【机器学习】集成学习ensemble之随机森林
Bootstrapping
Bootstrapping从字面意思翻译是拔靴法,从其内容翻译又叫自助法,是一种再抽样的统计方法。自助法的名称来源于英文短语“to pull oneself up by one’s bootstrap”,表示完成一件不能自然完成的事情。1977年美国Standford大学统计学教授Efron提出了一种新的增广样本的统计方法,就是Bootstrap方法,为解决小子样试验评估问题提供了很好的思路。
算法流程
- 从N个样本中有放回的随机抽取n个样本。
- 用n个样本计算统计量
- 重复1,2步骤m次,得到统计量
- 计算统计量
序列的方差,则可得到统计量
Bagging策略(bootstrap aggregating)套袋法
- 从N个样本中有放回的随机抽取n个样本。
- 用这n个样本的所有属性构建基分类器(LR,ID3,C4.5,SVM)
- 重复1,2两步m次,构建m个基分类器
- 投票得出分类结果,哪个票最多就是哪一类。对回归模型,取多有基分类器结果的均值。总而言之就是所有基分类器的权重相同。
![]()
随机森林
bagging方法可以有效降低模型的方差。随机森林每棵子树不需要剪枝,是低偏差高方差的模型,通过bagging降低方差后使得整个模型有较高的性能。
随机森林其实很简单,就是在bagging策略上略微改动了一下。
- 从N个样本中有放回的随机抽样n个样本。
- 如果每个样本的特征维度为M,指定一个常数m<<M,随机地从M个特征中选取m个特征子集,每次树(ID3,C4.5,CART)进行分裂时,从这m个特征中选择最优的(信息增益,信息增益比率,基尼系数);
- 每棵树都尽最大程度的生长,并且没有剪枝过程。
- 最后采用投票表决的方式进行分类。
特征m个数的选取:
用作分类时,m默认取,最小取1.
用作回归时,m默认取M/3,最小取5.
两个随机性的引入对随机森林的分类性能至关重要。由于它们的引入,使得随机森林不容易陷入过拟合,并且具有很好得抗噪能力(比如:对缺省值不敏感)。
随机森林分类效果(错误率)与两个因素有关:
- 森林中任意两棵树的相关性:相关性越大,错误率越大;
- 森林中每棵树的分类能力:每棵树的分类能力越强,整个森林的错误率越低。
减小特征选择个数m,树的相关性和分类能力也会相应的降低;增大m,两者也会随之增大。所以关键问题是如何选择最优的m(或者是范围),这也是随机森林唯一的一个参数。
OOB(Out Of Bag)袋外错误率
在bootstrapping的过程中,有些数据可能没有被选择,这些数据称为out-of-bag(OOB) examples。
![]()
解释一下上面这张图。一眼看还是挺难理解的,用白话讲一下。
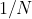 是什么?
是什么?
随机森林中每一次样本抽样(不是特征抽样),就是bootstrapping方法,是有放回的随机抽样,所以每一次抽的时候,对于一个特定的样本,抽到它的概率就是
,很好理解,N个样本里随机抽取一个,抽到的概率当然是
,因为是有放回的抽样,所以分母永远是N。
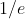 是什么?
是什么?
既然被抽到的概率是
,那不被抽到的概率就是
,很好理解。那指数大N又是什么呢?其实就是抽样的次数。假设我们的随机森林一共有A颗树,每棵树抽了B个样本,那么指数大N就是
,是不是感觉指数大N应该和分母的那个N一样?其实这里只是为了方便,它表达的意思就是抽了很多次。
搞明白了那个公式之后,就可以开始计算了。要用到数学分析中的极限知识。一步步推一下。
这是基本公式: 后面的都是基于这个变形
这说明了什么呢?就是你随机森林已经造好了,但是即使你的训练集是整个样本集,其中也会有的样本你抽不到。为什么抽不到,上面的公式就是告诉你为什么抽不到。这些抽不到的样本就叫做out-of-bag(OOB) examples
好了,到这里已经能搞懂什么是out-of-bag(OOB) examples了。那这些样本能用来做什么呢?下面就介绍oob袋外错误率。
袋外错误率的应用
正常情况下,我们训练一个模型,怎么验证它好不好。是不是要拿出一部分的数据集当作验证集,更好的还要拿出一部分当作测试集,一般是6:2:2。
在随机森林中,有了out-of-bag(OOB) examples,我们就不需要拿出一部分数据了,out-of-bag(OOB) examples就是那部分没有用到的数据,我们可以直接当成验证集来使用。
obb error = 被分类错误数 / 总数
随机森林算法中不需要再进行交叉验证或者单独的测试集来获取测试集误差的无偏估计。
Breiman [1996b]在对 bagged 分类器的错误率估计研究中, 给出实证证据显示,out-of-bag 估计 和使用与训练集大小一致的测试集所得到的错误率一样精确. 所以, 使用out-of-bag error 估计可以不在另外建立一个测试集.
特征重要性度量
计算某个特征X的重要性时,具体步骤如下:
对整个随机森林,得到相应的袋外数据(out of bag,OOB)计算袋外数据误差,记为errOOB1.
所谓袋外数据是指,每次建立决策树时,通过重复抽样得到一个数据用于训练决策树,这时还有大约1/3的数据没有被利用,没有参与决策树的建立。这部分数据可以用于对决策树的性能进行评估,计算模型的预测错误率,称为袋外数据误差。
这已经经过证明是无偏估计的,所以在随机森林算法中不需要再进行交叉验证或者单独的测试集来获取测试集误差的无偏估计。
随机对袋外数据OOB所有样本的特征X加入噪声干扰(可以随机改变样本在特征X处的值),再次计算袋外数据误差,记为errOOB2。
- 假设森林中有N棵树,则特征X的重要性=(∑errOOB2−errOOB1)/N。这个数值之所以能够说明特征的重要性是因为,如果加入随机噪声后,袋外数据准确率大幅度下降(即errOOB2上升),说明这个特征对于样本的预测结果有很大影响,进而说明重要程度比较高。
特征选择
在特征重要性的基础上,特征选择的步骤如下:
- 计算每个特征的重要性,并按降序排序
- 确定要剔除的比例,依据特征重要性剔除相应比例的特征,得到一个新的特征集
- 用新的特征集重复上述过程,直到剩下m个特征(m为提前设定的值)。
- 根据上述过程中得到的各个特征集和特征集对应的袋外误差率,选择袋外误差率最低的特征集。
优点
- 在数据集上表现良好
- 在当前的很多数据集上,相对其他算法有着很大的优势
- 它能够处理很高维度(feature很多)的数据,并且不用做特征选择
- 在训练完后,它能够给出哪些feature比较重要
- 在创建随机森林的时候,对generlization error使用的是无偏估计
- 训练速度快
- 在训练过程中,能够检测到feature间的互相影响
- 容易做成并行化方法
- 实现比较简单
- 可以得到变量重要性排序(两种:基于OOB误分率的增加量和基于分裂时的GINI下降量)
随机森林有许多优点:
- 具有极高的准确率
- 随机性的引入,使得随机森林不容易过拟合
- 随机性的引入,使得随机森林有很好的抗噪声能力
- 能处理很高维度的数据,并且不用做特征选择
- 既能处理离散型数据,也能处理连续型数据,数据集无需规范化
- 训练速度快,可以得到变量重要性排序
- 容易实现并行化
随机森林的缺点:
- 当随机森林中的决策树个数很多时,训练时需要的空间和时间会较大
- 随机森林模型还有许多不好解释的地方,有点算个黑盒模型
【机器学习】集成学习ensemble之随机森林相关推荐
- 【进阶版】机器学习之集成学习介绍、随机森林模型经验贴(12)
目录 欢迎订阅本专栏,持续更新中~ 本专栏前期文章介绍! 机器学习配套资源推送 进阶版机器学习文章更新~ 点击下方下载高清版学习知识图册 集成学习 个体与集成 Boosting Bagging与Ran ...
- 集成学习中的随机森林
摘要:随机森林是集成算法最前沿的代表之一.随机森林是Bagging的升级,它和Bagging的主要区别在于引入了随机特征选择. 本文分享自华为云社区<集成学习中的随机森林>,原文作者:ch ...
- 集成学习——BAGGING和随机森林
集成学习--BAGGING和随机森林 集成学习--BAGGING和随机森林 1.什么是集成学习 2.怎样进行集成学习 3.Bagging方法 4.Bagging方法训练.预测过程 5.Bagging方 ...
- 机器学习-集成学习(ensemble learning)
集成学习ensemble learning:本身不是一个单独的机器学习算法,而是通过构建并结合多个机器学习器来完成学习任务. 可以用两句话形容: 1."三个臭皮匠顶个诸葛亮":一堆 ...
- 集成学习(Ensemble Learning)
在机器学习的有监督学习算法中,我们的目标是学习出一个稳定的且在各个方面表现都较好的模型,但实际情况往往不这么理想,有时我们只能得到多个有偏好的模型(弱监督模型,在某些方面表现的比较好).集成学习就是组 ...
- EL:集成学习(Ensemble Learning)的概念讲解、问题应用、算法分类、关键步骤、代码实现等相关配图详细攻略
EL:集成学习(Ensemble Learning)的概念讲解.算法分类.问题应用.关键步骤.代码实现等相关配图详细攻略 目录 集成学习Ensemble Learning 1.集成学习中弱分类器选择 ...
- 集成学习(ensemble learning)(一)
文章目录 一.集成学习概述 二.个体学习器 三.Boosting 四.Bagging 五.结合策略 1.平均法 2.投票法 3.学习法 (1)核心图解 a.构建新的训练集 b.构建新的测试集 c.最终 ...
- 笔记︱集成学习Ensemble Learning与树模型、Bagging 和 Boosting、模型融合
基本内容与分类见上述思维导图. 文章目录 一.模型融合方法 . 概述 1.Voting 2.Averaging 3.Bagging 4.Boosting 5. Stacking (1)nfolds 次 ...
- 集成学习(ensemble learning)干货系列(3)——Boosting方法详解
集成学习(ensemble learning)干货系列(1)--集成学习概述 集成学习(ensemble learning)干货系列(2)--随机森林(Bagging) Boosting基本原理 提升 ...
最新文章
- 云计算的未来,就是“打车模式” | CCF C³@亚马逊云科技
- golang post get 请求 简介
- Window下Pothos SDR开发环境搭建(limeSDR)
- ZOJ3370. Radio Waves(2-sat)
- Java100例题(一)
- 为什么公司的HR这么牛掰
- 访问控制管理的积极意义案例
- Android多开和虚拟化--Docker概念的详细介绍
- 加拿大大数据:正在升温的大数据市场
- C/C++判断是否为笔记本电脑
- Stone Game, Why are you always there? HDU - 2999(sg定理)
- server 2008 mysql 报错 0xc000007b_这十个MySQL经典错误,99%的程序员一定遇到过!你呢?...
- 公司部分断电,这些人就没法干活?
- ubuntu20 scrt 连接ssh报错的解决方法
- arcgis两点之间连线_three3D地图设置两点之间的连线
- 自己用命令强制删除占用的文件或文件夹
- Quality-Estimation2 (翻译质量评价-在BERT模型后面加上Bi-LSTM进行fine-tuning)
- 深度学习(七)——图像验证码破解(数字加减验证码)
- 程旭/王蒙岑/袁梦婷/李建刚/熊武客座主编Frontiers根际微生物组专刊征稿(IF6)
- [网络广播] SQL Server 主数据管理结合 BizTalk Server SOA 架构实现保险行业 ECIF 解决方案