Spark 的核心 RDD 以及 Stage 划分细节,运行模式总结
精选30+云产品,助力企业轻松上云!>>> 
阅读文本大概需要 5 分钟。
以下内容,部分参考网络资料,也有自己的理解, 图片 99% 为自己制作。如有错误,欢迎留言指出,一起交流。
本文主要分为:
Spark 简介
Spark 的运行模式
RDD 是什么?
三个控制算子
RDD依赖关系
Stage划分依据
推荐阅读
1 Spark 简介
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。它产生于 UC Berkeley AMP Lab,继承了 MapReduce 的优点,但是不同于 MapReduce 的是,Spark 可以将结果保存在内存中,一直迭代计算下去,除非遇到 shuffle 。因此 Spark 能更好的适用于数据挖掘与机器学习等要迭代的算法。值得注意的是,官网说的 Spark 是 MR 计算速度的 100 倍。仅仅适用于逻辑回归等这样的迭代计算。

2 Spark 的运行模式
Local 模式:多用于本机编写、测试代码。
Standalone 模式:这是 Spark 自带的资源调度框架,它支持完全分布式。
Yarn 模式:这是 hadoop 里面的一个资源调度框架,Spark 同样也可以使用。
Mesos 模式:为应用程序(如Hadoop、Spark、Kafka、ElasticSearch)提供API的整个数据中心和云环境中的资源管理和调度。
下面分别介绍一下 Standalone 和 Yarn 模式下任务流程。
Standalone-client 提交方式
提交命令如下:以官方给的计算 PI 的代码为例。
./spark-submit--master spark://node1:7077--class org.apache.spark.example.SaprkPi../lib/spark-examples-1.6.0-hadoop2.6.0.jar1000执行流程图以及原理:

Standalone-cluster 提交方式
提交命令如下:以官方给的计算 PI 的代码为例。
./spark-submit--master spark://node1:7077--deploy-mode cluster--class org.apache.spark.example.SaprkPi../lib/spark-examples-1.6.0-hadoop2.6.0.jar1000执行流程图以及原理:

Yarn-client 提交方式
提交命令如下:以官方给的计算 PI 的代码为例。
./spark-submit--master yarn--deploy-mode client--class org.apache.spark.example.SaprkPi../lib/spark-examples-1.6.0-hadoop2.6.0.jar1000执行流程图以及原理:

Yarn-cluster 提交方式
提交命令如下:以官方给的计算 PI 的代码为例。
./spark-submit--master yarn--deploy-mode cluster--class org.apache.spark.example.SaprkPi../lib/spark-examples-1.6.0-hadoop2.6.0.jar1000执行流程图以及原理:

3 RDD是什么
Spark core 最核心的就是 Resilient Distributed Dataset (RDD) 了,RDD 比较抽象了。源码中 RDD.scala 中对 RDD 进行了一段描述。最主要的是下面的五个方面;
/** * Internally, each RDD is characterized by five main properties: * * - A list of partitions * - A function for computing each split * - A list of dependencies on other RDDs * - Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned) * - Optionally, a list of preferred locations to compute each split on (e.g. block locations for * an HDFS file) * * All of the scheduling and execution in Spark is done based on these methods, allowing each RDD * to implement its own way of computing itself. Indeed, users can implement custom RDDs (e.g. for * reading data from a new storage system) by overriding these functions. */RDD 的五大特性:
1.RDD 是由一系列的 Partition 组成的。
2.函数作用在每一个 split 上。
3.RDD 之间有一系列依赖关系。
4.分区器是作用在 K,V 格式的 RDD 上。
5.RDD 提供一系列最佳的位置
先记住这五个特性,之后的学习会慢慢体会到这样设计的好处。下面是理解 RDD 的逻辑图;
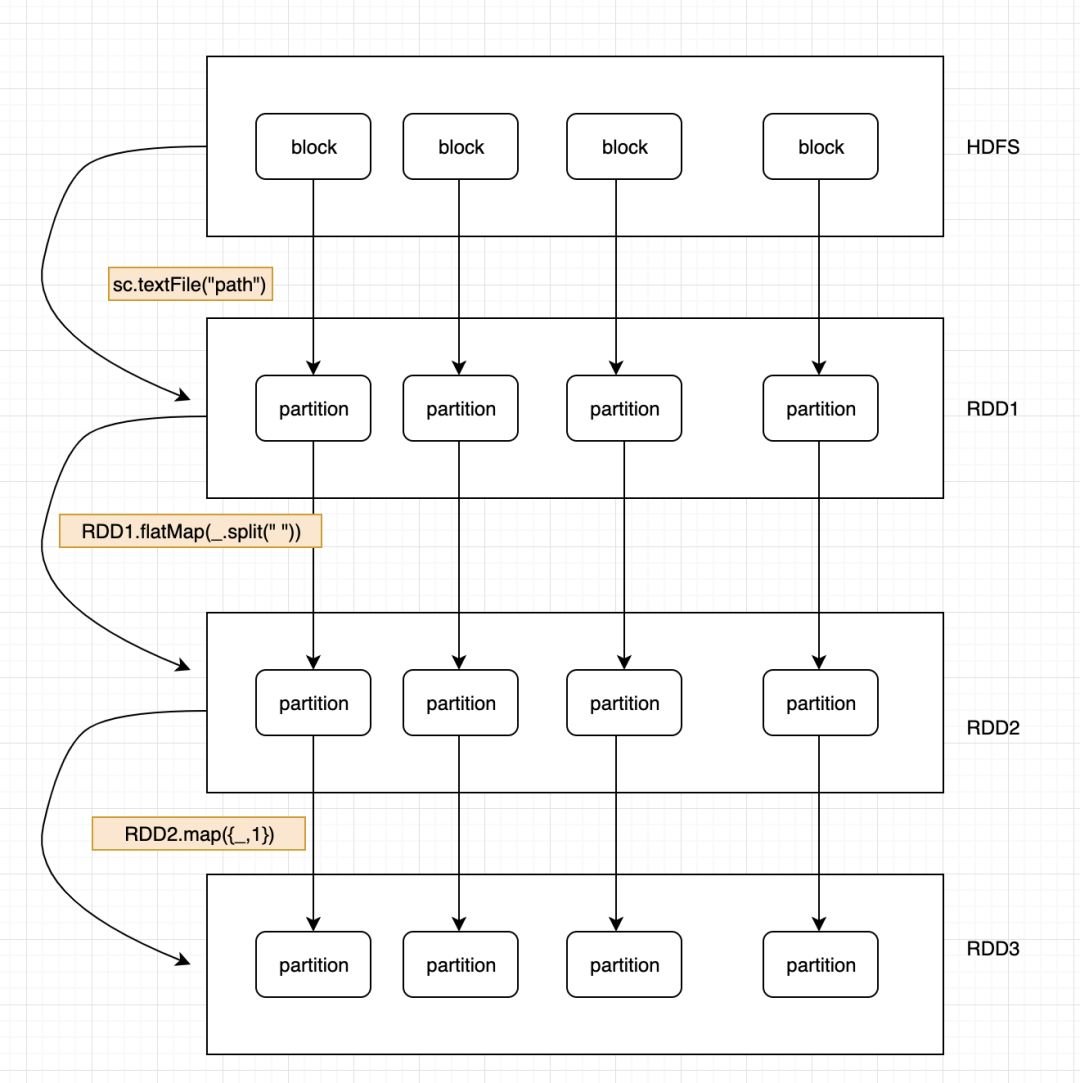
看这个图再回头理解一下上面的五个 RDD 的特性。
RDD 的弹性表现在 Partition 的数量上,并且大小没有限制。RDD 的依赖关系,可以基于上一个 RDD 计算出下一个 RDD。RDD 的每个 partition 是分布在不同数据节点上的,所有 RDD 的分布式的。RDD 提供了一些列的最佳的计算位置,体现了数据的本地化,我之前的这篇文章写过:一文搞懂数据本地化级别
RDD 还有一个 Lineage 的东西,叫做血统。
Lineage 简介:利用内存加快数据加载,在其它的In-Memory类数据库或Cache类系统中也有实现。Spark的主要区别在于它采用血统来实现分布式运算环境下的数据容错性(节点失效、数据丢失)问题。
RDD Lineage被称为RDD运算图或RDD依赖关系图,是RDD所有父RDD的图。它是在RDD上执行transformations函数并创建逻辑执行计划(logical execution plan)的结果,是RDD的逻辑执行计划。
相比其它系统的细颗粒度的内存数据更新级别的备份或者LOG机制,RDD 的 Lineage 记录的是粗颗粒度的特定数据转换(Transformation)操作(filter, map, join etc.)行为。当这个 RDD 的部分分区数据丢失时,它可以通过Lineage找到丢失的父RDD的分区进行局部计算来恢复丢失的数据,这样可以节省资源提高运行效率。这种粗颗粒的数据模型,限制了Spark的运用场合,但同时相比细颗粒度的数据模型,也带来了性能的提升。
4 控制算子
控制算子有三种:cache, persist, checkpoint, 以上算子都可以将 RDD 持久化、持久化的单位是 Partition。
cache 和 persist 都是懒执行的,必须有一个 action 算子来触发他们执行。checkpoint 不仅可以将 RDD 持久化到磁盘,还能切断 RDD 之间的依赖关系。
说几点区别:
cache 的持久化级别是 Memory_Only,就这一个。
persist 的持久化级别:常用的有Memory_Only 和Memory_and_Disk_2, 数字 2 表示副本数。
checkpoint 主要是用来做容错的。
checkpoint 的执行原理是:当 RDD 的 job 执行完毕之后,会从 finalRDD 进行回溯。当回溯到某一个 RDD 调用了 checkpoint 方法,会对当前的 RDD 做一个标记。Spark 框架会自动启动一个新的 Job ,重新计算这个 RDD 的数据,将数据持久化到 HDFS 上。根据这个原理,我们可以进行优化,对 RDD 进行 checkpoint 之前,最好先对这个 RDD 进行 cache, 这样启动新的 job 只需要将内存中的数据拷贝到 HDFS 上就可以了,节省了重新计算这一步。
5 RDD 的依赖关系
窄依赖:指父RDD的每一个分区最多被一个子RDD的分区所用,表现为一个父RDD的分区对应于一个子RDD的分区,和两个父RDD的分区对应于一个子RDD 的分区。图中,map/filter/union属于第一类,对输入进行协同划分(co-partitioned)的join属于第二类。窄依赖不会产生 shuffle。
宽依赖:指子RDD的分区依赖于父RDD的所有分区,这是因为 shuffle 类操作,如图中的 groupByKey 和未经协同划分的 join。 遇到宽依赖会产生 shuffle 。
上面我们说到了 RDD 之间的依赖关系,这些依赖关系形成了一个人 DAG 有向无环图。DAG 创建完成之后,会被提交给 DAGScheduler, 它负责把 DAG 划分相互依赖的多个 stage ,划分依据就是 RDD 之间的窄宽依赖。换句话说就是,遇到一个宽依赖就划分一个 stage,每一个 stage 包含一个或多个 stask 任务。然后将这些 task 以 taskset 的方式提交给 TaskScheduler 运行。也可以说 stage 是由一组并行的 task 组成。下图很清楚的描述了 stage 的划分。

6 Stage划分思路
接上图,Spark 划分 stage 的整体思路是:从后往前推,遇到宽依赖就断开,划分为一个stage;遇到窄依赖就将这个 RDD 加入该 stage 中。
因此在图中 RDD C, RDD D, RDD E, RDD F 被构建在一个 stage 中, RDD A被构建在一个单独的Stage中,而 RDD B 和 RDD G 又被构建在同一个 stage中。
另一个角度
一个 Job 会被拆分为多组 Task,每组任务被称为一个Stage就像 Map Stage,Reduce Stage。
Stage 的划分简单的说是以 shuffle 和 result 这两种类型来划分。在 Spark中有两类 task,一类是 shuffleMapTask,一类是 resultTask,第一类 task的输出是 shuffle 所需数据,第二类 task 的输出是 result,stage的划分也以此为依据,shuffle 之前的所有变换是一个 stage,shuffle之后的操作是另一个stage。
如果 job 中有多次 shuffle,那么每个 shuffle 之前都是一个 stage. 会根据 RDD 之间的依赖关系将 DAG图划分为不同的阶段,对于窄依赖,由于 partition 依赖关系的确定性,partition 的转换处理就可以在同一个线程里完成,窄依赖就被 spark 划分到同一个 stage 中,而对于宽依赖,只能等父 RDD shuffle 处理完成后,下一个 stage 才能开始接下来的计算。之所以称之为 ShuffleMapTask 是因为它需要将自己的计算结果通过 shuffle 到下一个 stage 中。
推荐阅读:
Spark 的 shuffle 文件寻址流程
Spark 调优整合篇-汇总(长文)
Kafka 遇上 Spark Streaming
Spark 调优一瞥 | shuffle 调优
武汉加油!
本文分享自微信公众号 - 大数据每日哔哔(bb-bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
Spark 的核心 RDD 以及 Stage 划分细节,运行模式总结相关推荐
- Spark的核心RDD(Resilient Distributed Datasets弹性分布式数据集)
Spark的核心RDD(Resilient Distributed Datasets弹性分布式数据集) 铺垫 在hadoop中一个独立的计算,例如在一个迭代过程中,除可复制的文件系统(HDFS)外没有 ...
- 理解Spark的核心RDD
与许多专有的大数据处理平台不同,Spark建立在统一抽象的RDD之上,使得它可以以基本一致的方式应对不同的大数据处理场景,包括MapReduce,Streaming,SQL,Machine Learn ...
- 2021年大数据Spark(四):三种常见的运行模式
目录 Spark 运行模式 一.本地模式:Local Mode 二.集群模式:Cluster Mode 三.云服务:Kubernetes 模式 Spark 运行模式 Spark 框架编 ...
- Spark基础学习笔记19:RDD的依赖与Stage划分
文章目录 零.本讲学习目标 一.RDD的依赖 (一)窄依赖 1.map()与filter()算子 2.union()算子 3.join()算子 (二)宽依赖 1.groupBy()算子 2.join( ...
- 用实例说明Spark stage划分原理
注意:此文的stage划分有错,stage的划分是以shuffle操作作为边界的,可以参考<spark大数据处理技术>第四章page rank例子! 参考:http://litaotao. ...
- Spark技术内幕:Stage划分及提交源码分析
当触发一个RDD的action后,以count为例,调用关系如下: org.apache.spark.rdd.RDD#count org.apache.spark.SparkContext#runJo ...
- Spark核心RDD详述
Spark核心RDD Spark的核心: RDD特性: RDD的关键特征: RDD创建方式 温馨提示:工作中已经很少使用RDD,一般直接使用df Spark的核心: Spark任务来说,最终的目标是A ...
- Spark精华问答 | RDD的核心概念是什么?
Hadoop再火,火得过Spark吗?今天我们继续关于Spark的精华问答吧. 1 Q:RDD的核心概念是什么? A:Client:客户端进程,负责提交作业到Master. Master:Standa ...
- Spark总结之RDD(四)
Spark总结之RDD(四) 1. 背景 Spark针对RDD的整体设计思想很多地方和MapReduce相似,但又做了很多优化. Spark整体API设计针对分布式数据处理做了很多优化,并且做了更高层 ...
最新文章
- 关于mongodb ,redis,memcache之间见不乱理还乱的关系和作用
- Leetcode 461. Hamming Distance JAVA语言
- java红黑树_JAVA学习-红黑树详解
- python语言用途-python编程语言有什么用途
- 刺激(codevs 1958)
- ORA-29861: 域索引标记为 LOADING/FAILED/UNUSABLE
- html+css+javascript 网页设计 从入门到精通_绵阳美工设计学习
- LeetCode 1332. 删除回文子序列
- Java_模拟comet的实现
- 【BZOJ】3566: [SHOI2014]概率充电器
- Parcelable protocol requires a Parcelable.Creator object called。。。。。
- CSS margin合并
- python命名元组namedtuple_Python命名元组--命名元组,Pythonnamedtuple,具名
- pic单片机c语言程序设计实例精粹 pdf,PIC单片机C语言程序设计.pdf
- 网易云音乐——Web学习day6
- Python3实现向指定邮箱发送邮件(支持附件文件、图片等)
- 中国唯一的图灵奖获得者姚期智,在清华开设的“姚班”有哪些 AI 名徒?
- 创建前缀索引时,如何确认“最佳长度”
- C++ 函数的声明和定义
- Slax本土化:移动硬盘上的Linux中文套件(转)
热门文章
- go语言 os.Rename() cannot move the file to a different disk drive 怎么办
- Linux学习(六):命令与文件的查阅,Root用户和个人用户使用which命令的差别...
- spark job运行参数优化
- python定时下载FTP指定文件
- Raid 原理及创建软raid
- atitit.设计文档---操作日志的实现
- Linux的下载命令wget详解
- 面试官系统精讲Java源码及大厂真题 - 39 经验总结:不同场景,如何使用线程池
- Spring Security 示例UserDetailsService
- 数据可视化组件Grafana详细解读--Debian/Ubuntu上的安装