我们如何在Pinterest Ads中使用AutoML,多任务学习和多塔模型
Ernest Wang | Software Engineer, Ads Ranking
欧内斯特·王| 软件工程师,广告排名
People come to Pinterest in an exploration mindset, often engaging with ads the same way they do with organic Pins. Within ads our mission is to help Pinners go from inspiration to action by introducing them to the compelling products and services that advertisers have to offer. A core component of the ads marketplace is predicting engagement of Pinners based on the ads we show them. In addition to click prediction, we look at how likely a user is to save or hide an ad. We make these predictions for different types of ad formats (image, video, carousel) and in context of the user (e.g., browsing the home feed, performing a search, or looking at a specific Pin.)
人们以探索的心态来到Pinterest,通常以与有机Pins相同的方式参与广告。 在广告中,我们的任务是通过向广告客户提供引人注目的产品和服务,帮助Pinners从灵感变为行动。 广告市场的核心组成部分是根据我们展示给他们的广告来预测Pinner的参与度。 除了点击预测之外,我们还将研究用户保存或隐藏广告的可能性。 我们针对不同类型的广告格式(图像,视频,轮播)以及针对用户的情况(例如,浏览家庭供稿,执行搜索或查看特定的Pin)做出这些预测。
In this blog post, we explain how key technologies, such as AutoML, DNN, Multi-Task Learning, Multi-Tower models, and Model Calibration, allow for highly performant and scalable solutions as we build out the ads marketplace at Pinterest. We also discuss the basics of AutoML and how it’s used for Pinterest Ads.
在此博客文章中,我们将解释在我们建立Pinterest广告市场时,诸如AutoML,DNN,多任务学习,多塔模型和模型校准之类的关键技术如何提供高性能和可扩展的解决方案。 我们还将讨论AutoML的基础知识以及如何将其用于Pinterest Ads。
自动语言 (AutoML)
Pinterest’s AutoML is a self-contained deep learning framework that powers feature injection, feature transformation, model training and serving. AutoML features a simple descriptive template to fuse varieties of pre-implemented feature transforms such that the deep neural networks are able to learn from raw signals. This significantly eases the human labor in feature engineering. AutoML also provides rich model representations where state-of-the-art machine learning techniques are employed. We developed ads CTR prediction models with AutoML, which has resulted in substantial outcomes.
PinterestAutoML是一个独立的深度学习框架,可支持功能注入,功能转换,模型训练和服务。 AutoML具有一个简单的描述性模板,可以融合各种预先实现的特征转换,从而使深度神经网络能够从原始信号中学习。 这极大地减轻了要素工程中的人力。 AutoML还使用最先进的机器学习技术,提供了丰富的模型表示。 我们使用AutoML开发了广告点击率预测模型,从而产生了可观的结果。
特征处理 (Feature processing)
While many data scientists and machine learning engineers believe that feature engineering is more of an art than science, AutoML finds many common patterns in this work and automates the process as much as possible. Deep learning theory has demonstrated that deep neural networks (DNN) can approximate arbitrary functions if provided enough resources. AutoML leverages this advantage and enables us to directly learn from raw features by applying a series of predefined feature transform rules.
尽管许多数据科学家和机器学习工程师认为功能工程比科学更是一门艺术,但AutoML在这项工作中发现了许多常见的模式,并尽可能地使过程自动化。 深度学习理论表明,如果提供足够的资源,深度神经网络(DNN)可以近似任意函数。 AutoML充分利用了这一优势,使我们能够通过应用一系列预定义的特征转换规则直接从原始特征中学习。
AutoML firstly characterizes the features into generic signal formats:
AutoML首先将特征表征为通用信号格式:
Continuous: single floating point value feature that can be consumed directly
连续 :可直接使用的单个浮点值功能
OneHot: single-valued categorical data that usually go through an embedding lookup layer, e.g., user country and language
OneHot :通常通过嵌入查找层进行的单值分类数据,例如,用户国家/地区和语言
Indexed: multi-hot categorical features that usually go through embedding and then projection/MLP summarize layers
索引 :通常通过嵌入然后投影/ MLP汇总层的多热点分类特征
Hash_OneHot: one-hot data with unbounded vocabulary size
Hash_OneHot :词汇量无限制的一键数据
Hash_Indexed: indexed data with unbounded vocabulary size
Hash_Indexed :具有无限制词汇量的索引数据
Dense: a dense floating point valued vector, e.g., GraphSage [6] embeddings
密集:密集的浮点值向量,例如GraphSage [6]嵌入
Then the feature transforms are performed according to the signal format and the statistical distribution of the raw signal:
然后根据信号格式和原始信号的统计分布执行特征变换:
- Continuous and dense features usually go through squashing or normalization
连续且密集的特征通常会经过挤压或归一化 - One-hot and multi-hot encoded signals will be looked up embeddings and be projected
一热和多热编码信号将被查找嵌入并被投影 - Categorical signals with unbounded vocabulary are hashed and converted to one-hot and multi-hot signals
词汇量不受限制的分类信号被散列并转换为单热点和多热点信号
This way the usually tedious feature engineering work can be saved, as the machine learning engineers can focus more on the signal quality and modeling techniques.
这样,由于机器学习工程师可以将更多精力放在信号质量和建模技术上,因此可以节省通常繁琐的特征工程工作。
模型结构 (Model structure)
AutoML leverages state-of-the-art deep learning technologies to empower ranking systems. The model consists of multiple layers that have distinct, yet powerful, learning capabilities.
AutoML利用最先进的深度学习技术来支持排名系统。 该模型由具有独特但强大的学习能力的多层组成。
The representation layer: The input features are formulated in the representation layer. The feature transforms described in the previous section are applied on this layer.
表示层 :输入要素在表示层中制定。 上一节中描述的特征转换将应用于此层。
The summarization layer: Features of the same type (e.g., Pin’s category vector and Pinner’s category vector) are grouped together. A common representation (embedding) is learned to summarize the signal group.
汇总层:相同类型的特征(例如,Pin的类别向量和Pinner的类别向量)被分组在一起。 学习通用表示(嵌入)以总结信号组。
The latent cross layer: The latent cross layers concatenate features from multiple signal groups and conduct feature crossing with multiplicative layers. Latent crossing enables high degree interactions among features.
潜在交叉层:潜在交叉层连接来自多个信号组的要素,并与乘法层进行要素交叉。 潜在交叉可实现要素之间的高度交互。
The fully connected layer: The fully connected (FC) layers implement the classic deep feed-forward neural network.
全连接层:全连接(FC)层实现了经典的深度前馈神经网络。
重点学习 (Key learnings)
As sophisticated as AutoML is, the framework can be sensitive to errors or noises introduced to the system. It’s critical to ensure the model’s stability to maximize its learning power. We find that several factors affect the quality of AutoML models significantly during our development:
就像AutoML一样复杂,该框架可能对引入系统的错误或噪声敏感。 确保模型的稳定性以最大化其学习能力至关重要。 我们发现在我们的开发过程中,有几个因素会严重影响AutoML模型的质量:
Feature importance: AutoML gives us a chance to revisit signals used in our models. Some signals that stood out in the old GBDT models (see the Calibration section) are not necessarily significant in DNNs, and vice versa. Bad features are not only useless to the model, the noises introduced may potentially deteriorate it. A feature importance report is thus developed with the random permutation [7] technique, which facilitates model development very well.
功能重要性: AutoML使我们有机会重新审视模型中使用的信号。 在旧的GBDT模型中突出的某些信号(请参阅“校准”部分)在DNN中不一定很重要,反之亦然。 不良特征不仅对模型没有用处,而且引入的噪声可能会使模型恶化。 因此,使用随机置换[7]技术开发了一种功能重要性报告,这非常有利于模型开发。
The distribution of feature values: AutoML relies on the “normal” distribution of feature values since it skips human engineering. The feature transforms defined in the representation layer may sometimes, however, fail to capture the extreme values. They will disrupt the stability of the subsequent neural networks, especially the latent cross layers where extreme values are augmented and are passed to the next layer. Outliers in both training and serving data must be properly managed.
特征值的分布: AutoML依靠特征值的“正态”分布,因为它跳过了人工工程。 但是,有时在表示层中定义的特征转换可能无法捕获极值。 它们将破坏后续神经网络的稳定性,尤其是潜伏的交叉层,其中极值会增加并传递到下一层。 训练和服务数据中的异常值必须得到适当管理。
Normalization: (Batch) normalization is one of the most commonly used deep learning techniques. Apart from it, we find that minmax normalization with value clipping is particularly useful for the input layer. It’s a simple yet effective treatment to the outliers in feature values as mentioned above.
规范化:(批量)规范化是最常用的深度学习技术之一。 除此之外,我们发现带有值裁剪的minmax归一化对于输入层特别有用。 如上所述,这是一种针对特征值的异常值的简单有效的处理方法。
多任务多塔 (Multi-task and multi-tower)
Besides clickthrough rate (CTR) prediction, we also estimate other user engagement rates as a proxy to the comprehensive user satisfaction. Those user engagements include but not are not limited to good clicks (click throughs where the user doesn’t bounce back immediately), and scroll ups (user scrolls up on the ad to reach more content on the landing page). DNNs allow us to learn multi-task models. Multi-task learning (MTL) [1] has several advantages:
除了点击率(CTR)预测之外,我们还估算其他用户参与率,以代替用户的综合满意度。 这些用户互动包括但不限于良好的点击(用户不会立即反弹的点击次数)和向上滚动(用户向上滚动广告以在目标网页上获得更多内容)。 DNN使我们能够学习多任务模型。 多任务学习(MTL)[1]有几个优点:
Simplify system: Learning a model for each of the engagement types and housekeeping them can be a difficult and tedious task. The system will be much simplified and the engineering velocity will be improved if we can train more than one of them at the same time.
简化系统 :为每种参与类型学习一个模型并将其整理内幕是一项艰巨而繁琐的任务。 如果我们可以同时训练其中一个以上的系统,它将大大简化系统并提高工程速度。
Save infra cost: With a common underneath model that is shared by multiple heads, repeated computation can be minimized at both serving and training time.
节省基础成本 :通过由多个负责人共享的通用底层模型,可以在服役和训练时间将重复计算减至最少。
Transfer knowledge across objectives: Learning different yet correlated objectives simultaneously enables the models to share knowledge from each other.
跨目标转移知识 :同时学习不同但相关的目标,可使模型彼此共享知识。
Each of the engagement types is defined as an output of the model. The loss function of an MTL model looks like:
每种参与类型都定义为模型的输出。 MTL模型的损失函数如下所示:
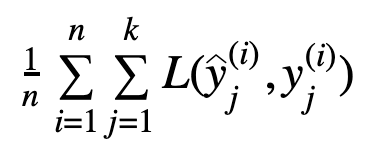
Where n denotes the number of examples, k the number of heads, y^ and y the prediction and true label, respectively.
其中n表示示例数, k表示头数, y和y分别是预测和真实标签。
Apart from MTL, we face another challenge with the Pinterest Shopping and Standard ads products, which are distinct in many ways:
除了MTL,我们还面临Pinterest购物和标准广告产品的另一项挑战,这些产品在许多方面都与众不同:
Creatives: The images of Standard Ads are partners’ creatives; Shopping Ads are crawled from partners’ catalogs.
广告素材 :标准广告的图像是合作伙伴的广告素材; 购物广告从合作伙伴的目录中抓取。
Inventory size: Shopping Ads’ inventory is multitudes bigger than Standard Ads
广告空间大小:购物广告的广告空间比标准广告大很多
Features: Shopping Ads have unique product features like texture, color, price, etc.
功能 :购物广告具有独特的产品功能,例如质地,颜色,价格等。
User behavior patterns: Pinners with stronger purchase intention tend to engage with Shopping Ads.
用户行为模式:购买意愿更强的固定人倾向于与购物广告互动。
We had been training and serving Shopping and Standard models separately before adopting DNN. With the help of AutoML, we started consolidating the two models. We then encountered a paradox: although the individual DNN models trained with Shopping or Standard data respectively outperformed the old models, a consolidated model that learned from a combination of Shopping and Standard data did not outperform either of the old individual models. The hypothesis is that single tower structure fails to learn the distinct characteristics of the two data sources simultaneously.
在采用DNN之前,我们曾分别培训和提供购物和标准模型。 在AutoML的帮助下,我们开始整合两个模型。 然后,我们遇到了一个悖论:尽管分别使用Shopping或Standard数据训练的单个DNN模型的性能优于旧模型,但是从Shopping和Standard数据的组合中学到的合并模型却没有优于任何一个旧的单个模型。 假设是单塔结构无法同时学习两个数据源的独特特征。
The shared-bottom, multi-tower model architecture [1] was hence employed to tackle the problem. We use the existing AutoML layers as the shared bottom of the two data sources. The multi-tower structure is implemented as separate multilayer perceptrons (MLP) on top of that. Examples from each source only go through a single tower. Those from other sources are masked. For each tower, every objective (engagement type) is trained with an MLP. Figure 3 illustrates the model architecture.
因此,采用了共享底的多塔模型体系结构[1]。 我们将现有的AutoML层用作两个数据源的共享底部。 在其之上,多塔式结构被实现为单独的多层感知器(MLP)。 每个来源的示例仅通过单个塔。 来自其他来源的信息被屏蔽。 对于每座塔,每个目标(参与类型)都需要通过MLP进行训练。 图3说明了模型架构。
The multi-tower structure is effective in isolating the interference between training examples from different data sources, while the shared bottom captures the common knowledge of all the data sources.
多塔式结构可以有效地隔离来自不同数据源的训练示例之间的干扰,而共享底部则捕获了所有数据源的常识。
We evaluated the offline AUC and log-loss of the proposed multi-tower model and a single-tower baseline model. The results are summarized in Table 1. We found that the performance of the proposed model is better on both shopping and standard Ads. Especially on the shopping ads slice, we observed significant improvement. We further validated the results through online A/B tests, which demonstrate positive gains consistently as seen from the offline evaluation.
我们评估了建议的多塔模型和单塔基线模型的离线AUC和对数损失。 结果汇总在表1中。我们发现,所建议的模型在购物广告和标准广告上的效果都更好。 特别是在购物广告方面,我们看到了明显的改善。 我们通过在线A / B测试进一步验证了结果,从离线评估中可以看出,这些结果始终显示出积极的收益。

校准 (Calibration)
Calibration represents the confidence in the probability predictions, which is essential to Ads ranking. For CTR prediction models, calibration is defined as:
校准表示对概率预测的信心,这对广告排名至关重要。 对于CTR预测模型,校准定义为:
The calibration model of the Pinterest Ads ranking system has evolved through three stages:
Pinterest Ads排名系统的校准模型经历了三个阶段:
GBDT + LR hybrid [5]: Gradient boosting descent trees (GBDT) are trained against the CTR objective. The GBDT model is featurized and embedded into a logistic regression (LR) model that optimizes against the same objective. LRs by nature generate calibrated predictions.
GBDT + LR混合 [5]:针对CTR目标训练了梯度提升后裔树(GBDT)。 GBDT模型是功能化的,并嵌入到针对同一目标进行优化的逻辑回归(LR)模型中。 LR本质上会生成校准的预测。
Wide & deep: We rely on the wide component (also an LR model) of the wide & deep model [2] for calibration.
宽和深 :我们依靠宽和深模型[2]的宽组件(也是LR模型)进行校准。
AutoML + calibration layer: A lightweight Platt Scaling model [3] is trained for each of the heads of the AutoML model.
AutoML +校准层 :针对AutoML模型的每个头部训练轻量级的Platt Scaling模型[3]。
The AutoML + calibration layer approach is the latest milestone for the calibration models.
AutoML +校准层方法是校准模型的最新里程碑。
As described above, we have been relying on the LR models to calibrate the prediction of engagement rates. The solution has several drawbacks:
如上所述,我们一直依靠LR模型来校准参与率的预测。 该解决方案有几个缺点:
- The wide (LR) model usually contains millions of features, most of which are ID features and cross features. The sparsity of the model is high. While the LR does a good job memorizing many critical signals, it requires a large number of training examples to converge. Our models often have difficulty capturing some transient trend in the change of Ads inventory or user behavior (e.g., a trending event or topic).
宽(LR)模型通常包含数百万个特征,其中大多数是ID特征和交叉特征。 该模型的稀疏性很高。 LR在记住许多关键信号方面做得很好,但它需要大量的训练示例来收敛。 我们的模型通常难以捕捉到广告库存或用户行为(例如趋势事件或主题)变化中的一些瞬态趋势。 - The LR model fails to learn the non-linearity and high order interactions of features, which are DNNs’ strength.
LR模型无法学习特征的非线性和高阶相互作用,这是DNN的优势。
We push all the sparse features to the AutoML model. The AutoML’s DNN models tend to be not calibrated well [4]. We then create a lightweight Platt Scaling model (essentially an LR model) with a relatively small number of signals for calibration. The signals in the calibration layer include contextual signals (country, device, time of day, etc.), creative signals (video vs image) and user profile signals (language, etc.). The model is both lean and dense, which enables it to converge fast. We are able to update the calibration layer hourly, when the DNNs are updated daily.
我们将所有稀疏功能推入AutoML模型。 AutoML的DNN模型往往没有得到很好的校准[4]。 然后,我们创建一个轻量级的Platt Scaling模型(本质上是LR模型),并使用相对较少的信号进行校准。 校准层中的信号包括上下文信号(国家,设备,一天中的时间等),创意信号(视频与图像)和用户配置文件信号(语言等)。 该模型既瘦又密集,因此可以快速收敛。 当DNN每天更新时,我们能够每小时更新一次校准层。
The new calibration solution reduced the day-to-day calibration error by as much as 80%.
新的校准解决方案将日常校准误差降低了多达80% 。
More specifically, we found two technical nuances about the calibration model: negative downsampling and selection bias.
更具体地说,我们发现了有关校准模型的两个技术细微差别:负下采样和选择偏差。
负下采样 (Negative downsampling)
Negative examples in the training data are downsampled to keep labels balanced [5]. The prediction p generated by the model is rescaled with downsampling rate w to ensure the final prediction q is calibrated:
对训练数据中的负样本进行下采样以保持标签的平衡[5]。 使用下采样率w重新缩放模型生成的预测p ,以确保对最终预测q进行了校准:
This formula doesn’t hold with multi-task learning, because the ratio between different user engagements are non-deterministic. Our solution is to set a base downsampling rate on one of the tasks (say the CTR head); the rescaling multiplier of other tasks are estimated dynamically during each training batch according to the base rate and the ratio in the number of engagements between other tasks and the base.
该公式不适用于多任务学习,因为不同的用户参与度之间的比率是不确定的。 我们的解决方案是为其中一项任务(例如CTR标头)设置基本下采样率; 在每个训练批次中,根据基本比率和其他任务与基础之间的参与次数之比,动态估算其他任务的重新调整乘数。
选择偏见 (Selection bias)
Our ads models are trained over user action logs. The selection bias is inevitable when the training examples are generated by other models. The intuition lies in the fact that the new model never has the exposure to the examples that are not selected by the old model. As a result, we often observe that newly trained models are always mis-calibrated when they are put on for experimentation. The calibration is usually fixed after ramping up, with the hypothesis that they are less affected by selection bias with a larger portion of examples generated by themselves.
我们的广告模型是根据用户操作日志进行训练的。 当训练示例由其他模型生成时,选择偏差是不可避免的。 直觉在于新模型永远不会暴露于旧模型未选择的示例。 结果,我们经常观察到,新训练的模型在进行实验时总是被错误校准。 校准通常是在加速后固定的,其假设是,选择偏差对它们的影响较小,而大部分示例是由它们自己生成的。
While we don’t aim at fundamentally fixing the selection bias, a small trick helps us mitigate the issue: we train the calibration layer only with the examples generated by its own. The underlying DNN models are still trained with all the examples available to ensure convergence. The lightweightness of the calibration model, however, doesn’t need a lot of training data to converge. That way the calibration layer can learn from the mistakes made by itself and the results are surprisingly good: the newly trained models are as well calibrated as the production model during A/B testing, even with lower traffic.
虽然我们的目标不是从根本上解决选择偏差问题,但有一个小技巧可以帮助我们缓解这一问题:我们仅使用自己生成的示例来训练校准层。 仍会使用所有可用示例来训练基础DNN模型,以确保收敛。 但是,校准模型的轻巧性并不需要大量的训练数据即可收敛。 这样,校准层可以从自身的错误中学习,并且结果出奇的好:在A / B测试过程中,即使是在流量较低的情况下,新训练的模型也可以像生产模型一样进行校准。
结论 (Conclusion)
AutoML has equipped our multi-task ads CTR models with automatic feature engineering and state-of-the-art machine learning techniques. The multi-tower structure enables us to learn from data sources with distinct characteristics by isolating the interference from one another. This innovation has driven significant improvement in values for Pinners, advertisers and Pinterest. We also learned that a lightweight Platt Scaling model can effectively calibrate the DNN predictions and mitigate selection bias. As future work, we will make the AutoML framework more extensible so we can try more deep learning techniques such as sequence models.
AutoML为我们的多任务广告点击率模型配备了自动功能工程和最新的机器学习技术。 多塔式结构使我们能够通过相互隔离干扰来学习具有鲜明特征的数据源。 这项创新推动了Pinners,广告商和Pinterest价值显着提高。 我们还了解到,轻量级的Platt Scaling模型可以有效地校准DNN预测并减轻选择偏差。 在将来的工作中,我们将使AutoML框架更具可扩展性,因此我们可以尝试更多的深度学习技术,例如序列模型。
致谢 (Acknowledgements)
This article summarizes a three-quarter work that involved multiple teams of Pinterest. The author wants to thank Minzhe Zhou, Wangfan Fu, Xi Liu, Yi-Ping Hsu and Aayush Mudgal for their tireless contributions. Thanks to Xiaofang Chen, Ning Zhang, Crystal Lee and Se Won Jang for many meaningful discussions. Thanks to Jiajing Xu, Xin Liu, Mark Otuteye, Roelof van Zwol, Ding Zhou and Randall Keller for the leadership.
本文总结了涉及多个Pinterest团队的四分之三的工作。 作者要感谢周敏哲,王望富,刘曦,徐一平和Aayush Mudgal的不懈贡献。 感谢Chen Xiaofang,Ning Zhang,Crystal Lee和Se Won Jang进行了许多有意义的讨论。 感谢徐嘉靖,刘鑫,马克·奥图蒂,罗洛夫·范兹沃,丁周和兰德尔·凯勒的领导。
翻译自: https://medium.com/pinterest-engineering/how-we-use-automl-multi-task-learning-and-multi-tower-models-for-pinterest-ads-db966c3dc99e
相关文章:
- python实现链表(一)
- 小型仓库管理系统MySQL
- MySQL 数据库基础(一)(数据库的简介)
- 数据库简介与 Mysql 服务基础
- 初学ue4#2 制作3d视角人物part2
- Cocos Creator 3.2 中实现2D地图3D人物45度角RPG游戏效果笔记(摄像机设置方案)
- 怎么画动漫人物的头
- 【经验】漫画中人物手臂怎么画?
- unity3d实现场景右下角人物小地图(可显示出地图上人物的位置以及boss或者其他重要坐标的小图标)
- unity3d之角色的移动篇 -- 俯视视角下的键盘移动
- Unity之升高人物视野
- 【YoLov5实战】记录一次不太成功的实战,足球场人物识别
- 人物的喜怒哀乐怎么画?动漫人物表情怎么画?
- 【透视课笔记】L2室内空间与人物
- UE4-蓝图-角色的移动,视角控制(四)人物瞄准偏移(视角自由转动)
- unity 2d文字跟随主角移动_使用 Unity 粒子系统实现 2D 人物足迹效果
- 关于Unity3D的初步学习研究周记
- 文学-人物:司马迁
- 零经验小白的独游历程——俯视角45度游戏,人物用2D还是3D
- 仅仅有人物没背景的图片怎么弄_纯干货//只会画人物不会画背景?这3种方法教你快速画背景!...
- 仅仅有人物没背景的图片怎么弄_只会画人物不会画背景?这3种方法教你快速画背景!...
- 【Unity俯视角射击】我们来做一个《元气骑士》的完整Demo1
- unity3d俯视角简易移动控制脚本及其易错点小分享
- 简单人物画像_怎样把复杂的人物肖像画简单化
- unity学习———2D人物的移动
- 向左还是向右?Unity中俯视视角下人物智能转向的控制方法
- [Unity实践笔记] 俯视视角人物360°移动脚本
- NCBI中各个符号代表意思
- 根据GSE号在NCBI批量获取文献
- HttpMessageConverter
我们如何在Pinterest Ads中使用AutoML,多任务学习和多塔模型相关推荐
- 深度学习中的多任务学习(一)
任务学习-Multitask Learning概述 Reference https://blog.csdn.net/u010417185/article/details/83065506 1.单任务学 ...
- adobe xd_如何在Adobe XD中创建简历简历网站模板
adobe xd 在本Adobe XD教程中,您将学习如何使用简历网站模板创建简历网页设计. 您还将学习如何轻松对其元素的各个部分进行动画处理. 您将在此Adobe XD教程中学到什么: 如何在Ado ...
- adb shell读取返回值_如何在ADB shell中读取耳机状态和读取ACCDET寄存器
如何在ADB shell中读取耳机状态和读取ACCDET寄存器 录入:edatop.com 点击: [Description] 如何在ADB shell中读取耳机状态和读取ACCDET寄存器 [ ...
- 如何在sqlite3连接中创建并调用自定义函数
#!/user/bin/env python # @Time :2018/6/8 14:44 # @Author :PGIDYSQ #@File :CreateFunTest.py '''如何在sql ...
- Iar环境c语言调用汇编函数,如何在IAR EWARM中通过内联汇编程序在另一个模块中调用C函数?...
我在硬故障处理程序中有一些程序集.程序集基本上是为了传递当前堆栈指针作为参数(在R0中).它看起来像这样...如何在IAR EWARM中通过内联汇编程序在另一个模块中调用C函数? __asm(&quo ...
- 学习如何在AutoCad土木工程中绘制建筑设计图
学习如何在AutoCad中绘制建筑设计图从平面图到AutoCad土木工程中的整栋建筑 你会学到: 如何绘制房屋地图 如何绘制建筑设计 如何从AutoCad打印或出图 AutoCaD使用 AutoCaD ...
- 如何在OS X中打印到PDF文件
如何在OS X中打印文件到PDF文件? 其实不需要安装任何其他软件,OS X本身支持打印到PDF文件这个功能. 具体操作详见下面文章: Want to save a document or web p ...
- 转 如何在IOS设备中去掉屏幕上的status bar
引入 如何在IOS设备中去掉屏幕上的status bar,即:不显示设备上方的[网络.时间.电池??]条? 操作 方法一: 在-info.list项目文件中,加上"Status bar is ...
- react中纯函数_如何在纯React中创建电子邮件芯片
react中纯函数 by Andreas Remdt 由Andreas Remdt 如何在纯React中创建电子邮件芯片 (How to create email chips in pure Reac ...
最新文章
- Python使用matplotlib函数subplot可视化多个不同颜色的折线图、自定义数据点的形状、自定义折线图的颜色
- R语言构建catboost模型:构建catboost模型并基于网格搜索获取最优模型参数(Select hyperparameters)、计算特征重要度
- 深度学习基础——激活函数以及什么时候使用它们?
- 用Python递归做个多层次的文件执行
- break与continue的的用法以及区别
- java springmvc 数据库事务_事务的简单回顾_JavaEE框架(Maven+SpringMvc+Spring+MyBatis)全程实战教程_Java视频-51CTO学院...
- python字符串格式化_Python3 字符串格式化
- PySpark+Windows开发环境的搭建
- 网络疯传IT男女标配图
- PID控制算法的C语言实现十 模糊算法简介
- 行人重识别论文阅读5-基于换衣服的行人重识别
- 宇枫资本投资理财的几大定律
- 解决桌面单击右键反应慢的问题
- HDU 4238 You Are the One
- blender2.8 bpy.data.images.new创建的图片返回值撤回操作后丢失
- oracle逗号隔开行转列_oralce逗号分割变多行-Oracle
- Dubbo剖析-粘包与半包问题(一)
- 新三板公司股权激励设计注意事项
- 一个基层管理者需要做好的几个方面
- 跟你聊聊员工的离职成本,细算下来超级恐怖!