KNN模型算法研究与案例分析
导读:机器学习算法中KNN属于比较简单的典型算法,既可以做聚类又可以做分类使用。本文通过一个模拟的实际案例进行讲解。整个流程包括:采集数据、数据格式化处理、数据分析、数据归一化处理、构造算法模型、评估算法模型和算法模型的应用。(本文原创,转载必须注明出处: KNN模型算法研究与案例分析)
1 理论介绍
什么是KNN?
k-近邻(kNN,k-NearestNeighbor)算法是一种基本分类与回归方法,我们这里只讨论分类问题中的 k-近邻算法。k-近邻算法的输入为实例的特征向量,对应于特征空间的点;输出为实例的类别,可以取多类。k-邻算法假设给定一个训练数据集,其中的实例类别已定。分类时,对新的实例,根据其 k 个最近邻的训练实例的类别,通过多数表决等方式进行预测。因此,k近邻算法不具有显式的学习过程即属于有监督学习范畴。k近邻算法实际上利用训练数据集对特征向量空间进行划分,并作为其分类的“模型”。k值的选择、距离度量以及分类决策规则是k近邻算法的三个基本要素。
KNN算法思想
1 计算已知类别中数据集的点与当前点的距离。[即计算所有样本点跟待分类样本之间的距离]
2 按照距离递增次序排序。[计算完样本距离进行排序]
3 选取与当前点距离最小的k个点。[选取距离样本最近的k个点]
4 确定前k个点所在类别的出现频率。[针对这k个点,统计下各个类别分别有多少个]
5 返回前k个点出现频率最高的类别作为当前点的预测分类。[k个点中某个类别最多,就将样本划归改点]
KNN工作原理
1 假设有一个带有标签的样本数据集(训练样本集),其中包含每条数据与所属分类的对应关系。
2 输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较。
3 计算新数据与样本数据集中每条数据的距离。
4 对求得的所有距离进行排序(从小到大,越小表示越相似)。
5 取前 k (k 一般小于等于 20 )个样本数据对应的分类标签。
6 求 k 个数据中出现次数最多的分类标签作为新数据的分类。
KNN算法流程
1 搜集数据:数据采集过程,其分为非结构化数据,半结构化数据和数据化数据。诸如:网络爬取,数据库,文件等。
2 准备数据:格式化处理,对不同类别的数据进行统一的格式化处理。诸如:将pdf,word,excel,sql等等统一转化为txt文本。
3 分析数据:主要看看数据特点,有没有缺失值,数据连续性还是离散型,进而选择不同模型。诸如:可视化数据分析
4 训练数据:不适用于KNN,但是在其他一些监督学习中会经常遇到,诸如:朴素贝叶斯分类等。
5 测试算法:评价指标,如计算错误率,准确率,召回率,F度量值等。
6 应用算法:针对完善的模型进行封装重构,然后进行实际应用。
KNN优缺点
优点:精度高、对异常值不敏感、无数据输入假定
缺点:计算复杂度高、空间复杂度好
适用数据范围:数值型和标称型
2 KNN算法实现与分析
2.1 数据准备
创建模拟数据集
描述:现在你来了一个新的任务,任务其实非常简单,就是根据吃冰淇淋和喝水的数量判断成都天气冷热程度。你现在要做的就是去成都春熙路街头采访记录一些游客吃了多少冰淇淋,又喝了几瓶水,他觉得成都天气怎么样(这里只考虑二分类问题,假设只有‘非常热’和‘一般热’)。其中特征向量包括两个分别是冰激凌数t1和喝水数t2,标签类别分别是非常热A和一般热B。
现在我们开始行动,随机采访4个游客(暂时不考虑样本数量问题),询问每个游客吃多少冰淇淋和喝多少水(两个整型的特征向量,不考虑特征重要程度),并记录下他们口中的成都天气感受(非常热A与一般热B)。然后通过采访数据训练一个KNN分类器,新的游客只需要说出特征向量自动判别成都天气冷热程度。创建模拟数据集代码如下:
'''KNN创建数据源,返回数据集和标签'''
def create_dataset():group = array(random.randint(0,10,size=(4,2))) # 数据集labels = ['A','A','B','B'] # 标签return group,labels
运行查看数据集的特征向量和分类标签:
'''1 KNN模拟数据分类算法'''
dataset,labels = create_dataset()
print('特征集:\n'+str(dataset))
print('标签集:\n'+str(labels))
运行结果:
特征集:
[[8 4][7 1][1 4][3 0]]
标签集:
['A', 'A', 'B', 'B']
分析解读:
本段代码没有实际意义,只是帮助读者理解特征向量和分类标签。可以这么理解,A代表非常热,B代表一般热,属性1代表吃冰淇淋数量,属性2代表喝水的数量。那么样本数据可以解读为:
游客 冰淇淋 喝水 冷热程度 判断描述小王 8 4 A 小王吃了8个冰淇淋喝了4瓶水,成都天气非常热小张 7 1 A 小张吃了7个冰淇淋喝了1瓶水,成都天气非常热小李 1 4 B 小王吃了1个冰淇淋喝了4瓶水,成都天气一般热小赵 3 0 B 小王吃了3个冰淇淋喝了0瓶水,成都天气一般热
思考:
计算机是不能直接处理自然语言,往往需要将自然语言转化成特征向量,再通过计算机处理。比如这里不是吃喝看天气情况了,而是垃圾邮件自动识别,我们就需要对邮件转化成数值型特征向量再输入计算机进行处理。
规范文件数据集处理
如下是一个规范文件的数据集(已经经过数采集、数据格式化、数据预处理等),特征向量包括3个,样本属于一个多分类的情况。即我们通过周飞行里程数、玩游戏占比、吃冰激凌数量判断一个人的优秀程度。假设1代表普通,2代表比较优秀,3代表非常优秀。(ps:一个人一周都在飞机上度过忙碌的工作,又不太玩游戏,关键还注意饮食,说明优秀是有道理的。)
周飞行里程数(km) 周玩游戏占比(%) 周消耗冰激凌(公升) 样本分类
40920 8.326976 0.953952 3
14488 7.153469 1.673904 2
26052 1.441871 0.805124 1
... ... ... ...
75136 13.147394 0.428964 1
38344 1.669788 0.134296 1
72993 10.141740 1.032955 1
上面是处理好保存在txt文本的数据,计算机如何去识别并处理这些数据呢?这里我们分别提取特征向量和标签向量。数据集处理代码如下:
'''对文件进行格式处理,便于分类器可以理解'''
def file_matrix(filename):f = open(filename)arrayLines = f.readlines()returnMat = zeros((len(arrayLines),3)) # 数据集classLabelVactor = [] # 标签集index = 0for line in arrayLines:listFromLine = line.strip().split(' ') # 分析数据,空格处理returnMat[index,:] = listFromLine[0:3]classLabelVactor.append(int(listFromLine[-1]))index +=1return returnMat,classLabelVactor
代码说明:
1 zeros(Y,X):填充矩阵,需要导入NumPy包。Y向量代表样本行数,X向量代表样本特征数即列数。
2 returnMat[index,:]:遍历样本特征向量
运行查看数据集的特征向量和分类标签:
''' KNN针对文件的分类算法'''
filename = os.path.abspath(r'./datasource/datingTestSet2.txt')
dataset,labels = file_matrix(filename)
print('特征集:\n'+str(dataset))
print('标签集:\n'+str(labels))
运行结果:
特征集:
[[4.0920000e+04 8.3269760e+00 9.5395200e-01][1.4488000e+04 7.1534690e+00 1.6739040e+00][2.6052000e+04 1.4418710e+00 8.0512400e-01]...[2.6575000e+04 1.0650102e+01 8.6662700e-01][4.8111000e+04 9.1345280e+00 7.2804500e-01][4.3757000e+04 7.8826010e+00 1.3324460e+00]]
标签集:
[3, 2, 1, 1, 1, 1, 3, 3, 1, 3, 1, 1, 2, 1, 1, 1, 1, 1, 2, 3, 2, 1, 2, 3, 2, 3, 2, 3, 2, 1, 3, 1, 3, 1, 2, 1, 1, 2, 3, 3, 1, 2, 3, 3, 3, ... 3, 3, 1, 2, 3, 1, 3, 1, 2, 2, 1, 1, 1, 1, 1]
不规范数据集处理
这里我们只是提供一个思路。比如做文本分类算法,如何将一篇篇新闻转化为规范的数值型数据集呢。假设Z政治新闻100篇,T体育新闻100篇,Y娱乐新闻100篇,K科技新闻100篇。我们进行分类:
1 遍历所有文本转化统一的txt格式文件(2.2节会讲到)
2 对全部ZTYK文本进行分词和停用词处理。
3 统计全部样本词频尺寸(可以采用TF-IDF或者深度学习方法处理)。
4 每个样本进行词频统计
最终模拟效果如下:
样本 词1 词2 词3 词4 ... 词n 标签
p1 200 0 100 50 ... 20 Z
p2 100 0 80 40 ... 10 Z
p3 0 100 5 5 ... 200 T
p4 6 230 40 12 ... 670 T
p5 0 2 110 57 ... 234 Y
... ... ... ... ... ... ... ...
pn 123 45 0 580 ... 24 K
2.2 数据格式化
数据文件转化
自然语言处理、数据挖掘、机器学习技术应用愈加广泛。针对大数据的预处理工作是一项庞杂、棘手的工作。首先数据采集和存储,尤其高质量数据采集往往不是那么简单。采集后的信息文件格式不一,诸如pdf,doc,docx,Excel,ppt等多种形式。然而最常见便是txt、pdf和word类型的文档。这里所谓格式转化主要对pdf和word文档进行文本格式转换成txt。格式一致化以后再进行后续预处理工作。具体详情请参照之前写的数据分析:基于Python的自定义文件格式转换系统一文。
文件格式化处理
这里可以采用多种方式,诸如上文提到的矩阵填充法,当然也可以采用现成的工具。比如百度的Echarts中表格数据转换工具。其支持纯数组的转换,数组+对象,地理坐标等方式,还支持json数据的转化,这对使用百度EChart可视化是非常友好的,也有助于可视化数据分析。文本数据格式效果如下图:
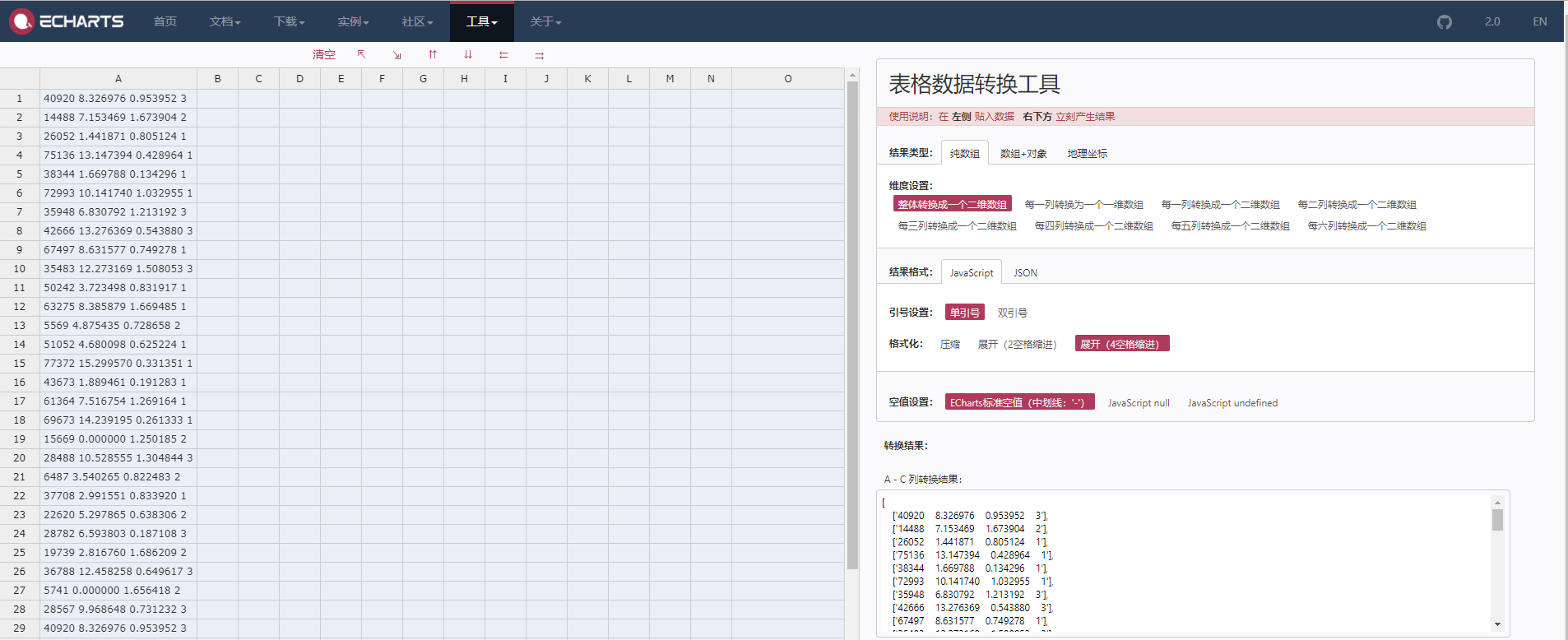
图2-1 文本数据表格转化
[['40920 8.326976 0.953952 3'],['14488 7.153469 1.673904 2'],['26052 1.441871 0.805124 1'],['75136 13.147394 0.428964 1'],['38344 1.669788 0.134296 1'],['72993 10.141740 1.032955 1'],...['35948 6.830792 1.213192 3'],['42666 13.276369 0.543880 3'],['67497 8.631577 0.749278 1'],['35483 12.273169 1.508053 3'],['50242 3.723498 0.831917 1'],['63275 8.385879 1.669485 1'],['5569 4.875435 0.728658 2'],['15669 0.000000 1.250185 2'],['28488 10.528555 1.304844 3'],['6487 3.540265 0.822483 2'],['37708 2.991551 0.833920 1']
]
2.3 数据归一化
数据归一化
机器学习、数据挖掘、自然语言处理等数据科学工作中,数据前期准备、数据预处理过程、特征提取等几个步骤比较花费时间。同时,数据预处理的效果也直接影响了后续模型能否有效的工作。然而,目前的很多研究主要集中在模型的构建、优化等方面,对数据预处理的理论研究甚少,很多数据预处理工作仍然是靠工程师的经验进行的。也不是所有数据都需要归一化,诸如
1. 数据类型一致且分布均匀。
2. 概率模型可以不做归一化,如决策树。
数据归一化优点
1. 归一化后加快了梯度下降求最优解的速度;
2. 归一化有可能提高精度;
归一化方法
1 sklearn线性归一化
# 线性函数将原始数据线性化的方法转换到[0, 1]的范围
min_max_scaler = preprocessing.MinMaxScaler()
X_train_minmax = min_max_scaler.fit_transform(X_train)
X_test_minmax = min_max_scaler.transform(X_test)
2 标准差标准化
# 经过处理的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为:
scaler = preprocessing.StandardScaler().fit(X_train)
scaler.transform(X_test)
3 非线性归一化
经常用在数据分化比较大的场景,有些数值很大,有些很小。通过一些数学函数,将原始值进行映射。该方法包括 log、指数,正切等。需要根据数据分布的情况,决定非线性函数的曲线,比如log(V, 2)还是log(V, 10)等。
线性归一化方法代码实现
'''数值归一化:特征值转化为0-1之间:newValue = (oldValue-min)/(max-min)'''
def norm_dataset(dataset):minVals = dataset.min(0) # 参数0是取得列表中的最小值,而不是行中最小值maxVals = dataset.max(0)ranges = maxVals - minValsnormdataset = zeros(shape(dataset)) # 生成原矩阵一样大小的0矩阵m = dataset.shape[0]# tile:复制同样大小的矩阵molecular = dataset - tile(minVals,(m,1)) # 分子: (oldValue-min)Denominator = tile(ranges,(m,1)) # 分母:(max-min)normdataset = molecular/Denominator # 归一化结果。return normdataset,ranges,minVals
数据归一化前:
归一化的数据结果:
[[4.0920000e+04 8.3269760e+00 9.5395200e-01][1.4488000e+04 7.1534690e+00 1.6739040e+00][2.6052000e+04 1.4418710e+00 8.0512400e-01]...[2.6575000e+04 1.0650102e+01 8.6662700e-01][4.8111000e+04 9.1345280e+00 7.2804500e-01][4.3757000e+04 7.8826010e+00 1.3324460e+00]]
展开第一条信息“40920 8.326976 0.953952 3”,其中里程40000多,而公升数才0.9.两者根本不在同一个数量级上面,也就是说,如果特征属性相同的情况下,公升数即使变动100倍对里程数的影响也微乎其微。而里程数轻微变化就直接影响公升数的结果。所以我们将其放在同一尺度下进行处理,也就是本文采用的线性缩放方,数据归一化后结果如下:
归一化的数据结果:
[[0.44832535 0.39805139 0.56233353][0.15873259 0.34195467 0.98724416][0.28542943 0.06892523 0.47449629]...[0.29115949 0.50910294 0.51079493][0.52711097 0.43665451 0.4290048 ][0.47940793 0.3768091 0.78571804]]
分析:
经过上述归一化处理后,各个特征指标都是0-1这样一个范畴中进行比较。当然实际工作中不同特征的权重不同,这个可以通过增加权重方法处理即可,本文不在进行深入讨论。
2.4 数据分析
基于matplotlib的可视化分析
我们对数据处理后,很不容易进行数据分析。毕竟密密麻麻的数字略显冰冷无趣。我们可以将其可视化展示出来,进而查看数据稀疏程度,离散程度等等。我们查看'玩游戏所耗时间百分比','每周消耗在冰淇淋的公升数'两个属性的散点图,实现代码如下:
'''
散列表分析数据:
dataset:数据集
datingLabels:标签集
Title:列表,标题、横坐标标题、纵坐标标题。
'''
def analyze_data_plot(dataset,datingLabels,Title):fig = plt.figure()# 将画布划分为1行1列1块ax = fig.add_subplot(111)ax.scatter(dataset[:,1],dataset[:,2],15.0*array(datingLabels),15.0*array(datingLabels))# 设置散点图标题和横纵坐标标题plt.title(Title[0],fontsize=25,fontname='宋体',fontproperties=myfont)plt.xlabel(Title[1],fontsize=15,fontname='宋体',fontproperties=myfont)plt.ylabel(Title[2],fontsize=15,fontname='宋体',fontproperties=myfont)# 设置刻度标记大小,axis='both'参数影响横纵坐标,labelsize刻度大小plt.tick_params(axis='both',which='major',labelsize=10)# 设置每个坐标轴取值范围# plt.axis([-1,25,-1,2.0])# 截图保存图片# plt.savefig('datasets_plot.png',bbox_inches='tight')# 显示图形plt.show()
这里注意一个问题,横纵坐标是乱码显示,解决这个问题,添加如下代码:
#加入中文显示
import matplotlib.font_manager as fm
# 解决中文乱码,本案例使用宋体字
myfont=fm.FontProperties(fname=r"C:\\Windows\\Fonts\\simsun.ttc")
调用可视化数据分析方法如下:
''' 文件数据图形化分析数据 '''
dataset,labels = file_matrix(filename)
noredataset = norm_dataset(dataset)[0] # 数据归一化
title = ['约会数据游戏和饮食散列点','玩游戏所耗时间百分比','每周消耗在冰淇淋的公升数']
visualplot.analyze_data_plot(noredataset,labels,title)
游戏占比与冰淇淋公升数关系散点图可视化:

图2-2 游戏占比与冰淇淋公升数关系散点图
折线图代码实现如下:
'''折线图'''
def line_chart(xvalues,yvalues):# 绘制折线图,c颜色设置,alpha透明度plt.plot(xvalues,yvalues,linewidth=0.5,alpha=0.5,c='red') # num_squares数据值,linewidth设置线条粗细# 设置折线图标题和横纵坐标标题plt.title("Python绘制折线图",fontsize=30,fontname='宋体',fontproperties=myfont)plt.xlabel('横坐标',fontsize=20,fontname='宋体',fontproperties=myfont)plt.ylabel('纵坐标',fontsize=20,fontname='宋体',fontproperties=myfont)# 设置刻度标记大小,axis='both'参数影响横纵坐标,labelsize刻度大小plt.tick_params(axis='both',labelsize=14)# 显示图形plt.show()
游戏占比与冰淇淋公升数关系折线图可视化:(此处折线图明显不合适,只是突出另一种分析方式。)

图2-3 游戏占比与冰淇淋公升数关系折线图
扩展:
更多matplotlib可视化实现效果图参考文章 70个注意的Python小Notes:完整的matplotlib可视化
基于Echart的可视化分析
我们上面采用的matplotlib可视化效果,采用该方式主要是结合python数据分析绑定比较方便。有些时候我们为了取得更加漂亮的可视化效果,可以选择百度echart进行分析,百度Echart使用简单且文档规范容易上手。我们对原数据进行分析并转化为json代码:
'''array数据转化json'''
def norm_Json(dataset):noredataset = norm_dataset(dataset)[0] # 数据归一化number1 = np.around(noredataset[:,1], decimals=4) # 获取数据集第二列number2 = np.around(noredataset[:,2], decimals=4) # 获取数据集第三列returnMat=zeros((dataset.shape[0],2)) # 二维矩阵returnMat[:,0] = number1returnMat[:,1] = number2file_path = os.path.abspath(r"./datasource/test.json")json.dump(returnMat.tolist(), codecs.open(file_path, 'w', encoding='utf-8'), separators=(',', ':'), sort_keys=True, indent=4)
生成json数据保存在指定文件中,打开文件查看数据如下:
[[0.3981,0.5623],[0.342,0.9872],[0.0689,0.4745],[0.6285,0.2525]...[0.4367,0.429],[0.3768,0.7857]
]
从百度Echart实例中选择一种散点图并绑定json文件,其html代码如下:
<!DOCTYPE html>
<html>
<head><meta charset="UTF-8"><title>图案例</title><script src="https://cdn.bootcss.com/jquery/2.2.0/jquery.min.js"></script><script type="text/javascript" src="./js/echarts.js"></script>
</head>
<body><div id="chartmain" style="width:800px; height: 400px; margin:auto; "></div><script type="text/javascript">//初始化echarts实例var myChart = echarts.init(document.getElementById('chartmain'));$.getJSON('game-food.json', function (data) {var option = {title: {text: '玩游戏时间占比和饮食数据描述',left: 'center',top: 0},visualMap: {min: 15202,max: 159980,dimension: 1,orient: 'vertical',right: 10,top: 'center',text: ['优秀', '一般'],calculable: true,inRange: {color: ['#f2c31a', '#24b7f2']}},tooltip: {trigger: 'item',axisPointer: {type: 'cross'}},xAxis: [{type: 'value'}],yAxis: [{type: 'value'}],series: [{name: 'price-area',type: 'scatter',symbolSize: 5,data: data}]};myChart.setOption(option);
});</script>
</body>
</html>
json文件读取需要在web运行环境中,单纯的运行效果如下图所示:
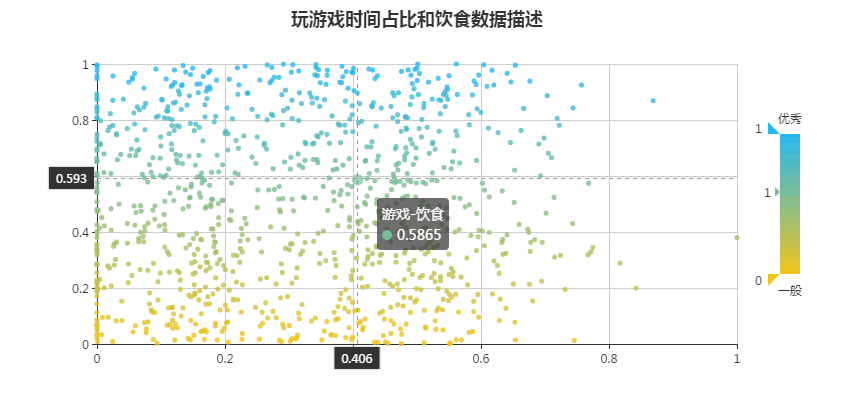
图2-4 游戏占比与冰淇淋公升数Echarts关系散点图
数据转化工具
本文采用自己构建的方式进行json文件生成,此外我们也可以采用现有的数据转化工具进行处理。比如百度的表格数据转化工具(2.2节已经介绍了)。
另一个便是在线json验证格式工具:http://www.bejson.com/
2.5 KNN分类器实现
通过数据分析,我们查看数据样本是否偏态分别,数据规模情况等等。针对性进行数据预处理后,编写具体算法模型。本文主要是KNN分类器,其代码如下:
''' 构造KNN分类器vecX:输入向量,待测数据filename: 特征集文件路径isnorm:是否进行归一化处理k:k值的选择,默认选择3
'''
def knn_classifier(vecX,dataset,labels,isnorm='Y',k=3):# 距离计算(方法1)if isnorm == 'Y':normMat,ranges,minVals = norm_dataset(dataset) # 对数据进行归一化处理normvecX = norm_dataset(vecX)else:normMat = datasetnormvecX = vecXm = normMat.shape[0]# tile方法是在列向量vecX,datasetSize次,行向量vecX1次叠加diffMat = tile(normvecX,(m,1)) - normMatsqDiffMat = diffMat ** 2sqDistances = sqDiffMat.sum(axis=1) # axis=0 是列相加,axis=1是行相加distances = sqDistances**0.5# print('vecX向量到数据集各点距离:\n'+str(distances))sortedDistIndexs = distances.argsort(axis=0) # 距离排序,升序# print(sortedDistIndicies)classCount = {} # 统计前k个类别出现频率for i in range(k):votelabel = labels[sortedDistIndexs[i]]classCount[votelabel] = classCount.get(votelabel,0) + 1 #统计键值# 类别频率出现最高的点,itemgetter(0)按照key排序,itemgetter(1)按照value排序sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)print(str(vecX)+'KNN的投票决策结果:\n'+str(sortedClassCount[0][0]))return sortedClassCount[0][0]
3 KNN算法模型评估
3.1 评价指标介绍
基本知识
混淆矩阵:正元组和负元组的合计
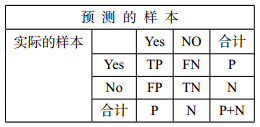
图3-1 混淆矩阵表
评估度量:(其中P:正样本数 N:负样本数 TP:真正例 TN:真负例 FP:假正例 FN:假负例)
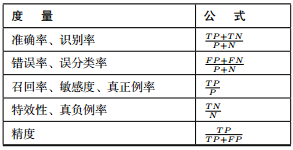

图3-2 评估信息度量表
注意:学习器的准确率最好在检验集上估计,检验集的由训练集模型时未使用的含有标记的元组组成数据。
各参数描述如下:
TP(真正例/真阳性):是指被学习器正确学习的正元组,令TP为真正例的个数。
TN(真负例/真阴性):是指被学习器正确学习的负元组,令TN为真负例的个数。
FP(假正例/假阳性):是被错误的标记为正元组的负元组。令FP为假正例的个数。
FN(假负例/假阴性):是被错误的标记为负元组的正元组。令FN为假负例的个数。
准确率:正确识别的元组所占的比例。
评价指标优点
一般采用精确率和召回率作为度量的方法具有以下几个优点:
(1) 准确率数值对于小数据不是特别敏感,而精确率和召回率对于这样数据比较敏感。 (2) 在相同实验环境下,F度量这种倾向和我们直观感觉是一致的,我们对目标事件很敏感,甚至返回一些垃圾数据也在所不惜。 (3) 通过精确率和找回来衡量目标事件和垃圾事件的差异。
模型评估拓展
参见《自然语言处理理论与实战》一书第13章模型评估。
3.2 评估算法模型实现
本文只是对错误率进行评估,其也是knn分类器核心指标,实现代码如下:
'''测试评估算法模型'''
def test_knn_perfor(filename):hoRatio = 0.1dataset,label = file_matrix(filename) # 获取训练数据和标签normMat,ranges,minVals = norm_dataset(dataset) # 对数据进行归一化处理m = normMat.shape[0]numTestVecs = int(m*hoRatio) # 10%的测试数据条数errorCount = 0.0 # 统计错误分类数for i in range(numTestVecs):classifierResult = knn_classifier(normMat[i,:],normMat[numTestVecs:m,:],label[numTestVecs:m],3) # 此处分类器可以替换不同分类模型print('分类结果:'+str(classifierResult)+'\t\t准确结果:'+str(label[i]))if classifierResult != label[i]:errorCount += 1.0Global.all_FileNum += 1print('总的错误率为:'+str(errorCount/float(numTestVecs))+"\n总测试数据量: "+str(Global.all_FileNum))
运行效果如下:
[0.44832535 0.39805139 0.56233353]KNN的投票决策结果:
分类结果:3 准确结果:3
[0.15873259 0.34195467 0.98724416]KNN的投票决策结果:
分类结果:2 准确结果:2
...
分类结果:3 准确结果:3
[0.19385799 0.30474213 0.01919426]KNN的投票决策结果:
分类结果:2 准确结果:2
[0.24463971 0.10813023 0.60259472]KNN的投票决策结果:
分类结果:1 准确结果:1
[0.51022756 0.27138082 0.41804137]KNN的投票决策结果:
分类结果:3 准确结果:1总的错误率为:0.05
总测试数据量: 100
耗时:0.0300 s
评估结果分析:
本文采用封闭评估的方法,前100条数据作为测试集,后900条数据作为训练集。如上结果最后一条信息表明knn分类器的结果是3,而标准结果是1.knn分类存在错误。将所有错误占比分析出来即错误率。本文错误率5%,即准确率95%.
读者可以选取200:800、300:700等等数据进行测试查看错误率。
4 KNN算法模型的实际应用
knn分类器应用
经过如上的改进最终形成实际应用的算法模型API开发给外部程序使用,调用knn算法代码如下:
'''调用可用算法'''
def show_classifyPerson(filename):resultlist = ['不喜欢','还可以','特别喜欢']ffMiles = float(input('每年飞行的历程多少公里?\n'))percentTats = float(input('玩游戏时间占百分比多少?\n')) # [751,13,0.4][40920 ,8.326976,0.953952]iceCream = float(input('每周消费冰淇淋多少公升?\n'))dataset,labels = file_matrix(filename) # 数据格式化处理inArr = array([ffMiles,percentTats,iceCream])classifierResult = knn_classifier(inArr,dataset,labels,3) # 数据归一化并进行分类print('预测的约会结果是:'+resultlist[classifierResult-1])
运行结果如下:
每年飞行的历程多少公里?
10000
玩游戏时间占百分比多少?
10
每周消费冰淇淋多少公升?
0.5
KNN的投票决策结果:
2
预测的约会结果是:还可以
展望
我们还可以采用knn分类器进行实际应用,比如新闻分类系统。大致思路如下:
1 采集数据:选用复旦大学的文本分类新闻语料 2 准备数据:数据格式化、分词、停用词处理等 3 分析数据:看看数据特点,有没有缺失值,数据连续性还是离散型,进而选择不同模型。诸如:可视化数据分析 4 数据转化:采用IF-IDF或者神经网络的方法对词频进行处理,最终转化为机器可以处理的数值型矩阵。 5 构建模型:KNN新闻分类器模型构建。 6 测试算法:评价指标,如计算错误率,准确率,召回率,F度量值等。 7 应用算法:针对完善的模型进行封装重构,然后进行实际的新闻分类应用。
5 参考文献
- 归一化学习:https://blog.csdn.net/hyq3235356/article/details/78472307
- 归一化方法:https://blog.csdn.net/zxd1754771465/article/details/73558103
- 百度Echart转化工具:http://echarts.baidu.com/spreadsheet.html
- 在线json验证格式工具:http://www.bejson.com/
- 模型评估:http://www.cnblogs.com/baiboy/p/mxpg2.html
完整代码下载
机器学习和自然语言QQ群:436303759。 微信公众号:datathinks


源码请进QQ群文件下载:
作者声明
本文原创,旨在学术和科研使用。转载必须注明出处【伏草惟存】: KNN模型算法研究与案例分析
KNN模型算法研究与案例分析相关推荐
- 逻辑回归模型算法研究与案例分析
逻辑回归模型算法研究与案例分析 (白宁超 2018年9月6日15: 21:20) 导读:逻辑回归(Logistic regression)即逻辑模型,属于常见的一种分类算法.本文将从理论介绍开始,搞清 ...
- 决策树模型算法研究与案例分析
决策树模型算法研究与案例分析 (白宁超 2018年8月27日11: 42:33) 导读:决策树算法是一种基本的分类与回归方法,是最经常使用的算法之一.决策树模型呈树形结构,在分类问题中,表示基于特征对 ...
- 实现 | 朴素贝叶斯模型算法研究与实例分析
实现 | 朴素贝叶斯模型算法研究与实例分析 (白宁超 2018年9月4日10:28:49) 导读:朴素贝叶斯模型是机器学习常用的模型算法之一,其在文本分类方面简单易行,且取得不错的分类效果.所以很受 ...
- 一步步教你轻松学KNN模型算法
一步步教你轻松学KNN模型算法 ( 白宁超 2018年7月24日08:52:16 ) 导读:机器学习算法中KNN属于比较简单的典型算法,既可以做聚类又可以做分类使用.本文通过一个模拟的实际案例进行讲解 ...
- matlab 30案例 目录,MATLAB-智能算法30个案例分析-终极版(带目录).doc
MATLAB-智能算法30个案例分析-终极版(带目录) MATLAB 智能算法30个案例分析(终极版) 1?基于遗传算法的TSP算法(王辉)? 2?基于遗传算法和非线性规划的函数寻优算法(史峰)? 3 ...
- MATLAB智能算法30个案例分析.史峰等
<MATLAB智能算法30个案例分析>是2011年由北京航空航天大学出版社出版的图书,作者是郁磊.史峰.王辉.胡斐- <MATLAB智能算法30个案例分析>是作者多年从事算法研 ...
- 数据结构与算法--代码鲁棒性案例分析
代码鲁棒性 鲁棒是robust的音译,就是健壮性.指程序能够判断输入是否符合规范,对不合要求的输入能够给出合理的结果. 容错性是鲁棒的一个重要体现.不鲁棒的代码发生异常的时候,会出现不可预测的异常,或 ...
- 数据结构与算法--代码完整性案例分析
确保代码完整性 在撸业务代码时候,经常面对的是接口的设计,在设计之初,我们必然要先想好入参,之后自然会有参数的校验过程,此时我们需要把可能的输入都想清楚,从而避免在程序中出现各种纰漏.但是难免面面俱到 ...
- MATLAB智能算法30个案例分析pdf
下载地址:网盘下载 MATLAB智能算法30个案例分析,ISBN:9787512403512,作者:史峰,王辉 等编著 下载地址:网盘下载 转载于:https://www.cnblogs.com/cf ...
最新文章
- php注册程序,[PHP初级]手把手教你写注册程序 1
- spring使用注解时配置文件的写法
- idea创建springboot项目出现的问题
- azul java_Java版本更新重大提醒 - Azul
- php的header()函数前有echo输出情况分析
- 24-java版Spark程序读取ElasticSearch数据
- windows和linux文件输 - ftp
- 竞价推广账户日常优化需要注意十大要点
- 快速突破面试算法之分治算法篇
- 网页完美内嵌多媒体,支持IE,Mozilla、Firefox、NetScape、Opera
- Mysql 语句执行顺序
- FMEA软件知识库(FMEAHunter)
- ad15图层显示_AD15使用及设置
- 关于微信双开后,王者荣耀默认只能打开微信主应用问题
- 阿拉伯数字转换成中文数字 C++
- [生存志] 第130节 司马著史记
- 2019,我的工作寻找之路
- win7java浏览器崩溃_win7系统IE浏览器出现各种崩溃问题的解决方法
- JSCharting JavaScript 3.3.X 12/17/2022 Crack
- 一款数据库合并工具的中文版更新