python模型训练框架_使用TensorFlow框架基于SSD算法训练模型
内容引用其它文章:https://my.oschina.net/u/876354/blog/1927351
目标检测是AI的一项重要应用,通过目标检测模型能在图像中把人、动物、汽车、飞机等目标物体检测出来,甚至还能将物体的轮廓描绘出来,就像下面这张图。

在动手训练自己的目标检测模型之前,建议先了解一下目标检测模型的原理(见文章:大话目标检测经典模型RCNN、Fast RCNN、Faster RCNN,以及Mark R-CNN),这样才会更加清楚模型的训练过程。
本文将在我们前面搭建好的AI实战基础环境上(见文章:AI基础环境搭建),基于SSD算法,介绍如何使用自己的数据训练目标检测模型。SSD,全称Single Shot MultiBox Detector(单镜头多盒检测器),是Wei Liu在ECCV 2016上提出的一种目标检测算法,是目前流行的主要检测框架之一。
本案例要做的识别便是在图像中识别出熊猫,可爱吧,呵呵

下面按照以下过程介绍如何使用自己的数据训练目标检测模型:
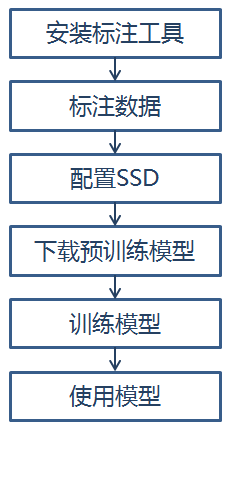
1、安装标注工具
要使用自己的数据来训练模型,首先得先作数据标注,也就是先要告诉机器图像里面有什么物体、物体在位置在哪里,有了这些信息后才能来训练模型。
(1)标注数据文件
目前流行的数据标注文件格式主要有VOC_2007、VOC_2012,该文本格式来源于Pascal VOC标准数据集,这是衡量图像分类识别能力的重要基准之一。本文采用VOC_2007数据格式文件,以xml格式存储,如下:
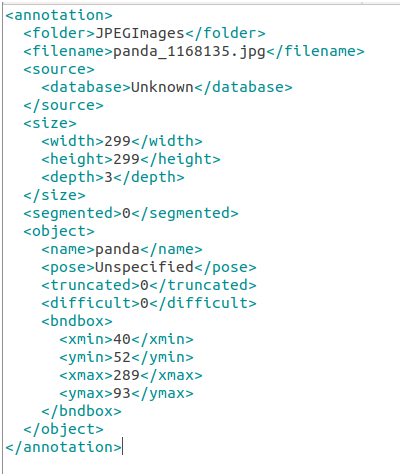
其中重要的信息有:
filename:图片的文件名
name:标注的物体名称
xmin、ymin、xmax、ymax:物体位置的左上角、右下角坐标
(2)安装标注工具
如果要标注的图像有很多,那就需要一张一张手动去计算位置信息,制作xml文件,这样的效率就太低了。
所幸,有一位大神开源了一个数据标注工具labelImg,可以通过可视化的操作界面进行画框标注,就能自动生成VOC格式的xml文件了。该工具是基于Python语言编写的,这样就支持在Windows、Linux的跨平台运行,实在是良心之作啊。安装方式如下:
a. 下载源代码
通过访问labelImg的github页面(https://github.com/tzutalin/labelImg),下载源代码。可通过git进行clone,也可以直接下载成zip压缩格式的文件。
在本案例中直接下载成zip文件。
b.安装编译
解压labelImg的zip文件,得到LabelImg-master文件夹。
labelImg的界面是使用PyQt编写的,由于我们搭建的基础环境使用了最新版本的anaconda已经自带了PyQt5,在python3的环境下,只需再安装lxml即可,进入LabelImg-master目录进行编译,代码如下:
#激活虚拟环境
source activate tensorflow
#在python3环境中安装PyQt5(anaconda已自带),如果是在python2环境下,则要安装PyQt4,PyQt4的安装方式如下
#conda install -c anaconda pyqt=4.11.4
#安装xml
conda install xml
#编译
make qt5py3
#打开标注工具
python3 labelImg.py
成功打开labelImg标注工具的界面如下:
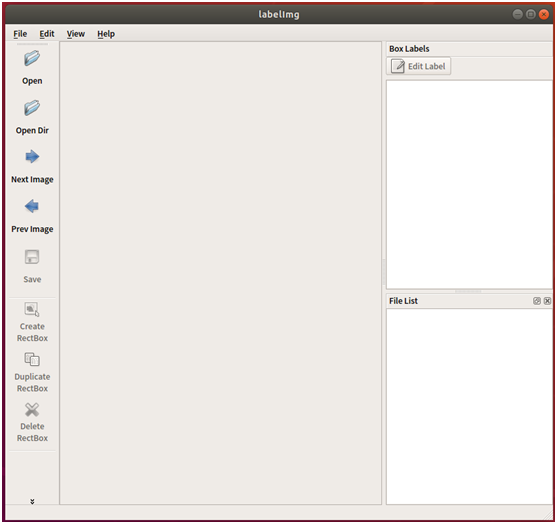
2、标注数据
成功安装了标注工具后,现在就来开始标注数据了。
(1)创建文件夹
按照VOC数据集的要求,创建以下文件夹
Annotations:用于存放标注后的xml文件
ImageSets/Main:用于存放训练集、测试集、验收集的文件列表
JPEGImages:用于存放原始图像
(2)标注数据
将熊猫图片集放在JPEGImages文件夹里面(熊猫的美照请找度娘要哦~),注意图片的格式必须是jpg格式的。
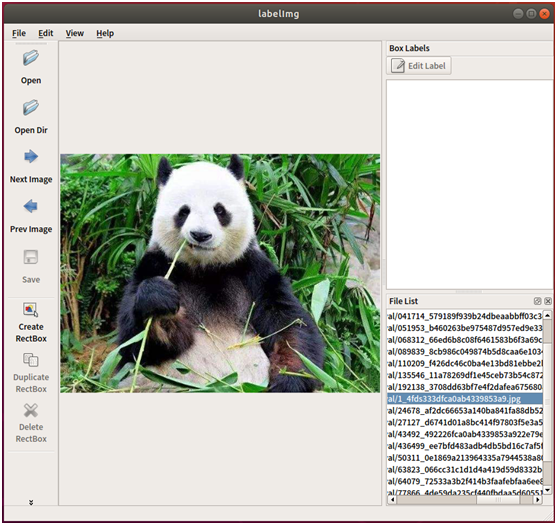
打开labelImg标注工具,然后点击左侧的工具栏“Open Dir”按钮,选择刚才放熊猫的JPEGImages文件夹。这时,主界面将会自动加载第一张熊猫照片。
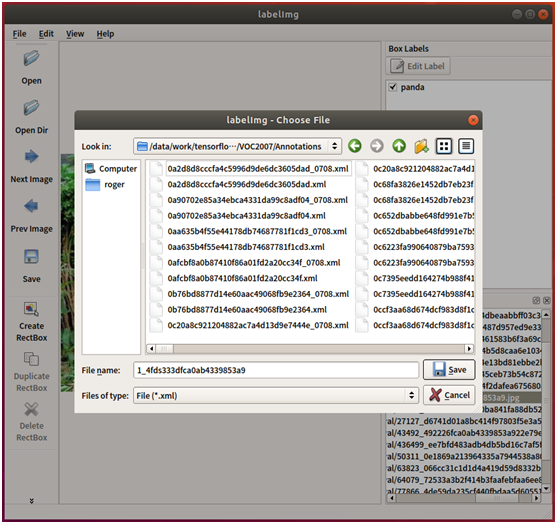
点击左侧工具栏的“Create RectBox”按钮,然后在主界面上点击拉个矩形框,将熊猫圈出来。圈定后,将会弹出一个对话框,用于输入标注物体的名称,输入panda作为熊猫的名称。

然后点击左侧工具栏的“Save”按钮,选择刚才创建的Annotations作为保存目录,系统将自动生成voc_2007格式的xml文件保存起来。这样就完成了一张熊猫照片的物体标注了。
接下来点击左侧工具栏的“Next Image”进入下一张图像,按照以上步骤,画框、输入名称、保存,如此反复,直到把所有照片都标注好,保存起来。
(3)划分训练集、测试集、验证集
完成所有熊猫照片的标注后,还要将数据集划分下训练集、测试集和验证集。
在github上下载一个自动划分的脚本(https://github.com/EddyGao/make_VOC2007/blob/master/make_main_txt.py)
然后执行以下代码
python make_main_txt.py
将会按照脚本里面设置的比例,自动拆分训练集、测试集和验证集,将相应的文件名列表保存在里面。
3、配置SSD
(1)下载SSD代码
由于本案例是基于tensorflow的,因此,在github上下载一个基于tensorflow的SSD,地址是 https://github.com/balancap/SSD-Tensorflow
以zip文件的方式下载下来,然后解压,得到SSD-Tensorflow-master文件夹
(2)转换文件格式
将voc_2007格式的文件转换为tfrecord格式,tfrecord数据文件tensorflow中的一种将图像数据和标签统一存储的二进制文件,能更加快速地在tensorflow中复制、移动、读取和存储等。
SSD-Tensorflow-master提供了转换格式的脚本,转换代码如下:
DATASET_DIR=./panda_voc2007/ # 自己创建的文件夹./VOC2007
OUTPUT_DIR=./panda_tfrecord/ # 希望放到某个位置./tfrecord/
以上两种参数在代码中可以设定默认值
python SSD-Tensorflow-master/tf_convert_data.py --dataset_name=pascalvoc --dataset_dir=${DATASET_DIR} --output_name=voc_2007_train --output_dir=${OUTPUT_DIR}
(3)修改物体类别
由于是我们自定义的物体,因此,要修改SSD-Tensorflow-master中关于物体类别的定义,打开SSD-Tensorflow-master/datasets/pascalvoc_common.py文件,进行修改,将VOC_LABELS中的其它无关类别全部删掉,增加panda的名称、ID、类别,如下:
VOC_LABELS = {
'none': (0, 'Background'),
'panda': (1, 'Animal'),
}
4、下载预训练模型
SSD-Tensorflow提供了预训练好的模型,基于VGG模型(要了解VGG模型详情,请阅读文章:大话经典CNN经典模型VGG),如下表:
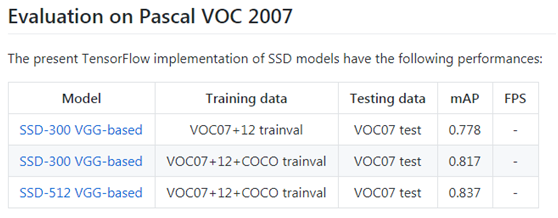
但这些预训练的模型文件都是存储在drive.google.com上,因此,无法直接下载。只能通过“你懂的”方式进行下载,在这里下载SSD-300 VGG-based预训练模型,得到文件:VGG_VOC0712_SSD_300x300_ft_iter_120000.ckpt.zip,然后进行解压
5、训练模型
终于把标注文件、SSD模型都准备好了,现在准备开始来训练了。
在训练模型之前,有个参数要修改下,打开SSD-Tensorflow-master/train_ssd_network.py找到里面的DATA_FORMAT参数项,如果是使用cpu训练则值为NHWC,如果是使用gpu训练则值为NCHW,如下:
DATA_FORMAT = 'NCHW' # gpu
# DATA_FORMAT = 'NHWC' # cpu
现在终于可以开始来训练了,打开终端,切换conda虚拟环境
source activate tensorflow
然后执行以下命令,开始训练
# 使用预训练好的 vgg_ssd_300 模型
DATASET_DIR=./ panda_tfrecord
TRAIN_DIR=./panda_model
CHECKPOINT_PATH=./model_pre_train/VGG_VOC0712_SSD_300x300_ft_iter_120000.ckpt/VGG_VOC0712_SSD_300x300_ft_iter_120000.ckpt
python3 SSD-Tensorflow-master/train_ssd_network.py \
--train_dir=${TRAIN_DIR} \
--dataset_dir=${DATASET_DIR} \
--dataset_name=pascalvoc_2007 \
--dataset_split_name=train \
--model_name=ssd_300_vgg \
--checkpoint_path=${CHECKPOINT_PATH} \
--save_summaries_secs=60 \
--save_interval_secs=600 \
--weight_decay=0.0005 \
--optimizer=adam \
--learning_rate=0.0001 \
--batch_size=16
其中,根据自己电脑的性能情况,设置batch_size的值,值越大表示批量处理的数量越大,对机器性能的要求越高。如果电脑性能普通的,则可以设置为8,甚至4,土豪请忽略。
学习率learning_rate也可以根据实际情况调整,学习率越小则越精确,训练的时间也越长,学习率越大则可缩短训练时间,但就会降低精准度。
在这里使用预训练好的模型,SSD将会锁定VGG模型的一些参数进行训练,这样能在较短的时间内完成训练。
6、使用模型
SSD模型训练好了,现在要来使用了,使用的方式也很简单。
SSD-Tensorflow-master自带了一个notebooks脚本,可通过jupyter直接使用模型。
先安装jupyter,安装方式如下:
conda install jupyter
或
pip install jupyter
然后启动jupyter-notebook,代码如下:
jupyter-notebook SSD-Tensorflow-master/notebooks/ssd_notebook.ipynb
启动后在SSD 300 Model的代码块设置模型的路径和名称
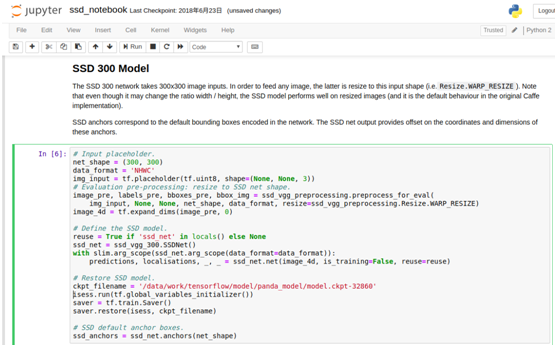
然后在最后的代码块中,设置要测试的图像路径path

然后点击菜单“Cell”,点击子菜单“Run All”,便能按顺序全部执行代码,并显示出结果出来

执行后,可爱的熊猫就被圈出来了

经过以上步骤,我们便使用了自己的数据完成了目标检测模型的训练。只要以后还有物体检测的需求,然后找相关的图片集进行标注,标注后进行模型训练,就能完成一个定制化的目标检测模型了,非常方便,希望本案例对大家能有所帮助。
使用jupyter时遇到的错误:
1. 刚刚进入软件,没有执行任何操作时,右上角红色模块提示error错误,点开后最下边提示pywin32错误。
解决: 降低pywin32版本 pip install pywin32==223
推荐相关阅读
python模型训练框架_使用TensorFlow框架基于SSD算法训练模型相关推荐
- python制作训练集_利用Tensorflow简单实现VGGNet,从数据集制作到训练完成测试
VGGNet_TF 利用Tensorflow简单实现VGGNet,从数据集制作到训练完成测试 参考:<Tensorflow实战><Tensorflow 实战Google深度学习框架& ...
- python模型训练 warm_start_08-06 细分构建机器学习应用程序的流程-训练模型
AI 人工智能 08-06 细分构建机器学习应用程序的流程-训练模型 更新.更全的<机器学习>的更新网站,更有python.go.数据结构与算法.爬虫.人工智能教学等着你:https:// ...
- python模型训练_python模型训练与预测练习
python模型训练与预测练习 发布时间:2018-03-09 17:49, 浏览次数:368 , 标签: python 我是照着YouTube上的机器学习视频做的,视频里讲的比较简洁,下来自己做遇到 ...
- python模型训练框架_深度学习三大框架(对比)
人工智能的浪潮正席卷全球,诸多词汇时刻萦绕在我们的耳边,如人工智能,机器学习,深度学习等."人工智能"的概念早在1956年就被提出,顾名思义用计算机来构造复杂的,拥有与人类智慧同样 ...
- python 分布式计算框架_漫谈分布式计算框架
如果问 mapreduce 和 spark 什么关系,或者说有什么共同属性,你可能会回答他们都是大数据处理引擎.如果问 spark 与 tensorflow 呢,就可能有点迷糊,这俩关注的领域不太一样 ...
- python模型部署方法_终极开箱即用的自动化Python模型选择方法
python模型部署方法 Choosing the best model is a key step after feature selection in any data science proje ...
- python实现胶囊网络_在TensorFlow中实现胶囊网络
点击上方"小白学视觉",选择加"星标"或"置顶" 重磅干货,第一时间送达 我们都知道,在许多计算机视觉任务中,卷积神经网络(CNN)的性能均 ...
- 【毕业设计_课程设计】基于 K-means 算法的校园微博热点话题发现系统(源码+论文)
文章目录 0 前言 1 项目说明 2 开发环境 3 系统架构 4 研究结果 5 论文目录 6 项目工程 0 前言 基于 K-means 算法的校园微博热点话题发现系统 提示:适合用于课程设计或毕业设计 ...
- python模型训练框架_以Python撰写 AI模型框架
以Python撰写 AI模型框架 by 高焕堂 1. 前言: 在AI(人工智慧)方面,由于当今的机器学习本质是一种<大数据相关性支撑的>归纳性推理.软体框架的复用(Reuse)性愈高,对于 ...
最新文章
- 万引大佬自曝这样被MIT拒掉:“系里不喜欢你”,找校长对峙后悟了
- linux内存使用统计,Linux 中free命令检查内存使用情况
- 清明是品茗的好时节,那么你了解quot;明前茶quot;吗?
- Matlab 2022a 安装教程(手把手式教程 超简单)
- 【thymeleaf】模板中定义变量
- LeetCode MySQL 1468. 计算税后工资
- 依赖注入[2]: 基于IoC的设计模式
- python窗体处理access数据库_用Python操作MS Access数据库
- 加速你的企业数字化转型,首先做到这一步!
- PHP上传文件大小限制的问题
- 浅析刚参加工作的大学生的心理态势
- CodeCombat 落地马来西亚巴生中华小学,支持人工智能远程教学
- Python电子书教程汇总
- PSPnet网络结构搭建
- 华为P40手机点位图PCBDOC下载
- excel格式和csv格式的区别(关键差异)
- IBM X系列服务器通过sysmgmt接口查看日志
- 第三周学习总结和心得
- Radware:防御现代鱼叉式网络钓鱼攻击的方法
- 【汇正财经】大盘低开回升