Python 数据科学入门教程:TensorFlow 聊天机器人
TensorFlow 聊天机器人
原文:Creating a Chatbot with Deep Learning, Python, and TensorFlow
译者:飞龙
协议:CC BY-NC-SA 4.0
一、使用深度学习创建聊天机器人
你好,欢迎阅读 Python 聊天机器人系列教程。 在本系列中,我们将介绍如何使用 Python 和 TensorFlow 创建一个能用的聊天机器人。 以下是一些 chatbot 的实例:
I use Google and it works.
— Charles the AI (@Charles_the_AI) November 24, 2017
I prefer cheese.
— Charles the AI (@Charles_the_AI) November 24, 2017
The internet
— Charles the AI (@Charles_the_AI) November 24, 2017
I’m not sure . I’m just a little drunk.
— Charles the AI (@Charles_the_AI) November 24, 2017
我的目标是创建一个聊天机器人,可以实时与 Twitch Stream 上的人交谈,而不是听起来像个白痴。为了创建一个聊天机器人,或者真的做任何机器学习任务,当然,你的第一个任务就是获取训练数据,之后你需要构建并准备,将其格式化为“输入”和“输出”形式,机器学习算法可以消化它。可以说,这就是做任何机器学习时的实际工作。建立模型和训练/测试步骤简单的部分!
为了获得聊天训练数据,你可以查看相当多的资源。例如,康奈尔电影对话语料库似乎是最受欢迎的语料之一。还有很多其他来源,但我想要的东西更加……原始。有些没有美化的东西,有一些带有为其准备的特征。自然,这把我带到了 Reddit。起初,我认为我会使用 Python Reddit API 包装器,但 Reddit 对抓取的限制并不是最友好的。为了收集大量的数据,你必须打破一些规则。相反,我发现了一个 17 亿个 Reddit 评论的数据转储。那么,应该使用它!
Reddit 的结构是树形的,不像论坛,一切都是线性的。父评论是线性的,但父评论的回复是个分支。以防有些人不熟悉:
-Top level reply 1
--Reply to top level reply 1
--Reply to top level reply 1
---Reply to reply...
-Top level reply 2
--Reply to top level reply 1
-Top level reply 3 我们需要用于深度学习的结构是输入输出。 所以我们实际上通过评论和回复偶对的方式,试图获得更多的东西。 在上面的例子中,我们可以使用以下作为评论回复偶对:
-Top level reply 1 and --Reply to top level reply 1--Reply to top level reply 1 and ---Reply to reply...所以,我们需要做的是获取这个 Reddit 转储,并产生这些偶对。 接下来我们需要考虑的是,每个评论应该只有 1 个回复。 尽管许多单独的评论可能会有很多回复,但我们应该只用一个。 我们可以只用第一个,或者我们可以用最顶上那个。 稍后再说。 我们的第一个任务是获取数据。 如果你有存储限制,你可以查看一个月的 Reddit 评论,这是 2015 年 1 月。否则,你可以获取整个转储:
magnet:?xt=urn:btih:7690f71ea949b868080401c749e878f98de34d3d&dn=reddit%5Fdata&tr=http%3A%2F%2Ftracker.pushshift.io%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.openbittorrent.com%3A80
我只下载过两次这个种子,但根据种子和对等的不同,下载速度可能会有很大差异。
最后,你还可以通过 Google BigQuery 查看所有 Reddit 评论。 BigQuery 表似乎随着时间的推移而更新,而 torrent 不是,所以这也是一个不错的选择。 我个人将会使用 torrent,因为它是完全免费的,所以,如果你想完全遵循它,就需要这样做,但如果你愿意的话,可以随意改变主意,使用 Google BigQuery 的东西!
由于数据下载可能需要相当长的时间,我会在这里中断。 一旦你下载了数据,继续下一个教程。 你可以仅仅下载2015-01文件来跟随整个系列教程,你不需要整个 17 亿个评论转储。 一个月的就足够了。
二、聊天数据结构
欢迎阅读 Python 和 TensorFlow 聊天机器人系列教程的第二部分。现在,我假设你已经下载了数据,或者你只是在这里观看。对于大多数机器学习,你需要获取数据,并且某些时候需要输入和输出。对于神经网络,这表示实际神经网络的输入层和输出层。对于聊天机器人来说,这意味着我们需要将东西拆成评论和回复。评论是输入,回复是所需的输出。现在使用 Reddit,并不是所有的评论都有回复,然后很多评论会有很多回复!我们需要挑一个。
我们需要考虑的另一件事是,当我们遍历这个文件时,我们可能会发现一个回复,但随后我们可能会找到更好的回复。我们可以使用一种方法是看看得票最高的。我们可能也只想要得票最高的回应。我们可以考虑在这里很多事情,按照你的希望随意调整!
首先,我们的数据格式,如果我们走了 torrent 路线:
{"author":"Arve","link_id":"t3_5yba3","score":0,"body":"Can we please deprecate the word \"Ajax\" now? \r\n\r\n(But yeah, this _is_ much nicer)","score_hidden":false,"author_flair_text":null,"gilded":0,"subreddit":"reddit.com","edited":false,"author_flair_css_class":null,"retrieved_on":1427426409,"name":"t1_c0299ap","created_utc":"1192450643","parent_id":"t1_c02999p","controversiality":0,"ups":0,"distinguished":null,"id":"c0299ap","subreddit_id":"t5_6","downs":0,"archived":true}
每一行就像上面那样。我们并不需要这些数据的全部,但是我们肯定需要body,comment_id和parent_id。如果你下载完整的 torrent 文件,或者正在使用 BigQuery 数据库,那么可以使用样例数据,所以我也将使用score。我们可以为分数设定限制。我们也可以处理特定的subreddit,来创建一个说话风格像特定 subreddit 的 AI。现在,我会处理所有 subreddit。
现在,即使一个月的评论也可能超过 32GB,我也无法将其纳入 RAM,我们需要通过数据进行缓冲。我的想法是继续并缓冲评论文件,然后将我们感兴趣的数据存储到 SQLite 数据库中。这里的想法是我们可以将评论数据插入到这个数据库中。所有评论将按时间顺序排列,所有评论最初都是“父节点”,自己并没有父节点。随着时间的推移,会有回复,然后我们可以存储这个“回复”,它将在数据库中有父节点,我们也可以按照 ID 拉取,然后我们可以检索一些行,其中我们拥有父评论和回复。
然后,随着时间的推移,我们可能会发现父评论的回复,这些回复的投票数高于目前在那里的回复。发生这种情况时,我们可以使用新信息更新该行,以便我们可以最终得到通常投票数较高的回复。
无论如何,有很多方法可以实现,让我们开始吧!首先,让我们进行一些导入:
import sqlite3
import json
from datetime import datetime我们将为我们的数据库使用sqlite3,json用于从datadump加载行,然后datetime实际只是为了记录。 这不完全必要。
所以 torrent 转储带有一大堆目录,其中包含实际的json数据转储,按年和月(YYYY-MM)命名。 他们压缩为.bz2。 确保你提取你打算使用的那些。 我们不打算编写代码来做,所以请确保你完成了!
下面,我们以一些变量开始:
timeframe = '2015-05'
sql_transaction = []connection = sqlite3.connect('{}.db'.format(timeframe))
c = connection.cursor()timeframe值将成为我们将要使用的数据的年份和月份。 你也可以把它列在这里,然后如果你喜欢,可以遍历它们。 现在,我将只用 2015 年 5 月的文件。 接下来,我们有sql_transaction。 所以在 SQL 中的“提交”是更昂贵的操作。 如果你知道你将要插入数百万行,你也应该知道你真的不应该一一提交。 相反,你只需在单个事务中构建语句,然后执行全部操作,然后提交。 接下来,我们要创建我们的表。 使用 SQLite,如果数据库尚不存在,连接时会创建数据库。
def create_table():c.execute("CREATE TABLE IF NOT EXISTS parent_reply(parent_id TEXT PRIMARY KEY, comment_id TEXT UNIQUE, parent TEXT, comment TEXT, subreddit TEXT, unix INT, score INT)")
在这里,我们正在准备存储parent_id,comment_id,父评论,回复(评论),subreddit,时间,然后最后是评论的评分(得票)。
接下来,我们可以开始我们的主代码块:
if __name__ == '__main__':create_table()目前为止的完整代码:
import sqlite3
import json
from datetime import datetimetimeframe = '2015-05'
sql_transaction = []connection = sqlite3.connect('{}2.db'.format(timeframe))
c = connection.cursor()def create_table():c.execute("CREATE TABLE IF NOT EXISTS parent_reply(parent_id TEXT PRIMARY KEY, comment_id TEXT UNIQUE, parent TEXT, comment TEXT, subreddit TEXT, unix INT, score INT)")if __name__ == '__main__':create_table()一旦我们建立完成,我们就可以开始遍历我们的数据文件并存储这些信息。 我们将在下一个教程中开始这样做!
三、缓冲数据
你好,欢迎阅读 Python TensorFlow 聊天机器人系列教程的第 3 部分。 在上一篇教程中,我们讨论了数据的结构并创建了一个数据库来存放我们的数据。 现在我们准备好开始处理数据了!
目前为止的代码:
import sqlite3
import json
from datetime import datetimetimeframe = '2015-05'
sql_transaction = []connection = sqlite3.connect('{}.db'.format(timeframe))
c = connection.cursor()def create_table():c.execute("CREATE TABLE IF NOT EXISTS parent_reply(parent_id TEXT PRIMARY KEY, comment_id TEXT UNIQUE, parent TEXT, comment TEXT, subreddit TEXT, unix INT, score INT)")if __name__ == '__main__':create_table()现在,让我们开始缓冲数据。 我们还将启动一些跟踪时间进度的计数器:
if __name__ == '__main__':create_table()row_counter = 0paired_rows = 0with open('J:/chatdata/reddit_data/{}/RC_{}'.format(timeframe.split('-')[0],timeframe), buffering=1000) as f:for row in f:row_counter会不时输出,让我们知道我们在迭代的文件中走了多远,然后paired_rows会告诉我们有多少行数据是成对的(意味着我们有成对的评论和回复,这是训练数据)。 请注意,当然,你的数据文件的实际路径将与我的路径不同。
接下来,由于文件太大,我们无法在内存中处理,所以我们将使用buffering参数,所以我们可以轻松地以小块读取文件,这很好,因为我们需要关心的所有东西是一次一行。
现在,我们需要读取json格式这一行:
if __name__ == '__main__':create_table()row_counter = 0paired_rows = 0with open('J:/chatdata/reddit_data/{}/RC_{}'.format(timeframe.split('-')[0],timeframe), buffering=1000) as f:for row in f:row_counter += 1row = json.loads(row)parent_id = row['parent_id']body = format_data(row['body'])created_utc = row['created_utc']score = row['score']comment_id = row['name']subreddit = row['subreddit']请注意format_data函数调用,让我们创建:
def format_data(data):data = data.replace('\n',' newlinechar ').replace('\r',' newlinechar ').replace('"',"'")return data我们将引入这个来规范平凡并将换行符转换为一个单词。
我们可以使用json.loads()将数据读取到 python 对象中,这只需要json对象格式的字符串。 如前所述,所有评论最初都没有父级,也就是因为它是顶级评论(父级是 reddit 帖子本身),或者是因为父级不在我们的文档中。 然而,在我们浏览文档时,我们会发现那些评论,父级确实在我们数据库中。 发生这种情况时,我们希望将此评论添加到现有的父级。 一旦我们浏览了一个文件或者一个文件列表,我们就会输出数据库并作为训练数据,训练我们的模型,最后有一个我们可以聊天的朋友! 所以,在我们把数据输入到数据库之前,我们应该看看能否先找到父级!
parent_data = find_parent(parent_id)现在我们需要寻找find_parent函数:
def find_parent(pid):try:sql = "SELECT comment FROM parent_reply WHERE comment_id = '{}' LIMIT 1".format(pid)c.execute(sql)result = c.fetchone()if result != None:return result[0]else: return Falseexcept Exception as e:#print(str(e))return False有可能存在实现他的更有效的方法,但是这样管用。 所以,如果我们的数据库中存在comment_id匹配另一个评论的parent_id,那么我们应该将这个新评论与我们已经有的父评论匹配。 在下一个教程中,我们将开始构建确定是否插入数据所需的逻辑以及方式。
四、插入逻辑
欢迎阅读 Python TensorFlow 聊天机器人系列教程的第 4 部分。 目前为止,我们已经获得了我们的数据,并开始遍历。 现在我们准备开始构建用于输入数据的实际逻辑。
首先,我想对全部评论加以限制,不管是否有其他评论,那就是我们只想处理毫无意义的评论。 基于这个原因,我想说我们只想考虑两票或以上的评论。 目前为止的代码:
import sqlite3
import json
from datetime import datetimetimeframe = '2015-05'
sql_transaction = []connection = sqlite3.connect('{}.db'.format(timeframe))
c = connection.cursor()def create_table():c.execute("CREATE TABLE IF NOT EXISTS parent_reply(parent_id TEXT PRIMARY KEY, comment_id TEXT UNIQUE, parent TEXT, comment TEXT, subreddit TEXT, unix INT, score INT)")def format_data(data):data = data.replace('\n',' newlinechar ').replace('\r',' newlinechar ').replace('"',"'")return datadef find_parent(pid):try:sql = "SELECT comment FROM parent_reply WHERE comment_id = '{}' LIMIT 1".format(pid)c.execute(sql)result = c.fetchone()if result != None:return result[0]else: return Falseexcept Exception as e:#print(str(e))return Falseif __name__ == '__main__':create_table()row_counter = 0paired_rows = 0with open('J:/chatdata/reddit_data/{}/RC_{}'.format(timeframe.split('-')[0],timeframe), buffering=1000) as f:for row in f:row_counter += 1row = json.loads(row)parent_id = row['parent_id']body = format_data(row['body'])created_utc = row['created_utc']score = row['score']comment_id = row['name']subreddit = row['subreddit']parent_data = find_parent(parent_id)现在让我们要求票数是两个或更多,然后让我们看看是否已经有了父级的回复,以及票数是多少:
if __name__ == '__main__':create_table()row_counter = 0paired_rows = 0with open('J:/chatdata/reddit_data/{}/RC_{}'.format(timeframe.split('-')[0],timeframe), buffering=1000) as f:for row in f:row_counter += 1row = json.loads(row)parent_id = row['parent_id']body = format_data(row['body'])created_utc = row['created_utc']score = row['score']comment_id = row['name']subreddit = row['subreddit']parent_data = find_parent(parent_id)# maybe check for a child, if child, is our new score superior? If so, replace. If not...if score >= 2:existing_comment_score = find_existing_score(parent_id)现在我们需要创建find_existing_score函数:
def find_existing_score(pid):try:sql = "SELECT score FROM parent_reply WHERE parent_id = '{}' LIMIT 1".format(pid)c.execute(sql)result = c.fetchone()if result != None:return result[0]else: return Falseexcept Exception as e:#print(str(e))return False如果有现有评论,并且我们的分数高于现有评论的分数,我们想替换它:
if score >= 2:existing_comment_score = find_existing_score(parent_id)if existing_comment_score:if score > existing_comment_score:接下来,很多评论都被删除,但也有一些评论非常长,或者很短。 我们希望确保评论的长度适合于训练,并且评论未被删除:
def acceptable(data):if len(data.split(' ')) > 50 or len(data) < 1:return Falseelif len(data) > 1000:return Falseelif data == '[deleted]':return Falseelif data == '[removed]':return Falseelse:return True好了,到了这里,我们已经准备好开始插入数据了,这就是我们将在下一个教程中做的事情。
五、构建数据库
欢迎阅读 Python TensorFlow 聊天机器人系列教程的第 5 部分。 在本教程之前,我们一直在处理我们的数据,准备插入数据的逻辑,现在我们已经准备好开始插入了。 目前为止的代码:
import sqlite3
import json
from datetime import datetimetimeframe = '2015-05'
sql_transaction = []connection = sqlite3.connect('{}.db'.format(timeframe))
c = connection.cursor()def create_table():c.execute("CREATE TABLE IF NOT EXISTS parent_reply(parent_id TEXT PRIMARY KEY, comment_id TEXT UNIQUE, parent TEXT, comment TEXT, subreddit TEXT, unix INT, score INT)")def format_data(data):data = data.replace('\n',' newlinechar ').replace('\r',' newlinechar ').replace('"',"'")return datadef acceptable(data):if len(data.split(' ')) > 50 or len(data) < 1:return Falseelif len(data) > 1000:return Falseelif data == '[deleted]':return Falseelif data == '[removed]':return Falseelse:return Truedef find_parent(pid):try:sql = "SELECT comment FROM parent_reply WHERE comment_id = '{}' LIMIT 1".format(pid)c.execute(sql)result = c.fetchone()if result != None:return result[0]else: return Falseexcept Exception as e:#print(str(e))return Falsedef find_existing_score(pid):try:sql = "SELECT score FROM parent_reply WHERE parent_id = '{}' LIMIT 1".format(pid)c.execute(sql)result = c.fetchone()if result != None:return result[0]else: return Falseexcept Exception as e:#print(str(e))return Falseif __name__ == '__main__':create_table()row_counter = 0paired_rows = 0with open('J:/chatdata/reddit_data/{}/RC_{}'.format(timeframe.split('-')[0],timeframe), buffering=1000) as f:for row in f:row_counter += 1row = json.loads(row)parent_id = row['parent_id']body = format_data(row['body'])created_utc = row['created_utc']score = row['score']comment_id = row['name']subreddit = row['subreddit']parent_data = find_parent(parent_id)if score >= 2:existing_comment_score = find_existing_score(parent_id)现在,如果有现有的评论分数,这意味着已经存在一个评论,所以这需要更新语句。 如果你还不知道 SQL,那么你可能需要阅读 SQLite 教程。 所以我们的逻辑最初是:
if score >= 2:existing_comment_score = find_existing_score(parent_id)if existing_comment_score:if score > existing_comment_score:if acceptable(body):sql_insert_replace_comment(comment_id,parent_id,parent_data,body,subreddit,created_utc,score)
现在,我们需要构建sql_insert_replace_comment函数:
def sql_insert_replace_comment(commentid,parentid,parent,comment,subreddit,time,score):try:sql = """UPDATE parent_reply SET parent_id = ?, comment_id = ?, parent = ?, comment = ?, subreddit = ?, unix = ?, score = ? WHERE parent_id =?;""".format(parentid, commentid, parent, comment, subreddit, int(time), score, parentid)transaction_bldr(sql)except Exception as e:print('s0 insertion',str(e))
这涵盖了评论已经与父级配对的情况,但我们还需要处理没有父级的评论(但可能是另一个评论的父级!),以及确实有父级,并且它们的父级没有回复的评论。 我们可以进一步构建插入块:
if score >= 2:existing_comment_score = find_existing_score(parent_id)if existing_comment_score:if score > existing_comment_score:if acceptable(body):sql_insert_replace_comment(comment_id,parent_id,parent_data,body,subreddit,created_utc,score)else:if acceptable(body):if parent_data:sql_insert_has_parent(comment_id,parent_id,parent_data,body,subreddit,created_utc,score)paired_rows += 1else:sql_insert_no_parent(comment_id,parent_id,body,subreddit,created_utc,score)
现在我们需要构建sql_insert_has_parent和sql_insert_no_parent函数:
def sql_insert_has_parent(commentid,parentid,parent,comment,subreddit,time,score):try:sql = """INSERT INTO parent_reply (parent_id, comment_id, parent, comment, subreddit, unix, score) VALUES ("{}","{}","{}","{}","{}",{},{});""".format(parentid, commentid, parent, comment, subreddit, int(time), score)transaction_bldr(sql)except Exception as e:print('s0 insertion',str(e))def sql_insert_no_parent(commentid,parentid,comment,subreddit,time,score):try:sql = """INSERT INTO parent_reply (parent_id, comment_id, comment, subreddit, unix, score) VALUES ("{}","{}","{}","{}",{},{});""".format(parentid, commentid, comment, subreddit, int(time), score)transaction_bldr(sql)except Exception as e:print('s0 insertion',str(e))所以为了看到我们在遍历期间的位置,我们将在每 10 万行数据输出一些信息:
if row_counter % 100000 == 0:print('Total Rows Read: {}, Paired Rows: {}, Time: {}'.format(row_counter, paired_rows, str(datetime.now())))
最后,我们现在需要的代码的最后一部分是,我们需要构建transaction_bldr函数。 这个函数用来构建插入语句,并以分组的形式提交它们,而不是一个接一个地提交。 这样做会快得多:
def transaction_bldr(sql):global sql_transactionsql_transaction.append(sql)if len(sql_transaction) > 1000:c.execute('BEGIN TRANSACTION')for s in sql_transaction:try:c.execute(s)except:passconnection.commit()sql_transaction = []是的,我用了个全局变量。
目前为止的代码:
import sqlite3
import json
from datetime import datetimetimeframe = '2015-05'
sql_transaction = []connection = sqlite3.connect('{}.db'.format(timeframe))
c = connection.cursor()def create_table():c.execute("CREATE TABLE IF NOT EXISTS parent_reply(parent_id TEXT PRIMARY KEY, comment_id TEXT UNIQUE, parent TEXT, comment TEXT, subreddit TEXT, unix INT, score INT)")def format_data(data):data = data.replace('\n',' newlinechar ').replace('\r',' newlinechar ').replace('"',"'")return datadef transaction_bldr(sql):global sql_transactionsql_transaction.append(sql)if len(sql_transaction) > 1000:c.execute('BEGIN TRANSACTION')for s in sql_transaction:try:c.execute(s)except:passconnection.commit()sql_transaction = []def sql_insert_replace_comment(commentid,parentid,parent,comment,subreddit,time,score):try:sql = """UPDATE parent_reply SET parent_id = ?, comment_id = ?, parent = ?, comment = ?, subreddit = ?, unix = ?, score = ? WHERE parent_id =?;""".format(parentid, commentid, parent, comment, subreddit, int(time), score, parentid)transaction_bldr(sql)except Exception as e:print('s0 insertion',str(e))def sql_insert_has_parent(commentid,parentid,parent,comment,subreddit,time,score):try:sql = """INSERT INTO parent_reply (parent_id, comment_id, parent, comment, subreddit, unix, score) VALUES ("{}","{}","{}","{}","{}",{},{});""".format(parentid, commentid, parent, comment, subreddit, int(time), score)transaction_bldr(sql)except Exception as e:print('s0 insertion',str(e))def sql_insert_no_parent(commentid,parentid,comment,subreddit,time,score):try:sql = """INSERT INTO parent_reply (parent_id, comment_id, comment, subreddit, unix, score) VALUES ("{}","{}","{}","{}",{},{});""".format(parentid, commentid, comment, subreddit, int(time), score)transaction_bldr(sql)except Exception as e:print('s0 insertion',str(e))def acceptable(data):if len(data.split(' ')) > 50 or len(data) < 1:return Falseelif len(data) > 1000:return Falseelif data == '[deleted]':return Falseelif data == '[removed]':return Falseelse:return Truedef find_parent(pid):try:sql = "SELECT comment FROM parent_reply WHERE comment_id = '{}' LIMIT 1".format(pid)c.execute(sql)result = c.fetchone()if result != None:return result[0]else: return Falseexcept Exception as e:#print(str(e))return Falsedef find_existing_score(pid):try:sql = "SELECT score FROM parent_reply WHERE parent_id = '{}' LIMIT 1".format(pid)c.execute(sql)result = c.fetchone()if result != None:return result[0]else: return Falseexcept Exception as e:#print(str(e))return Falseif __name__ == '__main__':create_table()row_counter = 0paired_rows = 0with open('J:/chatdata/reddit_data/{}/RC_{}'.format(timeframe.split('-')[0],timeframe), buffering=1000) as f:for row in f:row_counter += 1row = json.loads(row)parent_id = row['parent_id']body = format_data(row['body'])created_utc = row['created_utc']score = row['score']comment_id = row['name']subreddit = row['subreddit']parent_data = find_parent(parent_id)if score >= 2:existing_comment_score = find_existing_score(parent_id)if existing_comment_score:if score > existing_comment_score:if acceptable(body):sql_insert_replace_comment(comment_id,parent_id,parent_data,body,subreddit,created_utc,score)else:if acceptable(body):if parent_data:sql_insert_has_parent(comment_id,parent_id,parent_data,body,subreddit,created_utc,score)paired_rows += 1else:sql_insert_no_parent(comment_id,parent_id,body,subreddit,created_utc,score)if row_counter % 100000 == 0:print('Total Rows Read: {}, Paired Rows: {}, Time: {}'.format(row_counter, paired_rows, str(datetime.now())))
现在你可以开始运行它了。随着时间的输出应该是:
Total Rows Read: 100000, Paired Rows: 3221, Time: 2017-11-14 15:14:33.748595
Total Rows Read: 200000, Paired Rows: 8071, Time: 2017-11-14 15:14:55.342929
Total Rows Read: 300000, Paired Rows: 13697, Time: 2017-11-14 15:15:18.035447
Total Rows Read: 400000, Paired Rows: 19723, Time: 2017-11-14 15:15:40.311376
Total Rows Read: 500000, Paired Rows: 25643, Time: 2017-11-14 15:16:02.045075
遍历所有的数据将取决于起始文件的大小。 随着数据量增大插入会减慢。 为了处理 2015 年 5 月的整个文件,可能需要 5-10 个小时。
一旦你遍历了你想要的文件,我们已经准备好,将训练数据转换为我们的模型,这就是我们将在下一个教程中做的事情。
如果你正在训练更大的数据集,你可能会发现我们需要处理的数据有很大的膨胀。 这是因为只有大约 10% 的配对评论,所以我们的数据库中很大一部分并没有被实际使用。 我使用下面的附加代码:
if row_counter % cleanup == 0:print("Cleanin up!")sql = "DELETE FROM parent_reply WHERE parent IS NULL"c.execute(sql)connection.commit()c.execute("VACUUM")connection.commit()
它在另一个计数器之下。这需要新的cleanup变量,它规定了“清理”之前的多少航。这将消除我们的数据库膨胀,并使插入速度保持相当高。每个“清理”似乎移除 2K 对,几乎无论你放在哪里。如果每 100K 行一次,那么每 100K 行去掉 2K 对。我选择 100 万。另一个选项是每 100 万行清理一次,但不清理最后一百万行,而是清理最后 110 万行到第 100 万行,因为看起来这些 2K 对在最后的 100K 中。即使这样做,你仍然会失去一些偶对。我觉得每 100 万行中,100K 对中的 2K 对并不重要。我还添加了一个start_row变量,所以我可以在尝试提高速度的同时,启动和停止数据库插入。 c.execute("VACUUM")是一个 SQL 命令,用于将数据库的大小缩小到应该的值。实际上这可能不是必需的,你可能只想在最后完成此操作。我没有测试这个操作需要多长时间。我是这样做的,所以我可以在删除后立即看到数据库的大小。
完整代码是:
import sqlite3
import json
from datetime import datetime
import timetimeframe = '2017-03'
sql_transaction = []
start_row = 0
cleanup = 1000000connection = sqlite3.connect('{}.db'.format(timeframe))
c = connection.cursor()def create_table():c.execute("CREATE TABLE IF NOT EXISTS parent_reply(parent_id TEXT PRIMARY KEY, comment_id TEXT UNIQUE, parent TEXT, comment TEXT, subreddit TEXT, unix INT, score INT)")def format_data(data):data = data.replace('\n',' newlinechar ').replace('\r',' newlinechar ').replace('"',"'")return datadef transaction_bldr(sql):global sql_transactionsql_transaction.append(sql)if len(sql_transaction) > 1000:c.execute('BEGIN TRANSACTION')for s in sql_transaction:try:c.execute(s)except:passconnection.commit()sql_transaction = []def sql_insert_replace_comment(commentid,parentid,parent,comment,subreddit,time,score):try:sql = """UPDATE parent_reply SET parent_id = ?, comment_id = ?, parent = ?, comment = ?, subreddit = ?, unix = ?, score = ? WHERE parent_id =?;""".format(parentid, commentid, parent, comment, subreddit, int(time), score, parentid)transaction_bldr(sql)except Exception as e:print('s0 insertion',str(e))def sql_insert_has_parent(commentid,parentid,parent,comment,subreddit,time,score):try:sql = """INSERT INTO parent_reply (parent_id, comment_id, parent, comment, subreddit, unix, score) VALUES ("{}","{}","{}","{}","{}",{},{});""".format(parentid, commentid, parent, comment, subreddit, int(time), score)transaction_bldr(sql)except Exception as e:print('s0 insertion',str(e))def sql_insert_no_parent(commentid,parentid,comment,subreddit,time,score):try:sql = """INSERT INTO parent_reply (parent_id, comment_id, comment, subreddit, unix, score) VALUES ("{}","{}","{}","{}",{},{});""".format(parentid, commentid, comment, subreddit, int(time), score)transaction_bldr(sql)except Exception as e:print('s0 insertion',str(e))def acceptable(data):if len(data.split(' ')) > 1000 or len(data) < 1:return Falseelif len(data) > 32000:return Falseelif data == '[deleted]':return Falseelif data == '[removed]':return Falseelse:return Truedef find_parent(pid):try:sql = "SELECT comment FROM parent_reply WHERE comment_id = '{}' LIMIT 1".format(pid)c.execute(sql)result = c.fetchone()if result != None:return result[0]else: return Falseexcept Exception as e:#print(str(e))return Falsedef find_existing_score(pid):try:sql = "SELECT score FROM parent_reply WHERE parent_id = '{}' LIMIT 1".format(pid)c.execute(sql)result = c.fetchone()if result != None:return result[0]else: return Falseexcept Exception as e:#print(str(e))return Falseif __name__ == '__main__':create_table()row_counter = 0paired_rows = 0#with open('J:/chatdata/reddit_data/{}/RC_{}'.format(timeframe.split('-')[0],timeframe), buffering=1000) as f:with open('/home/paperspace/reddit_comment_dumps/RC_{}'.format(timeframe), buffering=1000) as f:for row in f:#print(row)#time.sleep(555)row_counter += 1if row_counter > start_row:try:row = json.loads(row)parent_id = row['parent_id'].split('_')[1]body = format_data(row['body'])created_utc = row['created_utc']score = row['score']comment_id = row['id']subreddit = row['subreddit']parent_data = find_parent(parent_id)existing_comment_score = find_existing_score(parent_id)if existing_comment_score:if score > existing_comment_score:if acceptable(body):sql_insert_replace_comment(comment_id,parent_id,parent_data,body,subreddit,created_utc,score)else:if acceptable(body):if parent_data:if score >= 2:sql_insert_has_parent(comment_id,parent_id,parent_data,body,subreddit,created_utc,score)paired_rows += 1else:sql_insert_no_parent(comment_id,parent_id,body,subreddit,created_utc,score)except Exception as e:print(str(e))if row_counter % 100000 == 0:print('Total Rows Read: {}, Paired Rows: {}, Time: {}'.format(row_counter, paired_rows, str(datetime.now())))if row_counter > start_row:if row_counter % cleanup == 0:print("Cleanin up!")sql = "DELETE FROM parent_reply WHERE parent IS NULL"c.execute(sql)connection.commit()c.execute("VACUUM")connection.commit()
六、训练数据集
欢迎阅读 Python TensorFlow 聊天机器人系列教程的第 6 部分。 在这一部分,我们将着手创建我们的训练数据。 在本系列中,我正在考虑使用两种不同的整体模型和工作流程:我所知的一个方法(在开始时展示并在 Twitch 流上实时运行),另一个可能会更好,但我仍在探索它。 无论哪种方式,我们的训练数据设置都比较相似。 我们需要创建文件,基本上是“父级”和“回复”文本,每一行都是一个样本。 因此,父级文件中的第15行是父评论,然后在回复文件中的第 15 行是父文件中第 15 行的回复。
要创建这些文件,我们只需要从数据库中获取偶对,然后将它们附加到相应的训练文件中。 让我们以这个开始:
import sqlite3
import pandas as pdtimeframes = ['2015-05']for timeframe in timeframes:对于这里的运行,我只在单个月上运行,只创建了一个数据库,但是你可能想创建一个数据库,里面的表是月份和年份,或者你可以创建一堆 sqlite 数据库 ,表类似于我们这些,然后遍历它们来创建你的文件。 无论如何,我只有一个,所以我会把timeframes作为一个单一的项目列表。 让我们继续构建这个循环:
for timeframe in timeframes:connection = sqlite3.connect('{}.db'.format(timeframe))c = connection.cursor()limit = 5000last_unix = 0cur_length = limitcounter = 0test_done = False第一行只是建立连接,然后我们定义游标,然后是limit。 限制是我们要从数据库中一次抽取的块的大小。 同样,我们正在处理的数据比我们拥有的RAM大得多。 我们现在要将限制设为 5000,所以我们可以有一些测试数据。 我们可以稍后产生。 我们将使用last_unix来帮助我们从数据库中提取数据,cur_length会告诉我们什么时候我们完成了,counter会允许我们显示一些调试信息,而test_done用于我们完成构建测试数据的时候。
while cur_length == limit:df = pd.read_sql("SELECT * FROM parent_reply WHERE unix > {} and parent NOT NULL and score > 0 ORDER BY unix ASC LIMIT {}".format(last_unix,limit),connection)last_unix = df.tail(1)['unix'].values[0]cur_length = len(df)
只要cur_length与我们的限制相同,我们就仍然有更多的工作要做。 然后,我们将从数据库中提取数据并将其转换为数据帧。 目前,我们对数据帧没有做太多的工作,但是之后我们可以用它对我们想要考虑的数据类型设置更多限制。 我们存储了last_unix,所以我们知道之后提取什么时候的。 我们也注意到回报的长度。 现在,建立我们的训练/测试文件。 我们将从测试开始:
if not test_done:with open('test.from','a', encoding='utf8') as f:for content in df['parent'].values:f.write(content+'\n')with open('test.to','a', encoding='utf8') as f:for content in df['comment'].values:f.write(str(content)+'\n')test_done = True现在,如果你希望,你也可以在这个时候提高限制。 在test_done = True之后,你也可以重新将limit定义为 100K 之类的东西。 现在,我们来为训练编写代码:
else:with open('train.from','a', encoding='utf8') as f:for content in df['parent'].values:f.write(content+'\n')with open('train.to','a', encoding='utf8') as f:for content in df['comment'].values:f.write(str(content)+'\n')我们可以通过把它做成一个函数,来使这个代码更简单更好,所以我们不会复制和粘贴基本相同的代码。 但是…相反…让我们继续:
counter += 1if counter % 20 == 0:print(counter*limit,'rows completed so far')这里,我们每 20 步就会看到输出,所以如果我们将限制保持为 5,000,每 100K 步也是。
目前的完整代码:
import sqlite3
import pandas as pdtimeframes = ['2015-05']for timeframe in timeframes:connection = sqlite3.connect('{}.db'.format(timeframe))c = connection.cursor()limit = 5000last_unix = 0cur_length = limitcounter = 0test_done = Falsewhile cur_length == limit:df = pd.read_sql("SELECT * FROM parent_reply WHERE unix > {} and parent NOT NULL and score > 0 ORDER BY unix ASC LIMIT {}".format(last_unix,limit),connection)last_unix = df.tail(1)['unix'].values[0]cur_length = len(df)if not test_done:with open('test.from','a', encoding='utf8') as f:for content in df['parent'].values:f.write(content+'\n')with open('test.to','a', encoding='utf8') as f:for content in df['comment'].values:f.write(str(content)+'\n')test_done = Trueelse:with open('train.from','a', encoding='utf8') as f:for content in df['parent'].values:f.write(content+'\n')with open('train.to','a', encoding='utf8') as f:for content in df['comment'].values:f.write(str(content)+'\n')counter += 1if counter % 20 == 0:print(counter*limit,'rows completed so far')好的,运行它,当你准备好数据的时候,我就会看到。
七、训练模型
欢迎阅读 Python TensorFlow 聊天机器人系列教程的第 7 部分。 在这里,我们将讨论我们的模型。 你可以提出和使用无数的模型,或在网上找到并适配你的需求。 我的主要兴趣是 Seq2Seq 模型,因为 Seq2Seq 可以用于聊天机器人,当然也可以用于其他东西。 基本上,生活中的所有东西都可以简化为序列到序列的映射,所以我们可以训练相当多的东西。 但是对于现在:我想要一个聊天机器人。
当我开始寻找聊天机器人的时候,我偶然发现了原来的 TensorFlow seq2seq 翻译教程,它把专注于英语到法语的翻译上,并做了能用的工作。不幸的是,由于 seq2seq 的一些变化,现在这个模型已经被弃用了。有一个传统的 seq2seq,你可以在最新的 TensorFlow 中使用,但我从来没有让它有效。相反,如果你想使用这个模型,你可能需要降级 TF(pip install tensorflow-gpu==1.0.0)。或者,你可以使用 TensorFlow 中最新,最好的 seq2seq 查看最新的神经机器翻译(NMT)模型。最新的 NMT 教程和来自 TensorFlow 的代码可以在这里找到:神经机器翻译(seq2seq)教程。
我们打算使用一个项目,我一直与我的朋友丹尼尔合作来从事它。
该项目的位置是:NMT 机器人,它是构建在 TensorFlow 的 NMT 代码之上的一组工具。
该项目可能会发生变化,因此你应该检查 README,在撰写本文时,该文件写了:
$ git clone --recursive https://github.com/daniel-kukiela/nmt-chatbot
$ cd nmt-chatbot
$ pip install -r requirements.txt
$ cd setup
(optional) edit settings.py to your liking. These are a decent starting point for ~4gb of VRAM, you should first start by trying to raise vocab if you can.
(optional) Edit text files containing rules in setup directory
Place training data inside "new_data" folder (train.(from|to), tst2012.(from|to)m tst2013(from|to)). We have provided some sample data for those who just want to do a quick test drive.
$ python prepare_data.py ...Run setup/prepare_data.py - new folder called "data" will be created with prepared training data
$ cd ../
$ python train.py Begin training所以让我们用它!我们将首先设置它,让它运行,然后我将解释你应该理解的主要概念。
如果你需要更多的处理能力,用这个 10 美元的折扣来查看 Paperspace,这会给你足够的时间来获得一些像样的东西。我一直在使用它们,并且非常喜欢我能够快速启动“ML-in-a-Box”选项并立即训练模型。
确保递归下载软件包,或者手动获取 nmt 软件包,或者从我们的仓库派生,或者从官方的 TensorFlow 源文件派生。我们的派生只是版本检查的一次更改,至少在那个时候,它需要非常特殊的 1.4.0 版本,而这实际上并不是必需的。这可能会在你那个时候被修复,但是我们也可能会对 NMT 核心代码做进一步的修改。
一旦下载完成,编辑setup/settings.py。如果你真的不知道自己在做什么,那没关系,你不需要修改任何东西。预设设置将需要约 4GB 的 VRAM,但至少仍然应该产生不错的模型。 Charles v2 用以下设置训练,'vocab_size': 100000,(在脚本的前面设置):
hparams = {'attention': 'scaled_luong','src': 'from','tgt': 'to','vocab_prefix': os.path.join(train_dir, "vocab"),'train_prefix': os.path.join(train_dir, "train"),'dev_prefix': os.path.join(train_dir, "tst2012"),'test_prefix': os.path.join(train_dir, "tst2013"),'out_dir': out_dir,'num_train_steps': 500000,'num_layers': 2,'num_units': 512,'override_loaded_hparams': True,'learning_rate':0.001,
# 'decay_factor': 0.99998,'decay_steps': 1,
# 'residual': True,'start_decay_step': 1,'beam_width': 10,'length_penalty_weight': 1.0,'optimizer': 'adam','encoder_type': 'bi','num_translations_per_input': 30
}我手动降低了学习率,因为 Adam 真的不需要逐渐衰减(亚当的ada代表自适应,m是时刻,所以adam就是自适应时刻)。 我以 0.001 开始,然后减半到 0.0005,然后 0.00025,然后 0.0001。 根据你拥有的数据量,你不希望在每个设定的步骤上衰减。 当使用 Adam 时,我会建议每 1-2 个迭代衰减一次。 默认的批量大小是 128,因此如果你想要将其设置为自动衰减,则可以计算出你的迭代的迭代步数。 如果你使用 SGD 优化器,那么注释掉衰减因子没有问题,并且你可能希望学习率从 1 开始。
一旦你完成了所有的设置,在主目录(utils,tests和setup目录)中,把你的train.to和train.from以及匹配的tst2012和tst2013文件放到new_data目录中。 现在cd setup来运行prepare_data.py文件:
$ python3 prepare_data.py最后cd ../,之后:
$ python3 train.py在下一个教程中,我们将更深入地讨论模型的工作原理,参数以及训练涉及的指标。
八、探索我们的 NMT 模型的概念和参数
欢迎阅读 Python TensorFlow 聊天机器人系列教程的第 8 部分。在这里,我们将讨论我们的模型。
对你来说,最主要的区别就是分桶(bucketing),填充(padding) 和更多的注意机制。在我们开始之前,先简单地谈谈这些事情。首先,如果你熟悉神经网络,请考虑 seq2seq 之类的任务,其中序列长度不完全相同。我们可以在聊天机器人范围内考虑这一点,但也可以考虑其他领域。在聊天机器人的情况下,一个单词的语句可以产生 20 个单词的回复,而长的语句可以返回单个单词的回复,并且每个输入在字符,单词等方面不同于输出。单词本身将被分配任意或有意义的 ID(通过单词向量),但是我们如何处理可变长度?一个答案就是使所有的单词串都是 50 个单词(例如)。然后,当语句长度为 35 个单词时,我们可以填充另外 15 个单词。超过 50 个单词的任何数据,我们可以不用于训练或截断。
不幸的是,这可能会让训练变得困难,特别是对于可能最为常见的较短回复,并且大多数单词/标记只是填充。原始的 seq2seq(英语到法语)的例子使用分桶来解决这个问题,并用 4 个桶训练。 5-10,10-15,20-25 和 40-50,我们最终将训练数据放入适合输入和输出的最小桶中,但这不是很理想。
然后,我们有了 NMT 代码,处理可变输入,没有分桶或填充!接下来,这段代码还包含对注意机制的支持,这是一种向循环神经网络添加长期记忆的尝试。最后,我们还将使用双向递归神经网络(BRNN)。我们来谈谈这些事情。
一般来说,一个 LSTM 可以很好地记住,长度达到 10-2 0的标记的正确序列。然而,在此之后,性能下降,网络忘记了最初的标记,为新的标记腾出空间。在我们的例子中,标记是词语,所以基本的 LSTM 应该能够学习 10-20 个单词长度的句子,但是,当我们比这更长的时候,输出可能不会那么好。注意机制就引入了,提供了更长的“注意力跨度”,这有助于网络达到更多单词,像 30,40 甚至 80 个,例如。想象一下,如果只能用 3-10 个字来处理和回应其他人的话,对于你来说有多困难,在这 10 个字的标记中,你会变得很草率,像它一样。在前面的句子中,你只需要想象一下,如果你…在你需要以至少 10 个单词开始建立你的回答之前,对你来说有多难。滑动一下,你会得到:如果你只能这样做,那么这将是很难的,而这又不是真正有意义的,并且会很难做出很好的回应。即使你确实知道你需要想象一些事情,想象什么?你必须等待,看看未来的元素,知道你打算想象什么…但是,当我们获得了这些未来的元素,哦,亲爱的,我们早已错过了我们打算想象它的部分。这是双向递归神经网络(BRNN)引入的地方。
在许多 seq2seq 的任务中,比如语言翻译,我们可以通过就地转换单词,学习简单的语法规律,因为许多语言在语法上是相似的。 随着自然语言和交际的发展,以及英语到日语等一些翻译形式的出现,在语境,流动等方面也越来越重要。 还有更多的事情要做。 双向递归神经网络(BRNN)假定现在,过去和未来的数据在输入序列中都是重要的。 双向递归神经网络(BRNN)的“双向”部分具有很好的描述性。 输入序列是双向的。 一个向前,另一个向后。 为了说明这一点:
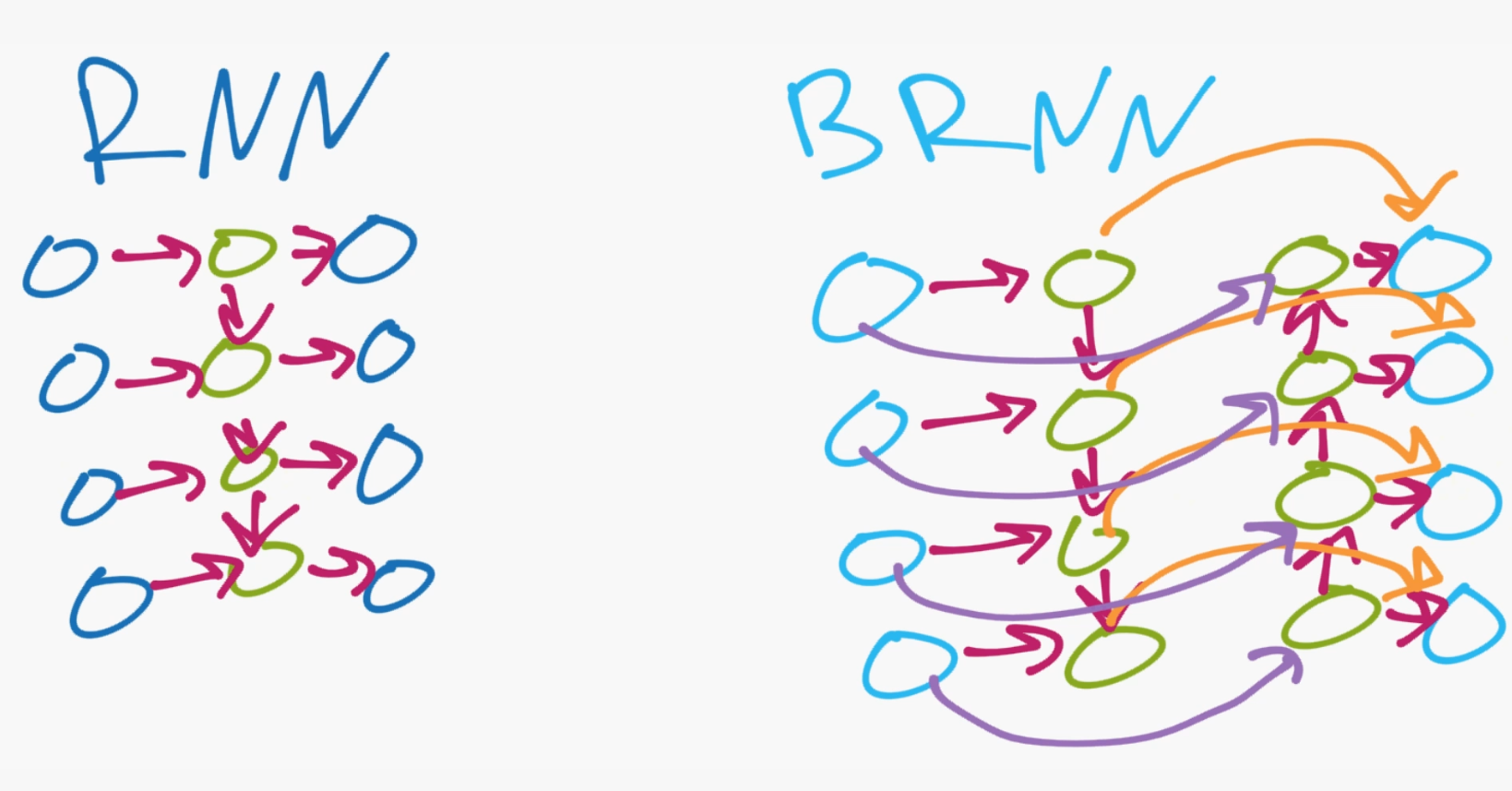
在简单的RNN上,你有输入层,你的输出层,然后我们只有一个隐藏层。然后,你从输入层连接到隐藏层,隐藏层中的每个节点也向下传递到下一个隐藏层节点,这就是我们如何得到我们的“时间”,以及来自循环神经网络的非静态特性,因为之前的输入允许在隐藏层上向下和向下传播。相反在 BRNN 上,你的隐藏层由相反方向的节点组成,所以你有输入和输出层,然后你会有你的隐藏层。然而,与基本的 RNN 不同,隐藏层向上和向下传递数据(或者向前和向后传递,取决于谁在绘制图片),这使得网络能够基于历史上发生的事情,以及我们传给序列的未来发生的事情,理解发生了什么。
下一个加入我们的网络是一个注意机制,因为尽管数据向前和向后传递,但是我们的网络不能一次记住更长的序列(每次最多 3-10 个标记)。如果你正在给我们所用的单词加上标记,那么这意味着每次最多只有 3 到 10 个单词,但是对于字符级别的模型来说,这个问题甚至更加棘手,你最多可以记住 3-10 个字符。但是,如果你做一个字符模型,你的词汇数可能低得多。
有了注意机制,我们可以处理序列中的 30, 40, 80+个标记。下面是一个描述 BLEU 的图片,其中包含或不包含注意机制:
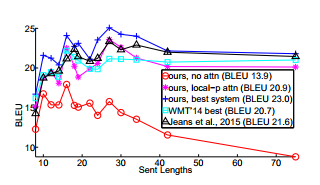
BLEU代表“双语评估替代”,它可能是我们确定翻译算法总体有效性的最佳方式。然而,重要的是,BLEU 将与我们正在翻译的序列有关。例如,我们的英语到法语的 BLEU 成绩远远,很可能高于英语到日语,甚至德语,或者单词,思想或短语没有任何直接翻译的语言。在我们的例子中,我们正在将序列翻译成序列,两个都是英文序列,所以我们应该看到一个非常高的 BLEU?可能不是。有了语言翻译,对于一个输入,经常存在“确切”或至少一些“完美”的匹配(同样,有些东西不能完美翻译,但这不会是多数)。有了对话数据,对于某些陈述真的有一个“确切”的答案吗?绝对不是。我们应该期待看到,BLEU 随着时间的推移缓慢上升,但不期望看到 BLEU 得分与语言翻译任务类似的。
注意机制不仅帮助我们处理更长的序列,而且还改善了短的。注意机制也允许学习比我们需要的聊天机器的更复杂。他们的主要驱动力似乎不仅是语言,在英语和法语之间进行翻译相对比较容易,但像日语这样的语言结构需要更多的注意。你可能真的需要看看 100 个单词的日语句子的结尾,来辨别第一个英文单词应该是什么,反之亦然。通过我们的聊天机器人,我们面临类似的困扰。我们没有将词翻译为词,将名词短语翻译为名词短语。相反,输入序列的结束可以并且通常完全确定输出序列应该是什么。我稍后可能会更深入地关注注意机制,但现在,这对于大体思路已经足够了。
除了 BLEU,你也要看看 Perplexity,通常是缩写为“PPL”。Perplexity 是另一个有用的方法,衡量模型的有效性。与 BLEU 不同的是,它越低越好,因为它是模型预测样本输出效果的概率分布。同样,对于语言翻译。
有了 BLEU 和 PPL,有了翻译,只要 BLEU 上升,PPL 下降,你通常可以训练一个模型。然而,如果一个聊天机器人从来没有或者从来不应该是一个“正确”的答案,那么只要 BLEU 和 PPL 上升,我就会警告不要继续训练,因为这样可能会产生更多的机器人似的反应,而不是高度多样的。我们还有其他方法可以解决这个问题,以后我们可以解决。
我希望这不是你第一个机器学习教程,但是,如果是这样,你也应该知道什么是损失。基本上损失是一个度量,衡量你的神经网络输出层与样本数据的“接近”程度。损失越低越好。
我想提到的最后一个概念是 Beam Search。使用这个,我们可以从我们的模型中查看一系列顶级翻译,而不仅仅是最顶端的一个而不考虑其他的。这样做会导致翻译时间更长,但在我看来,翻译模型必须这样,因为我们会发现,我们的模型仍然很有可能产生我们不想要的输出,但是对训练这些输出可能会导致其他地方的过拟合。允许多种翻译将有助于训练和生产。
好的,在下一个教程中,我们将讨论如何开始与聊天机器人进行交互。
九、与聊天机器人交互
欢迎阅读 Python Tensorflow 和深度学习聊天机器人系列教程的第 9 部分。 在本教程中,我们将讨论如何与我们的模型进行交互,甚至可能将其推入生产环境。
在训练你的模型时,默认情况下每 1,000 步将保存一个检查点文件。 如果你需要或想要停止你的训练,你可以安全地这样做,并选择最近的检查点的备份。 每个检查点的保存数据包含各种日志记录参数,还包括模型的完整权重/偏差等。 这意味着你可以选取这些检查点/模型文件,并使用它们继续训练或在生产中使用它们。
检查点默认保存在模型目录中。 你应该看到名为translate.ckpt-XXXXX的文件,其中X对应于步骤序号。 你应该有.data,.index和一个.meta文件,以及检查点文件。 如果你打开检查点文件,你会看到它看起来像:
model_checkpoint_path: "/home/paperspace/Desktop/nmt-chatbot/model/translate.ckpt-225000"
all_model_checkpoint_paths: "/home/paperspace/Desktop/nmt-chatbot/model/translate.ckpt-221000"
all_model_checkpoint_paths: "/home/paperspace/Desktop/nmt-chatbot/model/translate.ckpt-222000"
all_model_checkpoint_paths: "/home/paperspace/Desktop/nmt-chatbot/model/translate.ckpt-223000"
all_model_checkpoint_paths: "/home/paperspace/Desktop/nmt-chatbot/model/translate.ckpt-224000"
all_model_checkpoint_paths: "/home/paperspace/Desktop/nmt-chatbot/model/translate.ckpt-225000"
这仅仅让你的模型知道使用哪些文件。 如果你想使用一个特定的,较老的模型,你可以编辑它。
因此,为了加载模型,我们需要 4 个文件。 假设我们的步骤是 22.5 万。 这意味着我们需要以下内容来运行我们的模型,或者加载它来继续训练:
checkpoint
translate.ckpt-225000.meta
translate.ckpt-225000.index
translate.ckpt-225000.data-00000-of-00001因此,如果你转移到云中的某台计算机上,无论是用于训练还是生产,这些都是你需要的文件。
除了每隔 1000 步保存检查点外,我们还会做一些更多的示例(来自我们的tst.to和tst.from文件)。 这些数据每千步输出一次,并进入模型目录以及output_dev和output_test。 你可以使用这些文件查看每隔 1000 个步骤在控制台中完成的单个示例。 这些输出文件纯粹是测试文件的,顶级输出语句的结果响应。 既然你可以在你的测试文件中添加你想要的任何示例,那么这是你可以与聊天机器人进行交互的第一种方式,或者至少可以看到交互。 我写了一个简单的配对脚本,来输出测试文件和输出文件的评论响应偶对。
例如,假设你已经有了你的tst2013.from文件:
Aren ' t they streaming it for free online ... ?
try to get loud please
I ' m trying to eat a fajita here
E
It ' s been 3 innings and Spanton almost hit a dong .
Looks - wise yes , play - wise no
But we ' d both pay $ 9 . 9 9 to see that . newlinechar newlinechar Isn ' t he doing stuff for CZW ? Aren ' t they like extreme stuff , they should do a Punjabi Prison Match with CJ Parker .
' I simply feel as though the game is not for me . ' * Zaffre states , turning back to Ambrose , a frown on his face . *
The fire escape is there . You hear wood splintering , and look to see that a raptor has managed to break a hole in the top of the door , just above the dresser . Its head pokes through , then disappears . There ' s another thud , and the dresser moves forward a few inches .
[ ] ( / fritteehee ) I wonder how I ' ll make the eyes all red ...
3 6 0 , 6 7 8
I like the idea ... have an upvote !
who talks trash about Giannis ?
C
I ' m pretty sure that ' s the peace music .
Did well on my quiz today , am now eating ice cream . Good day .之后是你的output_dev文件:
Yes they are .
I don ' t think I ' ve ever heard of this . I ' ll have to check it out .
<unk>
R
It ' s been a while since I ' ve seen it , but it ' s been a while since I ' ve seen it .
I don ' t think I ' ve ever played - wise .
I don ' t think he ' s doing anything for <unk> . I ' m sure he ' ll be fine .
' I don ' t feel as though the game is for me . '
That ' s what I was thinking as well .
[ ] ( / <unk> ) I don ' t know .
3 6 0 , 6 7 9
Thank you !
I don ' t think that ' s what he ' s talking about .
K
You ' re right , it ' s the peace music .
Good day .我们可以手动前后移动,但这可能很乏味,所以我已经做了一个快速配对脚本:
output_file_location = 'output_dev'
tst_file_location = 'tst2013.from'if __name__ == '__main__':with open(output_file_location,"r") as f:content = f.read()to_data = content.split('\n')with open(tst_file_location,"r") as f:content = f.read()from_data = content.split('\n')for n, _ in enumerate(to_data[:-1]):print(30*'_')print('>',from_data[n])print()print('Reply:',to_data[n])输出应该是:
> Aren ' t they streaming it for free online ... ?Reply: Yes they are .接下来,你可能希望实际与你的机器人通信,这是推理脚本的用途。
如果你运行这个,你可以和你的机器人交互,提出问题。在写这篇文章的时候,我们仍然在修改评分结果和调整内容。你可能对这里的结果感到满意,或者你可能想用你自己的方法来选择“正确”的答案。举个例子,到目前为止,我训练过的聊天机器人有问题,例如只是重复问题,或者有时在回复完成之前没有完成一个想法。而且,如果机器人遇到不属于他们词汇表的词语,则会产生 UNK 标记,所以我们可能不想要这些标记。
如果你想从推理脚本获得 10 个以上合理的输出结果,你可以将beam_width和num_translations_per_input从 10 增加到 30,或者如果你喜欢,可以增加更多。
如果你想在 Twitter 上实现类似于 Charles AI 的东西,那么你可以稍微修改这个推理脚本。例如,我打开这个脚本,然后,在True循环内,我检查数据库是否有任何新的社交媒体输入。如果还没有任何回应,我使用该模型创建一个回应并将其存储到数据库中。然后使用 Twitter/Twitch/Reddit API,我实际上会产生一个回应。
你还需要“挑选”一个回应。你可以用机器人的第一个回应,但是由于光束 beam search,你可以看到不少的选择,不妨使用它们!如果你运行推理,你会看到有很多输出:
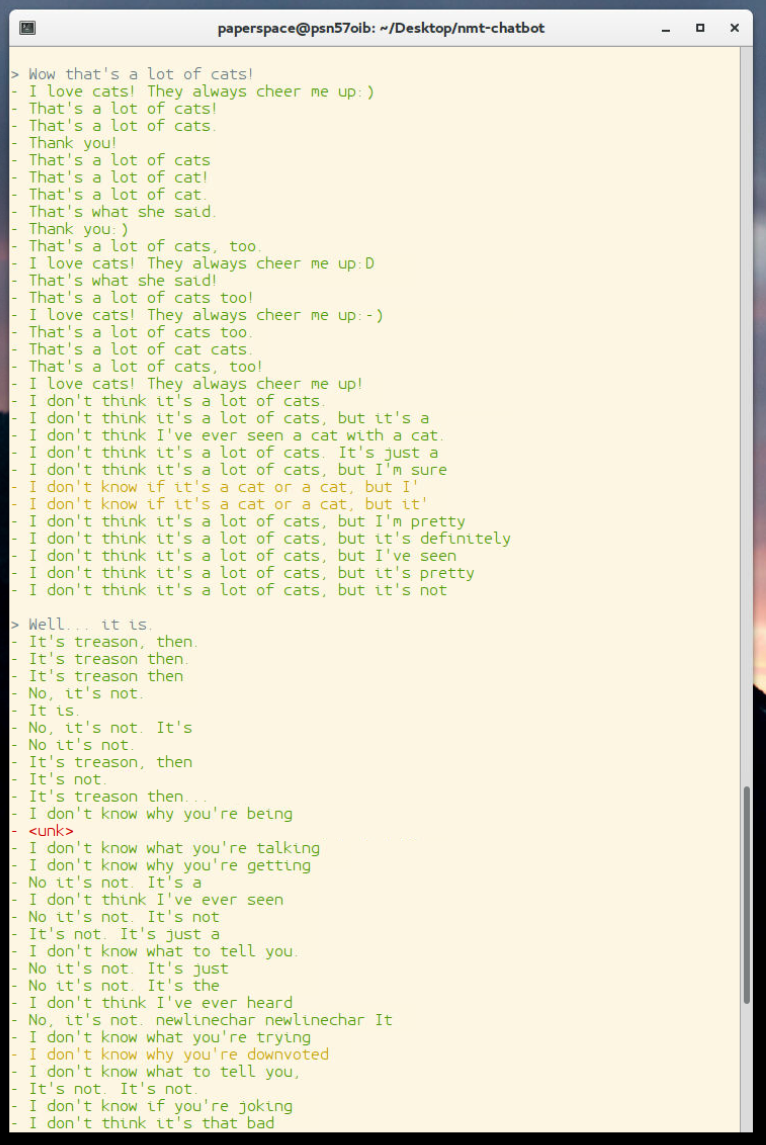
每个聊天机器人可能会有所不同,但如前所述,我们在这里可能经常会看到许多输出问题。例如,<UNK>标记看起来比较丑陋和不友好,也是我的机器人经常喜欢重复问题或没有完成的想法,因此我们可能会使用一个小型自然语言处理,试图挑最好的答案,我们 可以。 在写这篇文章的时候,我已经写了一个评分脚本,用来评价 Daniel 所做的评分,你可以在sentdex_lab目录中找到它。 基本上,如果你想使用它们,这里的所有文件都需要放在根目录中。 如果你这样做,你可以按照你的喜好调整scoring.py。 然后,你可以运行modded-inference.py,并获得单个最高分结果,例如:
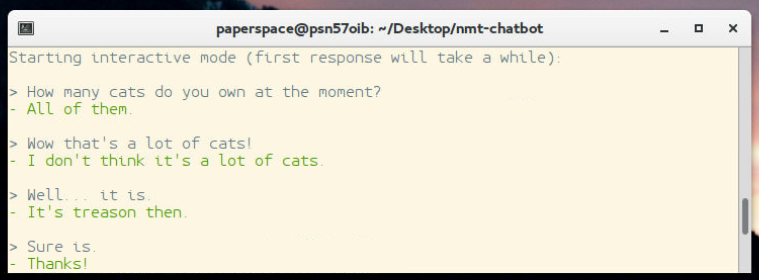
好吧,现在已经够了。 这个时候,你需要做很多调整,然后和它玩玩。 我仍然在讨论各种模型的大小,希望通过更好的方法来表达数据,从而使输出的词汇量可能更大。 我也有兴趣选取一个通用的模型,传入主要是讽刺的数据,看看我是否可以使用迁移学习,实现一个“有态度的查尔斯”类型的机器人,但我们会看看。
Python 数据科学入门教程:TensorFlow 聊天机器人相关推荐
- Python 数据科学入门教程:机器学习:回归
Python 数据科学入门教程:机器学习:回归 原文:Regression - Intro and Data 译者:飞龙 协议:CC BY-NC-SA 4.0 引言和数据 欢迎阅读 Python 机器 ...
- Python 数据科学入门教程:OpenCV
图像和视频分析 原文:Images and Video Analysis 译者:飞龙 协议:CC BY-NC-SA 4.0 一.Python OpenCV 入门 欢迎阅读系列教程,内容涵盖 OpenC ...
- Python 数据科学入门教程:Matplotlib
Matplotlib 入门教程 来源:Introduction to Matplotlib and basic line 译者:飞龙 协议:CC BY-NC-SA 4.0 在线阅读 PDF格式 EPU ...
- Python 数据科学入门教程:TensorFlow 目标检测
TensorFlow 目标检测 原文:TensorFlow Object Detection 译者:飞龙 协议:CC BY-NC-SA 4.0 一.引言 你好,欢迎阅读 TensorFlow 目标检测 ...
- Python 数据科学入门教程:NLTK
自然语言处理教程 原文:Natural Language Process 译者:飞龙 协议:CC BY-NC-SA 4.0 一.使用 NLTK 分析单词和句子 欢迎阅读自然语言处理系列教程,使用 Py ...
- 《Python数据科学入门》之阅读笔记(第2章)
Python数据科学入门 Dmitry Zinoviev著 熊子源 译 第二章 数据科学的Python核心 第4单元 理解基本的字符串函数 大小写转换函数: lower() 将所有字符转换为小写 up ...
- 《Python数据科学入门》之数据库的使用(第4章)
Python数据科学入门 Dmitry Zinoviev著 熊子源 译 第四章 使用数据库 本章介绍了数据库的使用.之前那本<Python爬虫>中有谈到数据库的使用,这里就不再详细介绍.仅 ...
- python数据科学入门_干货!小白入门Python数据科学全教程
前言本文讲解了从零开始学习Python数据科学的全过程,涵盖各种工具和方法 你将会学习到如何使用python做基本的数据分析 你还可以了解机器学习算法的原理和使用 说明 先说一段题外话.我是一名数据工 ...
- python3 array为什么不能放不同类型的数据_小白入门Python数据科学全教程lt;一gt;...
前言 本文讲解了从零开始学习Python数据科学的全过程,涵盖各种工具和方法 你将会学习到如何使用python做基本的数据分析 你还可以了解机器学习算法的原理和使用 说明 先说一段题外话.我是一名数据 ...
最新文章
- Docker 镜像小结 - 每天5分钟玩转 Docker 容器技术(21)
- [Oracle]使用非滚动游标
- JavaScript学习笔记:对象
- [SpriteKit] 系统框架中Cocos2d-x制作小游戏ZombieConga
- html5鼠标点击弹出层,jQuery实现单击弹出Div层窗口效果(可关闭可拖动)
- 路径标记语法 in Windows Presentation Foundation(WPF)
- 同时安装python2和python3
- DSP28335串口打印 printf
- Android 控件的各种方法介绍
- IP数据包格式各字段详解说明
- 领接矩阵结构的图的遍历(广度和深度遍历)
- Linux常用命令(四)
- TMS VCL UI包功能和特点
- 找一个能随时随地聊天的人很难?不,只是你还不知道Soul App
- 64马8赛道取前4问题
- 网站流量的算法是怎么算的?网站每月10G流量够用吗
- iframe嵌套视频,视频全屏用不了
- 未来的技术型人才,社会杰出人物的java人生实时记录
- 高鸿业微观经济学第8版笔记和课后答案
- oracle将以逗号分隔字符串转多行
热门文章
- 正则表达式2-测试代码
- 自己在win10中添加ADO控件步骤总结
- python读取csv文件_Hello,Python!小鲸教你Python之文件读取
- java 国家名称排序,我有一个国家名单。我想按字母顺序对它进行排序,除了两个我想放在第一位的国家...
- linux下的网桥介绍
- linux路由内核实现分析(二)---FIB相关数据结构(3)
- 关于Python ord()和chr()返回ASCII码和Unicode码的看法
- html php上传图片验证判断,HTML_PHP实例:上传多个图片并校验的代码,单张的图片上传是不复杂的, - phpStudy...
- endnote如何导入txt文件_python如何处理txt及excel文件
- 手机闪存速度排行_2020年双十二3000-4000元高性价比手机推荐!