Cocos Creator 资源加载流程剖析【二】——Download部分
Download流程的处理由Downloader这个pipe负责(downloader.js),Downloader提供了各种资源的“下载”方式——即如何获取文件内容,有从网络获取、从磁盘获取,不同类型的资源在不同的平台下有不同的获取方式。
- 比如脚本在原生平台使用require方法获取,而在H5平台则使用动态添加的
又比如json在原生平台使用jsb.fileutils进行加载,而在H5平台则使用XMLHttpRequest从网络下载。
Downloader处理
Downloader的handle接收一个item和callback,根据item的type在this.extMap中获取对应的downloadFunc,交由downloadFunc下载,根据下载结果调用callback。同时有一个并发限制,默认最多同时下载64个资源,超过的会进入队列,等待前面的资源加载完成后再依次进行加载。如果item的ignoreMaxConcurrency为true则无视该并发限制。downloadFunc接受一个item和一个callback,如果是同步下载,需要返回downloadFunc的返回值,而异步下载则返回undefined或不返回。
Downloader.prototype.handle = function (item, callback) {var self = this;var downloadFunc = this.extMap[item.type] || this.extMap['default'];var syncRet = undefined;if (this._curConcurrent < cc.macro.DOWNLOAD_MAX_CONCURRENT) {this._curConcurrent++;syncRet = downloadFunc.call(this, item, function (err, result) {self._curConcurrent = Math.max(0, self._curConcurrent - 1);self._handleLoadQueue();callback && callback(err, result);});// 当downloadFunc是同步执行的,会返回非undefined的syncRetif (syncRet !== undefined) {this._curConcurrent = Math.max(0, this._curConcurrent - 1);this._handleLoadQueue();return syncRet;}}else if (item.ignoreMaxConcurrency) {syncRet = downloadFunc.call(this, item, callback);if (syncRet !== undefined) {return syncRet;}}else {this._loadQueue.push({item: item,callback: callback});}
};Downloader的this.extMap记录了各种资源类型的下载方式,所有的类型最终都对应这6个下载方法,downloadScript、downloadImage(downloadWebp)、downloadAudio、downloadText、downloadFont、downloadUuid,它们对应实现了各种类型资源的下载,通过Downloader.addHandlers可以添加或修改任意资源的下载方式。
downloadScript
如果是微信或者原生平台,只是对脚本进行require(CommonJS模块化规范),这里主要是web平台的处理,原生平台的处理在后面统一介绍,web平台是通过创建一个script的HTML标签,指定标签的src,添加事件监听,通过这种HTML的方式下载脚本,使其生效。
function downloadScript (item, callback, isAsync) {if (sys.platform === sys.WECHAT_GAME) {require(item.url);callback(null, item.url);return;}// 创建一个script标签元素,并指定其src为我们的源码路径var url = item.url,d = document,s = document.createElement('script');s.async = isAsync;s.src = urlAppendTimestamp(url);function loadHandler () {s.parentNode.removeChild(s);s.removeEventListener('load', loadHandler, false);s.removeEventListener('error', errorHandler, false);callback(null, url);}function errorHandler() {s.parentNode.removeChild(s);s.removeEventListener('load', loadHandler, false);s.removeEventListener('error', errorHandler, false);callback(new Error('Load ' + url + ' failed!'), url);}// 添加加载完成和错误回调s.addEventListener('load', loadHandler, false);s.addEventListener('error', errorHandler, false);d.body.appendChild(s);
}当cc.game.config['noCache']为true时,urlAppendTimestamp会在url的尾部添加当前的时间戳,这会导致每次加载资源时由于url不同,不会直接使用浏览器的缓存,而是重新获取最新的资源,接下来的各种下载函数中也有urlAppendTimestamp。
downloadImage
downloadWebp和downloadImage都是用于下载图片资源,downloadWebp只是判断了cc.sys.capabilities.webp是否为true,如果为false表示当前的环境不支持webp,如果支持则直接调用downloadImage进行下载。downloadImage中引入了2个概念,imagePool和crossOrigin,imagePool是一个JS.Pool,它的get方法会返回一个Image对象。如果是非https下的跨域请求,下载失败时会使用不跨域的方式再请求一次。
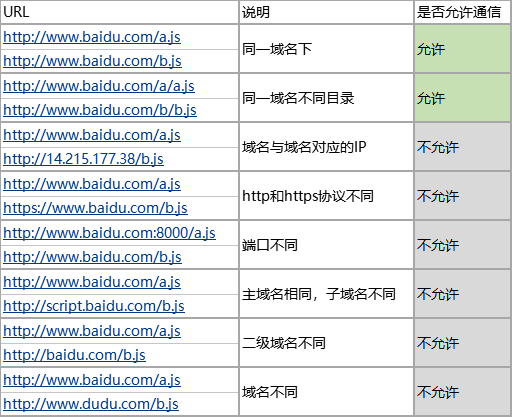
由于浏览器同源策略,凡是发送请求url的协议、域名、端口三者之间任意一与当前页面地址不同即为跨域,以下为跨域的详细描述表格。在web端,使用webgl模式无法直接使用跨域图片,需要服务器配合设置Access-Control-Allow-Origin(Canvas模式允许使用跨域图片)。
当我们访问跨域资源的时候,能否正确加载图片取决于图片服务器是否开启了跨域支持(Access-Control-Allow-Origin: *),比如 http://tools.itharbors.com/res/logo.png 这个资源的服务器开启了跨域支持,所以可以正确加载,不需要调整客户端加载的代码。
那么downloadImage为什么要在设置crossOrigin加载失败之后,将crossOrigin设置为null再加载一次呢?因为关闭crossOrigin之后虽然可以加载,但无法准确地捕获错误。在测试中,如果服务器没有开启跨域支持,通过将crossOrigin设置为null确实可以下载到图片,然而在webgl初始化该图片时会报错。
function downloadImage (item, callback, isCrossOrigin, img) {if (isCrossOrigin === undefined) {isCrossOrigin = true;}var url = urlAppendTimestamp(item.url);img = img || misc.imagePool.get();if (isCrossOrigin && window.location.protocol !== 'file:') {img.crossOrigin = 'anonymous';} else {img.crossOrigin = null;}if (img.complete && img.naturalWidth > 0 && img.src === url) {return img;} else {function loadCallback () {img.removeEventListener('load', loadCallback);img.removeEventListener('error', errorCallback);callback(null, img);}function errorCallback () {img.removeEventListener('load', loadCallback);img.removeEventListener('error', errorCallback);// Retry without crossOrigin mark if crossOrigin loading fails// 如果加载失败,重试的时候img.crossOrigin被置为null// Do not retry if protocol is https, even if the image is loaded, cross origin image isn't renderable.// 如果是https就不重试了,因为就算加载了到了图片也无法渲染if (window.location.protocol !== 'https:' && img.crossOrigin && img.crossOrigin.toLowerCase() === 'anonymous') {downloadImage(item, callback, false, img);} else {callback(new Error('Load image (' + url + ') failed'));}}// 设置src开始加载图片img.addEventListener('load', loadCallback);img.addEventListener('error', errorCallback);img.src = url;}
}downloadFont
downloadFont的本质也是通过添加HTML标签,通过div、style标签来实现字体的加载。通过item的name、srcs或name、url、type进行加载。
function _loadFont (name, srcs, type){// 创建一个类型为text/css的style标签var doc = document,fontStyle = document.createElement('style');fontStyle.type = 'text/css';doc.body.appendChild(fontStyle);// 构建并设置fontStyle的textContent属性var fontStr = '';if (isNaN(name - 0)) {fontStr += '@font-face { font-family:' + name + '; src:';}else {fontStr += '@font-face { font-family:\'' + name + '\'; src:';}if (srcs instanceof Array) {for (var i = 0, li = srcs.length; i < li; i++) {var src = srcs[i];type = Path.extname(src).toLowerCase();fontStr += 'url(\'' + srcs[i] + '\') format(\'' + FONT_TYPE[type] + '\')';fontStr += (i === li - 1) ? ';' : ',';}} else {type = type.toLowerCase();fontStr += 'url(\'' + srcs + '\') format(\'' + FONT_TYPE[type] + '\');';}fontStyle.textContent += fontStr + '}';// 添加一个试用该字体的div//<div style="font-family: PressStart;">.</div>var preloadDiv = document.createElement('div');var _divStyle = preloadDiv.style;_divStyle.fontFamily = name;preloadDiv.innerHTML = '.';_divStyle.position = 'absolute';_divStyle.left = '-100px';_divStyle.top = '-100px';doc.body.appendChild(preloadDiv);
}function downloadFont (item, callback) {var url = item.url,type = item.type,name = item.name,srcs = item.srcs;if (name && srcs) {if (srcs.indexOf(url) === -1) {srcs.push(url);}_loadFont(name, srcs);} else {type = Path.extname(url);name = Path.basename(url, type);_loadFont(name, url, type);}if (document.fonts) {document.fonts.load('1em ' + name).then(function () {callback(null, null);}, function(err){callback(err);});} else {return null;}
}downloadAudio
downloadAudio位于audio-downloader.js中,它会根据item的useDom选项决定使用哪种声音下载方式:
function downloadAudio (item, callback) {// 浏览器不支持音效if (formatSupport.length === 0) {return new Error('Audio Downloader: audio not supported on this browser!');}item.content = item.url;// 如果指定了useDom或者不支持WebAudio,会自动帮我们切换成DomAudioif (!__audioSupport.WEB_AUDIO || (item.urlParam && item.urlParam['useDom'])) {loadDomAudio(item, callback);} else {loadWebAudio(item, callback);}
}loadWebAudio会使用cc.loader.getXMLHttpRequest下载资源,在onLoad回调中使用sys.__audioSupport.context["decodeAudioData"]()进行解码。
而loadDomAudio则是通过aduio这个HTML标签进行加载和监听。
downloadText
文本的下载分2中方式,如果是原生平台,会使用jsb.fileUtils.getStringFromFile从磁盘中直接获取,如果是其他普通,会使用cc.loader.getXMLHttpRequest下载。
在Creator2.x之后,这段判断被移到了engine目录的jsb目录下,Creator直接在构建时使用合适的代码,而不是在函数执行中去判断当前是哪种平台。
if (CC_JSB) {module.exports = function (item, callback) {var url = item.url;var result = jsb.fileUtils.getStringFromFile(url);if (typeof result === 'string' && result) {return result;} else {return new Error('Download text failed: ' + url);}};
} else {var urlAppendTimestamp = require('./utils').urlAppendTimestamp;module.exports = function (item, callback) {var url = item.url;url = urlAppendTimestamp(url);var xhr = cc.loader.getXMLHttpRequest(),errInfo = 'Load ' + url + ' failed!',navigator = window.navigator;xhr.open('GET', url, true);if (/msie/i.test(navigator.userAgent) && !/opera/i.test(navigator.userAgent)) {// IE-specific logic herexhr.setRequestHeader('Accept-Charset', 'utf-8');xhr.onreadystatechange = function () {if(xhr.readyState === 4) {if (xhr.status === 200 || xhr.status === 0) {callback(null, xhr.responseText);} else {callback({status:xhr.status, errorMessage:errInfo});}}};} else {if (xhr.overrideMimeType) xhr.overrideMimeType('text\/plain; charset=utf-8');xhr.onload = function () {if(xhr.readyState === 4) {if (xhr.status === 200 || xhr.status === 0) {callback(null, xhr.responseText);} else {callback({status:xhr.status, errorMessage:errInfo});}}};xhr.onerror = function(){callback({status:xhr.status, errorMessage:errInfo});};}xhr.send(null);};
}
downloadUuid
Creator中的资源都会有它的uuid,都会调用该方法进行下载。而uuid资源可能以2种形式存在,第一种是单独的json文件,比如一个prefab或spriteFrame资源,都有自己的json文件。而另一种则是打包资源,所谓的Pack就是将多个json文件合并为一个json文件,把各个json文件中的json对象组合到一个json数组中,从而达到减少IO的作用。downloadUuid方法会使用PackDownloader进行下载,如果下载失败则使用json的下载方式,也就是downloadText。
function downloadUuid (item, callback) {var result = PackDownloader.load(item, callback);if (result === undefined) {return this.extMap['json'](item, callback);} else if (!!result) {return result;}
}PackDownloader的load方法实现如下,根据uuidToPack中的uuid取出packUuid,如果packUuid不存在,则说明这个uuid没有被打包,直接使用json的方式加载即可。接下来再根据globalUnpackers[packUuid]取出unpacker,调用unpacker.retrieve(uuid)解析出json并返回。
load: function (item, callback) {var uuid = item.uuid;var packUuid = uuidToPack[uuid];if (!packUuid) {// 返回undefined以让调用者知道它未被识别。// 不返回false,因为改变返回值类型可能会导致jit失败,尽管返回undefined可能有相同的问题return;}// 一个uuid有可能被重复打包到多个json文件中,《从编辑器到运行时》一章会介绍这种情况如何产生if (Array.isArray(packUuid)) {// 这里会遍历多个Pack,从中选择状态最接近加载完成的Pack(谁先加载完用谁)。packUuid = this._selectLoadedPack(packUuid);}// 取出unpacker,如果加载完成了,从unpacker中取出对应uuid的json对象返回。var unpacker = globalUnpackers[packUuid];if (unpacker && unpacker.state === PackState.Loaded) {var json = unpacker.retrieve(uuid);if (json) {return json;} else {return error(uuid, packUuid);}} else { // 其他情况为未加载完成// unpacker为空则创建一个if (!unpacker) {if (!CC_TEST) {console.log('Create unpacker %s for %s', packUuid, uuid);}unpacker = globalUnpackers[packUuid] = new JsonUnpacker();unpacker.state = PackState.Downloading;}// 如果正在加载中或未加载,会走_loadNewPack也就是cc.loader.load,但cc.loader中规避了重复加载。this._loadNewPack(uuid, packUuid, callback);}// 返回null,让调用者知道它正在异步加载return null;}接下来我们进一步了解一下PackDownloader这个类做了什么?Pack又是什么?globalUnpackers和packIndices又是什么?
- PackDownloader
- initPacks接受packs变量进行初始化,packIndices变量引用了packs,遍历packs来初始化uuidToPack,建立了uuid到pack的映射。
- _loadNewPack根据packUuid调用cc.AssetLibrary.getLibUrlNoExt(packUuid) + '.json';获取packUrl,并调用cc.loader.load加载json文件,加载完成后调用 _doLoadNewPack以及callback。
- _doLoadNewPack根据packUuid从globalUnpackers中取出unpacker,并返回unpacker.retrieve(uuid)
PackDownloader做的事情主要是对Json文件的解析、管理和获取。在某些情况下多个json文件会被打包成一个json文件,如AnimationClip文件,在编辑器制作的时候每个动画都是一个Clip文件(json文件),而在打包之后这些Clip会被合并成一个新的json文件(这样做的目的是节省IO),这就是Pack。
当我们发布项目时Creator自动帮我们进行合并,多个json对象组成一个数组对象,packIndices记录了每个packUuid对应的一组uuid(也就是一个pack文件中合并了哪些文件),每个文件的uuid对应这个json数组对象的下标。packIndices[packUuid]的下标1是该packUuid对应合并后的json数组下标1这个json对象的uuid。
每个Clip都有一个uuid,通过uuidToPack的索引获取这个Clip对应的packUuid,也就是合并Json的uuid,这个uuid会对应一个JsonUnpacker,JsonUnpacker会将合并后的json进行解析并缓存,同时保持一个映射,在这里就是每个Clip的uuid对应的json对象。
// 初始化Packs,这里传入的packs是一个二维数组,首先它是一个uuids的数组,一组uuid被视为一个pack,packs就是一组pack// 每个uuids都是一个数组,记录了这个pack中合并的所有uuid。initPacks: function (packs) {packIndices = packs;for (var packUuid in packs) {var uuids = packs[packUuid];for (var i = 0; i < uuids.length; i++) {var uuid = uuids[i];// the smallest pack must be at the beginning of the array to download more first// 最小的pack必须放在数组的前面,以便下载更多的包。var pushFront = uuids.length === 1;// map - uuidToPack, key - uuid, value - packUuid (如果已存在该key,value会添加到数组中)pushToMap(uuidToPack, uuid, packUuid, pushFront);}}},// 加载一个新的Pack时会调用该方法,根据packUuid去获取url,并立即下载(ignoreMaxConcurrency为true)_loadNewPack: function (uuid, packUuid, callback) {var self = this;var packUrl = cc.AssetLibrary.getLibUrlNoExt(packUuid) + '.json';cc.loader.load({ url: packUrl, ignoreMaxConcurrency: true }, function (err, packJson) {if (err) {cc.errorID(4916, uuid);return callback(err);}var res = self._doLoadNewPack(uuid, packUuid, packJson);if (res) {callback(null, res);} else {callback(error(uuid, packUuid));}});},// 当一个Pack加载完之后,会回调该方法_doLoadNewPack: function (uuid, packUuid, packJson) {var unpacker = globalUnpackers[packUuid];// double check cache after load// 只要unpacker的状态不是PackState.Loaded,进行解析并切换状态if (unpacker.state !== PackState.Loaded) {unpacker.read(packIndices[packUuid], packJson);unpacker.state = PackState.Loaded;}return unpacker.retrieve(uuid);},// 遍历多个packUuid,只要找到第一个状态为PackState.Loaded的unpacker// 找不到则找一个最接近PackState.Loaded的unpacker_selectLoadedPack: function (packUuids) {var existsPackState = PackState.Invalid;var existsPackUuid = '';for (var i = 0; i < packUuids.length; i++) {var packUuid = packUuids[i];var unpacker = globalUnpackers[packUuid];if (unpacker) {var state = unpacker.state;if (state === PackState.Loaded) {return packUuid;} else if (state > existsPackState) {existsPackState = state;existsPackUuid = packUuid;}}}return existsPackState !== PackState.Invalid ? existsPackUuid : packUuids[0];},- globalUnpackers
- globalUnpackers根据packUuid为索引,保存着JsonUnpacker对象。
- JsonUnpacker记录了jsons和state,关键的read方法和retrieve方法的职责是解析json数据以及根据key从jsons中查询信息。
JsonUnpacker.prototype.read = function (indices, data) {var jsons = typeof data === 'string' ? JSON.parse(data) : data;if (jsons.length !== indices.length) {cc.errorID(4915);}for (var i = 0; i < indices.length; i++) {var key = indices[i];var json = jsons[i];this.jsons[key] = json;}
};JsonUnpacker.prototype.retrieve = function (key) {return this.jsons[key] || null;
};这里传入的data是一个数组json对象,indices是一个uuid数组,read的职责就是将indices[i]作为uuid,对应的jsons[i]作为json对象,记录到this.jsons这个容器中,那么后面的retrieve就可以用uuid来获取对应的json对象了。
- 关于packIndices
- 在AssetLibrary的init方法中,调用了PackDownloader.initPacks(options.packedAssets);
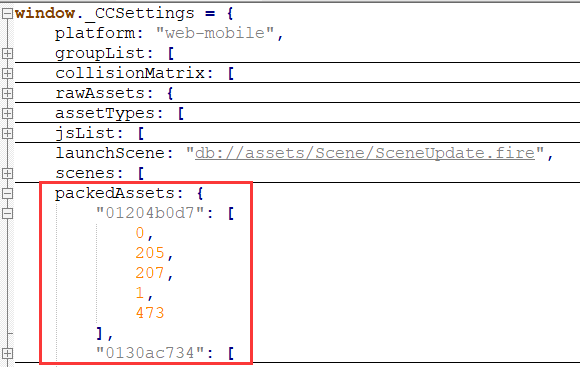
- 项目发布时会生成一个巨大的settings.js文件,该文件内容如下图所示,其中的packedAssets就是我们的packIndices。
- 例如图中的key 01204b0d7可以在发布后的res/import/01目录中找到01204b0d7.json,这个文件是一个有5个对象的json数组,他们的uuid分别为0、205、207、1、473。
01204b0d7.json文件对应的内容在格式化查看工具中打开如下所示,正好是一个拥有5个对象的json数组,第一个对象是Array、后面是4个Object对象。而上图对应的packedAssets下的01204b0d7对象数组为这个json数组的uuid,按下标一一对应。

原生Downloader处理
在原生平台下会执行jsb-loader.js下的内容,对于字体、音效、脚本和图片使用新的下载方法。
// 字体使用了empty
function empty (item, callback) {return null;
}// 下载脚本直接使用require即可
function downloadScript (item, callback) {require(item.url);return null;
}// 声音不需要下载,声音的加载流程包含了下载
function downloadAudio (item, callback) {return item.url;
}// 图片分3种情况,textureCache中缓存直接使用、远程图片使用jsb.loadRemoteImg、本地图片使用textureCache的addImageAsync方法加载。
function loadImage (item, callback) {var url = item.url;var cachedTex = cc.textureCache.getTextureForKey(url);if (cachedTex) {return cachedTex;} else if (url.match(jsb.urlRegExp)) {jsb.loadRemoteImg(url, function(succeed, tex) {if (succeed) {tex.url = url;callback && callback(null, tex);} else {callback && callback(new Error('Load image failed: ' + url));}});} else {var addImageCallback = function (tex) {if (tex instanceof cc.Texture2D) {tex.url = url;callback && callback(null, tex);}else {callback && callback(new Error('Load image failed: ' + url));}};cc.textureCache._addImageAsync(url, addImageCallback);}
}在项目发布时,会根据发布平台生成最终的执行代码。构建原生平台时Creator1.x会指定engine/jsb目录下的脚本,而Creator2.x指定的是engine/bin目录下的jsb脚本。
转载于:https://www.cnblogs.com/ybgame/p/10576986.html
Cocos Creator 资源加载流程剖析【二】——Download部分相关推荐
- 【CEGUI】资源加载流程
CEGUI资源加载流程 CEGUI版本 0.8.7 主要资源类型 Scheme scheme资源(包括图像集.字体资源.窗口外观信息.类型映射)等.可以通过".scheme"&qu ...
- 【CEGUI】Font资源加载流程
CEGUI Font资源加载流程 Font(字体),主要两个类型的字体:位图字体.矢量字体. 位图字体:PixmapFont,相当于每个字形(glyph)对应一个图片元素.有时候也称为光栅字体. 矢量 ...
- android资源加载流程6,FrameWork源码解析(6)-AssetManager加载资源过程
之前一段时间项目比较忙所以一直没有更新,接下来准备把插件化系列的文章写完,今天我们就先跳过ContentProvider源码解析来讲资源加载相关的知识,资源加载可以说是插件化非常重要的一环,我们很有必 ...
- cocos creator动态加载DragonBones
根据creator的龙骨组件来看的话添加一个龙骨的话需要设置五个地方,分别是DragonAsset(龙骨的配置json文件),DragonAtlas(龙骨的纹理json资源),Armature(Arm ...
- Cocos Creator2.4.8 资源加载源码阅读
最近用到资源加载的问题:加载的资源进度条倒退问题,现在只是用临时的解决方案 - 加载进度如果出现会倒退的问题还是用原来的数值.抽时间看了下cocos creator 资源加载的源码,整理了一下脑图 一 ...
- UE4 资源加载与资源缓存
前一段时间其实就做完了这个资源预加载的功能,仅仅是根据以往的经验完成的这项功能.最近稍微有一点时间,就把UE4资源加载和缓存的整体流程进行了分析,这样可以对整个UE4资源管理流程有更深入的了解,同时也 ...
- Android系统字体加载流程
一.背景 视觉同学提了一个需求,要求手机中显示的字体可以支持medium字体,经过分析,android原生的字体库中并没有中文的medium字体,如果使用bold,显示又太粗,为满足需求,需要分析an ...
- 【Android 插件化】Hook 插件化框架总结 ( 插件包管理 | Hook Activity 启动流程 | Hook 插件包资源加载 ) ★★★
Android 插件化系列文章目录 [Android 插件化]插件化简介 ( 组件化与插件化 ) [Android 插件化]插件化原理 ( JVM 内存数据 | 类加载流程 ) [Android 插件 ...
- Android apk动态加载机制的研究(二):资源加载和activity生命周期管理
转载请注明出处:http://blog.csdn.net/singwhatiwanna/article/details/23387079 (来自singwhatiwanna的csdn博客) 前言 为了 ...
最新文章
- 比Momentum更快:揭开Nesterov Accelerated Gradient的真面目NAG 梯度下降
- android使用webview时按后退退出的问题
- [摘录]第8章 与非美国人谈判的技巧
- 解决Python memory error的问题--扩充虚拟内存
- Nginx安装成Windows服务
- 林绪虹:看好QoE、音视频内容理解与AV1
- GPU Gems1 - 5 改良的Perlin噪声的实现
- android app源码大全_Android秋招秘籍,看我如何搞定BAT,Vivo,爱奇艺
- Git管理代码常用术语
- 【报告分享】2022中国女性内衣行业研究报告.pdf(附下载链接)
- angular HttpClient getbyid 方法获取数据
- mybatis注解开发-动态SQL
- Atitit 技术经理 技术总裁 cto 技术总监 职责与流程表总结 v4 t88.docx Atitit 技术总裁 cto 技术总监 技术经理职责与流程表总结 1. 人事财物 文化精神
- matlab做挖掘机仿真,基于Proe_Adams_Matlab挖掘机的机电液一体化仿真
- 厦门大学应用统计专硕考研上岸经验分享
- python表格绘制斜线表头_Java中使用POI在Excel单元格中画斜线—XLSX格式
- Latex录入参考文献bib.bib文件
- 郑职院官计算机网络,2020年陕西省青年职业技能大赛计算机网络管理员决赛开幕式在汉中职院举行...
- 直流电机参数术语中英文对照及解释
- 这10种赚钱方法,用手机就可以做,看看哪种适合你?