比Momentum更快:揭开Nesterov Accelerated Gradient的真面目NAG 梯度下降
d为累计梯度
文章的内容包括了Momentum、Nesterov Accelerated Gradient、AdaGrad、AdaDelta和Adam,在这么多个优化算法里面,一个妖艳的贱货(划去)成功地引起了我的注意——Nesterov Accelerated Gradient,简称NAG。原因不仅仅是它名字比别人长,而且还带了个逼格很高、一听就像是个数学家的人名,还因为,它仅仅是在Momentum算法的基础上做了一点微小的工作,形式上发生了一点看似无关痛痒的改变,却能够显著地提高优化效果。为此我折腾了一个晚上,终于扒开了它神秘的面纱……(主要是我推导公式太慢了……)
话不多说,进入正题,首先简要介绍一下Momentum和NAG,但是本文无耻地假设你已经懂了Momentum算法,如果不懂的话,强烈推荐这篇专栏:《路遥知马力——Momentum - 无痛的机器学习 - 知乎专栏》,本文的实验代码也是在这篇专栏的基础上改的。
Momentum改进自SGD算法,让每一次的参数更新方向不仅仅取决于当前位置的梯度,还受到上一次参数更新方向的影响:
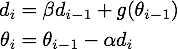

公式1,Momentum的数学形式
其中,和
分别是这一次和上一次的更新方向,
表示目标函数在
处的梯度,超参数
是对上一次更新方向的衰减权重,所以一般是0到1之间,
是学习率。总的来说,在一次迭代中总的参数更新量包含两个部分,第一个是由上次的更新量得到的
,第二个则是由本次梯度得到的
。
所以Momentum的想法很简单,就是多更新一部分上一次迭代的更新量,来平滑这一次迭代的梯度。从物理的角度上解释,就像是一个小球滚落的时候会受到自身历史动量的影响,所以才叫动量(Momentum)算法。这样做直接的效果就是使得梯度下降的的时候转弯掉头的幅度不那么大了,于是就能够更加平稳、快速地冲向局部最小点:
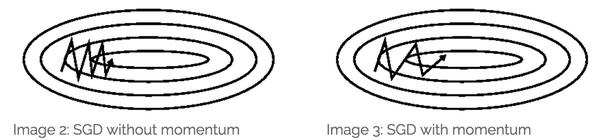
图片引自《An overview of gradient descent optimization algorithms》
然后NAG就对Momentum说:“既然我都知道我这一次一定会走的量,那么我何必还用现在这个位置的梯度呢?我直接先走到
之后的地方,然后再根据那里的梯度再前进一下,岂不美哉?”所以就有了下面的公式:
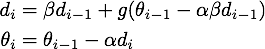
公式2,NAG的原始形式
跟上面Momentum公式的唯一区别在于,梯度不是根据当前参数位置,而是根据先走了本来计划要走的一步后,达到的参数位置
计算出来的。
对于这个改动,很多文章给出的解释是,能够让算法提前看到前方的地形梯度,如果前面的梯度比当前位置的梯度大,那我就可以把步子迈得比原来大一些,如果前面的梯度比现在的梯度小,那我就可以把步子迈得小一些。这个大一些、小一些,都是相对于原来不看前方梯度、只看当前位置梯度的情况来说的。
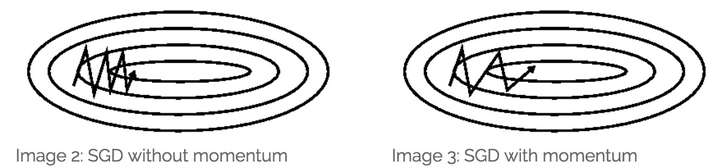
但是我个人对这个解释不甚满意。你说你可以提前看到,但是我下次到了那里之后不也照样看到了吗?最多比你落后一次迭代的时间,真的会造成非常大的差别?可是实验结果就是表明,NAG收敛的速度比Momentum要快:
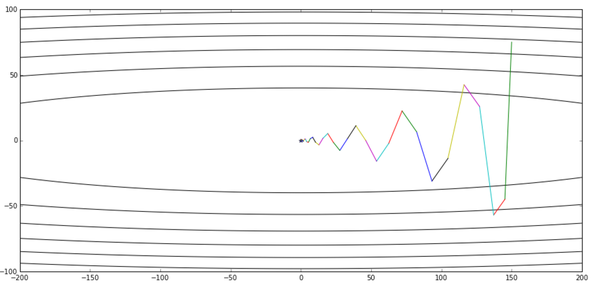
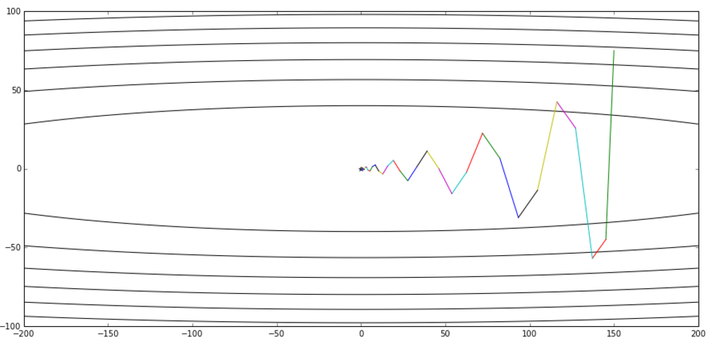

图片引自《路遥知马力——Momentum - 无痛的机器学习 - 知乎专栏》,上图是Momentum的优化轨迹,下图是NAG的优化轨迹
为了从另一个角度更加深入地理解这个算法,我们可以对NAG原来的更新公式进行变换,得到这样的等效形式(具体推导过程放在最后啦):
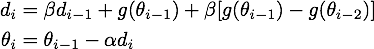

公式3,NAG的等效形式
这个NAG的等效形式与Momentum的区别在于,本次更新方向多加了一个,它的直观含义就很明显了:如果这次的梯度比上次的梯度变大了,那么有理由相信它会继续变大下去,那我就把预计要增大的部分提前加进来;如果相比上次变小了,也是类似的情况。这样的解释听起来好像和原本的解释一样玄,但是读者可能已经发现了,这个多加上去的项不就是在近似目标函数的二阶导嘛!所以NAG本质上是多考虑了目标函数的二阶导信息,怪不得可以加速收敛了!其实所谓“往前看”的说法,在牛顿法这样的二阶方法中也是经常提到的,比喻起来是说“往前看”,数学本质上则是利用了目标函数的二阶导信息。
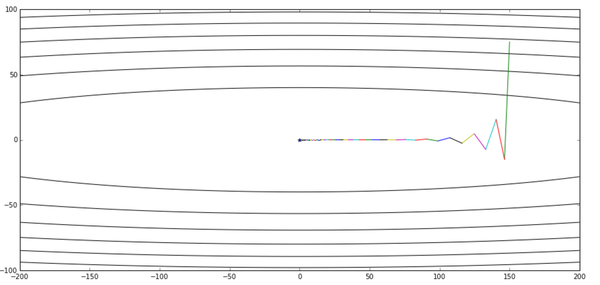
那么,变换后的形式真的与NAG的原始形式等效么?在给出数学推导之前,先让我用实验来说明吧:
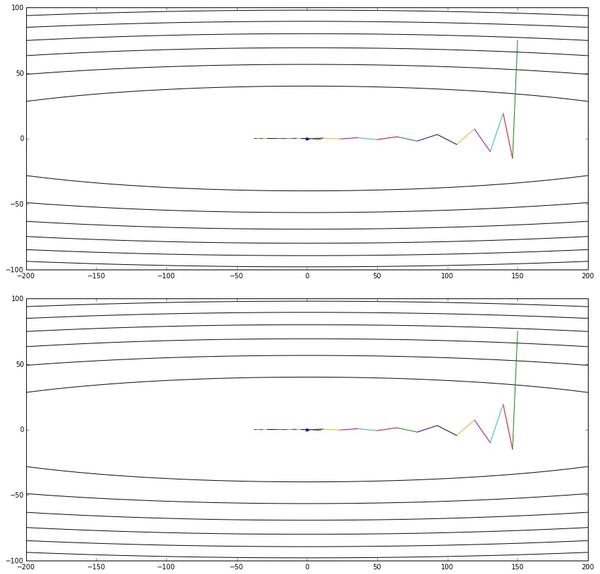
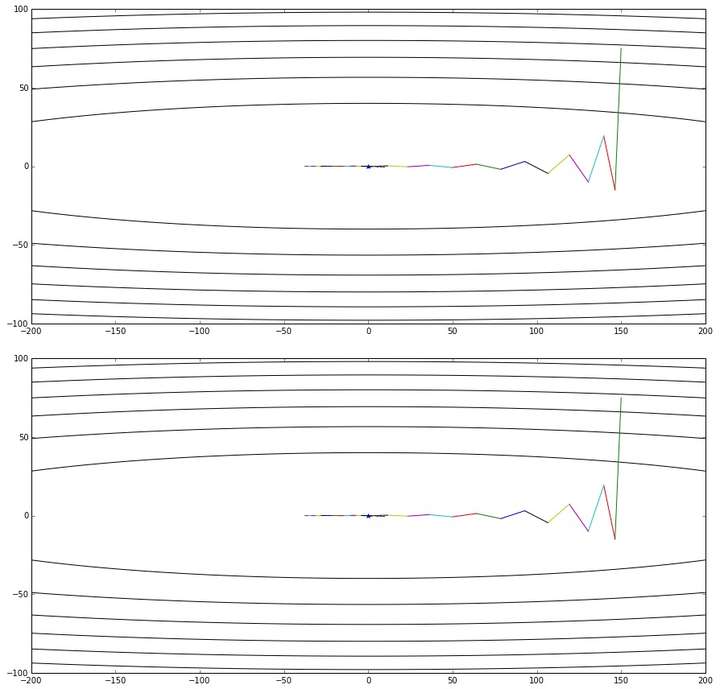
上图是公式3给出的优化轨迹,下图是公式2给出的优化轨迹——完全一样
实验代码放在Github,修改自《路遥知马力——Momentum - 无痛的机器学习 - 知乎专栏》的实验代码。有兴趣的读者可以多跑几个起始点+学习率+衰减率的超参数组合,无论如何两个算法给出的轨迹都会是一样的。
最后给出NAG的原始形式到等效形式的推导。由
可得
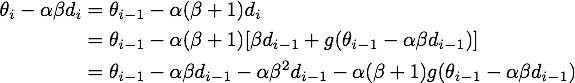
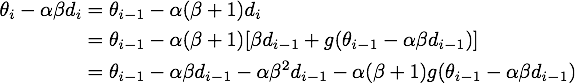
记
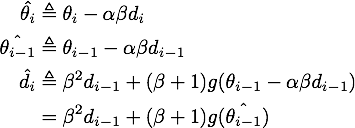
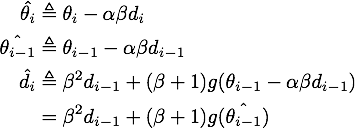
上式代入上上式,就得到了NAG等效形式的第二个式子:
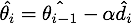
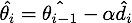
对展开可得
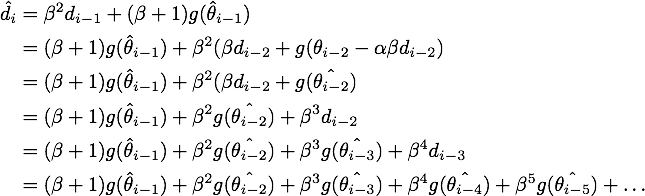
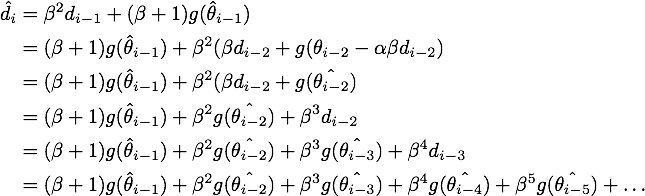
于是我们可以写出的形式,然后用
减去
消去后面的无穷多项,就得到了NAG等效形式的第一个式子:
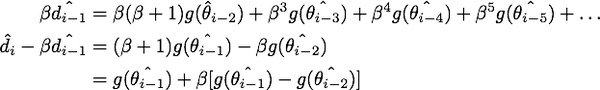
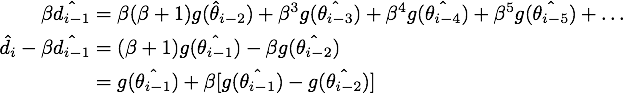
最终我们就得到了NAG的等效形式:
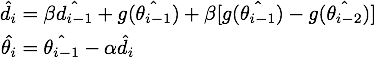
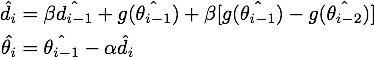
结论:在原始形式中,Nesterov Accelerated Gradient(NAG)算法相对于Momentum的改进在于,以“向前看”看到的梯度而不是当前位置梯度去更新。经过变换之后的等效形式中,NAG算法相对于Momentum多了一个本次梯度相对上次梯度的变化量,这个变化量本质上是对目标函数二阶导的近似。由于利用了二阶导的信息,NAG算法才会比Momentum具有更快的收敛速度。
本文实验代码放在Github

比Momentum更快:揭开Nesterov Accelerated Gradient的真面目NAG 梯度下降相关推荐
- NESTEROV ACCELERATED GRADIENT AND SCALE INVARIANCE FOR ADVERSARIAL ATTACKS (翻译,侵删)
NESTEROV ACCELERATED GRADIENT AND SCALE INVARIANCE FOR ADVERSARIAL ATTACKS(Nesterov 加速梯度和缩放不变性攻击) 摘要 ...
- 入门神经网络优化算法(一):Gradient Descent,Momentum,Nesterov accelerated gradient
入门神经网络优化算法(一):Gradient Descent,Momentum,Nesterov accelerated gradient 入门神经网络优化算法(二):Adaptive Optimiz ...
- APG(Accelerate Proximal Gradient)加速近端梯度算法 和 NAG(Nesterov accelerated gradient)优化器原理 (二)
文章目录 前言 NAG优化器 APG 与 NAG的结合 Pytorch 代码实现 总结 附录 公式(11)推导 引用 前言 近期在阅读Data-Driven Sparse Structure Sele ...
- 【机器学习】numpy实现NAG(Nesterov accelerated gradient)优化器
⚡本系列历史文章⚡ [Momentum优化器] [Nesterov accelerated gradient优化器] [RMSprop优化器] [Adagrad优化器] [Adadelta优化器] [ ...
- 深度学习优化函数详解(5)-- Nesterov accelerated gradient (NAG) 优化算法
深度学习优化函数详解系列目录 深度学习优化函数详解(0)– 线性回归问题 深度学习优化函数详解(1)– Gradient Descent 梯度下降法 深度学习优化函数详解(2)– SGD 随机梯度下降 ...
- 深度学习优化函数详解-- Nesterov accelerated gradient (NAG)
动量法每下降一步都是由前面下降方向的一个累积和当前点的梯度方向组合而成.于是一位大神(Nesterov)就开始思考,既然每一步都要将两个梯度方向(历史梯度.当前梯度)做一个合并再下降,那为什么不先按照 ...
- 深度学习优化函数详解(5)-- Nesterov accelerated gradient (NAG)
深度学习优化函数详解系列目录 本系列课程代码,欢迎star: https://github.com/tsycnh/mlbasic 深度学习优化函数详解(0)-- 线性回归问题 深度学习优化函数详解(1 ...
- 论文笔记《NESTEROV ACCELERATED GRADIENT AND SCALE INVARIANCE FOR ADVERSARIAL ATTACKS》
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 提出的方法 一.解决的问题 二.思路 三.算法 四.实验 五.结论 提出的方法 提出了两种新的方法来提高对抗实例的可移植性, ...
- APG(Accelerate Proximal Gradient)加速近端梯度算法 和 NAG(Nesterov accelerated gradient)优化器原理 (一)
文章目录 前言 APG(Accelerate Proximal Gradient)加速近端梯度算法[^1] PGD (Proximal Gradient Descent)近端梯度下降法推导[^2] E ...
最新文章
- 从实例入手学习Shiro的会话机制
- 第12天学习Java的笔记(数组小练习,数组与方法)
- L1-010 比较大小(8行代码AC!!!)
- java线程统一_Java线程结果不一致
- 不等待输入_明明显示“对方正在输入”却总等不来回复,其实是你误解了
- 间歇输入数据的数据处理设计模式
- linux 本地端口关,Linux查看端口使用状态、关闭端口方法
- 2013 ACM区域赛长沙 H zoj 3733 (hdu 4798) Skycity
- python中fg是什么意思_Python fg
- hex2bin和bin2hex
- 单片机51keil编程流程
- xls解密(实战详细教程)
- C/C++《程序设计基础(C语言)课程设计》[2023-04-20]
- 鸿蒙系统诞生的背景,为何国产系统发展多年无人问津,华为鸿蒙系统刚一开始就引起轰动...
- 22部漫威电影大合集和观影顺序
- 实用的19条android平台设计规范
- 黑客宣称可以越狱苹果T2安全芯片
- androidstudio虚拟机打不开的解决方法,一路坎坷,靠运气成功的!!!
- WINCC 7.5 sp1 sp2安装包,硬件狗等,Sim_EKB_Install_2018下载
- Excel模板数据填充导出
热门文章
- 设置select下拉框不可修改的→“四”←种方法
- 【Kubernetes】如何使用Kubeadm部署K8S集群
- linux修改mysql密码sa_如何修改SA口令,数据库SA密码怎么改?
- 2022-2028年中国演出市场深度调研与投资可行性报告
- pykafka连接重要使用pykafka,kafka-python的api开发kafka生产者和消费者
- 受用一生的高效 PyCharm 使用技巧(一)
- pandas数据框,统计某列或者某行数据元素的个数
- LeetCode简单题之找出两数组的不同
- LeetCode简单题之仅执行一次字符串交换能否使两个字符串相等
- LeetCode简单题之数组中两元素的最大乘积