《Scala机器学习》一一3.3 应用
本节书摘来自华章计算机《Scala机器学习》一书中的第3章,第3.3节,作者:[美] 亚历克斯·科兹洛夫(Alex Kozlov),更多章节内容可以访问云栖社区“华章计算机”公众号查看。
3.3 应用
下面会介绍Spark/Scala中的一些实际示例和库,具体会从一个非常经典的单词计数问题开始。
3.3.1 单词计数
大多数现代机器学习算法需要多次传递数据。如果数据能存放在单台机器的内存中,则该数据会容易获得,并且不会呈现性能瓶颈。如果数据太大,单台机器的内存容纳不下,则可保存在磁盘(或数据库)上,这样虽然可得到更大的存储空间,但存取速度大约会降为原来的1/100。另外还有一种方式就是分割数据集,将其存储在网络中的多台机器上,并通过网络来传输结果。虽然对这种方式仍有争议,但分析表明,对于大多数实际系统而言,如果能有效地在多个CPU之间拆分工作负载,则通过一组网络连接节点存储数据比从单个节点上的硬盘重复存储和读取数据略有优势。
磁盘的平均带宽约为100 MB/s,由于磁盘的转速和缓存不同,其传输时会有几毫秒的延迟。相对于直接从内存中读取数据,速度要降为原来的1/100左右,当然,这也会取决于数据大小和缓存的实现。现代数据总线可以超过10 GB/s的速度传输数据。而网络速度仍然落后于直接的内存访问,特别是标准网络层中TCP/IP内核的开销会对网络速度影响很大。但专用硬件可以达到每秒几十吉字节,如果并行运行,则可能和从内存读取一样快。当前的网络传输速度介于1~10 GB/s之间,但在实际应用中仍然比磁盘更快。因此,可以将数据分配到集群节点中所有机器的内存中,并在集群上执行迭代机器学习算法。
但内存也有一个问题:在节点出现故障并重新启动后,内存中的数据不会跨节点持久保存。一个流行的大数据框架Hadoop解决了这个问题。Hadoop受益于Dean/Ghemawat的论文(Jeff Dean和Sanjay Ghemawat, MapReduce: Simplified Data Processing on Large Clusters, OSDI, 2004.),这篇文章提出使用磁盘层持久性来保证容错和存储中间结果。Hadoop MapReduce程序首先会在数据集的每一行上运行map函数,得到一个或多个键/值对。然后按键值对这些键/值对进行排序、分组和聚合,使得具有相同键的记录最终会在同一个reducer上处理,该reducer可能在一个(或多个)节点上运行。reducer会使用一个reduce函数,遍历同一个键对应的所有值,并将它们聚合在一起。如果reducer因为一些原因失败,由于其中间结果持久保存,则可以丢弃部分计算,然后可从检查点保存的结果重新开始reduce计算。很多简单的类ETL应用程序仅在保留非常少的状态信息的情况下才遍历数据集,这些状态信息是从一个记录到另一个记录的。
单词计数是MapReduce的经典应用程序。该程序可统计文档中每个单词的出现次数。在Scala中,对排好序的单词列表采用foldLeft方法,很容易得到单词计数。

如果运行这个程序,会输出(字,计数)这样的元组列表。该程序会按行来分词,并对得到的单词排序,然后将每个单词与(字,计数)元组列表中的最新条目(entry)进行匹配。同样的计算在MapReduce中会表示成如下形式:

首先需要按行处理文本,将行拆分成单词,并生成(word,1)对。这个任务很容易并行化。为了并行化全局计数,需对计数部分进行划分,具体的分解通过对单词子集分配计数任务来实现。在Hadoop中需计算单词的哈希值,并根据哈希值来划分工作。
一旦map任务找到给定哈希的所有条目,它就可以将键/值对发送到reducer,在MapReduce中,发送部分通常称为shuffle。从所有mapper中接收完所有的键/值对后,reducer才会组合这些值(如果可能,在mapper中也可部分组合这些值),并对整个聚合进行计算,在这种情况下只进行求和。单个reducer将查看给定单词的所有值。
下面介绍Spark中单词计数程序的日志输出(Spark在默认情况下输出的日志会非常冗长,为了输出关键的日志信息,可将conf /log4j.properties文件中的INFO替换为ERROR或FATAL):
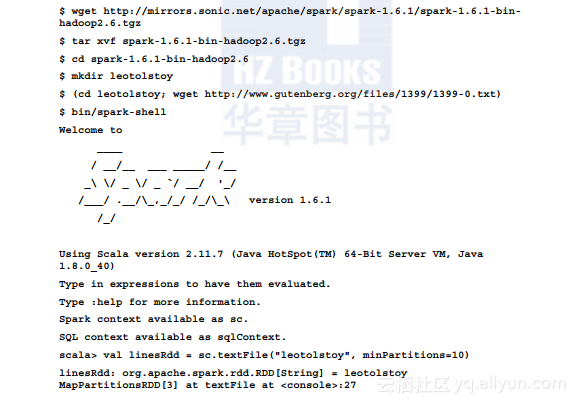
这个过程发生的唯一的事情是元数据操作,Spark不会触及数据本身,它会估计数据集的大小和分区数。默认情况下是HDFS块数,但是可使用minPartitions参数明确指定最小分区数:

下面定义另一个RDD,它源于linesRdd:
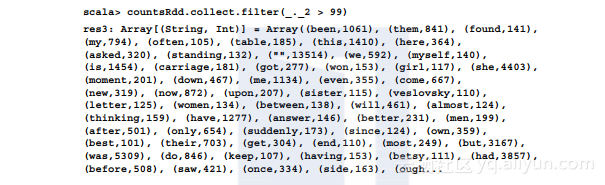
在2 GB的文本数据(共有40 291行,353 087个单词)上执行单词计算程序时,进行读取、分词和按词分组所花的时间不到1秒。通过扩展日志记录可看到以下内容:
Spark打开几个端口与执行器和用户通信
Spark UI运行的端口为4040(可通过http://localhost: 4040打开)
可从本地或分布式存储(HDFS、Cassandra和S3)中读取文件
如果Spark构建时支持Hive,它会连接到Hive上
Spark使用惰性求值(仅当输出请求时)来执行管道
Spark使用内部调度器将作业拆分为任务,优化执行任务,然后执行它们
结果存储在RDD中,可用集合方法来保存或导入到执行shell的节点的RAM中
并行性能调整的原则是在不同节点或线程之间分割工作负载,使得开销相对较小,而且要保持负载平衡。
3.3.2 基于流的单词计数
Spark支持对输入流进行监听,能对其进行分区,并以接近实时的方式来计算聚合。目前支持来自Kafka、Flume、HDFS/S3、Kinesis、Twitter,以及传统的MQ(如ZeroMQ和MQTT)的数据流。在Spark中,流的传输是以小批量(micro-batch)方式进行的。在Spark内部会将输入数据分成小批量,通常按大小的不同,有些所花的时间不到1秒,有些却要几分钟,然后会对这些小批量数据执行RDD聚合操作。
下面扩展前面介绍的Flume示例。这需要修改Flume配置文件来创建一个Spark轮询槽(polling sink),用这种槽来替代HDFS:

现在不用写入HDFS,Flume将会等待Spark的轮询数据:

为了运行程序,在一个窗口中启动Flume代理:

然后在另一个窗口运行FlumeWordCount对象:

现在任何输入到netcat连接的文本都将被分词并在6秒的滑动窗口上按每2秒计算单词的量:

Spark/Scala允许在不同的流之间无缝切换。例如,Kafka发布/订阅主题模型类似于如下形式:


要启动Kafka代理,首先下载最新发布的二进制包并启动ZooKeeper。ZooKeeper是一个分布式服务协调器,即使Kafka部署在单节点上也需要它:

在另一个窗口中启动Kafka服务器:

运行KafkaWordCount对象:

现在将单词流发布到Kafka主题中,这需要再开启一个计数窗口:
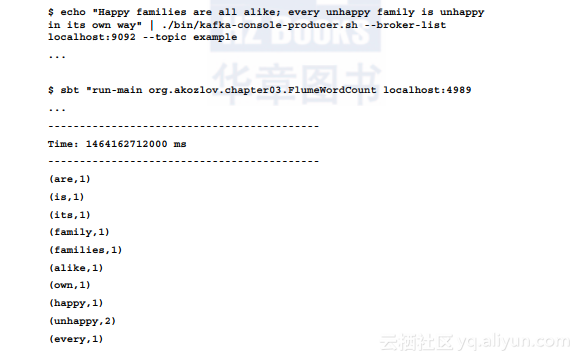
从上面的结果可以看出程序每两秒输出一次。Spark流有时被称为小批次处理(micro-batch processing)。数据流有许多其他应用程序(和框架),但要完全讨论清楚会涉及很多内容,因此需要单独进行介绍。在第5章会讨论一些数据流上的机器学习问题。下面将介绍更传统的类SQL接口。
3.3.3 Spark SQL和数据框
数据框(Data Frame)相对较新,在Spark的1.3版本中才引入,它允许人们使用标准的SQL语言来分析数据。在第1章就使用了一些SQL命令来进行数据分析。SQL对于简单的数据分析和聚合非常有用。
最新的调查结果表明大约有70%的Spark用户使用DataFrame。虽然DataFrame最近成为表格数据最流行的工作框架,但它是一个相对重量级的对象。DataFrame使用的管道在执行速度上可能比基于Scala的vector或LabeledPoint(这两个对象将在下一章讨论)的速度慢得多。来自多名开发人员的证据表明:响应时间可为几十或几百毫秒,这与具体查询有关,若是更简单的对象会小于1毫秒。
Spark为SQL实现了自己的shell,这是除标准Scala REPL shell以外的另一个shell。可通过./bin/spark-sql来运行该shell,还可通过这种shell来访问Hive/Impala或关系数据库表:
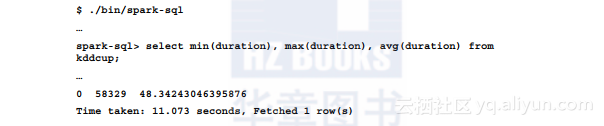
在标准Spark的REPL中,可以通过运行相同的查询来执行以下命令:
《Scala机器学习》一一3.3 应用相关推荐
- 《Scala机器学习》一一
本节书摘来自华章计算机<Scala机器学习>一书中的第3章,第3.1节,作者:[美] 亚历克斯·科兹洛夫(Alex Kozlov),更多章节内容可以访问云栖社区"华章计算机&qu ...
- 《Scala机器学习》一一1.1 Scala入门
本节书摘来自华章计算机<Scala机器学习>一书中的第1章,第1.1节,作者:[美] 亚历克斯·科兹洛夫(Alex Kozlov),更多章节内容可以访问云栖社区"华章计算机&qu ...
- 《Scala机器学习》一一第3章 使用Spark和MLlib
第3章 使用Spark和MLlib 上一章介绍了在全局数据驱动的企业架构中的什么地方以及如何利用统计和机器学习来处理知识,但接下来不会介绍Spark和MLlib的具体实现,MLlib是Spark顶层的 ...
- 《Scala机器学习》一一2.3 探索与利用问题
2.3 探索与利用问题 探索(exploration)与利用(exploitation)的应用很广,从资金分配到研究自动驾驶汽车项目都在使用,但它最初也是源于赌博问题.该问题的经典形式是一个多臂赌博机 ...
- murmurhash 下载_MurmurHash3?
HashMap面试必问的6个点,你知道几个? 一.HashMap的实现原理? 此题可以组成如下连环炮来问 你看过HashMap源码嘛,知道原理嘛?为什么用数组+链表?hash冲突你还知道哪些解决办法? ...
- 大二上学数据结构和操作系统_毕业后的工作比上学要重要得多。 这是数据。...
大二上学数据结构和操作系统 by Aline Lerner 通过艾琳·勒纳(Aline Lerner) 毕业后的工作比上学要重要得多. 这是数据. (What you do after you gra ...
- 【我大学接触过的知识统计--大数据专业】
简单统计一下,我使用过的软件,和用过的一些技术,数据库,用过的编程语言 eclipse: https://baike.baidu.com/item/eclipse/61703?fr=aladdin h ...
- 华章计算机祝广大读者“猿”宵节快乐
"猿"宵节快乐 猿宵节,是程序猿通宵赶代码的中国传统节日.在此佳节来临之际,恭祝全国程序猿节日快乐. 又到了一年一度的元宵节 对程序员来说,这个节日叫什么 "猿" ...
- 机器学习(三)--- scala学习笔记
Scala是一门多范式的编程语言,一种类似Java的编程语言,设计初衷是实现可伸缩的语言.并集成面向对象编程和函数式编程的各种特性. Spark是UC Berkeley AMP lab所开源的类Had ...
最新文章
- 什么是稀疏矩阵算法?
- android keytool 不是内部命令或外部命令在 (win7下不能用的解决方法)
- python的ai写作_神奇,用Python写一个AI贪吃蛇,真的可以追着你跑的那种
- 查询缓存---Mybatis学习笔记(十)
- 网络编程套接字API
- asp.net读取用户控件,自定义加载用户控件
- 基于JAVA+SpringMVC+Mybatis+MYSQL的校友录管理系统
- 【C/C++】基本数据类型的隐式类型转换
- 移动端向上滑动整个屏幕
- C#中使用Dictionary实现Map数据结构
- python水仙花数的代码_Python水仙花数的编程代码写法
- 做短视频自媒体,常用工具和素材网站分享,新手小白收藏抓紧行动
- vue模板字符串标签动态参数_vue模板字符串
- 文件服务器异地容灾,服务器异地容灾
- 重磅突发!支付宝下架互联网存款产品,蚂蚁集团回应
- Ant design-05 表单多选的组件
- OCIOS开发小技巧总结
- mysql删除重复记录语句
- as.net core 5.0 Configuration读取consul的kv存储
- NS3-LENA源码阅读报告(1)