MySQL主从1205报错【转】
主从报错1205 Slave SQL thread retried transaction 10 time(s) in vain, giving up. Consider raising the value of the slave_transaction_retries variable
Last_Errno: 1205
Last_Error: Slave SQL thread retried transaction 10 time(s) in vain, giving up. Consider raising the value of the slave_transaction_retries variable
![]()
解决办法:
stop slave; start slave; show slave status\G;
大家都知道DBA就像是消(背)防(锅)员(侠),因为前端应用还有开发上线的新版本都会影响到位于最底层的数据库,前方稍微有些风吹草动,就能反应在数据库的性能上。但是有的时候SQL不仅能决定数据库的性能,还能决定数据库的生死,今天的案例是开发的一条SQL,引起的MySQL数据库主从复制报错,vip漂移问题。
今天下午有客户反馈发消息有点慢,手机收到几条报警:
nagios报警如下大致意思就是
14:39分 vip发生了漂移
**** Nagios ***** Notification Type: PROBLEM
Service: check_ha_mysqld
Host: prod-bjuc-mysql1-vip
Address: 192.168.87.74
State: CRITICAL
Date/Time: Wed Mar 28 14:39:27 CST 2018
Additional Info:
CRITICAL: HA Failover from 192.168.87.72 to 192.168.87.123,
192.168.87.123 result:PROCS OK: 1 processes with command name /usr/sbin/mysqld,
args VIP=192.168.87.74, 192.168.87.72:PROCS OK: 1 processes with command name /usr/sbin/mysqld14:46分主从复制中断
***** Nagios ***** Notification Type: PROBLEM
Service: check_mysql_health_slave-sql-running
Host: bjuc-mysql1
Address: 192.168.87.72
State: CRITICAL
Date/Time: Wed Mar 28 14:46:06 CST 2018
Additional Info:
CRITICAL - Slave sql is not running登录数据库服务器查看主从复制的状态,发现报错1205错
mysql> show slave status\G
*************************** 1. row ***************************Slave_IO_State: Waiting for master to send eventMaster_Host: 192.168.87.123Master_User: zhuMaster_Port: 3306Connect_Retry: 60Master_Log_File: mysql-bin.000481Read_Master_Log_Pos: 218802975Relay_Log_File: mysql-relay-bin.000428Relay_Log_Pos: 2428110Relay_Master_Log_File: mysql-bin.000481Slave_IO_Running: YesSlave_SQL_Running: NoReplicate_Do_DB: Replicate_Ignore_DB: performance_schema,information_schema,test,mysqlReplicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: %.%Replicate_Wild_Ignore_Table: Last_Errno: 1205Last_Error: Error 'Lock wait timeout exceeded; try restarting transaction' on query. Default database: 'statusnet'. Query: 'UPDATE notice_status_new set valid = 0 WHERE conversation = 384667 AND user_id IN(4337475,4337529,4337471,4337365)'Skip_Counter: 0Exec_Master_Log_Pos: 182088298Relay_Log_Space: 39142986Until_Condition: NoneUntil_Log_File: Until_Log_Pos: 0Master_SSL_Allowed: NoMaster_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: NoLast_IO_Errno: 0Last_IO_Error:
Last_SQL_Errno: 1205
Last_SQL_Error: Error 'Lock wait timeout exceeded; try restarting transaction' on query.
Default database: 'statusnet'. Query: 'UPDATE notice_status_new set valid = 0 WHERE conversation = 384667 AND user_id IN(4337475,4337529,4337471,4337365)'Replicate_Ignore_Server_Ids: Master_Server_Id: 6
1 row in set (0.00 sec)查看错误日志有一下报错信息:
错误日志中给出了报错原因和解决方法
tail -70 error.log
180328 14:36:05 [ERROR] Slave SQL: Error 'Lock wait timeout exceeded; try restarting transaction' on query. Default database: 'statusnet'. Query: 'UPDATE notice_status_new set valid = 0 WHERE conversation = 384667 AND user_id IN(4337475,4337529,4337471,4337365)', Error_code: 1205
180328 14:36:21 [ERROR] Slave SQL: Error 'Lock wait timeout exceeded; try restarting transaction' on query. Default database: 'statusnet'. Query: 'UPDATE notice_status_new set valid = 0 WHERE conversation = 384667 AND user_id IN(4337475,4337529,4337471,4337365)', Error_code: 1205
180328 14:36:38 [ERROR] Slave SQL: Error 'Lock wait timeout exceeded; try restarting transaction' on query. Default database: 'statusnet'. Query: 'UPDATE notice_status_new set valid = 0 WHERE conversation = 384667 AND user_id IN(4337475,4337529,4337471,4337365)', Error_code: 1205
180328 14:36:56 [ERROR] Slave SQL: Error 'Lock wait timeout exceeded; try restarting transaction' on query. Default database: 'statusnet'. Query: 'UPDATE notice_status_new set valid = 0 WHERE conversation = 384667 AND user_id IN(4337475,4337529,4337471,4337365)', Error_code: 1205
180328 14:37:15 [ERROR] Slave SQL: Error 'Lock wait timeout exceeded; try restarting transaction' on query. Default database: 'statusnet'. Query: 'UPDATE notice_status_new set valid = 0 WHERE conversation = 384667 AND user_id IN(4337475,4337529,4337471,4337365)', Error_code: 1205
180328 14:37:35 [ERROR] Slave SQL: Error 'Lock wait timeout exceeded; try restarting transaction' on query. Default database: 'statusnet'. Query: 'UPDATE notice_status_new set valid = 0 WHERE conversation = 384667 AND user_id IN(4337475,4337529,4337471,4337365)', Error_code: 1205
180328 14:37:56 [ERROR] Slave SQL: Error 'Lock wait timeout exceeded; try restarting transaction' on query. Default database: 'statusnet'. Query: 'UPDATE notice_status_new set valid = 0 WHERE conversation = 384667 AND user_id IN(4337475,4337529,4337471,4337365)', Error_code: 1205
180328 14:38:17 [ERROR] Slave SQL: Error 'Lock wait timeout exceeded; try restarting transaction' on query. Default database: 'statusnet'. Query: 'UPDATE notice_status_new set valid = 0 WHERE conversation = 384667 AND user_id IN(4337475,4337529,4337471,4337365)', Error_code: 1205
180328 14:38:38 [ERROR] Slave SQL: Error 'Lock wait timeout exceeded; try restarting transaction' on query. Default database: 'statusnet'. Query: 'UPDATE notice_status_new set valid = 0 WHERE conversation = 384667 AND user_id IN(4337475,4337529,4337471,4337365)', Error_code: 1205
180328 14:38:59 [ERROR] Slave SQL: Error 'Lock wait timeout exceeded; try restarting transaction' on query. Default database: 'statusnet'. Query: 'UPDATE notice_status_new set valid = 0 WHERE conversation = 384667 AND user_id IN(4337475,4337529,4337471,4337365)', Error_code: 1205
180328 14:39:20 [ERROR] Slave SQL: Error 'Lock wait timeout exceeded; try restarting transaction' on query. Default database: 'statusnet'. Query: 'UPDATE notice_status_new set valid = 0 WHERE conversation = 384667 AND user_id IN(4337475,4337529,4337471,4337365)', Error_code: 1205
180328 14:39:20 [ERROR] Slave SQL thread retried transaction 10 time(s) in vain, giving up. Consider raising the value of the slave_transaction_retries variable.
180328 14:39:20 [Warning] Slave: Lock wait timeout exceeded; try restarting transaction Error_code: 1205
180328 14:39:20 [ERROR] Error running query, slave SQL thread aborted. Fix the problem, and restart the slave SQL thread with "SLAVE START". We stopped at log 'mysql-bin.000481' position 182088298查看参数结合着两个参数可以知道主从复制报错的原因为:
180328 14:39:20 [ERROR] Slave SQL thread retried transaction 10 time(s) in vain, giving up. Consider raising the value of the slave_transaction_retries variable.
180328 14:39:20 [Warning] Slave: Lock wait timeout exceeded; try restarting transaction Error_code: 1205
180328 14:39:20 [ERROR] Error running query, slave SQL thread aborted,Fix the problem, and restart the slave SQL thread with "SLAVE START". We stopped at log 'mysql-bin.000481' position 182088298
因为表notice_status_new产生了锁,阻塞了这条update语句
参数innodb_lock_wait_time 设置的为15秒,单个事务在等待15秒后开始报1025错:因为锁执行超时并重启事务
参数slave_transaction_retries 设置的为10次,如果事务重试次数超过10次,复制中断。(但是错误日志中尝试了11次)
mysql> show variables like '%innodb_lock_wait_timeout%';+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| innodb_lock_wait_timeout | 15 |
+--------------------------+-------+
1 row in set (0.01 sec)mysql> show variables like '%slave_transaction_retries%';
+---------------------------+-------+
| Variable_name | Value |
+---------------------------+-------+
| slave_transaction_retries | 10 |
+---------------------------+-------+
1 row in set (0.00 sec)解决方法:重启slave后主从复制恢复,并开始追日志
mysql> stop slave;
Query OK, 0 rows affected (0.02 sec)mysql> start slave;
Query OK, 0 rows affected (0.00 sec)mysql> show slave status\G
*************************** 1. row ***************************Slave_IO_Running: YesSlave_SQL_Running: Yes1 row in set (0.00 sec)vip的问题等到晚上在切回来,
---------------------------------我是分割线--------------------------
这次问题虽然解决了,但是发现问题我们一定要找到根音,这样问题才能算是闭环。
为什么会产生这个锁呢,因为记录锁信息的表都是实时的,现在查不出当时的锁信息,但是从存储引擎的运行状态中还是能发现一些问题,数据库出现了死锁!!显然在update这张表一定会等待的!!
发现了一条奇葩SQL,被锁的那张表也是notice_status_new
UPDATE notice_status_new SET count = count + 1, push_count = push_count + 1 WHERE conversation = 2609759 AND user_id != 7384662 AND user_id IN(7359498)
show engine innodb status\G
截取死锁的这部分
------------------------
LATEST DETECTED DEADLOCK
------------------------
180328 14:33:52
*** (1) TRANSACTION:
TRANSACTION 1B285E9F9, ACTIVE 0 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 4 lock struct(s), heap size 1248, 3 row lock(s), undo log entries 1
MySQL thread id 3972036, OS thread handle 0x7fc0c3464700, query id 2525495433 192.168.87.42 dstatusnet Updating
UPDATE notice_status_new SET count = count + 1, push_count = push_count + 1 WHERE conversation = 2609759 AND user_id != 7384662 AND user_id IN(7359498)
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 3535 page no 65360 n bits 448 index `conv_user` of table `statusnet`.`notice_status_new` trx id 1B285E9F9 lock_mode X locks rec but not gap waiting
Record lock, heap no 241 PHYSICAL RECORD: n_fields 3; compact format; info bits 00: len 8; hex 000000000027d25f; asc ' _;;1: len 4; hex 80704c0a; asc pL ;;2: len 4; hex 80b1a0fe; asc ;;*** (2) TRANSACTION:
TRANSACTION 1B285E9FD, ACTIVE 0 sec starting index read, thread declared inside InnoDB 500
mysql tables in use 1, locked 1
4 lock struct(s), heap size 1248, 3 row lock(s), undo log entries 1
MySQL thread id 3867908, OS thread handle 0x7fbfc6d4f700, query id 2525495437 192.168.87.42 dstatusnet Updating
UPDATE notice_status_new SET count = count + 1, push_count = push_count + 1 WHERE conversation = 2609759 AND user_id != 7359498 AND user_id IN(7384662)
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 3535 page no 65360 n bits 448 index `conv_user` of table `statusnet`.`notice_status_new` trx id 1B285E9FD lock_mode X locks rec but not gap
Record lock, heap no 241 PHYSICAL RECORD: n_fields 3; compact format; info bits 00: len 8; hex 000000000027d25f; asc ' _;;1: len 4; hex 80704c0a; asc pL ;;2: len 4; hex 80b1a0fe; asc ;;*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 3535 page no 65360 n bits 448 index `conv_user` of table `statusnet`.`notice_status_new` trx id 1B285E9FD lock_mode X locks rec but not gap waiting
Record lock, heap no 242 PHYSICAL RECORD: n_fields 3; compact format; info bits 00: len 8; hex 000000000027d25f; asc ' _;;1: len 4; hex 8070ae56; asc p V;;2: len 4; hex 80b1a0fc; asc ;;*** WE ROLL BACK TRANSACTION (2)问题找到了,找对该业务的开发,沟通后决定在周六上线新版本,彻底解决问题。
可以写一个实时监控锁的脚本,把内容输出打印,这样方便以后定位问题!
-----------------------------------------------
后面想了想可能是由于vip漂移导致的主从复制报错
线上架构为MM+heartbeat
vip漂移的原因待定,vip漂移后,数据库开始在192.168.87.123服务器上写入数据库,72数据库作为备份库,但是还会同步123数据库的数据,由于192.168.87.72数据库表notice_status_new还存在死锁,所以在slave SQL thread应用来自123服务器的中继日志时,执行到该SQL时,发生了锁等待,等待15秒后超时并重新尝试该事务,尝试10后,还是在锁表状态,slave SQL thread 线程停止工作,主从同步中断。
----------------------------------------
3月29日和开发复盘
因为报警时间不是很准确,实际时间还是以heartbeat日志和mysql日志为准,通过查看日志确定是heartbeat首先发生漂移,然后才是主从复制报错
主要是讨论的问题有两个
① Heartbeat为什么会发生漂移
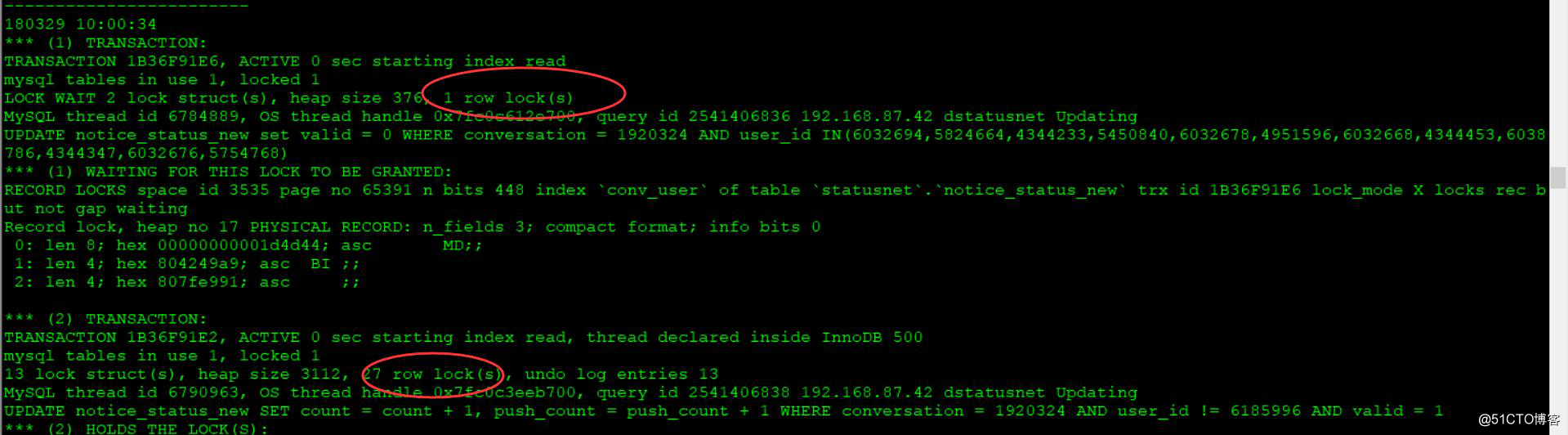
通过查看heartbeat日志,72和123存在心跳检测,在72ping123的时候发生了丢包,
在123ping72的时候正常,72节点以为自己死掉?在14:35:26发生vip漂移,从72漂移到123。
Mar 28 14:35:26 bjuc-mysql1 pengine: [14176]: notice: LogActions: Move VIP_192_168_87_74 (Started bjuc-mysql1 -> prod-uc-yewu-db-slave2)
② 为什么会出现死锁
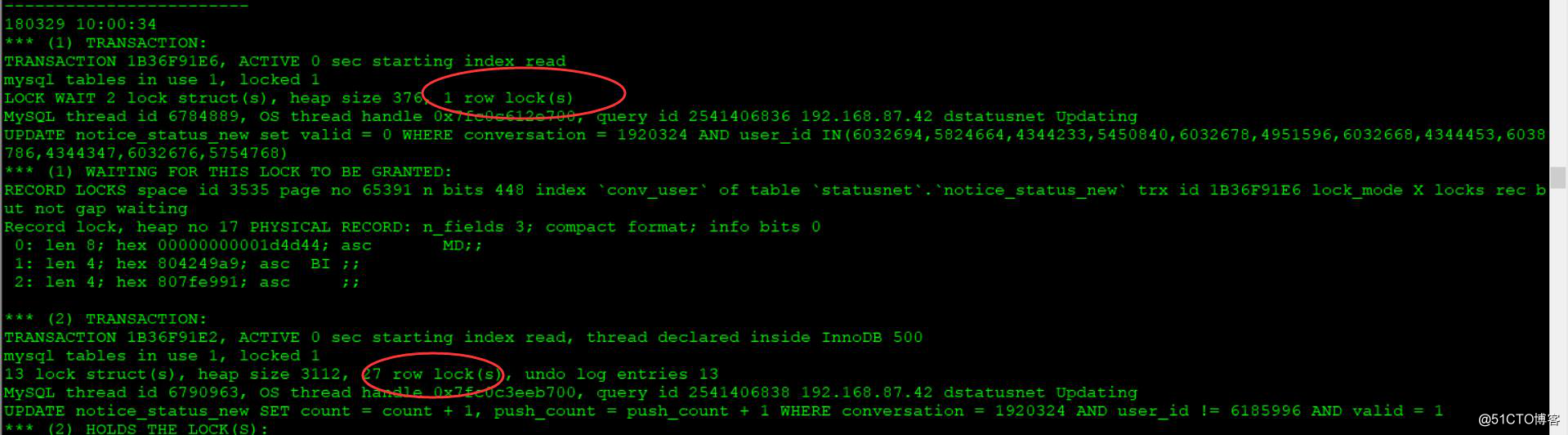
从存储引擎的运行状态中查看,如果这两条SQL的请求同时到达数据库,因为innodb支持到行锁的粒度,第二条SQL会锁住很多行,如果和第一条SQL中锁住有重复的,就会发生相互等待的状况,所以出现死锁。
这两条SQL的where条件如下:
user_id IN(6032694,5824664,4344233,5450840,6032678,4951596,6032668,4344453,6038786,4344347,6032676,5754768);
user_id != 6185996
这两个条件可能发生逻辑上的冲突,然后导致死锁
转自
MySQL主从复制报错 Errno 1205-11774929-51CTO博客 http://blog.51cto.com/11784929/2092097
MySQL主从1205报错【转】相关推荐
- mysql主从同步报错_mysql主从同步报错
主从不同步,经查看发现如下报错 Last_Errno: 1666 Last_Error: Error executing row event: 'Cannot execute statement: ...
- Mysql主从同步报错解决:Fatal error: The slave I/O thread stops because master and slave have equal..
报错信息: 在搭建Mysql主从架构过程中,由于从服务器是克隆的主服务器系统,导致主从Mysql uuid相同, Slave_IO无法启动,报错如下: Last_IO_Error: Fatal ...
- mysql主从同步报错Fatal error: The slave I/O thread stops because master and slave have equal MySQL server
问题:在mysql主从同步的过程中检查主从同步状态时IO线程报错 Last_IO_Error: Fatal error: The slave I/O thread stops because mast ...
- Mysql主从同步报错解决:Error executing row event: Table zabbix.history-uint doesnt exist
报错信息: 因为之前在主数据库服务器上搭建了Zabbix,所以在配置主从时报错. Error executing row event: 'Table 'zabbix.history_uint' d ...
- 【转载保存】Mysql主从同步报错集锦
https://www.cnblogs.com/wangxin37/p/6398755.html
- mysql从节点报错_CentOS7.9 下 MySQL 之 PXC 集群部署【Docker+多机多节点】
背景 最近在进行 MySQL 集群搭建测试的研究中 对于业界主流方案自然不能跳过 在此,整理成完整的文章,希望道友能得到参考价值 - [注]:Percona XtraDB Cluster(简称 PXC ...
- mysql安装教程博音网_RTSP视频平台EasyNVR使用mysql数据源启动报错unknow drivermysql优化...
原标题:RTSP视频平台EasyNVR使用mysql数据源启动报错unknow driver"mysql"优化 我们上一篇讲了TSINGSEE青犀视频开发的视频平台默认都是使用的s ...
- mysql表恢复报错binlog_mysql数据恢复,利用binlog2sql快速闪回
一.环境设置 1.mysql配置中首先要开启binlog,如没开启,在my.conf 下配置如下参数: server-id = 1 log_bin = /var/log/mysql/mysql-bin ...
- mysql source导入报错ERROR 1366的解决方法
mysql source导入报错ERROR 1366的解决方法 参考文章: (1)mysql source导入报错ERROR 1366的解决方法 (2)https://www.cnblogs.com/ ...
- mysql group by 报错 ,only_full_group_by 三种解决方案
mysql group by 报错 ,only_full_group_by 三种解决方案 参考文章: (1)mysql group by 报错 ,only_full_group_by 三种解决方案 ( ...
最新文章
- 进击时代!王雪红的谦卑与坚守
- 1.10 对象序列化控制输入输出
- OpenCASCADE:绘制测试线束之基本命令
- python字符串转字典并获取多层嵌套字典元素
- mysql maxconnections 最大值,MySQL性能优化之max_connections配置参数浅析
- 程序中调用命令行命令,不显示那个黑黑的DOS窗口
- [html] 对一个元素设置浮动后,它的特征是什么?
- Java并发编程实战~软件事务内存
- 互联网晚报 | 11月7日 星期日 | EDG夺得《英雄联盟》S11总冠军;拼多多推出“超拼夜”系列;VMware与戴尔完成分拆...
- 华为云该网站服务器错了,云服务器选错镜像版本
- oracle开发的小技巧(原创)
- 密码生成的思路---电脑mac地址
- SketchUp Pro 2022草图大师27个最常用的快捷键(含PC和Mac)
- ==和 equals 的区别
- 三层交换机内网访问外网
- 【Solr】之使用结巴分词模拟搜索商品1
- 莫队算法(小Z的袜子)
- InCallContrller内部逻辑
- Vue + DataV + SignalR 数字化大屏展示
- 二叉树结构——BTree、BTreeNode