模式匹配Pattern Matching
目录
1.模式匹配(pattern matching)的概念
2. 制造模式匹配的测试串
3. 模式匹配蛮力算法(Brute-Force,也成Naive朴素算法)
3.1 Version 1
3.2 Version 2:(与Version 1的不同在于i,j)
3.3 算法分析
(1)最差情况
(2)最佳情况 —— 找到
(3)最佳情况 —— 没找到
4. 模式匹配KMP算法
5. 模式匹配BC(Begin With The End)算法
1.模式匹配(pattern matching)的概念
——一个目标对象 T(字符串)
——(pattern)P(字符串)
在目标 T 中寻找一个给定的模式P的过程
![]()
应用
1. 文本编辑时的特定词、句的查找
•UNIX/Linux: sed, awk, grep
2. DNA 信息的提取
2. 制造模式匹配的测试串
![]()
制造模式匹配测试串的两种策略
策略一:随机生成Test串,随机生成Pattern串,然后进行匹配。该策略下,P在T中出现的概率小。
策略二:随机生成Test串,在从中随机截取Pattern串。
3. 模式匹配蛮力算法(Brute-Force,也成Naive朴素算法)
![]()
3.1 Version 1
![]()
匹配过程详解:
T = pepeople
P = people
---------------------------------------
i = 0 j = 0
T = pepeople
P = people
T[0] = P[0] = p
i + 1 = 1
j + 1 = 1
-----------------------------------------
i = 1 j = 1
T = pepeople
P = people
T[1] = P[1] = e
i + 1 = 2
j + 1 = 2
----------------------------------------------
i = 2 j = 2
T = pepeople
P = people
T[2] = p
P[2] = 0
T[2] != P[2]
i = 2 - (2 - 1) = 1 (T回退)
j = 0 (P复位)
------------------------------------------------
i = 1 j = 0
T = pepeople
P = people
(......)
3.2 Version 2:(与Version 1的不同在于i,j)
![]()
匹配过程详解:
T = pepeople
P = people
---------------------------------------
i = 0 j = 0
T = pepeople
P = people
T[0+0]
T[0] = P[0] = p
j + 1 = 1
-----------------------------------------
i = 0 j = 1
T = pepeople
P = people
T[0+1]
T[1] = P[1] = e
j + 1 = 2
----------------------------------------------
i = 0 j = 2
T = pepeople
P = people
T[0+2]
T[2] = p
P[2] = 0
T[2] != P[2]
i = i+1 = 1
j = 0
------------------------------------------------
i = 1 j = 0
T = pepeople
P = people
T[1+0]
T[1] = e
P[0] = p
(......)
3.3 算法分析
3.3.1 最差情况
3.3.2 最佳情况 —— 找到
3.3.3 最佳情况 —— 没找到
![]()
4. 模式匹配KMP算法
推荐JULY的博文:https://blog.csdn.net/v_JULY_v/article/details/7041827
推荐阮一峰的博文http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html
字符串:BBC ABCDAB ABCDABCDABDE
搜索词:ABCDABD
1.

B与A不匹配,搜索词后移一位。
2.

B与A不匹配,搜索词再往后移。
3.

直到字符串有一个字符,与搜索词的第一个字符相同为止。
4.

接着比较字符串和搜索词的下一个字符,还是相同。
5.

直到字符串有一个字符,与搜索词对应的字符不相同为止。
6.

这时,最自然的反应是,将搜索词整个后移一位,再从头逐个比较。这样做虽然可行,但是效率很差,因为你要把"搜索位置"移到已经比较过的位置,重比一遍。
7.
一个基本事实是,当空格与D不匹配时,你其实知道前面六个字符是"ABCDAB"。KMP算法的想法是,设法利用这个已知信息,不要把"搜索位置"移回已经比较过的位置,继续把它向后移,这样就提高了效率。
8.
怎么做到这一点呢?可以针对搜索词,算出一张《部分匹配表》(Partial Match Table)。这张表是如何产生的,后面再介绍,这里只要会用就可以了。
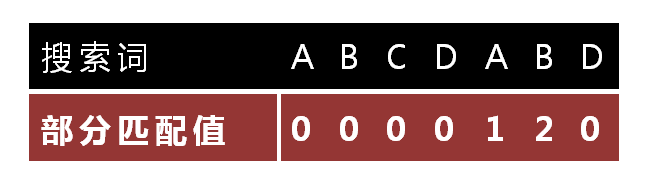
9.
![]()
已知空格与D不匹配时,前面六个字符"ABCDAB"是匹配的。查表可知,最后一个匹配字符B对应的"部分匹配值"为2,因此按照下面的公式算出向后移动的位数:
移动位数 = 已匹配的字符数 - 对应的部分匹配值(搜索词"前缀"和"后缀"的最长的共有元素的长度)
因为 6 - 2 等于4,所以将搜索词向后移动4位。
10.

![]()
因为空格与C不匹配,搜索词还要继续往后移。这时,已匹配的字符数为2("AB"),对应的"部分匹配值"为0。所以,移动位数 = 2 - 0,结果为 2,于是将搜索词向后移2位。
11.
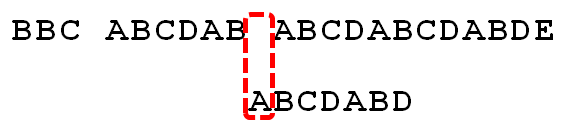
因为空格与A不匹配,继续后移一位。
12.

逐位比较,直到发现C与D不匹配。于是,移动位数 = 6 - 2,继续将搜索词向后移动4位。
13.

逐位比较,直到搜索词的最后一位,发现完全匹配,于是搜索完成。如果还要继续搜索(即找出全部匹配),移动位数 = 7 - 0,再将搜索词向后移动7位,这里就不再重复了。
14.

下面介绍《部分匹配表》是如何产生的。
首先,要了解两个概念:"前缀"和"后缀"。 "前缀"指除了最后一个字符以外,一个字符串的全部头部组合;"后缀"指除了第一个字符以外,一个字符串的全部尾部组合。
15.
"部分匹配值"就是"前缀"和"后缀"的最长的共有元素的长度。以"ABCDABD"为例,
前缀 后缀 公有元素的长度
"A" 空集 空集 0
"AB" [A] [B] 0
"ABC" [A, AB] [BC, C] 0
"ABCD" [A, AB, ABC] [BCD, CD, D] 0
"ABCDA" [A, AB, ABC, ABCD] [BCDA, CDA, DA, A] 1
"ABCDAB" [A, AB, ABC, ABCD, ABCDA] [BCDAB, CDAB, DAB, AB, B] 2
"ABCDABD" [A, AB, ABC, ABCD, ABCDA, ABCDAB] [BCDABD, CDABD, DABD, ABD, BD, D] 0
16.
"部分匹配"的实质是,有时候,字符串头部和尾部会有重复。比如,"ABCDAB"之中有两个"AB",那么它的"部分匹配值"就是2("AB"的长度)。搜索词移动的时候,第一个"AB"向后移动4位(字符串长度-部分匹配值),就可以来到第二个"AB"的位置。
17. next数组
next 数组相当于“最大长度值” 整体向右移动一位,然后初始值赋为-1。
![]()
移动位数 = 失配字符所在位置(下标从0开始) - 失配字符对应的next 值
18 next数组优化版
![]()
相等,则让next[j] = next[k]
j=3,k=0,next[0]=-1
j=5,k=1,next[1]=0
j=7,k=1,next[1]=0
j=8,k=2,next[2]=0
5. 模式匹配BC(Begin With The End)算法
推荐阮一峰的博文:http://www.ruanyifeng.com/blog/2013/05/boyer-moore_string_search_algorithm.html
模式匹配Pattern Matching相关推荐
- Python 3.10 的新功能:模式匹配 Pattern Matching
简介 2021 年 3 月 2 日的时候,Guido 发推说 3.10.0a6 出来了,文档也已经有了,4 月 5 日会释出 a7,5 月 3 日出 b1. 推文中还特别提到「With Pattern ...
- 函数式编程之-模式匹配(Pattern matching)
编者:C# 7.0也加入了模式匹配,来源于F#. 模式匹配在F#是非常普遍的,用来对某个值进行分支匹配或流程控制. 模式匹配的基本用法 模式匹配通过match...with表达式来完成,一个完整的模式 ...
- C#9.0 终于来了,带你一起解读 nint 和 Pattern matching 两大新特性玩法
一:背景 1. 讲故事 上一篇C#9.0 终于来了,您还学的动吗? 带上VS一起解读吧!跟大家聊到了Target-typed new 和 Lambda discard parameters,看博客园和 ...
- 9.7. Pattern Matching
9.7. Pattern Matching 9.7. 模式匹配 There are three separate approaches to pattern matching provided by ...
- PEP 634 – Structural Pattern Matching: Specification
PEP 634 – Structural Pattern Matching: Specification PEP 634 – 结构化模式匹配:规范 PEP: 634 Title: Structural ...
- 论文翻译——Multi-Constrained Graph Pattern Matching in Large-Scale Contextual Social Graphs
文章目录 Abstract 附加 Introduction Background 附加 Problem 附加 Contribuitions 附加 Related Work (1) 附加 (2) 附加 ...
- CodeForces - 1476E Pattern Matching(字典树+拓扑)
题目链接:点击查看 题目大意:给出 nnn 个模式串和 mmm 个匹配串,题目要求输出一种模式串的排列方式,使得 mmm 个模式串从头开始匹配的话,可以匹配到相应的模式串 模式串的长度不超过 444, ...
- E. Pattern Matching(题意理解+拓扑排序)
E. Pattern Matching 首先p[mtj]p[mt_j]p[mtj]必须能够匹配所给字符sjs_jsj,然后把所有能够匹配的sjs_jsj的其他模板串也找出来,这些必须放在p[mt ...
- 面试题 16.18. Pattern Matching LCCI
Title 你有两个字符串,即pattern和value. pattern字符串由字母"a"和"b"组成,用于描述字符串中的模式.例如,字符串"cat ...
最新文章
- Nature综述:植物与微生物组的相互作用:从群落装配到植物健康(上)
- 贝叶斯推断方法 —— 从经验知识到推断未知
- 【JNI】JNI中java类型的简写
- Nginx的Gzip模块配置指令(一)
- Guava的测试集合实现
- 专注计算机专业知识讲授,计算机一级考试MS Office上机指导
- Windows服务器上使用phpstudy部署PHP程序
- Beta 冲刺 (6/7)
- linux搜索文件中包含的字符
- Vijos 1303
- 前景检测算法 (GMM)
- 涨姿势了!delete后加 limit是个好习惯么?
- 计算机用户界面英文,计算机主板CMOS界面英文翻译(2)
- vue keep-alive案例全教程
- 《智能搜索和推荐系统》总结
- bcd 初始化库系统卷失败_中级|软考题库每日一练|2.24
- 击退加拿大鹅,波司登成年轻人冬季新欢?
- ECC-Elliptic Curves Cryptography,椭圆曲线密码编码学
- 三本计算机的专业需要考研嘛,三本计算机考研难吗
- CSDN什么时候倒闭啊