POI框架EXCEL解析性能优化
背景
在做商品EXCEL的时候,线上发现了Full GC,排查得知是商家搞了一个巨大的excel,单商品发布接口平均耗时400ms(调用sell耗时200ms左右,系统自身处理商品同步耗时150ms左右),对于3000个商品的发布,耗时在20min左右,这20min内该excel的内存一直未能释放。
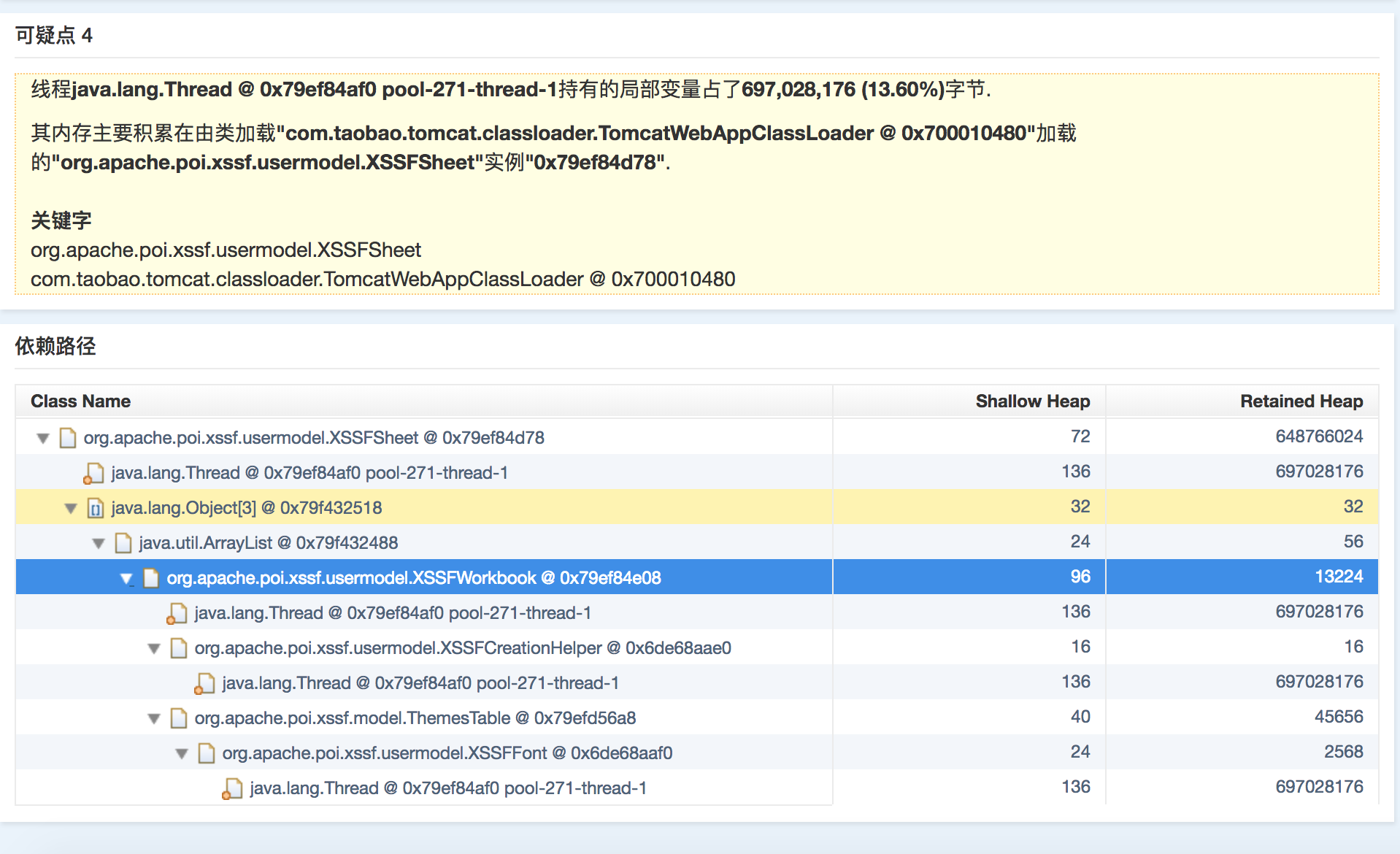
第一时间想到的是POI真坑,真吃内存。 事情发生了就想着怎么处理,
- 止血 线上机器分批重启,
- 马上加一个excel行数的限制然后发布 线上半个小时左右就没有任何问题了。
思考
为什么poi这么吃内存,poi这么老了,肯定有人踩过这个坑,撸起袖子,搜poi full gc. 很多文档将的都太粗糙了,本质没有说透
原因
- excel本质上是xml文件的集合体。从office 2007起开始使用xml来存档和数据交换:https://zh.wikipedia.org/wiki/Office_Open_XML
- poi默认是使用dom方式解析excel,因此文件中String的数量越多,其dom树越大。
解法
由于excel商品发布不需要动态的更改excel中的数据,所以并不强依赖dom解析,直接换成sax来解析excel就行
Action
poi中sax用法
/*** @author zhengqiang.zq* @date 2018/05/04 ,参考链接:https://poi.apache.org/spreadsheet/how-to.html#sxssf*/
public class MyEventUserModel {public static ThreadLocal<List<ParsedRow>> local = new ThreadLocal<>();public void processOneSheet(String filename) throws Exception {OPCPackage pkg = OPCPackage.open(filename);XSSFReader r = new XSSFReader(pkg);SharedStringsTable sst = r.getSharedStringsTable();XMLReader parser = fetchSheetParser(sst);//从workbook.xml.res 中获取所有需要解析的xml文件,rid1 就是第一个sheet,其target就是该sheet所在的相对路径//<?xml version="1.0" encoding="UTF-8" standalone="yes"?>//<Relationships xmlns="http://schemas.openxmlformats.org/package/2006/relationships">// <Relationship Id="rId3" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/theme" Target="theme/theme1.xml"/>// <Relationship Id="rId4" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/styles" Target="styles.xml"/>// <Relationship Id="rId5" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/sharedStrings" Target="sharedStrings.xml"/>// <Relationship Id="rId1" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/worksheet" Target="worksheets/sheet1.xml"/>// <Relationship Id="rId2" Type="http://schemas.openxmlformats.org/officeDocument/2006/relationships/worksheet" Target="worksheets/sheet2.xml"/>//</Relationships>//InputStream sheet2 = r.getSheet("rId1");InputSource sheetSource = new InputSource(sheet2);parser.parse(sheetSource);sheet2.close();}public XMLReader fetchSheetParser(SharedStringsTable sst) throws SAXException {XMLReader parser =XMLReaderFactory.createXMLReader("org.apache.xerces.parsers.SAXParser");ContentHandler handler = new SheetHandler(sst);parser.setContentHandler(handler);return parser;}/*** See org.xml.sax.helpers.DefaultHandler javadocs*/private class SheetHandler extends DefaultHandler {/*** excel 常量数据对象,对应的就是sharedStrings.xml文件中的内容,类似excel中的常量池*/private SharedStringsTable sst;/*** 当前处理的文本值*/private String lastContents;/*** 下一个文本是不是String类型*/private boolean nextIsString;/*** 当前单元格的索引值,从0开始,0:第一列*/private Short index;/*** 自定义数据类型,存储被解析的每一行原始数据*/List<ParsedRow> sheetData = Lists.newArrayList();ParsedRow currentRow = new ParsedRow();private SheetHandler(SharedStringsTable sst) {this.sst = sst;}@Overridepublic void startElement(String uri, String localName, String name, Attributes attributes) throws SAXException {//第一行if (name.equals("row")) {currentRow.setRowNum(new Long(attributes.getValue("r")));sheetData.add(currentRow);}//c => cell 一个单元格,if (name.equals("c")) {//r属性表示单元格位置,例如A2,C3String coordinate = attributes.getValue("r");CellReference cellReference = new CellReference(coordinate);//根据r属性获取其列下标,从0开始index = cellReference.getCol();//t:属性代表单元格类型String cellType = attributes.getValue("t");if (cellType != null && cellType.equals("s")) {//t="s"表示是改单元格是字符串,那么该单元格的实际值值需要去SharedStringsTable中取nextIsString = true;} else {nextIsString = false;}}// Clear contents cachelastContents = "";}@Overridepublic void endElement(String uri, String localName, String name) throws SAXException {if (nextIsString) {int idx = Integer.parseInt(lastContents);//从SharedStringsTable中取当前单元格的实际值lastContents = new XSSFRichTextString(sst.getEntryAt(idx)).toString();nextIsString = false;}// v => contents of a cell// Output after we've seen the string contentsif (name.equals("v")) {//不管是不是数字还是文本值currentRow.getData().put(index, lastContents);}if (name.equals("row")) {currentRow = new ParsedRow();}}@Overridepublic void endDocument() throws SAXException {local.set(sheetData);}/*** 通知一个元素中的字符,是否处理由自己决定,比如 <v>1</v>,** @param ch The characters. 整个sheet.xml的char[]数组表示* @param start The start position in the character array. 本次处理的元素值的的开始位置* @param length The number of characters to use from the ,元素长度* character array.* @throws SAXException Any SAX exception, possibly* wrapping another exception.* @see ContentHandler#characters*/@Overridepublic void characters(char[] ch, int start, int length) throws SAXException {//对于lastContents是String类型来说,lastContent存放的是其在SharedStringsTable中的索引,// 对于是数字类型来说,lastContents存放就是该数字的字符串表示lastContents += new String(ch, start, length);}}public static void main(String[] args) throws Exception {String fileName = "/Users/thinerzq/alltest/excel/test_big_3300_diffrent_row.xlsx";MyEventUserModel example = new MyEventUserModel();Stopwatch stopwatch = new Stopwatch();stopwatch.start();example.processOneSheet(fileName);System.out.println("-----------------finish, " + stopwatch.toString());System.out.println(local.get());Thread.sleep(100000 * 1000);}
}性能对比
dom 3455行
解析时间
-----------------finish, 6.987 s
内存消耗
jmap -histo:live 2646
thinerzq@thinerzq-2:~$ jmap -histo:live 2646num #instances #bytes class name
----------------------------------------------1: 2574454 247147584 org.apache.xmlbeans.impl.store.Xobj$AttrXobj2: 1332126 127884096 org.apache.xmlbeans.impl.store.Xobj$ElementXobj3: 1265264 50610560 java.util.TreeMap$Entry4: 778421 48667664 [C5: 636 37006672 [B6: 611910 29371680 java.util.TreeMap7: 611886 24475440 org.apache.xmlbeans.impl.values.XmlUnsignedIntImpl8: 653334 20906688 org.apache.poi.xssf.usermodel.XSSFCell9: 653334 20906688 org.openxmlformats.schemas.spreadsheetml.x2006.main.impl.STCellRefImpl10: 775269 18606456 java.lang.String11: 653334 15680016 org.openxmlformats.schemas.spreadsheetml.x2006.main.impl.CTCellImpl12: 611866 14684784 org.apache.poi.xssf.usermodel.XSSFRow13: 611866 14684784 org.openxmlformats.schemas.spreadsheetml.x2006.main.impl.CTRowImpl14: 622210 9955360 java.lang.Integer15: 55239 1767648 org.openxmlformats.schemas.spreadsheetml.x2006.main.impl.STXstringImpl16: 34552 1105664 org.openxmlformats.schemas.spreadsheetml.x2006.main.impl.STCellTypeImpl17: 18776 600832 java.util.HashMap$Node18: 10328 247872 org.openxmlformats.schemas.spreadsheetml.x2006.main.impl.CTRstImpl
….726: 1 16 sun.util.resources.LocaleData$LocaleDataResourceBundleControl
Total 11909576 686173768=81.8MBsax 3455行
解析时间
-----------------finish, 2.427 s
内存消耗
jmap -histo:live 2646
thinerzq@thinerzq-2:~$ jmap -histo:live 2711num #instances #bytes class name
----------------------------------------------1: 612060 29378880 java.util.HashMap2: 611866 14684784 com.zq.poi.ParsedRow3: 611866 14684784 java.lang.Long4: 1298 3342120 [Ljava.lang.Object;5: 60140 3149488 [C6: 51946 1662272 java.util.HashMap$Node7: 60096 1442304 java.lang.String8: 3610 578024 [Ljava.util.HashMap$Node;9: 617 288960 [B10: 1626 186544 java.lang.Class11: 975 173176 [I12: 2911 116440 java.util.LinkedHashMap$Entry13: 2648 63552 javax.xml.namespace.QName14: 1811 57952 java.util.concurrent.ConcurrentHashMap$Node15: 2242 53808 org.apache.xmlbeans.SchemaType$Ref16: 423 27072 java.net.URL17: 1619 25904 java.lang.Object18: 290 20496 [Ljava.lang.String;531: 1 16 sun.util.resources.LocaleData$LocaleDataResourceBundleControl
Total 2036715 70309432 =8.4MB总览
| 解析类型 | 数据量 | 解析时间 | 内存占用 |
|---|---|---|---|
| dom | 3455行不同数据 | 6.587 s | 81.8MB |
| sax | 3455行不同数据 | 2.427 s | 8.4MB |
| dom | 10000行数据,2/3重复 | 6.748s | 100.4M |
| sax | 10000行数据,2/3重复 | 2.827s | 9.4MB |
可以看到使用sax解析之后内存下降了近10倍之多,再也不用担心full gc了。由于其常量池的缘故,excel文件大小和行数是否有重复的单元格有关系。
其他
参考链接
- poi文档
查看excel的xml文件
将excel文件的后缀名改为.zip 然后解压缩里面就全部都是xml文件了。
xml文件快速一览
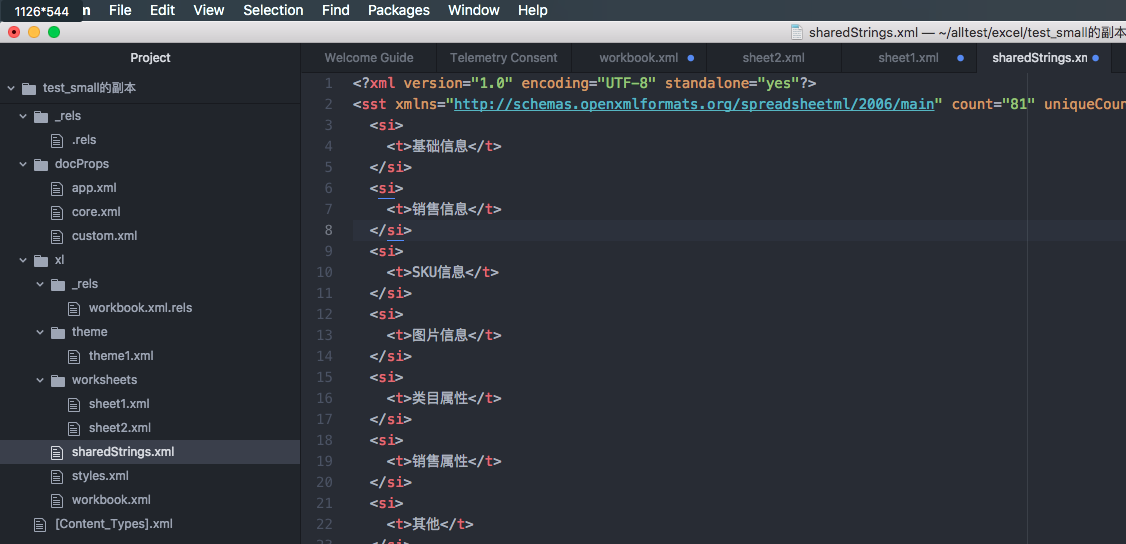
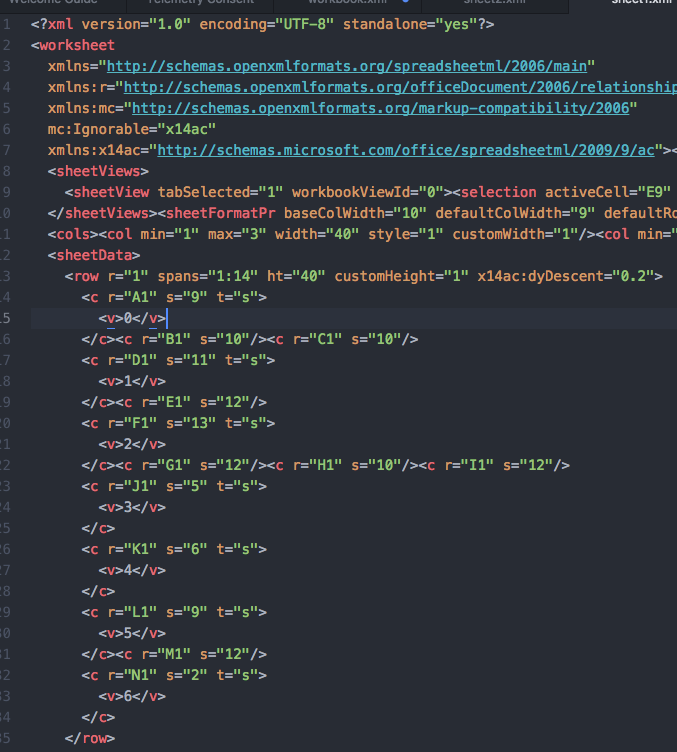
POI框架EXCEL解析性能优化相关推荐
- poi的excel解析工具类
2019独角兽企业重金招聘Python工程师标准>>> import org.apache.commons.lang.StringUtils; import org.apache.c ...
- 开源100天,OneFlow送上“百天大礼包”:深度学习框架如何进行性能优化?
11月8日是OneFlow开源100天的纪念日,为了这个有纪念性的日子,我们为大家准备了一个"百天大礼包"--深度学习框架性能优化系列文章,希望能和大家共同探讨开源框架如何进行优化 ...
- 前端框架/架构,性能优化,负载均衡,首屏渲染
前端数据结构与算法- https://zhuanlan.zhihu.com/p/27659059 > 前端重构方案 前端重构方案了解一下- https://blog.csdn.net/vM199 ...
- java 用 jxl poi 进行excel 解析 *** 最爱那水货
1 /** 2 * 解析excel文件 ,并把数据放入数组中 格式 xlsx xls 3 * @param path 从ftp上下载到本地的文件的路径 4 * @return 数据数组集合 5 */ ...
- Storm 性能优化
目录 场景假设 调优步骤和方法 Storm 的部分特性 Storm 并行度 Storm 消息机制 Storm UI 解析 性能优化 场景假设 在介绍 Storm 的性能调优方法之前,假设一个场景: 项 ...
- React Native性能优化总结
React Native开源已经接近2年时间,京东.携程.58同城等互联网公司都在使用,公司于今年也开始使用,并推广到各个新项目.本文重点分享我们遇到的一些问题以及优化方案. 一.为什么会引入Reac ...
- SpringBoot 性能优化
1.服务监控 在开始对SpringBoot服务进行性能优化之前,我们需要做一些准备,把SpringBoot服务的一些数据暴露出来. 比如,你的服务用到了缓存,就需要把缓存命中率这些数据进行收集:用到了 ...
- MegEngine推理性能优化
MegEngine推理性能优化 MegEngine「训练推理一体化」的独特范式,通过静态图优化保证模型精度与训练时一致,无缝导入推理侧,再借助工业验证的高效卷积优化技术,打造深度学习推理侧极致加速方案 ...
- 不得不说,其实你的性能优化手段已经过时了
10 月 21 日-23 日,QCon 上海站 2021 将很快与大家见面.已有 12 年历史的 QCon 早已沉淀了科学严谨的议题筛选机制和内容打磨流程,我们有十足的信心给你交付足够前沿.可探索.可 ...
- 工程之道,解读业界最佳的深度学习推理性能优化方案
本文转载自旷视研究院 MegEngine「训练推理一体化」的独特范式,通过静态图优化保证模型精度与训练时一致,无缝导入推理侧,再借助工业验证的高效卷积优化技术,打造深度学习推理侧极致加速方案,实现当前 ...
最新文章
- conda的导入导出
- Keras【Deep Learning With Python】Save reload 保存提取模型
- [POJ-3237] [Problem E]
- wxWidgets:wxMediaCtr类用法
- Gartner市场分析报告显示2010年全球安全软件市场增长12%
- sql2008 sql服务_SQL即服务
- Kubernetes operator 模式开发实践
- php callable 参数,php 利用反射执行callable
- laravel 错误与日志
- SSH实战项目——在线商品拍卖网
- Android doc |Getting Started|部分 部分译文 --Building Your First App
- 如何重命名图层名称_PS新手教程:教你认识“图层”面板及图层面板的相关操作方法...
- 快速凝血分析仪行业调研报告 - 市场现状分析与发展前景预测
- 3d打印机 form3_桌面SLA卖掉5万台后,Formlabs发布新机型Form3和Form 3L
- redis入门(转)
- TrueCrypt中文教程
- 初入行的C++程序员,如何快速摆脱CRUD阶段?
- 微信小程序卡券java_微信小程序领取卡券(java)
- ASPCMS调用分类名称及链接
- 5G标准核心内容:R15+R16(内含赠书福利)