymmetry, however, can be exploited in the sense that in cases where we wish to learn the parameters of a distribution q that over-compensates for p, we can minimize KL(p||q). Conversely when we wish to seek just the main components of p with q distribution, we can minimize KL(q||p). This example from the Bishop book illustrates this well.
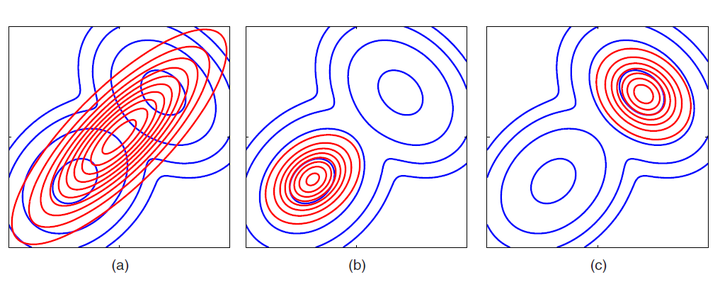
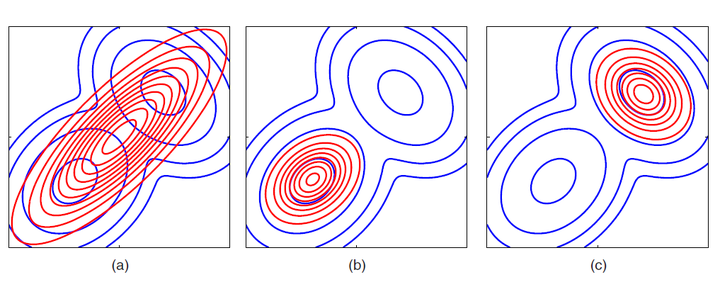
KL divergence belongs to an alpha family of divergences, where the parameter alpha takes on separate limits for the forward and backwards KL. When alpha = 0, it becomes symmetric, and linearly related to the Hellinger distance. There are other metrics such as the Cauchy Schwartz divergence which are symmetric, but in machine learning settings where the goal is to learn simpler, tractable parameterizations of distributions which approximate a target, they might not be as useful as KL.
关于KL距离(KL Divergence)相关推荐
- Kullback–Leibler divergence(相对熵,KL距离,KL散度)
1 前言 注意两个名词的区别: 相对熵:Kullback–Leibler divergence 交叉熵:cross entropy KL距离的几个用途: ① 衡量两个概率分布的差异. ② 衡量利用概率 ...
- kl距离 java_KL距离,Kullback-Leibler Divergence
http://www.cnblogs.com/ywl925/p/3554502.html http://www.cnblogs.com/hxsyl/p/4910218.html http://blog ...
- KL距离,Kullback-Leibler Divergence 浅谈KL散度
KL距离,是Kullback-Leibler差异(Kullback-Leibler Divergence)的简称,也叫做相对熵(Relative Entropy).它衡量的是相同事件空间里的两个概率分 ...
- 相对熵(relative entropy或 Kullback-Leibler divergence,KL距离)的java实现(三)
代码下载 http://files.cnblogs.com/finallyliuyu/KL.rar 主函数代码 主函数代码 public static void main(String[] args) ...
- KL距离的计算与含义(转)
KL距离,是Kullback-Leibler差异(Kullback-Leibler Divergence)的简称,也叫做相对熵(Relative Entropy).它衡量的是相同事件空间里的两个概率分 ...
- kl距离 java_信息量、熵、最大熵、联合熵、条件熵、相对熵、互信息。
一直就对机器学习中各种XX熵的概念比较模糊,现在总结一下自己的学习心得. 信息量 先说一下信息量的概念,其实熵就是信息量的集合. 摘抄个例子: 英文有26个字母,假设每个字母出现的概率是一样的,每个字 ...
- 关于相对熵(KL距离)的理解
定义:两个概率质量函数为 p(x) 和 q(x) 之间的相对熵或KL距离定义为 D(p||q)=∑x∈χp(x)logp(x)q(x) 理解 如果已知随机变量的真实分布为 p ,可以构造平均描述长度为 ...
- 计算KL距离的几个例子
原理 生成两个分布,并且生成它们的ksdensity, 和histogram, 最后计算ksdensity 和 histogram与真实分布的KL距离 真实分布是用normpdf计算出来的 Kerne ...
- 信息论:信息熵+信息散度(交叉熵\kl距离)
信息散度(交叉熵\kl距离) 思考题:对于只用A,B,C,D四个单词写的信使用0和1进行编码的一个信息的平均编码长度?思考题:对于只用A,B,C,D四个单词写的信\\ 使用0和1进行编码的一个信息的平 ...
- Matlab 显著性检测模型评价算法之KL距离
KL距离是用来计算两个概率分布函数的差异大小: h是ground thruth map,p是saliency map,当h和p完全相等时,KL值为0 现在一般用对称形式,即h和p换个位置,求个KL,两 ...
最新文章
- 万字长文总结机器学习的模型评估与调参 | 附代码下载
- Html引入百度富文本编辑器ueditor
- STM32F1与STM32F0在GPIO_TypeDef 寄存器方面的不同
- html iframe php,html iframe使用的实战总结分享
- 算法导论-15.5-4
- apache ab测试与centos系统优化
- C++冒泡排序(正宗版)
- 英语常用九种时态记忆要点
- 变量的作用域与生命周期
- 往届毕业生档案去向查询网_大学毕业档案怎么处理 毕业生档案去向查询
- Mac SOME/IP编译以及Ubuntu的SOME/IP集成与编译
- 浙江大学计算机学院 翁恺,“中文MOOC第一人”浙江大学教师翁恺获得百万大奖...
- moment获取几小时前_moment.js 常用(几天前、相差几天、自然周、自然月)
- 【Linux】更改登陆时显示的账号名称
- 重装系统后激活win10和office2016
- 匿名社交?无秘模式基本宣告失败
- deepCopy:1 Uncaught SyntaxError: Identifier ‘xxx’ has already been declared
- nib must contain exactly one top level object which must be a UITableViewCell instance
- 重新认识你自己-克里希那穆提
- jpg与png图片的优缺点