如何总结和整理学术文献
来自知乎:https://www.zhihu.com/question/26901116/answer/39253382
--------------------------------------------------------------------------------------------------------------
个人推荐软件组合:
文献总结整理 :Endnote
文献阅读 :网页版fulltext
做笔记 :Onenote
为什么使用这几个软件?
因为这样最 符合我的需求 。
我们的需求是什么?
1. 阅读文献的时候:
- 排版舒服容易阅读(网页版和pdf都合适)
- 不懂的内容,即时google(网页版较合适)
- 例如,内容中出现:“xxxxx[11]”。我希望马上看看这个参考文献[11]是什么。pdf版太烦了——要拖下去找这个参考文献[11],然后再滚上来,忘了刚刚看到哪了。这点(大部分文献的)网页版就很好,鼠标虚指一下[11]这个链接,参考文献的citation信息就显示出来,再点一下,直接就可以打开这个参考文献的页面(如图)。
- 在内容中highlight关键部分:IE可用imarkup扩展;firefox可用wired-marker(如图)。高亮记录永不丢失,并可搜索。
- 阅读的同时做笔记:onenote可贴到屏幕右边,记录你的总结和火花。如果使用IE,onenote还可以自动记住你是在阅读原文哪一段时做的这一句笔记。
- 所以,我阅读文献采用网页版,笔记采用onenote。

2. 做文献整理的时候:
我对文献整理软件的唯一需求,就是能快速找到想要的那一篇/几篇文献。想找哪篇找哪篇,忘了关键信息也能找到,模糊检索也能找到。想象以下场景:
- 我想找那篇之前读过的(标记已读/未读功能);
- 2005年发表的(排序功能);
- 分组在"Crystallography"组的(分组功能);
- 曾被我标记了"mTOR"标签的(标签功能);
- 忘了是题目还是内容中含有"pET28a"的(全文内搜索功能)
- 的文献
满足所有这些功能的,我知道的只有Endnote和Mendeley (可能还有别的软件)。我选择了Endnote。另外,把Endnote文件放在OneDrive/Dropbox等文件夹里,还可实现同步。
综上所述,我的选择是网页版阅读+Onenote笔记+Endnote整理。
--------------------------------------------------------------------------------------------------------------
我认为整理文献的主要目的就是:能够在任何条件下,快速找到所需信息。任何好用的软件,都不如大批量多批次的文献阅读。
我的思路是:轻整理,重搜索。轻整理,是指不对文献分类,或者只是对文献简单分类。重搜索,是指利用不同的搜索工具,快速定位到我需要的文献。我认为在现在搜索技术已经很强大的情况下,如果利用笔记等手段整理,反而容易造成条条框框,在对于一篇文献关注太长的时间,不利于提高效率。在日常使用中, 除了在文献PDF上直接标注,我很少用其他的软件去记录我看过的文献。因为除了文献本身,其他还有什么载体能够那么直接方便地记录呢?所以整理文献问题就成了:如何快速找出那篇有我笔记的PDF文献。以此为目的,我建立了一套以文献PDF云同步为基础,辅以大量搜索工具的文献整理方案。
其实做过科研工作的人都会发现,其实真正需要把一篇文献从头到尾读完的情况是很少的。在大多数情况下,我们需要的其实是大批量多轮次地阅读文献,因为在一个项目的不同阶段,哪怕是同一篇文献,所关注的点也是不一样的。如果在项目初期,就对所有的文献,都投入同样的时间,阅读同样的深度,势必会浪费大量时间和做无用功。我曾经也走过文献整理的弯路,每阅读一篇文献,都会在Onenote上建立一个条目,按照文献题目,创新点,实验过程,个人感想等分别填空。但是文献读的多了之后,这个方法我觉得效率不高,用的频率也越来越少了。
我现在的主要方法是:以Mendeley建立电子文献索引为主,并以云端同步PDF文献为主要储存手段,通过Everything,Google Scholar,桌面搜索软件,Onenote笔记等多种搜索手段,快速找到自己所要的信息。
==================干货开始=====================
**重搜索部分**
在新项目(写一篇综述,开始一个新课题或者完成一份大作业)开始之前,我会在Mendeley中根据不同项目,建立一个新文件夹。
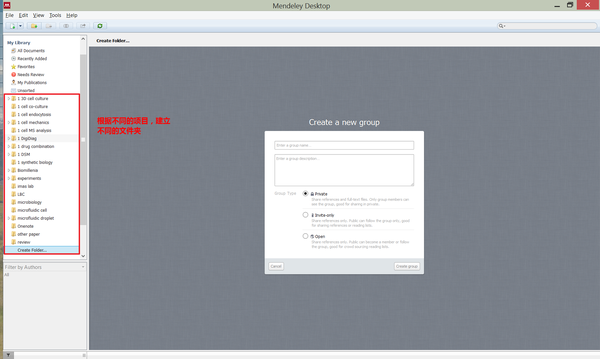
一个项目刚开始的时候,文件夹中没有文献,就需要先建立一份本地的文献原始积累。我习惯在Web of Science上根据关键词去找所需要的文献。
比如我现在想看一下微流控单细胞测序(microfluidic single cell sequencing)最近的进展时,就去WoS搜:
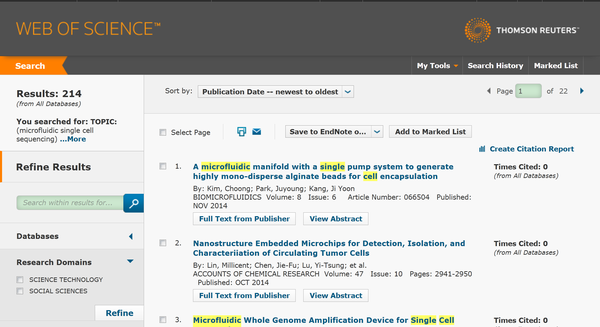 总共有214篇文献。我会把214篇文献的题目先全部浏览一遍,其中大概100篇需要下载看一下PDF。最后我会剩下大概50篇左右PDF,拖进Mendeley,建立原始的文献积累。Mendeley会自动提取文献信息,按照文献的发表年份,期刊,和文章题目将文献重命名,并将该文献自动整理到指定文件夹中,完成文献的原始积累。
总共有214篇文献。我会把214篇文献的题目先全部浏览一遍,其中大概100篇需要下载看一下PDF。最后我会剩下大概50篇左右PDF,拖进Mendeley,建立原始的文献积累。Mendeley会自动提取文献信息,按照文献的发表年份,期刊,和文章题目将文献重命名,并将该文献自动整理到指定文件夹中,完成文献的原始积累。
其他回答中提到了用Endnote。我用Mendeley而不是Endnote做文献索引,主要是因为:Mendeley是我用过所有的文献整理软件中,提取文章题目,发表年份和期刊等信息最准确和方便的软件。看到一篇有意思的文章,我只需要往Mendeley中一拖,它就会帮我自动提取文献信息建立条目,并将文件拷贝到指定文件夹中。其他的软件,要么是提取文献条目的准确度不高,要么就是建立文献条目非常麻烦,需要花大量的时间去建立条目,大大降低文献阅读效率。
我又将这个Mendeley的文件夹中所有文献用dropbox同步。之后我要看文献时,只从这个文件夹中打开文献。这样做的好处就是,把所有的文献和笔记信息全部集中化了,不会造成信息碎片。
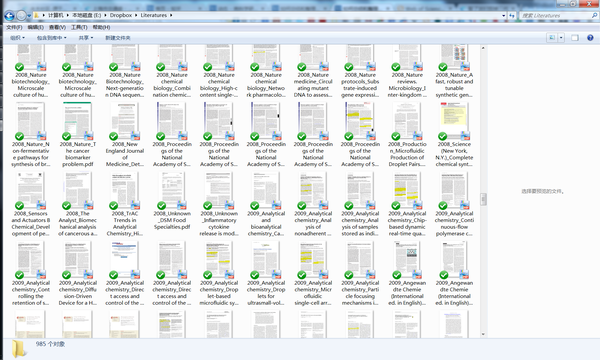
做笔记我也只在PDF上做,这样就不用另外开一个软件写笔记,并可以对自己感兴趣的信息直接标注,实现信息最大程度集中化。哪怕打印了纸版的文献,我在看完后也会把纸版上的笔记全部在PDF上标注,避免信息碎片化。

我看一篇文献,除了一些世界上的顶尖超级大牛,一般记不住作者的名字,但是我一般会对文章发表年份和所在期刊有很深的印象。而且一般题目又提供了文章中最主要的信息。所以我设置Mendeley自动根据文献的三个强信息:发表年,发表期刊,和文章题目自动重命名,并结合everything,在本地实现文献的第一重搜索。
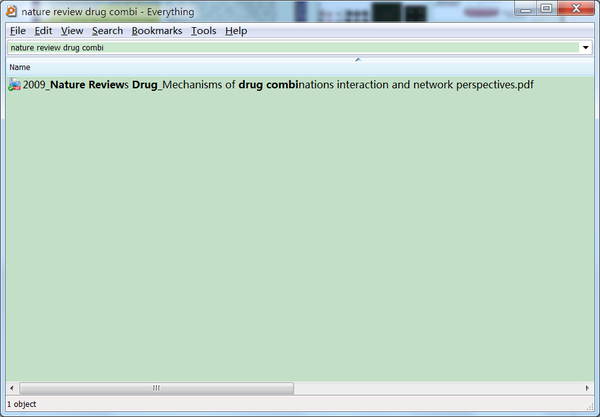
如果搜索目标很明确,比如我现在想找一篇之前在Nature Drug Review上看过的关于drug combination的文章,由于关键词很明确,用Everything直接就从本地找到了,耗时不超过3秒。
如果搜索目标不那么明确,比如题主说的,“总感觉有些文献读过就忘记了,想用的时候想不起来”;或者找找一些特定的问题,不确定本地文献有没有。这个时候我一般会把所有能想到的关键词输入,上Google Scholar搜索。
这个时候,可能会找到一些文献在本地是有的,那就可以根据文献名,用Everything快速在本地找到对应的文献。
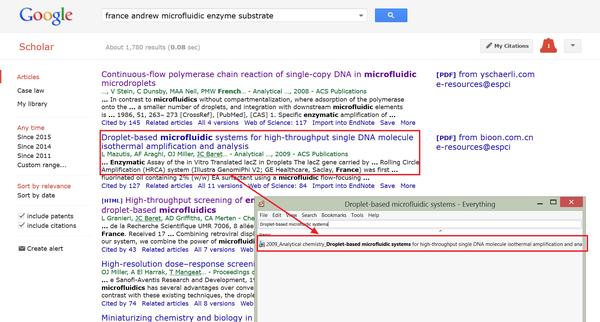 如果一些文献本地没有,那就直接下载PDF,阅读后在Mendeley建立本地索引。
如果一些文献本地没有,那就直接下载PDF,阅读后在Mendeley建立本地索引。
如果想要搜索特定一句话,或者在写文章的时候想对一些说法进行佐证,就可以用Mendeley的搜索工具,
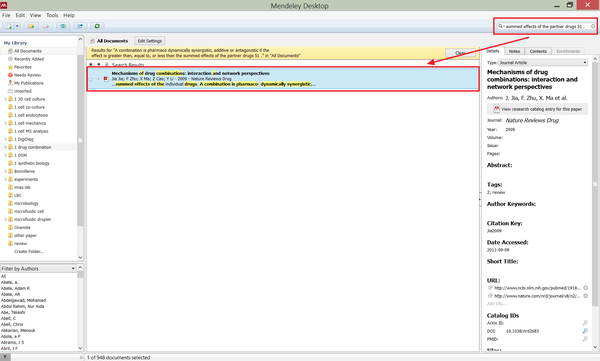 或者还是上Google Scholar。。。
或者还是上Google Scholar。。。
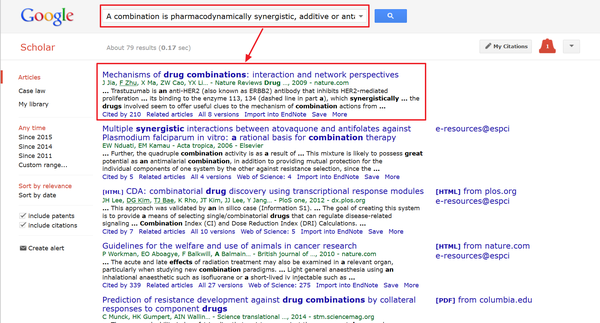
**轻整理部分**
之后随着时间的流逝,一个文件夹下的文献慢慢变多,这个时候就需要在Mendeley中建立子文件夹了(对于我来说,每个项目中前前后后需要阅读的文献大概在300篇左右),也就是传统意义上的整理。但是我不赞成把文献归类做的过细。对一个项目下简单分类,使每个子文件夹中的文献大概不超过50篇,再通过发表年份,期刊名,作者名等信息,也可以很容易找到所需的文章了。
但是我现在不会等文献很多了之后再去建立子文件夹,而是会在平时读文献的时候,根据一个项目下的不同问题,建立一些小的分类。在Mendeley中,同一篇文献是可以归属不同的文件夹的,所以在归文件夹的时候也不用那么纠结。
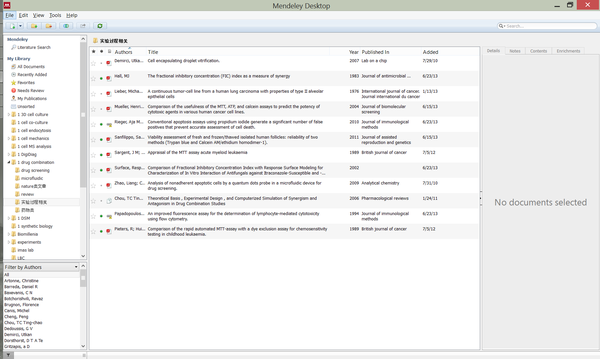
最后,我想说的是,任何文献整理软件都不能代替人对文献的阅读,任何时候读文献中信息永远是第一位的。整理软件只能够帮助更加快速地找到所需的信息而已。
以上。
--------------------------------------------------------------------------------------------------------------
在我看来,当搜集的文献多的时候,再牛逼的分类\分组方法也失去了最初期待的功能,这是因为每一个「分类」下面都会有很多文章,其实这种情况下根本没有办法通过「分类\分组」清晰的提取进一步的信息。
与其给 PDF 分类,真不如读完文章之后好好整理「读后的 notes」,以后需要什么内容就直接在 notes 里面搜索。notes 记在印象笔记里面就行(虽然印象笔记的搜索功能还处在初级的关键字匹配阶段,但还算够用)。
首先和大家说,我读的是 Computer Science 相关的文献, 不是很清楚其他专业的文献是否可以用同样的方法来整理 notes。不过工科\理科专业应该差不多的。OK,现在开始。
*** 1. 需要在 notes 里面清楚的标注文章的 title,作者信息,和会议信息 ***
那么问题来了,应该用什么样的格式来放置这些数据呢?
在这一步推荐使用 dblp(http://dblp.uni-trier.de/),但 dblp 本身并不支持按照文章 title 搜索,所以我们在这里取一个巧,用 Google 里面的「关键字+site:[domain]」功能间接的在 dblp 中按文章 title 搜索。
(如果是非 CS 专业的,也可以通过类似的方法借助 Google 来间接搜索索引类网站,因为这种方法受网站自身内容影响,效果不一定特别好。
注:复制下来的文章标题一定要全+规范,可以提高未来搜索 note 内容时的准确性。)
例如,我们要读一篇名为“eBay in the Sky: Strategy-Proof Wireless Spectrum Auctions”的文献,我们就在 Google 中输入
"eBay in the Sky: Strategy-Proof Wireless Spectrum Auctions site: http://www.informatik.uni-trier.de"
进行搜索。我们点击第一个链接便可以看到如下页面,
 然后我们直接复制红框当中的内容到印象笔记就OK。这样一来我们便有了 准确+规范化 的「文章题目,文章作者,以及文章所在会议」
然后我们直接复制红框当中的内容到印象笔记就OK。这样一来我们便有了 准确+规范化 的「文章题目,文章作者,以及文章所在会议」
*** 2. 总结文章内容 ***
记录好了文章的基本信息,下一步便是阅读文章。
目前(2015年04月),我通过问自己以下几个问题来保证“阅读过程当中思路不跑偏”:
1. What is the problem?
2. Why is the problem interesting?
3. Why is the problem unsolved?
4. What is the authors' idea?
可能有时候会认为:“一篇还比较重要的文章,我就从头到尾一点一点去看,然后看完第一段看第二段,直至看完”。
但其实这样的做法是有点问题的,因为很可能读到中间还不知道这篇文章到底在讲什么。这样就很“致命”。
“致命”是因为,在没有掌握文章的基本逻辑的时候,就 很难分辨出什么部分是重点,什么部分不是重点 。虽然说文章内容都有其意义,但是意义的重要程度却不尽相同。所以推荐先使用上面四个问题来理顺文章框架,然后再针对感兴趣的内容仔细研读文章。
[精力有限,慢慢一点点的分享给大家喽]
如果大家觉得我写的对整理文献有一点启发,欢迎点赞!等我有空会持续更新 :)
如何总结和整理学术文献相关推荐
- 致正煎熬的科研人:一个工具让你快速“KO”学术文献!
最近在后台多次收到做大数据科研领域同学的留言: "面对浩如烟海的学习资料和科研文献,了解科学前沿背景,总是没日没夜的搜集整理,但效果甚微呀?" "怎么控制实验仪器的敏感度 ...
- 如何免费下载学术文献?
程序员宝藏库:GitHub - Jackpopc/CS-Books-Store: 你想要的计算机经典书籍,这里都有! 如何免费下载学术文献? 如何摆脱百度搜索差劲的体验? 如何解决Chrome内存占用 ...
- 搜索推荐系统[10]项目实战系列Z1:手把手教学(商品搜索系统、学术文献检索)语义检索系统搭建、召回排序模型详解。
搜索推荐系统专栏简介:搜索推荐全流程讲解(召回粗排精排重排混排).系统架构.常见问题.算法项目实战总结.技术细节以及项目实战(含码源) 专栏详细介绍:搜索推荐系统专栏简介:搜索推荐全流程讲解(召回粗排 ...
- 免费下载学术文献的网站,好用!
推荐几款好用的免费下载学术文献网站,让你的查找文献环节更加事半功倍! 1.Open Access Library(OALib)图书馆让学者可以免费下载学术文献和论文,并在这个平台上发表自己的论文.提供 ...
- 关于学术文献推荐系统的调研报告
关于学术文献推荐系统的调研报告 1 引言 1.1 研究背景 随着大数据时代的到来,互联网在给人们的生活带来丰富多彩的同时,海量信息也导致了"信息过载"问题.对于信息使用者来说,如何 ...
- 论文必备-五大学术文献资料推荐网站+免费下载知网、万方的论文资料
五大学术文献资料推荐网站 国家哲学社会科学文献中心 http://www.ncpssd.org 提供免费下载,提供各类哲学社会科学文献. 搜索功能强大,提供分类搜索.提名/关键词等搜索,也可以输入关键 ...
- 如何阅读计算机学术文献?
阅读学术文献是每个科研工作者必须掌握的技能,但在学校中我们很少被教授如何正确的阅读学术文献.这里,易智编译分享5步阅读法帮你有效阅读科技文献. 虽然在进入大学时,我们已经阅读了大量的书籍.杂志.报纸. ...
- 自研·学术·文献查找
常用网站 Web of science 谷粉学术 Sci-hub Web of science和谷粉学术主要用来查找文献,Sci-hub主要用来下载文献. Web of science的使用 这里主要 ...
- 关系抽取论文整理——早期文献
说明 本文是个人阅读文章的笔记整理,没有涉及到深度学习在关系抽取中的应用. 笔记中一部分来自个人解读,一部分来自原文,一部分来自网上摘录.[由于文章是分开做笔记,很多参考链接没有及时保留,还请谅解.如 ...
最新文章
- 银行的清算、清分、结算、对账
- LINUX设备驱动之设备模型一--kobject
- 如何在 Linux 中使用 find
- google四件套之Dagger2
- CF1458C Latin Square
- 安卓逆向_3 --- 篡改apk名称和图标、修改包名实现应用分身、修改资源去广告、去除re管理器广告
- Serverless 服务选型
- python反向迭代器_Python中对象迭代与反迭代的技巧总结
- 阿里达摩院420集python_阿里达摩院推荐的420集的python教程,入门到精通简直不要太简单...
- linux中demo当前目录,Linux pwd命令:显示当前路径
- linux视频补帧,SVP补帧软件最新版-SVP补帧软件免费版-QQ下载站
- IDEA插件系列(100):CPU Usage Indicator插件——显示CPU使用情况
- Saliency Detection: A Spectral Residual Approach
- C++ 打印表格到屏幕或文件
- Anima Toon:体素角色动画软件
- 如何批量添加图片到ppt的方法
- 毕业论文开题报告怎么写
- video视频多个循环播放
- Microsoft Windows CredSSP 远程执行代码漏洞CVE-2018-0886
- 实用至上,推荐五款非常实用的软件