【译】Diving Into The Ethereum VM Part 3 — The Hidden Costs of Arrays
Solidity提供了其他编程语言中常见的数据结构。 除了诸如数字和结构之类的简单值之外,还有数据类型可以随着更多数据的添加而动态扩展。 这些动态类型的三个主要类别是:
- 映射:
mapping(bytes32 => uint256),mapping(address => string)等 - 数组:
[]uint256,[]byte等。 - 字节数组。 只有两种:
string,bytes。
在本系列的第二部分中,我们已经看到存储中代表固定大小的简单类型。
- 基本值:
uint256,byte等 - 固定大小的数组:
[10]uint8,[32]byte,bytes32 - 结合上述类型的结构。
具有固定大小的存储变量在存储中一个接一个地布置,尽可能紧凑地包装成32个字节的块。
(如果这看起来不熟悉,请阅读潜入以太坊VM第二部分 - 存储成本 )
在本文中,我们将介绍Solidity如何支持更复杂的数据结构。 Solidity中的数组和映射可能看起来很熟悉,但它们的实现方式使它们具有完全不同的性能特征。
我们将从映射开始,这是三者中最简单的一种。 事实证明,数组和字节数组只是映射了更多的功能。
制图
让我们在uint256 => uint256映射中存储单个值:
杂注扎实0.4.11;
合同C { 映射(uint256 => uint256)项目;
函数C(){ 项目[0xC0FEFE] = 0x42; } }
编译:
solc --bin --asm --optimize c-mapping.sol
大会:
TAG_2: //不做任何事情。 应该优化掉。 0xc0fefe 为0x0 swap1 DUP2 mstore 为0x20 mstore
//将0x42存储到地址0x798 ... 187c 的0x42 0x79826054ee948a209ff4a6c9064d7398508d2c1909a392f899d301c6d232187c sstore
我们可以将EVM存储视为键值数据库,每个键限制为存储32个字节。 不是直接使用密钥0xC0FEFE ,而是将密钥散列为0x798...187c ,并将值0x42存储在那里。 使用的散列函数是keccak256 (SHA256)函数。
在这个例子中,我们没有看到keccak256指令本身,因为优化器已经决定预先计算结果并将其内联到字节码中。 我们仍然以无用的mstore指令的形式看到这种计算的痕迹。
计算地址
让我们使用一些Python代码来将0x798...187c散列为0x798...187c 。 如果你想跟随,你需要Python 3.6,或者安装pysha3来获得keccak_256哈希函数。
定义两个辅助函数:
导入binascii 导入sha3
#将一个数字转换为32字节的数组。 def bytes32(i): return binascii.unhexlify('%064x'%i)
#计算32字节数组的keccak256哈希值。 def keccak256(x): 返回sha3.keccak_256(x).hexdigest()
将数字转换为32字节:
>>> bytes32(1) B'\ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X01'
>>> bytes32(0xC0FEFE) B'\ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ XC0 \ XFE \ XFE”
要将两个字节数组连接在一起,请使用+运算符:
>>> bytes32(1)+ bytes32(2) B'\ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X01 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X00 \ X02'
要计算某些字节的keccak256哈希值:
>>> keccak256(bytes(1)) 'bc36789e7a1e281436464229828f817d6612f7b477d66591ff96a9e064bcc98a'
我们现在有足够的计算0x798...187c 。
商店变量items的位置是0x0 (因为它是第一个商店变量)。 要获取地址,请将键0xc0fefe与items的位置连接0xc0fefe :
#key = 0xC0FEFE,position = 0 >>> keccak256(bytes32(0xC0FEFE)+ bytes32(0)) '79826054ee948a209ff4a6c9064d7398508d2c1909a392f899d301c6d232187c'
计算密钥存储地址的公式为:
keccak256(bytes32(key)+ bytes32(position))
两个映射
我们来计算公式,我们必须计算值的存储位置! 假设我们有两个映射的合约:
杂注扎实0.4.11;
合同C { 映射(uint256 => uint256)itemsA; 映射(uint256 => uint256)itemsB;
函数C(){ itemsA [0xAAAA] = 0xAAAA; itemsB [0xBBBB] = 0xBBBB; } }
itemsA位置的位置为0,对于键0xAAAA:
#key = 0xAAAA,position = 0 >>> keccak256(bytes32(0xAAAA)+ bytes32(0)) '839613f731613c3a2f728362760f939c8004b5d9066154aab51d6dadf74733f3'
itemsB位置的位置是1,对于键0xBBBB:
#key = 0xBBBB,position = 1 >>> keccak256(bytes32(0xBBBB)+ bytes32(1)) '34cb23340a4263c995af18b23d9f53b67ff379ccaa3a91b75007b010c489d395'
让我们用编译器来验证这些计算:
$ solc --bin --asm --optimize c-mapping-2.sol
大会:
TAG_2: // ...省略可以优化的内存操作
加上0xAAAA 0x839613f731613c3a2f728362760f939c8004b5d9066154aab51d6dadf74733f3 sstore
0xbbbb 0x34cb23340a4263c995af18b23d9f53b67ff379ccaa3a91b75007b010c489d395 sstore
如预期。
KECCAK256装配中
编译器能够预先计算一个键的地址,因为所涉及的值是常量。 如果使用的密钥是一个变量,那么散列需要用汇编代码完成。 现在我们要禁用这个优化,以便我们可以看到哈希如何在汇编中完成。
事实证明,通过引入一个带虚拟变量i的额外间接方法可以简化优化器:
杂注扎实0.4.11;
合同C { 映射(uint256 => uint256)项目;
//这个变量会导致常量折叠失败。 uint256 i = 0xC0FEFE;
函数C(){ items [i] = 0x42; } }
变量items的位置仍然是0x0 ,所以我们应该期待与之前相同的地址。
编译优化,但这次没有哈希预计算:
$ solc --bin --asm --optimize c-mapping - no-constant-folding.sol
大会注释:
TAG_2: //将`i`加载到堆栈上 SLOAD(为0x1) [0xC0FEFE]
//将密钥0xC0FEFE存储在内存0x0处进行散列。 为0x0 [0x0 0xC0FEFE] swap1 [0xC0FEFE 0x0] DUP2 [0x0 0xC0FEFE 0x0] mstore [为0x0] 记忆:{ 0x00 => 0xC0FEFE }
//将位置0x0存储在0x20(32)的存储器中,用于散列。 0x20 // 32 [0x20 0x0] DUP2 [0x0 0x20 0x0] swap1 [0x20 0x0 0x0] mstore [为0x0] 记忆:{ 0x00 => 0xC0FEFE 0x20 => 0x0 }
//从第0字节开始,在内存中散列下一个0x40(64)字节 0x40 // 64 [0x40 0x0] swap1 [0x0 0x40] keccak256 [0x798 ... 187C]
//将0x42存储在计算出的地址中 的0x42 [0x42 0x798 ... 187c] swap1 [0x798 ... 187c 0x42] sstore 商店:{ 0x798 ... 187c => 0x42 }
mstore指令在内存中写入32个字节。 内存要便宜得多,只需要三种气体来读写。 程序集的前半部分通过将密钥和位置加载到相邻的内存块中来“连接”密钥和位置:
0 31 32 63 [键(32字节)] [位置(32字节)]
然后, keccak256指令散列该内存区域中的数据。 成本取决于有多少数据被散列:
- 30为每个SHA3操作付费。
- 6为每个32字节的单词付费。
对于uint256键,气体成本是42( 30 + 6 * 2 )。
映射大数值
每个存储插槽只能存储32个字节。 如果我们试图存储更大的结构会发生什么?
杂注扎实0.4.11;
合同C { 映射(uint256 => Tuple)元组;
结构元组{ uint256 a; uint256 b; uint256 c; }
函数C(){ 元组[0x1] .a = 0x1A; 元组[0x1] .b = 0x1B; 元组[0x1] .c = 0x1C; } }
编译,你应该看到3个sstore指令:
TAG_2: // ...省略未优化的代码 0X1A 0xada5013122d395ba3c54772283fb069b10426056ef8ca54750cb9bb552a59e7d sstore
0x1b 0xada5013122d395ba3c54772283fb069b10426056ef8ca54750cb9bb552a59e7e sstore
为0x1C 0xada5013122d395ba3c54772283fb069b10426056ef8ca54750cb9bb552a59e7f sstore
请注意,除最后一位数字外,计算出的地址是相同的。 Tuple结构体的成员字段被一个接一个地排列(.7d,.7e,.7f)。
映射不包装
鉴于映射的设计方式,即使您只存储1个字节,每个项目支付的最小存储量也是32个字节:
杂注扎实0.4.11;
合同C { 映射(uint256 => uint8)项目;
函数C(){ 项目[0xA] = 0xAA; 项目[0xB] = 0xBB; } }
如果值大于32字节,则以32字节为单位支付存储费用。
动态数组映射++
在一种典型的语言中,数组只是一个在内存中坐在一起的项目列表。 假设你有一个包含100个uint8元素的数组,那么它将占用100个字节的内存。 在此方案中,将整个阵列批量加载到CPU缓存中并循环遍历项目很便宜。
对于大多数语言来说,数组比地图便宜。 不过,对于Solidity来说,数组是一种更昂贵的映射版本。 数组的项目将按顺序排列在存储中,如:
0x290d ... e563 0x290d ... e564 0x290d ... E565 0x290d ... e566
但请记住,对这些存储插槽的每次访问实际上都是数据库中的键值查找。 访问数组元素与访问映射元素没有区别。
考虑类型[]uint256 ,它与mapping(uint256 => uint256)基本相同,并增加了使其“类似数组”的功能:
length来表示有多少物品。- 绑定检查。 读取和写入大于长度的索引时引发错误。
- 比映射更复杂的存储包装行为。
- 数组缩小时自动清零未使用的存储插槽。
- 对
bytes和string进行特殊优化,使短阵列(小于31字节)的存储效率更高。
简单的数组
我们来看看存储三个项目的数组:
// c-darray.sol 杂注扎实0.4.11;
合同C { uint256 [] chunks;
函数C(){ chunks.push(和0xAA); chunks.push(为0xBB); chunks.push(的0xCC); } }
数组访问的汇编代码太复杂,无法跟踪。 让我们使用Remix调试器来运行合约:
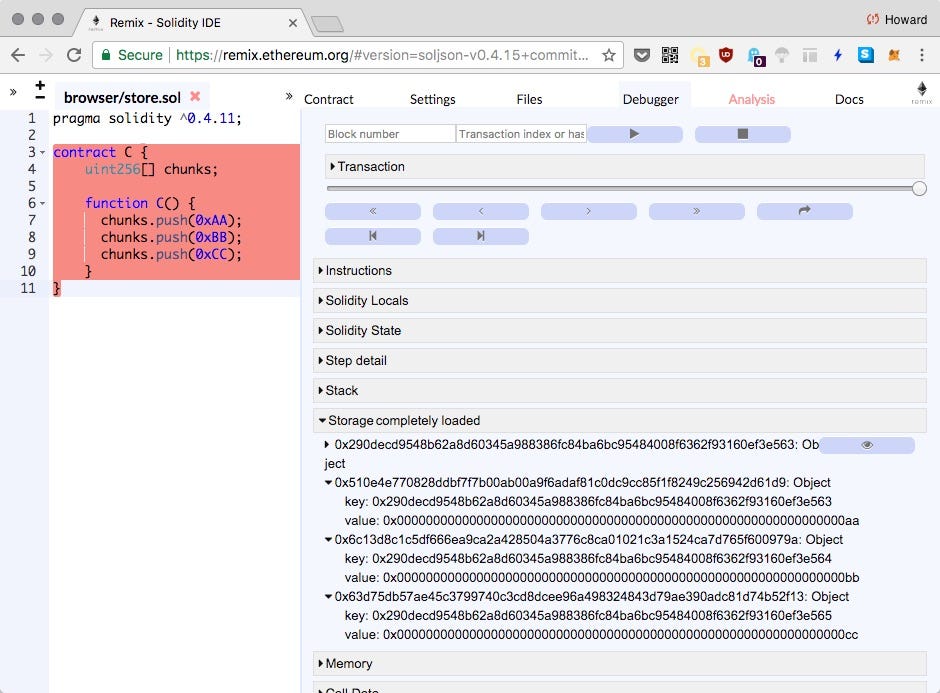
在仿真结束时,我们可以看到使用了4个存储插槽:
键:0x0000000000000000000000000000000000000000000000000000000000000000 值:0x0000000000000000000000000000000000000000000000000000000000000003
键:0x290decd9548b62a8d60345a988386fc84ba6bc95484008f6362f93160ef3e563 值:0x00000000000000000000000000000000000000000000000000000000000000
键:0x290decd9548b62a8d60345a988386fc84ba6bc95484008f6362f93160ef3e564 值:0x00000000000000000000000000000000000000000000000000000000000000BB
键:0x290decd9548b62a8d60345a988386fc84ba6bc95484008f6362f93160ef3e565 值:0x00000000000000000000000000000000000000000000000000000000000000CC
chunks变量的位置是0x0 ,用于存储数组的长度( 0x3 )。 散列变量的位置以查找存储阵列数据的地址:
#位置= 0 >>> keccak256(bytes32(0)) '290decd9548b62a8d60345a988386fc84ba6bc95484008f6362f93160ef3e563'
数组中的每个项目都从该地址( 0x29..65 )开始顺序0x29..65 。
动态数组打包
所有重要的包装行为如何? 数组映射的一个优点是包装工作。 四个项目的uint128[]阵列恰好适合两个存储插槽(加上1个用于存储长度)。
考虑:
杂注扎实0.4.11;
合同C { uint128 [] s;
函数C(){ s.length = 4; s [0] = 0xAA; s [1] = 0xBB; s [2] = 0xCC; s [3] = 0xDD; } }
在Remix中运行它,最后的存储如下所示:
键:0x0000000000000000000000000000000000000000000000000000000000000000 值:0x0000000000000000000000000000000000000000000000000000000000000004
键:0x290decd9548b62a8d60345a988386fc84ba6bc95484008f6362f93160ef3e563 值:0x000000000000000000000000000000bb000000000000000000000000000000aa
键:0x290decd9548b62a8d60345a988386fc84ba6bc95484008f6362f93160ef3e564 值:0x000000000000000000000000000000dd000000000000000000000000000000CC
正如预期的那样,只使用3个插槽。 长度再次存储在0x0处,即存储变量的位置。 四个项目包装在两个独立的存储插槽中。 该数组的起始地址是变量位置的哈希值:
#位置= 0 >>> keccak256(bytes32(0)) '290decd9548b62a8d60345a988386fc84ba6bc95484008f6362f93160ef3e563'
地址现在每增加两个数组元素就会增加一次。 看起来不错!
但汇编代码本身并没有得到很好的优化。 由于只使用两个存储插槽,因此我们希望优化器使用两个sstore进行分配。 不幸的是,在sstore边界检查(以及其他一些)的情况下,不可能优化sstore指令。
四个sstore指令用于分配:
/ *“c-bytes - sstore-optimize-fail.sol”:105:116 s [0] = 0xAA * / sstore / *“c-bytes - sstore-optimize-fail.sol”:126:137 s [1] = 0xBB * / sstore / *“c-bytes - sstore-optimize-fail.sol”:147:158 s [2] = 0xCC * / sstore / *“c-bytes - sstore-optimize-fail.sol”:168:179 s [3] = 0xDD * / sstore
字节数组和字符串
bytes和string是分别针对字节和字符进行优化的特殊数组类型。 如果阵列的长度小于31个字节,则只用一个存储槽来存储整个事物。 较长的字节数组与正常数组的表示方式大致相同。
我们来看一个实际使用的短字节数组:
// c-bytes - long.sol 杂注扎实0.4.11;
合同C { 字节s;
函数C(){ s.push(和0xAA); s.push(为0xBB); s.push(的0xCC); } }
由于阵列只有3个字节(小于31个字节),因此它只占用一个存储插槽。 在混音中运行,存储:
键:0x0000000000000000000000000000000000000000000000000000000000000000 值:0xaabbcc0000000000000000000000000000000000000000000000000000000006
数据0xaabbcc...从左到右存储。 接下来的0是空数据。 最后一个字节0x06是数组的编码长度。 公式为encodedLength / 2 = length 。 在这种情况下,实际长度是6 / 2 = 3 。
一个字符串的工作方式完全相同。
一个长字节数组
如果数据量大于31字节,则字节数组就像[]byte 。 让我们看看长度为128字节的字节数组:
// c-bytes - long.sol 杂注扎实0.4.11;
合同C { 字节s;
函数C(){ s.length = 32 * 4; s [31] = 0x1; s [63] = 0x2; s [95] = 0x3; s [127] = 0x4; } }
在Remix中运行,我们看到存储中使用了四个插槽:
0×0000 ... 0000 0×0000 ... 0101
0x290d ... e563 0×0000 ... 0001
0x290d ... e564 为0x0000技术...
0x290d ... E565 0×0000 ... 0003
0x290d ... e566 0×0000 ... 0004
插槽0x0不再用于存储数据。 整个插槽现在存储编码的数组长度。 要获得实际长度,请执行length = (encodedLength - 1) / 2 。 在这种情况下,长度是128 = (0x101 - 1) / 2 。 实际的字节存储在0x290d...e563 ,以及按顺序排列的插槽。
字节数组的汇编代码非常大。 除了正常的边界检查和数组调整大小的东西,它还需要编码/解码长度,以及在长和短字节数组之间进行转换。
为什么要编码长度? 因为它的完成方式,有一个简单的方法来测试一个字节数组是短还是长。 请注意,长阵列的编码长度总是奇数,即使是短阵列也是如此。 程序集只需要查看最后一位,看它是零(偶/短)还是非零(奇/长)。
结论
查看Solidity编译器的内部工作,我们发现熟悉的数据结构(如映射和数组)与传统的编程语言完全不同。
回顾一下:
- 数组就像映射,效率不高。
- 比映射更复杂的汇编代码。
- 比较小类型(字节,uint8,字符串)映射更好的存储效率。
- 大会没有得到很好的优化。 即使打包,每个作业也有一个
sstore。
EVM存储是一个键值数据库,非常像git。 如果你改变了任何东西,那么根节点的校验和就会改变。 如果两个根节点具有相同的校验和,则存储的数据保证相同。
要了解Solidity和EVM的独特之处,可以想象数组中的每个元素都是它自己的文件在git存储库中。 当你改变一个数组元素的值时,你实际上正在创建一个git commit。 在遍历数组时,无法一次加载整个数组,您必须查看存储库并分别查找每个文件。
不仅如此,每个文件被限制为32个字节! 因为我们需要将数据结构分割成32个字节的块,所以Solidity的编译器由于各种逻辑和优化技巧而复杂化,所有这些都是在汇编中完成的。
然而,32字节的限制完全是任意的。 备份键值存储可以使用键存储任意数量的字节。 也许在将来我们可以添加一个新的EVM指令来存储任意字节和一个关键字。
目前,EVM存储是一个预先假定为32字节数组的键值数据库。
请参阅ArrayUtils :: resizeDynamicArray了解编译器在调整数组大小时的作用。 通常情况下,数据结构将作为标准库的一部分在语言中完成,但在Solidity中,它会被烧入编译器。
https://medium.com/@hayeah/diving-into-the-ethereum-vm-the-hidden-costs-of-arrays-28e119f04a9b
【译】Diving Into The Ethereum VM Part 3 — The Hidden Costs of Arrays相关推荐
- 【译】 Diving Into The Ethereum VM Part 6 - How Solidity Events Are Implemented
在如何解读智能合约方法调用中,我们了解到"方法"是如何构建在简单EVM基元之上的抽象,如"跳转"和"比较"指令. 在本文中,我们将深入探讨S ...
- 【译】Diving Into The Ethereum VM Part 4 - How To Decipher A Smart Contract Method Call
在本系列的前几篇文章中,我们已经看到了Solidity如何在EVM存储中表示复杂的数据结构. 但是如果没有办法与数据交互,数据就毫无用处. 智能合约是数据与外部世界的中介. 在本文中,我们将看到Sol ...
- [译】Diving Into The Ethereum VM
Solidity提供了许多高级语言抽象,但是这些特性使我很难理解当我的程序运行时发生了什么. 阅读Solidity文档仍然让我对基本的东西感到困惑. 字符串,字节32,字节[],字节之间有什么区别? ...
- 【译】Diving Into The Ethereum VM Part 5 — The Smart Contract Creation Process
在本系列的前几篇文章中,我们学习了EVM汇编的基础知识,以及ABI编码如何允许外部世界与合同进行通信. 在这篇文章中,我们将看到合同是如何从无到有的. 本系列的前几篇文章(按顺序). EVM汇编代码简 ...
- 【译】Diving Into The Ethereum VM Part 2 — How I Learned To Start Worrying And Count The Storage Cost
在本系列的第一篇文章中,我们窥见了一个简单的Solidity合约的汇编代码: 合同C { uint256 a; 函数C(){ a = 1; } } 该合约归结为sstore指令的调用: // a = ...
- 从比特币脚本引擎到以太坊虚拟机
这个系列是目标受众是区块链开发者和有其他开发经验的CS专业学生 面对媒体对区块链相关技术的解读和吹捧,许多人一时不知所措.投资人.大公司都在FOMO(fear of missing out)的心理驱动 ...
- 深入了解以太坊虚拟机第4部分——ABI编码外部方法调用的方式
本文由币乎社区(bihu.com)内容支持计划赞助. 在本系列的上一篇文章中我们看到了Solidity是如何在EVM存储器中表示复杂数据结构的.但是如果无法交互,数据就是没有意义的.智能合约就是数据和 ...
- 深入了解以太坊虚拟机第3部分——动态数据类型的表示方法
本文由币乎社区(bihu.com)内容支持计划赞助. Solidity提供了在其他编程语言常见的数据类型.除了简单的值类型比如数字和结构体,还有一些其他数据类型,随着数据的增加可以进行动态扩展的动态类 ...
- 深入了解以太坊虚拟机第2部分——固定长度数据类型的表示方法
本文由币乎社区(bihu.com)内容支持计划赞助 在本系列的第一篇文章中,我们已经看到了一个简单的Solidity合约的汇编代码: contract C {uint256 a;function C( ...
最新文章
- 2021 - 9 下旬 数据结构-线性表-循环队列-java实现代码
- PHP 如何阻止用户上传成人照片或者裸照
- 图解ARP协议(二)ARP攻击原理与实践
- 【bzoj2006】【NOI2015】超级钢琴
- 自己定义WinXP的时间校正服务器
- addEventListener 的事件函数的传递【转载】
- 用TortoiseGit时的实用git命令
- fastjson解析JSON数据乱序导致的问题
- 字符串最后一个单词的长度
- KTHREAD 线程调度 SDT TEB SEH shellcode中DLL模块机制动态获取 《寒江独钓》内核学习笔记(5)...
- SQL代码自动生成器
- python灰色预测模型步骤人口预测_人口预测模型灰色预测
- Chrome插件--IDM
- C语言最新学习路线(从入门到实战)
- 【博闻强记】java来发送邮件
- Java学习-发红包案例
- outlook邮箱邮件大小限制_附件大小超过了允许的限制错误 - Outlook | Microsoft Docs...
- 服务器存储视频文件夹在哪里找,微信视频文件夹存储在什么位置?在哪里能找到...
- 如何将项目使用docker分块部署
- Oracle标准版和企业版
热门文章
- Android 自定义组件随着手指自动画圆
- pku 1850 Code 组合数学排列组合的应用
- Python学习笔记:基础
- 系统安装重装与优化:chapter6:使用常用软件与电脑外设
- 浅谈 Python 程序和 C 程序的整合
- IEEE conference 中出现的PDF字体嵌入的问题
- 【随笔】深度学习之美——杨家有女初长成,养在深闺人未识
- 学长毕业日记 :本科毕业论文写成博士论文的神操作20170316
- 云炬Android开发报错处理教程 解决Android Studio kotlin等依赖下载慢,下载超时失败的问题
- 台湾大学林轩田机器学习基石课程学习笔记2 -- Learning to Answer Yes/No