java温故笔记(二)java的数组HashMap、ConcurrentHashMap、ArrayList、LinkedList
为什么80%的码农都做不了架构师?>>> 
HashMap
摘要
HashMap是Java程序员使用频率最高的用于映射(键值对)处理的数据类型。随着JDK(Java Developmet Kit)版本的更新,JDK1.8对HashMap底层的实现进行了优化,例如引入红黑树的数据结构和扩容的优化等。本文结合JDK1.7和JDK1.8的区别,深入探讨HashMap的结构实现和功能原理。
简介
Java为数据结构中的映射定义了一个接口java.util.Map,此接口主要有四个常用的实现类,分别是HashMap、Hashtable、LinkedHashMap和TreeMap,类继承关系如下图所示:
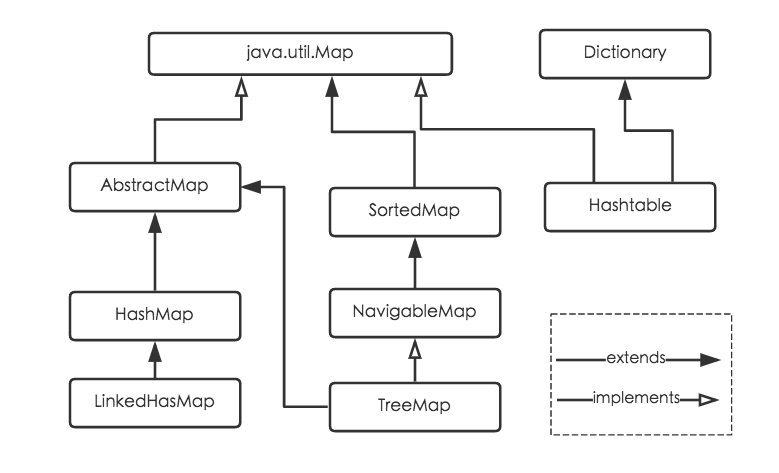
下面针对各个实现类的特点做一些说明:
(1) HashMap:它根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。 HashMap最多只允许一条记录的键为null,允许多条记录的值为null。HashMap非线程安全,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用 Collections的synchronizedMap方法使HashMap具有线程安全的能力,或者使用ConcurrentHashMap。
(2) Hashtable:Hashtable是遗留类,很多映射的常用功能与HashMap类似,不同的是它承自Dictionary类,并且是线程安全的,任一时间只有一个线程能写Hashtable,并发性不如ConcurrentHashMap,因为ConcurrentHashMap引入了分段锁。Hashtable不建议在新代码中使用,不需要线程安全的场合可以用HashMap替换,需要线程安全的场合可以用ConcurrentHashMap替换。
(3) LinkedHashMap:LinkedHashMap是HashMap的一个子类,保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的,也可以在构造时带参数,按照访问次序排序。
(4) TreeMap:TreeMap实现SortedMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的。如果使用排序的映射,建议使用TreeMap。在使用TreeMap时,key必须实现Comparable接口或者在构造TreeMap传入自定义的Comparator,否则会在运行时抛出java.lang.ClassCastException类型的异常。
对于上述四种Map类型的类,要求映射中的key是不可变对象。不可变对象是该对象在创建后它的哈希值不会被改变。如果对象的哈希值发生变化,Map对象很可能就定位不到映射的位置了。
通过上面的比较,我们知道了HashMap是Java的Map家族中一个普通成员,鉴于它可以满足大多数场景的使用条件,所以是使用频度最高的一个。下文我们主要结合源码,从存储结构、常用方法分析、扩容以及安全性等方面深入讲解HashMap的工作原理。
内部实现
搞清楚HashMap,首先需要知道HashMap是什么,即它的存储结构-字段;其次弄明白它能干什么,即它的功能实现-方法。下面我们针对这两个方面详细展开讲解。
存储结构-字段
从结构实现来讲,HashMap是数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,如下如所示。
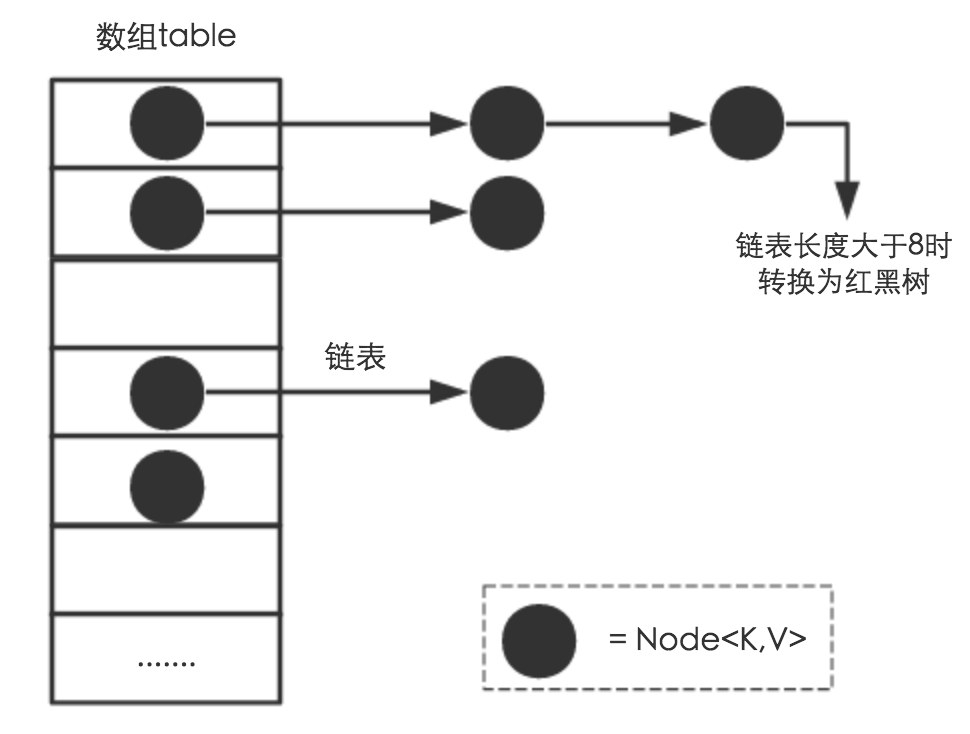
这里需要讲明白两个问题:数据底层具体存储的是什么?这样的存储方式有什么优点呢?
(1) 从源码可知,HashMap类中有一个非常重要的字段,就是 Node[] table,即哈希桶数组,明显它是一个Node的数组。我们来看Node[JDK1.8]是何物。
static class Node<K,V> implements Map.Entry<K,V> {final int hash; //用来定位数组索引位置final K key;V value;Node<K,V> next; //链表的下一个nodeNode(int hash, K key, V value, Node<K,V> next) { ... }public final K getKey(){ ... }public final V getValue() { ... }public final String toString() { ... }public final int hashCode() { ... }public final V setValue(V newValue) { ... }public final boolean equals(Object o) { ... }
}
Node是HashMap的一个内部类,实现了Map.Entry接口,本质是就是一个映射(键值对)。上图中的每个黑色圆点就是一个Node对象。
(2) HashMap就是使用哈希表来存储的。哈希表为解决冲突,可以采用开放地址法和链地址法等来解决问题,Java中HashMap采用了链地址法。链地址法,简单来说,就是数组加链表的结合。在每个数组元素上都一个链表结构,当数据被Hash后,得到数组下标,把数据放在对应下标元素的链表上。例如程序执行下面代码:
map.put("美团","小美");
系统将调用"美团"这个key的hashCode()方法得到其hashCode 值(该方法适用于每个Java对象),然后再通过Hash算法的后两步运算(高位运算和取模运算,下文有介绍)来定位该键值对的存储位置,有时两个key会定位到相同的位置,表示发生了Hash碰撞。当然Hash算法计算结果越分散均匀,Hash碰撞的概率就越小,map的存取效率就会越高。
如果哈希桶数组很大,即使较差的Hash算法也会比较分散,如果哈希桶数组数组很小,即使好的Hash算法也会出现较多碰撞,所以就需要在空间成本和时间成本之间权衡,其实就是在根据实际情况确定哈希桶数组的大小,并在此基础上设计好的hash算法减少Hash碰撞。那么通过什么方式来控制map使得Hash碰撞的概率又小,哈希桶数组(Node[] table)占用空间又少呢?答案就是好的Hash算法和扩容机制。
在理解Hash和扩容流程之前,我们得先了解下HashMap的几个字段。从HashMap的默认构造函数源码可知,构造函数就是对下面几个字段进行初始化,源码如下:
int threshold; // 所能容纳的key-value对极限 final float loadFactor; // 负载因子int modCount; int size;
首先,Node[] table的初始化长度length(默认值是16),Load factor为负载因子(默认值是0.75),threshold是HashMap所能容纳的最大数据量的Node(键值对)个数。threshold = length * Load factor。也就是说,在数组定义好长度之后,负载因子越大,所能容纳的键值对个数越多。
结合负载因子的定义公式可知,threshold就是在此Load factor和length(数组长度)对应下允许的最大元素数目,超过这个数目就重新resize(扩容),扩容后的HashMap容量是之前容量的两倍。默认的负载因子0.75是对空间和时间效率的一个平衡选择,建议大家不要修改,除非在时间和空间比较特殊的情况下,如果内存空间很多而又对时间效率要求很高,可以降低负载因子Load factor的值;相反,如果内存空间紧张而对时间效率要求不高,可以增加负载因子loadFactor的值,这个值可以大于1。
size这个字段其实很好理解,就是HashMap中实际存在的键值对数量。注意和table的长度length、容纳最大键值对数量threshold的区别。而modCount字段主要用来记录HashMap内部结构发生变化的次数,主要用于迭代的快速失败。强调一点,内部结构发生变化指的是结构发生变化,例如put新键值对,但是某个key对应的value值被覆盖不属于结构变化。
在HashMap中,哈希桶数组table的长度length大小必须为2的n次方(一定是合数),这是一种非常规的设计,常规的设计是把桶的大小设计为素数。相对来说素数导致冲突的概率要小于合数,具体证明可以参考http://blog.csdn.net/liuqiyao_01/article/details/14475159,Hashtable初始化桶大小为11,就是桶大小设计为素数的应用(Hashtable扩容后不能保证还是素数)。HashMap采用这种非常规设计,主要是为了在取模和扩容时做优化,同时为了减少冲突,HashMap定位哈希桶索引位置时,也加入了高位参与运算的过程。
这里存在一个问题,即使负载因子和Hash算法设计的再合理,也免不了会出现拉链过长的情况,一旦出现拉链过长,则会严重影响HashMap的性能。于是,在JDK1.8版本中,对数据结构做了进一步的优化,引入了红黑树。而当链表长度太长(默认超过8)时,链表就转换为红黑树,利用红黑树快速增删改查的特点提高HashMap的性能,其中会用到红黑树的插入、删除、查找等算法。本文不再对红黑树展开讨论,想了解更多红黑树数据结构的工作原理可以参考http://blog.csdn.net/v_july_v/article/details/6105630。
功能实现-方法
HashMap的内部功能实现很多,本文主要从根据key获取哈希桶数组索引位置、put方法的详细执行、扩容过程三个具有代表性的点深入展开讲解。
1. 确定哈希桶数组索引位置
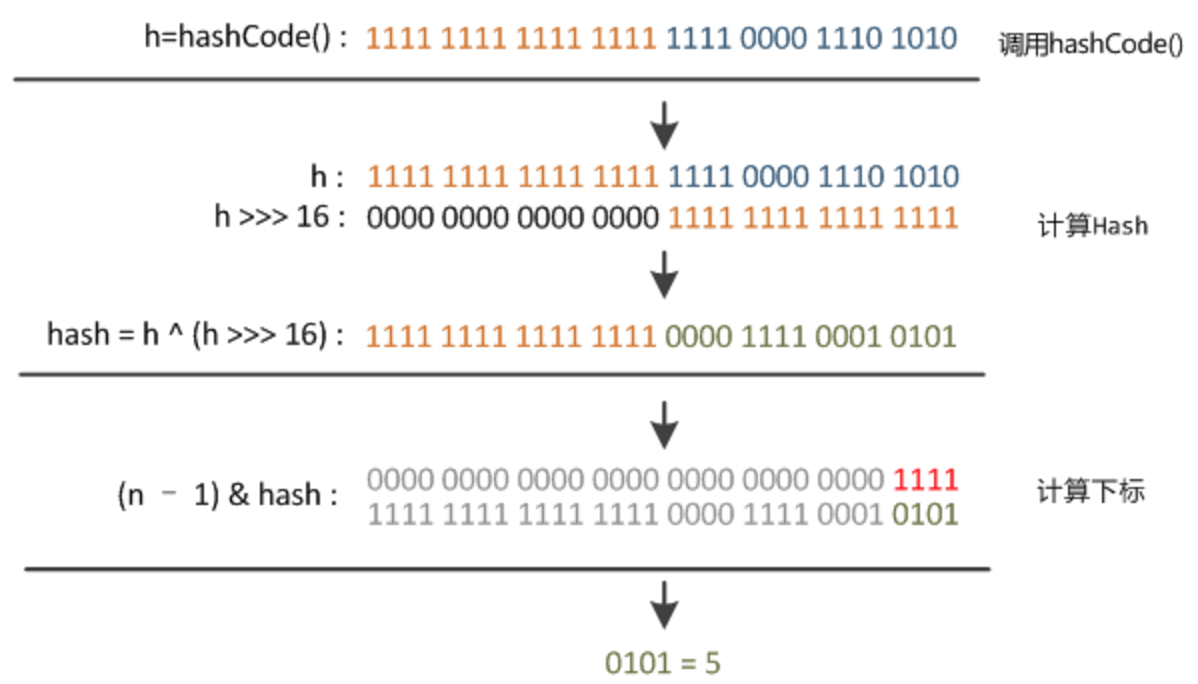
不管增加、删除、查找键值对,定位到哈希桶数组的位置都是很关键的第一步。前面说过HashMap的数据结构是数组和链表的结合,所以我们当然希望这个HashMap里面的元素位置尽量分布均匀些,尽量使得每个位置上的元素数量只有一个,那么当我们用hash算法求得这个位置的时候,马上就可以知道对应位置的元素就是我们要的,不用遍历链表,大大优化了查询的效率。HashMap定位数组索引位置,直接决定了hash方法的离散性能。先看看源码的实现(方法一+方法二):
方法一:
static final int hash(Object key) { //jdk1.8 & jdk1.7int h;// h = key.hashCode() 为第一步 取hashCode值// h ^ (h >>> 16) 为第二步 高位参与运算return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
方法二:
static int indexFor(int h, int length) { //jdk1.7的源码,jdk1.8没有这个方法,但是实现原理一样的return h & (length-1); //第三步 取模运算
}
这里的Hash算法本质上就是三步:取key的hashCode值、高位运算、取模运算。
对于任意给定的对象,只要它的hashCode()返回值相同,那么程序调用方法一所计算得到的Hash码值总是相同的。我们首先想到的就是把hash值对数组长度取模运算,这样一来,元素的分布相对来说是比较均匀的。但是,模运算的消耗还是比较大的,在HashMap中是这样做的:调用方法二来计算该对象应该保存在table数组的哪个索引处。
这个方法非常巧妙,它通过h & (table.length -1)来得到该对象的保存位,而HashMap底层数组的长度总是2的n次方,这是HashMap在速度上的优化。当length总是2的n次方时,h& (length-1)运算等价于对length取模,也就是h%length,但是&比%具有更高的效率。
在JDK1.8的实现中,优化了高位运算的算法,通过hashCode()的高16位异或低16位实现的:(h = k.hashCode()) ^ (h >>> 16),主要是从速度、功效、质量来考虑的,这么做可以在数组table的length比较小的时候,也能保证考虑到高低Bit都参与到Hash的计算中,同时不会有太大的开销。
下面举例说明下,n为table的长度。
2. 分析HashMap的put方法
HashMap的put方法执行过程可以通过下图来理解,自己有兴趣可以去对比源码更清楚地研究学习。
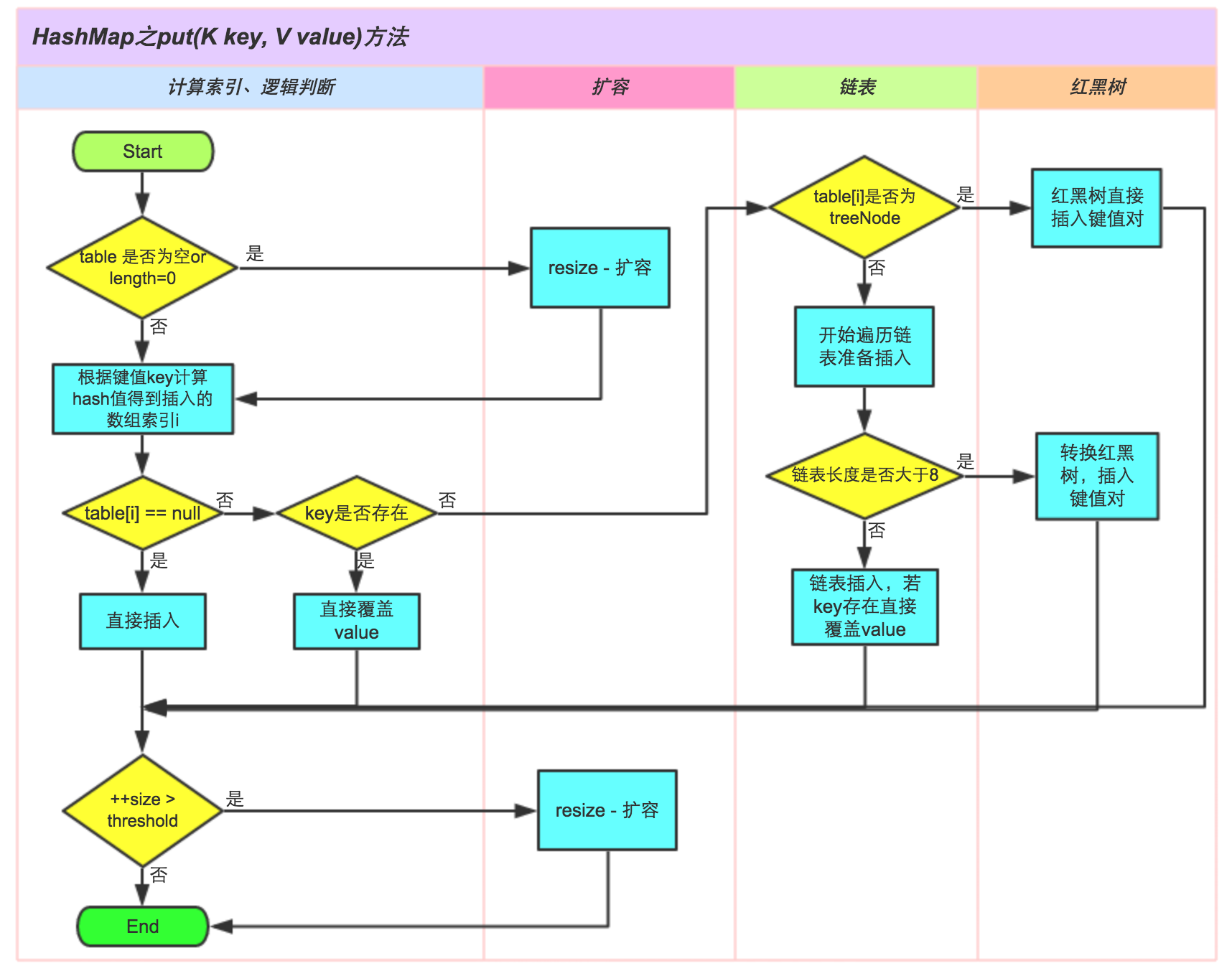
①.判断键值对数组table[i]是否为空或为null,否则执行resize()进行扩容;
②.根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加,转向⑥,如果table[i]不为空,转向③;
③.判断table[i]的首个元素是否和key一样,如果相同直接覆盖value,否则转向④,这里的相同指的是hashCode以及equals;
④.判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向⑤;
⑤.遍历table[i],判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;
⑥.插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold,如果超过,进行扩容。
JDK1.8HashMap的put方法源码如下:
1 public V put(K key, V value) {2 // 对key的hashCode()做hash3 return putVal(hash(key), key, value, false, true);4 }5 6 final V putVal(int hash, K key, V value, boolean onlyIfAbsent,7 boolean evict) {8 Node<K,V>[] tab; Node<K,V> p; int n, i;9 // 步骤①:tab为空则创建
10 if ((tab = table) == null || (n = tab.length) == 0)
11 n = (tab = resize()).length;
12 // 步骤②:计算index,并对null做处理
13 if ((p = tab[i = (n - 1) & hash]) == null)
14 tab[i] = newNode(hash, key, value, null);
15 else {
16 Node<K,V> e; K k;
17 // 步骤③:节点key存在,直接覆盖value
18 if (p.hash == hash &&
19 ((k = p.key) == key || (key != null && key.equals(k))))
20 e = p;
21 // 步骤④:判断该链为红黑树
22 else if (p instanceof TreeNode)
23 e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
24 // 步骤⑤:该链为链表
25 else {
26 for (int binCount = 0; ; ++binCount) {
27 if ((e = p.next) == null) {
28 p.next = newNode(hash, key,value,null);//链表长度大于8转换为红黑树进行处理
29 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
30 treeifyBin(tab, hash);
31 break;
32 }// key已经存在直接覆盖value
33 if (e.hash == hash &&
34 ((k = e.key) == key || (key != null && key.equals(k))))
35 break;
36 p = e;
37 }
38 }
39
40 if (e != null) { // existing mapping for key
41 V oldValue = e.value;
42 if (!onlyIfAbsent || oldValue == null)
43 e.value = value;
44 afterNodeAccess(e);
45 return oldValue;
46 }
47 }48 ++modCount;
49 // 步骤⑥:超过最大容量 就扩容
50 if (++size > threshold)
51 resize();
52 afterNodeInsertion(evict);
53 return null;
54 }
3. 扩容机制
扩容(resize)就是重新计算容量,向HashMap对象里不停的添加元素,而HashMap对象内部的数组无法装载更多的元素时,对象就需要扩大数组的长度,以便能装入更多的元素。当然Java里的数组是无法自动扩容的,方法是使用一个新的数组代替已有的容量小的数组,就像我们用一个小桶装水,如果想装更多的水,就得换大水桶。
我们分析下resize的源码,鉴于JDK1.8融入了红黑树,较复杂,为了便于理解我们仍然使用JDK1.7的代码,好理解一些,本质上区别不大,具体区别后文再说。
1 void resize(int newCapacity) { //传入新的容量2 Entry[] oldTable = table; //引用扩容前的Entry数组3 int oldCapacity = oldTable.length; 4 if (oldCapacity == MAXIMUM_CAPACITY) { //扩容前的数组大小如果已经达到最大(2^30)了5 threshold = Integer.MAX_VALUE; //修改阈值为int的最大值(2^31-1),这样以后就不会扩容了6 return;7 }8 9 Entry[] newTable = new Entry[newCapacity]; //初始化一个新的Entry数组
10 transfer(newTable); //!!将数据转移到新的Entry数组里
11 table = newTable; //HashMap的table属性引用新的Entry数组
12 threshold = (int)(newCapacity * loadFactor);//修改阈值
13 }
这里就是使用一个容量更大的数组来代替已有的容量小的数组,transfer()方法将原有Entry数组的元素拷贝到新的Entry数组里。
1 void transfer(Entry[] newTable) {2 Entry[] src = table; //src引用了旧的Entry数组3 int newCapacity = newTable.length;4 for (int j = 0; j < src.length; j++) { //遍历旧的Entry数组5 Entry<K,V> e = src[j]; //取得旧Entry数组的每个元素6 if (e != null) {7 src[j] = null;//释放旧Entry数组的对象引用(for循环后,旧的Entry数组不再引用任何对象)8 do {9 Entry<K,V> next = e.next;
10 int i = indexFor(e.hash, newCapacity); //!!重新计算每个元素在数组中的位置
11 e.next = newTable[i]; //标记[1]
12 newTable[i] = e; //将元素放在数组上
13 e = next; //访问下一个Entry链上的元素
14 } while (e != null);
15 }
16 }
17 }
newTable[i]的引用赋给了e.next,也就是使用了单链表的头插入方式,同一位置上新元素总会被放在链表的头部位置;这样先放在一个索引上的元素终会被放到Entry链的尾部(如果发生了hash冲突的话),这一点和Jdk1.8有区别,下文详解。在旧数组中同一条Entry链上的元素,通过重新计算索引位置后,有可能被放到了新数组的不同位置上。
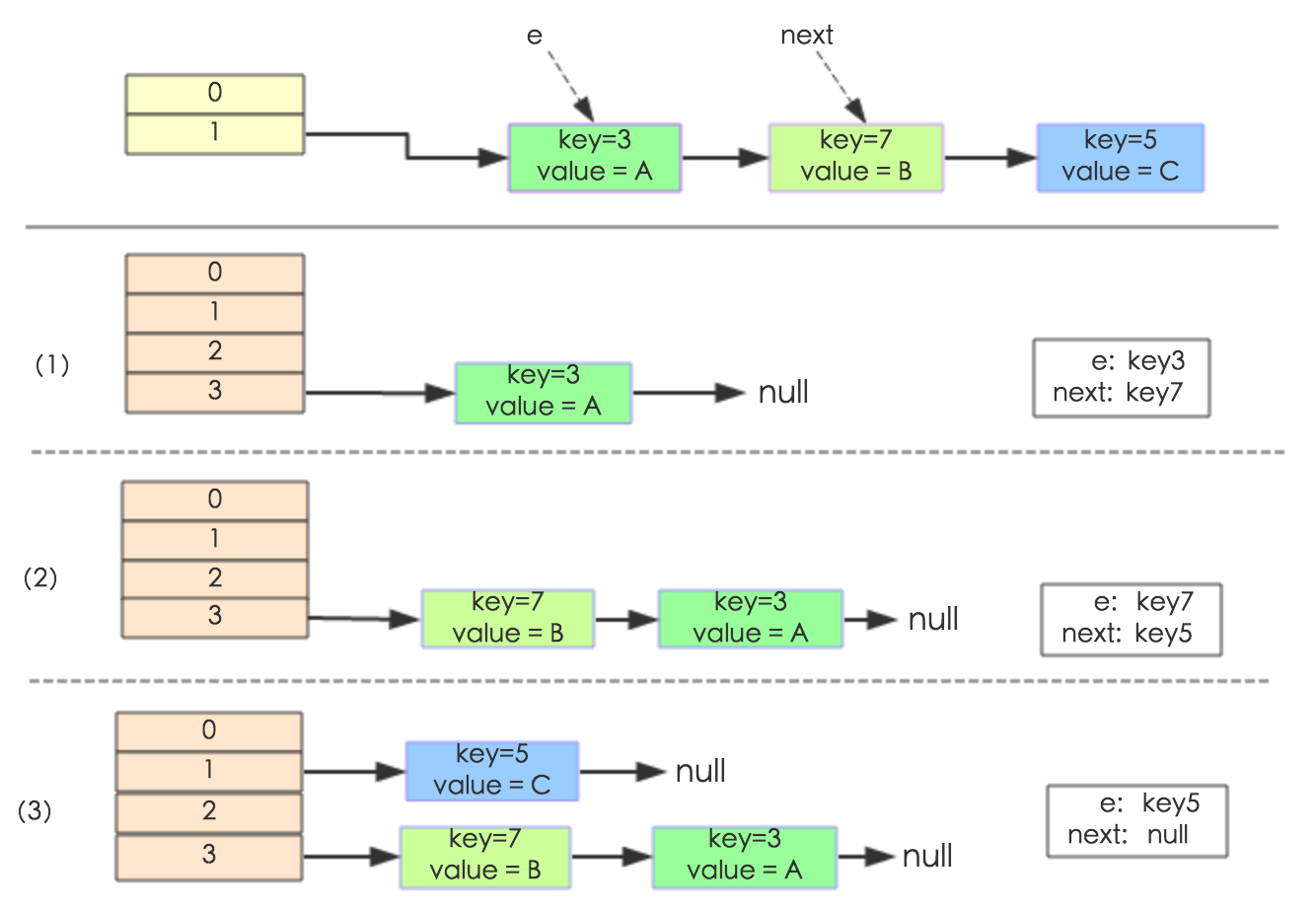
下面举个例子说明下扩容过程。假设了我们的hash算法就是简单的用key mod 一下表的大小(也就是数组的长度)。其中的哈希桶数组table的size=2, 所以key = 3、7、5,put顺序依次为 5、7、3。在mod 2以后都冲突在table[1]这里了。这里假设负载因子 loadFactor=1,即当键值对的实际大小size 大于 table的实际大小时进行扩容。接下来的三个步骤是哈希桶数组 resize成4,然后所有的Node重新rehash的过程。
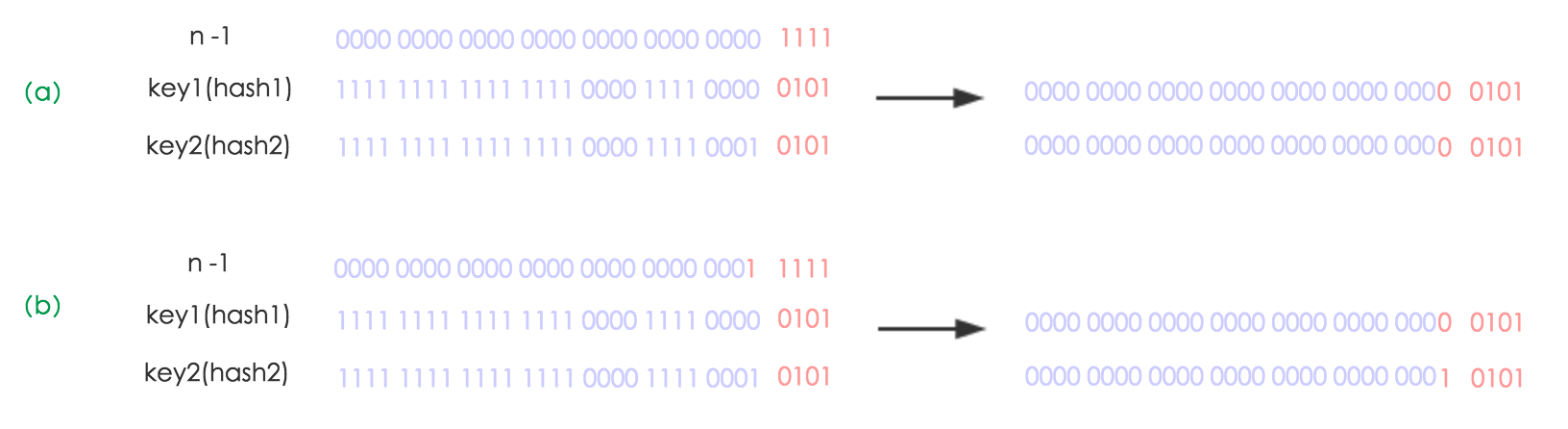
下面我们讲解下JDK1.8做了哪些优化。经过观测可以发现,我们使用的是2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。看下图可以明白这句话的意思,n为table的长度,图(a)表示扩容前的key1和key2两种key确定索引位置的示例,图(b)表示扩容后key1和key2两种key确定索引位置的示例,其中hash1是key1对应的哈希与高位运算结果。
元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:
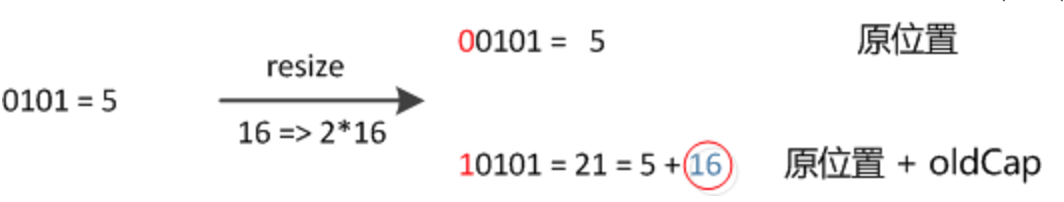
因此,我们在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”,可以看看下图为16扩充为32的resize示意图:
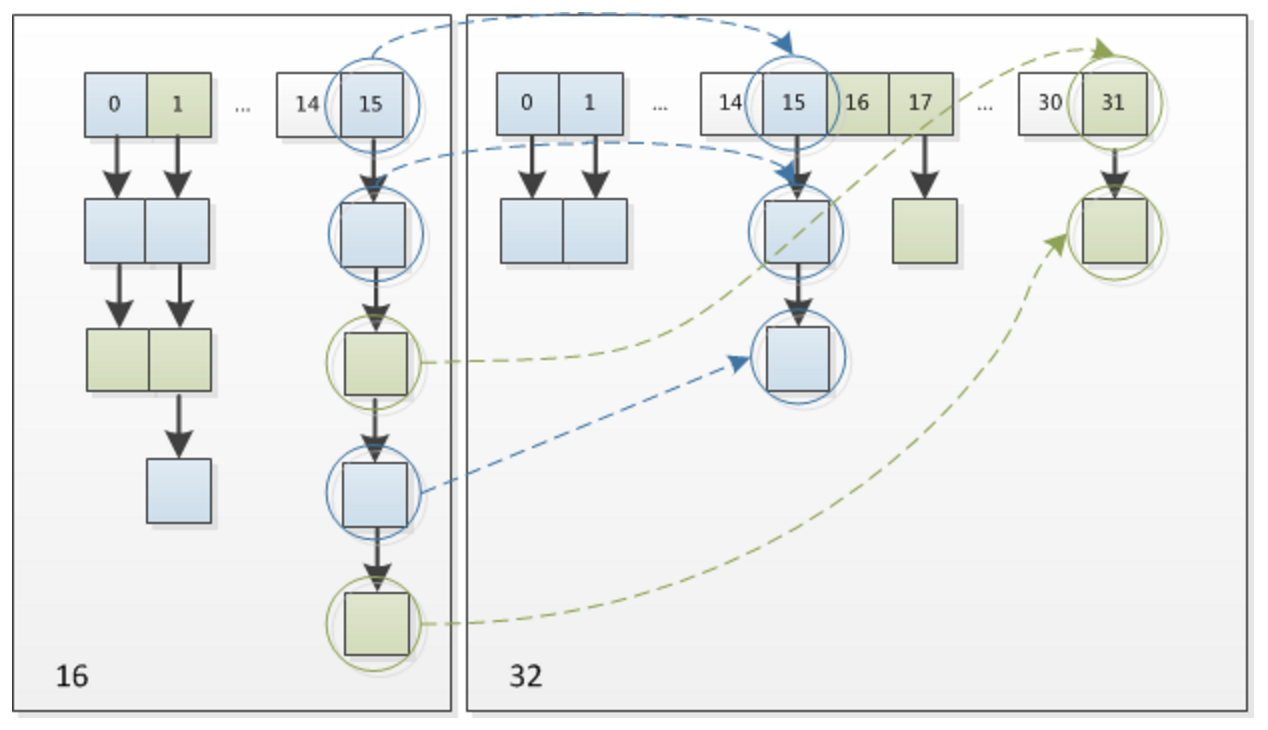
这个设计确实非常的巧妙,既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。这一块就是JDK1.8新增的优化点。有一点注意区别,JDK1.7中rehash的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置,但是从上图可以看出,JDK1.8不会倒置。有兴趣的同学可以研究下JDK1.8的resize源码,写的很赞,如下:
1 final Node<K,V>[] resize() {2 Node<K,V>[] oldTab = table;3 int oldCap = (oldTab == null) ? 0 : oldTab.length;4 int oldThr = threshold;5 int newCap, newThr = 0;6 if (oldCap > 0) {7 // 超过最大值就不再扩充了,就只好随你碰撞去吧8 if (oldCap >= MAXIMUM_CAPACITY) {9 threshold = Integer.MAX_VALUE;
10 return oldTab;
11 }
12 // 没超过最大值,就扩充为原来的2倍
13 else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
14 oldCap >= DEFAULT_INITIAL_CAPACITY)
15 newThr = oldThr << 1; // double threshold
16 }
17 else if (oldThr > 0) // initial capacity was placed in threshold
18 newCap = oldThr;
19 else { // zero initial threshold signifies using defaults
20 newCap = DEFAULT_INITIAL_CAPACITY;
21 newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
22 }
23 // 计算新的resize上限
24 if (newThr == 0) {
25
26 float ft = (float)newCap * loadFactor;
27 newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
28 (int)ft : Integer.MAX_VALUE);
29 }
30 threshold = newThr;
31 @SuppressWarnings({"rawtypes","unchecked"})
32 Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
33 table = newTab;
34 if (oldTab != null) {
35 // 把每个bucket都移动到新的buckets中
36 for (int j = 0; j < oldCap; ++j) {
37 Node<K,V> e;
38 if ((e = oldTab[j]) != null) {
39 oldTab[j] = null;
40 if (e.next == null)
41 newTab[e.hash & (newCap - 1)] = e;
42 else if (e instanceof TreeNode)
43 ((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
44 else { // 链表优化重hash的代码块
45 Node<K,V> loHead = null, loTail = null;
46 Node<K,V> hiHead = null, hiTail = null;
47 Node<K,V> next;
48 do {
49 next = e.next;
50 // 原索引
51 if ((e.hash & oldCap) == 0) {
52 if (loTail == null)
53 loHead = e;
54 else
55 loTail.next = e;
56 loTail = e;
57 }
58 // 原索引+oldCap
59 else {
60 if (hiTail == null)
61 hiHead = e;
62 else
63 hiTail.next = e;
64 hiTail = e;
65 }
66 } while ((e = next) != null);
67 // 原索引放到bucket里
68 if (loTail != null) {
69 loTail.next = null;
70 newTab[j] = loHead;
71 }
72 // 原索引+oldCap放到bucket里
73 if (hiTail != null) {
74 hiTail.next = null;
75 newTab[j + oldCap] = hiHead;
76 }
77 }
78 }
79 }
80 }
81 return newTab;
82 }
线程安全性
在多线程使用场景中,应该尽量避免使用线程不安全的HashMap,而使用线程安全的ConcurrentHashMap。那么为什么说HashMap是线程不安全的,下面举例子说明在并发的多线程使用场景中使用HashMap可能造成死循环。代码例子如下(便于理解,仍然使用JDK1.7的环境):
public class HashMapInfiniteLoop { private static HashMap<Integer,String> map = new HashMap<Integer,String>(2,0.75f); public static void main(String[] args) { map.put(5, "C"); new Thread("Thread1") { public void run() { map.put(7, "B"); System.out.println(map); }; }.start(); new Thread("Thread2") { public void run() { map.put(3, "A); System.out.println(map); }; }.start(); }
}
其中,map初始化为一个长度为2的数组,loadFactor=0.75,threshold=2*0.75=1,也就是说当put第二个key的时候,map就需要进行resize。
通过设置断点让线程1和线程2同时debug到transfer方法(3.3小节代码块)的首行。注意此时两个线程已经成功添加数据。放开thread1的断点至transfer方法的“Entry next = e.next;” 这一行;然后放开线程2的的断点,让线程2进行resize。结果如下图。
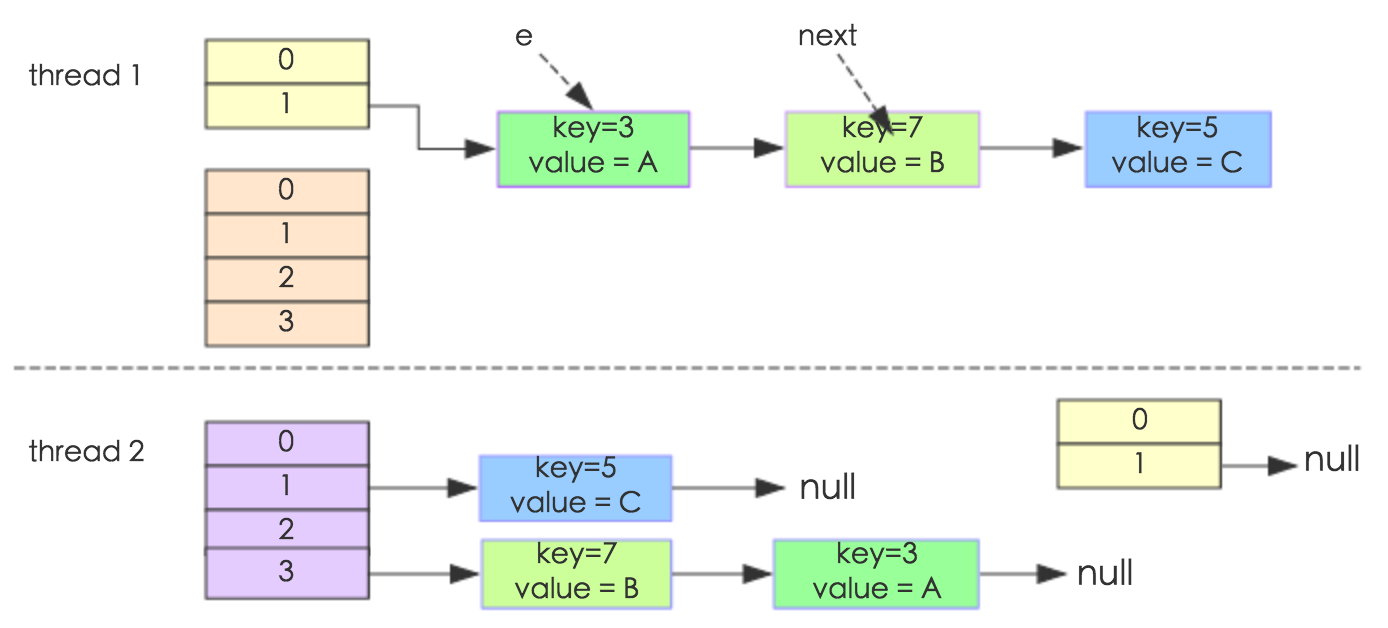
注意,Thread1的 e 指向了key(3),而next指向了key(7),其在线程二rehash后,指向了线程二重组后的链表。
线程一被调度回来执行,先是执行 newTalbe[i] = e, 然后是e = next,导致了e指向了key(7),而下一次循环的next = e.next导致了next指向了key(3)。
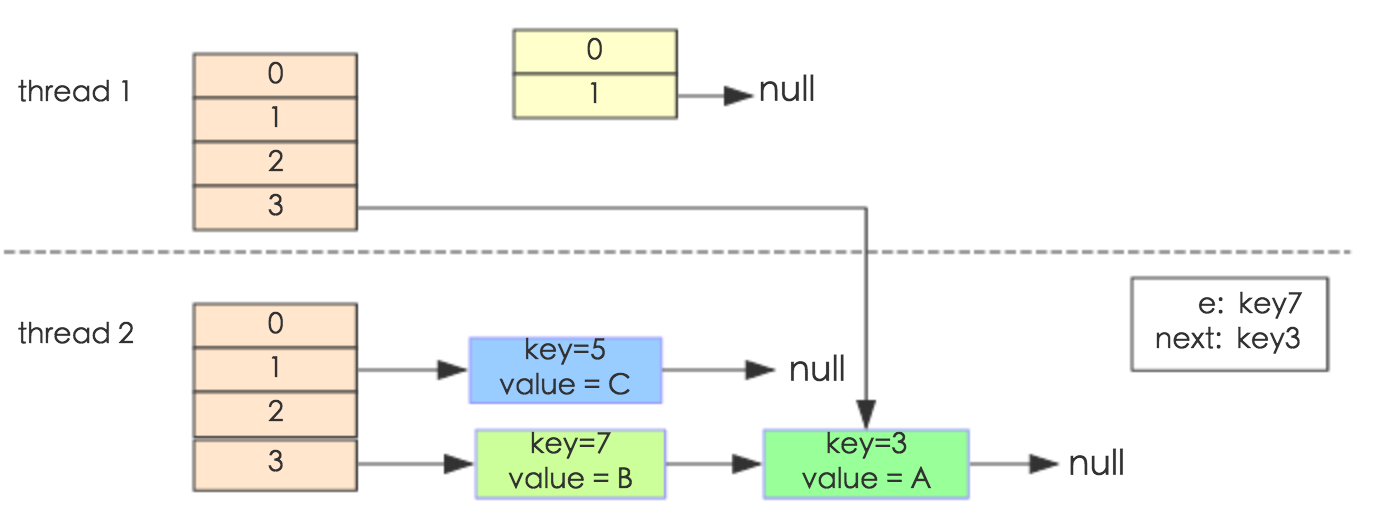
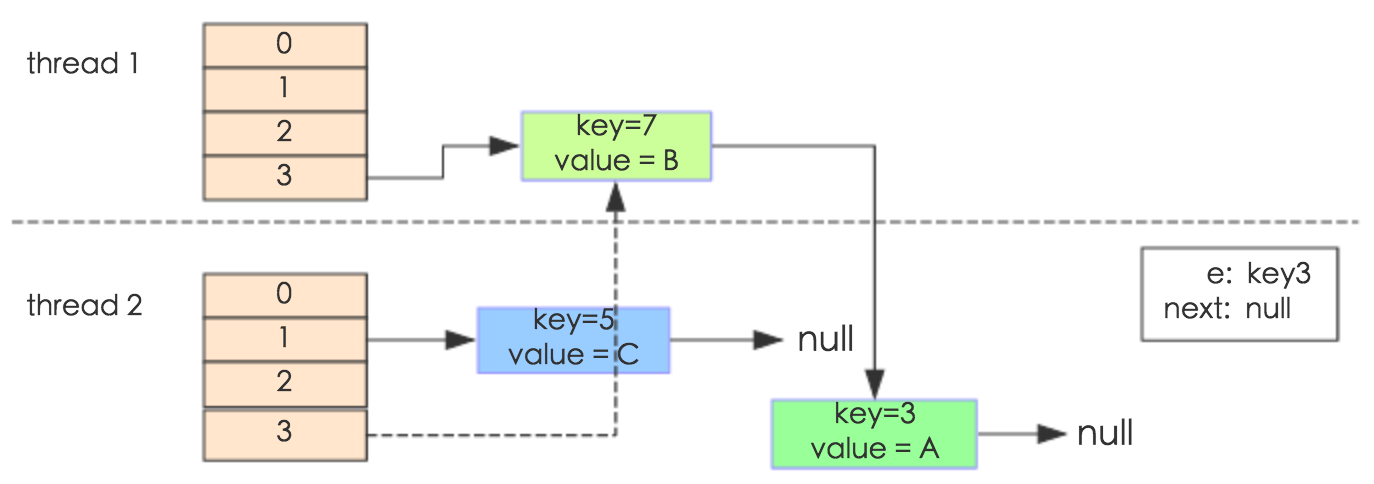
e.next = newTable[i] 导致 key(3).next 指向了 key(7)。注意:此时的key(7).next 已经指向了key(3), 环形链表就这样出现了。
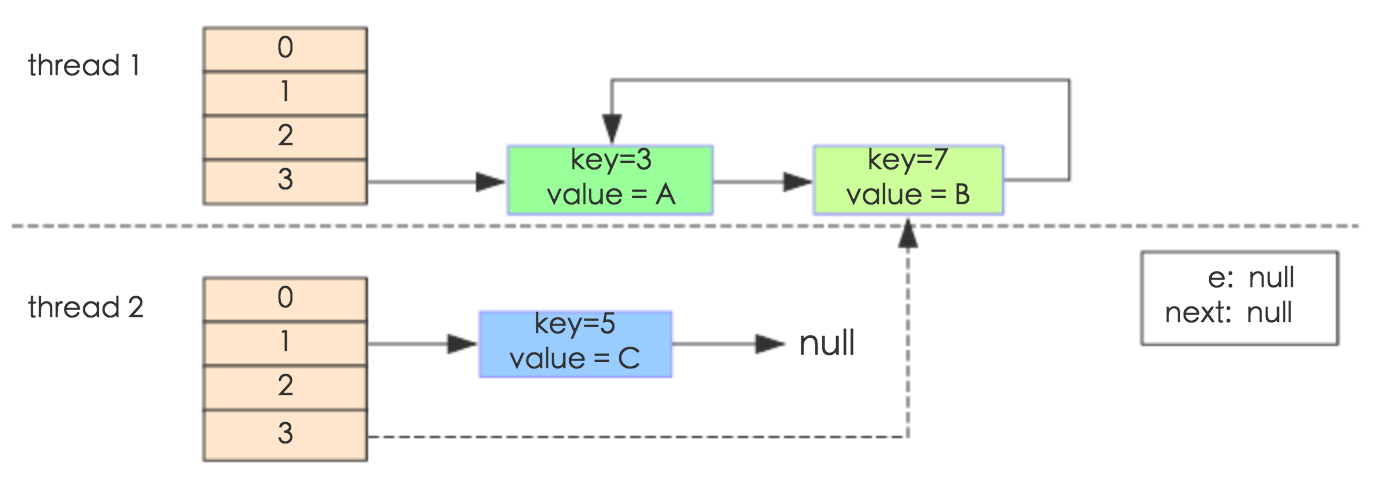
于是,当我们用线程一调用map.get(11)时,悲剧就出现了——Infinite Loop。
JDK1.8与JDK1.7的性能对比
HashMap中,如果key经过hash算法得出的数组索引位置全部不相同,即Hash算法非常好,那样的话,getKey方法的时间复杂度就是O(1),如果Hash算法技术的结果碰撞非常多,假如Hash算极其差,所有的Hash算法结果得出的索引位置一样,那样所有的键值对都集中到一个桶中,或者在一个链表中,或者在一个红黑树中,时间复杂度分别为O(n)和O(lgn)。 鉴于JDK1.8做了多方面的优化,总体性能优于JDK1.7,下面我们从两个方面用例子证明这一点。
Hash较均匀的情况
为了便于测试,我们先写一个类Key,如下:
class Key implements Comparable<Key> {private final int value;Key(int value) {this.value = value;}@Overridepublic int compareTo(Key o) {return Integer.compare(this.value, o.value);}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass())return false;Key key = (Key) o;return value == key.value;}@Overridepublic int hashCode() {return value;}
}
这个类复写了equals方法,并且提供了相当好的hashCode函数,任何一个值的hashCode都不会相同,因为直接使用value当做hashcode。为了避免频繁的GC,我将不变的Key实例缓存了起来,而不是一遍一遍的创建它们。代码如下:
public class Keys {public static final int MAX_KEY = 10_000_000;private static final Key[] KEYS_CACHE = new Key[MAX_KEY];static {for (int i = 0; i < MAX_KEY; ++i) {KEYS_CACHE[i] = new Key(i);}}public static Key of(int value) {return KEYS_CACHE[value];}
}
现在开始我们的试验,测试需要做的仅仅是,创建不同size的HashMap(1、10、100、......10000000),屏蔽了扩容的情况,代码如下:
static void test(int mapSize) {HashMap<Key, Integer> map = new HashMap<Key,Integer>(mapSize);for (int i = 0; i < mapSize; ++i) {map.put(Keys.of(i), i);}long beginTime = System.nanoTime(); //获取纳秒for (int i = 0; i < mapSize; i++) {map.get(Keys.of(i));}long endTime = System.nanoTime();System.out.println(endTime - beginTime);}public static void main(String[] args) {for(int i=10;i<= 1000 0000;i*= 10){test(i);}}
在测试中会查找不同的值,然后度量花费的时间,为了计算getKey的平均时间,我们遍历所有的get方法,计算总的时间,除以key的数量,计算一个平均值,主要用来比较,绝对值可能会受很多环境因素的影响。结果如下:

通过观测测试结果可知,JDK1.8的性能要高于JDK1.7 15%以上,在某些size的区域上,甚至高于100%。由于Hash算法较均匀,JDK1.8引入的红黑树效果不明显,下面我们看看Hash不均匀的的情况。
Hash极不均匀的情况
假设我们又一个非常差的Key,它们所有的实例都返回相同的hashCode值。这是使用HashMap最坏的情况。代码修改如下:
class Key implements Comparable<Key> {//...@Overridepublic int hashCode() {return 1;}
}
仍然执行main方法,得出的结果如下表所示:

从表中结果中可知,随着size的变大,JDK1.7的花费时间是增长的趋势,而JDK1.8是明显的降低趋势,并且呈现对数增长稳定。当一个链表太长的时候,HashMap会动态的将它替换成一个红黑树,这话的话会将时间复杂度从O(n)降为O(logn)。hash算法均匀和不均匀所花费的时间明显也不相同,这两种情况的相对比较,可以说明一个好的hash算法的重要性。
测试环境:处理器为2.2 GHz Intel Core i7,内存为16 GB 1600 MHz DDR3,SSD硬盘,使用默认的JVM参数,运行在64位的OS X 10.10.1上。
小结
(1) 扩容是一个特别耗性能的操作,所以当程序员在使用HashMap的时候,估算map的大小,初始化的时候给一个大致的数值,避免map进行频繁的扩容。
(2) 负载因子是可以修改的,也可以大于1,但是建议不要轻易修改,除非情况非常特殊。
(3) HashMap是线程不安全的,不要在并发的环境中同时操作HashMap,建议使用ConcurrentHashMap。
(4) JDK1.8引入红黑树大程度优化了HashMap的性能。
(5) 还没升级JDK1.8的,现在开始升级吧。HashMap的性能提升仅仅是JDK1.8的冰山一角。
---------------------------------------------------------------------------
ThreadLocal
源码分析
为了解释ThreadLocal类的工作原理,必须同时介绍与其工作甚密的其他几个类
- ThreadLocalMap(内部类)
- Thread
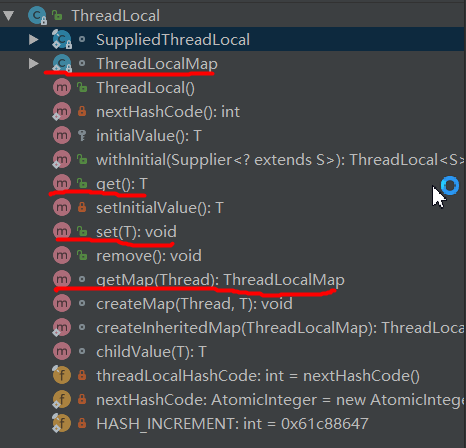
首先,在Thread类中有一行:
/* ThreadLocal values pertaining to this thread. This map is maintained by the ThreadLocal class. */ThreadLocal.ThreadLocalMap threadLocals = null;其中ThreadLocalMap类的定义是在ThreadLocal类中,真正的引用却是在Thread类中。同时,ThreadLocalMap中用于存储数据的entry定义:
static class Entry extends WeakReference<ThreadLocal<?>> {/** The value associated with this ThreadLocal. */Object value;Entry(ThreadLocal<?> k, Object v) {super(k);value = v;}}从中我们可以发现这个Map的key是ThreadLocal类的实例对象,value为用户的值,并不是网上大多数的例子key是线程的名字或者标识。ThreadLocal的set和get方法代码:
public void set(T value) {Thread t = Thread.currentThread();ThreadLocalMap map = getMap(t);if (map != null)map.set(this, value);elsecreateMap(t, value);}public T get() {Thread t = Thread.currentThread();ThreadLocalMap map = getMap(t);if (map != null) {ThreadLocalMap.Entry e = map.getEntry(this);if (e != null) {@SuppressWarnings("unchecked")T result = (T)e.value;return result;}}return setInitialValue();}其中的getMap方法:
ThreadLocalMap getMap(Thread t) {return t.threadLocals;}给当前Thread类对象初始化ThreadlocalMap属性:
void createMap(Thread t, T firstValue) {t.threadLocals = new ThreadLocalMap(this, firstValue);}到这里,我们就可以理解ThreadLocal究竟是如何工作的了
- Thread类中有一个成员变量属于ThreadLocalMap类(一个定义在ThreadLocal类中的内部类),它是一个Map,他的key是ThreadLocal实例对象。
- 当为ThreadLocal类的对象set值时,首先获得当前线程的ThreadLocalMap类属性,然后以ThreadLocal类的对象为key,设定value。get值时则类似。
- ThreadLocal变量的活动范围为某线程,是该线程“专有的,独自霸占”的,对该变量的所有操作均由该线程完成!也就是说,ThreadLocal 不是用来解决共享对象的多线程访问的竞争问题的,因为ThreadLocal.set() 到线程中的对象是该线程自己使用的对象,其他线程是不需要访问的,也访问不到的。当线程终止后,这些值会作为垃圾回收。
由ThreadLocal的工作原理决定了:每个线程独自拥有一个变量,并非是共享的,下面给出一个例子:
public class Son implements Cloneable{ public static void main(String[] args){Son p=new Son();System.out.println(p);Thread t = new Thread(new Runnable(){ public void run(){ThreadLocal<Son> threadLocal = new ThreadLocal<>();System.out.println(threadLocal);threadLocal.set(p);System.out.println(threadLocal.get());threadLocal.remove();try {threadLocal.set((Son) p.clone());System.out.println(threadLocal.get());} catch (CloneNotSupportedException e) {e.printStackTrace();}System.out.println(threadLocal);}}); t.start(); } }输出:
Son@7852e922 java.lang.ThreadLocal@3ffc8195 Son@7852e922 Son@313b781a java.lang.ThreadLocal@3ffc8195也就是如果把一个共享的对象直接保存到ThreadLocal中,那么多个线程的ThreadLocal.get()取得的还是这个共享对象本身,还是有并发访问问题。 所以要在保存到ThreadLocal之前,通过克隆或者new来创建新的对象,然后再进行保存。
ThreadLocal的作用是提供线程内的局部变量,这种变量在线程的生命周期内起作用。作用:提供一个线程内公共变量(比如本次请求的用户信息),减少同一个线程内多个函数或者组件之间一些公共变量的传递的复杂度,或者为线程提供一个私有的变量副本,这样每一个线程都可以随意修改自己的变量副本,而不会对其他线程产生影响。
如何实现一个线程多个ThreadLocal对象,每一个ThreadLocal对象是如何区分的呢?
查看源码,可以看到:
private final int threadLocalHashCode = nextHashCode();
private static AtomicInteger nextHashCode = new AtomicInteger();
private static final int HASH_INCREMENT = 0x61c88647;
private static int nextHashCode() {return nextHashCode.getAndAdd(HASH_INCREMENT);
} 对于每一个ThreadLocal对象,都有一个final修饰的int型的threadLocalHashCode不可变属性,对于基本数据类型,可以认为它在初始化后就不可以进行修改,所以可以唯一确定一个ThreadLocal对象。
但是如何保证两个同时实例化的ThreadLocal对象有不同的threadLocalHashCode属性:在ThreadLocal类中,还包含了一个static修饰的AtomicInteger([əˈtɒmɪk]提供原子操作的Integer类)成员变量(即类变量)和一个static final修饰的常量(作为两个相邻nextHashCode的差值)。由于nextHashCode是类变量,所以每一次调用ThreadLocal类都可以保证nextHashCode被更新到新的值,并且下一次调用ThreadLocal类这个被更新的值仍然可用,同时AtomicInteger保证了nextHashCode自增的原子性。
为什么不直接用线程id来作为ThreadLocalMap的key?
这一点很容易理解,因为直接用线程id来作为ThreadLocalMap的key,无法区分放入ThreadLocalMap中的多个value。比如我们放入了两个字符串,你如何知道我要取出来的是哪一个字符串呢?
而使用ThreadLocal作为key就不一样了,由于每一个ThreadLocal对象都可以由threadLocalHashCode属性唯一区分或者说每一个ThreadLocal对象都可以由这个对象的名字唯一区分(下面的例子),所以可以用不同的ThreadLocal作为key,区分不同的value,方便存取。
public class Son implements Cloneable{public static void main(String[] args){Thread t = new Thread(new Runnable(){ public void run(){ThreadLocal<Son> threadLocal1 = new ThreadLocal<>();threadLocal1.set(new Son());System.out.println(threadLocal1.get());ThreadLocal<Son> threadLocal2 = new ThreadLocal<>();threadLocal2.set(new Son());System.out.println(threadLocal2.get());}}); t.start();}
}ThreadLocal的内存泄露问题
根据上面Entry方法的源码,我们知道ThreadLocalMap是使用ThreadLocal的弱引用作为Key的。下图是本文介绍到的一些对象之间的引用关系图,实线表示强引用,虚线表示弱引用:
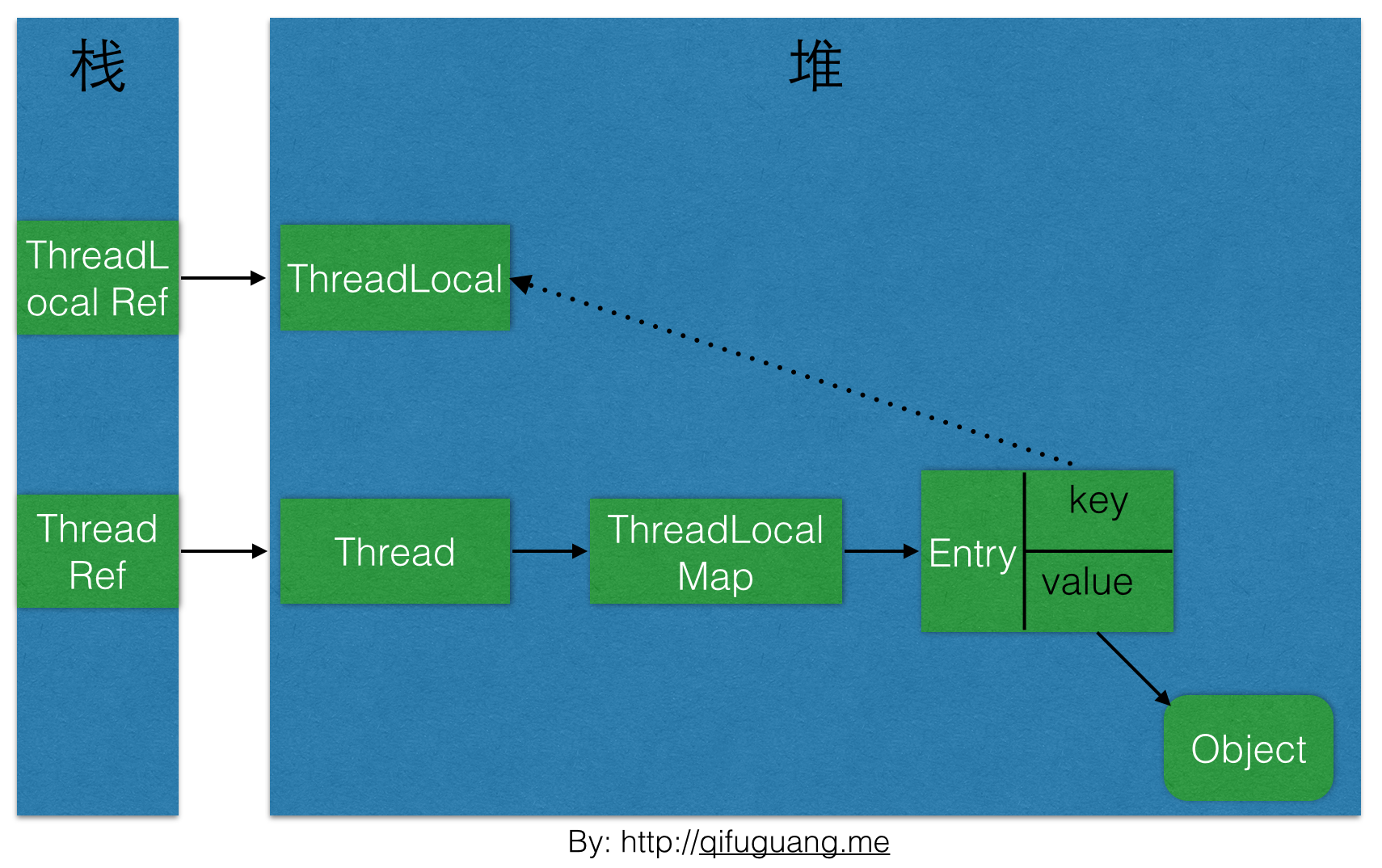
如上图,ThreadLocalMap使用ThreadLocal的弱引用作为key,如果一个ThreadLocal没有外部强引用引用他,那么系统gc的时候,这个ThreadLocal势必会被回收,这样一来,ThreadLocalMap中就会出现key为null的Entry,就没有办法访问这些key为null的Entry的value,如果当前线程再迟迟不结束的话,这些key为null的Entry的value就会一直存在一条强引用链:
Thread Ref -> Thread -> ThreaLocalMap -> Entry -> value
永远无法回收,造成内存泄露。
ThreadLocalMap设计时的对上面问题的对策:
ThreadLocalMap的getEntry函数的流程大概为:
- 首先从ThreadLocal的直接索引位置(通过ThreadLocal.threadLocalHashCode & (table.length-1)运算得到)获取Entry e,如果e不为null并且key相同则返回e;
- 如果e为null或者key不一致则向下一个位置查询,如果下一个位置的key和当前需要查询的key相等,则返回对应的Entry。否则,如果key值为null,则擦除该位置的Entry,并继续向下一个位置查询。在这个过程中遇到的key为null的Entry都会被擦除,那么Entry内的value也就没有强引用链,自然会被回收。仔细研究代码可以发现,set操作也有类似的思想,将key为null的这些Entry都删除,防止内存泄露。
但是光这样还是不够的,上面的设计思路依赖一个前提条件:要调用ThreadLocalMap的getEntry函数或者set函数。这当然是不可能任何情况都成立的,所以很多情况下需要使用者手动调用ThreadLocal的remove函数,手动删除不再需要的ThreadLocal,防止内存泄露。所以JDK建议将ThreadLocal变量定义成private static的,这样的话ThreadLocal的生命周期就更长,由于一直存在ThreadLocal的强引用,所以ThreadLocal也就不会被回收,也就能保证任何时候都能根据ThreadLocal的弱引用访问到Entry的value值,然后remove它,防止内存泄露。
关于ThreadLocalMap内部类的简单介绍
初始容量16,负载因子2/3,解决冲突的方法是再hash法,也就是:在当前hash的基础上再自增一个常量。
ThreadLocal应用场景
1、数据库连接池实现
jdbc连接数据库,如下所示:
Class.forName("com.mysql.jdbc.Driver");
java.sql.Connection conn = DriverManager.getConnection(jdbcUrl);- 注意:一次Drivermanager.getConnection(jdbcurl)获得只是一个connection,并不能满足高并发情况。因为connection不是线程安全的,一个connection对应的是一个事物。
每次获得connection都需要浪费cpu资源和内存资源,是很浪费资源的。所以诞生了数据库连接池。数据库连接池实现原理如下:
pool.getConnection(),都是先从threadlocal里面拿的,如果threadlocal里面有,则用,保证线程里的多个dao操作,用的是同一个connection,以保证事务。如果新线程,则将新的connection放在threadlocal里,再get给到线程。
将connection放进threadlocal里的,以保证每个线程从连接池中获得的都是线程自己的connection。
Hibernate的数据库连接池源码实现:
public class ConnectionPool implements IConnectionPool { // 连接池配置属性 private DBbean dbBean; private boolean isActive = false; // 连接池活动状态 private int contActive = 0;// 记录创建的总的连接数 // 空闲连接 private List<Connection> freeConnection = new Vector<Connection>(); // 活动连接 private List<Connection> activeConnection = new Vector<Connection>(); // 将线程和连接绑定,保证事务能统一执行private static ThreadLocal<Connection> threadLocal = new ThreadLocal<Connection>(); public ConnectionPool(DBbean dbBean) { super(); this.dbBean = dbBean; init(); cheackPool(); } // 初始化 public void init() { try { Class.forName(dbBean.getDriverName()); for (int i = 0; i < dbBean.getInitConnections(); i++) { Connection conn; conn = newConnection(); // 初始化最小连接数 if (conn != null) { freeConnection.add(conn); contActive++; } } isActive = true; } catch (ClassNotFoundException e) { e.printStackTrace(); } catch (SQLException e) { e.printStackTrace(); } } // 获得当前连接 public Connection getCurrentConnecton(){ // 默认线程里面取 Connection conn = threadLocal.get(); if(!isValid(conn)){ conn = getConnection(); } return conn; } // 获得连接 public synchronized Connection getConnection() { Connection conn = null; try { // 判断是否超过最大连接数限制 if(contActive < this.dbBean.getMaxActiveConnections()){ if (freeConnection.size() > 0) { conn = freeConnection.get(0); if (conn != null) { threadLocal.set(conn); } freeConnection.remove(0); } else { conn = newConnection(); } }else{ // 继续获得连接,直到从新获得连接 wait(this.dbBean.getConnTimeOut()); conn = getConnection(); } if (isValid(conn)) { activeConnection.add(conn); contActive ++; } } catch (SQLException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } return conn; } // 获得新连接 private synchronized Connection newConnection() throws ClassNotFoundException, SQLException { Connection conn = null; if (dbBean != null) { Class.forName(dbBean.getDriverName()); conn = DriverManager.getConnection(dbBean.getUrl(), dbBean.getUserName(), dbBean.getPassword()); } return conn; } // 释放连接 public synchronized void releaseConn(Connection conn) throws SQLException { if (isValid(conn)&& !(freeConnection.size() > dbBean.getMaxConnections())) { freeConnection.add(conn); activeConnection.remove(conn); contActive --; threadLocal.remove(); // 唤醒所有正待等待的线程,去抢连接 notifyAll(); } } // 判断连接是否可用 private boolean isValid(Connection conn) { try { if (conn == null || conn.isClosed()) { return false; } } catch (SQLException e) { e.printStackTrace(); } return true; } // 销毁连接池 public synchronized void destroy() { for (Connection conn : freeConnection) { try { if (isValid(conn)) { conn.close(); } } catch (SQLException e) { e.printStackTrace(); } } for (Connection conn : activeConnection) { try { if (isValid(conn)) { conn.close(); } } catch (SQLException e) { e.printStackTrace(); } } isActive = false; contActive = 0; } // 连接池状态 @Override public boolean isActive() { return isActive; } // 定时检查连接池情况 @Override public void cheackPool() { if(dbBean.isCheakPool()){ new Timer().schedule(new TimerTask() { @Override public void run() { // 1.对线程里面的连接状态 // 2.连接池最小 最大连接数 // 3.其他状态进行检查,因为这里还需要写几个线程管理的类,暂时就不添加了 System.out.println("空线池连接数:"+freeConnection.size()); System.out.println("活动连接数::"+activeConnection.size()); System.out.println("总的连接数:"+contActive); } },dbBean.getLazyCheck(),dbBean.getPeriodCheck()); } }
} 2、有时候ThreadLocal也可以用来避免一些参数传递,通过ThreadLocal来访问对象。
比如一个方法调用另一个方法时传入了8个参数,通过逐层调用到第N个方法,传入了其中一个参数,此时最后一个方法需要增加一个参数,第一个方法变成9个参数是自然的,但是这个时候,相关的方法都会受到牵连,使得代码变得臃肿不堪。这时候就可以将要添加的参数设置成线程本地变量,来避免参数传递。
上面提到的是ThreadLocal一种亡羊补牢的用途,不过也不是特别推荐使用的方式,它还有一些类似的方式用来使用,就是在框架级别有很多动态调用,调用过程中需要满足一些协议,虽然协议我们会尽量的通用,而很多扩展的参数在定义协议时是不容易考虑完全的以及版本也是随时在升级的,但是在框架扩展时也需要满足接口的通用性和向下兼容,而一些扩展的内容我们就需要ThreadLocal来做方便简单的支持。
简单来说,ThreadLocal是将一些复杂的系统扩展变成了简单定义,使得相关参数牵连的部分变得非常容易。
3、在某些情况下提升性能和安全。
用SimpleDateFormat这个对象,进行日期格式化。因为创建这个对象本身很费时的,而且我们也知道SimpleDateFormat本身不是线程安全的,也不能缓存一个共享的SimpleDateFormat实例,为此我们想到使用ThreadLocal来给每个线程缓存一个SimpleDateFormat实例,提高性能。同时因为每个Servlet会用到不同pattern的时间格式化类,所以我们对应每一种pattern生成了一个ThreadLocal实例。
public interface DateTimeFormat {String DATE_PATTERN = "yyyy-MM-dd";ThreadLocal<DateFormat> DATE_FORMAT = ThreadLocal.withInitial(() -> {return new SimpleDateFormat("yyyy-MM-dd");});String TIME_PATTERN = "HH:mm:ss";ThreadLocal<DateFormat> TIME_FORMAT = ThreadLocal.withInitial(() -> {return new SimpleDateFormat("HH:mm:ss");});String DATETIME_PATTERN = "yyyy-MM-dd HH:mm:ss";ThreadLocal<DateFormat> DATE_TIME_FORMAT = ThreadLocal.withInitial(() -> {return new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");});}为什么SimpleDateFormat不安全,可以参考此篇博文:
SimpleDateFormat线程不安全及解决办法
假如我们把SimpleDateFormat定义成static成员变量,那么多个thread之间会共享这个sdf对象, 所以Calendar对象也会共享。
假定线程A和线程B都进入了parse(text, pos) 方法, 线程B执行到calendar.clear()后,线程A执行到calendar.getTime(), 那么就会有问题。
如果不用static修饰,将SimpleDateFormat定义成局部变量:
每调用一次方法就会创建一个SimpleDateFormat对象,方法结束又要作为垃圾回收。加锁性能较差,每次都要等待锁释放后其他线程才能进入。那么最好的办法就是:使用ThreadLocal: 每个线程都将拥有自己的SimpleDateFormat对象副本。
附-SimpleDateFormat关键源码:
public class SimpleDateFormat extends DateFormat { public Date parse(String text, ParsePosition pos){ calendar.clear(); // Clears all the time fields // other logic ... Date parsedDate = calendar.getTime(); }
} abstract class DateFormat{ // other logic ... protected Calendar calendar; public Date parse(String source) throws ParseException{ ParsePosition pos = new ParsePosition(0); Date result = parse(source, pos); if (pos.index == 0) throw new ParseException("Unparseable date: \"" + source + "\"" , pos.errorIndex); return result; }
}---------------------------------------------------------------------------
ConcurrentHashMap
主要参考:http://www.cnblogs.com/leesf456/p/5453341.html
http://blog.csdn.net/sunyangwei1993/article/details/77001597
一、前言
最近几天忙着做点别的东西,今天终于有时间分析源码了,看源码感觉很爽,并且发现ConcurrentHashMap在JDK1.8版本与之前的版本在并发控制上存在很大的差别,很有必要进行认真的分析,下面进行源码分析。
二、ConcurrentHashMap数据结构(jdk1.8)
之前已经提及过,ConcurrentHashMap相比HashMap而言,是多线程安全的,其底层数据与HashMap的数据结构相同,数据结构如下
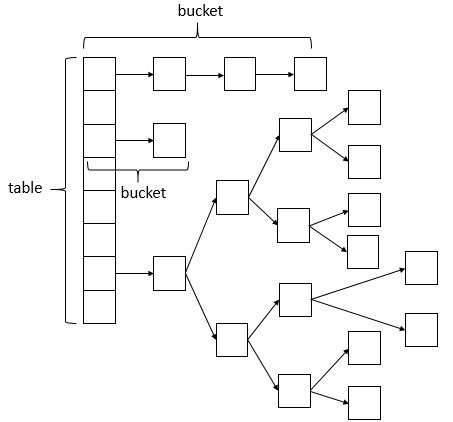
说明:ConcurrentHashMap的数据结构(数组+链表+红黑树),桶中的结构可能是链表,也可能是红黑树,红黑树是为了提高查找效率。
三、ConcurrentHashMap源码分析(jdk1.8)
3.1 类的继承关系
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>implements ConcurrentMap<K,V>, Serializable {}
说明:ConcurrentHashMap继承了AbstractMap抽象类,该抽象类定义了一些基本操作,同时,也实现了ConcurrentMap接口,ConcurrentMap接口也定义了一系列操作,实现了Serializable接口表示ConcurrentHashMap可以被序列化。
3.2 类的内部类
ConcurrentHashMap包含了很多内部类,其中主要的内部类框架图如下图所示
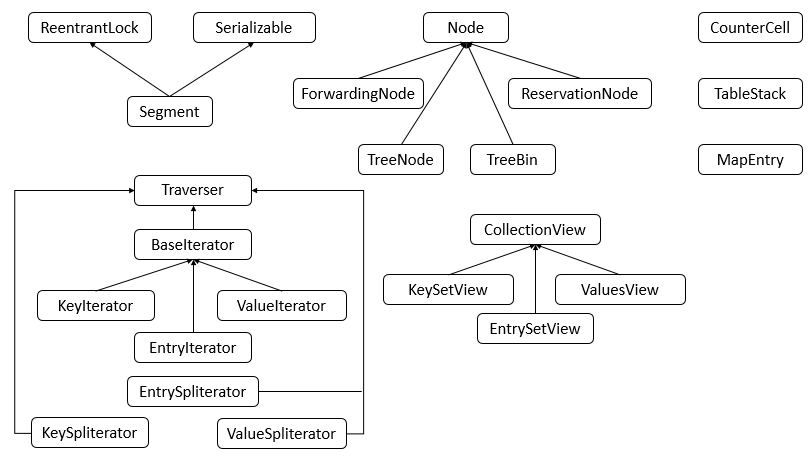
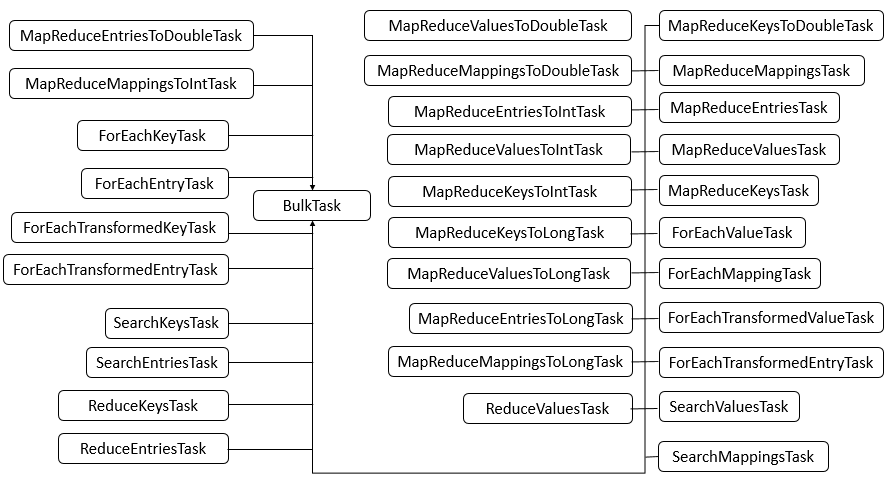
说明:可以看到,ConcurrentHashMap的内部类非常的庞大,第二个图是在JDK1.8下增加的类。
下面对主要的内部类进行分析和讲解。
1. Node类
Node类主要用于存储具体键值对,其子类有ForwardingNode、ReservationNode、TreeNode和TreeBin四个子类。四个子类具体的代码在之后的具体例子中进行分析讲解。
2. Traverser类
Traverser类主要用于遍历操作,其子类有BaseIterator、KeySpliterator、ValueSpliterator、EntrySpliterator四个类,BaseIterator用于遍历操作。KeySplitertor、ValueSpliterator、EntrySpliterator则用于键、值、键值对的划分。
3. CollectionView类
CollectionView抽象类主要定义了视图操作,其子类KeySetView、ValueSetView、EntrySetView分别表示键视图、值视图、键值对视图。对视图均可以进行操作。
4. Segment类
Segment类在JDK1.8中与之前的版本的JDK作用存在很大的差别,JDK1.8下,其在普通的ConcurrentHashMap操作中已经没有失效,其在序列化与反序列化的时候会发挥作用。
5. CounterCell
CounterCell类主要用于对baseCount的计数。
3.3 类的属性
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>implements ConcurrentMap<K,V>, Serializable {private static final long serialVersionUID = 7249069246763182397L;
// 表的最大容量private static final int MAXIMUM_CAPACITY = 1 << 30;// 默认表的大小private static final int DEFAULT_CAPACITY = 16;// 最大数组大小static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;// 默认并发数private static final int DEFAULT_CONCURRENCY_LEVEL = 16;// 装载因子private static final float LOAD_FACTOR = 0.75f;// 转化为红黑树的阈值static final int TREEIFY_THRESHOLD = 8;// 由红黑树转化为链表的阈值static final int UNTREEIFY_THRESHOLD = 6;// 转化为红黑树的表的最小容量static final int MIN_TREEIFY_CAPACITY = 64;// 每次进行转移的最小值private static final int MIN_TRANSFER_STRIDE = 16;// 生成sizeCtl所使用的bit位数private static int RESIZE_STAMP_BITS = 16;// 进行扩容所允许的最大线程数private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1;// 记录sizeCtl中的大小所需要进行的偏移位数private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS; // 一系列的标识static final int MOVED = -1; // hash for forwarding nodesstatic final int TREEBIN = -2; // hash for roots of treesstatic final int RESERVED = -3; // hash for transient reservationsstatic final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash// /** Number of CPUS, to place bounds on some sizings */// 获取可用的CPU个数static final int NCPU = Runtime.getRuntime().availableProcessors();// /** For serialization compatibility. */// 进行序列化的属性private static final ObjectStreamField[] serialPersistentFields = {new ObjectStreamField("segments", Segment[].class),new ObjectStreamField("segmentMask", Integer.TYPE),new ObjectStreamField("segmentShift", Integer.TYPE)};// 表transient volatile Node<K,V>[] table;// 下一个表private transient volatile Node<K,V>[] nextTable;///*** Base counter value, used mainly when there is no contention,* but also as a fallback during table initialization* races. Updated via CAS.*/// 基本计数private transient volatile long baseCount;///*** Table initialization and resizing control. When negative, the* table is being initialized or resized: -1 for initialization,* else -(1 + the number of active resizing threads). Otherwise,* when table is null, holds the initial table size to use upon* creation, or 0 for default. After initialization, holds the* next element count value upon which to resize the table.*/// 对表初始化和扩容控制private transient volatile int sizeCtl;/*** The next table index (plus one) to split while resizing.*/// 扩容下另一个表的索引private transient volatile int transferIndex;/*** Spinlock (locked via CAS) used when resizing and/or creating CounterCells.*/// 旋转锁private transient volatile int cellsBusy;/*** Table of counter cells. When non-null, size is a power of 2.*/// counterCell表private transient volatile CounterCell[] counterCells;// views// 视图private transient KeySetView<K,V> keySet;private transient ValuesView<K,V> values;private transient EntrySetView<K,V> entrySet;// Unsafe mechanicsprivate static final sun.misc.Unsafe U;private static final long SIZECTL;private static final long TRANSFERINDEX;private static final long BASECOUNT;private static final long CELLSBUSY;private static final long CELLVALUE;private static final long ABASE;private static final int ASHIFT;static {try {U = sun.misc.Unsafe.getUnsafe();Class<?> k = ConcurrentHashMap.class;SIZECTL = U.objectFieldOffset(k.getDeclaredField("sizeCtl"));TRANSFERINDEX = U.objectFieldOffset(k.getDeclaredField("transferIndex"));BASECOUNT = U.objectFieldOffset(k.getDeclaredField("baseCount"));CELLSBUSY = U.objectFieldOffset(k.getDeclaredField("cellsBusy"));Class<?> ck = CounterCell.class;CELLVALUE = U.objectFieldOffset(ck.getDeclaredField("value"));Class<?> ak = Node[].class;ABASE = U.arrayBaseOffset(ak);int scale = U.arrayIndexScale(ak);if ((scale & (scale - 1)) != 0)throw new Error("data type scale not a power of two");ASHIFT = 31 - Integer.numberOfLeadingZeros(scale);} catch (Exception e) {throw new Error(e);}}
}
说明:ConcurrentHashMap的属性很多,其中不少属性在HashMap中就已经介绍过,而对于ConcurrentHashMap而言,添加了Unsafe实例,主要用于反射获取对象相应的字段,需要注意的是
transient volatile Node<K,V>[] table;
这里Node用了transient volatile来保证
3.4 类的构造函数
1. ConcurrentHashMap()型构造函数
public ConcurrentHashMap() {}
说明:该构造函数用于创建一个带有默认初始容量 (16)、加载因子 (0.75) 和 concurrencyLevel (16) 的新的空映射。
2. ConcurrentHashMap(int)型构造函数
public ConcurrentHashMap(int initialCapacity) {if (initialCapacity < 0) // 初始容量小于0,抛出异常throw new IllegalArgumentException();int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?MAXIMUM_CAPACITY :tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1)); // 找到最接近该容量的2的幂次方数// 初始化this.sizeCtl = cap;}
说明:该构造函数用于创建一个带有指定初始容量、默认加载因子 (0.75) 和 concurrencyLevel (16) 的新的空映射。
3. ConcurrentHashMap(Map<? extends K, ? extends V>)型构造函数
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {this.sizeCtl = DEFAULT_CAPACITY;// 将集合m的元素全部放入putAll(m);}
说明:该构造函数用于构造一个与给定映射具有相同映射关系的新映射。
4. ConcurrentHashMap(int, float)型构造函数
public ConcurrentHashMap(int initialCapacity, float loadFactor) {this(initialCapacity, loadFactor, 1);}
说明:该构造函数用于创建一个带有指定初始容量、加载因子和默认 concurrencyLevel (1) 的新的空映射。
5. ConcurrentHashMap(int, float, int)型构造函数
public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0) // 合法性判断throw new IllegalArgumentException();if (initialCapacity < concurrencyLevel) // Use at least as many binsinitialCapacity = concurrencyLevel; // as estimated threadslong size = (long)(1.0 + (long)initialCapacity / loadFactor);int cap = (size >= (long)MAXIMUM_CAPACITY) ?MAXIMUM_CAPACITY : tableSizeFor((int)size);this.sizeCtl = cap;}
说明:该构造函数用于创建一个带有指定初始容量、加载因子和并发级别的新的空映射。
对于构造函数而言,会根据输入的initialCapacity的大小来确定一个最小的且大于等于initialCapacity大小的2的n次幂,如initialCapacity为15,则sizeCtl为16,若initialCapacity为16,则sizeCtl为16。若initialCapacity大小超过了允许的最大值,则sizeCtl为最大值。值得注意的是,构造函数中的concurrencyLevel参数已经在JDK1.8中的意义发生了很大的变化,其并不代表所允许的并发数,其只是用来确定sizeCtl大小,在JDK1.8中的并发控制都是针对具体的桶而言,即有多少个桶就可以允许多少个并发数。
这时候我们先来回顾一下JDK1.7中的CocurrentHashMap:
HashMap的容量由负载因子决定,插入的元素超过了容量的范围就会触发扩容操作,就是rehash。
在多线程环境下,若同时存在其他元素进行put操作,如果hash值相同,可能出现在同一数组下用链表表示,出现闭环,导致在get的操作会出现死循环,所以hashmap是线程不安全的。
Hashtable是线程安全的,它在所有都涉及到多线程操作时都加了synchronized关键字来锁住整个table,意味着所有线程都在争用一把锁,在多线程的环境下,它是安全的,但效率低下。
ConcurrentHashMap采用锁分离技术,将锁的粒度降低,利用多个锁来控制多个小的table。
ConcurrentHashMap的数据结构是由一个Segment数组和多个HashEntry组成,如下图所示:
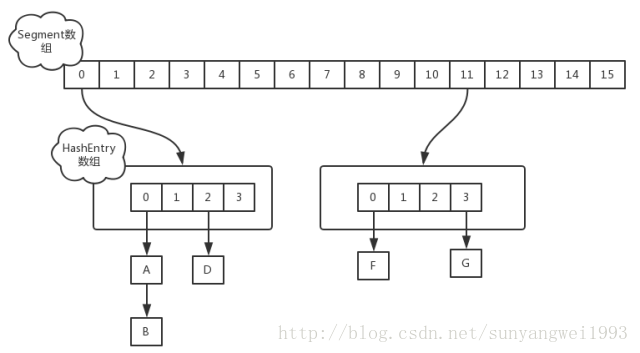
Segment数组的意义就是将一个大的table分割成多个小的table来进行加锁,也就是上面的提到的锁分离技术,而每一个Segment元素存储的是HashEntry数组+链表,这个和HashMap的数据存储结构一样。
ConcurrentHashMap的初始化是会通过位与运算来初始化Segment的大小,用ssize来表示,如下所示
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {++sshift;ssize <<= 1;
}如上所示,因为ssize用位于运算来计算(ssize <<=1),所以Segment的大小取值都是以2的N次方,无关concurrencyLevel的取值,当然concurrencyLevel最大只能用16位的二进制来表示,即65536,换句话说,Segment的大小最多65536个,没有指定concurrencyLevel元素初始化,Segment的大小ssize默认为16。
每一个Segment元素下的HashEntry的初始化也是按照位于运算来计算,用cap来表示,如下所示
int cap = 1;
while (cap < c)cap <<= 1;如上所示,HashEntry大小的计算也是2的N次方(cap <<=1), cap的初始值为1,所以HashEntry最小的容量为2。
put操作
对于ConcurrentHashMap的数据插入,这里要进行两次Hash去定位数据的存储位置
static class Segment<K,V> extends ReentrantLock implements Serializable {从上Segment的继承体系可以看出,Segment实现了ReentrantLock,也就带有锁的功能,当执行put操作时,会进行第一次key的hash来定位Segment的位置,如果该Segment还没有初始化,即通过CAS操作进行赋值,然后进行第二次hash操作,找到相应的HashEntry的位置,这里会利用继承过来的锁的特性,在将数据插入指定的HashEntry位置时(链表的尾端),会通过继承ReentrantLock的tryLock()方法尝试去获取锁,如果获取成功就直接插入相应的位置,如果已经有线程获取该Segment的锁,那当前线程会以自旋的方式去继续的调用tryLock()方法去获取锁,超过指定次数就挂起,等待唤醒。
get操作
ConcurrentHashMap的get操作跟HashMap类似,只是首先要判断volatile类型变量count是否不等于0,若不等于0则ConcurrentHashMap第一次需要经过一次hash定位到Segment的位置,然后再hash定位到指定的HashEntry,遍历该HashEntry下的链表进行对比,成功就返回,不成功就返回null。是弱一致性的。
因为count是volatile,所以对count的写要happens-before于读操作。写线程 M 对链表做的结构性修改,在读线程 N 读取了同一个 volatile 变量后,对线程 N 也是可见的了。虽然线程 N 是在未加锁的情况下访问链表。Java 的内存模型可以保证:只要之前对链表做结构性修改操作的写线程 M 在退出写方法前写 volatile 型变量 count,读线程 N 在读取这个 volatile 型变量 count 后,就一定能“看到”这些修改。使得在 ConcurrentHashMap 中,读线程在读取散列表时,基本不需要加锁就能成功获得需要的值,不仅减少了请求同一个锁的频率(读操作一般不需要加锁就能够成功获得值),也减少了持有同一个锁的时间(只有读到 value 域的值为 null 时 , 读线程才需要加锁后重读)。
size操作
计算ConcurrentHashMap的元素大小是一个有趣的问题,因为他是并发操作的,就是在你计算size的时候,他还在并发的插入数据,可能会导致你计算出来的size和你实际的size有相差(在你return size的时候,插入了多个数据),要解决这个问题,JDK1.7版本用两种方案。
try {for (;;) {if (retries++ == RETRIES_BEFORE_LOCK) {for (int j = 0; j < segments.length; ++j) ensureSegment(j).lock(); // force creation}sum = 0L;size = 0;overflow = false;for (int j = 0; j < segments.length; ++j) {Segment<K,V> seg = segmentAt(segments, j);if (seg != null) { sum += seg.modCount; int c = seg.count; if (c < 0 || (size += c) < 0)overflow = true;} }if (sum == last) break;last = sum; } }
finally {if (retries > RETRIES_BEFORE_LOCK) {for (int j = 0; j < segments.length; ++j)segmentAt(segments, j).unlock();}
}- 第一种方案他会使用不加锁的模式去尝试多次计算ConcurrentHashMap的size,最多三次,比较前后两次计算的结果,结果一致就认为当前没有元素加入,计算的结果是准确的;
- 第二种方案是如果第一种方案不符合,他就会给每个Segment加上锁,然后计算ConcurrentHashMap的size返回。
以上为JDK1.7中的实现。
在JDK1.8中:
改变了HashMap的索引方法,详见JDK1.8之HashMap,在put时并不会导致链表死循环,但依然不能保证HashMap的线程安全,即是多线程put的时候,当index相同而又同时达到链表的末尾时,另一个线程put的数据会把之前线程put的数据覆盖掉,就会产生数据丢失。
JDK1.8的实现已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized和CAS来操作,整个看起来就像是优化过且线程安全的HashMap,虽然在JDK1.8中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本,序列化与反序列化的时候会发挥作用。
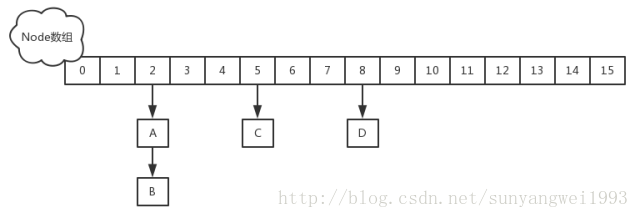
Node
Node是ConcurrentHashMap存储结构的基本单元,继承于HashMap中的Entry,用于存储数据,源代码如下
static class Node<K,V> implements Map.Entry<K,V> {//链表的数据结构final int hash;final K key;//val和next都会在扩容时发生变化,所以加上volatile来保持可见性和禁止重排序volatile V val;volatile Node<K,V> next;Node(int hash, K key, V val, Node<K,V> next) {this.hash = hash;this.key = key;this.val = val;this.next = next;}public final K getKey() { return key; }public final V getValue() { return val; }public final int hashCode() { return key.hashCode() ^ val.hashCode(); }public final String toString(){ return key + "=" + val; }//不允许更新value public final V setValue(V value) {throw new UnsupportedOperationException();}public final boolean equals(Object o) {Object k, v, u; Map.Entry<?,?> e;return ((o instanceof Map.Entry) &&(k = (e = (Map.Entry<?,?>)o).getKey()) != null &&(v = e.getValue()) != null &&(k == key || k.equals(key)) &&(v == (u = val) || v.equals(u)));}//用于map中的get()方法,子类重写Node<K,V> find(int h, Object k) {Node<K,V> e = this;if (k != null) {do {K ek;if (e.hash == h &&((ek = e.key) == k || (ek != null && k.equals(ek))))return e;} while ((e = e.next) != null);}return null;}
}Node数据结构很简单,它与HashMap中的定义很相似,但是但是有一些差别它对value和next属性设置了volatile同步锁,它不允许调用setValue方法直接改变Node的value域,它增加了find方法辅助map.get()方法。
TreeNode
TreeNode继承与Node,但是数据结构换成了二叉树结构,它是红黑树的数据的存储结构,用于红黑树中存储数据,当链表的节点数大于8时会转换成红黑树的结构,树节点类,另外一个核心的数据结构。当链表长度过长的时候,会转换为TreeNode。但是与HashMap不相同的是,它并不是直接转换为红黑树,而是把这些结点包装成TreeNode放在TreeBin对象中,由TreeBin完成对红黑树的包装。而且TreeNode在ConcurrentHashMap集成自Node类,而并非HashMap中的集成自LinkedHashMap.Entry<K,V>类,也就是说TreeNode带有next指针,这样做的目的是方便基于TreeBin的访问。
static final class TreeNode<K,V> extends Node<K,V> {//树形结构的属性定义TreeNode<K,V> parent; // red-black tree linksTreeNode<K,V> left;TreeNode<K,V> right;TreeNode<K,V> prev; // needed to unlink next upon deletionboolean red; //标志红黑树的红节点TreeNode(int hash, K key, V val, Node<K,V> next,TreeNode<K,V> parent) {super(hash, key, val, next);this.parent = parent;}Node<K,V> find(int h, Object k) {return findTreeNode(h, k, null);}//根据key查找 从根节点开始找出相应的TreeNode,final TreeNode<K,V> findTreeNode(int h, Object k, Class<?> kc) {if (k != null) {TreeNode<K,V> p = this;do {int ph, dir; K pk; TreeNode<K,V> q;TreeNode<K,V> pl = p.left, pr = p.right;if ((ph = p.hash) > h)p = pl;else if (ph < h)p = pr;else if ((pk = p.key) == k || (pk != null && k.equals(pk)))return p;else if (pl == null)p = pr;else if (pr == null)p = pl;else if ((kc != null ||(kc = comparableClassFor(k)) != null) &&(dir = compareComparables(kc, k, pk)) != 0)p = (dir < 0) ? pl : pr;else if ((q = pr.findTreeNode(h, k, kc)) != null)return q;elsep = pl;} while (p != null);}return null;}
}TreeBin
TreeBin从字面含义中可以理解为存储树形结构的容器,而树形结构就是指TreeNode,所以TreeBin就是封装TreeNode的容器,它提供转换黑红树的一些条件和锁的控制。这个类并不负责包装用户的key、value信息,而是包装的很多TreeNode节点。它代替了TreeNode的根节点,也就是说在实际的ConcurrentHashMap“数组”中,存放的是TreeBin对象,而不是TreeNode对象,这是与HashMap的区别。另外这个类还带有了读写锁。
static final class TreeBin<K,V> extends Node<K,V> {//指向TreeNode列表和根节点TreeNode<K,V> root;volatile TreeNode<K,V> first;volatile Thread waiter;volatile int lockState;// 读写锁状态static final int WRITER = 1; // 获取写锁的状态static final int WAITER = 2; // 等待写锁的状态static final int READER = 4; // 增加数据时读锁的状态/*** 初始化红黑树*/TreeBin(TreeNode<K,V> b) {super(TREEBIN, null, null, null);this.first = b;TreeNode<K,V> r = null;for (TreeNode<K,V> x = b, next; x != null; x = next) {next = (TreeNode<K,V>)x.next;x.left = x.right = null;if (r == null) {x.parent = null;x.red = false;r = x;}else {K k = x.key;int h = x.hash;Class<?> kc = null;for (TreeNode<K,V> p = r;;) {int dir, ph;K pk = p.key;if ((ph = p.hash) > h)dir = -1;else if (ph < h)dir = 1;else if ((kc == null &&(kc = comparableClassFor(k)) == null) ||(dir = compareComparables(kc, k, pk)) == 0)dir = tieBreakOrder(k, pk);TreeNode<K,V> xp = p;if ((p = (dir <= 0) ? p.left : p.right) == null) {x.parent = xp;if (dir <= 0)xp.left = x;elsexp.right = x;r = balanceInsertion(r, x);break;}}}}this.root = r;assert checkInvariants(root);}......
}ForwardingNode
一个用于连接两个table的节点类。它包含一个nextTable指针,用于指向下一张表。而且这个节点的key value next指针全部为null,它的hash值为-1. 这里面定义的find的方法是从nextTable里进行查询节点,而不是以自身为头节点进行查找
/** * A node inserted at head of bins during transfer operations. */ static final class ForwardingNode<K,V> extends Node<K,V> { final Node<K,V>[] nextTable; ForwardingNode(Node<K,V>[] tab) { super(MOVED, null, null, null); this.nextTable = tab; } Node<K,V> find(int h, Object k) { // loop to avoid arbitrarily deep recursion on forwarding nodes outer: for (Node<K,V>[] tab = nextTable;;) { Node<K,V> e; int n; if (k == null || tab == null || (n = tab.length) == 0 || (e = tabAt(tab, (n - 1) & h)) == null) return null; for (;;) { int eh; K ek; if ((eh = e.hash) == h && ((ek = e.key) == k || (ek != null && k.equals(ek)))) return e; if (eh < 0) { if (e instanceof ForwardingNode) { tab = ((ForwardingNode<K,V>)e).nextTable; continue outer; } else return e.find(h, k); } if ((e = e.next) == null) return null; } } } } Unsafe与CAS
在ConcurrentHashMap中,随处可以看到U, 大量使用了U.compareAndSwapXXX的方法,这个方法是利用一个CAS算法实现无锁化的修改值的操作,他可以大大降低锁代理的性能消耗。这个算法的基本思想就是不断地去比较当前内存中的变量值与你指定的一个变量值是否相等,如果相等,则接受你指定的修改的值,否则拒绝你的操作。因为当前线程中的值已经不是最新的值,你的修改很可能会覆盖掉其他线程修改的结果。这一点与乐观锁,SVN的思想是比较类似的。
unsafe静态块
unsafe代码块控制了一些属性的修改工作,比如最常用的SIZECTL 。 在这一版本的concurrentHashMap中,大量应用来的CAS方法进行变量、属性的修改工作。 利用CAS进行无锁操作,可以大大提高性能。
介绍了ConcurrentHashMap主要的属性与内部的数据结构,现在通过一个简单的例子以debug的视角看看ConcurrentHashMap的具体操作细节。
先通过new ConcurrentHashMap()来进行初始化
public ConcurrentHashMap() {
}由上你会发现ConcurrentHashMap的初始化其实是一个空实现,并没有做任何事,这里后面会讲到,这也是和其他的集合类有区别的地方,初始化操作并不是在构造函数实现的,而是在put操作中实现,当然ConcurrentHashMap还提供了其他的构造函数。
put操作
在上面的例子中我们新增个人信息会调用put方法,我们来看下。
public V put(K key, V value) {return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {if (key == null || value == null) throw new NullPointerException();int hash = spread(key.hashCode()); //两次hash,减少hash冲突,可以均匀分布int binCount = 0;for (Node<K,V>[] tab = table;;) { //对这个table进行迭代Node<K,V> f; int n, i, fh;//这里就是上面构造方法没有进行初始化,在这里进行判断,为null就调用initTable进行初始化,属于懒汉模式初始化if (tab == null || (n = tab.length) == 0)tab = initTable();else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {//如果i位置没有数据,就直接无锁插入if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))break; // no lock when adding to empty bin}else if ((fh = f.hash) == MOVED)//如果在进行扩容,则先进行扩容操作tab = helpTransfer(tab, f);else {V oldVal = null;//如果以上条件都不满足,那就要进行加锁操作,也就是存在hash冲突,锁住链表或者红黑树的头结点synchronized (f) {if (tabAt(tab, i) == f) {if (fh >= 0) { //表示该节点是链表结构binCount = 1;for (Node<K,V> e = f;; ++binCount) {K ek;//这里涉及到相同的key进行put就会覆盖原先的valueif (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}Node<K,V> pred = e;if ((e = e.next) == null) { //插入链表尾部pred.next = new Node<K,V>(hash, key,value, null);break;}}}else if (f instanceof TreeBin) {//红黑树结构Node<K,V> p;binCount = 2;//红黑树结构旋转插入if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}if (binCount != 0) { //如果链表的长度大于8时就会进行红黑树的转换if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);if (oldVal != null)return oldVal;break;}}}addCount(1L, binCount);//统计size,并且检查是否需要扩容return null;
}ConcurrentHashMap不允许key或value为null值
这个put的过程很清晰,对当前的table进行无条件自循环直到put成功,可以分成以下六步流程来概述。
① 判断存储的key、value是否为空,若为空,则抛出异常,否则,进入步骤②
② 计算key的hash值,随后进入无限循环,该无限循环可以确保成功插入数据,若table表为空或者长度为0,则初始化table表,否则,进入步骤③
③ 根据key的hash值取出table表中的结点元素,若取出的结点为空(该桶为空),则使用CAS将key、value、hash值生成的结点放入桶中。否则,进入步骤④
④ 若该结点的的hash值为MOVED,则对该桶中的结点进行转移,即该线程帮助其进行扩容。否则,进入步骤⑤
⑤ 对桶中的第一个结点(即table表中的结点)进行加锁,对该桶进行遍历,桶中的结点的hash值与key值与给定的hash值和key值相等,则根据标识选择是否进行更新操作(用给定的value值替换该结点的value值),若遍历完桶仍没有找到hash值与key值和指定的hash值与key值相等的结点,则直接新生一个结点并赋值为之前最后一个结点的下一个结点。进入步骤⑥
⑥ 若binCount值达到红黑树转化的阈值,则将桶中的结构转化为红黑树存储,最后,增加binCount的值。
其中:
helpTransfer()方法的目的就是调用多个工作线程一起帮助进行扩容,这样的效率就会更高,而不是只有检查到要扩容的那个线程进行扩容操作,其他线程就要等待扩容操作完成才能工作。 帮助从旧的table的元素复制到新的table中,新的table即nextTba已经存在前提下才能帮助扩容。
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {Node<K,V>[] nextTab; int sc;if (tab != null && (f instanceof ForwardingNode) &&(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) { //新的table nextTba已经存在前提下才能帮助扩容int rs = resizeStamp(tab.length);while (nextTab == nextTable && table == tab &&(sc = sizeCtl) < 0) {if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||sc == rs + MAX_RESIZERS || transferIndex <= 0)break;if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {transfer(tab, nextTab);//调用扩容方法break;}}return nextTab;}return table;
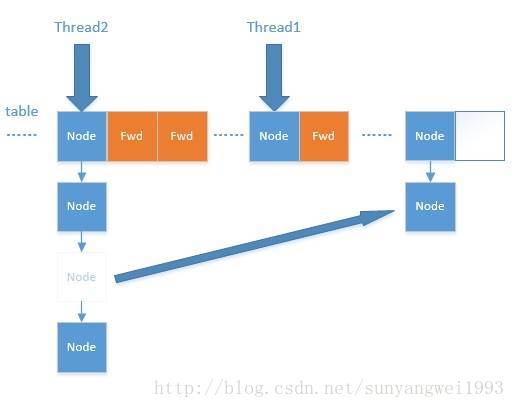
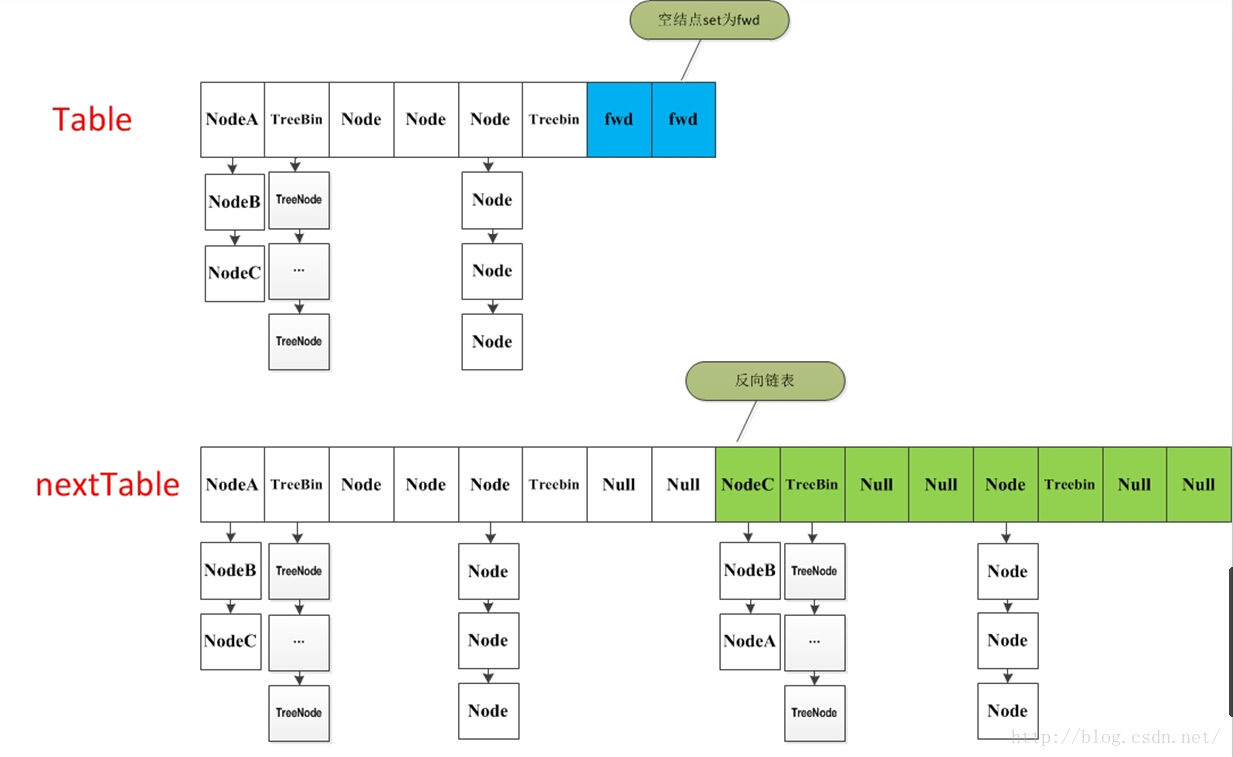
}扩容过程有点复杂,这里主要涉及到多线程并发扩容,ForwardingNode的作用就是支持扩容操作,将已处理的节点和空节点置为ForwardingNode,并发处理时多个线程经过ForwardingNode就表示已经遍历了,就往后遍历,下图是多线程合作扩容的过程:
在并发处理中使用的是乐观锁,当有冲突的时候才进行并发处理,而且流程步骤很清晰,但是细节设计的很复杂,毕竟多线程的场景也复杂。
扩容方法 transfer()
当ConcurrentHashMap容量不足的时候,需要对table进行扩容。这个方法的基本思想跟HashMap是很像的,但是由于它是支持并发扩容的,所以要复杂的多。原因是它支持多线程进行扩容操作,而并没有加锁。我想这样做的目的不仅仅是为了满足concurrent的要求,而是希望利用并发处理去减少扩容带来的时间影响。因为在扩容的时候,总是会涉及到从一个“数组”到另一个“数组”拷贝的操作,如果这个操作能够并发进行,那真真是极好的了。
整个扩容操作分为两个部分
第一部分是构建一个nextTable,它的容量是原来的两倍,这个操作是单线程完成的。这个单线程的保证是通过RESIZE_STAMP_SHIFT这个常量经过一次运算来保证的,这个地方在后面会有提到;
- 第二个部分就是将原来table中的元素复制到nextTable中,这里允许多线程进行操作。
先来看一下单线程是如何完成的:
它的大体思想就是遍历、复制的过程。首先根据运算得到需要遍历的次数i,然后利用tabAt方法获得i位置的元素:
如果这个位置为空,就在原table中的i位置放入forwardNode节点,这个也是触发并发扩容的关键点;
如果这个位置是Node节点(fh>=0),如果它是一个链表的头节点,就构造一个反序链表,把他们分别放在nextTable的i和i+n的位置上
如果这个位置是TreeBin节点(fh<0),也做一个反序处理,并且判断是否需要untreefi,把处理的结果分别放在nextTable的i和i+n的位置上
- 遍历过所有的节点以后就完成了复制工作,这时让nextTable作为新的table,并且更新sizeCtl为新容量的0.75倍 ,完成扩容。
再看一下多线程是如何完成的:
在代码的69行有一个判断,如果遍历到的节点是forward节点,就向后继续遍历,再加上给节点上锁的机制,就完成了多线程的控制。多线程遍历节点,处理了一个节点,就把对应点的值set为forward,另一个线程看到forward,就向后遍历。这样交叉就完成了复制工作。而且还很好的解决了线程安全的问题。 这个方法的设计实在是让我膜拜。
/** * 一个过渡的table表 只有在扩容的时候才会使用 */ private transient volatile Node<K,V>[] nextTable; /** * Moves and/or copies the nodes in each bin to new table. See * above for explanation. */ private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) { int n = tab.length, stride; if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE) stride = MIN_TRANSFER_STRIDE; // subdivide range if (nextTab == null) { // initiating try { @SuppressWarnings("unchecked") Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];//构造一个nextTable对象 它的容量是原来的两倍 nextTab = nt; } catch (Throwable ex) { // try to cope with OOME sizeCtl = Integer.MAX_VALUE; return; } nextTable = nextTab; transferIndex = n; } int nextn = nextTab.length; ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);//构造一个连节点指针 用于标志位 boolean advance = true;//并发扩容的关键属性 如果等于true 说明这个节点已经处理过 boolean finishing = false; // to ensure sweep before committing nextTab for (int i = 0, bound = 0;;) { Node<K,V> f; int fh; //这个while循环体的作用就是在控制i-- 通过i--可以依次遍历原hash表中的节点 while (advance) { int nextIndex, nextBound; if (--i >= bound || finishing) advance = false; else if ((nextIndex = transferIndex) <= 0) { i = -1; advance = false; } else if (U.compareAndSwapInt (this, TRANSFERINDEX, nextIndex, nextBound = (nextIndex > stride ? nextIndex - stride : 0))) { bound = nextBound; i = nextIndex - 1; advance = false; } } if (i < 0 || i >= n || i + n >= nextn) { int sc; if (finishing) { //如果所有的节点都已经完成复制工作 就把nextTable赋值给table 清空临时对象nextTable nextTable = null; table = nextTab; sizeCtl = (n << 1) - (n >>> 1);//扩容阈值设置为原来容量的1.5倍 依然相当于现在容量的0.75倍 return; } //利用CAS方法更新这个扩容阈值,在这里面sizectl值减一,说明新加入一个线程参与到扩容操作 if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) { if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT) return; finishing = advance = true; i = n; // recheck before commit } } //如果遍历到的节点为空 则放入ForwardingNode指针 else if ((f = tabAt(tab, i)) == null) advance = casTabAt(tab, i, null, fwd); //如果遍历到ForwardingNode节点 说明这个点已经被处理过了 直接跳过 这里是控制并发扩容的核心 else if ((fh = f.hash) == MOVED) advance = true; // already processed else { //节点上锁 synchronized (f) { if (tabAt(tab, i) == f) { Node<K,V> ln, hn; //如果fh>=0 证明这是一个Node节点 if (fh >= 0) { int runBit = fh & n; //以下的部分在完成的工作是构造两个链表 一个是原链表 另一个是原链表的反序排列 Node<K,V> lastRun = f; for (Node<K,V> p = f.next; p != null; p = p.next) { int b = p.hash & n; if (b != runBit) { runBit = b; lastRun = p; } } if (runBit == 0) { ln = lastRun; hn = null; } else { hn = lastRun; ln = null; } for (Node<K,V> p = f; p != lastRun; p = p.next) { int ph = p.hash; K pk = p.key; V pv = p.val; if ((ph & n) == 0) ln = new Node<K,V>(ph, pk, pv, ln); else hn = new Node<K,V>(ph, pk, pv, hn); } //在nextTable的i位置上插入一个链表 setTabAt(nextTab, i, ln); //在nextTable的i+n的位置上插入另一个链表 setTabAt(nextTab, i + n, hn); //在table的i位置上插入forwardNode节点 表示已经处理过该节点 setTabAt(tab, i, fwd); //设置advance为true 返回到上面的while循环中 就可以执行i--操作 advance = true; } //对TreeBin对象进行处理 与上面的过程类似 else if (f instanceof TreeBin) { TreeBin<K,V> t = (TreeBin<K,V>)f; TreeNode<K,V> lo = null, loTail = null; TreeNode<K,V> hi = null, hiTail = null; int lc = 0, hc = 0; //构造正序和反序两个链表 for (Node<K,V> e = t.first; e != null; e = e.next) { int h = e.hash; TreeNode<K,V> p = new TreeNode<K,V> (h, e.key, e.val, null, null); if ((h & n) == 0) { if ((p.prev = loTail) == null) lo = p; else loTail.next = p; loTail = p; ++lc; } else { if ((p.prev = hiTail) == null) hi = p; else hiTail.next = p; hiTail = p; ++hc; } } //如果扩容后已经不再需要tree的结构 反向转换为链表结构 ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) : (hc != 0) ? new TreeBin<K,V>(lo) : t; hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) : (lc != 0) ? new TreeBin<K,V>(hi) : t; //在nextTable的i位置上插入一个链表 setTabAt(nextTab, i, ln); //在nextTable的i+n的位置上插入另一个链表 setTabAt(nextTab, i + n, hn); //在table的i位置上插入forwardNode节点 表示已经处理过该节点 setTabAt(tab, i, fwd); //设置advance为true 返回到上面的while循环中 就可以执行i--操作 advance = true; } } } } } } get操作
使用String name = map.get(“name”)获取新增的name信息,现在我们依旧用debug的方式来分析下ConcurrentHashMap的获取方法get()
public V get(Object key) {Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;int h = spread(key.hashCode()); //计算两次hashif ((tab = table) != null && (n = tab.length) > 0 &&(e = tabAt(tab, (n - 1) & h)) != null) {//读取首节点的Node元素if ((eh = e.hash) == h) { //如果该节点就是首节点就返回if ((ek = e.key) == key || (ek != null && key.equals(ek)))return e.val;}//hash值为负值表示正在扩容,这个时候查的是ForwardingNode的find方法来定位到nextTable来//查找,查找到就返回else if (eh < 0)return (p = e.find(h, key)) != null ? p.val : null;while ((e = e.next) != null) {//既不是首节点也不是ForwardingNode,那就往下遍历if (e.hash == h &&((ek = e.key) == key || (ek != null && key.equals(ek))))return e.val;}}return null;
}ConcurrentHashMap的get操作的流程很简单,也很清晰,可以分为三个步骤来描述:
1. 计算hash值,定位到该table索引位置,如果是首节点符合就返回
2. 如果遇到扩容的时候,会调用标志正在扩容节点ForwardingNode的find方法,查找该节点,匹配就返回
3. 以上都不符合的话,就往下遍历节点,匹配就返回,否则最后就返回null
这个get请求,我们需要cas来保证变量的原子性。如果tab[i]正被锁住,那么CAS就会失败,失败之后就会不断的重试。这也保证了get在高并发情况下不会出错。我们来分析下到底有多少种情况会导致get在并发的情况下可能取不到值。1、一个线程在get的时候,另一个线程在对同一个key的node进行remove操作;2、一个线程在get的时候,另一个线程正则重排table。可能导致旧table取不到值。那么本质是,我在get的时候,有其他线程在对同一桶的链表或树进行修改。那么get是怎么保证同步性的呢?我们看到e = tabAt(tab, (n - 1) & h)) != null,在看下tablAt到底是干嘛的:
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}它是对tab[i]进行原子性的读取,因为我们知道putVal等对table的桶操作是有加锁的,那么一般情况下我们对桶的读也是要加锁的,但是我们这边为什么不需要加锁呢?因为我们用了Unsafe的getObjectVolatile,因为table是volatile类型,所以对tab[i]的原子请求也是可见的。因为如果同步正确的情况下,根据happens-before原则,对volatile域的写入操作happens-before于每一个后续对同一域的读操作。所以不管其他线程对table链表或树的修改,都对get读取可见。
size操作
最后我们来看下例子中最后获取size的方式int size = map.size();,现在让我们看下size()方法:
public int size() {long n = sumCount();return ((n < 0L) ? 0 :(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :(int)n);
}
final long sumCount() {CounterCell[] as = counterCells; CounterCell a; //变化的数量long sum = baseCount;if (as != null) {for (int i = 0; i < as.length; ++i) {if ((a = as[i]) != null)sum += a.value;}}return sum;
}在JDK1.8版本中,对于size的计算,在扩容和addCount()方法就已经有处理了,JDK1.7是在调用size()方法才去计算,其实在并发集合中去计算size是没有多大的意义的,因为size是实时在变的,只能计算某一刻的大小,但是某一刻太快了,人的感知是一个时间段,所以并不是很精确。
总结与思考
其实可以看出JDK1.8版本的ConcurrentHashMap的数据结构已经接近HashMap,相对而言,ConcurrentHashMap只是增加了同步的操作来控制并发,从JDK1.7版本的ReentrantLock+Segment+HashEntry,到JDK1.8版本中synchronized+CAS+HashEntry+红黑树,相对而言,总结如下思考:
1. JDK1.8的实现降低锁的粒度,JDK1.7版本锁的粒度是基于Segment的,包含多个HashEntry,而JDK1.8锁的粒度就是HashEntry(首节点)
2. JDK1.8版本的数据结构变得更加简单,使得操作也更加清晰流畅,因为已经使用synchronized来进行同步,所以不需要分段锁的概念,也就不需要Segment这种数据结构了,由于粒度的降低,实现的复杂度也增加了
3. JDK1.8使用红黑树来优化链表,基于长度很长的链表的遍历是一个很漫长的过程,而红黑树的遍历效率是很快的,代替一定阈值的链表,这样形成一个最佳拍档
4. JDK1.8为什么使用内置锁synchronized来代替重入锁ReentrantLock,我觉得有以下几点:因为粒度降低了,在相对而言的低粒度加锁方式,synchronized并不比ReentrantLock差,在粗粒度加锁中ReentrantLock可能通过Condition来控制各个低粒度的边界,更加的灵活,而在低粒度中,Condition的优势就没有了
5. JVM的开发团队从来都没有放弃synchronized,而且基于JVM的synchronized优化空间更大,使用内嵌的关键字比使用API更加自然
6. 在大量的数据操作下,对于JVM的内存压力,基于API的ReentrantLock会开销更多的内存,虽然不是瓶颈,但是也是一个选择依据
--------------------------
线性表及ArrayList/LinkedList源码分析总结
一.线性表
定义:零个或者多个元素的有限序列。
也就是说它得满足以下几个条件:
①该序列的数据元素是有限的。
②如果元素有多个,除了第一个和最后一个元素之外,每个元素只有一个前驱元素和一个后驱元素。
③第一元素没有前驱元素,最后一个元素没有后继元素。
④序列中的元素数据类型相同。
则这样的数据结构为线性结构。在复杂的线性表中,一个数据元素(对象)可以由若干个数据项组成,组成一张数据表,类似于数据库。
二.线性表的抽象数据类型
1.相关概念
抽象数据类型(abstract data type,ADT)是带有一组操作的一组对象的集合。这句话表明,线性表的抽闲数据类型主要包括两个东西:数据集合和数据集合上的操作集合。
①数据集合:我们假设型如a0,a1,a2,...an-1的表,我们说这个表的大小是N,我们将大小为0的标称为空表。
②集合上的操作:一般常用的操作包括,查找,插入,删除,判断是否为空等等。
2.线性表的顺序储存结构
线性表的顺序储存结构,指的是用一段地址连续的储存单元依次储存线性表的数据元素。我们可以用一维数组实现顺序储存结构,并且上述对表的所有操作都可由数组实现。但是一维数组有一个很大缺点就是它得长度是固定的,也就是我们创建的额时候就声明的长度,一旦我们要存储的数据超出了这个长度,我们就不得不手动的创建一个更长的新数组并将原来数组中的数据拷贝过去。
int [] arr = new int[10]......int [] newArr = new int[arr.length*2]for(int i=0;i<arr;i++){newArr[i] = arr[i];}arr = new Arr;
显然这样做非常的不明智,因此java中的ArrayList就应用而生了。ArrayList也就是传说中的动态数组,也就是我们可以随着我们数据的添加动态增长的数组。
实际上不管是简单数组也好,动态数组也好,在具体的操作中都存在这样的问题:
①如果我们在线性表的第i个位置插入/删除一个元素,那么我们需要怎么做呢?首先我们得从最后一个元素开始遍历,到第i个位置,分辨将他们向后/前移动一个位置;在i位置处将要插入/删除的元素进行相应的插入/删除操作;整体的表长加/减1.
②如果我们在线性表的第一个位置插入/删除一个元素,那么整个表的所有元素都得向后/向前移动一个单位,那么此时操作的时间复杂度为O(N);如果我们在线性表的最末位置进行上面两种操作,那么对应的时间复杂度为O(1)——综合来看,在线性表中插入或者删除一个元素的平均时间复杂度为O(N/2)。
总结一下,线性表的缺点——插入和删除操作需要移动大量的元素;造成内存空间的"碎片化"。这里有些童鞋就说了,ArrayList是一个线性表吧,我再ArrayList中添加/删除一个元素直接调用add()/remove()方法就行了啊,也是一步到位啊——这样想就不对了,如果我们看ArrayList的源码就会发现,实际上他内部也是通过数组来实现的,remove()/add()操作也要通过上面说的一系列步骤才能完成,只不过做了封装让我们用起来爽。之后我们会通过源码分析ArrayList等的内部的实现方式。
当然了,优缺点就会有优点——由于顺序储存结构的元素数目,元素相对位置都确定的,那么我们在存取确定位置的元素数据的时候就比较方便,直接返回就行了。
3.线性表的链式储存结构
上面我们说过,顺序结构的最大不足是插入和删除时需要移动大量元素;造成内存空间的"碎片化。那么造成这中缺点的原因是什么呢?原因就在于这个线性表中相邻两元素之间的储存位置也就有相邻关系,也就是说元素的位置是相对固定的,这样就造成了"牵一发而动全身"的尴尬局面;同时,什么是"碎片化"呢?就是说上述顺序结构中,以数组为例来说,如果我们先在内存中申请一个10位长度的数组,然后隔3个位置放一个5位长度的数组,这个时候如果再来一个8位长度的数组,那么显然不能放在前两个数组之间(他们之间只有三个空位),那只能另找地方,中间的这三个位置就空下了,久而久之类似的事情多了就发生了"碎片化"的现象。
(1)简单链表
为了解决上述两个问题,我们前辈的科学家们就发明了伟大的"链式储存结构",也就是传说中的链表(Linked List)。链表的结构有两大特点:
①用一组任意的储存单元储存线性表的数据元素,这组储存单元可以是连续的,也可以是不连续的。这就意味着,这些数据元素可以存在内存中任意的未被占用的位置。
②在上面的顺序数据结构中,每个数据元素只要储存数据信息就可以了,但是在链表中,由于数据元素之间的位置不是固定的,因此为了保证数据元素之间能相互找到前后的位置,每个数据元素不仅需要保存自己的数据信息,还需要保存指向下一个指针位置的信息。
简单链表.png
如图,我们画出了简单链表的示意图。链表由一系列结点组成,这些结点不必再内存中相连,每个结点含有表元素(数据域)和到包含该元素后继结点的链(link)(指针域)。
对于一个线性表来说,总得有头有尾,链表也不例外。我们把第一个链表储存的位置叫做"头指针",整个链表的存取就是从头指针开始的。之后的每一个结点,其实就是上一个结点的指针域指向的位置。最后一个结点由于没有后继结点,因此它的指针域为NULL。
有时我们会在第一个指针前面加上一个头结点,头结点的数据域可以不表示任何数值,也可以储存链表长度等公共信息,头结点的指针域储存指向第一个结点的位置的信息。
需要注意的是,头结点不是链表的必要要素,但是有了头结点,在对第一个结点之前的位置添加/删除元素时,就与其他元素的操作统一了。
(1.1)简单链表的读取
在上面的线性表的顺序储存结构中,我们知道它的一个优点就是存取确定位置的元素比较的方便。但是对于链式储存结构来说,假设我们要读取i位置上的元素信息,但是由于我们事先并不知道i元素到底在哪里,所以我们只能从头开始找,知道找到第i个元素为止。由于这个算法的时间复杂度取决于i的位置,最坏的情况就是O(n),即元素在末尾。
由于单链表没有定义表长,所以我们没有办法使用for循环来查找。因此这里查找算法的核心思想是"工作指针后移",也就是当前的元素查完之后,移动到下一个位置,检查下一个位置的元素,以此循环,直到找到第i个位置的元素。
可以看到,这是链表结构的一个缺点,对于确定位置的元素查找平均时间复杂度为O(N/2)。
(1.2)简单链表的插入与删除
当然了,有缺点就有优点,我们说过链表解决了顺序表中"插入和删除时需要移动大量元素"的缺点。也就是说,链表中插入删除元素不需要移动其他的元素,那么链表是怎么做到的呢?
单链表的删除与插入.png
我们用“.next”表示一个节点的后继指针,X.next = Y表示将X的后继指针指向Y节点。这里不得不说一下,由于Java中没有指针的概念,而是引用(关于指针和引用的区别我们这里不做过多的说明,他们本质上都是指向储存器中的一块内存地址)。在java语言描述的链表中,上面所说的“指针域”更准确的说是“引用域”,也就是说,这里的x.next实际上是X的下一个节点x->next元素的引用。说的更直白一点,我们可以简单的理解为x.next = x->next,就像我们经常做的Button mbutton = new Button();一样,在实际操作中我们处理mbutton这个引用实际上就是在处理new Button()对象。
我们先说删除的做法,如上图所示,我们假设一个x为链表节点,他的前一个结点为x->prev,后一个结点为x->next,我们用x.next表示他的后继引用。现在我们要删除x结点,需要怎么做呢?实际上很简单,直接让前一个结点元素的后继引用指向x的下一个节点元素(向后跳过x)就可以了x->prev.next = x.next。
同理插入一个节点呢?首先我们把Node的后继节点Next的变成P的后继节点,接着将Node的后继引用指向P,用代码表示就是:P.next = Node.next; Node.next = P;。解释一下这两句代码,P.next = Node.next;实际上就是用Node.next的引用覆盖了P.next的引用,P.next的引用本来是一个空引用(刚开始还没插入链表不指向任何节点),而Node.next本来是指向Next节点的,这一步操作完之后实际上P.next这个引用就指向了Next节点;这个时候Node.next = P;这句代码中,我们将Node.next这个引用重新赋值,也就是指向了P这个节点,这样整个插入过程就完成了。
为什么我们啰里啰嗦的为两句代码解释了一堆内容呢?就是要强调,上面两个步骤顺序是不能颠倒的!为什么呢?我们不妨颠倒顺序看一下——我们首先进行Node.next = P;这一步,开始的时候,P的引用域是空的(或者指向无关的地址),此时如果我们进行了这一步,那么Node.next这个引用就指向了P节点,这个时候我们再进行P.next = Node.next这一步就相当于P.next = p,p.next引用域指向自己,这没有任何意义。
(2)双链表(LinkedList)
上面我们说了简单链表的各种事项,但是在实际的运用中,为了我们的链表更加灵活(比如既可以工作指针后移向后查找,也可以指针向前移动查询),我们运用更多的是双向链表,即每个节点持有前面节点和后面节点的引用。java的双向链表通过LinkedList类实现,通过阅读源码我们在该类中可以看到关于结点的定义:
private static class Node<E> {E item;Node<E> next;Node<E> prev;Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;}}
Java双链表中的结点是通过一个静态内部类定义。一个结点包含自身元素(item),该节点对后一个节点的引用(next),该节点对前一个节点的引用(prev)。
(2.1)双链表的删除
双链表的删除.png
如图,我们假设在一个双向链表中有一个节点X,他的前继节点是prev,后继节点是next.现在我们展示删除节点X的源码(sources/ansroid-24/java/util/LinkedList):
public boolean remove(Object o) { //删除分为两种情况,一种是删链表中的null元素,一种是删正常元素if (o == null) { //删除的具体操作没什么区别,都是从第一个开始,向后移动工作指针,直到找到符合条件的for (Node<E> x = first; x != null; x = x.next) {if (x.item == null) {unlink(x);return true;}}} else {for (Node<E> x = first; x != null; x = x.next) {if (o.equals(x.item)) {unlink(x);return true;}}}return false;}
E unlink(Node<E> x) { //上面是找元素,这个方法是真正删除元素final E element = x.item; //x.item表示当前的x节点final Node<E> next = x.next; //x.next表示x后继引用,next同final Node<E> prev = x.prev; //x.prev是x的前继引用,prev同......if (prev == null) { //如果prev为null,则表示x为第一个结点,此时删除x的做法只需要将x的first = next; //下一个节点设为第一个节点即可,first表示链表的第一节点。} else {① prev.next = next; //否则的话,x为普通节点。那么只要将x的前一个结点(prev)的后继引用指向x的下一个 x.prev = null; //节点就行了,也就是(向后)跳过了x节点。x的前继引用删除,断开与前面元素的联系。}if (next == null) {last = prev; //如果x节点后继无人,说明他是最后一个节点。直接把前一个结点作为链表的最后一个节点就行} else {② next.prev = prev; //否则x为普通节点,将x的下一个节点的前继引用指向x的前一个节点,也就是(向前)跳过x. x.next = null; //x的后继引用删除,断了x的与后面元素的联系}x.item = null; //删除x自身size--; //链表长度减1modCount++;return element;}
我们在在上面的源码中标出了删除一个元素所需要的两个步骤,即prev节点中原本指向X节点的后继引用,现在向后越过X,直接指向next节点①(prev.next = next;);next节点中原本指向X节点的前继引用,现在向前越过X节点,直接指向prev节点。;然后就是将X的前继引用和后继引用都设置为null,断了他与前后节点之间的联系;最后将X节点本身置为null,方便内存的释放。
(2.2)双链表的插入
双链表的添加.png
这里我们选取较为容易的,在指定位置添加一个元素的add方法分析(sources/ansroid-24/java/util/LinkedList):
public void add(int index, E element) {checkPositionIndex(index);if (index == size) //size表示整个链表的长度,如果指定的索引等于链表的长度,那么就把这个元素添加到链表末尾linkLast(element);else //否则执行linkBefore()方法,添加到末尾之前的元素前面linkBefore(element, node(index));}
这里我们看一下这个node(index)方法:
/*** Returns the (non-null) Node at the specified element index.返回指定索引处的非空元素*/Node<E> node(int index) {if (index < (size >> 1)) { //size >> 1,表示二进制size右移一位,相当于size除以2Node<E> x = first;for (int i = 0; i < index; i++) //如果指定的索引值小于size的一般,那么从第一个元素开始,x = x.next; //指针向后移动查找,一直到指定的索引处return x;} else { //else,从最后一个元素开始,向前查找Node<E> x = last;for (int i = size - 1; i > index; i--)x = x.prev;return x;}}
/*** Inserts element e before non-null Node succ.*/void linkBefore(E e, Node<E> succ) { //e为我们要插入的元素,succ为我们要插入索引处的元素final Node<E> pred = succ.prev; //先将succ的前继引用(或者前一个结点的元素)保存在pred变量中final Node<E> newNode = new Node<>(pred, e, succ); //创建一个新节点,也就是我们要插入的这个元素//注意new Node<>(pred, e, succ);这三个参数,可以参照(1.3)处的源码① succ.prev = newNode; //succ的前继引用指向NewNodeif (pred == null) //如果这个前继引用为空,那就说明我们插入的元素是在最前面first = newNode; //直接让newNode做第一个元素就行了else② pred.next = newNode; //否则的话,在让pred的后继引用指向newNode节点size++;modCount++;}
可以看到这里实际上和简单链表的添加一样,也是分两步走,而且两步的顺序不能颠倒。这里需要说明的一点是,我们在图上用灰色的点线多画了两条箭头,其中①②分别表示的是新元素的前继引用和后继引用分别指向pred和succ的赋值过程。在笔者参考的《大话数据结构》中,双链表的添加算上点线的那两步一共是四步,但实际上在java中创建newNode的时候new Node<>(pred, e, succ)这句代码已经一次性做完了上述两部过程,真正做事的就是我们在图中用黑线标出的那两步。
三.JAVA中相关的collection集合
java集合主要由两个接口派生而出——Collection接口和Map接口。collection储存一组类型相同的对象,且每个位置只能保存一个元素;Map保存的是键值对(key-value)。我们本节重点来说Collection集合。
对于collection接口中的方法,我我们可以通过他的源码来看:
public interface Collection<E> extends Iterable<E> {int size(); //@return the number of elements in this collectionboolean isEmpty(); //@return <tt>true</tt> if this collection contains no elementsboolean contains(Object o); //Returns <tt>true</tt> if this collection contains the specified element.Object[] toArray(); //Returns an array containing all of the elements in this collection.boolean remove(Object o); //<tt>true</tt> if an element was removed as a result of this callboolean add(E e); //<tt>true</tt> if this collection changed as a result of the callboolean containsAll(Collection<?> c);boolean addAll(Collection<? extends E> c);boolean removeAll(Collection<?> c);void clear();boolean equals(Object o);......
}
上面我们列出了Collection集合的几个主要的方法,从注释中我们可以很清楚的知道他们的用途。
1.Iterable/Iterator接口
我们看上面的collection接口的时候,collection接口继承了Iterable类,我们来看看这个Iterable类:
public interface Iterable<T> {/*** Returns an iterator over elements of type {@code T}.** @return an Iterator.*/Iterator<T> iterator();/** @param action The action to be performed for each element* @throws NullPointerException if the specified action is null* @since 1.8*/default void forEach(Consumer<? super T> action) {Objects.requireNonNull(action);for (T t : this) {action.accept(t);}}......
}
我们先看一下第二个函数forEach(Consumer<? super T> action),在java8中,Iterator新加了这个个forEach循环(注意与java5中的foreach循环的区别,大小写,用法不同),主要用于更加方便的循环遍历集合中的元素并对每一个元素迭代做出相应的处理,其中的参数Consumer<? super T> action就是我们对集合中的元素所施加的操作。举例说明具体的用法:
传统方式循环List:
List<String> items = new ArrayList<>();items.add("A");items.add("B");items.add("C");items.add("D");items.add("E");for(String item : items){System.out.println(item);}
在java8中使用forEach循环+Lambda表达式遍历list:
List<String> items = new ArrayList<>();items.add("A");items.add("B");items.add("C");items.add("D");items.add("E");//lambda//Output : A,B,C,D,Eitems.forEach(item->System.out.println(item));//Output : Citems.forEach(item->{if("C".equals(item)){System.out.println(item);}});
回到Iterable类中,我们可以看到他还返回了一个Iterator接口的实例。而这个接口类是什么呢?
public interface Iterator<E> {boolean hasNext();E next();default void remove() {throw new UnsupportedOperationException("remove");}default void forEachRemaining(Consumer<? super E> action) {Objects.requireNonNull(action);while (hasNext())action.accept(next());}
}
可以看到,该接口类中一共有四个方法。其中forEachRemaining()方法是java8之后新增的方法,主要的作用和上面我们说过的foreach()循环是一样的,用法也基本相同。
Iterator类的作用是一个迭代器,主要用于操作colloection集合类中的元素。Iterator类必须依附于Collection对象,Iterator本身并不提供盛装对象的能力。如果需要创建Iterator对象,则必需有一个被迭代的集合,如果没有Colletion集合,Iterator也没有存在的价值。
Iterator类中的结果方法——hasNext(),用于判断在遍历时collection集合中是否还有剩下的元素;next()用于返回遍历时集合中的下一个元素,这两个方法很好理解。唯独这个remove()方法有一些注意事项需要说明一下:
我们可以先看看这个方法的注释:
/*** Removes from the underlying collection the last element returned* by this iterator (optional operation). This method can be called* only once per call to {@link #next}. * ......** @throws IllegalStateException if the {@code next} method has not* yet been called, or the {@code remove} method has already* been called after the last call to the {@code next}* method*/
翻译一下:从底层集合中删除此迭代器返回的最后一个元素。这个方法只能在每一次调用完next()方法之后调用一次。如果next()方法没有调用,或者remove()方法在上一次next()方法调用完了之后,又调用了一次,则会抛出IllegalStateException异常。
结合这段注释,我们交代一下next()方法调用的几个注意事项:
①remove()只能在next()方法调用完后紧接着调用一次,此时他删除的是在他之前调用的那个next()返回的元素
②remove()在调用之心完之后,只能等待下一次next()方法执行完了之后,才可以调用。
同时我们还需要注意:③在使用Iterator迭代的过程中,我们不能手动修改collection集合中的元素,即不能手动调用collection类本身的remove(),add(),clear()等方法,只能调用Iterator的remove()方法。举个例子:
public class IteratorTest{public static void main(String[] args){...Iterator it = books.iterator();while(it.hasNext()){String book = (String)it.next();if("book.equals("hhhhhh"))it.remove(); //删除上一次next()返回的元素,也就是"hhhhhh"book = "666666"; *}}
}
上面是一段"正常"的程序,这里需要说明的一点,上一段代码星号处我们将book的赋值为“666666”,但是当我们再次打印出books的集合时会发现集合中的元素没有什么改变,还是原来的值。这说明——当使用Iterator迭代器进行迭代时,Iterator并不是把集合元素本身传递给了迭代变量,而是把集合元素的额值出给了迭代变量,因此我们在后边进行的各种赋值并不影响集合本身的元素。
public class IteratorTest{public static void main(String[] args){...Iterator it = books.iterator();while(it.hasNext()){String book = (String)it.next();if("book.equals("hhhhhh"))books.remove(book); //错误,在迭代时调用了修改集合本身的方法}}
}
这是一段有问题的代码。这里还需要注意一点,这个Iterator中的remove()和collection本身的remove(o)方法是不一样的,一个有参数一个无参数。而且子删除集合中元素时,我们优先考虑用Iterator的remve()方法,因为他有更高的效率,为什么呢?这里我们先作为一个遗留问题,后面我们再详细证明。
同样我们可以用java5中的foreach循环来遍历collection集合中的元素,这个更加简洁一些:
public class ForeachTest{public static void main(String[] args){...for(Object obj : books){String book = (String)it.next(); //此处的book也不是变量本身if("book.equals("hhhhhh"))books.remove(book); //错误,在迭代时调用了修改集合本身的方法}}
}
上面加注释的两个地方,是foreach循环与Iterator迭代类似的地方。
2.List接口,ArrayList类,LinkedList类
colection接口有三个子类实现接口:List(有序集合,元素可以重复),Queue(对列),Set(无序集合,元素不可重复),其中List又有两个最常见的实现类:ArrayList(动态数组)和LinkedList(双向链表),这两个也就是我们前面一直说的线性表的顺序储存结构和链式储存结构。List接口作为collection接口的子类,当然实现了collection接口中的所有方法。并且由于List是有序集合,因此List集合中增加了一些根据元素索引来操作集合的方法。
(1)List源码解析
public interface List<E> extends Collection<E> {...... //省略一些collection中展示过的方法/**同时List接口定义了一些自己的方来实现“有序”这一功能特点*//***返回列表中指定索引的元素*/E get(int index);/***设定某个列表索引的值*/E set(int index, E element);/***在指定位置插入元素,当前元素和后续元素后移*这是可选操作,类似于顺序表的插入操作*/void add(int index, E element);/*** 删除指定位置的元素(可选操作)*/E remove(int index);/*** 获得指定对象的最小索引位置,没有则返回-1*/int indexOf(Object o);/*** 获得指定对象的最大索引位置* 可以知道的是若集合中无给定元素的重复元素下* 其和indexOf返回值是一样的*/int lastIndexOf(Object o);/***一种更加强大的迭代器,支持向前遍历,向后遍历插入删除操作*/ListIterator<E> listIterator(); *ListIterator<E> listIterator(int index); */*** 返回索引fromIndex(包括)和toIndex(不包括)之间的视图。*/List<E> subList(int fromIndex, int toIndex);
}
这里解释一下ListIterator类,该类继承自Iterator类,提供了专门操作List的方法。ListIterator接口在Iterator接口的基础上增加了洗下面几个关键的方法:
public interface ListIterator<E> extends Iterator<E> {boolean hasNext();E next();void remove();/**下面是在Iterator基础上增加的方法*/boolean hasPrevious(); //是否还有前继元素E previous(); //返回前一个元素int nextIndex(); //返回下一个元素的索引int previousIndex(); //返回前一个元素的索引void set(E e); //替换由上一次next()或者previous()方法返回的元素.void add(E e); //在上一次由next()方法返回的元素之前,或者在上一次previous()方法返回的元素之后,添加一个元素
}
可以看到,ListIterator增加了向前迭代的功能(Iterator只能向后迭代),而且ListIterator可以通过add()方法向List中添加元素(Iterator只能删除)。
(2)ArrayList源码解析
(2.1)ArrayList类的头部:
public class ArrayList<E> extends AbstractList<E>implements List<E>, RandomAccess, Cloneable, java.io.Serializable{
RandomAccess:RandmoAccess是一个标记接口,用于被List相关类实现。他主要的作用表明这个相关类支持快速随机访问。在ArrayList中,我们即可以通过元素的序号快速获取元素对象——这就是快速随机访问。稍后,我们会比较List的“快速随机访问”和“通过Iterator迭代器访问”的效率。
Cloneable:实现该接口的类可以对该类的实例进行克隆(按字段进行复制)
Serializable:ArrayList支持序列化,能通过序列化去传输。
(2.2)ArrayList属性
private static final long serialVersionUID = 8683452581122892189L;private static final int DEFAULT_CAPACITY = 10; //默认的初始容量private static final Object[] EMPTY_ELEMENTDATA = {}; //共享的空数组实例/*** 储存ArrayList元素的数组缓冲区。ArrayList的容量就是该缓冲数组的长度。任何以EMPTY_ELEMENTDATA作为* 数据元素的空ArrayList,在他们添加第一个元素的时候,都将被扩展至DEFAULT_CAPACITY(默认为10)长度。*/transient Object[] elementData;private int size; //ArrayList的大小,即他所包含的元素的个数
从ArrayList的属性元素我们可以看出,他的内部是由一个数组(elementData)实现的。这里需要说明一下transient Object[] elementData;这句中的transient关键字:
我们都知道一个对象只要实现了Serilizable接口,这个对象就可以被序列化,java的这种序列化模式为开发者提供了很多便利,我们可以不必关系具体序列化的过程,只要这个类实现了Serilizable接口,这个类的所有属性和方法都会自动序列化。
然而在实际开发过程中,我们常常会遇到这样的问题,这个类的有些属性需要序列化,而其他属性不需要被序列化,打个比方,如果一个用户有一些敏感信息(如密码,银行卡号等),为了安全起见,不希望在网络操作(主要涉及到序列化操作,本地序列化缓存也适用)中被传输,这些信息对应的变量就可以加上transient关键字。换句话说,这个字段的生命周期仅存于调用者的内存中而不会写到磁盘里持久化。
总之,java 的transient关键字为我们提供了便利,你只需要实现Serilizable接口,将不需要序列化的属性前添加关键字transient,序列化对象的时候,这个属性就不会序列化到指定的目的地中。
(3.1)ArrayList构造方法
public ArrayList(int initialCapacity) {super();if (initialCapacity < 0)throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);this.elementData = new Object[initialCapacity];}public ArrayList() {super();this.elementData = EMPTY_ELEMENTDATA; //EMPTY_ELEMENTDATA等于10,前面说过}public ArrayList(Collection<? extends E> c) {elementData = c.toArray();size = elementData.length;// c.toArray might (incorrectly) not return Object[] (see 6260652)if (elementData.getClass() != Object[].class)elementData = Arrays.copyOf(elementData, size, Object[].class);}
可以看到ArrayList有三种构造方法:
①指定长度的初始化
②初始化一个空ArrayList,此时会自动将该初始化的ArrayList长度变为默认长度10。
③将指定的集合作为参数提供给初始化的ArrayList,并在该构造函数内部,先通过toArray将该集合强制转化为Object类型,然后通过Arrays.copyOf方法将其赋给elementData,也就是ArrayList缓存元素的地方。
(3.4)ArrayList的增加
public boolean add(E e) {ensureCapacityInternal(size + 1); // 扩容检查,确保当前数组在扩容之后可以容纳它的参数个大小的元素elementData[size++] = e; // 将e增加至list的数据尾部,容量+1return true;}public void add(int index, E element) { //在指定位置添加一个元素if (index > size || index < 0) //判断是否越界throw new IndexOutOfBoundsException(outOfBoundsMsg(index));// 对数组进行复制处理,目的就是空出index的位置插入element,并将index后的元素位移一个位置ensureCapacityInternal(size + 1); // 扩容检查System.arraycopy(elementData, index, elementData, index + 1,size - index);elementData[index] = element; //将元素添加到指定的位置size++; //容量+1}public boolean addAll(Collection<? extends E> c) { //将整个collection集合和添加到List结尾Object[] a = c.toArray(); //将c转化成Object类数组int numNew = a.length;ensureCapacityInternal(size + numNew); //扩容检查System.arraycopy(a, 0, elementData, size, numNew); //将c添加到list尾部size += numNew; //更新当前容器大小return numNew != 0;}public boolean addAll(int index, Collection<? extends E> c) { //在指定额索引处添加整个集合if (index > size || index < 0)throw new IndexOutOfBoundsException(outOfBoundsMsg(index));Object[] a = c.toArray();int numNew = a.length;ensureCapacityInternal(size + numNew); // 扩容检查int numMoved = size - index;if (numMoved > 0)System.arraycopy(elementData, index, elementData, index + numNew,numMoved);System.arraycopy(a, 0, elementData, index, numNew);size += numNew;return numNew != 0;}
这里我们需要注意的是~~在数组的增加过程中,有两个过程是是比较耗费性能的:数组扩容(ensureCapacityInternal)与数组复制(System.arraycopy),这两个步骤在上面四个添加方法中都存在,待会我们会详细分析。
(3.5)ArrayList的删除
public E remove(int index) { //根据索引位置删除元素if (index >= size) //越界检查throw new IndexOutOfBoundsException(outOfBoundsMsg(index));modCount++;E oldValue = (E) elementData[index]; //去除要删除的元素,该方法最终会返回这个值int numMoved = size - index - 1; //计算数组要复制的值的数量if (numMoved > 0)System.arraycopy(elementData, index+1, elementData, index,numMoved); //复制数组//数组最后一个元素置空,让垃圾回收器工作。因为删了一个元素,index之后的元素都往前移动了一个位置elementData[--size] = null; // clear to let GC do its workreturn oldValue;}public boolean remove(Object o) { //根据内容删除,只删除匹配的那个if (o == null) { //对要删除的元素进行是否为null的判断for (int index = 0; index < size; index++) //遍历数组,掘地三尺找这个要删除的null元素if (elementData[index] == null) { //找到null值了.(注意这个null值需要用"=="判断)fastRemove(index);return true;}} else {for (int index = 0; index < size; index++)if (o.equals(elementData[index])) { //非null是用.equals()比较fastRemove(index);return true;}}return false;}private void fastRemove(int index) {modCount++;int numMoved = size - index - 1; //计算要复制的数组容量if (numMoved > 0)System.arraycopy(elementData, index+1, elementData, index,numMoved);elementData[--size] = null; // clear to let GC do its work}
增加和删除使我们在ArrayLisy中比较常用的两个方法。下面我们来说说上面遗留的那个关于扩容和复制的问题。首先我们来看看ensureCapacityInternal方法的源码:
private void ensureCapacityInternal(int minCapacity) { //minCapacity就是我们需要的最小容量if (elementData == EMPTY_ELEMENTDATA) { //如果此时elementData等于空数组minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity); //如果minCapacity比默认值10小,则//minCapacity为10,否则为他自己。}ensureExplicitCapacity(minCapacity);}private void ensureExplicitCapacity(int minCapacity) {modCount++;// overflow-conscious code//如果当前的数组长度小于我们所需要的minCapacity值(当前数组长度不够),则进行扩容if (minCapacity - elementData.length > 0)grow(minCapacity);}private void grow(int minCapacity) {// overflow-conscious codeint oldCapacity = elementData.length; //oldCapacity等于当前数组的长度//oldCapacity >> 1,表示二进制的向右移一位,相当于十进制的除以2int newCapacity = oldCapacity + (oldCapacity >> 1); //newCapacity = 1.5 * oldCapacityif (newCapacity - minCapacity < 0)newCapacity = minCapacity; //如果此时newCapacity还是小于我们所需要的minCapacity,那就让他等于minCapacityif (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);// minCapacity is usually close to size, so this is a win://以这个新的长度为标准重新创建,将原来数组中的元素拷贝一份到新的数组中去。Arrays.copyOf底层实现是System.arrayCopy()elementData = Arrays.copyOf(elementData, newCapacity);}
扩容的方法中包含三个个过程:
①判断需要的大小(minCapacity)是否超出了默认长度10.
②超出了就开始扩容,用他的1.5倍长度去和minCapacity作比较(有些java版本是2.5倍)。
③如果1.5倍大小还是小于所需要的minCapacity大小,那就将原来的元素复制到一个以minCapacity为长度的新数组中,并将elementData引用指向这个新数组。
可以看到,扩容的过程伴随着数组的复制。如果数组初试容量过小,假设为默认的10个大小,而我们使用ArrayList的操作时需要不断的增加元素。在这种场景下,不断的增加,意味着数组需要不断的进行扩容,扩容的过程就是数组拷贝System.arraycopy的过程,每一次扩容就会开辟一块新的内存空间和数据的复制移动(但是数组复制不需要开辟新内存空间,只需将数据进行复制),这样势必对性能造成影响。那么在这种以写为主(写会扩容,删不会缩容)场景下,提前预知性的设置一个大容量,便可减少扩容的次数,提高了性能。需要注意一点的是ensureCapacity()方法是public的,我们可以通过它手动的增加容量。
增加元素可能会进行扩容,而删除元素却不会进行缩容,如果在以删除为主的场景下使用list,一直不停的删除而很少进行增加,或者数组进行一次大扩容后,我们后续只使用了几个空间,那就会造成控件的极大浪费。这个时候我们就可以将底层的数组elementData的容量调整为当前实际元素的大小(缩容),来释放空间。
public void trimToSize() {modCount++;if (size < elementData.length) {elementData = Arrays.copyOf(elementData, size);}}
总结一下:
ArrayList底层以数组实现,允许重复,默认第一次插入元素时创建数组的大小为10,超出限制时会增加50%的容量,每次扩容都底层采用System.arrayCopy()复制到新的数组,初始化时最好能给出数组大小的预估值(采用给定值初始化)。
(3.6)ArrayList的遍历方式
ArrayList支持三种遍历方式
①通过迭代器Itertor去遍历
②随机访问,通过索引值去遍历,由于ArrayList实现了RandomAccess接口,它支持通过索引值去随机访问元素。
③foreach循环遍历
下面我们用三段程序来测试这三种遍历方法哪一个效率最高,同时展示三种遍历的写法。为了测量更为精准,我们新建三个类分别测试——randomAccessTest.java;iteratorTest.java;foreachTest.java。同时我们采用多次测量(笔者用的eclipse测试时,测试结果经常跳票)并采用纳秒计时(毫秒误差惨不忍睹)。
public class randomAccessTest {private static long startTime;private static long endTime;public static void main(String[] args){List list = new ArrayList();for(int i=0; i<1000; i++){list.add(i);}startTime = System.nanoTime();randomAccess(list);endTime = System.nanoTime();long time = endTime - startTime;System.out.println("randomAccessTime = " + time + "ns");}public static void randomAccess(List list){for(int i=0; i<list.size(); i++){}}
}
public class iteratorTest {private static long startTime;private static long endTime;public static void main(String[] args){List list = new ArrayList();for(int i=0; i<1000; i++){list.add(i);}startTime = System.nanoTime();iterator(list);endTime = System.nanoTime();long time = endTime - startTime;System.out.println("iteratorTime = " + time + "ns");}public static void iterator(List list){Iterator iter = list.iterator();while( iter.hasNext()) {iter.next();}}
}public class foreachTest {private static long startTime;private static long endTime;public static void main(String[] args){List list = new ArrayList();for(int i=0; i<1000; i++){list.add(i);}startTime = System.nanoTime();foreach(list);endTime = System.nanoTime();long time = endTime - startTime;System.out.println("foreachTime = " + time + "ms");}public static void foreach(List list){for(Object obj:list) {}}
}最终的结果大致稳定为:
randomAccessTime = 7x10^5 ns
iteratorTime = 6x10^6ns
foreachTime = 5x10^6ns
可以看到,虽然结果经常跳票,但八九不离十,randomAccessTime显然是用时最快的,毕竟少了一个数量级,这点机器还是没有算错的。也就是说遍历ArrayList时,使用随机访问(即,通过索引序号访问)效率最高,这点毋庸置疑,使用迭代器遍历的效率最低(这点是网上的答案,由于两者的测试结果处于同一个数量级,加上机器误差,这点笔者很难证实,读者可以自行验证)。
其实产生上面结果,我们并不感到意外,因为关于randomAccessTime这个接口的注释中就已经很明确的说明了这个问题:
/*** ......* As a rule of thumb, a* <tt>List</tt> implementation should implement this interface if,* for typical instances of the class, this loop:* <pre>* for (int i=0, n=list.size(); i < n; i++)* list.get(i);* </pre>* runs faster than this loop:* <pre>* for (Iterator i=list.iterator(); i.hasNext(); )* i.next();* </pre>* /* 根据经验,一个list类的实现类应当实现这个接口,对于典型的该类的实例,上面的循环快于下面的循环。
(3)LinkedList源码解析
上面我们在讲双链表的时候已经讲了linkedList的remove(),add()等关键方法,以及LinkedList的一个结点(Node)的构成。下面我们来讲一下LinkedList剩余的一些知识点:
(3.1)LinkedList的头
public class LinkedList<E>extends AbstractSequentialList<E>implements List<E>, Deque<E>, Cloneable, java.io.Serializable {
可以看到LinkedList是一个继承自AbstractSequentialList的双链表,他可以被当做堆栈,队列(实现了List接口),
双端队列(实现了Deque接口)使用。同时LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆。LinkedList 实现java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输。
(3.2)LinkedList的属性元素
transient int size = 0;/*** Pointer to first node.* Invariant: (first == null && last == null) ||* (first.prev == null && first.item != null)*/transient Node<E> first;/*** Pointer to last node.* Invariant: (first == null && last == null) ||* (last.next == null && last.item != null)*/transient Node<E> last;
其中size就是list的数量,和ArrayList一样。这个Node<E> first和Node<E> last就是节点的前继引用和后继引用,Node表示链表上的一个结点。这里再贴一遍代码,免得你忘了:
private static class Node<E> {E item;Node<E> next;Node<E> prev;Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;}}
(3.3)LinkedList的构造函数
/**构造一个空的构造函数,这个构造函数,也真够空的**/public LinkedList() {}/**构造一个包含指定collection元素的表,这些元素按照collection的迭代器返回的顺序排列**/public LinkedList(Collection<? extends E> c) {this();addAll(c);}
LinkedList就两个构造函数,一个空构造函数,一个包含指定collection的构造函数。
(3.4)LinkedList的增加方法
上面我们在讲双链表的时候讲过在指定位置插入元素的add(int index, E element)方法,现在我们补充一下其他几种添加方法:
①在双链表的尾部添加一个元素:
public boolean add(E e) {linkLast(e);return true;}void linkLast(E e) {final Node<E> l = last; //last表示双链表中的最后一个元素,l表示指向最后一个元素的引用final Node<E> newNode = new Node<>(l, e, null); //新建一个后继引用为空的新节点,后继为空,意味着他是最后一个元素last = newNode; //直接让这个新建的元素作为链表的最后一个元素就行了if (l == null) //指向原本链表最后一个元素的引用l为空,说明原来的链表是一个空链表。first = newNode; //此时让这个新建的结点元素最为第一个结点(就他一个啊)elsel.next = newNode; //否则的话,让原链表的后继引用指向我们新建的这个节点,插入完成size++;modCount++;}
②在指定索引处插入一个集合
public boolean addAll(int index, Collection<? extends E> c) {checkPositionIndex(index); //越域判断Object[] a = c.toArray();int numNew = a.length; // 要插入元素的个数if (numNew == 0)return false;Node<E> pred, succ; //申明两个节点类的前继,后继引用(这个循环就是在找出原列表中插入索引处的前后引用)if (index == size) { //索引等于链表的长度,说明是要求插在链表的最后面succ = null;pred = last; //此时后继引用为空,前继引用指向原链表的最后一个元素} else {succ = node(index); //否则后继引用指向原链表索引处的元素。node()方法我们之前讲过,二分法查找索引处元素pred = succ.prev; //前继引用指向原链表索引处元素的前一个元素,完成插入}for (Object o : a) { //遍历我们要插入的这个集合E e = (E) o;//新建一个结点,以pred作为前继引用,该for循环中每次遍历得到的collection集合中的e作为结点本身元素,//null作为后继引用。在第一次进行该循环时,通过上一个if的赋值,pred指向原链表中指定索引处的前一个元素。Node<E> newNode = new Node<>(pred, e, null); //在第一次循环遍历的时候,这个新节点就是collection集合的第一个元素if (pred == null) //如果pred为空,说明原链表为空first = newNode; //新节点等于第一个节点elsepred.next = newNode; //否则,原链表中指定索引处的前一个元素 的后继引用指向这个新节点。pred = newNode; //然后将这个pred指向这个新的节点(在第一次循环中,这个新节点表示collection集合中的第一个元素),相当于工作指针后移,然后重复上述过程。}//上述循环结束后,pred指针已经指向了collection集合的最后一个元素,此时由于succ没动过,因此他还是指向原链表中指定索引处的后一个元素if (succ == null) { //如果succ为null,和第一个if中的情况一样,说明这是在原链表的末尾插入元素last = pred; //直接让此时的pred也就是collection中的最后一个元素作为插入后链表的最后一个元素就可以了} else { //否则的话说明是在原链表中间插入元素pred.next = succ; //此时让collection中最后一个元素的后继指针指向 原链表索引处的后一个元素,完成差诶工作succ.prev = pred; //同时让succ的前继指针指向collection的最后一个元素,完成双向链表的建立}size += numNew; //增加链表长度modCount++;return true;}
这段代码中,注释已经写的很详细了,难点就是for (Object o : a)这个foreach循环中,我们插入的collection元素是如何建立双链表联系的,读者务必要仔细分析流程。
(3.5)LinkedList的删除方法
删除的方法我们上面讲双链表的时候已经说的很详细了,这个没有什么好说的,大家可以翻上去复习一下。这里我们通过LinkedList的remove()方法的几种形式,来讲一下算法选型的问题。
这个例子的来源于《数据结构与算法分析(java语言描述)》这本书,笔者觉得很典型。题目的要求是,给出一个线性表,将表中所有偶数项全部删除。
①首先第一种算法,使用普通for循环:
public class usuallyforTest {private static long startTime;private static long endTime;private static final int SIZE = 10000;public static void main(String[] args){List<Integer> arraylist = new ArrayList<Integer>(SIZE);List<Integer> linkedlist = new LinkedList<Integer>();for(int i=0; i<SIZE; i++){linkedlist.add(i);arraylist.add(i);}startTime = System.currentTimeMillis();usuallyfor(linkedlist);endTime = System.currentTimeMillis();long linkedlistTime = endTime - startTime;System.out.println("usuallyforLinkedlistTime = " + linkedlistTime + "ms");startTime = System.currentTimeMillis();usuallyfor(arraylist);endTime = System.currentTimeMillis();long arraylistTime = endTime - startTime;System.out.println("usuallyforArraylistTime = " + arraylistTime + "ms");}public static void usuallyfor(List<Integer> list){for(int i=0; i<list.size(); i++){if(list.get(i) % 2 == 0){list.remove(i);}}}
}
运行的结果是:
usuallyforLinkedlistTime = 57ms
usuallyforArraylistTime = 7ms如果我们将其中的线性表大小SIZE改为20000(扩大两倍),得到结果为:
usuallyforLinkedlistTime = 232ms
usuallyforArraylistTime = 29ms
很显然,对于ArrayList和LinkedList而言,这个算法都是时间复杂度为O(N^2)的二次算法。
public static void usuallyfor(List<Integer> list){for(int i=0; i<list.size(); i++){if(list.get(i) % 2 == 0){list.remove(i);}}}
这段代码中,对于LinkedList而言,list.get(i)方法是O(N)时间,慢在寻址;而他的remove()方法确实O(1)的。对于ArrayList而言,他的get(i)方法是O(1)的,但是remove(i)方法却是O(N)的,因为只要删除一个元素,后面的元素都要跟着向前移位,并伴随着数组的复制拷贝等耗时操作;但是他的get(i)却是O(1)的。
所以无论对谁,这种算法都不是明智的选择。但是整体上来看,ArrayList用时更少一些(1/8的量)。
②使用迭代器Iterator
public class iteratorTest {private static long startTime;private static long endTime;private static final int SIZE = 10000;public static void main(String[] args){List<Integer> arraylist = new ArrayList<Integer>(SIZE);List<Integer> linkedlist = new LinkedList<Integer>();for(int i=0; i<SIZE; i++){linkedlist.add(i);arraylist.add(i);}startTime = System.currentTimeMillis();iterator(linkedlist);endTime = System.currentTimeMillis();long linkedlistTime = endTime - startTime;System.out.println("iteratorLinkedlistTime = " + linkedlistTime + "ms");startTime = System.currentTimeMillis();iterator(arraylist);endTime = System.currentTimeMillis();long arraylistTime = endTime - startTime;System.out.println("iteratorArraylistTime = " + arraylistTime + "ms");}public static void iterator(List<Integer> list){Iterator<Integer> iter = list.iterator();while( iter.hasNext()) {if(iter.next() % 2 == 0){iter.remove();}}}
}
结果为:
iteratorLinkedlistTime = 2ms
iteratorArraylistTime = 10ms
将其中的线性表大小SIZE改为20000(扩大两倍),得到结果为:
iteratorLinkedlistTime = 4ms
iteratorArraylistTime = 34ms
显然,此时LikedList变成了O(N)一次时间,而ArrayList变成了O(N^2)二次时间,并且LinkedList所用的时间大大小于ArrayList所用的时间。为什么呢?因为此时用迭代器循环遍历时,对于linkdList的next()方法,是O(1)时间关系,remove()也是一次时间关系;但是对于ArrayList而言,rwmove()仍然是O(N)时间关系。
从这两个例子中我们可以体验到,算法的强大之处,实现同样功能,采用不同的算法,成败异变,功业相反~~妙哉!
3.总结——ArrayList和LinkedList的比较
写的太多了,不知道该怎么总结,这里直接照搬一下Java集合干货系列-(二)LinkedList源码解析这篇文章最后的总结,这篇文章写得很好,推荐读者去看一下
(1)顺序插入速度ArrayList会比较快,因为ArrayList是基于数组实现的,数组是事先new好的,只要往指定位置塞一个数据就好了;LinkedList则不同,每次顺序插入的时候LinkedList将new一个对象出来,如果对象比较大,那么new的时间势必会长一点,再加上一些引用赋值的操作,所以顺序插入LinkedList必然慢于ArrayList
(2)基于上一点,因为LinkedList里面不仅维护了待插入的元素,还维护了Entry的前置Entry和后继Entry,如果一个LinkedList中的Entry非常多,那么LinkedList将比ArrayList更耗费一些内存
(3)数据遍历的速度,看最后一部分,这里就不细讲了,结论是:使用各自遍历效率最高的方式,ArrayList的遍历效率会比LinkedList的遍历效率高一些
(4)有些说法认为LinkedList做插入和删除更快,这种说法其实是不准确的:
①LinkedList做插入、删除的时候,慢在寻址,快在只需要改变Node前后引用
②ArrayList做插入、删除的时候,慢在数组元素的批量copy,快在寻址
所以,如果待插入、删除的元素是在数据结构的前半段尤其是非常靠前的位置的时候,LinkedList的效率将大大快过ArrayList,因为ArrayList将批量copy大量的元素;越往后,对于LinkedList来说,因为它是双向链表,所以在第2个元素后面插入一个数据和在倒数第2个元素后面插入一个元素在效率上基本没有差别,但是ArrayList由于要批量copy的元素越来越少,操作速度必然追上乃至超过LinkedList。
从这个分析看出,如果你十分确定你插入、删除的元素是在前半段,那么就使用LinkedList;如果你十分确定你删除、删除的元素在比较靠后的位置,那么可以考虑使用ArrayList。如果你不能确定你要做的插入、删除是在哪儿呢?那还是建议你使用LinkedList吧,因为一来LinkedList整体插入、删除的执行效率比较稳定,没有ArrayList这种越往后越快的情况;二来插入元素的时候,弄得不好ArrayList就要进行一次扩容,记住,ArrayList底层数组扩容是一个既消耗时间又消耗空间的操作。
站在巨人的肩膀上摘苹果:
Java集合干货系列-(一)ArrayList源码解析
Java集合干货系列-(二)LinkedList源码解析
《大话数据结构》
《数据结构与算法分析(java语言描述)》
《疯狂java讲义》
转载于:https://my.oschina.net/oosc/blog/1614939
java温故笔记(二)java的数组HashMap、ConcurrentHashMap、ArrayList、LinkedList相关推荐
- Java语言基础(Java自我进阶笔记二)
Java语言基础(Java自我进阶笔记二) 一. 什么是Java 的主类结构? 1. #mermaid-svg-xWTL2A8kDyyRPexH .label{font-family:'trebuch ...
- 20145206《Java程序设计》实验二Java面向对象程序设计实验报告
20145206<Java程序设计>实验二Java面向对象程序设计实验报告 实验内容 初步掌握单元测试和TDD 理解并掌握面向对象三要素:封装.继承.多态 初步掌握UML建模 熟悉S.O. ...
- Java基础学习笔记(二)_Java核心技术(进阶)
本篇文章的学习资源来自Java学习视频教程:Java核心技术(进阶)_华东师范大学_中国大学MOOC(慕课) 本篇文章的学习笔记即是对Java核心技术课程的总结,也是对自己学习的总结 文章目录 Jav ...
- JAVA基础整理(二):数组
记录JAVA基础,主要是数组部分的知识点. 该系列文章仅供自己复习使用,记录学习过程中遇到的值得注意的问题,并非记录全部知识点细节. 文章目录 前言 一.什么是数组 1.数组的部分注意事项 2.数组的 ...
- 黑马程序员并发编程笔记(二)--java线程基本操作和理解
3.java进程的基本操作 3.1.创建进程 方法一,直接使用 Thread // 构造方法的参数是给线程指定名字,,推荐给线程起个名字(用setName()也可以) Thread t1 = new ...
- java面试题总结(二)----java中级面试题 含答案
一.Java基础 1. 实例方法和静态方法有什么不一样? 2. Java中的异常有哪几类?分别怎么使用? 检出异常,非检出异常.检出异常需要try...catch才能编译通过.非检出异常不用try.. ...
- 《深入理解java虚拟机》笔记1——Java内存区域与Java对象
运行时数据区域 JVM载执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域.这些区域都有各自的用途,以及创建和销毁的时间,有的区域随着虚拟机进程的启动而存在,有些区域则是依赖用户线程 ...
- Java SE 学习笔记5 Java阶段复习
计算机.Java基础 一.计算机 1.硬件介绍 2.中央处理器 3.比特(bit)和字节(byte) 4.内存 5.存储设备 6.输入和输出设备 二.Java介绍 1.常用的dos命令 2.java语 ...
- JAVA笔试题笔记(二)
2016广联达笔试题 一.解释操作系统中heap和stack的区别 1.heap是堆,stack是栈. 2.stack的空间由操作系统自动分配和释放,heap的空间是手动申请和释放的(Java中是由垃 ...
最新文章
- Python 元组的使用
- INODE上网IP地址刷新超时处理
- 安装Oracle10g on RedHat as 4 64bit
- 推荐系统笔记:矩阵分解+基于邻居的模型
- PHP中的错误控制运算符
- 处于计算机学科的基础地位,谈谈离散数学在计算机学科中的地位和作用(原稿)...
- javaScript中const,var,let区别与用法详解
- springboot响应结果超长(7.8M)浏览器无法接收
- NYOJ 85:有趣的数(打表,规律)
- Benelux Algorithm Programming Contest Final-B解题报告
- 「leetcode」236. 二叉树的最近公共祖先:【递归与回溯】详解
- MRP存在的七大缺陷,你造吗?
- 机器学习必须要会的:方差、标准差、相对标准偏差、正态分布的概念
- 怎么用计算机弹植物大战僵尸,[原创] CE基础-自动汇编:植物大战僵尸之子弹回旋...
- android点击特效,android 点击特效动画
- nginx的网页压缩以及图片的压缩
- Java基础——类与对象
- 施一公:如何做一名优秀的博士生
- LPC2478(6)UART
- 【ORACLE】关于多态表函数PTF(Polymorphic Table Functions)的使用
热门文章
- java enummap_Java EnumMap size()方法与示例
- 为什么要返回softmax_为什么softmax搭配cross entropy是解决分类问题的通用方案?
- 数据挖掘肿瘤预测_Nature Medicine封面文章:利用单核细胞数量预测及评估肿瘤免疫治疗效果...
- app调html页面,app界面管理(风格色调).html
- C语言模拟实现标准库函数之strcmp()
- php显示时间,php实现用已经过去多长时间的方式显示时间
- Qt Creator 窗体控件自适应窗口大小布局
- 每日一题:leetcode90.子集贰
- Linux系统【五】进程间通信-共享内存mmap
- Linux命令【四】文件+虚拟内存+常用系统函数