InnoDB引擎Myslq数据库数据恢复
2019独角兽企业重金招聘Python工程师标准>>> 
首先祝愿看到这片文章的你永远不要有机会用到它...
本文指针对用InnoDB引擎的Mysql数据库的数据恢复,如果是其它引擎的Mysql或其它数据库请自行google...
如果有一天你手挫不小心删掉了正式数据库中的数据,甚至把整个库给drop掉了,瞬间感觉眼前一黑有木有,感觉就像世界末日到了有木有,如果你有数据库备份还好,回复备份中的数据即可,或者你开了Mysql的二进制日志记录好像也可以从里面恢复,可是如果木有备份又木有开二进制日志记录是不是感觉苦逼了无从下手,下面的内容就针对这种情况给出一些解决方法...
1.首先你要尽快停掉mysql服务,把mysql数据库data文件夹下的内容全部拷出来,防止之后的操作覆盖删掉的数据。
2.准备一个Linux系统我用的是Ubuntu 12.04。
3.准备数据库恢复工具percona-data-recovery-tool-for-innodb,关于percona-data-recovery-tool-for-innodb:
3.1.这个工具只能对InnoDB/XtraDB表有效,而无法恢复MyISAM表。
3.2.这个工具是以保存的MySQL数据文件进行恢复的,而不用MySQL Server运行。
3.3.不能保证数据总一定可被恢复。例如,被重写的数据不能被恢复。
3.4.使用这个工具需要手动做一些工作,并不是全自动完成的。
3.5.恢复过程依赖于你对丢失数据的了解程度,在恢复过程中可能需要在不同版本的数据之间做出选择。那么如果你越了解自己的数据,恢复的可能性就越大。
4.下载percona-data-recovery-tool-for-innodb并解压,打开终端,输入以下命令:
wget https://launchpad.net/percona-data-recovery-tool-for-innodb/trunk/release-0.5/+download/percona-data-recovery-tool-for-innodb-0.5.tar.gz
tar -zxvf percona-data-recovery-tool-for-innodb-0.5.tar.gz4.1.转到解压后的目录的mysql-source子目录,运行配置命令:
cd percona-data-recovery-tool-for-innodb-0.5/mysql-source
./configure 4.2.完成配置步骤后,回到解压后的根目录,运行make命令,编译生成page_parser和constraints_parser工具(如果编译过程中出现问题,诸如包依赖之类的,请根据错误提示自行补全):
cd ..
make5.提取数据
InnoDB页的默认大小是16K,每个页属于一个特定表中的一个特定的index。page_parser工具通过读取数据文件,根据页头中的index ID,拷贝每个页到一个单独的文件中。
如果你的MySQL server被配置为innodb_file_per_table=1,那么系统已经帮你实现上述过程。所有需要的页都在.ibd文件,而且通常你不需要再切分它。然而,如果.ibd文件中可能包含多个index,那么将页单独切分开还是有必要的。如果MySQL server没有配置innodb_file_per_table,那么数据会被保存在一个全局的表命名空间(通常是一个名为ibdata1的文件,本文属于这种情况),这时候就需要按页对文件进行切分。
5.1.切分页--在解压后的根目录下新建dbfile文件夹并把你拷的data目录下的ibdata1文件复制到该文件夹。
5.1.1.如果MySQL是5.0之前的版本,InnoDB采取的是REDUNDANT格式,在终端运行以下命令:
./page_parser -4 -f ./dbfile/ibdata15.1.2.如果MySQL是5.0及以上版本,InnoDB采取的是COMPACT格式,在终端运行以下命令:
./page_parser -5 -f ./dbfile/ibdata15.2.运行后,page_parser工具会创建一个pages-<TIMESTAMP>的目录,其中TIMESTAMP是UNIX系统时间戳。在这个目录下,为每个index ID,以页的index ID创建一个子目录。如图:
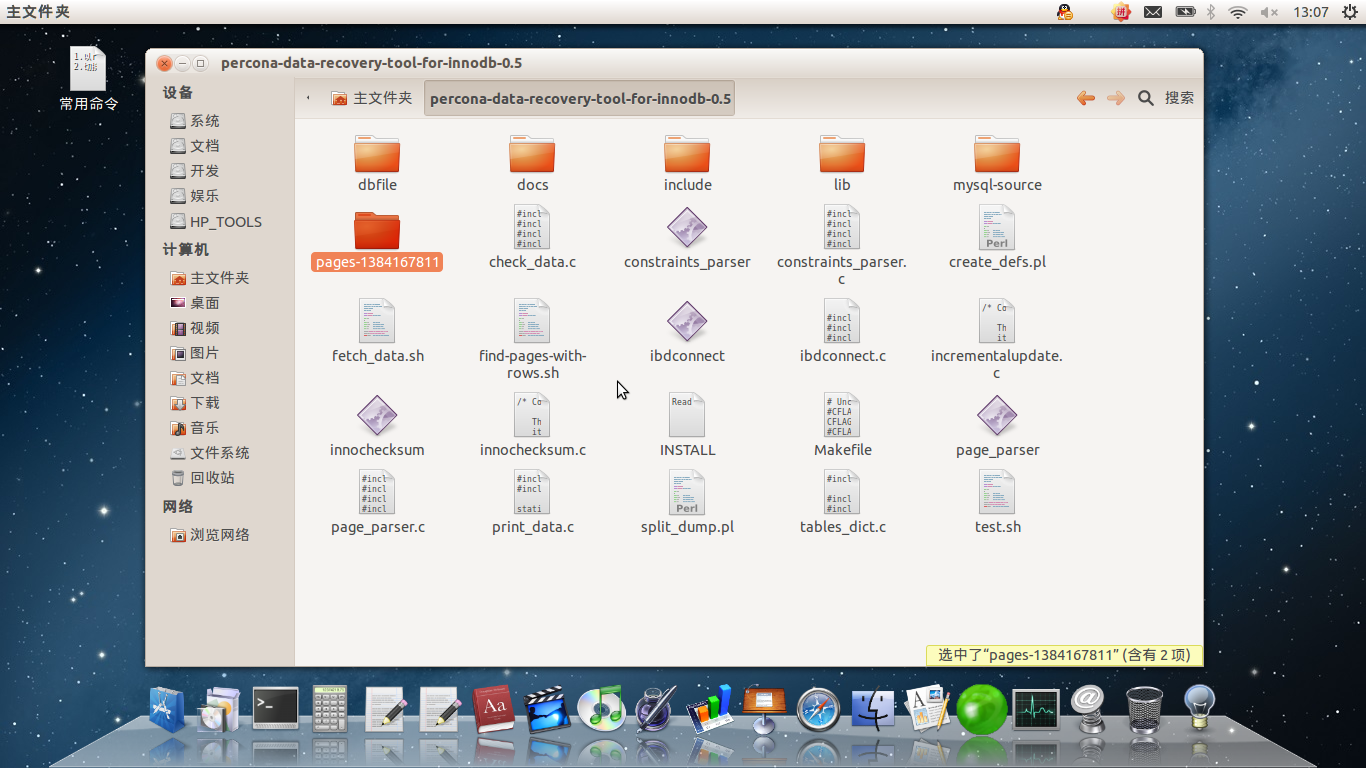
5.3.选择需要的Index ID
5.3.1.如果你只是删除了表中的数据而没有删除表,那么可以启动InnoDB Tablespace Monitor,输出所有表和indexes,index IDs到MySQL server的错误日志文件。创建innodb_table_monitor表用于收集innodb存储引擎表及其索引的存储方式:
mysql> CREATE TABLE innodb_table_monitor (id int) ENGINE=InnoDB;如果innodb_table_monitor已经存在,drop表然后重新create表。等MySQL错误日志输出后,可以drop掉这张表以停止打印输出更多的监控。一个输出的例子如下:
TABLE: name sakila/customer, id 0 142, columns 13, indexes 4, appr.rows 0COLUMNS: customer_id: DATA_INT len 2 prec 0; store_id: DATA_INT len 1 prec 0; first_name: type 12 len 135 prec 0; last_name: type 12 len 135 prec 0; email:type 12 len 150 prec 0; address_id: DATA_INT len 2 prec 0; active: DATA_INT len 1 prec 0; create_date: DATA_INT len 8 prec 0; last_update: DATA_INT len 4 pr
ec 0; DB_ROW_ID: DATA_SYS prtype 256 len 6 prec 0; DB_TRX_ID: DATA_SYS prtype 257 len 6 prec 0; DB_ROLL_PTR: DATA_SYS prtype 258 len 7 prec 0; INDEX: name PRIMARY, id 0 286, fields 1/11, type 3root page 50, appr.key vals 0, leaf pages 1, size pages 1FIELDS: customer_id DB_TRX_ID DB_ROLL_PTR store_id first_name last_name email address_id active create_date last_updateINDEX: name idx_fk_store_id, id 0 287, fields 1/2, type 0root page 56, appr.key vals 0, leaf pages 1, size pages 1FIELDS: store_id customer_idINDEX: name idx_fk_address_id, id 0 288, fields 1/2, type 0root page 63, appr.key vals 0, leaf pages 1, size pages 1FIELDS: address_id customer_idINDEX: name idx_last_name, id 0 289, fields 1/2, type 0root page 1493, appr.key vals 0, leaf pages 1, size pages 1FIELDS: last_name customer_id这里,我们恢复的是sakila库下的customer表,从上面可以获取其主键信息:
INDEX: name PRIMARY, id 0 286, fields 1/11, type 35.3.2如果你把整个数据库都drop掉了,那是没办法按照上面的方法找到需要的Index ID的,那么你可以用一下的方法来获取需要的Index ID:
A:如果你能确定需要的表中有一些字段会有特殊值只在这个表中有记录,那么可以用以下命令搜索全部切分后的页:
grep -r "CP201310090001" pages-1384167811 搜索后的结果如图(可以看到0-968就是需要的Index ID):
B:如果找不出特殊值,官方教程好像说可以通过表字段名称搜索全部切分后的页,可是由于上面说的很笼统,我测试半天没有成功,有需要可以参考链接:http://www.percona.com/docs/wiki/innodb-data-recovery-tool:mysql-data-recovery:advanced_techniques#finding_index_ids
C:最后方法,暴力破解,由于我要回复的表除A方法里面的之外其它的没有特殊值,B方法也没研究出来,只能通过脚本循环所有文件来比对了,首先需要执行5.4,5.5步骤,生成好要查找的表定义并编译constraints_parser工具,然后在解压根目录新建一个shell脚本,我命名的是test.sh,脚本内容:
#!/bin/bash
function ergodic(){
for file in ` ls $1`
doif [ -d $1"/"$file ]thenergodic $1"/"$fileelseecho $1"/"$file #输出文件的完整的路径./constraints_parser -5 -f $1"/"$file #提取数据echo $1"/"$file #输出文件的完整的路径sleep 1 #暂停一秒fidone
}
INIT_PATH="pages-1384167811/FIL_PAGE_INDEX" #这里是分页后页面文件所在的文件夹
ergodic $INIT_PATH 然后在终端输入./test.sh执行脚本,盯着终端直到终端输出有数据,且不是乱码的时候,那么当前提取的文件所在的文件夹名就是你要找的Index ID,然后执行5.6,5.7的过程即可,截图如下:
5.4.生成表定义,这需要你知道要恢复表的结构,最简单的方法在测试服务器上新建一个与要恢复数据库一样的数据库,然后在终端输入(如果不知道表结构,也有可能通过表定义文件.frm回复,详细请参考:http://www.percona.com/docs/wiki/innodb-data-recovery-tool:mysql-data-recovery:advanced_techniques#getting_create_table_from_frm_files):
./create_defs.pl --host=服务器地址 --user=用户名 --password=密码 --db=数据库名 --table=表名 > include/table_defs.h然后转到解压根目录下的include子目录打开table_defs.h文件,检查一下生成的是否正确,防止你在上面的数据库或表名写错而生成定义为空的文件,如图:
5.5.编译constraints_parser工具(每次生成表定义后都要重新编译):
make
gcc -DHAVE_OFFSET64_T -D_FILE_OFFSET_BITS=64 -D_LARGEFILE64_SOURCE=1 -D_LARGEFILE_SOURCE=1 -g -I include -I mysql-source/include -I mysql-source/innobase/include -c tables_dict.c -o lib/tables_dict.o
gcc -DHAVE_OFFSET64_T -D_FILE_OFFSET_BITS=64 -D_LARGEFILE64_SOURCE=1 -D_LARGEFILE_SOURCE=1 -g -I include -I mysql-source/include -I mysql-source/innobase/include -o constraints_parser constraints_parser.c lib/tables_dict.o lib/print_data.o lib/check_data.o lib/libut.a lib/libmystrings.a
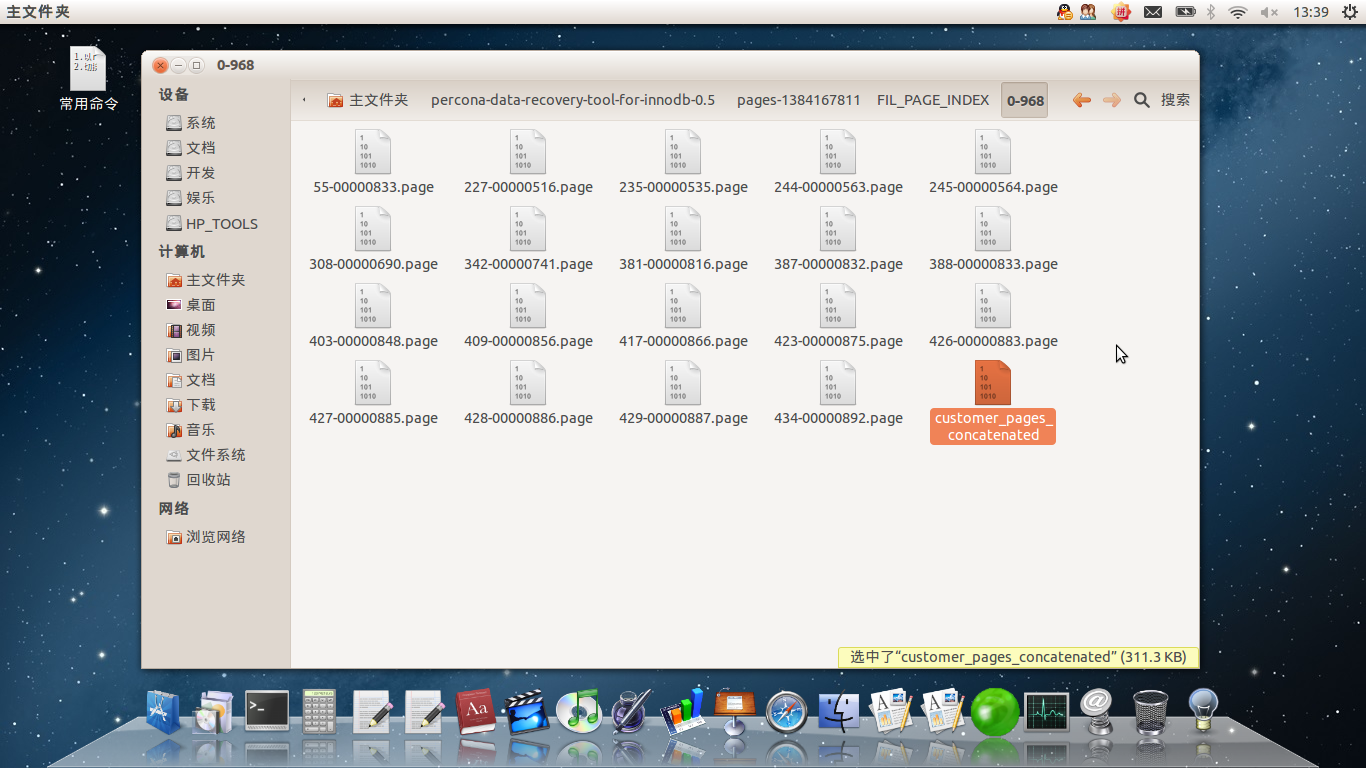
gcc -DHAVE_OFFSET64_T -D_FILE_OFFSET_BITS=64 -D_LARGEFILE64_SOURCE=1 -D_LARGEFILE_SOURCE=1 -g -I include -I mysql-source/include -I mysql-source/innobase/include -o page_parser page_parser.c lib/tables_dict.o lib/libut.a5.6.合并页,切分页后生成的Index号码的文件夹下面会有好多文件,提取记录前需要先把这些文件合并成一个文件:
find pages-1384167811/FIL_PAGE_INDEX/0-968/ -type f -name '*.page' | sort -n | xargs cat > pages-1384167811/FIL_PAGE_INDEX/0-968/customer_pages_concatenated合并后如图:
5.7.提取合并后的数据:
./constraints_parser -5 -f pages-1384167811/FIL_PAGE_INDEX/0-968/customer_pages_concatenated > pages-1384167811/FIL_PAGE_INDEX/0-968/customer_data.tsv提取后的文件如图:
文件中的内容就是表中的记录,你可以直接把tsv文件中的内容导入到数据库,也可以打开tsv文件把内容复制到excel表格中,用你习惯的方式导入。
转载于:https://my.oschina.net/secyaher/blog/274474
InnoDB引擎Myslq数据库数据恢复相关推荐
- mysql使用混合引擎如何,mysql – 使用MyISAM和InnoDB引擎的数据库的一致逻辑备份...
我有一个关于MySQL数据库的逻辑备份的问题 同时使用MyISAM和InnoDB. mysqldump实用程序支持以下两个选项: > –single-transaction – 通过转储单个事务 ...
- MySQL数据库的InnoDB引擎TableSpaceExists问题解决
文章中所有操作均是在 MySQL 5.7 版本下进行的 引入问题 MySQL 使用过程中如果出现如下报错: ERROR 1813 (HY000): Tablespace '`库名`.`表名`' exi ...
- 【数据库数据恢复】华为云mysql数据库数据被delete的数据恢复案例
数据库数据恢复环境: 华为云ECS,linux操作系统: mysql数据库,实例内数据表默认存储引擎为innodb. 数据库故障: 在执行数据库版本更新测试时,用户误将本应在测试库测试的sql脚本执行 ...
- mysql断电不受影响db引擎_一次服务器断电,造成innodb引擎表(日志表)损坏的解决办法...
1.mysql日志报错 innodb引擎提示数据库没有正常关闭,报innodb错误180112 0:49:28 InnoDB: Database was not shut down normall ...
- mysql数据库断电恢复_MySQL数据库InnoDB引擎下服务器断电数据恢复方法
说明: 线上的一台MySQL数据库服务器突然断电,造成系统故障无法启动,重新安装系统后,找到之前的MySQL数据库文件夹. 问题: 通过复制文件的方式对之前的MySQL数据库进行恢复,发现在程序调用时 ...
- 工作中InnoDB引擎数据库主从复制同步心得
近期将公司的MySQL架构升级了,由原先的一主多从换成了DRBD+Heartbeat双主多从,正好手上有一个电子商务网站新项目也要上线了,用的是DRBD+Heartbeat双主一从,由于此过程还是有别 ...
- 阿里云mysql数据库引擎_在阿里云RDS数据库服务器中将MySQL InnoDB引擎表转为压缩格式...
今年以来将我们以前托管或者租用的服务器全面转向阿里云,除了采用ECS服务器以外,还有一项重要的是采用了RDS数据库服务器,这对于服务的稳定性.各项指标的监控.调优等都有帮助. 不过随着近期更多数据库转 ...
- mysql数据库存储引擎和索引的描述_Mysql InnoDB引擎的索引与存储结构详解
前言 在Oracle 和SQL Server等数据库中只有一种存储引擎,所有数据存储管理机制都是一样的. 而MySql数据库提供了多种存储引擎.用户可以根据不同的需求为数据表选择不同的存储引擎,用户也 ...
- mysql innodb引擎丢失_【MySQL】InnoDB引擎ibdata文件损坏/删除后使用frm和ibd文件恢复数据...
注意!此方法只适用于innodb_file_per_table独立表空间的InnoDB实例. 此种方法可以恢复ibdata文件被误删.被恶意修改,没有从库和备份数据的情况下的数据恢复,不能保证数据库所 ...
最新文章
- 模糊测试(fuzz testing)介绍(一)
- mysql设计表时 varchar长度_设计表的时候,对变长字段长度选择的一点思考
- 交通违章行为,和记分、处罚条款——不仅要扣分,还要罚钱哪,没有不罚钱的扣分!!!...
- 升腾联手VMware 发布首款本土化桌面虚拟化
- 如何在python中打开文件_Python文件处理:创建、打开、追加、读、写
- 用matlab仿真0到9十个数字的语音识别
- robotframework--登录接口,post传递多个参数、及获取content中指定属性的值(5)
- eclipse-Tomcat运行项目笔记
- 使用docker私有化部署nuget server-proget
- 数据结构--------二叉排序树
- js实现浏览器打印PDF
- html点击超链接出现弹窗,如何实现超链接弹窗打开
- flutter中的点击事件
- html5 运动轨迹绘画,html5 canvas行星运动轨迹动画特效
- 在微服务架构中管理技术债务
- CLion中回退和前进的快捷键
- 基于80C51单片机的经纬度定位显示装置设计
- java switch语句-for循环讲解
- Vue 实现 登陆后打开主页面(登陆组件 + 主页面组件)
- MA Chapter 17 Budgetary process(SRCharlotte)