python爬取淘宝商品信息并加入购物车
先说一下最终要达到的效果:谷歌浏览器登陆淘宝后,运行python项目,将任意任意淘宝商品的链接传入,并手动选择商品属性,输出其价格与剩余库存,然后选择购买数,自动加入购物车。
在开始爬取淘宝链接之前,咱么要先做一些准备工作,我项目中使用的是 python2.7 ,开发与运行环境都是win10,浏览器是64位chrome 59.0.3。由于淘宝的模拟登陆涉及到一些复杂的UA码算法以及滑块登陆验证,能力有限,为了图省事就使用浏览器手动登录淘宝然后python获取生成的cookie的方式来爬取登录后的数据。
要获取登录成功后的cookie,一种办法是浏览器打开开发者工具,手动复制cookie,但是这样比较麻烦,因为淘宝里面的请求很多不是同一个域,所以发送给服务器的cookie也不一样,如果换一个地址就手动复制一次也太low了,咱们为了有big一些,直接读取chrome存储在本地的cookie,然后拼出来。
网上查了一下,chrome的中的cookie以sqlite的方式存储在 %LOCALAPPDATA%GoogleChromeUser DataDefaultCookies 目录下,cookie的value也经过了CryptUnprotectData加密。知道了这些,我们就可以往下走了。
这里要用到sqlite3模块:
def get_cookie(url):"""获取该的可用cookie:param url::return:"""domain = urllib2.splithost(urllib2.splittype(url)[1])[0]domain_list = ['.' + domain, domain]if len(domain.split('.')) > 2:dot_index = domain.find('.')domain_list.append(domain[dot_index:])domain_list.append(domain[dot_index + 1:])conn = Nonecookie_str = Nonetry:conn = sqlite3.connect(r'%s\Google\Chrome\User Data\Default\Cookies' % os.getenv('LOCALAPPDATA'))cursor = conn.cursor()print '-' * 50sql = 'select host_key, name, value, encrypted_value, path from cookies where host_key in (%s)' % ','.join(['"%s"' % x for x in domain_list])row_list = cursor.execute(sql).fetchall()print u'一共找到 %d 条' % len(row_list)print '-' * 50print u'%-20s\t%-5s\t%-5s\t%s' % (u'域', u'键', u'值', u'路径')cookie_list = []for host_key, name, value, encrypted_value, path in row_list:decrypted_value = win32crypt.CryptUnprotectData(encrypted_value, None, None, None, 0)[1].decode(print_charset) or valuecookie_list.append(name + '=' + decrypted_value)print u'%-20s\t%-5s\t%-5s\t%s' % (host_key, name, decrypted_value, path)print '-' * 50cookie_str = '; '.join(cookie_list)except Exception:raise CookieException()finally:conn.close()return cookie_str, domain````
get_cookie函数的开头需要获取domain_list是因为淘宝的一些请求是跨域共享cookie的,所以要把该url所有可用的cookie提取出来。然后,我们就可以拿着这个cookie去请求登陆后的数据啦,不过在此之前最好再说一件事——设置代理,防止本机的IP被封禁。建议使用高匿代理,这样淘宝就检测不出原地址啦,代理的获取途径有很多,网上有免费的代理,虽然不是很稳定,不过咱们只是玩玩嘛,就不计较这些了,随便百度了一下,找到一个www.xicidaili.com网站,咱们就爬取这个网站的高匿代理来作为我们的代理,获取成功后访问bing来测试咱们的代理是否可用:def set_proxy():
"""
设置代理
"""
# 获取xicidaili的高匿代理
proxy_info_list = [] # 抓取到的ip列表
for page in range(1, 2): # 暂时只抓第一页request = urllib2.Request('http://www.xicidaili.com/nn/%d' % page)request.add_header('Accept-Encoding', 'gzip, deflate')request.add_header('Accept', 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8')request.add_header('Accept-Language', 'zh-CN,zh;q=0.8,en;q=0.6')request.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36')response = urllib2.urlopen(request, timeout=5)headers = response.info()content_type = headers.get('Content-Type')if content_type:charset = re.findall(r"charset=([\w-]+);?", content_type)[0]else:charset = 'utf-8'if headers.get('Content-Encoding') == 'gzip':gz = gzip.GzipFile(fileobj=StringIO.StringIO(response.read()))content = gz.read().decode(charset)gz.close()else:content = response.read().decode(charset)response.close()print u'获取第 %d 页' % pageip_page = re.findall(r'<td>(\d.*?)</td>', content)proxy_info_list.extend(ip_page)time.sleep(random.choice(range(1, 3)))# 打印抓取的内容
print u'代理IP地址\t端口\t存活时间\t验证时间'
for i in range(0, len(proxy_info_list), 4):print u'%s\t%s\t%s\t%s' % (proxy_info_list[i], proxy_info_list[i + 1], proxy_info_list[i + 2], proxy_info_list[i + 3])all_proxy_list = [] # 待验证的代理列表
# proxy_list = [] # 可用的代理列表
for i in range(0, len(proxy_info_list), 4):proxy_host = proxy_info_list[i] + ':' + proxy_info_list[i + 1]all_proxy_list.append(proxy_host)# 开始验证# 单线程方式
for i in range(len(all_proxy_list)):proxy_host = test(all_proxy_list[i])if proxy_host:break
else:# TODO 进入下一页print u'没有可用的代理'return None# 多线程方式
# threads = []
# # for i in range(len(all_proxy_list)):
# for i in range(5):
# thread = threading.Thread(target=test, args=[all_proxy_list[i]])
# threads.append(thread)
# time.sleep(random.uniform(0, 1))
# thread.start()
#
# # 等待所有线程结束
# for t in threading.enumerate():
# if t is threading.currentThread():
# continue
# t.join()
#
# if not proxy_list:
# print u'没有可用的代理'
# # TODO 进入下一页
# sys.exit(0)
print u'使用代理: %s' % proxy_host
urllib2.install_opener(urllib2.build_opener(urllib2.ProxyHandler({'http': proxy_host})))```本来是想使用多线程来验证代理可用性,当有一个测试通过后想关闭其他线程,结束验证请求,但是没找到解决办法,就暂时先用循环一个一个来验证了,有其他思路想法的小伙伴可以在留言区指教。
接下来,我们需要获取商品每个sku所对应的价格和库存,先说一下我的分析过程,有更好的分析方法可以留言或私信交流。打开 Chrome Web Developer Tools ,输入某个淘宝商品的地址,将工具切换到Network标签,然后在标签内容中右键 - > save as HAR with content,将当前所有请求和响应的文本内容保存到本地,用编辑器打开,然后通过关键字搜索想要的东西然后分析猜测。
经过推测,淘宝中每个商品属性有一个id保存在data-value中,
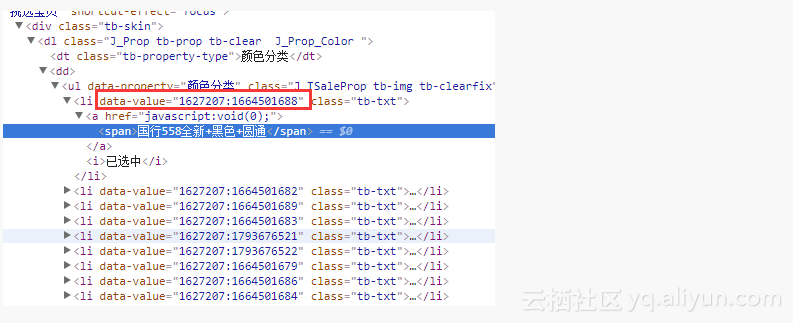
通过不同的属性值可以组合成不同的“sku_key”,然后通关页面中的skuMap来获取该sku_key对应的sku信息
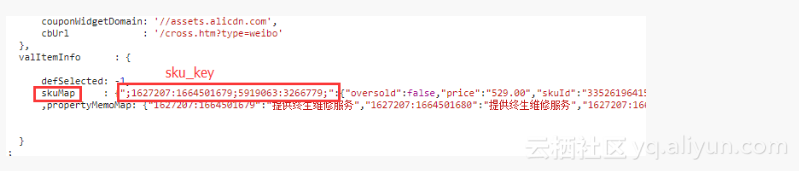
这里有三步比较关键
通过正则来获取页面中的skuMap数据,然后转化为python的字典对象;
对不同的属性值进行排列组合,寻找是否有sku_key(通过itertools模块的permutations函数实现)
将中文的属性名和属性值对应起来,以便于后续通过输入属性来获取sku数据
def get_base_info(page_url):"""从页面获取基本的参数:param page_url: :return:"""page_url = page_url.strip()cookie_str = get_cookie(page_url)print u'page cookie :', cookie_strrequest = urllib2.Request(page_url)request.add_header('Accept', 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8')request.add_header('Accept-Encoding', 'gzip, deflate, br')request.add_header('Cookie', cookie_str)request.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36')response = urllib2.urlopen(request)headers = response.info()content_type = headers.get('Content-Type')if content_type:charset = re.findall(r"charset=([\w-]+);?", content_type)[0]else:charset = 'utf-8'if headers.get('Content-Encoding') == 'gzip':gz = gzip.GzipFile(fileobj=StringIO.StringIO(response.read()))content = gz.read().decode(charset)gz.close()else:content = response.read().decode(charset)with open(u'.\content.html', 'w+') as page_file:page_file.write(content.encode(print_charset)) # 写入文件待观察# 获取item_iditem_id = re.findall(r'(^|&)id=([^&]*)(&|$)', page_url[page_url.find('?'):])[0][1]# 获取sku_dictsku_map = json.loads(re.findall(r'skuMap\s*:\s*(\{.*\})\n\r?', content)[0])sku_dict = {}for k, v in sku_map.items():sku_dict[k] = {'price': v['price'], # 非推广价'stock': v['stock'], # 库存'sku_id': v['skuId'] # skuId}ct = re.findall(r'"ct"\s*:\s*"(\w*)",', content)[0]timestamp = int(time.time())doc = pq(content)# ========== 获取每个类别属性及其属性值的集合 start ==========prop_to_values = {}for prop in doc('.J_Prop ').items():values = []for v in prop.find('li').items():values.append({'name': v.children('a').text(),'code': v.attr('data-value')})prop_to_values[prop.find('.tb-property-type').text()] = values# ========== end ==========return {'ct': ct,'nekot': timestamp,'item_id': item_id,'prop_to_values': prop_to_values,'sku_dict': sku_dict}```
这个函数取名叫get_base_info是因为经过几个案例分析,发现页面上的价格和库存并不是淘宝最后显示的数据,真实的数据需要通过https://detailskip.taobao.com/service/getData/1/p1/item/detail/sib.htm来获取,这里面包括了一些库存、推广信息。获取可以出售的商品信息:def get_sale_info(sib_url):
"""
获取可以出售的商品信息
:param sib_url:
:return:
"""
cookie_str, host = get_cookie(sib_url)
print u'sale cookie :', cookie_strrequest = urllib2.Request(sib_url)
request.add_header('Accept', '*/*')
request.add_header('Accept-Encoding', 'gzip, deflate, br')
request.add_header('Accept-Language', 'zh-CN,zh;q=0.8,en;q=0.6')
request.add_header('Connection', 'keep - alive')
request.add_header('Cookie', cookie_str)
request.add_header('Host', host)
request.add_header('Referer', 'https://item.taobao.com')
request.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36')
response = urllib2.urlopen(request)headers = response.info()# 获取字符集
content_type = headers.get('Content-Type')
if content_type:charset = re.findall(r"charset=([\w-]+);?", content_type)[0]
else:charset = 'utf-8'if headers.get('Content-Encoding') == 'gzip':gz = gzip.GzipFile(fileobj=StringIO.StringIO(response.read()))content = gz.read().decode(charset)gz.close()
else:content = response.read().decode(charset)
json_obj = json.loads(content)
sellable_sku = json_obj['data']['dynStock']['sku'] # 可以售卖的sku
promo_sku = json_obj['data']['promotion']['promoData'] # 推广中的sku
if promo_sku:for k, v in sellable_sku.items():promos = promo_sku[k]if len(promos) > 1:print u'有多个促销价,建议手动确认'price = min([float(x['price']) for x in promos])v['price'] = price# TODO amountRestriction 限购数量
return sellable_sku```ps:不久前才发现还有限购数量的限制,不过并不影响后续加入购物车的操作,就暂时先加入TODO,以后再更新
最后通过终端输入地址和属性获取商品信息,看看能不能成功。
def check_item():page_url = raw_input(u'请输入商品地址:'.encode(print_charset)).decode(print_charset)base_info = get_base_info(page_url)item_id = base_info['item_id']modules = ['dynStock', 'qrcode', 'viewer', 'price', 'duty', 'xmpPromotion', 'delivery', 'activity','fqg', 'zjys', 'couponActivity', 'soldQuantity', 'contract', 'tradeContract']ajax_url = 'https://detailskip.taobao.com/service/getData/1/p1/item/detail/sib.htm?itemId=%s&modules=%s' % (item_id, ','.join(modules))print 'request -> ', ajax_urlsku_dict = get_sale_info(ajax_url)prop_to_values = base_info['prop_to_values']base_info_sku_dict = base_info['sku_dict']info = {'ct': base_info['ct'],'nekot': base_info['nekot'],'item_id': base_info['item_id'],'prop_to_values': prop_to_values,}for k, v in sku_dict.items():v['sku_id'] = base_info_sku_dict[k].get('sku_id')if 'price' not in v.keys():v['price'] = base_info_sku_dict[k].get('price')info['sku_dict'] = sku_dictwith open(u'.\sku.json', 'w+') as sku_file:sku_file.write(json.dumps(info, ensure_ascii=False).encode('utf-8'))code_list = []item_prop = raw_input(u'请输入商品类别名称(如:颜色分类,直接回车结束输入):'.encode(print_charset)).decode(print_charset)while item_prop:if item_prop in prop_to_values.keys():prop_values = prop_to_values[item_prop]sku_value = raw_input(u'请输入商品属性(如:可爱粉):'.encode(print_charset)).decode(print_charset)for v in prop_values:if v.get('name') == sku_value:code_list.append(v.get('code'))breakelse:print u'没有该属性'else:print u'没有该类别'item_prop = raw_input(u'请输入商品类别名称(如:颜色分类,直接回车结束输入):'.encode(print_charset)).decode(print_charset)sku_id = Noneprice = Nonestock = Nonefor x in list(permutations(code_list, len(code_list))):if ';' + ';'.join(map(str, x)) + ';' in sku_dict.keys():item_prop = ';' + ';'.join(map(str, x)) + ';'sku_id = sku_dict[item_prop]['sku_id']price = sku_dict[item_prop]['price']stock = sku_dict[item_prop]['stock']print u'%s\t%s' % (u'sku_key为:', item_prop)print u'%s\t%s' % (u'sku_id为:', sku_id)print u'%s\t%s' % (u'单价为:', price)print u'%s\t%s' % (u'库存为:', stock)breakelse:print u'没有该款式。'如果以上输出没毛病,就可以正式进入下一步了,加入购物车,试着自己在浏览器上加入购物车,然后观察请求,发现请求是通过cart.taobao.com/add_cart_item.htm这个地址发送的,分析了一下关键的发送参数:
item_id —— 商品ID(页面的g_config中)
outer_id —— skuId(skuMap中)
outer_id_type —— outer_id类型,2表示outer_id传递的是skuid
quantity —— 需要加入购物车的数量
opp —— 单价
tb_token —— 可以从cookie中获取
ct —— (g_config.vdata.viewer中)
deliveryCityCode —— 发货城市 (sib.htm中,暂时取默认或者不填)
nekot —— 当前时间戳
既然需要的东西都找到了,那就好办了:
def add_item_to_cart(item_id, sku_id, price, ct, nekot, tb_token, stock):"""添加商品到购物车:param item_id: :param sku_id: :param price: :param ct: :param nekot: :param tb_token: :param stock: :return: """add_cart_url = 'https://cart.taobao.com/add_cart_item.htm?'cookie_str, host = get_cookie(add_cart_url)print u'cookie串:', cookie_strquantity = raw_input(u'请输入需要加到购物车的数量:'.encode(print_charset))if quantity.isdigit():quantity = int(quantity)if quantity > stock:print u'超过最大库存', stockelse:print u'非法输入'params = {'item_id': item_id,'outer_id': sku_id,'outer_id_type': '2','quantity': quantity,'opp': price,'nekot': nekot,'ct': ct,'_tb_token_': tb_token,'deliveryCityCode': '','frm': '','buyer_from': '','item_url_refer': '','root_refer': '','flushingPictureServiceId': '','spm': '','ybhpss': ''}request = urllib2.Request(add_cart_url + urllib.urlencode(params))request.add_header('Accept', '*/*')request.add_header('Accept-Encoding', 'gzip, deflate, br')request.add_header('Accept-Language', 'zh-CN,zh;q=0.8,en;q=0.6')request.add_header('Connection', 'keep - alive')request.add_header('Cookie', cookie_str)request.add_header('Host', host)request.add_header('Referer', 'https://item.taobao.com/item.htm')request.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36')response = urllib2.urlopen(request)headers = response.info()content_type = headers.get('Content-Type')if content_type:charset = re.findall(r"charset=([\w-]+);?", content_type)[0]else:charset = 'utf-8'http_code = response.getcode()if http_code == 200:print u'添加到购物车成功'这里需要注意http_code=200时不一定是加入成功,如果没有登录也会返回200,后续研究后会完善。
python爬取淘宝商品信息并加入购物车相关推荐
- Python爬取淘宝商品信息保存到Excel
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取 python免费学习资 ...
- 使用python爬取淘宝商品信息
使用python爬虫爬取淘宝商品信息 使用的模块主要有 selenium ,time , re, from selenium import webdriver import time import c ...
- python爬取淘宝商品信息_python爬取淘宝商品信息并加入购物车
先说一下最终要达到的效果:谷歌浏览器登陆淘宝后,运行python项目,将任意任意淘宝商品的链接传入,并手动选择商品属性,输出其价格与剩余库存,然后选择购买数,自动加入购物车. 在开始爬取淘宝链接之前, ...
- Python 爬取淘宝商品信息栏目
一.相关知识点 1.1.Selenium Selenium是一个强大的开源Web功能测试工具系列,可进行读入测试套件.执行测试和记录测试结果,模拟真实用户操作,包括浏览页面.点击链接.输入文字.提交表 ...
- python爬虫——用selenium爬取淘宝商品信息
python爬虫--用selenium爬取淘宝商品信息 1.附上效果图 2.淘宝网址https://www.taobao.com/ 3.先写好头部 browser = webdriver.Chrome ...
- python+scrapy简单爬取淘宝商品信息
python结合scrapy爬取淘宝商品信息 一.功能说明: 已实现功能: 通过scrapy接入selenium获取淘宝关键字搜索内容下的商品信息. 待扩展功能: 爬取商品中的全部其他商品信息. 二. ...
- python淘宝爬虫_python爬虫爬取淘宝商品信息
本文实例为大家分享了python爬取淘宝商品的具体代码,供大家参考,具体内容如下 import requests as req import re def getHTMLText(url): try: ...
- 利用Selenium爬取淘宝商品信息
文章来源:公众号-智能化IT系统. 一. Selenium和PhantomJS介绍 Selenium是一个用于Web应用程序测试的工具,Selenium直接运行在浏览器中,就像真正的用户在操作一样. ...
- 爬取淘宝商品信息selenium+pyquery+mongodb
''' 爬取淘宝商品信息,通过selenium获得渲染后的源码,pyquery解析,mongodb存储 '''from selenium import webdriver from selenium. ...
最新文章
- JSONUtil,POJO实体类和JSON互转,
- pandas统计缺失值的个数
- 密码学基础(1)-前言
- Spark 1.1.1 Programing Guide
- odciexttableopen 调用出错 error open log_如何在 Spring 异步调用中传递上下文
- 多个表添加几个相同的字段
- for循环一种不常见的用法
- Android系统(62)---Alarm的机制
- 网站域名安全:泛解析处理及防护
- python内置函数type_Python基于内置函数type创建新类型
- shell脚本-从路径提取文件名、后缀
- Eclipse离线安装Svn插件
- 通过Windows的bat方式一键给计算机网卡替换IP地址
- 跨平台应用开发进阶(四) :uni-app 实现上传图片
- 问题解决--npm install 安装依赖一直失败
- Java 在接口Interface中 使用关键字 default
- 2021年电工(初级)考试资料及电工(初级)考试总结
- Codeforces-1487 D. Pythagorean Triples(数学)
- ABAP 数字前导零,去除前导零
- (原创)android6.0系统 PowerManager深入分析