使用Apache Flume抓取数据(1)
使用Apache Flume抓取数据,怎么来抓取呢?不过,在了解这个问题之前,我们必须明确ApacheFlume是什么?
一、什么是Apache Flume
Apache Flume是用于数据采集的高性能系统 ,名字来源于原始的近乎实时的日志数据采集工具,现在广泛用于任何流事件数据的采集,支持从很多数据源聚合数据到HDFS。
最初由Cloudera开发 ,在2011年贡献给了Apache基金会 ,在2012年变成了Apache的顶级项目,Flume OG升级换代成了Flume NG。
Flume具有横向扩展、延展性、可靠性的优势
二、Flume 体系结构
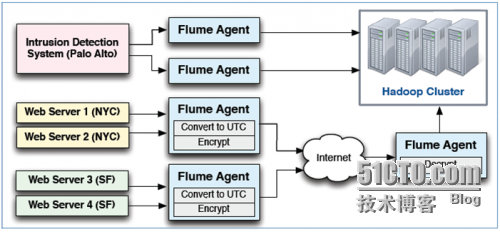
Source:接受外部系统生成event
Sink:发送event到指定的目的地
Channel:从Source缓存event,直到Sink把event取走
Agent:一个独立的Flume进程,包含了source,channel和sink组件
三、Flume设计目标:可靠性
Channels提供了Flume可靠性保障 ,那么它通过什么样的方式来保障呢?默认的模式就是Memory Channel,Memory Channel就是内存,所有的数据存放在内存当中。那么,这里就会存在一个问题?如果Channel的节点出现断电,数据就会丢失。为解决这一问题,这里有另外一种模式,就是基于磁盘的Channel,基于磁盘的队列确保出现断电时数据不丢失 。
另外,Agent和Channel之间的数据传输是事务性的 ,传输给下游agent失败的数据会回滚和重试 。相同的任务可以配置多个Agent,
比如,两个agent完成一个数据采集作业,如果一个agent失败,则上游的agent会失败切换到另一个。
四、Flume设计目标:扩展性
当我们采集的数据特别多的时候,可以通过添加更多的系统资源从而线性地增加系统性能。而且Flume可横向的扩展规模 ,随着复杂增加,可以添加更多的机器到配置当中 。
五、Flume设计目标:延展性
延展性就是能够添加新的功能到系统中。Flume通过添加Sources和Sinks到现有的存储层或数据平台,常见的Sources包括files、syslog和任何linux进程的标准输出的数据;常用Sinks包括本地文件系统或HDFS,开发员可以写自己的Sources或Sinks。
六、常见的Flume数据源

七、大规模部署实例
Flume使用agents收集数据 ,Agents可以从很多源接收数据,包括其他agents。大规模的部署使用多层来实现扩展性和可靠,Flume支持传输中数据的检查和修改。
以上就是关于Apache Flume的部分详情介绍,后续将会继续分享。大数据将会是未来的风口,要想很好的站在风口上,就要持续不断地学习和努力,这里推荐大家关注一个微信公众号“大数据cn ”,里面有很多关于大数据知识的介绍,对于想要了解和学习大数据的人是一个很好的平台。
本文作者:佚名
来源:51CTO
使用Apache Flume抓取数据(1)相关推荐
- 基于Thinkphp5+phpQuery 网络爬虫抓取数据接口,统一输出接口数据api
TP5_Splider 一个基于Thinkphp5+phpQuery 网络爬虫抓取数据接口 统一输出接口数据api.适合正在学习Vue,AngularJs框架学习 开发demo,需要接口并保证接口不跨 ...
- WebMagic抓取数据
目录 WebMagic 官网 http://webmagic.io/ 导入依赖 根据官方给的案例GithubRepoPageProcessor(测试案例不能直接运行,网络认证的关系.没啥事). 只 ...
- 模拟微信浏览器抓取数据
步骤: 1. 配置谷歌浏览器,按f12进入检查,右下角点击选择settings 2. 选择device,点击add 3. 填写userAgent 微信安卓UA Mozilla/5.0 (Linux; ...
- 朋友开网店 做个抓取数据的小程序
朋友开网店需要填充初期的数据. 专门做了一个抓取数据的小程序.分享一下. private void button1_Click(object sender, EventArgs e) ...
- wget抓取数据,需要用户登录验证
Niushop3.0电商系统,性价比之王!开牛店的第一选择! 在用wget抓取数据的时候,有的时候需要用户登录才能进行.这种情况下就需要时用cookie. 先看下面的代码: wget --load ...
- python爬取大众点评评论_python爬虫抓取数据 小试Python——爬虫抓取大众点评上的数据 - 电脑常识 - 服务器之家...
python爬虫抓取数据 小试Python--爬虫抓取大众点评上的数据 发布时间:2017-04-07
- python爬虫抓取数据的步骤-Python爬虫抓取手机APP的传输数据
大多数APP里面返回的是json格式数据,或者一堆加密过的数据 .这里以超级课程表APP为例,抓取超级课程表里用户发的话题. 1.抓取APP数据包 得到超级课程表登录的地址:http://120.55 ...
- libpcap抓取数据包
libpcap是数据包捕获函数库.该库提供的C函数接口可用于需要捕获经过网络接口数据包的系统开发上.libpcap提供的接口函数主要实现和封装了与数据包截获有关的过程.这个库为不同的平台提供了一致的编 ...
- php 抓取https请求数据,PHP + curl 实现 http 或 https 抓取数据:
/** * 抓取数据 https 或 http 形式 * @param $url 链接 * @param $data 参数 * @return mixed 返回数据 */ private functi ...
最新文章
- backup restore On Ubuntu
- Spring cloud zuul跨域(一)
- python基因差异分析_差异基因
- 1.4 面向对象的基本概念
- 运营商与厂商发力 智能机进入700元以下时代
- 21 MM配置-采购-定义采购组
- 字节跳动面试流程和考点都在这儿
- 2020年前端如何适应大环境,发展的前途与趋势是怎么样的?
- android shape 3d效果,如何绘制SuperShape3D作为网格?
- android 如何实现连接蓝牙打印机来实现打印功能
- python学到什么程度可以找到工作-Python学到什么程度可以面试工作?
- 计算机word无法打开,电脑中office文件无法打开的三种解决方法
- Unity篇——Minimap小地图
- SQL语句中计算百分比
- Edge的新标签页设置
- 绘声绘影2023简体中文版新功能介绍
- 刚子:走马观花奋达创“芯”发布会
- element-plus表单验证使用 个人总结
- 无水印的电脑录屏软件,推荐这3款软件,2023年新版
- yolov5的backbone学习
热门文章
- 字符串过长截断 html,(SqlServe)关于字符串长度被截断的问题
- excel自动生成舒尔特表_财务总监:超完美Excel全套账财务系统,自动生成报表,收好喽...
- 访问云服务器储存的mp4_服务器如何存储视频文件格式
- 哈希运算python实现_一致性哈希算法 python实现
- 微擎支付返回商户单号_一步一步教你在SpringBoot中集成微信扫码支付
- c语言for循环运行格式,关于for循环的格式
- java 滚动加载,滚动加载,可视区域判断
- trove mysql 镜像_Linux运维----03.制作trove-mysql5.7镜像
- 零基础学HTML5和CSS3前端开发第一课
- JDK15新特性密封类可以被继承了!