为金融带来智慧的视觉——CVPR 2018参会总结(上)
引言
CVPR( Computer Vision and Pattern Recognization )是计算机视觉领域的三大学术顶会之一,也是工业界极为关注的风向标,各种前瞻性的技术动向,商业应用场景,乃至创业投资热点都会在大会上进行展示和传播。2018年CVPR在美国盐湖城召开,蚂蚁金服首次以白金赞助商的身份参会,并展示了定损宝、无人零售、Zolos、xMedia等计算机视觉方面的应用,引起业内关注;同时,参会同学也借此机会和参会同行进行了广泛交流,取长补短,互通有无。
本文尝试以互联网金融,尤其是互联网保险领域的视角,对CVPR 2018所展示的值得注意的技术方向,并对未来可能的应用前景进行探讨。本届CVPR共接受979篇论文,20多场tutorial,近50场workshop,信息量堪称巨大;作为以行业应用为主线的总结,本文难以做到全面而详尽,大家也可参阅集团和蚂蚁AI部门各位参会同学的文章。

1.C端场景下的影像采集与处理
自助式服务、在线提交材料、快捷理赔甚至全自动理赔,已经成为互联网保险理赔服务的标志性卖点。相比传统线下理赔渠道,互联网保险
对保险标的或理赔材料的拍摄、上传,是在线理赔服务的第一步。例如,蚂蚁金服推出的“多收多保”产品,可以让用户对医疗发票和单据进行拍摄上传,无需传递纸质单据;而“定损宝”可以引导用户对车辆损伤处拍摄照片或视频,对纯外观案件完成全自动定损。这一步所采集的图像或视频信息的质量,将直接决定后续步骤的准确率。
保险行业使用原始资料的影像件已有几十年的历史,但在传统处理流程中,影像化这一步是由专业团队,使用扫描仪、高拍仪等专业设备来完成的,对数字影像的要求以人眼能准确辨识为主,数字化影像的主要用途是实现人工处理流程中单据的无纸化流转,以及降低资料存档的成本,提高检索效率。其中对于部分印刷资料,可能使用传统OCR技术来完成影像到文字的转换,以利用IT系统实现自动处理。而对于互联网保险场景,操作者是普通用户,往往不具备专业人员的操作技能,所使用的设备是普通手机自带的相机,拍摄场景五花八门,因此所拍摄的图像或视频往往有拍摄目标错误、拍摄角度不合理、成像模糊、曝光不足或强光反射等问题,因而采集到的数字化影像质量和专业团队操作相比要差很多,传统OCR算法难以取得较好效果。

示例:用户上传的拍摄质量很差的发票照片
而车险理赔场景中,传统线下理赔流程是由专职查勘人员对车辆损伤进行拍摄,就事故成因、损伤程度等关键定损信息来说,拍摄的专业程度也要比普通车主高很多。
因此,互联网保险理赔场景要回答几个关键问题:
- 怎样引导用户正确地拍摄目标
- 怎样帮助用户提高成像质量
- 怎样给用户合适的反馈,帮助用户知道不合格拍摄的问题在哪里,以及怎样纠正问题
- 怎样从较低拍摄质量的影像数据中得到满意结果
对这些问题的解答,可以分为以下几个类别。
移动端视觉任务
如果能将分类、检测等任务前置到移动设备上进行,就能大幅提高拍摄引导、反馈的时效性,甚至做到准实时。例如,下面的交互设计案例中,在拍摄实景中实时叠加损伤区域,帮助用户对准车辆损失部位:

在这种场景下,如何提高运行效率、减少模型大小、降低运算能耗,就成为比较重要的问题。本次大会有相当数量的paper关注移动端计算,例如:
Shift: A Zero FLOP, Zero Parameter Alternative to Spatial Convolutions
提出了一种融合了平移和逐点卷积的可端到端训练的模块,以代替传统的卷积操作,能大幅减少参数。这种模型压缩方法有望将之前只能运行在服务端的大型模型压缩到移动设备可接受测尺寸。

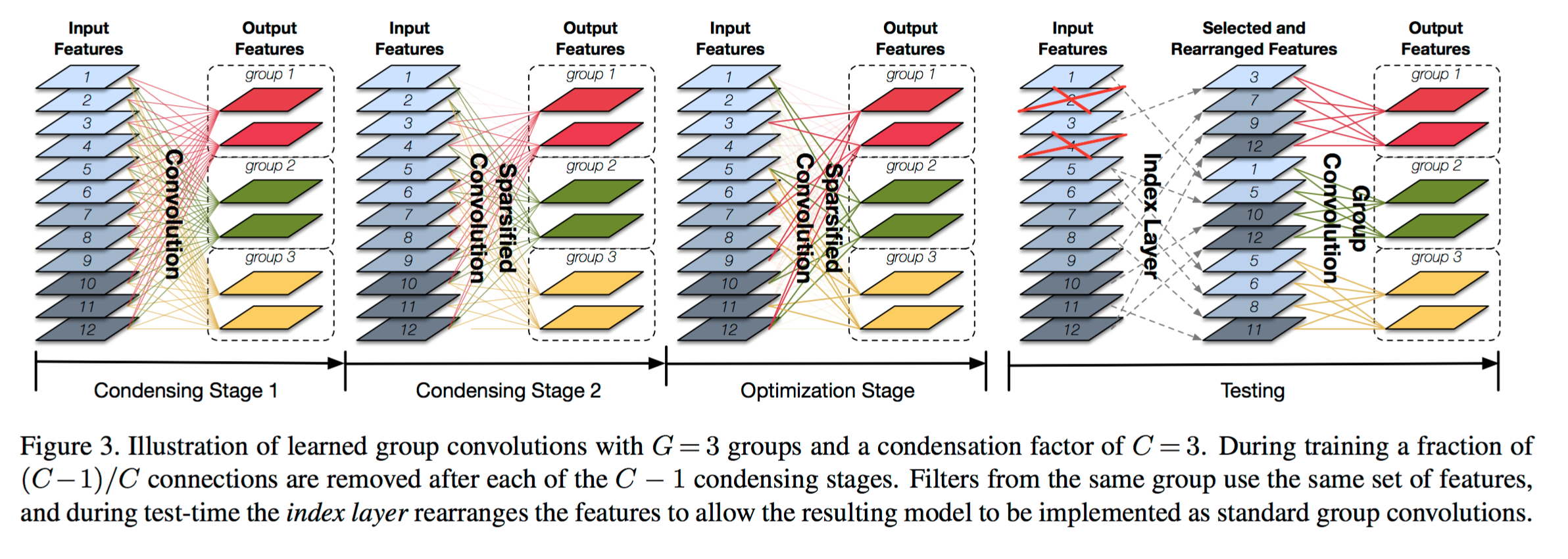
CondenseNet: An Efficient DenseNet using Learned Group Convolutions
提出DenseNet的优化方案,通过卷积的group操作以及在训练时候的剪枝来达到降低显存提高速度的目的。
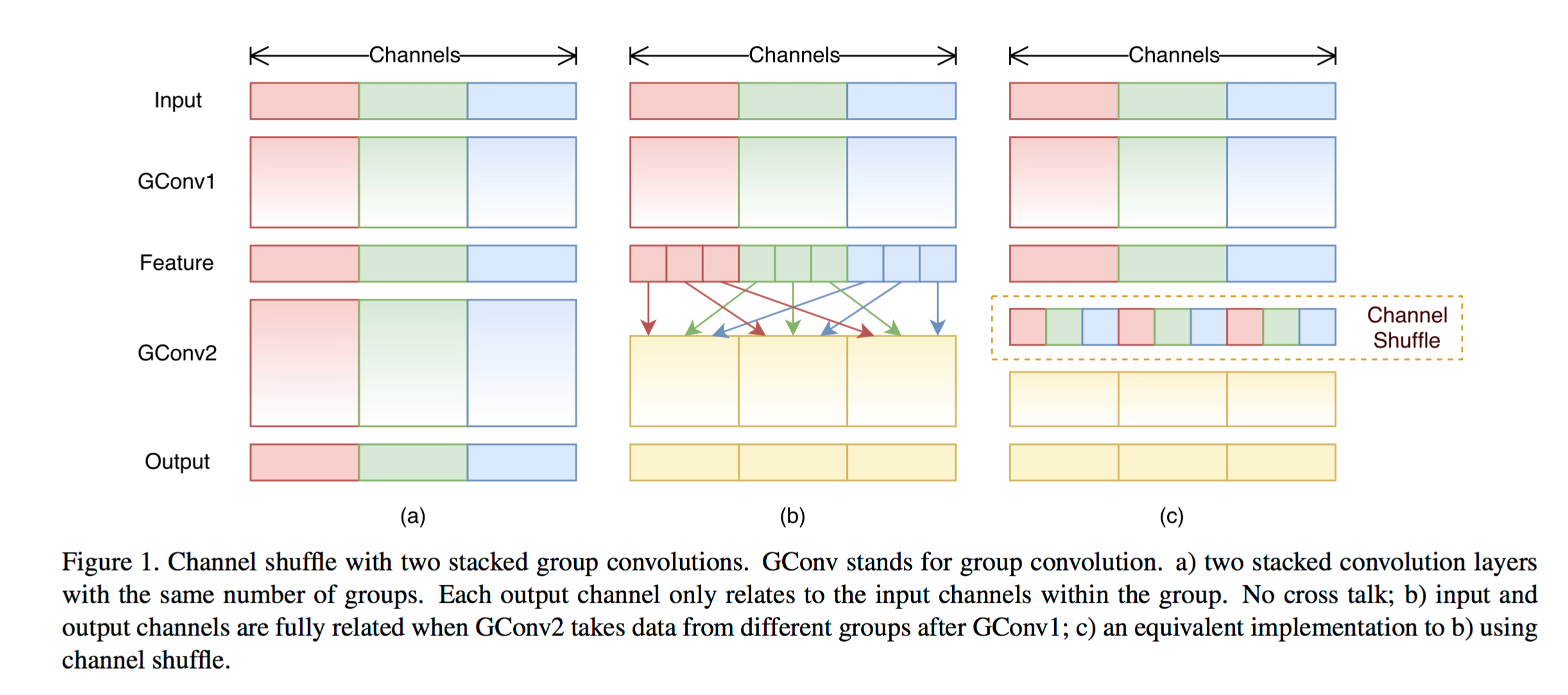
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
来自旷视科技孙剑团队的ShuffleNet,提出一种适合移动设备的网络结构,引入pointwise group convolution和channel shuffle两种新的操作,以提高运算效率。
图像与视频质量增强
让用户手持手机在任意时间地点拍摄,始终无法根除弱光,抖动,脱焦等影响成像质量的因素。如果有办法提升原始影像的质量,对后续处理——不论是自动还是人工——都是有好处的。
Super SloMo: High Quality Estimation of Multiple Intermediate Frames for Video Interpolation
Nvidia提出一种可变长度多帧视频插值的端到端卷积神经网络,对普通视频进行插帧后,达到高速摄像机的“超慢动作”拍摄效果。现场演示效果黑科技感非常强。这种技术如果用于监控视频增强处理,有望给事故现场还原带来全新的解决方案。

图片不足以体现惊艳的效果,可以移步观看Nvidia提供的演示视频:
视频地址
Learning to See in the Dark
引入了短时间曝光图片和对应的长时间曝光图片的数据集,并以此训练出一个全卷积网络,直接用于原始传感器数据,取代传统的图像处理pipeline。这种方法有望在移动设备上产生更好的弱光成像效果。

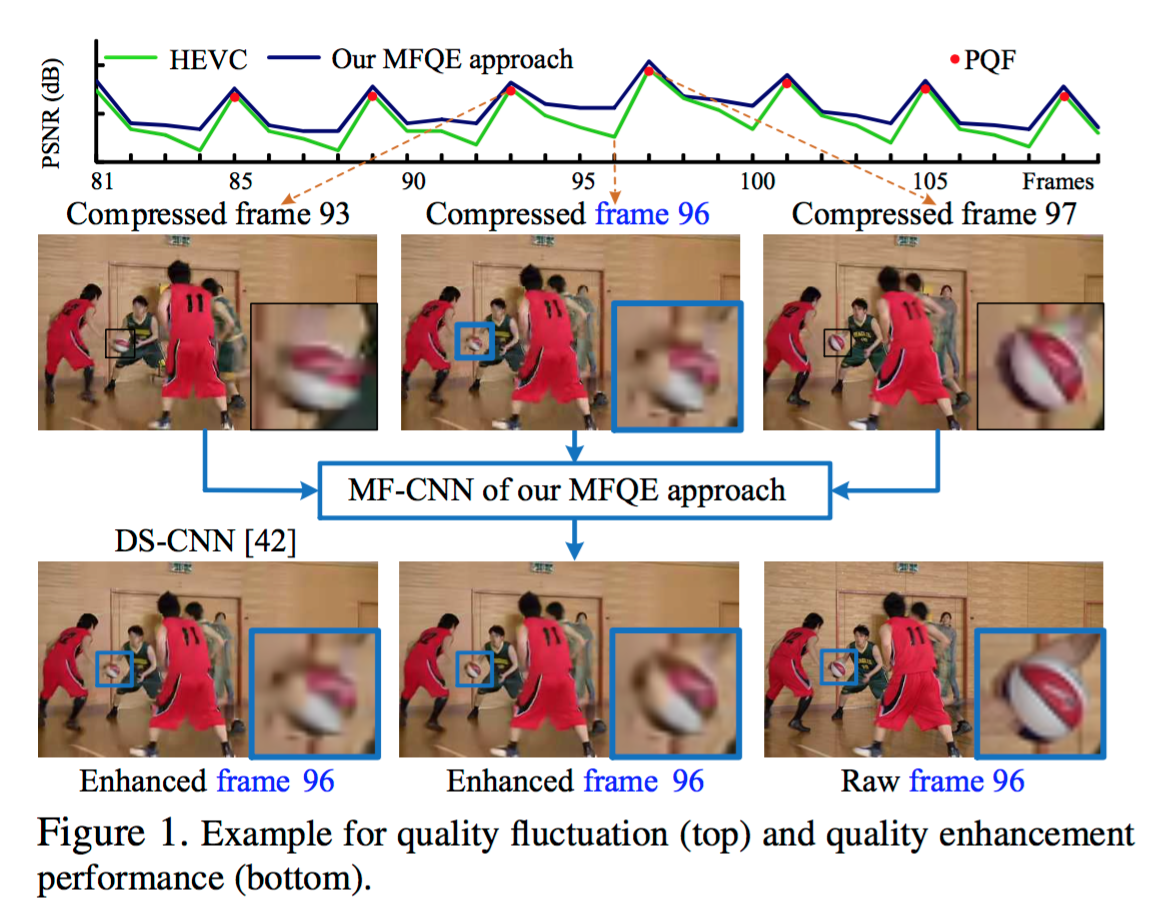
Multi Frame Quality Enhancement for Compressed Video
提出视频多帧质量增强的一种方法,用临近的高质量帧对低质量帧进行增强。作者的思路是通过SVM检测视频中各帧的质量峰值,然后设计了一种多帧卷积神经网络(MF-CNN),以低质量帧及其最近的两个高质量帧未输入,得到增强质量的结果。
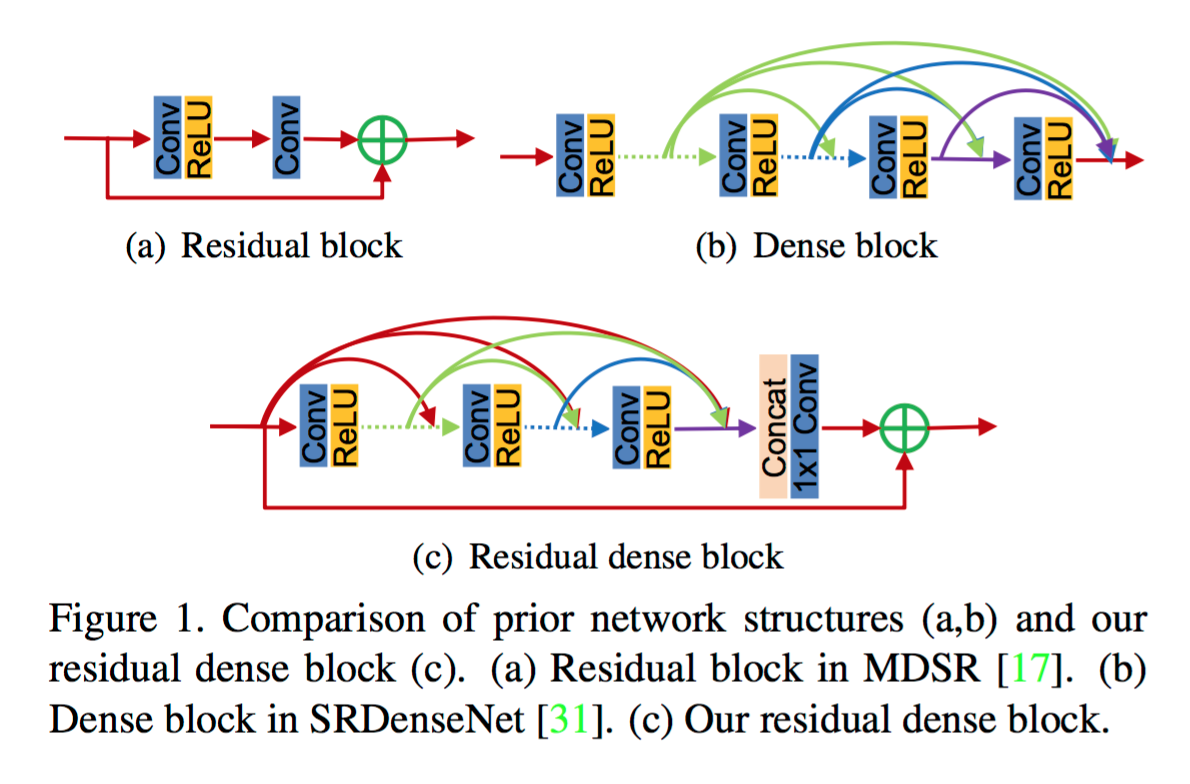
Residual Dense Network for Image Super-Resolution
利用CNN来实现图像高分辨率重建(SR),本篇比较新颖的地方是提出残差密集网络(residual dense network ),充分利用所有各卷积层从低分辨率图像中提取的层次化特征。
此外,利用GAN来做图像质量增强也是一个热门的方向,将在后面GAN专题部分详细介绍。
2.海量图片的标注与处理
绝大多数成功的互联网业务都意味着海量的数据。以支付宝中的“多收多保”业务为例,哪怕只是面向小型商户而非所有用户,其承载的日常理赔量也达到了XXX量级(此处因保密原因不能直接透露数据,大家可以用贝叶斯网络进行脑补),每天都有海量的医疗票据图片需要处理。因此,以下问题的探索,对于互联网应用具有非常重要的价值:
- 如果提高人工标注的效率
- 如何减少对标注数量的需求
- 怎样降低标注数据的获取难度
以下各举一例:
Efficient Interactive Annotation of Segmentation Datasets with Polygon-RNN++
很有趣的一个思路,由人去点击图片中要标注目标的边缘点,再算法去自动识别目标的边缘,这种半自动交互式的标注比纯人工标注边缘的效率要高很多。作者使用了多种优化方案:为本场景设计基于CNN编码器,用强化学习的思路提高训练效率,用Graph Neural Network提高标注的分辨率。

Learning to Segment Every Thing
Kaiming He团队提出的利用MaskRCNN解决分割问题的新思路。在目标分割这个领域,标注成本始终是一个难题。本文提出一种transfer learning的思路,用instance mask+bounding box混合数据集(Visual Genome+COCO)构建一个从廉价的bounding box到昂贵的instance mask映射,以达到“Segment every thing”的目的。
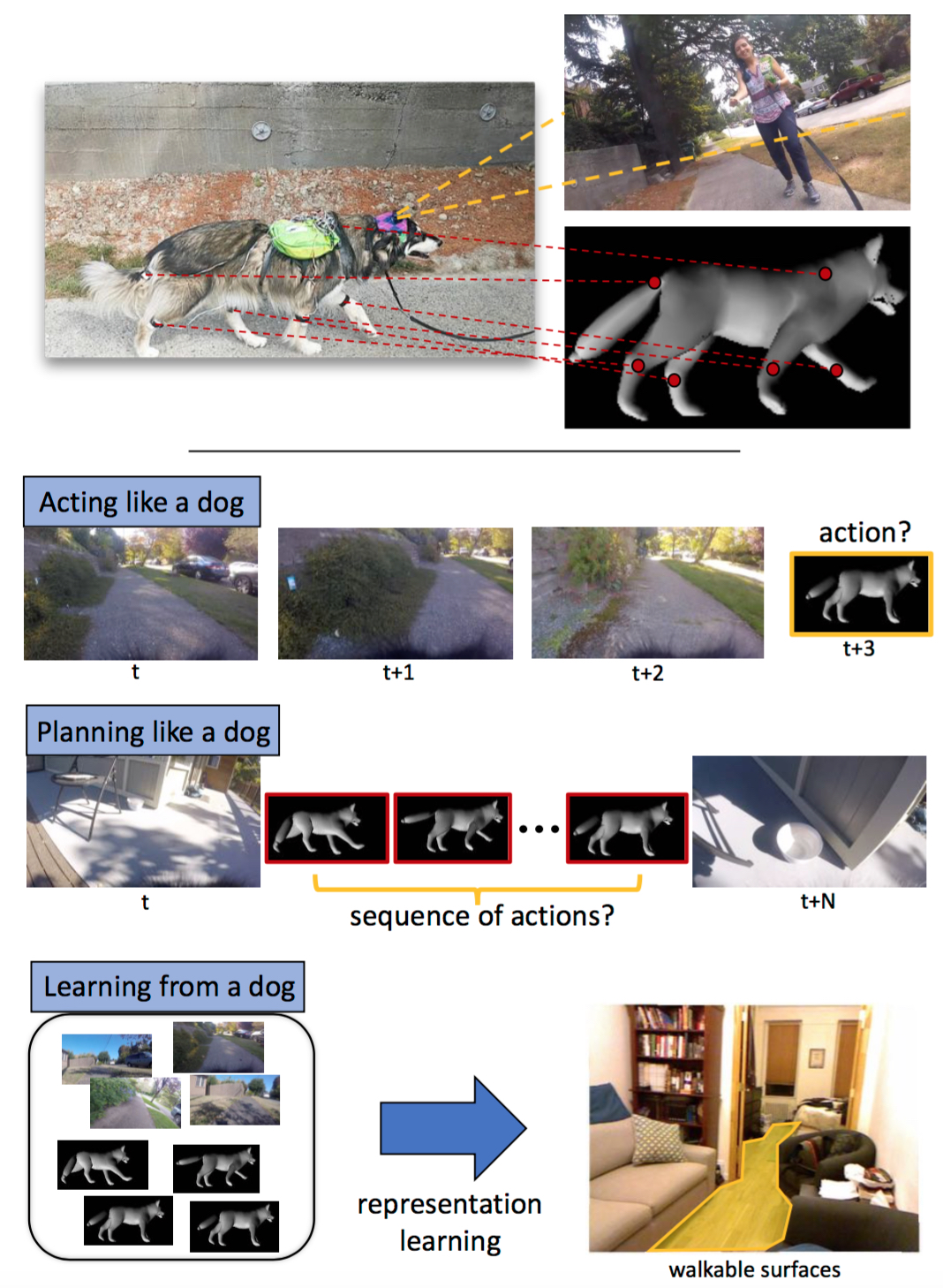
Who Let The Dogs Out? Modeling Dog Behavior From Visual Data
这一定是全场最萌的一篇paper,思路清奇。汪星人整天都在想啥呢?为了破解这个难题,作者在狗身上安装了摄像机和传感器,同时采集视觉数据和行为数据,然后以CNN去提取视觉特征,用LSTM去预测狗的下一步行动。简单说,就是输入视觉,输出行动。数据的获取和行为的标注是一个全自动的闭环,一只自由行动的狗,可以不断产生大量标注数据,相比于外包标注的时薪成本可以说是相当之低了。这个案例给我们的启发,一是寻找能够让数据“自我标注”的方法,二是融合多种信息,也许可以发现不同的解决思路。
3. GAN
本届大会,GAN是毫无疑问最火热的研究领域,以至于有一种说法:GAN成为下一个“深度学习”。有Goodfellow大神参加的GAN的专题workshop,现场爆满,热情观众都排到门外了。

目前在GAN的应用场景上,画风迁移、图像修饰(嗯,美颜P图)、图像生成在文娱行业有非常广泛的前景,现场也看到Facebook、今日头条、腾讯等公司都展示了相关的产品或技术。
High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
本次大会的Oral,通过在D中多层抽取 feature map来改进Adversarial Loss,以及G和D引入多重scale等创新方法,将GAN生成图像的分辨率提高到了2048*1024,突破了以往的极限。此外从实用角度,特别值得关注的是,作者通过引入目标分割信息,来提供对目标对象的操作功能(如增减对象,改变对象类型等),以及探索了让用户能够交互式编辑生成对象的外观的方法。
WESPE: Weakly Supervised Photo Enhancer for Digital Cameras
GAN用于手机拍摄的低质量图片增强,达到单反效果。这是互联网理赔场景下特别实用的一个方向。前文介绍了用CNN来生成低质量图片的高质量版本,或替代图像增强pipeline中某个步骤的方法,而基于GAN的image-to-image方法,能够用少量训练数据,以弱监督学习的方式达到不错的效果,也是非常有前景的。

Finding Tiny Faces in the Wild with Generative Adversarial Network
这是一个有趣的组合,将GAN用于对图片中的tiny face生成高分辨率版本,从而提高人脸检测的性能。推广到其他检测目标在原始图像中比例较小的场景,也是有可能的,例如在一张车辆全景照中检测微小的损伤。

DA-GAN: Instance-level Image Translation by Deep Attention Generative Adversarial Networks
微软亚洲研究院提出的将Attention机制与GAN结合,提高图像生成质量的工作。有大量的图像生成任务都可以归纳为image2image,即将输入图像翻译为目标输出图像,例如画风转换,质量增强,缺失复原等。目前一对一(paired data)转换效果最好的是pix2pix网络,多对一(unpaired data)转换效果最好的是CycleGAN,但这两种方法都是图像级的特征学习,难以对部分区域进行控制。本文提出了解决instance-level图像转换问题的思路:通过一个深度 Attention 编码器(DAE)来自动地学习各个 instance,然后将不同的部分分别投射到一个「隐空间」,最后通过 GAN 网络进行生成。

最后附上一张蚂蚁金服在CVPR 2018上的展台。作为本次AI热潮的领头羊,计算机视觉在互联网金融领域有广泛的应用前景,蚂蚁金服保险事业群以及人工智能、物联网事业部也诚邀各位有兴趣的技术同学共同加入!

为金融带来智慧的视觉——CVPR 2018参会总结(上)相关推荐
- 商汤科技 中科院自动化所:视觉跟踪之端到端的光流相关滤波 | CVPR 2018
作者丨朱政 学校丨中科院自动化所博士生 单位丨商汤科技 研究方向丨视觉目标跟踪及其在机器人中的应用 本文主要介绍我们发表于 CVPR 2018 上的一篇文章:一种端到端的光流相关滤波跟踪算法.据我们所 ...
- 【CVPR 2018热文】MIT提出“透明设计”网络,揭开视觉黑盒
根据看到的图像来回答问题,需要在图像识别和分类的基础上再进一步,形成对图中物体彼此关系的推理和理解,是机器完成复杂任务所需的一项基本能力,也是视觉研究人员目前正在努力攻克的问题. 最近,在视觉推理任务 ...
- CVPR 2018 | 8篇论文、10+Demo、双项挑战赛冠军,旷视科技掀起CVPR产学研交流热潮
第 31 届计算机视觉和模式识别大会 CVPR 2018(Conference on Computer Vision and Pattern Recognition)在 6 月 18 日至 22 日于 ...
- CVPR 2018 | 旷视科技Face++率先提出DocUNet 可复原扭曲的文档图像
全球计算机视觉顶会 CVPR 2018 (Conference on Computer Vision and Pattern Recognition,即IEEE国际计算机视觉与模式识别会议)将于6月1 ...
- CVPR 2018现场见闻
关于作者:万纬韬,本科毕业于清华大学电子工程系,现于清华大学信息认知与智能系统研究所攻读博士二年级,主要研究方向包括基于深度学习的人脸检测与识别,对抗样本,图像语义分割. 计算机视觉顶级会议 CVPR ...
- CVPR 2018 最具创意论文 TOP10
每年计算机视觉与模式识别会议 (CVPR) 都会带来杰出而有趣的研究,今年在美国盐湖城举办的CVPR 2018也不例外. CVPR 2018上许多论文提出了全新的深度神经网络在视觉上的应用,它们可能不 ...
- CVPR 2018 | 腾讯AI Lab关注的三大方向与55篇论文
感谢阅读腾讯 AI Lab 微信号第 32 篇文章,CVPR 2018上涌现出非常多的优秀论文,腾讯 AI Lab 对其中精华文章归类与摘要,根据受关注程度,对生成对抗网络.视频分析与理解和三维视觉三 ...
- CVPR 2018 最酷的十篇论文
本文为 AI 研习社编译的技术博客,原标题 : The 10 coolest papers from CVPR 2018 作者 | George Seif 翻译 | Vincents ...
- CVPR 2018 | 鸡尾酒网络DCTN:源分布结合律引导的迁移学习框架
机器之心经授权发布,作者:Ruijia Xu.Ziliang Chen.Wangmeng Zuo.Junjie Yan.Liang Lin. 来自中山大学.哈尔滨工业大学以及商汤科技公司的研究人员联合 ...
最新文章
- 基本概念学习(9001)---指令系统
- gdo图形引擎中的旋转角
- 继续C#开发or转做产品
- 2016windows(10) wamp 最简单30分钟thrift入门使用讲解,实现php作为服务器和客户端的hello world...
- [css] 用CSS绘制一个红色的爱心
- 音频服务器未运行怎么办,音频服务未运行怎么办 音频服务未运行解决方法【详细介绍】...
- 联想服务器查看运行状态,服务器硬件批量监控工具
- 国外兼职网站列举 79个
- D630,vista sp2,4GB Turbo Memory,ITMService.exe(SmartPinService),Posses lots of CPU Resources
- 洛谷 P2672 推销员
- C++笔试面试题 从网上整理的,带答案
- 再现隐私之争_反谷歌FLoC联盟: selenium谷歌浏览器报错: Error with Permissions-Policy header
- iOS “此证书由未知颁发机构签名“
- sqlite3数据库文件损坏修复
- Revit API: Dimension 尺寸标注
- Unity3D网络游戏《僵尸星球》
- 统信UOS专业版安装VMware
- Linux 系统烧写实操
- Logback设置日志级别
- 简单记录Java的AES128加密和解密