Web Scraper爬虫
前置准备
chrome浏览器、Web Scraper-0.2.0.18
一、插件安装
打开chrome浏览器,地址栏内输入:chrome://extensions/,点击加载已解压的扩展程序,选择webscraper
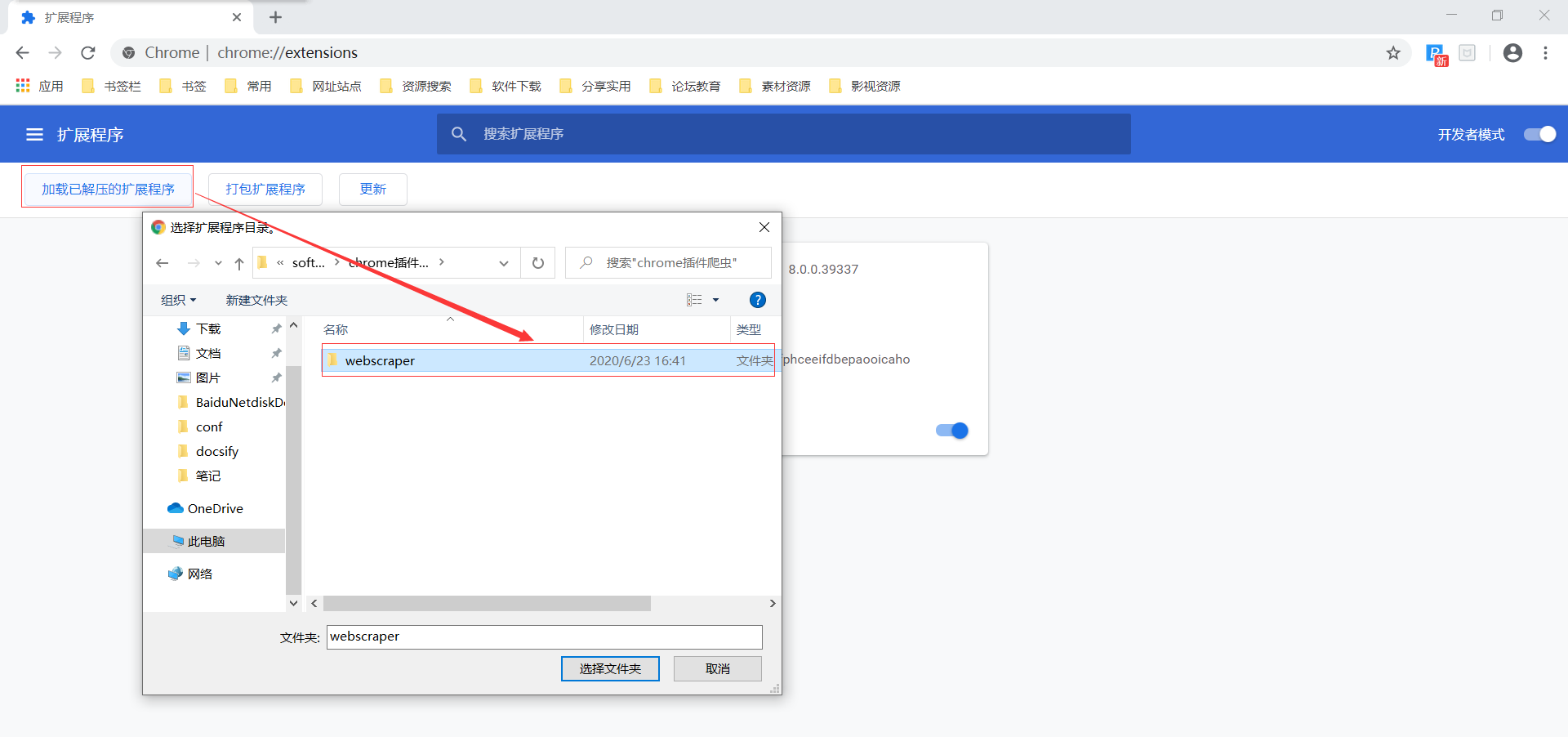
加载完成后,在页面鼠标右击选择检查(或F12),可以看到Web Scraper选项

插件以及视频中sitemap下载地址:https://wwa.lanzous.com/b02b87nda,密码:5rjv
二、数据爬取
2.1 选取目标网址
这里我以bilibili为例进行演示,我将会爬取python关键字相关的信息。网址:https://search.bilibili.com/all?keyword=python&from_source=nav_suggest_new
进入开发者模式的Web Scraper选项栏中,准备开始爬取数据。
2.2 新建一个Sitemap
点击Create new sitemap,里面有两个选项:Import sitemap是指导入一个已有的sitemap,Create sitemap表示我们要新建一个sitemap。 这里大家可以用我已经测试好的来看下效果,也可以自己动手创建一个新的(爬其它数据),我给大家从新建开始演示。

Sitemap name:给你要爬取的网页取个名字,需要使用英文字母,并且至少3个字符。比如我抓的是B站有关python的数据,那我就用bi-python-spider来命名。
Start URL:把需要爬取的网页链接复制到这里。
最后点击下方的Create Sitemap完成新建

2.3 设置这个Sitemap
点击 Add new selector 创建一级Selector
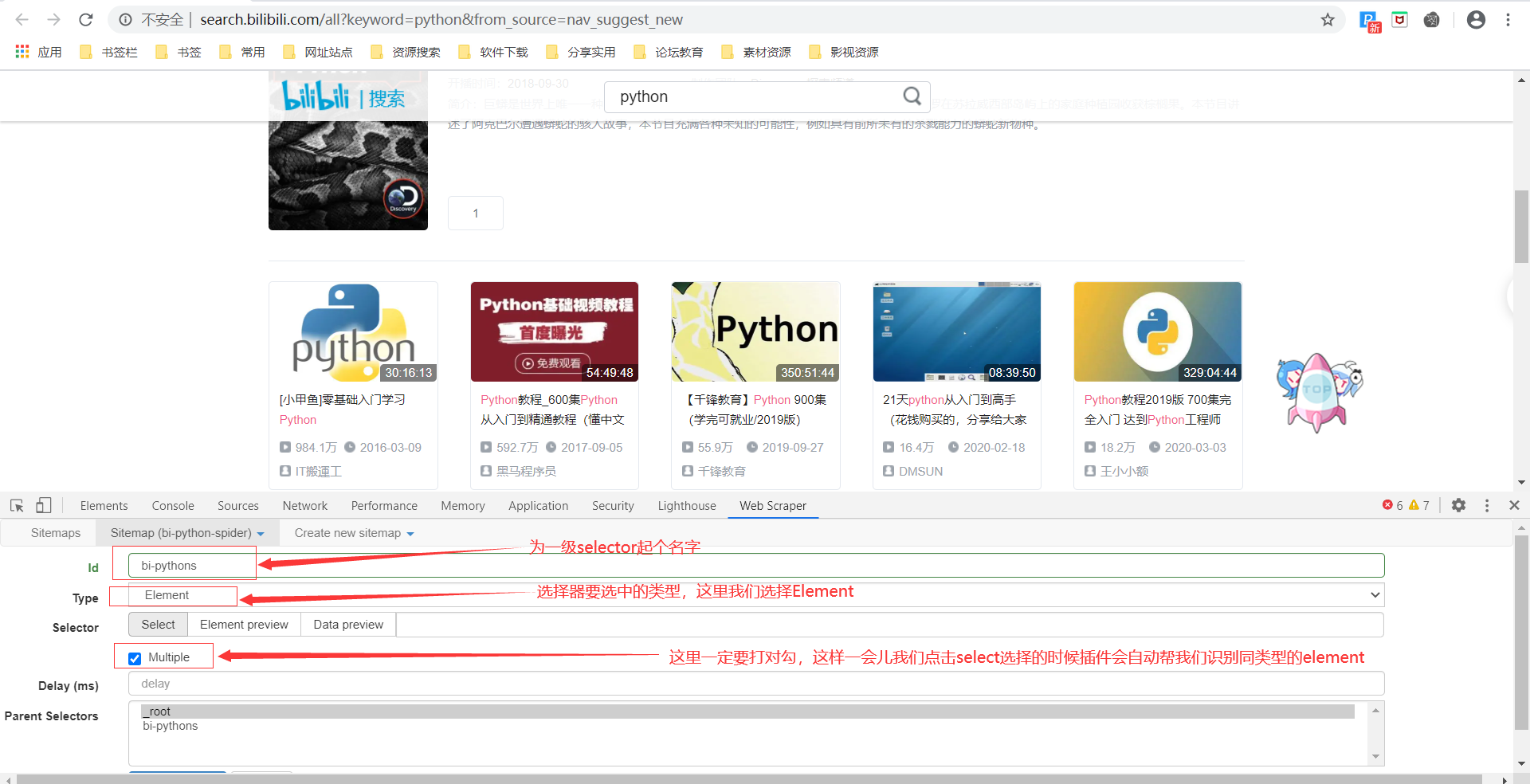

设置好这个一级的Selector之后,点进去设置二级的Selector
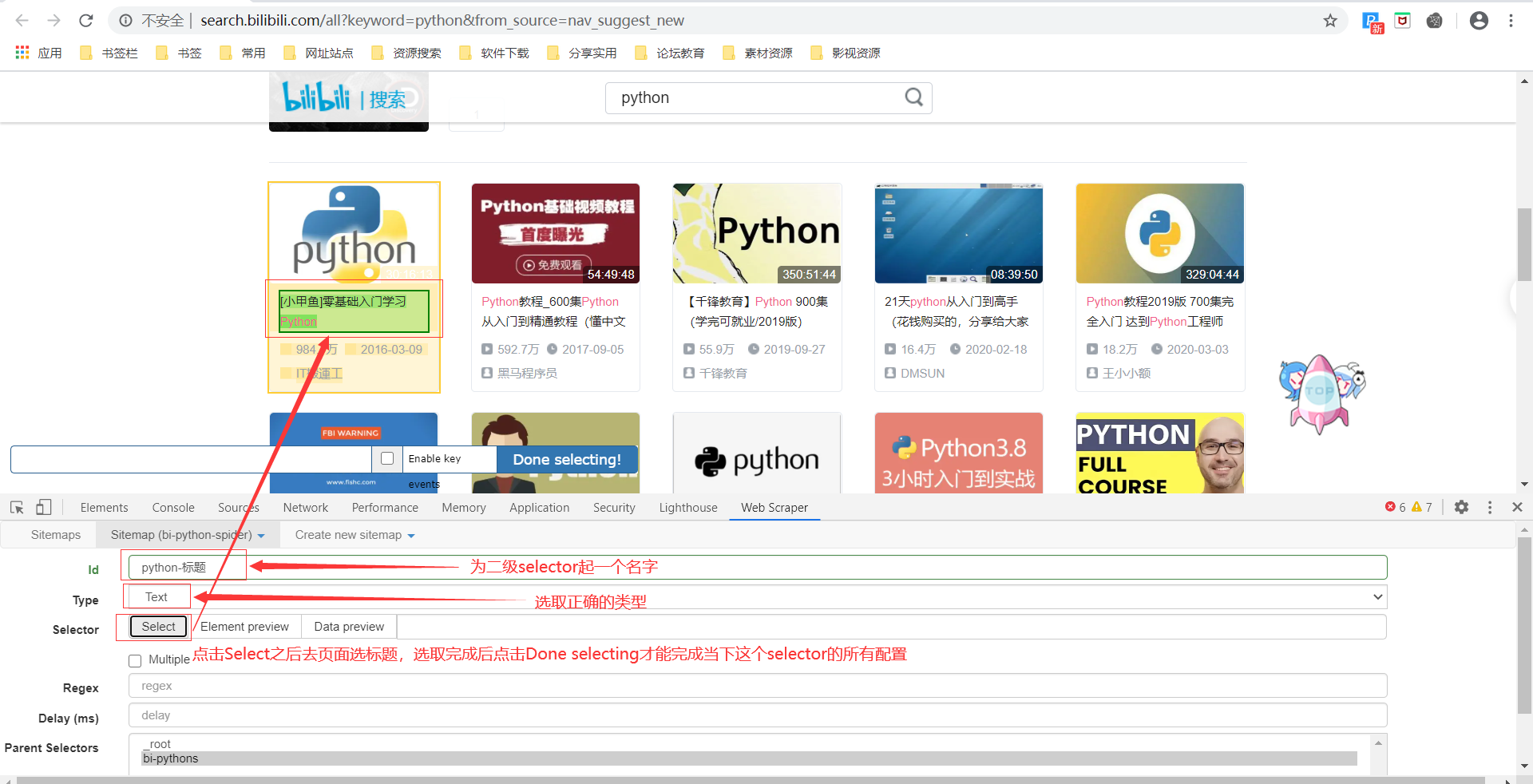
重复上面二级Selector的操作,直到选完你想爬的字段
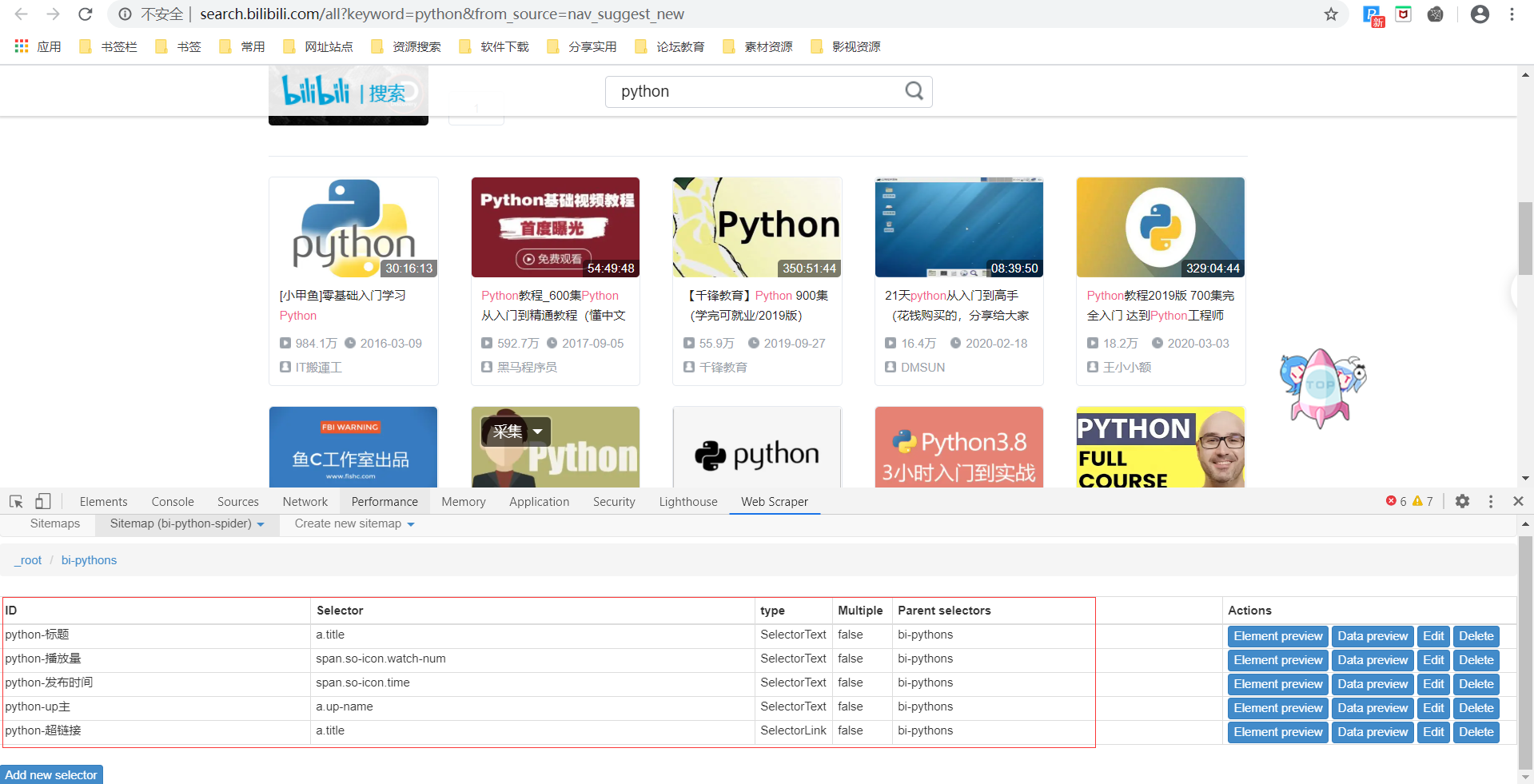
2.4 爬取数据
点击Scrape,设置好请求时间间隔和页面加载延迟(默认即可),然后点Start scraping,弹出一个小窗后爬虫就会开始工作。你会得到一个列表,上面有你想要的所有数据。
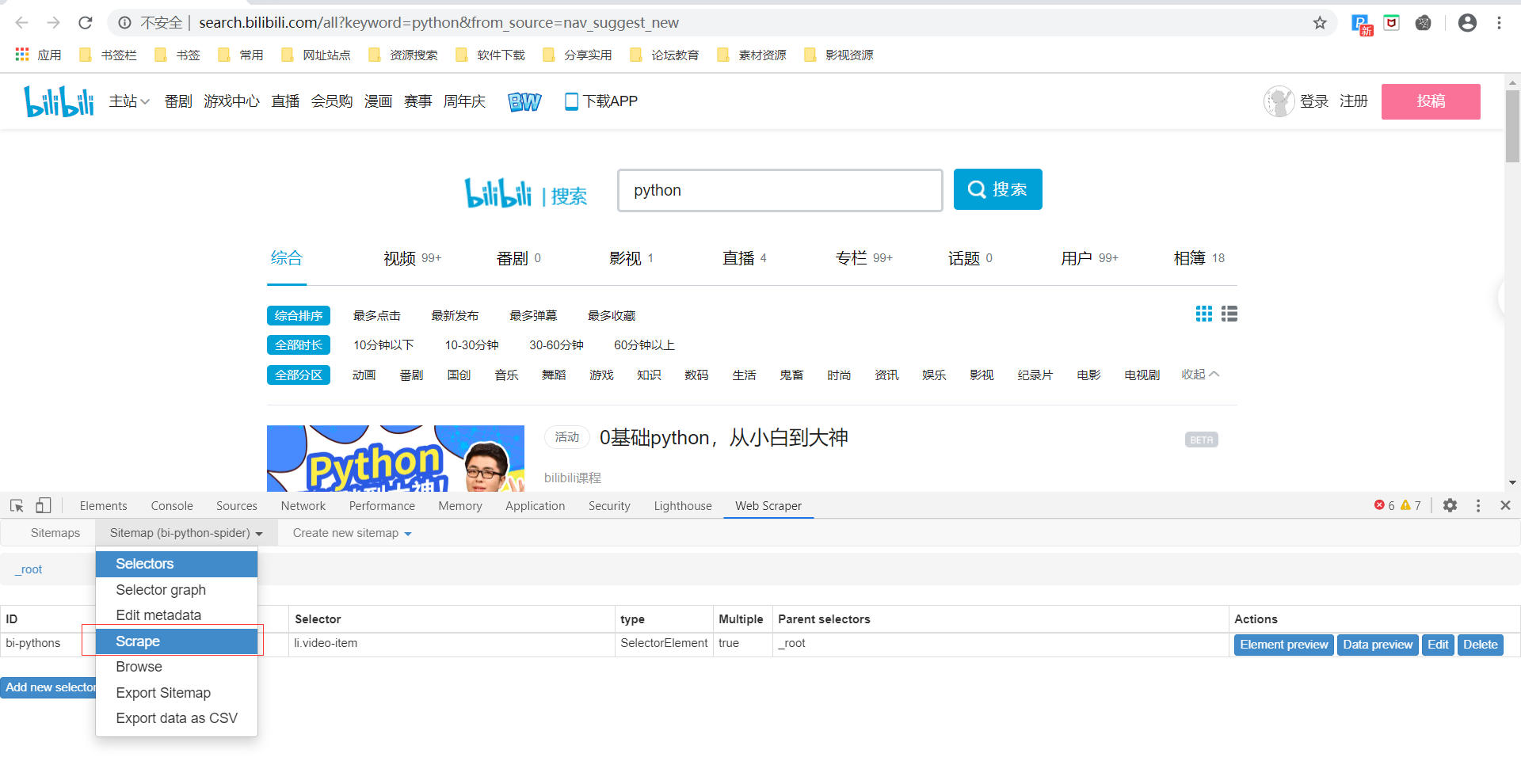

由于我们只是爬取了第一页的数据,所以很快我们就可以看到结果

2.5 数据导出
这里我们可以将爬取的数据以CSV格式导出,同样也可以将Sitemap导出供他人使用。

三、其它
有些时候我们需要爬取的数据往往会有分页,比如我们上面有关python的检索结果https://search.bilibili.com/all?keyword=python&from_source=nav_suggest_new&page=2,这里第二页是通过路径一个page参数来进行传递。在Web Scraper 中提供了一种写法,可以设置页码范围及递增步长。格式: [开始值-结束值:步长],举几个例子来说明一下:
1、获取2-6页,步长为1的页面 :[2-6] 或者 [2-6:1]
2、获取2-6页,步长为2的页面:[2-6:2]
这里小编只是简单介绍总结了Web Scraper的插件的安装以及一个简单的单页面例子。其实Web Scraper的功能远远不止于此,它还能抓取分页、多页多元素的页面,还能抓取二级页面。需要大家自己慢慢摸索~~~
Web Scraper爬虫相关推荐
- Web scraper 爬虫傻瓜教程(不断更新中)
教程 安装 基本操作 打开Web scraper 使用Web scraper 创建爬取 运行爬虫,查看数据 这里讲一个复杂一点的例子帮助大家学习 参考: 安装 Web scraper只支持chrome ...
- web scraper爬虫工具(简介)
web scraper 简介 一.什么是web scraper web scraper是一款网站数据提取工具,类似于爬虫,但不需要像python爬虫那样编写代码,使用门槛较低,适用于轻度的数据爬取.w ...
- Chrome 爬虫插件 Web Scraper
Web Scraper 官网:https://webscraper.io/ 有关webscraper的问题,看这个就够了(建议收藏): https://zhuanlan.zhihu.com/p/341 ...
- 零代码爬虫神器 — Web Scraper 的使用
经常会遇到一些简单的需求,需要爬取某网站上的一些数据,但这些页面的结构非常的简单,并且数据量比较小,自己写代码固然可以实现,但杀鸡焉用牛刀? 目前市面上已经有一些比较成熟的零代码爬虫工具,比如说八爪鱼 ...
- 零代码爬虫神器 -- Web Scraper 的使用
点击上方"Python爬虫与数据挖掘",进行关注 回复"书籍"即可获赠Python从入门到进阶共10本电子书 今 日 鸡 汤 八骏日行三万里,穆王何事不重来. ...
- webscraper多页爬取_爬虫工具实战篇(Web Scraper)- 京东商品信息爬取(原创)
一.背景与目的 数字化营销时代,快速掌握了解数据是一项基本技能,本文主要讲解里面Web Scraper工具如何爬取公开数据,比如爬取京东的店铺售卖商品情况数据,以便我们更好地了解竞品对手的产品情况和定 ...
- 使用Web Scraper插件实现简单爬虫
1.添加扩展程序 Microsoft Edge添加扩展程序Web Scraper(蜘蛛网图标) 2.进入开发者模式 在所需爬取网页界面下,打开Web Scraper:Windows系统下使用 Ctrl ...
- 零代码爬虫神器 -- Web Scraper 的使用!
我是小z 经常会遇到一些简单的需求,需要爬取某网站上的一些数据,但这些页面的结构非常的简单,并且数据量比较小,自己写代码固然可以实现,但杀鸡焉用牛刀? 目前市面上已经有一些比较成熟的零代码爬虫工具,比 ...
- Web Scraper 小白爬虫笔记:单元素多页数据抓取
Web Scraper 是谷歌 Chrome 浏览器插件,人称爬虫神器,功能不要太强大,非常适合不想敲代码,又对数据有需求的我们,文末附有下载地址奥☟☟ 装好插件之后,我们就开始上手啦 以豆瓣电影 T ...
最新文章
- Linux之vim中翻页的命令
- python3之subprocess常见方法使用
- 6、HTML有序列表+无序列表+定义列表
- Python输出黄金分隔数列前n项。 黄金分隔数列由Fibonacci数列相邻两项之比组成:1/1,1/2,2/3,3/5,5/8,...其取值逐渐接近黄金分隔数。
- SQL server 2012 如何取上个月的最后一天
- 微信小游戏“跳一跳”,Python“外挂”已上线
- Java程序员都要懂得知识点:反射
- linux之mktemp命令
- MacOS开发-给自己的 app 添加 URL Scheme(Xcode 9之后)
- matlab imcrop 用法
- C#操作Word(二)——将Word文档嵌入到WinForm窗体中
- ThinkPHP整合微信支付之发裂变红包
- [转贴][教学] 教你如何打飞机 ^_^
- 【Android】在有menu键的手机上显示ActionBar上的Menu键
- oceanbase安装
- python日历图_Python干货宝典!玩转内置模块:日历模块
- 软件扫描出rsh漏洞,但是并无安装rsh服务,原因是为何?
- 心率检测--异常可能
- 双非本硕,成功上岸大数据开发 !!!
- 2021年西式面点师(高级)免费试题及西式面点师(高级)模拟考试题库