基于python的贝叶斯分类算法_分类算法-朴素贝叶斯
朴素贝叶斯分类器(Naive Bayes Classifier, NBC)发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。同时,NBC 模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。之所以成为“朴素”是因为整个形式化过程只做最原始、最简单的假设。朴素贝叶斯在数据较少的情况下仍然有效,可以处理多类别问题。
0x00贝叶斯概论原理
首先,要明白贝叶斯统计方式与统计学中的频率概念是不同
统计学中的概率从频率的角度出发,即假定数据遵循某种分布,我们的目标是确定该分布的几个参数,在某个固定的环境一下做模型。而贝叶斯则是根据实际的推理方式来建模。我们拿到的数据,来更新模型对某事件即将发生的可能性的预测结果。
在贝叶斯统计学中,我们使用数据来描述模型,而不是使用模型来描述数据。 贝叶斯定理旨在计算P(A|B)的值,也就是在已知B发生的条件下,A发生的概率是多少。
大多数情况下,B是被观察事件,比如“昨天下雨了”,A为预测结果“今天会下雨”。对数据挖掘来说,B通常是观察样本个体,A为被预测个体所属类别。所以,说简单一点,贝叶斯就是计算的是:B是A类别的概率。
举例说明,我们想计算含有单词drugs的邮件为垃圾邮件的概率。
在这里,A为“这是封垃圾邮件”。我们先来计算P(A),它也被称为先验概率,计算方法是,统计训练中的垃圾邮件的比例,如果我们的数据集每100封邮件有30封垃圾邮件,P(A)为30/100=0.3。
B表示“该封邮件含有单词drugs”。类似地,我们可以通过计算数据集中含有单词drugs的邮件数P(B)。如果每100封邮件有10封包含有drugs,那么P(B)就为10/100=0.1。
P(B|A)指的是垃圾邮件中含有的单词drugs的概率,计算起来也很容易,如果30封邮件中有6封含有drugs,那么P(B|A)的概率为6/30=0.2。
现在,就可以根据贝叶斯定理计算出P(A|B),得到含有drugs的邮件为垃圾邮件的概率。把上面的每一项带入前面的贝叶斯公式,得到结果为0.6。这表明如果邮件中含有drugs这个词,那么该邮件为垃圾邮件的概率为60%。

算法应用示例
下面举例说明下计算过程,假如数据集中有以下一条用二值特征表示的数据:[1,0,0,1]。
训练集中有75%的数据集属于类别0,25%属于类别1,且每一个特征属于每个类别的概率为:
类别0:[0.3, 0.4, 0.4, 0.7]
类别1:[0.7, 0.3, 0.4, 0.9]
注:上述类别中的小数表示有多少概率该特征为1,例如0.3表示有30%的数据,特征1的值为1。
我们来计算一下这条数据属于类别0的概率。类别为0时,P(C=0) = 0.75。
朴素贝叶斯算法不用P(D),因此我们不用计算它。
P(D|C=0) = P(D1|C=0) * P(D2|C=0) * P(D3|C=0) * P(D4|C=0)
= 0.3 * 0.6 * 0.6 * 0.7
= 0.0756
现在我们就可以计算该条数据从属于每个类别的概率。
P(C=0|D) = P(C=0) * P(D|C=0)
= 0.75 * 0.0756
= 0.0567
接着计算类别1的概率,方法同上。可以得到
P(C=1|D) = 0.06615
由此可以推断这条数据应该分到类别1中。以上就是朴素贝叶斯的全部计算过程。还有一点应该注意,通常, P(C=0|D) + P(C=1|D) 应该等于1。然而在上述中并不是等于1,这是因为我们在计算中省去了公式中的P(D)项。
补充:
上述只考虑了二值特征属性(离散属性)的情况,但是,在实际情况中也会遇上非离散属性而是连续属性的情况,这时就该用概率密度函数来计算条件概率P(x|c)。μ(c,i)和 σ(c,i)^2分别是第c类样本在第i个属性上取值的均值和方差。则有:
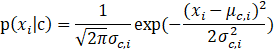
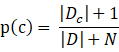
同时,对于朴素贝叶斯还需要说明的一点是:若某种属性值在训练集中没有与某个类同时出现过,则直接基于概率估计公式得出来概率为0,再通过各个属性概率连乘式计算出的概率也为0,这就导致没有办法进行分类了,所以,为了避免属性携带的信息被训练集未出现的属性值“抹去”,在估计概率值时通常要进行“平滑”,常用“拉普拉斯修正”,具体来讲,令N表示训练集D中可能的类别数,Ni表示第i个属性可能的取值数。
拉普拉斯修正避免了样本不充分而导致概率估计为零的问题,并且在训练集样本变大的时候,修正过程所引入的先验的影响也会逐渐变得可忽视,使得估计值越来越接近实际概率值。
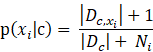
0x00朴素贝叶斯
其实,通过上面的例子我们可以知道它能计算个体从属于给定类别的概率。因此,他能用来分类。
我们用C表示某种类别,用D代表数据集中的一篇文档,来计算贝叶斯公式所要用到的各种统计量,对于不好计算的,做出朴素假设,简化计算。
P(C)为某一类别的概率,可以从训练集中计算得到。
P(D)为某一文档的概率,它牵扯到很多特征,计算很难,但是,可以这样理解,当在计算文档属于哪一类别时,对于所有类别来说,每一篇文档都是独立重复事件,P(D)相同,因此根本不用计算它。稍后看怎样处理它。
P(D|C)为文档D属于C类的概率,由于D包含很多特征,计算起来很难,这时朴素贝叶斯就派上用场了,我们朴素地假定各个特征是互相独立的,分别计算每个特征(D1、D2、D3等)在给定类别的概率,再求他们的积。
上式右侧对于二值特征相对比较容易计算。直接在数据集中进行统计,就能得到所有特征的概率值。
相反,如果我们不做朴素的假设,就要计算每个类别不同特征之间的相关性。这些计算很难完成,如果没有大量的数据或足够的语言分析模型是不可能完成的。
0x00贝叶斯概论和统计概论区别
频率学派:
频率学派认为,对于一批样本,其分布是确定的,也即是是确定的,只不过未知。为什么会有这样的想法?这就要从频率学派的基本宗旨来看了,频率学派认为概率即是频率,某次得到的样本X只是无数次可能的试验结果的一个具体实现,样本中未出现的结果不是不可能出现,只是这次抽样没有出现而已,因此综合考虑已抽取到的样本X以及未被抽取、实现的结果,可以认为总体分布是确定的,不过未知,而样本来自于总体,故其样本分布也同样的特点。 基于此,就可以使用估计方法去推断。
贝叶斯学派:
贝叶斯学派否定了概率及频率的观点,并且反对把样本X放到“无限多可能值之一”背景下去考虑,既然只得到了样本X,那么就只能依靠它去做推断,而不能考虑那些有可能出现而未出现的结果。与此同时,贝叶斯学派引入了主观概率的概念,认为一个事件在发生之前,人们应该对它是有所认知的,即中的不是固定的,而是一个随机变量,并且服从分布,该分布称为“先验分布”(指抽样之前得到的分布),当得到样本X后,我们对的分布则有了新的认识,此时有了更新,这样就得到了“后验分布”(指抽样之后得到的分布),此时可以再对做点估计、区间估计,此时的估计不再依赖样本,完全只依赖的后验分布了。
频率学派对贝叶斯学派的批评
频率学派对贝叶斯学派的批评主要集中在主观概率及与之相关的先验分布的确定问题上。按频率学派的观点,一个事件的概率可以用大量重复试验之下事件出现的频率来解释,这种解释不取决于主体的认识。频率学派认为主观概率不仅难以捉摸,而且与认识主体有关,没有客观性,因而也就没有科学性,这是不可接受的。
针对频率学派的批评,贝叶斯学派做出了以下回应:
1. 主观概率事实上是人们常用的概念。例如人们常说:”这个事儿十有八九能成”,这就是人们的一个主观概率,能做出这样的推测人们肯定是考虑了一些因素的(比如考虑了做事儿的人,做事的方法等),这是有一定道理的。
2. 在涉及采取行动并承担后果的问题上,每个人了解的情况不同,对问题所具有的只是也不同,他们采取的最佳行动方案也会不同,在这种情况下,不同的人有不同的先验分布是很正常的,要求所谓的“客观性”反倒没有意义了。
频率学派对贝叶斯学派还有一个批评,样本分布一般都是在频率的意义上来解释的,他们认为,既然贝叶斯学派否定频率观点,为何也会用到样本分布?对于这个批评,贝叶斯学派确实是难以做出让人信服的回答,如果做一个彻底的主观概率论者,就必须把样本分布看成刻画样本取各种值在主观上的信服程度,由于样本是已知的,而贝叶斯学派反对把样本放到无穷多可能样本的背景下去考虑这种做法,故而将主观概率的思想推到极端,贝叶斯学派甚至不能去谈论什么样本分布问题。
贝叶斯学派对频率学派的批评
1. 关于概率的频率解释观点。许多问题是没法做重复性试验、是一次性的,严格相同甚至大致相同的条件下的重复事实上是不可能的,比如地震观测,因此在这种条件下统计概念和方法的频率解释完全没有现实意义。
2. 频率学派基于概率的频率解释,其所导出的方法(点估计、区间估计、假设检验等)的精度和可靠度也只是大量重复下的平均值,这是在抽样之前就已经确定的(也就是前文所说
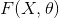
的是确定的),这种不顾实际的样本值而在事前就规定的精度和可靠度是不合理的,而且往往是实际情况大相庭径。直观上人们更倾向于接受的是:统计推断的精度和可靠性如何,与试验结果(样本)有关。
我们来计算一个列题试一试:
基本数据和结果:
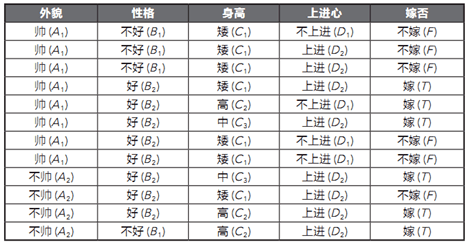
特征和类别时相互独立的,
特征:外貌、性格、身高、上进心
类别:嫁否
尝试计算男生向女生求婚,但是男的特点不帅、性格不好、矮、不上进、判断嫁还是不嫁?

根据朴素贝叶斯算法得出结果1/48大于1/864,答案时不嫁。
本作品采用《CC 协议》,转载必须注明作者和本文链接
基于python的贝叶斯分类算法_分类算法-朴素贝叶斯相关推荐
- sklearn朴素贝叶斯分类器_机器学习06——朴素贝叶斯
一.概率公式: 条件概率公式: 事件A发生的条件下,事件B发生的概率=事件A和事件B同时发生的概率/事件A发生的概率 P(AB)=P(A)*P(B|A) 事件A和事件B同时发生的概率=事件A发生的概率 ...
- 白话 贝叶斯公式_【白话机器学习】算法理论+实战之朴素贝叶斯
来自于: AI蜗牛车团队(作者:Miracle8070) 公众号: AI蜗牛车 原文链接:[白话机器学习]算法理论+实战之朴素贝叶斯mp.weixin.qq.com 有兴趣的同学可以关注我的公众号: ...
- 【白话机器学习】算法理论+实战之朴素贝叶斯
1. 写在前面 如果想从事数据挖掘或者机器学习的工作,掌握常用的机器学习算法是非常有必要的,常见的机器学习算法: 监督学习算法:逻辑回归,线性回归,决策树,朴素贝叶斯,K近邻,支持向量机,集成算法Ad ...
- 《机器学习实战》学习笔记(四):基于概率论的分类方法 - 朴素贝叶斯
欢迎关注WX公众号:[程序员管小亮] [机器学习]<机器学习实战>读书笔记及代码 总目录 https://blog.csdn.net/TeFuirnever/article/details ...
- 基于概率论的分类方法: 朴素贝叶斯
朴素贝叶斯 概述 贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类.本章首先介绍贝叶斯分类算法的基础--贝叶斯定理.最后,我们通过实例来讨论贝叶斯分类的中最简单的一种: ...
- 【手写算法实现】 之 朴素贝叶斯 Naive Bayes 篇
[手写算法实现] 之 朴素贝叶斯 Naive Bayes 篇 朴素贝叶斯模型(naive bayes)属于分类模型,也是最为简单的概率图模型,对于之后理解HMM.CRF等模型,大有裨益.这里手写算法介 ...
- 机器学习算法(7)—— 朴素贝叶斯算法
朴素贝叶斯算法 1 朴素贝叶斯介绍 2 贝叶斯公式 3 拉普拉斯平滑系数 4 朴素贝叶斯api使用 5 朴素贝叶斯算法总结 5.1 朴素贝叶斯优缺点 5.2 朴素贝叶斯疑难点 5.3 与逻辑回归的区别 ...
- 算法工程师面试之朴素贝叶斯
前言 文章来源: LawsonAbs@CSDN 弄懂一个算法是快乐的,V(^-^)V 是生成模型,是分类算法.使用的参数估计方法是极大似然估计(其实就是频率统计) 在定义朴素贝叶斯之前,先给出如下几个 ...
- 基于概率论的分类方法—朴素贝叶斯
基于概率论的分类方法-朴素贝叶斯 转载于:https://www.cnblogs.com/liuys635/p/11181304.html
- bayes什么意思_什么是朴素贝叶斯法?
1) 朴素贝叶斯法(naive Bayes)基于什么理论? 朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法. 2) 朴素贝叶斯法的过程是怎样的? 对于给定的训练数据集,首先基于特征条件独立假 ...
最新文章
- 【Android游戏开发二十七】讲解游戏开发与项目下的hdpi 、mdpi与ldpi资源文件夹以及游戏高清版本的设置...
- IO流(IO异常处理方式)
- es中修改某个字段值_搜索引擎之laravel中使用elasticsearch(一)
- flask开启调试的四种模式
- php代码提示助手,laravel自动补全助手ide-helper安置及配置
- c++语言偶数分离,在C++的链表中分离偶数和奇数节点
- 解决vue在ie9中的兼容问题
- python房价数据分析波士顿_Python编程数据科学入门 - 波士顿房价数据分析
- 清除/收缩SQL Server数据库日志
- python免费使用谷歌翻译的方法
- 数据科学数据清理和可视化,适合使用python的初学者
- 杂记 - 0002 - 衣服 - 尺寸表与跳码
- 麒麟V10系统-系统激活点击按钮无响应
- SQL(进阶实战05)
- 反激式开关电源输出电压的PID控制之MATLAB仿真
- html5中图片热点,HTML5 创建热点图
- 球面三角形的梅涅劳斯定理、塞瓦定理及其应用
- 【IT运维小知识】安全组是什么意思?
- 判断某个数列是不是二元查找树的后序遍历。
- viterbi算法词性标注