决策树的生成与剪枝CART
跟我一起机器学习系列文章将首发于公众号:月来客栈,欢迎文末扫码关注!
在之前的一篇文章中,笔者分别介绍了用ID3和C4.5这两种算法来生成决策树。其中ID3算法每次用信息增益最大的特征来划分数据集,C4.5算法每次用信息增益比最大的特征来划分数据集。接下来,我们再来看另外一种采用基尼指数为标准的划分方法,CART算法。
1 CART算法
分类与回归算法(Classification and Regression Tree,CAR),即可以用于分类也可以用于回归,它是应用最为广泛的决策树学习方法之一。CART假设决策树是二叉树,内部节点特征的取值均为“是”和“否”,左分支是取值为“是”的分支,右分支是取值为“否”的分支。这样的决策树等价与递归地二分每个特征,将输入空间即特征空间划分为有限个单元。
CART算法由以下两步组成:
(1)决策树生成:基于训练数据集生成决策树,生成的决策树要尽量最大;
(2)决策树剪枝:用验证集对已生成的树进行剪枝并选择最优子树,这时用损失函数最小作为剪枝标准。
2 分类树
在介绍分类树的生成算法前,我们先介绍一下划分标准基尼指数(gini index)。
2.1 基尼指数
在分类问题中,假设数据包含有KKK个类别,样本点属于第kkk类的概率为pk\large p_{\small k}pk,则概率分布的基尼指数定义为:
Gini(p)=∑k=1Kpk(1−pk)=1−∑k=1Kpk2(1)Gini(p)=\sum_{k=1}^K\large p_{\small k}(1-\large p_{\small k})=1-\sum_{k=1}^K\large p_{\small k}^2\tag{1} Gini(p)=k=1∑Kpk(1−pk)=1−k=1∑Kpk2(1)
因此,对于给定的样本集合DDD,其基尼指数为:
Gini(D)=1−∑k=1K(∣Ck∣∣D∣)2(2)Gini(D)=1-\sum_{k=1}^K\left(\frac{|C_k|}{|D|}\right)^2\tag{2} Gini(D)=1−k=1∑K(∣D∣∣Ck∣)2(2)
其中,CkC_kCk是DDD中属于第kkk类的样本子集,KKK是类别的个数。
如果样本集合DDD根据特征AAA是否取某一可能值aaa被分割成D1,D2D_1,D_2D1,D2两个部分,即
D1={(x,y)∈D∣A(x)=a},D2=D−D1D_1=\{(x,y)\in D|A(x)=a\},D_2=D-D_1 D1={(x,y)∈D∣A(x)=a},D2=D−D1
则在特征AAA的条件下,集合DDD的基尼指数定义为(类似于条件熵的感觉):
Gini(D,A)=∣D1∣∣D∣Gini(D1)+∣D2∣∣D∣Gini(D2)(3)Gini(D,A)=\frac{|D_1|}{|D|}Gini(D_1)+\frac{|D_2|}{|D|}Gini(D_2)\tag{3} Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)(3)
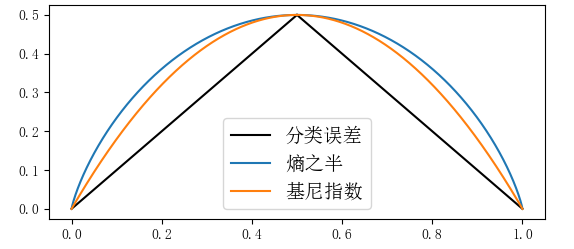
基尼指数Gini(D)Gini(D)Gini(D)表示集合DDD的不确定性,即表示经A=aA=aA=a分割后集合DDD的不确定性。基尼指数越大,样本集合的不确定性也就越大,这点与信息熵相似。下图是基尼指数、熵之半12H(p)\frac{1}{2}H(p)21H(p)和分类误差率之间的关系。横坐标表示概率,纵坐标表示损失。可以看出基尼指数和熵之半的曲线很接近,都可以近似的表示分类误差率。
2.2 生成算法
输入:训练数据集DDD,停止计算条件;
输出:CART决策树
根据训练集,从根节点开始,递归地对每个节点进行如下操作,构建二叉决策树:
(1)设节点的训练集为DDD,利用公式(2)(2)(2)计算现有特征对该数据集的基尼指数。此时,对于每一个特征AAA,对其可能的每一个值aaa,根据样本点对A=aA=aA=a的测试为“是”或“否”将DDD分割成D1,D2D_1,D_2D1,D2两个部分,利用公式(3)(3)(3)计算A=aA=aA=a时的基尼指数;
(2)在所有可能的特征AAA以及它们所有可能的切分点aaa中,选择基尼指数最小的特征作为划分标准将原有数据集划分为两个部分,并分配到两个子节点中去;
(3)对两个子节点递归的调用(1),(2),直到满足停止条件;
(4)生成CART决策树
其中,算法停止计算的条件是:节点中的样本点个数小于预定阈值,或样本集的基尼指数小于预定阈值(也就是说此时样本基本属于同一类),或者没有更多特征。
2.3 生成示例
同样我们还是拿之前的数据集来走一遍生成流程:
ID年龄有工作有自己的房子贷款情况类别1青年否否一般否2青年否否好否3青年是否好是4青年是是一般是5青年否否一般否6中年否否一般否7中年否否好否8中年是是好是9中年否是非常好是10中年否是非常好是11老年否是非常好是12老年否是好是13老年是否好是14老年是否非常好是15老年否否一般否\begin{array}{c|cc} \hline ID&\text{年龄}&\text{有工作}&\text{有自己的房子}&\text{贷款情况}&\text{类别}\\ \hline 1&\text{青年}&\text{否}&\text{否}&\text{一般}&\text{否}\\ 2&\text{青年}&\text{否}&\text{否}&\text{好}&\text{否}\\ 3&\text{青年}&\text{是}&\text{否}&\text{好}&\text{是}\\ 4&\text{青年}&\text{是}&\text{是}&\text{一般}&\text{是}\\ 5&\text{青年}&\text{否}&\text{否}&\text{一般}&\text{否}\\ \hline 6&\text{中年}&\text{否}&\text{否}&\text{一般}&\text{否}\\ 7&\text{中年}&\text{否}&\text{否}&\text{好}&\text{否}\\ 8&\text{中年}&\text{是}&\text{是}&\text{好}&\text{是}\\ 9&\text{中年}&\text{否}&\text{是}&\text{非常好}&\text{是}\\ 10&\text{中年}&\text{否}&\text{是}&\text{非常好}&\text{是}\\ \hline 11&\text{老年}&\text{否}&\text{是}&\text{非常好}&\text{是}\\ 12&\text{老年}&\text{否}&\text{是}&\text{好}&\text{是}\\ 13&\text{老年}&\text{是}&\text{否}&\text{好}&\text{是}\\ 14&\text{老年}&\text{是}&\text{否}&\text{非常好}&\text{是}\\ 15&\text{老年}&\text{否}&\text{否}&\text{一般}&\text{否}\\ \hline \end{array} ID123456789101112131415年龄青年青年青年青年青年中年中年中年中年中年老年老年老年老年老年有工作否否是是否否否是否否否否是是否有自己的房子否否否是否否否是是是是是否否否贷款情况一般好好一般一般一般好好非常好非常好非常好好好非常好一般类别否否是是否否否是是是是是是是否
用DDD表示整个数据集,A1,A2,A3,A4A_1,A_2,A_3,A_4A1,A2,A3,A4,分别依次表示四个特征,用Ai=1,2,3...A_i=1,2,3...Ai=1,2,3...,表示每个特征的可能取值;如A2=1,A2=2A_2=1,A_2=2A2=1,A2=2,表示有工作和无工作。
由公式(2)(2)(2)可知:
Gini(D)=1−∑k=1K(∣Ck∣∣D∣)2=1−[(615)2+(915)2]=2×615×915=0.48\begin{aligned} Gini(D)=1-\sum_{k=1}^K\left(\frac{|C_k|}{|D|}\right)^2=1-\left[(\frac{6}{15})^2+(\frac{9}{15})^2\right]=2\times\frac{6}{15}\times\frac{9}{15}=0.48 \end{aligned} Gini(D)=1−k=1∑K(∣D∣∣Ck∣)2=1−[(156)2+(159)2]=2×156×159=0.48
由公式(3)(3)(3)可知:
Gini(D,A)=∣D1∣∣D∣Gini(D1)+∣D2∣∣D∣Gini(D2)Gini(D,A)=\frac{|D_1|}{|D|}Gini(D_1)+\frac{|D_2|}{|D|}Gini(D_2) Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
求特征A1A_1A1的基尼指数(注意,每次都是将其划分为两部分,即Ai=aA_i=aAi=a和Ai≠aA_i\neq aAi=a):
Gini(D,A1=1)=515Gini(D1)+1015Gini(D2)=515[2⋅25⋅(1−25)]+1015[2⋅710⋅(1−710)]=0.44Gini(D,A1=2)=515[2⋅25⋅35]+1015[2⋅410⋅610]=0.48Gini(D,A1=3)=515[2⋅15⋅45]+1015[2⋅510⋅510]=0.44\begin{aligned} Gini(D,A_1=1)&=\frac{5}{15}Gini(D_1)+\frac{10}{15}Gini(D_2)\\[1ex] &=\frac{5}{15}\left[2\cdot\frac{2}{5}\cdot(1-\frac{2}{5})\right]+\frac{10}{15}\left[2\cdot\frac{7}{10}\cdot(1-\frac{7}{10})\right]=0.44\\[1ex] Gini(D,A_1=2)&=\frac{5}{15}\left[2\cdot\frac{2}{5}\cdot\frac{3}{5}\right]+\frac{10}{15}\left[2\cdot\frac{4}{10}\cdot\frac{6}{10}\right]=0.48\\[1ex] Gini(D,A_1=3)&=\frac{5}{15}\left[2\cdot\frac{1}{5}\cdot\frac{4}{5}\right]+\frac{10}{15}\left[2\cdot\frac{5}{10}\cdot\frac{5}{10}\right]=0.44 \end{aligned} Gini(D,A1=1)Gini(D,A1=2)Gini(D,A1=3)=155Gini(D1)+1510Gini(D2)=155[2⋅52⋅(1−52)]+1510[2⋅107⋅(1−107)]=0.44=155[2⋅52⋅53]+1510[2⋅104⋅106]=0.48=155[2⋅51⋅54]+1510[2⋅105⋅105]=0.44
求特征A2,A3A_2,A_3A2,A3的基尼指数:
Gini(D,A2=1)=515[2⋅55⋅0]+1015[2⋅410⋅610]=0.32Gini(D,A3=1)=915[2⋅69⋅39]+615[2⋅66⋅0]=0.27\begin{aligned} Gini(D,A_2=1)&=\frac{5}{15}\left[2\cdot\frac{5}{5}\cdot0\right]+\frac{10}{15}\left[2\cdot\frac{4}{10}\cdot\frac{6}{10}\right]=0.32\\[1ex] Gini(D,A_3=1)&=\frac{9}{15}\left[2\cdot\frac{6}{9}\cdot\frac{3}{9}\right]+\frac{6}{15}\left[2\cdot\frac{6}{6}\cdot0\right]=0.27\\[1ex] \end{aligned} Gini(D,A2=1)Gini(D,A3=1)=155[2⋅55⋅0]+1510[2⋅104⋅106]=0.32=159[2⋅96⋅93]+156[2⋅66⋅0]=0.27
求特征A4A_4A4的基尼指数:
Gini(D,A4=1)=515[2⋅15⋅45]+1015[2⋅210⋅810]=0.32Gini(D,A4=2)=615[2⋅26⋅46]+915[2⋅49⋅59]=0.47Gini(D,A4=3)=415[2⋅44⋅0]+1115[2⋅511⋅611]=0.36\begin{aligned} Gini(D,A_4=1)&=\frac{5}{15}\left[2\cdot\frac{1}{5}\cdot\frac{4}{5}\right]+\frac{10}{15}\left[2\cdot\frac{2}{10}\cdot\frac{8}{10}\right]=0.32\\[1ex] Gini(D,A_4=2)&=\frac{6}{15}\left[2\cdot\frac{2}{6}\cdot\frac{4}{6}\right]+\frac{9}{15}\left[2\cdot\frac{4}{9}\cdot\frac{5}{9}\right]=0.47\\[1ex] Gini(D,A_4=3)&=\frac{4}{15}\left[2\cdot\frac{4}{4}\cdot0\right]+\frac{11}{15}\left[2\cdot\frac{5}{11}\cdot\frac{6}{11}\right]=0.36 \end{aligned} Gini(D,A4=1)Gini(D,A4=2)Gini(D,A4=3)=155[2⋅51⋅54]+1510[2⋅102⋅108]=0.32=156[2⋅62⋅64]+159[2⋅94⋅95]=0.47=154[2⋅44⋅0]+1511[2⋅115⋅116]=0.36
由以上计算结果我们可以知道,Gini(D,A3=1)=0.27Gini(D,A_3=1)=0.27Gini(D,A3=1)=0.27为所有基尼指数中最小者,所有A3=1A_3=1A3=1为最优划分点。于是根节点生成两个子节点,如下:
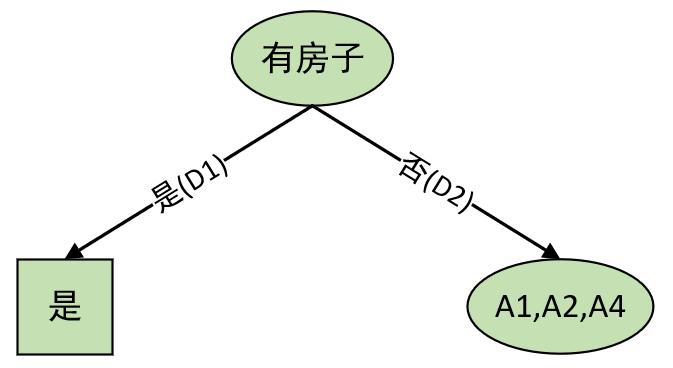
且我们发现对于“有房子左边“是”这个子节点来说,已经满足算法停止条件(均属于同一类);所有只需对另外一个子节点继续递归计算每个特征取值情况下的基尼指数即可。并且,最终我们将得到与ID3算法所生成的决策树完全一致。
2.3 剪枝算法
我们知道总体上来说,模型(决策树)越复杂,越容易导致过拟合,此时对应的代价函数值也相对较小。 所以就要进行剪枝处理。CART剪枝算法由两部组成:(1)首先是从之前生成的决策树T0T_0T0底端开始不断剪枝,直到T0T_0T0的根节点,形成一个子序列{T0,T1,...,Tn}\{T_0,T_1,...,T_n\}{T0,T1,...,Tn};(2)然后通过交叉验证对这一子序列进行测试,从中选择最优的子树。
下面的为选读内容,可自由选择是否继续阅读(如果是第一次学习可不读)
可以看出,第二步没有什么难点,关键就在于如何来剪枝生成这么一个子序列.
(1)剪枝,形成一个子序列
在剪枝过程中,计算子树的损失函数:
Cα(T)=C(T)+α∣T∣(4)C_{\alpha}(T)=C(T)+\alpha|T|\tag{4} Cα(T)=C(T)+α∣T∣(4)
其中,TTT为任意子树,C(T)C(T)C(T)为对训练集的预测误差,∣T∣|T|∣T∣为子树的叶节点个数,α≥0\alpha\geq0α≥0为参数。需要指出的是不同与之前ID3和C4.5中剪枝算法的α\alphaα,前者是人为给定的,而此处则是通过计算得到,具体见后面。
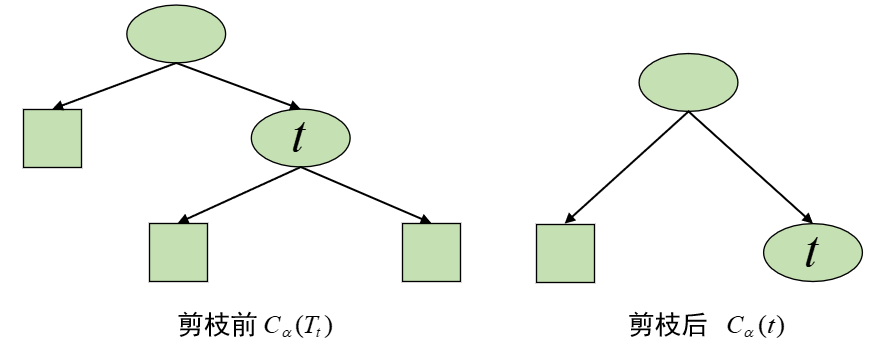
具体地,从整体树T0T_0T0开始剪枝。对T0T_0T0的任意内部节点ttt,以ttt为根节点子树TtT_tTt(可以看作是剪枝前)的损失函数是:
Cα(Tt)=C(Tt)+α∣Tt∣(5)C_{\alpha}(T_t)=C(T_t)+\alpha|T_t|\tag{5} Cα(Tt)=C(Tt)+α∣Tt∣(5)
以ttt为单节点树(可以看作是剪枝后)的损失函数是:
Cα(t)=C(t)+α⋅1(6)C_{\alpha}(t)=C(t)+\alpha\cdot1\tag{6} Cα(t)=C(t)+α⋅1(6)
①当α=0\alpha=0α=0或者极小的时候,有不等式
Cα(Tt)<Cα(t)(7)C_{\alpha}(T_t)< C_{\alpha}(t)\tag{7} Cα(Tt)<Cα(t)(7)
不等式成立的原因是因为,当α=0\alpha=0α=0或者极小的时候,起决定作用的就是预测误差C(t),C(Tt)C(t),C(T_t)C(t),C(Tt),而模型越复杂其训练误差总是越小的,因此不等式成立。
②当α\alphaα增大时,在某一α\alphaα有
Cα(Tt)=Cα(t)(8)C_{\alpha}(T_t)=C_{\alpha}(t)\tag{8} Cα(Tt)=Cα(t)(8)
等式成立的原因是因为,当α\alphaα慢慢增大时,就不能忽略模型复杂度所带来的影响(也就是式子(4)(4)(4)第二项。但由于相同取值的α\alphaα对于式子(5)(6)(5)(6)(5)(6)所对应模型的惩罚力度不同(剪枝前的惩罚力度更大),因此尽管式子(5)(6)(5)(6)(5)(6)所对应的模型复杂度均在减小(误差变大),但是(5)(5)(5)较小得更快(误差变大得更快),所以总有个时候等式会成立。
③当α\alphaα再增大时,不等式(8)(8)(8)反向。因此,当Cα(Tt)=Cα(t)C_{\alpha}(T_t)=C_{\alpha}(t)Cα(Tt)=Cα(t)时,有α=C(t)−C(Tt)∣Tt∣−1\alpha=\frac{C(t)-C(T_t)}{|T_t|-1}α=∣Tt∣−1C(t)−C(Tt),此时的子树TtT_tTt和单节点 树ttt有相同的损失函数值,但ttt的节点少模型更简单,因此ttt比TtT_tTt更可取,即对TtT_tTt进行剪枝。(注:此时的α\alphaα是通过Cα(Tt)=Cα(t)C_{\alpha}(T_t)=C_{\alpha}(t)Cα(Tt)=Cα(t)计算得到)
为此,对决策树T0T_0T0中每一个内部节点ttt来说,都可以计算
g(t)=C(t)−C(Tt)∣Tt∣−1(9)g(t)=\frac{C(t)-C(T_t)}{|T_t|-1}\tag{9} g(t)=∣Tt∣−1C(t)−C(Tt)(9)
它表示剪枝后整体损失函数减少的程度。因为每个g(t)g(t)g(t)背后都对应着一个决策树模型,而不同的g(t)g(t)g(t)则表示损失函数变化的不同程度。接着,在树T0T_0T0中减去g(t)g(t)g(t)最小的子树TtT_tTt,将得到的子树作为T1T_1T1。如此剪枝下去,直到得到根节点。
注意,此时得到的一系列g(t)g(t)g(t)即α\alphaα,都能使得在每种情况下剪枝前和剪枝后的损失值相等,因此按照上面第③种情况中的规则要进行剪枝,但为什么是减去其中g(t)g(t)g(t)最小的呢?如下图:

对于树TTT来说,其内部可能的节点ttt有t0,t1,t2,t3t_0,t_1,t_2,t_3t0,t1,t2,t3;tit_iti表示其中任意一个。因此我们便可以计算得到g(t0),g(t1),g(t2),g(t3)g(t_0),g(t_1),g(t_2),g(t_3)g(t0),g(t1),g(t2),g(t3),也即对应的α0,α1,α2,α3\alpha_0,\alpha_1,\alpha_2,\alpha_3α0,α1,α2,α3。从上面的第③种情况我们可以知道,g(t)g(t)g(t)是根据公式(9)(9)(9)所计算得到,因此这四种情况下tit_iti比TtiT_{t_i}Tti更可取,都满足剪枝。但是由于以tit_iti为根节点的子树对应的复杂度各不相同,也就意味着αi≠αj,(i,j=0,1,2,3;i≠j)\alpha_i\neq\alpha_j,(i,j=0,1,2,3;i\neq j)αi=αj,(i,j=0,1,2,3;i=j),即αi,αj\alpha_i,\alpha_jαi,αj存在着大小关系。又因为我们知道:当α\alphaα大的时候,最优子树TαT_{\alpha}Tα偏小;当α\alphaα小的时候,最优子树TαT_{\alpha}Tα偏大;且子树偏大意味着拟合程度更好。因此,在都满足剪枝的条件下,选择拟合程度更高的子树当然是最好的选择。所有选择减去其中g(t)g(t)g(t)最小的子树。
在得到子树T1T_1T1后,再通过上述步骤对T1T_1T1进行剪枝得到T2T_2T2。如此剪枝下去直到得到根节点,此时我们便得到了子树序列T0,T1,T2,....TnT_0,T_1,T_2,....T_nT0,T1,T2,....Tn。
(2)交叉验证选择最优子树TαT_{\alpha}Tα
通过第(1)步我们便可以得到一系列的子树序列T0,T1,...,TnT_0,T_1,...,T_nT0,T1,...,Tn,然后便可以通过交叉验证来选取最优决的策树TαT_{\alpha}Tα。
最后,通过sklearn来完成对于CART分类树的使用也很容易,只需要将类DecisionTreeClassifier()中的划分标准设置为criterion="gini"即可,其它地方依旧不变,可参见上一篇文章。
3 总结
在这篇文章中, 笔者首先介绍了什么是CART算法,进一步介绍了CART分类树中的划分标准基尼指数;接着详细介绍了CART分类树的生成过程,通过示例展示整个流程;最后介绍了CART分类树剪枝过程的基本原理。本次内容就到此结束,感谢阅读!
若有任何疑问与见解,请发邮件至moon-hotel@hotmail.com并附上文章链接,青山不改,绿水长流,月来客栈见!
引用
[1]《统计机器学习(第二版)》李航,公众号回复“统计学习方法”即可获得电子版与讲义
[3]《Python与机器学习实战》何宇健

决策树的生成与剪枝CART相关推荐
- 机器学习笔记(九)——决策树的生成与剪枝
一.决策树的生成算法 基本的决策树生成算法主要有ID3和C4.5, 它们生成树的过程大致相似,ID3是采用的信息增益作为特征选择的度量,而C4.5采用信息增益比.构建过程如下: 从根节点开始,计算所有 ...
- 决策树的生成之ID3与C4.5算法
跟我一起机器学习系列文章将首发于公众号:月来客栈,欢迎文末扫码关注! 1 基本概念 在正式介绍决策树的生成算法前,我们先将上一篇文章中介绍的几个概念重新梳理一下:并且同时再通过一个例子来熟悉一下计算过 ...
- 二叉树剪枝_决策树,生成剪枝,CART算法
决策树 1. 原理 1.1 模型简介 决策树是一种基本的回归和分类算法.在分类问题中,可以认为是一系列 if-then 规则的几何.决策树学通常包括三个步骤:特征选择,决策树的生成, 决策树的修剪. ...
- 决策树及决策树生成与剪枝
文章目录 1. 决策树学习 2. 最优划分属性的选择 2.1 信息增益 - ID3 2.1.1 什么是信息增益 2.1.2 ID3 树中最优划分属性计算举例 2.2 信息增益率 - C4.5 2.3 ...
- 决策树(二)——决策树的生成
说明:这篇博客是看李航老师的<统计学习方法>的笔记总结,博客中有很多内容是摘选自李航老师的<统计学习方法>一书,仅供学习交流使用. 决策树的生成 在上一篇博客决策树(一)--构 ...
- 决策树算法原理以及决策树规则生成方法
决策树算法原理以及决策树规则生成方法 决策树是一种可解释性较强的策略分析工具.creditmodel提供了分类回归树和条件推断树两种决策树生成和提取规则的方法. 每一个风险管理人员都应该掌握使用决策树 ...
- 决策树(三):CART算法
CART(分类与回归树),也就是说CART算法既可以用于分类,也可以用于回归,它是在给定输入随机变量X条件下输出随机变量Y的条件概率分布的学习方法,其也和回归树一样是二叉树. 是CART算法,也是分为 ...
- 决策树第二部分预剪枝
决策树预剪枝: 决策树可以分成ID3.C4.5和CART. 算法目的:决策树的剪枝是为了简化决策树模型,避免过拟合. 剪枝类型:预剪枝.后剪枝 预剪枝:在构造决策树的同时进行剪枝.所有决策树的构建方法 ...
- 风控策略的自动化生成-利用决策树分分钟生成上千条策略
本文重点:风控策略挖掘.策略推荐,策略发现,风控策略自动化,决策树 风控策略同学在挖掘有效的风控规则的时候,经常需要基于业务经验,将那几个特征进行组合形成风控策略,会导致在特征组合的时候浪费大量的时间 ...
最新文章
- Prolific PL2303SA 调试
- SELECT中常用的子查询操作
- docker pip 换源_Docker 部署 jupyterlab 3.0.3
- arcgis使用工具箱导出dbf_ArcGIS——好好的属性表,咋就乱码了呢?
- 深度学习必备的几款流行网络与数据集
- IOS中获取屏幕尺寸
- open wrt 跟换主题_键盘还能这样玩,个性兼实用 达尔优归燕主题
- 终于有机会获得百度SEO的邀请码了
- Atitit. 衡量项目规模 ----包含的类的数量 .net java类库包含多少类 多少个api方法??
- 数学建模方法-多项式拟合
- 等保2.0 等保二级基本要求与测评控制点
- 英语单词辨析(同类单词)
- 超级爆笑学生作文大全
- 终端文本编辑神器--Vim命令详解。如何配置使用Vim、Vim插件?
- 管理学中的纳什均衡理论分享
- 火车头采集细节(一)
- CSS Text Decoration
- 递归:这帮小兔子崽子、汉诺塔游戏+习题复习
- 《系统工程》--课程笔记一(SE及系统科学体系)
- 联系人管理-客户拜访记录| CRM客户关系管理系统项目 实战七(Struts2+Spring+Hibernate)解析+源代码