如何在Python中使用LightFM构建可扩展的电子商务推荐系统?
AI 前线导读:在我国,电商非常发达。今年双 11 的成交额仅仅过了 12 小时就达到了惊人的 1491.6 亿元!电商在我国的火爆程度由此可见一斑。不知你们有没有发现,在网店浏览商品时,它们好像能读懂你的内心,推荐的几乎都是你想找的宝贝?其实,这背后的功臣就是人工智能的应用之一——推荐系统。今天,我们分享了一篇在 Python 中使用 LightFM 构建可扩展的电子商务推荐系统的文章,以飨读者。
更多干货内容请关注微信公众号“AI 前线”(ID:ai-front)
在过去的几年里,网购的形式发生了翻天覆地的变化。像 Amazon 这样的网店,以更为个性化的方式来接待客户。这些网店根据客户的网购活动(如查看商品、往购物车里添加商品以及最终下单的商品等)来了解客户对某些商品的兴趣。例如,你在 Amazon 上搜索某件商品,然后点击其中一些搜索结果。当你下一次再次登陆 Amazon 时,会看到页面上有一块特定部分:“与您浏览过的商品相关的推荐”,里面罗列的是根据你上次搜索内容为你推荐的类似商品。但故事并未就此结束,随着你与网店进行更多的交互,你将会得到更多的个性化建议,包括 “购买此商品的顾客也同时购买……”,并向你显示经常一起购买的商品列表。另外,一些商店还会发送促销电邮,提供针对客户更有可能购买的商品清单。
推荐系统是机器学习最常用的应用之一。由于本文的目标是专注于如何使用 LightFM 包来构建推荐系统,并提供明确的指标来衡量模型性能,因此,我将只会简单提一下不同类型的推荐系统。要了解有关推荐系统的更多详情,我推荐观看 Siraj Raval 制作的这部短片, 并阅读 Chhavi Aluja 撰写的这篇文章《Recommendation Systems made simple!》。
推荐系统有三种类型如下:
Content-Based(基于内容的推荐);
Collaborative Filtering(协同过滤,CF)(Item-Based、User-Based、Model-Based)
混合方法(整合基于内容的推荐和协同过滤)
我最初的目标是构建一个混合模型,因为它可以将基于内容的推荐整合到协同过滤中,并能够通过纯协同过滤推荐系统来解决冷启动问题。然而,有着公开可用的良好数据集,且同时具有商品或用户的元数据和评级交互,并不是很多。因此,我决定先研究协作过滤模型并理解推荐系统的不同方面,在下一篇文章中,我将会构建一个混合模型。
AI 前线注:所谓冷启动问题,就是在对用户一无所知的情况下,如何进行最有效的推荐。
实现方法
为什么选择 LightFM?
我在研究推荐系统时,我无意碰到了许多相关的重大项目,然而,这些项目都缺少一个用于评估模型性能的明确指标。我认为,如果你无法通过提供的明确指标来评估模型的性能,那么你可能很难让人相信这个推荐系统模型运行良好。因此,我选择 LightFM 的原因是,它提供了明确的指标,可以用于评估训练模型的性能的 AUC 得分、Precision@K 等。如果想构建更好的模型并实现更高的正确率(accuracy),这可能非常有用。
根据用例或我们要解决的问题类型,究竟是选择 Precision@K 还是 AUC 分数,这可能是个棘手的问题。在这种情况下,我们将使用 AUC 分数,因为它能够测量综合排名质量,并能够被解释为随机选择的正向条目排名高于随机的负向条目的概率。
根据 LightFM 的文档可知,“LightFM 是针对隐式和显式反馈的许多流行的推荐算法的 Python 实现,包括 BPR 和 WARP 排名损失的有效实现。它具备易用、快速(通过多线程模型估计)的特点,能够产生高质量的结果。”
AI 前线注:LightFM 官方文档网址为:http://lyst.github.io/lightfm/docs/home.html
数据
对于这个项目,我们将使用 Book-Crossing 数据集 来实现基于矩阵分解(Matrix Factorization) 方法的纯协同过滤模型。我们将利用 Chhavi Aluja 在博文《My Journey to building Book Recommendation System…》 中提到的方法,进行数据清洗,并为数据集进行预处理。让我们来看一下数据:

以上代码块的用途是常规数据清洗,以确保在将数据用于模型中的输入之前,数据格式是正确的。此外,我们还需要确保评级数据帧中的所有行都代表了来自用户和图书数据帧的数据。接下来,评级必须只包括有效的评级分数(1-10),因此我们应该去掉所有评级值为零的所有行。

这是评级值的分布:
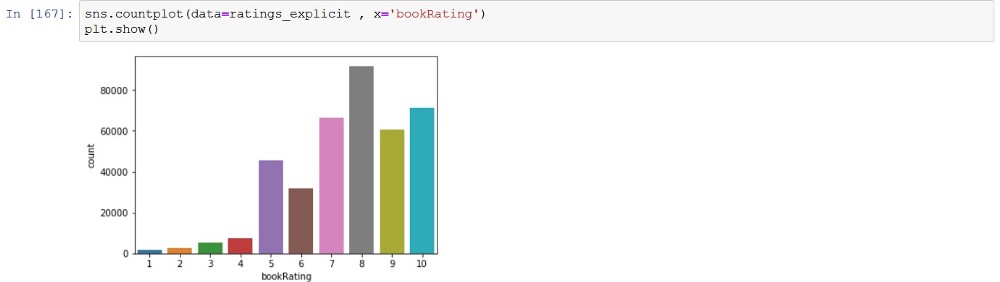
要完成数据预处理的最后一件事就是,为已评级图书的用户数量和用户评分的图书数量指定一个阈值。换言之,我们必须有用户和图书的最低评级计算数量。我认为,只有至少为 20 本图书评级的用户和至少被 20 位用户评级的图书,这样感觉就会很好。
ratings_explicit.shape
(217729, 3)
训练模型
在此步骤中,我们将训练模型,但问题有所不同。在协同过滤模型中,我们寻找基于 user-item 交互的每个商品(图书)的潜在特征,并寻找每个用户对每个潜在特征发现的相关性。这一过程是通过矩阵分解来完成的。首先我们需要将数据 (ratings_explict) 分成训练集和测试集。这正是使事情变得棘手的地方。 很明显,纯协同过滤方法并不能解决冷启动问题。因此,必须完成拆分训练集和测试集,这样,测试集中的用户或图书的实例就能在训练集中有剩余的实例:
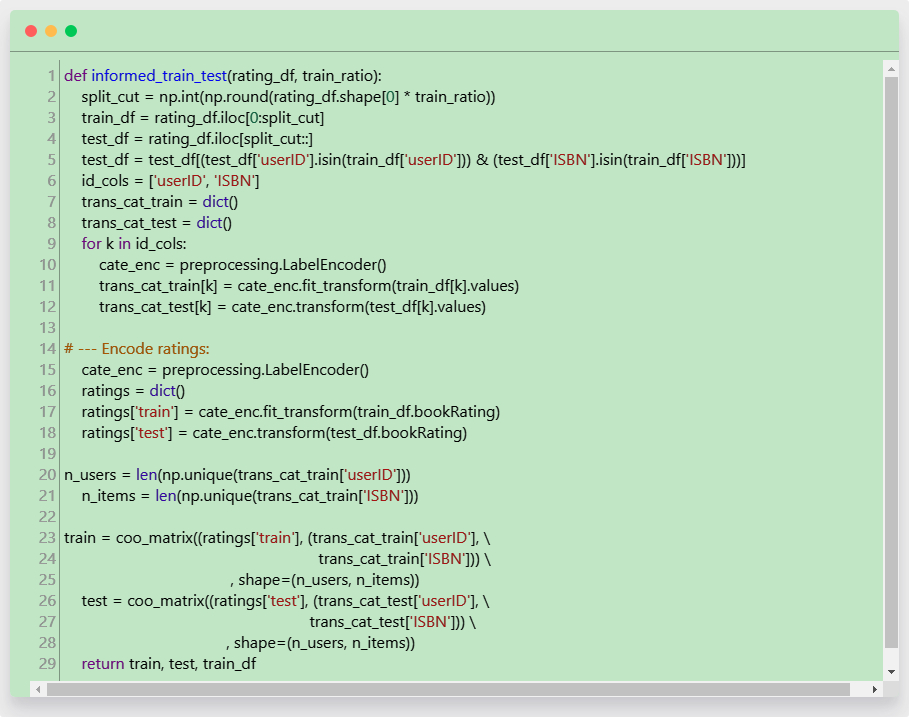
函数 informed_train_test() 返回训练集和测试集的 coo 矩阵,以及原始训练数据帧,以便稍后评估模型。让我们看看如何如何配合模型来评估其性能:

— Run time: 4.7663776795069377 mins —Train AUC Score: 0.9801499843597412Test AUC Score: 0.853681743144989
正如预期那样,训练集的 AUC 分数接近 1,我们的测试集中 AUC 得分为 0.853,情况不算太差。使用随机搜索来调整用于训练 LightFM 模型的参数。由于 GridSearch 的运行成本太高,因此我决定在 scikit-optimize 包中使用函数 forest_minimize() 来调整参数。有关调整参数的函数更多详情,请参阅本文的 GitHub 页面。
我清楚,我之前提到的纯协同过滤,对向没有与网店进行任何交互的新用户推荐商品(冷启动问题)的预期效果不佳。在 LightFM 文档中提供的示例中,他们还表明,使用电影数据集向新客户推荐影片的纯协同方法并不能得到令人满意的结果。但是,出于好奇,我还是自己想测试一下 book-crossing 数据集。令人惊讶的是,测试结果显示数据集对冷启动问题反应良好,AUC 分数相对较高!在这种情况下训练模型,唯一的区别是,我们随机将数据集分成训练集和测试集。这意味着在训练集和测试集中具有共同的 user-item 交互的概率完全是随机的:

现在,我们来看一看随机训练 - 测试分组中 AUC 分数的差异:
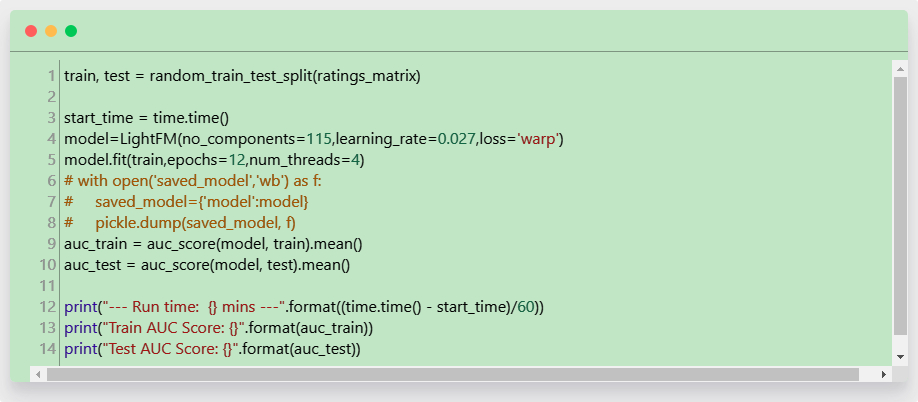
— Run time: 8.281255984306336 mins —Train AUC Score: 0.9871253967285156Test AUC Score: 0.6499683856964111
对于随机拆分数据,预计可以得到 0.5 左右的 AUC 分数,但我们可以看到,因为我们的 AUC 分数为 0.649,相比通过掷硬币来向新用户推荐商品或想当前用户推荐新商品,我们的表现则要好得多。我将此行为的进一步分析留给本文读者来做。
应用
让我们假设,售出数据集中的图书是我们正销售的商品,数据集中的用户实际上是预期的客户。为了更接近电子商务网店的实际情况,我们可以做的一件事是改变评级值,将其值的范围从(1-10)缩小到(7-10)。客户的互动行为可归纳为:
A - 浏览商品;B - 点击商品;C - 将商品加到购物车中;D - 下单购买商品。
因此,在这种情况下,通过将评级值降低到前 4 个评级(7,8,9,10),我们就可以对上述 item-customer 互动进行更为逼真的模拟。
推荐系统有三种主要方案可用于电子商务应用。 限于篇幅,在本文中,我不提供为下一节中提供结果的函数的实际代码,你可以在 GitHub repo 中的 Jupyter notebook 中看到:https://github.com/nxs5899/Recommender-System-LightFM
- 最常见的情景是根据客户的交易(如浏览和点击商品)向特定客户提供的典型建议:
user_dikt, item_dikt = user_item_dikts(user_item_matrix, books)similar_recommendation(model, user_item_matrix, 254, user_dikt, item_dikt,threshold = 7)Items that were liked (selected) by the User: 1- The Devil You Know 2- Harlequin Valentine 3- Shout!: The Beatles in Their Generation 4- Sandman: The Dream Hunters 5- Dream Country (Sandman, Book 3) 6- Assata: An Autobiography (Lawrence Hill \u0026amp; amp; Co.) 7- The Golden Compass (His Dark Materials, Book 1) 8- The Fellowship of the Ring (The Lord of the Rings, Part 1) 9- The Hobbit: or There and Back Again 10- Harry Potter and the Sorcerer's Stone (Book 1) 11- Something Wicked This Way Comes 12- Martian Chronicles 13- Animal Farm 14- 1984 15- The Dark Half 16- Harry Potter and the Goblet of Fire (Book 4) 17- Harry Potter and the Prisoner of Azkaban (Book 3) 18- Harry Potter and the Prisoner of Azkaban (Book 3) 19- Harry Potter and the Chamber of Secrets (Book 2) 20- Harry Potter and the Chamber of Secrets (Book 2) 21- The Bonesetter's Daughter 22- The Wolves in the Walls 23- Stardust 24- Martian Chronicles 25- American Gods: A NovelRecommended Items: 1- The Lovely Bones: A Novel 2- Harry Potter and the Order of the Phoenix (Book 5) 3- The Catcher in the Rye 4- The Da Vinci Code 5- Harry Potter and the Sorcerer's Stone (Harry Potter (Paperback)) 6- Red Dragon 7- Interview with the Vampire 8- Divine Secrets of the Ya-Ya Sisterhood: A Novel 9- Sphere 10- The Pelican Brief 11- Little Altars Everywhere: A Novel 12- To Kill a Mockingbird 13- Coraline 14- The Queen of the Damned (Vampire Chronicles (Paperback)) 15- The Hours: A Novel我们根据类似的 user-item 交互,向 ID 号为 254 的用户推荐了 15 个商品(图书)。
- 第二种最常见的情景是,当你计划告知客户有关向上销售和交叉销售的选项时。具体的例子是:“购买此商品的顾客也同时购买……”、“浏览过此商品的顾客也浏览过……” 为完成这一任务,我不得不将用户和图书评级的阈值从 20 提高到 200,这样我就可以获得更小的评级数据帧。查找相似商品需要为数据集中的所有商品创建 item embedding,它可能会占用很多内存。我尝试过运行几次,但都遇到了 LowMemory 错误。因此如果你电脑有足够的内存,那么你可以试试它较低的阈值:
item_embedings = item_emdedding_distance_matrix(model,user_item_matrix) also_bought_recommendation(item_embedings,'B0000T6KHI' ,item_dikt)Item of interest :Three Fates (ISBN: B0000T6KHI) Items that are frequently bought together: 1- Surrender to Love (Avon Historical Romance) 2- Landower Legacy 3- Ranch Wife 4- Sara's SongAI 前线注:向上销售 是指根据既有客户过去的消费喜好,提供更高价值的产品或服务,刺激客户做更多的消费。如向客户销售某一特定产品或服务的升级品、附加品、或者其他用以加强其原有功能或者用途的产品或服务,向上销售也称为增量销售。这里的特定产品或者服务必须具有可延展性,追加的销售标的与原产品或者服务相关甚至相同,有补充、加强或者升级的作用。所谓 交叉销售,就是发现现有客户的多种需求,并通过满足其需求而实现销售多种相关的服务或产品的营销方式。促成交叉销售的各种策略和方法即 “交叉营销”。简单地理解是,说服现有的顾客去购买另一种产品,也是根据客人的多种需求,在满足其需求的基础上实现销售多种相关的服务或产品的营销方式。
- 推荐系统的第三个情景是,当你有一家网店,并决定通过向更有可能购买该商品的特定用户推荐来投放促销广告时,它可以帮助改善客户的体验,并增加销售量:
users_for_item(model, user_item_matrix, '0195153448', 10)[98391, 5499, 136735, 156214, 96473, 83443, 67775, 28666, 115929, 42323]我们推荐的 10 个用户(ID),他们更有可能对 ISBN 编号为 0195153448 的图书感兴趣。下一步可能就是向这些用户发送促销电邮,看看他们是否对提到的商品感兴趣。
结语
值得注意的是,一般来说,协同过滤方法需要足够的数据(user-item 交互)才能获得良好的结果。
本文提到的该项目的 GitHub repo 的链接如下:
https://github.com/nxs5899/Recommender-System-LightFM
参考资料:
https://github.com/aayushmnit/cookbook/blob/master/recsys.py
https://towardsdatascience.com/my-journey-to-building-book-recommendation-system-5ec959c41847
https://towardsdatascience.com/challenges-solutions-for-production-recommendation-systems-d656024bbdca
原文链接:
https://towardsdatascience.com/if-you-cant-measure-it-you-can-t-improve-it-5c059014faad
会议推荐:
12月20-21, AICon将于北京开幕,在这里可以学习来自Google、微软、BAT、360、京东、美团等40+AI落地案例,与国内外一线技术大咖面对面交流。
如何在Python中使用LightFM构建可扩展的电子商务推荐系统?相关推荐
- python 个性化推荐系统_如何在 Python 中使用 LightFM 构建可扩展的个性化推荐系统?...
在我国,电商非常发达.今年双 11 的成交额仅仅过了 12 小时就达到了惊人的 1491.6 亿元!电商在我国的火爆程度由此可见一斑.不知你们有没有发现,在网店浏览商品时,它们好像能读懂你的内心,推荐 ...
- python中knn_如何在python中从头开始构建knn
python中knn k最近邻居 (k-Nearest Neighbors) k-Nearest Neighbors (KNN) is a supervised machine learning al ...
- 如何在 Python 中构建跨平台桌面应用程序
如何在 Python 中构建跨平台桌面应用程序 开发桌面 GUI 应用程序曾经是一个乏味.容易出错且缓慢的过程. 当然,Python 在整体上极大地简化了应用程序开发,但在 GUI 领域,仍然没有真正 ...
- 如何在Python中反转列表?
如何在Python中执行以下操作? array = [0, 10, 20, 40] for (i = array.length() - 1; i >= 0; i--) 我需要一个数组的元素,但是 ...
- 【机器学习基础】如何在Python中处理不平衡数据
特征锦囊:如何在Python中处理不平衡数据 ???? Index 1.到底什么是不平衡数据 2.处理不平衡数据的理论方法 3.Python里有什么包可以处理不平衡样本 4.Python中具体如何处理 ...
- 如何在Python中建立和训练K最近邻和K-Means集群ML模型
One of machine learning's most popular applications is in solving classification problems. 机器学习最流行的应 ...
- linux中python如何调用matlab的数据_特征锦囊:如何在Python中处理不平衡数据
今日锦囊 特征锦囊:如何在Python中处理不平衡数据 ? Index 1.到底什么是不平衡数据 2.处理不平衡数据的理论方法 3.Python里有什么包可以处理不平衡样本 4.Python中具体如何 ...
- python 线性回归模型_如何在Python中建立和训练线性和逻辑回归ML模型
python 线性回归模型 Linear regression and logistic regression are two of the most popular machine learning ...
- 如何在Python中加速信号处理
如何在Python中加速信号处理 This post is the eighth installment of the series of articles on the RAPIDS ecosyst ...
最新文章
- deepin更新失败_检查更新失败
- KBMMW 4.6 正式版发布
- Pixhawk代码分析-启动代码及入口函数
- tf报错之raise TypeError(“pred must not be a Python bool“)
- Javascript基础--对象
- 文件流操作,报“because it is being used by another process. ”错误解决
- Python3安装turtle库(已成功安装)
- 国家地理相关资源数据库
- 校园网络构建方案设计
- CPU HQ 什么意思
- Java 枚举和泛型
- echarts的饼图制作分析
- 2013年图灵奖--莱斯利·兰波特简介
- RabbitMq中的warren模式和shovel模式
- 基于LSTM实现乐器声音音频识别
- java定义一个eat方法_小黄鸭系列java基础知识 | java中的方法
- ECMAScript 6 字符串和数值的拓展
- 一九产业AI速写:工业篇
- 用koomail有条不紊分类管理邮件
- 安装完Ubuntu16.04后要做的事