【NLP】【七】fasttext源码解析
2019独角兽企业重金招聘Python工程师标准>>> 
【一】关于fasttext
fasttext是Facebook开源的一个工具包,用于词向量训练和文本分类。该工具包使用C++11编写,全部使用C++11 STL(这里主要是thread库),不依赖任何第三方库。具体使用方法见:https://fasttext.cc/ ,在Linux 使用非常方便。fasttext不仅提供了软件源码,还提供了训练好的一些模型(多语种的词向量:英文、中文等150余种)
源码地址:https://github.com/facebookresearch/fastText/
gensim也对该功能进行了封装,可以直接使用。
fasttext的源码实现非常优雅,分析源码,带来以下几方面的收获:
1. 如何组织文本数据?
2. CBOW和skip-gram是如何实现的?
3. 模型如何量化?
【二】fasttext整体结构
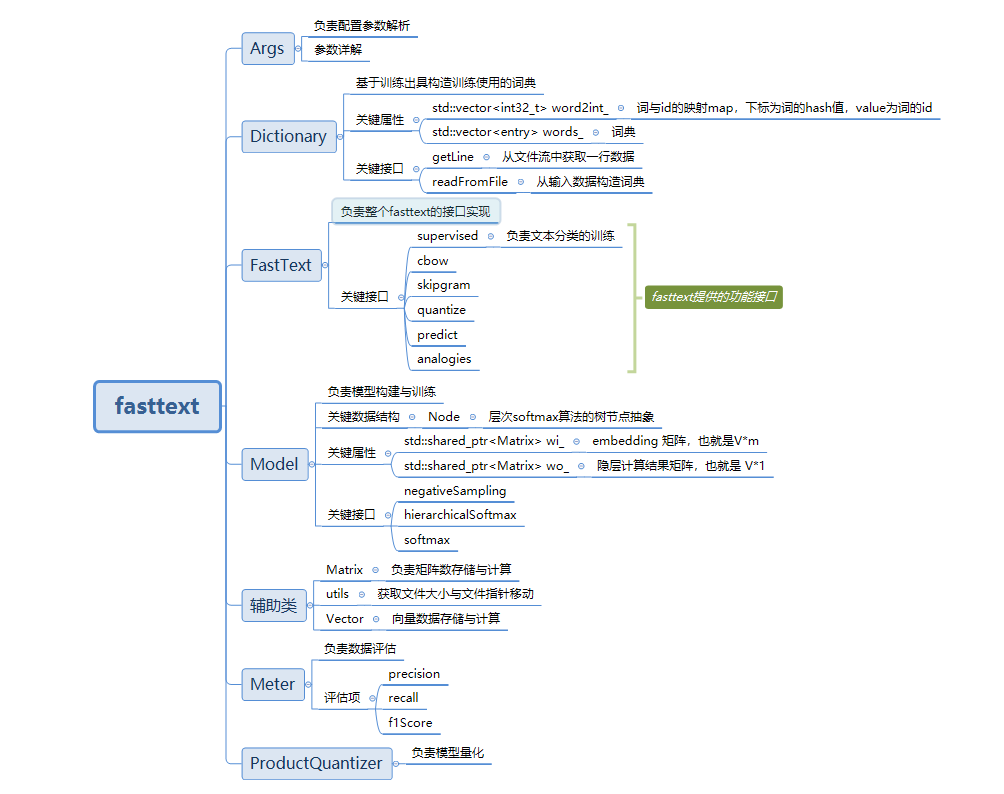
【三】fasttext参数配置
主要参数如下:

具体参数使用可以参考:https://fasttext.cc/docs/en/support.html
【四】dict相关源码分析
1. 从输入数据构造词典的整体流程
void Dictionary::readFromFile(std::istream& in) {std::string word;int64_t minThreshold = 1;// 1. 逐词读取while (readWord(in, word)) {// 2. 将词添加到词典中add(word);if (ntokens_ % 1000000 == 0 && args_->verbose > 1) {std::cerr << "\rRead " << ntokens_ / 1000000 << "M words" << std::flush;}// 如果超出词典容量,则去除低频词if (size_ > 0.75 * MAX_VOCAB_SIZE) {minThreshold++;// 去除低频词threshold(minThreshold, minThreshold);}}// 去除低频词,并按照词频降序排序threshold(args_->minCount, args_->minCountLabel);initTableDiscard();// 基于n-gram,初始化sub-wordinitNgrams();if (args_->verbose > 0) {std::cerr << "\rRead " << ntokens_ / 1000000 << "M words" << std::endl;std::cerr << "Number of words: " << nwords_ << std::endl;std::cerr << "Number of labels: " << nlabels_ << std::endl;}if (size_ == 0) {throw std::invalid_argument("Empty vocabulary. Try a smaller -minCount value.");}
}2. 面对不同的语言,如何读取一个词?
// 1. 对于词向量训练,需要先分词,然后词之前用空格隔开
bool Dictionary::readWord(std::istream& in, std::string& word) const {int c;// 1. 获取文件流的data指针std::streambuf& sb = *in.rdbuf();word.clear();// 2. 循环读取,每次从文件流中读取一个charwhile ((c = sb.sbumpc()) != EOF) {// 3. 对c读取的字符做不同的处理,如果不是空格等,则继续读取下一个字符if (c == ' ' || c == '\n' || c == '\r' || c == '\t' || c == '\v' ||c == '\f' || c == '\0') {if (word.empty()) {if (c == '\n') {word += EOS;return true;}continue;} else {if (c == '\n')sb.sungetc();return true;}}// 4. 将char添加到word中,继续读取下一个字符word.push_back(c);}// trigger eofbitin.get();return !word.empty();
}3. 如何将一个词添加到词典中?
void Dictionary::add(const std::string& w) {// 1. 通过find获取词的hash值int32_t h = find(w);ntokens_++;// 2. 通过hash值,查询该词是否在表word2int_中。// 该表的下标为词的hash值,value为词的id,容量为 MAX_VOCAB_SIZEif (word2int_[h] == -1) {// 3. 新词,将其添加到词典 words_中entry e;e.word = w;e.count = 1; // 新词,词频为1e.type = getType(w); // 词的类型,分类则为label,词向量则为word,即将所有的词放在一个词典中的// 没有分开存储label与wordwords_.push_back(e);word2int_[h] = size_++; // 添加词的id,id就是个顺序值,和普通的for循环中的i作为id是一样的} else {// 词典中已存在的词,仅增加词频words_[word2int_[h]].count++;}
}4. 如何去低频词?
void Dictionary::threshold(int64_t t, int64_t tl) {// 1. 先对词典中的词按照词频排序,sort(words_.begin(), words_.end(), [](const entry& e1, const entry& e2) {if (e1.type != e2.type) {return e1.type < e2.type;}// 词频降序排列return e1.count > e2.count;});// 2. 将 word 词频小于t的删除,将label词频小于t1的删除words_.erase(remove_if(words_.begin(),words_.end(),[&](const entry& e) {return (e.type == entry_type::word && e.count < t) ||(e.type == entry_type::label && e.count < tl);}),words_.end());// 3. 词典容量调整,前面删除了部分词。words_.shrink_to_fit();// 4. 重置词典数据size_ = 0;nwords_ = 0;nlabels_ = 0;std::fill(word2int_.begin(), word2int_.end(), -1);// 将词典中的数据重新计算id值for (auto it = words_.begin(); it != words_.end(); ++it) {int32_t h = find(it->word);word2int_[h] = size_++;if (it->type == entry_type::word) {nwords_++;}if (it->type == entry_type::label) {nlabels_++;}}
}
5. initTableDiscard
void Dictionary::initTableDiscard() {// 将 大小调整为词典大小pdiscard_.resize(size_);for (size_t i = 0; i < size_; i++) {// 计算概率,词频/词总数real f = real(words_[i].count) / real(ntokens_);pdiscard_[i] = std::sqrt(args_->t / f) + args_->t / f;}
}6. initNgrams
void Dictionary::initNgrams() {for (size_t i = 0; i < size_; i++) {// 1. 从词典中获取一个词,并给该词加上"<"与">",例如:北京---->"<北京>"std::string word = BOW + words_[i].word + EOW;words_[i].subwords.clear();// 该词的子词列表,首先添加全词的id,全词也算一个子词words_[i].subwords.push_back(i);if (words_[i].word != EOS) {// 依据n-gram,计算子词computeSubwords(word, words_[i].subwords);}}
}// word ---->原始的词
// ngrams --->依据n-gram分割出的子词,出参
// substrings --->默认值为nullptr
void Dictionary::computeSubwords(const std::string& word,std::vector<int32_t>& ngrams,std::vector<std::string>* substrings) const {// 1. 获取词的大小,一个词可能是由多个字符组成的// 例如:word = "<终南山>"for (size_t i = 0; i < word.size(); i++) {std::string ngram;// 2. 这里是为了解决utf-8编码问题// 参考:https://stackoverflow.com/questions/3911536/utf-8-unicode-whats-with-0xc0-and-0x80if ((word[i] & 0xC0) == 0x80) {continue;}// args_->maxn --->配置参数,表示n-gram中的n的最大值,默认为maxn = 6;// args_->minn --->配置参数,表示n-gram中的n的最小值,默认为minn = 3;// args_->bucket--->配置参数,表示bucket = 2000000;// 进行n-gram切分:例如:终南山---->终南、南山for (size_t j = i, n = 1; j < word.size() && n <= args_->maxn; n++) {ngram.push_back(word[j++]);while (j < word.size() && (word[j] & 0xC0) == 0x80) {ngram.push_back(word[j++]);}if (n >= args_->minn && !(n == 1 && (i == 0 || j == word.size()))) {int32_t h = hash(ngram) % args_->bucket;// 这里面会建立一个sub-word的hash索引pushHash(ngrams, h);if (substrings) {substrings->push_back(ngram);}}}}
}至此,依据数据数据构建词典的流程已经完成。主要是完成了word的去重、词频统计、词频排序、基于n-gram的sub-word预处理、word2id等处理。
【五】train流程分析
1. train的主流程
void FastText::train(const Args args) {args_ = std::make_shared<Args>(args);dict_ = std::make_shared<Dictionary>(args_);if (args_->input == "-") {// manage expectationsthrow std::invalid_argument("Cannot use stdin for training!");}std::ifstream ifs(args_->input);if (!ifs.is_open()) {throw std::invalid_argument(args_->input + " cannot be opened for training!");}// 1. 词典构造dict_->readFromFile(ifs);ifs.close();// 2. 如果有与训练的向量,则加载if (args_->pretrainedVectors.size() != 0) {loadVectors(args_->pretrainedVectors);} else {// 3. 构造输入数据矩阵的大小,这里也就是embidding的大小// V*minput_ =std::make_shared<Matrix>(dict_->nwords() + args_->bucket, args_->dim);// 初始化词嵌入矩阵input_->uniform(1.0 / args_->dim);}if (args_->model == model_name::sup) {// 隐层输出矩阵大小,分类: n*m,词向量 V*moutput_ = std::make_shared<Matrix>(dict_->nlabels(), args_->dim);} else {output_ = std::make_shared<Matrix>(dict_->nwords(), args_->dim);}output_->zero();// 启动计算startThreads();model_ = std::make_shared<Model>(input_, output_, args_, 0);if (args_->model == model_name::sup) {model_->setTargetCounts(dict_->getCounts(entry_type::label));} else {model_->setTargetCounts(dict_->getCounts(entry_type::word));}
}2. 单线程训练流程
void FastText::trainThread(int32_t threadId) {std::ifstream ifs(args_->input);// 1. 按照线程数,将输入数据平均分配给各个线程,// 各个线程之间不存在数据竞争,英雌不需要加锁utils::seek(ifs, threadId * utils::size(ifs) / args_->thread);// 2. 初始化一个modelModel model(input_, output_, args_, threadId);// 3. setTargetCounts 接口内部会完成tree或者负采样的数据初始化if (args_->model == model_name::sup) {model.setTargetCounts(dict_->getCounts(entry_type::label));} else {model.setTargetCounts(dict_->getCounts(entry_type::word));}const int64_t ntokens = dict_->ntokens();int64_t localTokenCount = 0;std::vector<int32_t> line, labels;while (tokenCount_ < args_->epoch * ntokens) {// 计算处理进度,动态调整学习率real progress = real(tokenCount_) / (args_->epoch * ntokens);real lr = args_->lr * (1.0 - progress);// 每次读取一行数据,依据模型不同,调用不同接口处理if (args_->model == model_name::sup) {// 文本分类localTokenCount += dict_->getLine(ifs, line, labels);supervised(model, lr, line, labels);} else if (args_->model == model_name::cbow) {// cbowlocalTokenCount += dict_->getLine(ifs, line, model.rng);cbow(model, lr, line);} else if (args_->model == model_name::sg) {// sglocalTokenCount += dict_->getLine(ifs, line, model.rng);skipgram(model, lr, line);}if (localTokenCount > args_->lrUpdateRate) {tokenCount_ += localTokenCount;localTokenCount = 0;if (threadId == 0 && args_->verbose > 1)loss_ = model.getLoss();}}if (threadId == 0)loss_ = model.getLoss();ifs.close();
}3. 层次softmax的tree的构造
void Model::buildTree(const std::vector<int64_t>& counts) {tree.resize(2 * osz_ - 1);for (int32_t i = 0; i < 2 * osz_ - 1; i++) {tree[i].parent = -1;tree[i].left = -1;tree[i].right = -1;tree[i].count = 1e15;tree[i].binary = false;}for (int32_t i = 0; i < osz_; i++) {tree[i].count = counts[i];}int32_t leaf = osz_ - 1;int32_t node = osz_;for (int32_t i = osz_; i < 2 * osz_ - 1; i++) {int32_t mini[2];for (int32_t j = 0; j < 2; j++) {if (leaf >= 0 && tree[leaf].count < tree[node].count) {mini[j] = leaf--;} else {mini[j] = node++;}}tree[i].left = mini[0];tree[i].right = mini[1];tree[i].count = tree[mini[0]].count + tree[mini[1]].count;tree[mini[0]].parent = i;tree[mini[1]].parent = i;tree[mini[1]].binary = true;}for (int32_t i = 0; i < osz_; i++) {std::vector<int32_t> path;std::vector<bool> code;int32_t j = i;while (tree[j].parent != -1) {// 节点路径,即从root到label的路径// 路径哈夫曼编码,即从root到label的路径的哈夫曼编码// 后面会借用这两个变量,计算losspath.push_back(tree[j].parent - osz_);code.push_back(tree[j].binary);j = tree[j].parent;}paths.push_back(path);codes.push_back(code);}
}4. 负采样
void Model::initTableNegatives(const std::vector<int64_t>& counts) {real z = 0.0;for (size_t i = 0; i < counts.size(); i++) {z += pow(counts[i], 0.5);}for (size_t i = 0; i < counts.size(); i++) {real c = pow(counts[i], 0.5);for (size_t j = 0; j < c * NEGATIVE_TABLE_SIZE / z; j++) {negatives_.push_back(i);}}std::shuffle(negatives_.begin(), negatives_.end(), rng);
}5. 参数更新
void Model::update(const std::vector<int32_t>& input, int32_t target, real lr) {assert(target >= 0);assert(target < osz_);if (input.size() == 0) {return;}// 1. 计算隐层的输出值。如果是分类,则是labels_number * 1// 如果是word2vec,则是V*1computeHidden(input, hidden_);// 依据模型类型调用不同的接口计算lossif (args_->loss == loss_name::ns) {loss_ += negativeSampling(target, lr);} else if (args_->loss == loss_name::hs) {loss_ += hierarchicalSoftmax(target, lr);} else {loss_ += softmax(target, lr);}nexamples_ += 1;// 梯度计算,参数更新if (args_->model == model_name::sup) {grad_.mul(1.0 / input.size());}for (auto it = input.cbegin(); it != input.cend(); ++it) {wi_->addRow(grad_, *it, 1.0);}
}具体计算的代码这里就不分析了。
【六】总结
其余部分的代码(如:预测、评估等),这里就不分析了,顺着代码看就可以了。fasttext的代码结构还是比较简单的。代码阅读的难点在于算法的理解。后续再结合算法,对代码细节做分析。
fasttext是一个很好的工具,但要训练出一个合适的模型,需要对模型的参数有所理解,然而一般情况下,默认的参数就能满足要求了。
转载于:https://my.oschina.net/u/3800567/blog/2877570
【NLP】【七】fasttext源码解析相关推荐
- snabbdom源码解析(七) 事件处理
事件处理 我们在使用 vue 的时候,相信你一定也会对事件的处理比较感兴趣. 我们通过 @click 的时候,到底是发生了什么呢! 虽然我们用 @click绑定在模板上,不过事件严格绑定在 vnode ...
- SEAL全同态加密开源库(七) rns剩余数系统-源码解析
SEAL全同态加密开源库(七) rns剩余数系统-源码解析 2021SC@SDUSC 2021-11-14 前言 这是SEAL开源库代码分析报告第六篇,本篇将分析util文件夹中的rns.h和rns. ...
- Ocelot简易教程(七)之配置文件数据库存储插件源码解析
作者:依乐祝 原文地址:https://www.cnblogs.com/yilezhu/p/9852711.html 上篇文章给大家分享了如何集成我写的一个Ocelot扩展插件把Ocelot的配置存储 ...
- 容器源码解析之HashMap(七)
再进入源码解析之前,先来看看hashMap的工作原理 当我们执行put存值时,hashmap会先调用key的hashcode方法的到哈希码,也就是桶的索引bucketIndex,找到该桶,然后遍历桶用 ...
- 【NLP】Words Normalization+PorterStemmer源码解析
Words Normalization 目录 Words Normalization Stemming(词干提取) Lemmatisation(词形还原) PorterStemmer源码解析 1.de ...
- Spring源码解析(七)-Bean属性间的循环依赖
首先复习一下前面学习的Spring容器启动的大致流程,首先Spring会先扫描所有需要实例化的Bean,将这些Bean的信息封装成一个个BeanDefinition,然后注册到BeanDefiniti ...
- webpack源码解析七(optimization)
前言 前面我们写了几篇文章用来介绍webpack源码,跟着官网结合demo把整个webpack配置撸了一遍: webpack源码解析一 webpack源码解析二(html-webpack-plugin ...
- 谷歌BERT预训练源码解析(一):训练数据生成
目录 预训练源码结构简介 输入输出 源码解析 参数 主函数 创建训练实例 下一句预测&实例生成 随机遮蔽 输出 结果一览 预训练源码结构简介 关于BERT,简单来说,它是一个基于Transfo ...
- Laravel5.2之Filesystem源码解析(下)
2019独角兽企业重金招聘Python工程师标准>>> 说明:本文主要学习下\League\Flysystem这个Filesystem Abstract Layer,学习下这个pac ...
最新文章
- Android Prelink
- php函数介绍,PHP函数介绍_PHP教程
- 2. JSF---托管Bean
- 钉钉猛增40倍流量压力,阿里云DBA如何应对?
- android wtf_WTF连接池
- 发布:偶写的NHibernate代码生成器
- 常犇_武汉大学管理学院2019年工商管理硕士(MBA)第三批复试通知
- 压力大对身体有没有伤害,你觉的有伤害就有伤害,你觉的没伤害就没伤害
- html网页效果跳动的心
- 降钙素(Cys(Acm)²·⁷)-α-CGRP (human)、125448-83-1
- 【ROS2学习】二、用python编写publisher和subscriber
- 3种方式构造HTTP请求详解(HTTP4)
- 【STL】11 list容器操作
- MySQL实现分数排名问题
- 著名童星刘佳琪深圳市中心举办个人Live音乐汇专辑发布会圆满成功
- Java后端技术微信交流群!工作、学习、技术、资源等!期待你的加入!
- matlab页面批量下载,[转载]matlab批量从NOAA网站下载验潮站数据
- 贪心算法及Jump Game系列题详解
- 《数学建模:基于R》一一1.7 数学建模案例分析——食品质量安全抽检数据分析...
- 移远BC25/28/35GMQTT连接阿里云物联网平台并实现属性上报
热门文章
- 交换机怎么使用vtp
- 计算机硬件系统的ppt,计算机硬件系统.ppt
- linux u盘内容乱码,Linux挂载U盘,中文显示为乱码
- 为什么只有三次挥手_TCP为什么是三次握手,为什么不是两次或四次,TCP四次挥手...
- 广联达2018模板算量步骤_工程人必须掌握:这9份软件算量教程+24份算量计算表,无偿分享...
- python求点到曲线距离_Python。如何从点和偏移距离的x,y列表中获取偏移样条曲线的x,y坐标...
- SSIM与PSNR的计算方式
- 【知识星球】做作业还能赢奖金,传统图像/机器学习/深度学习尽在不言中
- 【分割模型解读】感受野与分辨率的控制术—空洞卷积
- 全球及中国台式破壁机行业销售模式及市场需求份额调研报告2021-2027年