python爬虫抓取数据的步骤-Python爬虫抓取手机APP的传输数据
大多数APP里面返回的是json格式数据,或者一堆加密过的数据 。这里以超级课程表APP为例,抓取超级课程表里用户发的话题。
1、抓取APP数据包
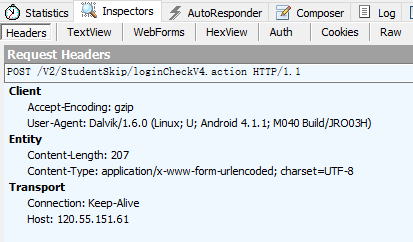
得到超级课程表登录的地址:http://120.55.151.61/V2/StudentSkip/loginCheckV4.action
表单:

表单中包括了用户名和密码,当然都是加密过了的,还有一个设备信息,直接post过去就是。
另外必须加header,一开始我没有加header得到的是登录错误,所以要带上header信息。
2、登录
登录代码:
?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import urllib2
from cookielibimport CookieJar
loginUrl= 'http://120.55.151.61/V2/StudentSkip/loginCheckV4.action'
headers= {
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent':'Dalvik/1.6.0 (Linux; U; Android 4.1.1; M040 Build/JRO03H)',
'Host':'120.55.151.61',
'Connection':'Keep-Alive',
'Accept-Encoding':'gzip',
'Content-Length':'207',
}
loginData= 'phoneBrand=Meizu&platform=1&deviceCode=868033014919494&account=FCF030E1F2F6341C1C93BE5BBC422A3D&phoneVersion=16&password=A55B48BB75C79200379D82A18C5F47D6&channel=MXMarket&phoneModel=M040&versionNumber=7.2.1&'
cookieJar= CookieJar()
opener= urllib2.build_opener(urllib2.HTTPCookieProcessor(cookieJar))
req= urllib2.Request(loginUrl, loginData, headers)
loginResult= opener.open(req).read()
print loginResult
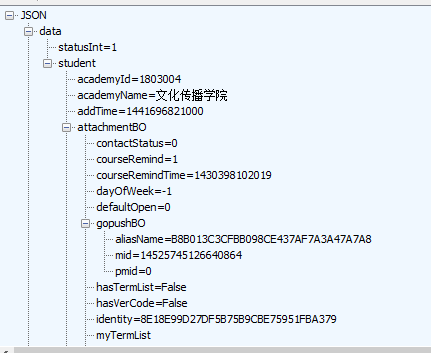
登录成功 会返回一串账号信息的json数据

和抓包时返回数据一样,证明登录成功
3、抓取数据
用同样方法得到话题的url和post参数
下见最终代码,有主页获取和下拉加载更新。可以无限加载话题内容。
?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
#!/usr/local/bin/python2.7
# -*- coding: utf8 -*-
"""
超级课程表话题抓取
"""
import urllib2
from cookielibimport CookieJar
import json
''' 读Json数据 '''
def fetch_data(json_data):
data= json_data['data']
timestampLong= data['timestampLong']
messageBO= data['messageBOs']
topicList= []
for eachin messageBO:
topicDict= {}
if each.get('content',False):
topicDict['content']= each['content']
topicDict['schoolName']= each['schoolName']
topicDict['messageId']= each['messageId']
topicDict['gender']= each['studentBO']['gender']
topicDict['time']= each['issueTime']
print each['schoolName'],each['content']
topicList.append(topicDict)
return timestampLong, topicList
''' 加载更多 '''
def load(timestamp, headers, url):
headers['Content-Length']= '159'
loadData= 'timestamp=%s&phoneBrand=Meizu&platform=1&genderType=-1&topicId=19&phoneVersion=16&selectType=3&channel=MXMarket&phoneModel=M040&versionNumber=7.2.1&' % timestamp
req= urllib2.Request(url, loadData, headers)
loadResult= opener.open(req).read()
loginStatus= json.loads(loadResult).get('status',False)
if loginStatus== 1:
print 'load successful!'
timestamp, topicList= fetch_data(json.loads(loadResult))
load(timestamp, headers, url)
else:
print 'load fail'
print loadResult
return False
loginUrl= 'http://120.55.151.61/V2/StudentSkip/loginCheckV4.action'
topicUrl= 'http://120.55.151.61/V2/Treehole/Message/getMessageByTopicIdV3.action'
headers= {
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent':'Dalvik/1.6.0 (Linux; U; Android 4.1.1; M040 Build/JRO03H)',
'Host':'120.55.151.61',
'Connection':'Keep-Alive',
'Accept-Encoding':'gzip',
'Content-Length':'207',
}
''' ---登录部分--- '''
loginData= 'phoneBrand=Meizu&platform=1&deviceCode=868033014919494&account=FCF030E1F2F6341C1C93BE5BBC422A3D&phoneVersion=16&password=A55B48BB75C79200379D82A18C5F47D6&channel=MXMarket&phoneModel=M040&versionNumber=7.2.1&'
cookieJar= CookieJar()
opener= urllib2.build_opener(urllib2.HTTPCookieProcessor(cookieJar))
req= urllib2.Request(loginUrl, loginData, headers)
loginResult= opener.open(req).read()
loginStatus= json.loads(loginResult).get('data',False)
if loginResult:
print 'login successful!'
else:
print 'login fail'
print loginResult
''' ---获取话题--- '''
topicData= 'timestamp=0&phoneBrand=Meizu&platform=1&genderType=-1&topicId=19&phoneVersion=16&selectType=3&channel=MXMarket&phoneModel=M040&versionNumber=7.2.1&'
headers['Content-Length']= '147'
topicRequest= urllib2.Request(topicUrl, topicData, headers)
topicHtml= opener.open(topicRequest).read()
topicJson= json.loads(topicHtml)
topicStatus= topicJson.get('status',False)
print topicJson
if topicStatus== 1:
print 'fetch topic success!'
timestamp, topicList= fetch_data(topicJson)
load(timestamp, headers, topicUrl)
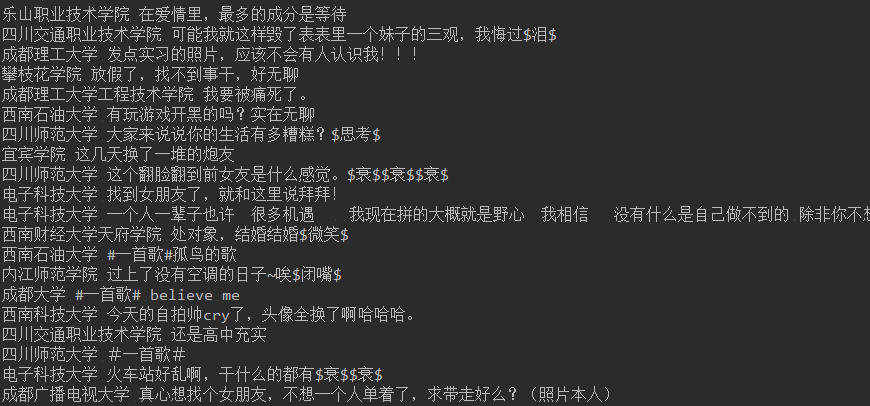
结果:
python爬虫抓取数据的步骤-Python爬虫抓取手机APP的传输数据相关推荐
- python爬虫app步骤_Python爬虫抓取手机APP的传输数据,python爬虫抓取app
Python爬虫抓取手机APP的传输数据,python爬虫抓取app 大多数APP里面返回的是json格式数据,或者一堆加密过的数据 .这里以超级课程表APP为例,抓取超级课程表里用户发的话题. 1. ...
- python爬app_Python爬虫抓取手机APP的传输数据
大多数APP里面返回的是json格式数据,或者一堆加密过的数据 .这里以超级课程表APP为例,抓取超级课程表里用户发的话题. 1.抓取APP数据包 方法详细可以参考这篇博文:Fiddler如何抓取手机 ...
- 网络爬虫入门:网络爬虫的目的,企业获取数据的方式,可以用于做爬虫的程序语言,爬虫爬取数据的步骤
目录 爬取数据的目的: 1.获取大量数据,用于做数据分析 2.公司项目的测试数据,公司业务所需数据 企业获取数据的方式 1.公司自有数据 2.第三方数据平台购买(数据堂,贵阳大数据交易所) 3.爬虫爬 ...
- 爬虫python的爬取步骤-Python爬虫爬取数据的步骤
爬虫: 网络爬虫是捜索引擎抓取系统(Baidu.Google等)的重要组成部分.主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份. 步骤: 第一步:获取网页链接 1.观察需要爬取的多 ...
- python爬取网页数据流程_Python爬虫爬取数据的步骤
爬虫: 网络爬虫是捜索引擎抓取系统(Baidu.Google等)的重要组成部分.主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份. 步骤: 第一步:获取网页链接 1.观察需要爬取的多 ...
- Python爬虫爬取数据的步骤
爬虫: 网络爬虫是捜索引擎抓取系统(Baidu.Google等)的重要组成部分.主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份. 步骤: 第一步:获取网页链接 1.观察需要爬取的多 ...
- python爬虫步骤-Python爬虫爬取数据的步骤
爬虫: 网络爬虫是捜索引擎抓取系统(Baidu.Google等)的重要组成部分.主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份. 步骤: 第一步:获取网页链接 1.观察需要爬取的多 ...
- python爬取数据步骤_Python爬虫爬取数据的步骤
爬虫: 网络爬虫是捜索引擎抓取系统(Baidu.Google等)的重要组成部分.主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份. 步骤: 第一步:获取网页链接 1.观察需要爬取的多 ...
- python定时爬取数据_python实现scrapy爬虫每天定时抓取数据的示例代码
1. 前言. 1.1. 需求背景. 每天抓取的是同一份商品的数据,用来做趋势分析. 要求每天都需要抓一份,也仅限抓取一份数据. 但是整个爬取数据的过程在时间上并不确定,受本地网络,代理速度,抓取数据量 ...
最新文章
- 提取Windows用户密钥文件cachedump
- python培训班深圳-深圳哪里有Python培训班?
- Normal Equations 的由来与推导
- 还不知道要看什么小说嘛?爬取小说网站前10页的小说数据分析一波
- same things betewen university and companies
- java 语音匹配,java-语音识别,是否可以通过正则表达式确定用户所说的内容?
- RocketMQ学习
- matlab的czt变换,CZT变换(chirp z-transform)
- android studio 2.0 导入工程
- FastDFS服务器搭建
- 为啥有的人能受穷,却不能吃苦?
- Windows一般都用系统进程来加载内核模块
- 谷歌翻译突然用不了了
- tar 打包隐藏文件
- 天下3 最多的服务器,《天下3》服务器合并规则
- html 图片滑动验证码,selenium滑动验证码
- 微信支付服务商以及特约商户相关总结
- 解决IDEA的HTML文件格式的显示问题
- 蔡司影像,品阅时光:年度影像旗舰vivo X70系列发布
- 淘宝天猫如何导入数据包批量上传宝贝的方法