CentOS 7下配置hadoop 2.8 分布式集群
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,实现分布式文件系统HDFS,用于存储大数据集,以及可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。本文描述了在CentOS 7下,基于三个节点安装hadoop 2.8,供大家参考。
我有几张阿里云幸运券分享给你,用券购买或者升级阿里云相应产品会有特惠惊喜哦!把想要买的产品的幸运券都领走吧!快下手,马上就要抢光了。
一、基础环境描述
OS版本
[root@namenode ~]# more /etc/redhat-release
CentOS Linux release 7.2.1511 (Core)JAVA环境
[root@namenode ~]# java -version
openjdk version "1.8.0_65"
OpenJDK Runtime Environment (build 1.8.0_65-b17)
OpenJDK 64-Bit Server VM (build 25.65-b01, mixed mode)三个节点主机名及IP
192.168.81.142 namenode.example.com namenode
192.168.81.146 datanode1.example.com datanode1
192.168.81.147 datanode2.example.com datanode2hadoop版本
[hadoop@namenode ~]$ hadoop version
Hadoop 2.8.1二、主要步骤
配置Java运行环境
配置hosts文件
配置hadoop运行账户及数据存放目录
配置ssh等效连接
配置用户环境变量
下载解压hadoop安装包
配置hadoop相关配置文件
格式化namenode
启动hadoop
验证hadoop
三、配置及安装hadoop 2.8
1、配置java运行环境(所有节点)
[root@namenode ~]# vim /etc/profile.d/java.sh
export JAVA_HOME=/etc/alternatives/java_sdk_1.8.0_openjdk
export PATH=$PATH:$JAVA_HOME[root@namenode ~]# source /etc/profile.d/java.sh
[root@namenode ~]# env |grep JAVA_HOME
JAVA_HOME=/etc/alternatives/java_sdk_1.8.0_openjdk2、配置Hosts文件,添加用户及创建目录(所有节点)
[root@namenode ~]# vim /etc/hosts192.168.81.142 namenode.example.com namenode
192.168.81.146 datanode1.example.com datanode1
192.168.81.147 datanode2.example.com datanode2[root@namenode ~]# useradd hadoop
[root@namenode ~]# passwd hadoop
[root@namenode ~]# mkdir -pv /usr/local/hadoop/datanode
[root@namenode ~]# chmod 755 /usr/local/hadoop/datanode
[root@namenode ~]# chown hadoop:hadoop /usr/local/hadoop3、配置等效性(所有节点)
[root@namenode ~]# su - hadoop
[hadoop@namenode ~]$
[hadoop@namenode ~]$ ssh-keygen
[hadoop@namenode ~]$ ssh-copy-id localhost
[hadoop@namenode ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@192.168.81.146
[hadoop@namenode ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@192.168.81.147[hadoop@namenode ~]$ ssh namenode.example.com date;\
> ssh datanode1.example.com date;
> ssh datanode2.example.com date
Wed Nov 15 16:06:16 CST 2017
Wed Nov 15 16:06:16 CST 2017
Wed Nov 15 16:06:16 CST 20174、配置hadoop运行环境(所有节点)
[hadoop@namenode ~]$ vi ~/.bash_profile
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin[hadoop@namenode ~]$ source ~/.bash_profile5、安装hadoop(所有节点)
[hadoop@namenode ~]$ wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.8.1/hadoop-2.8.1.tar.gz -P /tmp
[hadoop@namenode ~]$ tar -xf /tmp/hadoop-2.8.1.tar.gz -C /usr/local/hadoop --strip-components 16、配置hadoop相关配置文件
[hadoop@namenode ~]$ vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>2</value></property><property><name>dfs.datanode.data.dir</name><value>file:///usr/local/hadoop/datanode</value></property>
</configuration>[hadoop@namenode ~]$ scp /usr/local/hadoop/etc/hadoop/hdfs-site.xml \
> datanode1:/usr/local/hadoop/etc/hadoop[hadoop@namenode ~]$ scp /usr/local/hadoop/etc/hadoop/hdfs-site.xml \
> datanode2:/usr/local/hadoop/etc/hadoop[hadoop@namenode ~]$ vim /usr/local/hadoop/etc/hadoop/core-site.xml<configuration><property><name>fs.defaultFS</name><value>hdfs://namenode.example.com:9000/</value></property>
</configuration>[hadoop@namenode ~]$ scp /usr/local/hadoop/etc/hadoop/core-site.xml \
> datanode1:/usr/local/hadoop/etc/hadoop[hadoop@namenode ~]$ scp /usr/local/hadoop/etc/hadoop/core-site.xml \
> datanode2:/usr/local/hadoop/etc/hadoop再次编辑hdfs-site.xml,仅仅针对namenode节点
[hadoop@namenode ~]$ mkdir -pv /usr/local/hadoop/namenode
[hadoop@namenode ~]$ vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
将以下内容添加到<configuration> - </configuration>
<property><name>dfs.namenode.name.dir</name><value>file:///usr/local/hadoop/namenode</value>
</property>[hadoop@namenode ~]$ vi /usr/local/hadoop/etc/hadoop/mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>[hadoop@namenode ~]$ vi /usr/local/hadoop/etc/hadoop/yarn-site.xml
<configuration><property><name>yarn.resourcemanager.hostname</name><value>namenode.example.com</value></property><property><name>yarn.nodemanager.hostname</name><value>namenode.example.com</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
</configuration>[hadoop@namenode ~]$ vi /usr/local/hadoop/etc/hadoop/slaves
# add all nodes (remove localhost)
namenode.example.com
datanode1.example.com
datanode2.example.com7、格式化
[hadoop@namenode ~]$ hdfs namenode -format
17/11/16 16:32:20 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: user = hadoop
STARTUP_MSG: host = namenode.example.com/192.168.81.142
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.8.1
........17/11/16 16:32:21 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at namenode.example.com/192.168.81.142
************************************************************/8、启动hadoop
[hadoop@namenode ~]$ start-dfs.sh
Starting namenodes on [namenode.example.com]
namenode.example.com: starting namenode, logging to /usr/...-namenode-namenode.example.com.out
datanode2.example.com: starting datanode, logging to /usr/...-datanode-datanode2.example.com.out
namenode.example.com: starting datanode, logging to /usr/...-datanode-namenode.example.com.out
datanode1.example.com: starting datanode, logging to /usr/...-datanode-datanode1.example.com.out
Starting secondary namenodes [blogs.jrealm.net]
blogs.jrealm.net: starting secondarynamenode, logging to /usr/...-secondarynamenode-namenode.example.com.out[hadoop@namenode ~]$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/...-resourcemanager-namenode.example.com.out
datanode2.example.com: starting nodemanager, logging to /usr/...-datanode2.example.com.out
datanode1.example.com: starting nodemanager, logging to /usr/...-datanode1.example.com.out
namenode.example.com: starting nodemanager, logging to /usr/...-namenode.example.com.out[root@namenode ~]# jps
12995 Jps
10985 ResourceManager
11179 NodeManager ## Author : Leshami
10061 NameNode ## QQ/Weixin : 645746311
10301 DataNode
10655 SecondaryNameNode9、测试hadoop
[hadoop@namenode ~]$ hdfs dfs -mkdir /test ##创建测试目录
上传文件到hadoop集群
[hadoop@namenode ~]$ hdfs dfs -copyFromLocal /usr/local/hadoop/NOTICE.txt /test
查看已上传的文件
[hadoop@namenode ~]$ hdfs dfs -cat /test/NOTICE.txt
This product includes software developed by The Apache Software
Foundation (http://www.apache.org/).The binary distribution of this product bundles binaries of
org.iq80.leveldb:leveldb-api (https://github.com/dain/leveldb), which has the
following notices:
* Copyright 2011 Dain Sundstrom <dain@iq80.com>
* Copyright 2011 FuseSource Corp. http://fusesource.com使用自带的jar包map-reduce 测试字数统计
[hadoop@namenode ~]$ hadoop jar \
> /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.1.jar wordcount /test/NOTICE.txt /output01
17/11/17 14:14:39 INFO client.RMProxy: Connecting to ResourceManager at namenode.example.com/192.168.81.142:8032
17/11/17 14:14:49 INFO input.FileInputFormat: Total input files to process : 1
17/11/17 14:14:49 INFO mapreduce.JobSubmitter: number of splits:1
17/11/17 14:14:50 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1510837568617_0001
17/11/17 14:14:56 INFO impl.YarnClientImpl: Submitted application application_1510837568617_0001
17/11/17 14:14:56 INFO mapreduce.Job: The url to track the job: http://namenode.example.com:8088/proxy/application_1510837568617_0001/
17/11/17 14:14:56 INFO mapreduce.Job: Running job: job_1510837568617_0001
17/11/17 14:16:05 INFO mapreduce.Job: Job job_1510837568617_0001 running in uber mode : false
17/11/17 14:16:05 INFO mapreduce.Job: map 0% reduce 0%
17/11/17 14:16:56 INFO mapreduce.Job: map 100% reduce 0%
17/11/17 14:17:10 INFO mapreduce.Job: map 100% reduce 100%
17/11/17 14:17:14 INFO mapreduce.Job: Job job_1510837568617_0001 completed successfully
17/11/17 14:17:16 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=12094查看输出日志文件及结果
[hadoop@namenode ~]$ hdfs dfs -ls /output01
Found 2 items
-rw-r--r-- 2 hadoop supergroup 0 2017-11-17 14:17 /output01/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 9485 2017-11-17 14:17 /output01/part-r-00000[hadoop@namenode ~]$ hdfs dfs -cat /output01/part-r-00000
"AS 1
"GCC 1
"License"); 1
& 1
'Aalto 1
'Apache 4
'ArrayDeque', 110、Web界面控制台
查看集群摘要信息
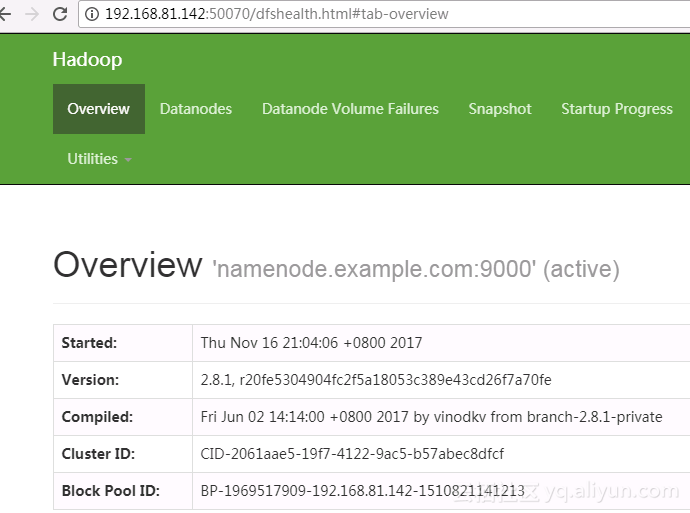
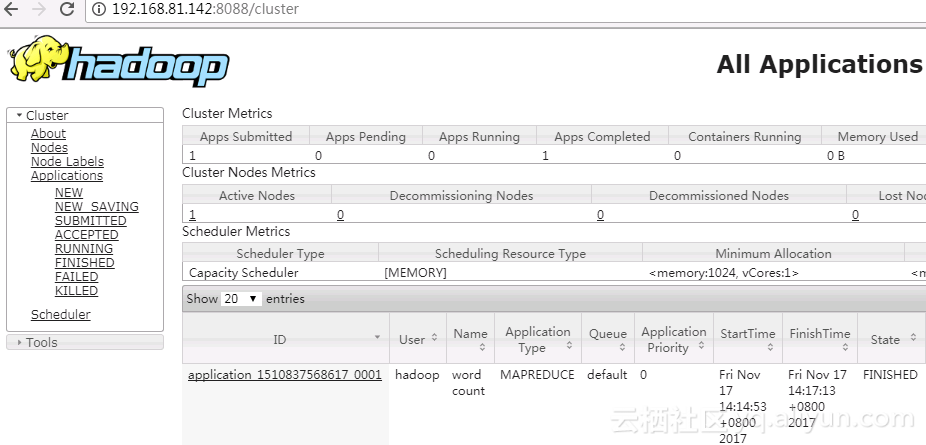
查看集群信息
阅读原文http://click.aliyun.com/m/35560/
CentOS 7下配置hadoop 2.8 分布式集群相关推荐
- hadoop搭建伪分布式集群(centos7+hadoop-3.1.1)
原文地址:https://www.cnblogs.com/zhengna/p/9316424.html Hadoop三种安装模式 搭建伪分布式集群准备条件 第一部分 安装前部署 1.查看虚拟机版本 2 ...
- Hadoop搭建完全分布式集群
Hadoop搭建完全分布式集群 搭建准备 配置ssh和编写一个分发shell脚本 java和hadoop 运行测试 最近公司事情不是很多,趁此机会,学习一下大数据的内容,正好公司之后也要使用大数据方面 ...
- 手把手教你搭建Hadoop生态系统伪分布式集群
Hello,我是 Alex 007,一个热爱计算机编程和硬件设计的小白,为啥是007呢?因为叫 Alex 的人太多了,再加上每天007的生活,Alex 007就诞生了. 手把手教你搭建Hadoop生态 ...
- linux下使用nginx搭建集群,CentOS(linux) 下Nginx的安装(Nginx+Tomcat集群第一步)
CentOS(linux) 下Nginx的安装(Nginx+Tomcat集群) CentOS 7.4(腾讯云) pcre库 zlib库 openssl Nginx服务器 安装gcc g++开发类库 y ...
- Hadoop单机/伪分布式集群搭建(新手向)
此文已由作者朱笑笑授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 本文主要参照官网的安装步骤实现了Hadoop伪分布式集群的搭建,希望能够为初识Hadoop的小伙伴带来借鉴意 ...
- 记Hadoop HA高可用性分布式集群搭建过程
为完成毕业设计中并行算法测试,在学习后,自己在虚拟机搭建了一个基于Hadoop的分布式集群,在这里做个记录,菜鸟首次写博客,已深夜,下面直接进入主题: 规划与说明 在hadoop集群中通常由两个Nam ...
- hadoop配置文件_Hadoop分布式集群
Hadoop分布式集群的详细介绍,首先Hadoop的搭建有三种方式,单机版适合开发调试;伪分布式版,适合模拟集群学习;完全分布式,生产使用的模式.这篇文件介绍如何搭建完全分布式的hadoop集群,一个 ...
- Windows上安装HADOOP单机伪分布式集群
2019独角兽企业重金招聘Python工程师标准>>> 1.准备HADOOP运行环境 下载解压并拷贝到Cygwin的用户主目录 http://archive.apache.org/d ...
- 学习搭建Hadoop+HBase+ZooKeeper分布式集群环境
一.环境配置 由于集群至少需要三台服务器,我就拿上次做的MongoDB Master, Slave, Arbiter环境来做Hadoop集群.服务器还是ibmcloud 免费提供的.其中Arbiter ...
最新文章
- Openshift创建Router和Registry
- padavan支持惠普打印服务器,[分享]Padavan打印机共享,电脑和手机上添加,亲测通过!...
- 机器学习:KNN算法(MATLAB实现)
- java定时增量同步,一种可配置的定时数据同步方法与流程
- linux修改文件没有备份文件,linux文件或目录权限修改后如何恢复(备份了权限就能恢复)...
- 她是如何从传统金融行业转行产品经理的?
- 京东炸年兽活动一键做任务工具v1.7
- 身在旋涡中的百度外卖,还能否找到接盘者?
- 节点本地范围和链路本地范围_微服务链路追踪——skywalking
- 村级行政shape_行政区划图边界制作shap.doc
- 一年月份大小月口诀_《认识年月日》大小月记忆法知识点教学设计
- 关于手机app合并m3u8文件失效,pc端合成方法
- 如何解决哔哩哔哩视频声音过小的问题?
- 我们已经开发好了Magento的Ctopay(收汇宝)非3D网关
- BulletProof vs snark vs stark性能对比
- UNITY与Mac⭐一、在苹果电脑上配置 Unity 安卓环境的教程
- 青云QingCloud推出“平步青云”创业扶持计划
- 2020年9月程序员工资最新统计
- 028-实现阿里云ESC多FLAT网络
- 向日葵在mac不能以服务器运行吗,使用向日葵软件实现mac远程桌面连接windows的步骤...