深度学习中用到的几种图像操作
- 视频抽取图片
如何从视频文件中分解出一张张独立的图片?
视频其实就是一张张的图片,利用opencv库可以很容易的从视频文件中抽离出图像文件来,下面我们就看一段示例代码是如何从视频文件中抽取出多张图片的。
例子:
import cv2
cap = cv2.VideoCapture("F:/ai/a_002.mp4")
success, frame = cap.read()
index = 1
while success :index = index+1cv2.imwrite(str(index)+".png",frame)if index > 20:break;success,frame = cap.read()
cap.release()执行完上述代码后我们可以看到视频文件目录下生成了无数的图片文件,如图:
好了,图片抽取出来之后就可以用各种神经网络模型来玩图像识别等应用了。
2、图像处理scipy.ndimage
scipy.ndimage是一个处理多维图像的函数库,它其中又包括以下几个模块:
- filters:图像滤波器。
- fourier:傅立叶变换。
- interpolation:图像的插值、旋转以及仿射变换等。
- measurements:图像相关信息的测量。
- morphology:形态学图像处理。
更强大的图像处理库。
scipy.ndimage只提供了一些基础的图像处理功能,下面是一些更强大的图像处理库:
- OpenCV
- SimpleCV
- scikit-image
- Pillow
3、热点图
首先载入地图图片,并创建一些随机分布的散列点,这些散列点以某些坐标为中心正态分布,构成一些热点。使用numpy.histogram2d()可以在地图图片的网格中统计二维散列点的频度。由于散列点数量较少,histogram2d()的结果并不能形成足够的热点信息:
img = plt.imread("images/china010.png")
h, w, _ = img.shape
xs, ys = [], []
for i in range(100):mean = w*np.random.rand(), h*np.random.rand()a = 50 + np.random.randint(50, 200)b = 50 + np.random.randint(50, 200)c = (a + b)*np.random.normal()*0.2cov = [[a, c], [c, b]]count = 200x, y = np.random.multivariate_normal(mean, cov, size=count).Txs.append(x)ys.append(y)
x = np.concatenate(xs)
y = np.concatenate(ys)hist, _, _ = np.histogram2d(x, y, bins=(np.arange(0, w), np.arange(0, h)))
hist = hist.T
plt.imshow(hist);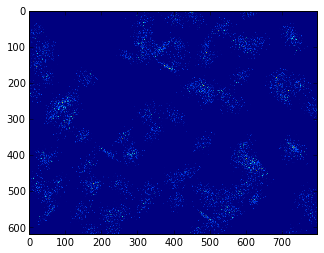
调用scipy.ndimage.filters.gaussian_filter对频度图进行高斯模糊处理,则相当与在上图中每个亮点处描绘一个高斯曲面,让每个亮点增加其周围的像素的亮度。其第二个参数为高斯曲面的宽度,即高斯分布的标准差。这个值越大,曲面的影响范围越大,最终的热点图也越平滑。
from scipy.ndimage import filtersheat = filters.gaussian_filter(hist, 10.0)plt.imshow(heat);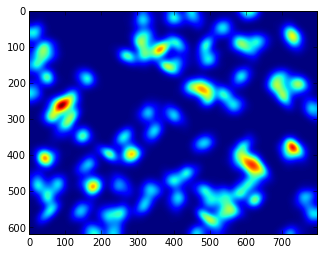
下面通过修改热点图的alpha通道,将热点图与地图叠加显示。
4、高斯滤波
高斯滤波在图像处理概念下,将图像频域处理和时域处理相联系,作为低通滤波器使用,可以将低频能量(比如噪声)滤去,起到图像平滑作用。
高斯滤波是一种线性平滑滤波,适用于消除高斯噪声,广泛应用于图像处理的减噪过程。通俗的讲,高斯滤波就是对整幅图像进行加权平均的过程,每一个像素点的值,都由其本身和邻域内的其他像素值经过加权平均后得到。高斯滤波的具体操作是:用一个模板(或称卷积、掩模)扫描图像中的每一个像素,用模板确定的邻域内像素的加权平均灰度值去替代模板中心像素点的值用。高斯平滑滤波器对于抑制服从正态分布的噪声非常有效。
我们常说的高斯模糊就是使用高斯滤波器完成的,高斯模糊是低通滤波的一种,也就是滤波函数是低通高斯函数,但是高斯滤波是指用高斯函数作为滤波函数,至于是不是模糊,要看是高斯低通还是高斯高通,低通就是模糊,高通就是锐化。
在图像处理中,高斯滤波一般有两种实现方式,一是用离散化窗口滑窗卷积,另一种通过傅里叶变换。最常见的就是第一种滑窗实现,只有当离散化的窗口非常大,用滑窗计算量非常大(即使用可分离滤波器的实现)的情况下,可能会考虑基于傅里叶变化的实现方法。
由于高斯函数可以写成可分离的形式,因此可以采用可分离滤波器实现来加速。所谓的可分离滤波器,就是可以把多维的卷积化成多个一维卷积。具体到二维的高斯滤波,就是指先对行做一维卷积,再对列做一维卷积。这样就可以将计算复杂度从O(M*M*N*N)降到O(2*M*M*N),M,N分别是图像和滤波器的窗口大小。
高斯模糊是一个非常典型的图像卷积例子,本质上,高斯模糊就是将(灰度)图像和一个高斯核进行卷积操作:
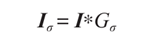
其中 * 表示卷积操作; Gσ 是标准差为σ 的二维高斯核,定义为:
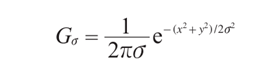
这里补充以下卷积的知识:
卷积是分析数学中一种重要的运算。
设:f(x),g(x)是R1上的两个可积函数,作积分:
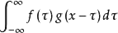
可以证明,关于几乎所有的实数x,上述积分是存在的。这样,随着x的不同取值,这个积分就定义了一个新函数h(x),称为函数f与g的卷积,记为h(x)=(f*g)(x)。
卷积是一个单纯的定义,本身没有什么意义可言,但是其在各个领域的应用是十分广泛的,在滤波中可以理解为一个加权平均过程,每一个像素点的值,都由其本身和邻域内的其他像素值经过加权平均后得到,而如何加权则是依据核函数高斯函数。
平均的过程:
对于图像来说,进行平滑和模糊,就是利用周边像素的平均值。
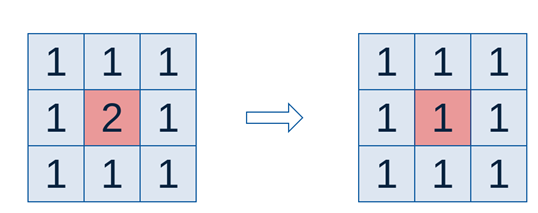
“中间点”取”周围点”的平均值,就会变成1。在数值上,这是一种”平滑化”。在图形上,就相当于产生”模糊”效果,”中间点”失去细节。
显然,计算平均值时,取值范围越大,”模糊效果”越强烈。
使用opencv2进行高斯滤波很方便,参考下面代码:
import cv2
#两个回调函数
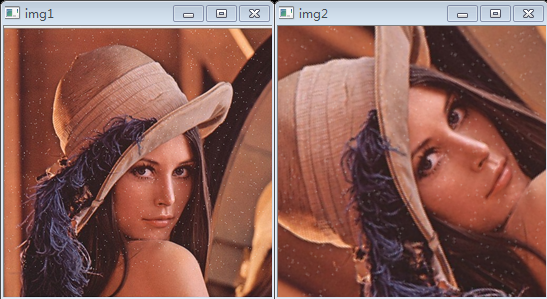
def GaussianBlurSize(GaussianBlur_size):global KSIZE KSIZE = GaussianBlur_size * 2 +3print KSIZE, SIGMAdst = cv2.GaussianBlur(scr, (KSIZE,KSIZE), SIGMA, KSIZE) cv2.imshow(window_name,dst)我们对图片lena.png添加噪音作为输入图片,进行高斯滤波后看看结果如何。这个例子中我们采用的核大小是3,代码如下:
from __future__ import print_function
import os
import struct
import numpy as np
import cv2
KSIZE = 3
SIGMA = 3
image = cv2.imread("d:/ai/lena.png")
print("image shape:",image.shape)
dst = cv2.GaussianBlur(image, (KSIZE,KSIZE), SIGMA, KSIZE)
cv2.imshow("img1",image)
cv2.imshow("img2",dst)
cv2.waitKey()最终生成的结果如下图所示(左边是噪音图像,右边是处理后的结果):

5、图片翻转
openCv2提供图像的翻转函数getRotationMatrix2D和warpAffine,详细用法可查看相关API文档,这里给出一个简单的例子。
from __future__ import print_function
import os
import struct
import math
import numpy as np
import cv2def rotate(img, #image matrixangle #angle of rotation): height = img.shape[0]width = img.shape[1] if angle%180 == 0:scale = 1elif angle%90 == 0:scale = float(max(height, width))/min(height, width)else:scale = math.sqrt(pow(height,2)+pow(width,2))/min(height, width)#print 'scale %f\n' %scale rotateMat = cv2.getRotationMatrix2D((width/2, height/2), angle, scale)rotateImg = cv2.warpAffine(img, rotateMat, (width, height))return rotateImg #rotated imageimage = cv2.imread("d:/ai/lena.png")
dst = rotate(image,60)
cv2.imshow("img1",image)
cv2.imshow("img2",dst)
cv2.waitKey()通过以下这两个方法获得翻转后的图像矩阵:
rotateMat = cv2.getRotationMatrix2D((width/2, height/2), angle, scale)
rotateImg = cv2.warpAffine(img, rotateMat, (width, height))运行之后得出结果如下图所示:
6、轮廓检测
轮廓检测也是图像处理中经常用到的。OpenCV2使用findContours()函数来查找检测物体的轮廓。
import cv2
img = cv2.imread('D:\\test\\contour.jpg')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret, binary = cv2.threshold(gray,127,255,cv2.THRESH_BINARY)
contours, hierarchy = cv2.findContours(binary,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
cv2.drawContours(img,contours,-1,(0,0,255),3)
cv2.imshow("img", img)
cv2.waitKey(0) 需要注意的是cv2.findContours()函数接受的参数为二值图,即黑白的(不是灰度图),所以读取的图像要先转成灰度的,再转成二值图。
原图如下:

检测结果如下:

注意,findcontours函数会“原地”修改输入的图像。这一点可通过下面的语句验证:
cv2.imshow("binary", binary)
contours, hierarchy = cv2.findContours(binary,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
cv2.imshow("binary2", binary) 执行这些语句后会发现原图被修改了。
cv2.findContours()函数
函数的原型为
cv2.findContours(image, mode, method[, contours[, hierarchy[, offset ]]])
返回两个值:contours:hierarchy。
参数
第一个参数是寻找轮廓的图像;
第二个参数表示轮廓的检索模式,有四种(本文介绍的都是新的cv2接口):
cv2.RETR_EXTERNAL表示只检测外轮廓。
cv2.RETR_LIST检测的轮廓不建立等级关系。
cv2.RETR_CCOMP建立两个等级的轮廓,上面的一层为外边界,里面的一层为内孔的边界信息。如果内孔内还有一个连通物体,这个物体的边界也在顶层。
cv2.RETR_TREE建立一个等级树结构的轮廓。
第三个参数method为轮廓的近似办法。
cv2.CHAIN_APPROX_NONE存储所有的轮廓点,相邻的两个点的像素位置差不超过1,即max(abs(x1-x2),abs(y2-y1))==1。
cv2.CHAIN_APPROX_SIMPLE压缩水平方向,垂直方向,对角线方向的元素,只保留该方向的终点坐标,例如一个矩形轮廓只需4个点来保存轮廓信息。
cv2.CHAIN_APPROX_TC89_L1,CV_CHAIN_APPROX_TC89_KCOS使用teh-Chinl chain 近似算法。
返回值
cv2.findContours()函数返回两个值,一个是轮廓本身,还有一个是每条轮廓对应的属性。
contour返回值
cv2.findContours()函数首先返回一个list,list中每个元素都是图像中的一个轮廓,用numpy中的ndarray表示。这个概念非常重要。在下面drawContours中会看见。
print (type(contours))
print (type(contours[0]))
print (len(contours))
可以验证上述信息。会看到本例中有两条轮廓,一个是五角星的,一个是矩形的。每个轮廓是一个ndarray,每个ndarray是轮廓上的点的集合。
由于我们知道返回的轮廓有两个,因此可通过
cv2.drawContours(img,contours,0,(0,0,255),3)
和
cv2.drawContours(img,contours,1,(0,255,0),3)
分别绘制两个轮廓,关于该参数可参见下面一节的内容。同时通过
print (len(contours[0]))
print (len(contours[1]))
输出两个轮廓中存储的点的个数,可以看到,第一个轮廓中只有4个元素,这是因为轮廓中并不是存储轮廓上所有的点,而是只存储可以用直线描述轮廓的点的个数,比如一个“正立”的矩形,只需4个顶点就能描述轮廓了。
7、角点
角点的定义和特性:
- 角点:是一类含有足够信息且能从当前帧和下一帧中都能提取出来的点。
- 最普遍使用的角点的定义是由Harris提出的。
- 典型的角点检测算法:Harris角点检测、CSS角点检测。
- 好的角点检测算法的特点:1、检测出图像中“真实的”角点;2、准确的定位性能;3、很高的重复检测率(稳定性好);4、具有对噪声的鲁棒性;5、具有较高的计算效率。
Open 中的函数cv2.cornerHarris(src, blockSize, ksize, k[, dst[, borderType]]) → dst 可以用来进行角点检测。参数如下:
- src –数据类型为float32 的输入图像。
- dst – 存储角点数组的输出图像,和输入图像大小相等。
- blockSize –角点检测中要考虑的领域大小。
- ksize –Sobel 求导中使用的窗口大小。
- k –Harris 角点检测方程中的自由参数,取值参数为[0,04,0.06]。
- borderType –边界类型。
# coding=utf-8
import cv2
import numpy as np
'''Harris算法角点特征提取'''
img = cv2.imread('chess_board.png')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
gray = np.float32(gray)
# {标记点大小,敏感度(3~31,越小越敏感)}
# OpenCV函数cv2.cornerHarris() 有四个参数 其作用分别为 :
dst = cv2.cornerHarris(gray,2,23,0.04)
img[dst>0.01 * dst.max()] = [0,0,255]
cv2.imshow('corners',img)
cv2.waitKey()
cv2.destroyAllWindows()最后检测出角点并在图像上标注出来,示例如下:

8、直方图
图像的构成是有像素点构成的,每个像素点的值代表着该点的颜色(灰度图或者彩色图)。所谓直方图就是对图像的中的这些像素点的值进行统计,得到一个统一的整体的灰度概念。直方图的好处就在于可以清晰了解图像的整体灰度分布,这对于后面依据直方图处理图像来说至关重要。
一般情况下直方图都是灰度图像,直方图x轴是灰度值(一般0~255),y轴就是图像中每一个灰度级对应的像素点的个数。
那么如何获得图像的直方图?首先来了解绘制直方图需要的一些量:灰度级,正常情况下就是0-255共256个灰度级,从最黑一直到最亮(白)(也有可能统计其中的某部分灰度范围),那么每一个灰度级对应一个数来储存该灰度对应的点数目。也就是说直方图其实就是一个1*m(灰度级)的一个数组而已。但是有的时候我们不希望一个一个灰度的递增,比如现在我想15个灰度一起作为一个灰度级来花直方图,这个时候我们可能只需要1*(m/15)这样一个数组就够了。那么这里的15就是直方图的间隔宽度了。
OpenCV给我们提供的函数是cv2.calcHist(),该函数有5个参数:
- image输入图像,传入时应该用中括号[]括起来。
- channels::传入图像的通道,如果是灰度图像,那就不用说了,只有一个通道,值为0,如果是彩色图像(有3个通道),那么值为0,1,2,中选择一个,对应着BGR各个通道。这个值也得用[]传入。
- mask:掩膜图像。如果统计整幅图,那么为none。主要是如果要统计部分图的直方图,就得构造相应的炎掩膜来计算。
- histSize:灰度级的个数,需要中括号,比如[256]。
- ranges:像素值的范围,通常[0,256],有的图像如果不是0-256,比如说你来回各种变换导致像素值负值、很大,则需要调整后才可以。
除此之外,强大的numpy也有函数用于统计直方图的,通用的一个函数np.histogram,还有一个函数是np.bincount()(用于以为统计直方图,速度更快)。这三个方式的传入参数基本上差不多,不同的是opencv自带的需要中括号括起来。
对于直方图的显示也是比较简单的,直接plt.plot()就可以。一个实例如下:
import cv2
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread('flower.jpg',0) #直接读为灰度图像
#opencv方法读取-cv2.calcHist(速度最快)
#图像,通道[0]-灰度图,掩膜-无,灰度级,像素范围
hist_cv = cv2.calcHist([img],[0],None,[256],[0,256])
#numpy方法读取-np.histogram()
hist_np,bins = np.histogram(img.ravel(),256,[0,256])
#numpy的另一种方法读取-np.bincount()(速度=10倍法2)
hist_np2 = np.bincount(img.ravel(),minlength=256)
plt.subplot(221),plt.imshow(img,'gray')
plt.subplot(222),plt.plot(hist_cv)
plt.subplot(223),plt.plot(hist_np)
plt.subplot(224),plt.plot(hist_np2)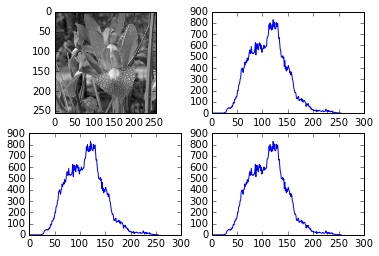
现在来考虑opencv的直方图函数中掩膜的使用,这个掩膜就是一个区域大小,表示你接下来的直方图统计就是这个区域的像素统计。一个例子如下:
import cv2
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread('flower.jpg',0) #直接读为灰度图像
mask = np.zeros(img.shape[:2],np.uint8)
mask[100:200,100:200] = 255
masked_img = cv2.bitwise_and(img,img,mask=mask) #opencv方法读取-cv2.calcHist(速度最快)
#图像,通道[0]-灰度图,掩膜-无,灰度级,像素范围
hist_full = cv2.calcHist([img],[0],None,[256],[0,256])
hist_mask = cv2.calcHist([img],[0],mask,[256],[0,256])plt.subplot(221),plt.imshow(img,'gray')
plt.subplot(222),plt.imshow(mask,'gray')
plt.subplot(223),plt.imshow(masked_img,'gray')
plt.subplot(224),plt.plot(hist_full),plt.plot(hist_mask)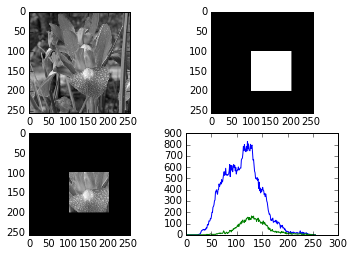
9、形态学图像处理
本节介绍如何使用morphology模块实现二值图像处理。二值图像中的每个像素的颜色只有两种:黑色和白色,在NumPy中可以用二维布尔数组表示:False表示黑色,True表示白色。也可以用无符号单字节整型(uint8)数组表示:0表示黑色,非0表示白色。
下面的两个函数用于显示形态学图像处理的结果。
import numpy as np
def expand_image(img, value, out=None, size = 10):if out is None:w, h = img.shapeout = np.zeros((w*size, h*size),dtype=np.uint8)tmp = np.repeat(np.repeat(img,size,0),size,1)out[:,:] = np.where(tmp, value, out)out[::size,:] = 0out[:,::size] = 0return out
def show_image(*imgs):for idx, img in enumerate(imgs, 1):ax = plt.subplot(1, len(imgs), idx)plt.imshow(img, cmap="gray")ax.set_axis_off()plt.subplots_adjust(0.02, 0, 0.98, 1, 0.02, 0)9.1 膨胀和腐蚀
二值图像最基本的形态学运算是膨胀和腐蚀。膨胀运算是将与某物体(白色区域)接触的所有背景像素(黑色区域)合并到该物体中的过程。简单地说,就是对于原始图像中的每个白色像素进行处理,将其周围的黑色像素都设置为白色像素。这里的“周围”是一个模糊概念,在实际运算时,需要明确给出“周围”的定义。下图是膨胀运算的一个例子,其中左图是原始图像,中间的图是四连通定义的“周围”的膨胀效果,右图是八连通定义的“周围”的膨胀效果。图中用灰色方块表示由膨胀处理添加进物体的像素。
from scipy.ndimage import morphology
def dilation_demo(a, structure=None):b = morphology.binary_dilation(a, structure)img = expand_image(a, 255)return expand_image(np.logical_xor(a,b), 150, out=img)
a = plt.imread("images/scipy_morphology_demo.png")[:,:,0].astype(np.uint8)
img1 = expand_image(a, 255)
img2 = dilation_demo(a)
img3 = dilation_demo(a, [[1,1,1],[1,1,1],[1,1,1]])
show_image(img1, img2, img3)
四连通包括上下左右四个像素,而八连通则还包括四个斜线方向上的邻接像素。它们都可以使用下面的正方形矩阵定义,其中正中心的元素表示当前要进行运算的像素,而其周围的1和0表示对应位置的像素是否算作其“周围”像素。这种矩阵描述了周围像素和当前像素之间的关系,被称作结构元素(structuring element)。
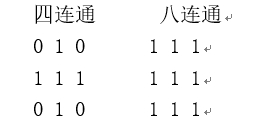
假设数组a是一个表示二值图像的数组,可以用如下语句对其进行膨胀运算:
binary_dilation(a)
binary_dilation()缺省使用四连通进行膨胀运算,通过structure参数可以指定其它的结构元素,下面是进行八连通膨胀运算的语句:
binary_dilation(a, structure=[[1,1,1],[1,1,1],[1,1,1]])
通过设置不同的结构元素,能够制作出各种不同的效果,下面显示了三个种不同结构元素的膨胀效果。图中的结构元素分别为:

img4 = dilation_demo(a, [[0,0,0],[1,1,1],[0,0,0]])
img5 = dilation_demo(a, [[0,1,0],[0,1,0],[0,1,0]])
img6 = dilation_demo(a, [[0,1,0],[0,1,0],[0,0,0]])
show_image(img4, img5, img6)
binary_erosion()的腐蚀运算正好和膨胀相反,它将“周围”有黑色像素的白色像素设置为黑色。下面是四连通和八连通腐蚀的效果,图中用灰色方块表示被腐蚀的像素。
def erosion_demo(a, structure=None):b = morphology.binary_erosion(a, structure)img = expand_image(a, 255)return expand_image(np.logical_xor(a,b), 100, out=img)img1 = expand_image(a, 255)
img2 = erosion_demo(a)
img3 = erosion_demo(a, [[1,1,1],[1,1,1],[1,1,1]])
show_image(img1, img2, img3)
9.2 Hit和Miss
Hit和Miss是二值形态学图像处理中最基本的运算,因为几乎所有的其它的运算都可以用Hit和Miss的组合推演出来。它对图像中的每个像素周围的像素进行模式判断,如果周围像素的黑白模式符合指定的模式,则将此像素设为白色,否则设置为黑色。因为它需要同时对白色和黑色像素进行判断,因此需要指定两个结构元素。进行Hit和Miss运算的binary_hit_or_miss()的调用形式如下:
binary_hit_or_miss(input, structure1=None, structure2=None, ...)
其中structure1参数指定白色像素的结构元素,而structure2参数则指定黑色像素的结构元素。下图是binary_hit_or_miss()的运算结果。其中左图为原始图像,中图为使用下面两个结构元素进行运算的结果:
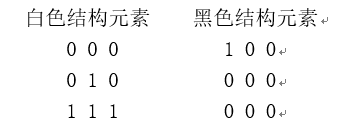
在这两个结构元素中,0表示不关心其对应位置的像素的颜色,1表示其对应位置的像素必须为结构元素所表示的颜色。因此通过这两个结构元素可以找到“下方三个像素为白色,并且左上像素为黑色的白色像素”。
与右图对应的结构元素如下。通过它可以找到“下方三个像素为白色、左上像素为黑色的黑色像素”。
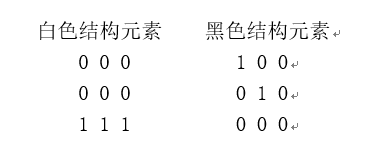
def hitmiss_demo(a, structure1, structure2):b = morphology.binary_hit_or_miss(a, structure1, structure2)img = expand_image(a, 100)return expand_image(b, 255, out=img)
img1 = expand_image(a, 255)
img2 = hitmiss_demo(a, [[0,0,0],[0,1,0],[1,1,1]], [[1,0,0],[0,0,0],[0,0,0]])
img3 = hitmiss_demo(a, [[0,0,0],[0,0,0],[1,1,1]], [[1,0,0],[0,1,0],[0,0,0]])
show_image(img1, img2, img3)
使用Hit和Miss运算的组合,可以实现很复杂的图像处理。例如文字识别中常用的细线化运算就可以用一系列的Hit和Miss运算实现。下图显示了细线化处理的效果。
def skeletonize(img):h1 = np.array([[0, 0, 0],[0, 1, 0],[1, 1, 1]])m1 = np.array([[1, 1, 1],[0, 0, 0],[0, 0, 0]])h2 = np.array([[0, 0, 0],[1, 1, 0],[0, 1, 0]])m2 = np.array([[0, 1, 1],[0, 0, 1],[0, 0, 0]])hit_list = []miss_list = []for k in range(4):hit_list.append(np.rot90(h1, k))hit_list.append(np.rot90(h2, k))miss_list.append(np.rot90(m1, k))miss_list.append(np.rot90(m2, k))img = img.copy()while True:last = imgfor hit, miss in zip(hit_list, miss_list):hm = morphology.binary_hit_or_miss(img, hit, miss)# 从图像中删除hit_or_miss所得到的白色点img = np.logical_and(img, np.logical_not(hm))# 如果处理之后的图像和处理前的图像相同,则结束处理if np.all(img == last):breakreturn img
a = plt.imread("images/scipy_morphology_demo2.png")[:,:,0].astype(np.uint8)
b = skeletonize(a)
_, (ax1, ax2) = plt.subplots(1, 2, figsize=(9, 3))
ax1.imshow(a, cmap="gray", interpolation="nearest")
ax2.imshow(b, cmap="gray", interpolation="nearest")
ax1.set_axis_off()
ax2.set_axis_off()
plt.subplots_adjust(0.02, 0, 0.98, 1, 0.02, 0)
细线化算法的实现程序如下,这里只列出其中真正进行细线化算法的函数skeletonize():
根据上图所示的两个结构元素为基础,构造四个3*3的二维数组:h1、m1、h2、m2。其中h1和m1对应图中左边的结构元素,而h2和m2对应图中右边的结构元素,h1和h2对应白色结构元素,m1和m2对应黑色结构元素。将这些结构元素进行90、180、270度旋转之后一共得到8个结构元素。
依次使用这些结构元素进行Hit和Miss运算,并从图像中删除运算所得到的白色像素,其效果就是依次从8个方向删除图像的边缘上的像素。重复运算直到没有像素可删除为止。
转载于:https://my.oschina.net/u/778683/blog/3100953
深度学习中用到的几种图像操作相关推荐
- 一种基于深度学习的目标检测提取视频图像关键帧的方法
摘要:针对传统的关键帧提取方法误差率高.实时性差等问题,提出了一种基于深度学习的目标检测提取视频图像关键帧的方法,分类提取列车头部.尾部及车身所在关键帧.在关键帧提取过程中,重点研究了基于SIFT特征 ...
- 基于深度学习和支持向量机的4种苜蓿叶部病害图像识别
基于深度学习和支持向量机的4种苜蓿叶部病害图像识别 1.研究思路 对 采 集 获 得 的899张苜蓿叶部病害图像,利 用 人工裁剪方法从每张原始图像中获得1张子图像,然后利用结合 K 中值聚类算法和线 ...
- 【深度学习】DL下的3D图像和Low-level Vision问题解析
[深度学习]DL下的3D图像和Low-level Vision问题解析 文章目录 1 概述 2 low-level vision2.1 [注意力机制.超分]Learning Texture Trans ...
- 【深度学习】一个应用—肝脏CT图像自动分割(术前评估)
[深度学习]一个应用-肝脏CT图像自动分割(术前评估) 文章目录 1 目标 2 数据集 3 LITS20173.1 LiTS数据的预处理3.2 LiTS数据的读取3.3 数据增强3.4 数据存储 4 ...
- 【深度学习】利用一些API进行图像数据增广
[深度学习]利用一些API进行图像数据增广 文章目录 [深度学习]利用一些API进行图像数据增广 1 先送上一份最强的翻转代码(基于PIL) 2 Keras中的数据增强API种类概述 3 特征标准化 ...
- 深度学习在计算机视觉领域(包括图像,视频,3-D点云,深度图)的应用
深度学习在计算机视觉领域(包括图像,视频,3-D点云,深度图)的应用 转自 https://zhuanlan.zhihu.com/p/55747295 深度学习在计算机视觉领域(包括图像,视频,3-D ...
- 深度学习(17)TensorFlow高阶操作六: 高阶OP
深度学习(17)TensorFlow高阶操作六: 高阶OP 1. Where(tensor) 2. where(cond, A, B) 3. 1-D scatter_nd 4. 2-D scatter ...
- 深度学习(14)TensorFlow高阶操作三: 张量排序
深度学习(14)TensorFlow高阶操作三: 张量排序 一. Sort, argsort 1. 一维Tensor 2. 多维Tensor 二. Top_k 三. Top-k accuracy(To ...
- 深度学习(12)TensorFlow高阶操作一: 合并与分割
深度学习(12)TensorFlow高阶操作一: 合并与分割 1. concat 2. stack: create new dim 3. Dim mismatch 4. unstuck 5. spli ...
最新文章
- 剑指Offer #03 从尾到头打印链表(递归)
- 数据埋点方案和规范确定
- python秒数转化为时间用户jianpang_Python中文转为拼音
- 有两个程序员得了肺癌 都是30多岁的男人
- java获取本机ip地址_代码片段:获取系统所有IP
- React Native 开发豆瓣评分(五)屏幕适配方案
- 如何有逻辑的,简单清晰的回应问题
- RN 开发遇到的问题之传参函数错误Invariant Violation: Maximum update depth exceeded.
- windows安全中心接口
- 坦克大战小游戏的实现
- 计算机维修兴趣小组,计算机兴趣小组章程
- libcef和js交互
- linux下国产达梦数据库的命令行安装
- R语言plotly可视化:使用plotly可视化模型预测概率值的直方图、使用分类标签为阴性和阳性样本预测概率直方图进行颜色区分(prediction probability histogram)
- 小精灵无尽的长廊_神奇宝贝之无尽系统
- Midjourney如何给模特换衣服
- Spring Boot与Elasticsearch的对应版本
- 无法分配请求的地址(Cannot assign requested address)的解决方案
- 【方案分享】阿里城市大脑数据智能解决方案.pdf(附下载链接)
- (原創) X61用戶,小心你的上蓋!! (NB) (ThinkPad) (X61)